【完整源码+数据集+部署教程】飞机表面损伤检测系统源码和数据集:改进yolo11-AFPN-P345
【完整源码+数据集+部署教程】飞机表面损伤检测系统源码和数据集:改进yolo11-AFPN-P345
背景意义
随着航空工业的快速发展,飞机的安全性和可靠性成为了行业关注的重点。飞机在使用过程中,表面损伤如凹陷、划痕等问题不仅影响美观,更可能对飞行安全造成潜在威胁。因此,及时、准确地检测飞机表面损伤显得尤为重要。传统的人工检测方法不仅耗时耗力,而且容易受到人为因素的影响,导致漏检或误检的情况发生。为了提高检测效率和准确性,基于计算机视觉的自动化检测系统应运而生。
在众多计算机视觉算法中,YOLO(You Only Look Once)系列算法因其高效的实时检测能力而受到广泛关注。YOLOv11作为该系列的最新版本,具备更强的特征提取能力和更快的推理速度,适合应用于复杂的视觉检测任务。通过对YOLOv11进行改进,结合飞机表面损伤的特点,可以构建一个高效的飞机表面损伤检测系统。该系统不仅能够快速识别和定位损伤,还能为后续的维修和保养提供重要依据。
本研究所使用的数据集包含220张标注图像,主要针对凹陷这一类别进行训练。数据集的设计考虑到了实际应用中的需求,确保了模型在真实场景中的有效性和可靠性。通过对数据集的精细标注和YOLOv11模型的优化,期望能够显著提升飞机表面损伤检测的准确率和效率,为航空安全提供更为坚实的技术支持。
综上所述,基于改进YOLOv11的飞机表面损伤检测系统的研究,不仅具有重要的学术价值,也为航空工业的安全管理提供了切实可行的解决方案。通过这一系统的应用,能够有效降低人工检测的成本,提高飞机维护的及时性,从而保障航空安全,推动航空业的可持续发展。
图片效果
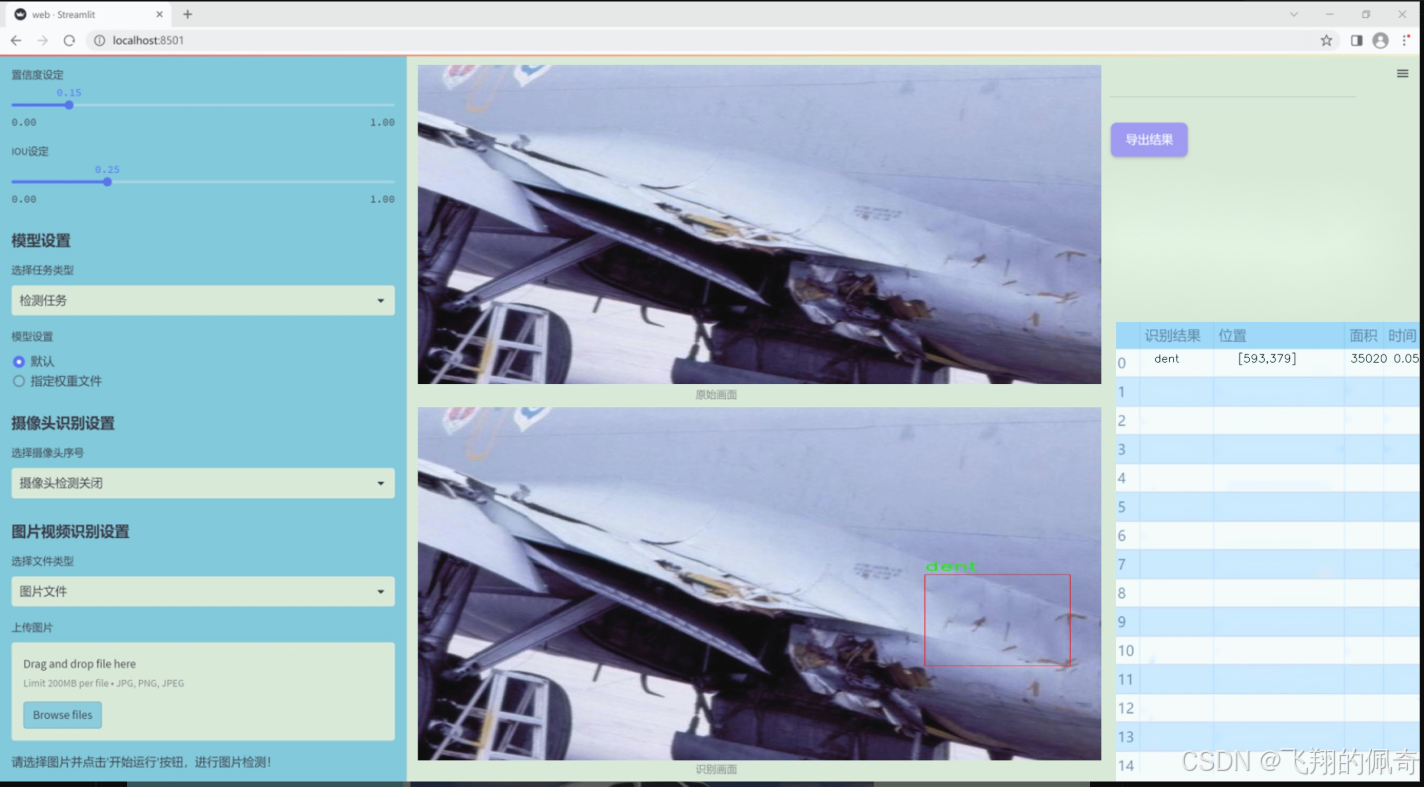
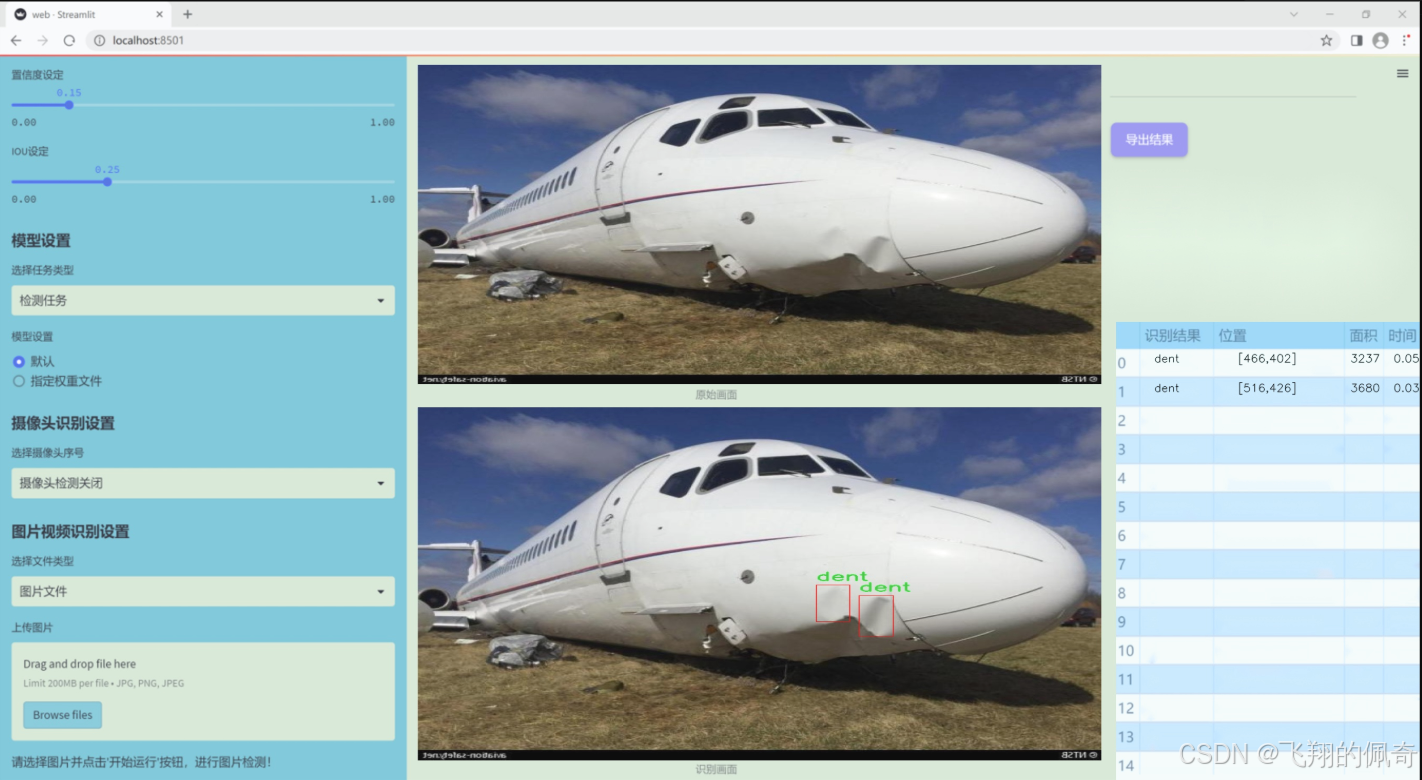
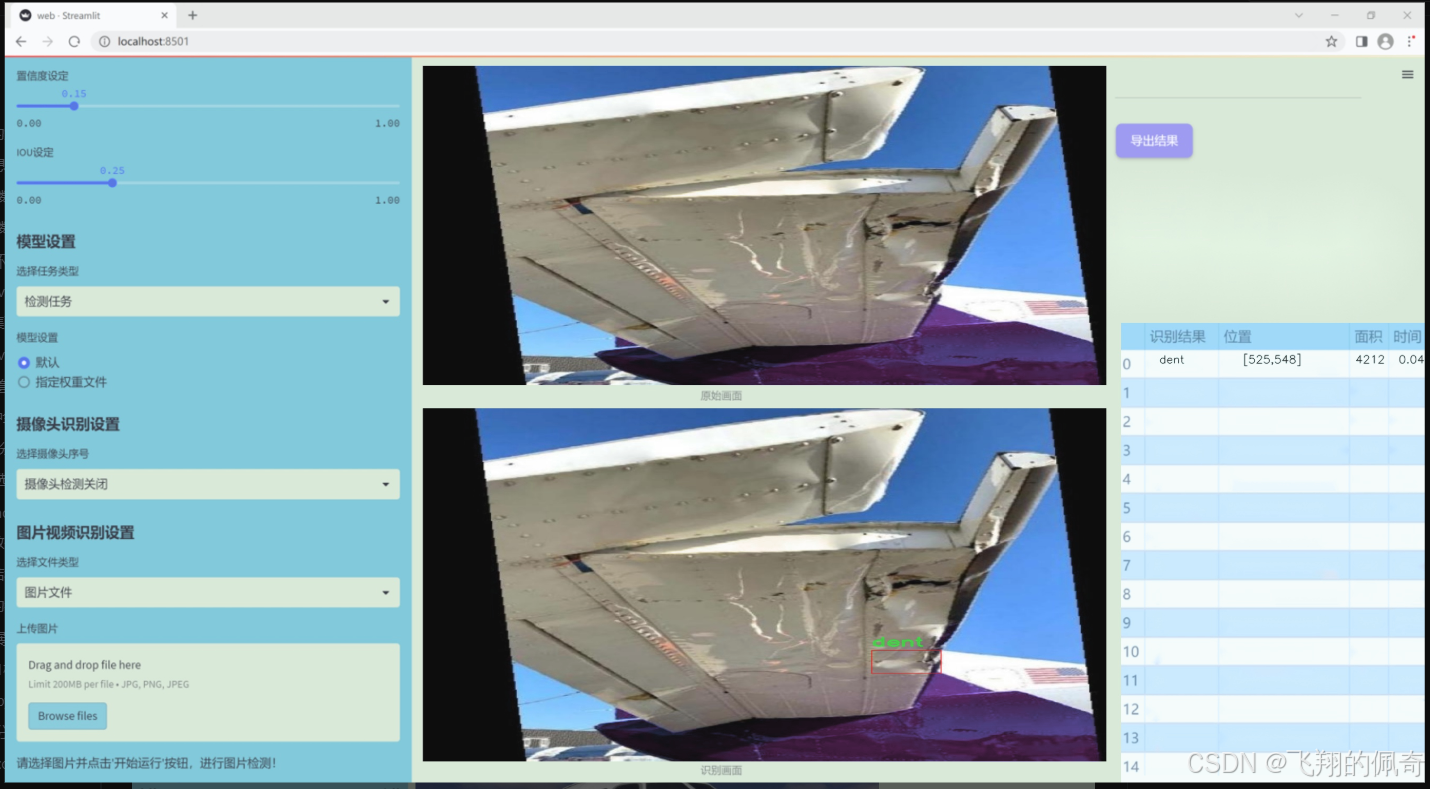
数据集信息
本项目数据集信息介绍
本项目旨在开发一种改进的YOLOv11模型,以实现对飞机表面损伤的高效检测。为此,我们使用了名为“Aircraft Damage Detection 2”的数据集,该数据集专门针对飞机表面损伤的识别与分类而设计。数据集中包含了多种飞机表面损伤的图像,经过精心标注,以确保模型在训练过程中能够准确学习到损伤特征。
该数据集的类别数量为1,具体类别为“dent”,即凹陷损伤。这一类别的选择反映了飞机在使用过程中常见的损伤类型,能够有效地帮助航空维修人员及时发现并处理潜在的安全隐患。数据集中包含的图像涵盖了不同角度、光照条件和背景的凹陷损伤实例,确保了模型训练的多样性和鲁棒性。
通过对“dent”类别的深度学习,模型将能够识别出飞机表面微小的凹陷损伤,这对于保障飞行安全至关重要。数据集中的图像不仅包含了不同类型的凹陷损伤,还考虑到了不同飞机材料和表面处理的差异,使得模型能够在实际应用中具备更强的适应性和准确性。
在数据预处理阶段,我们对图像进行了标准化处理,以提高模型的训练效率。同时,采用数据增强技术,增加了数据集的多样性,进一步提升了模型的泛化能力。通过这些措施,我们期望最终训练出的YOLOv11模型能够在实际应用中实现高效、准确的飞机表面损伤检测,为航空安全提供有力保障。




核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.layers import to_2tuple, trunc_normal_
class CrossLayerPosEmbedding3D(nn.Module):
def init(self, num_heads=4, window_size=(5, 3, 1), spatial=True):
super(CrossLayerPosEmbedding3D, self).init()
self.spatial = spatial # 是否使用空间位置嵌入
self.num_heads = num_heads # 注意力头的数量
self.layer_num = len(window_size) # 层数
# 初始化相对位置偏置表
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[0] - 1), num_heads)
)
# 计算相对位置索引
self.register_buffer(“relative_position_index”, self.compute_relative_position_index(window_size))
trunc_normal(self.relative_position_bias_table, std=.02) # 初始化偏置表
# 初始化绝对位置偏置
self.absolute_position_bias = nn.Parameter(torch.zeros(len(window_size), num_heads, 1, 1, 1))
trunc_normal_(self.absolute_position_bias, std=.02)
def _compute_relative_position_index(self, window_size):
# 计算相对位置索引的函数
coords_h = [torch.arange(ws) - ws // 2 for ws in window_size]
coords_w = [torch.arange(ws) - ws // 2 for ws in window_size]
coords = [torch.stack(torch.meshgrid([coord_h, coord_w])) for coord_h, coord_w in zip(coords_h, coords_w)]
coords_flatten = torch.cat([torch.flatten(coord, 1) for coord in coords], dim=-1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += window_size[0] - 1
relative_coords[:, :, 1] += window_size[0] - 1
relative_coords[:, :, 0] *= 2 * window_size[0] - 1
return relative_coords.sum(-1)
def forward(self):
# 前向传播,计算位置嵌入
pos_indicies = self.relative_position_index.view(-1)
pos_indicies_floor = torch.floor(pos_indicies).long()
pos_indicies_ceil = torch.ceil(pos_indicies).long()
value_floor = self.relative_position_bias_table[pos_indicies_floor]
value_ceil = self.relative_position_bias_table[pos_indicies_ceil]
weights_ceil = pos_indicies - pos_indicies_floor.float()
weights_floor = 1.0 - weights_ceil
pos_embed = weights_floor.unsqueeze(-1) * value_floor + weights_ceil.unsqueeze(-1) * value_ceil
pos_embed = pos_embed.reshape(1, 1, self.num_token, -1, self.num_heads).permute(0, 4, 1, 2, 3)
return pos_embed
class CrossLayerSpatialAttention(nn.Module):
def init(self, in_dim, layer_num=3, beta=1, num_heads=4, mlp_ratio=2, reduction=4):
super(CrossLayerSpatialAttention, self).init()
self.num_heads = num_heads # 注意力头的数量
self.reduction = reduction # 维度缩减比例
self.window_sizes = [(2 ** i + beta) if i != 0 else (2 ** i + beta - 1) for i in range(layer_num)][::-1]
self.token_num_per_layer = [i ** 2 for i in self.window_sizes] # 每层的token数量
self.token_num = sum(self.token_num_per_layer) # 总token数量
# 定义卷积位置编码、层归一化、线性变换等模块
self.cpe = nn.ModuleList([ConvPosEnc(dim=in_dim, k=3) for _ in range(layer_num)])
self.norm1 = nn.ModuleList(LayerNormProxy(in_dim) for _ in range(layer_num))
self.norm2 = nn.ModuleList(nn.LayerNorm(in_dim) for _ in range(layer_num))
self.qkv = nn.ModuleList(nn.Conv2d(in_dim, in_dim, kernel_size=1) for _ in range(layer_num))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x_list):
# 前向传播,计算跨层空间注意力
q_list, k_list, v_list = [], [], []
for i, x in enumerate(x_list):
x = self.cpe[i](x) # 应用卷积位置编码
qkv = self.qkv[i](x) # 计算Q、K、V
q, k, v = qkv.chunk(3, dim=1) # 分割Q、K、V
q_list.append(q)
k_list.append(k)
v_list.append(v)
# 计算注意力
q_stack = torch.cat(q_list, dim=1)
k_stack = torch.cat(k_list, dim=1)
v_stack = torch.cat(v_list, dim=1)
attn = F.normalize(q_stack, dim=-1) @ F.normalize(k_stack, dim=-1).transpose(-1, -2)
attn = self.softmax(attn)
# 输出结果
out = attn @ v_stack
return out
class ConvPosEnc(nn.Module):
def init(self, dim, k=3):
super(ConvPosEnc, self).init()
self.proj = nn.Conv2d(dim, dim, kernel_size=k, padding=k // 2, groups=dim) # 深度可分离卷积
self.activation = nn.GELU() # 激活函数
def forward(self, x):
return x + self.activation(self.proj(x)) # 残差连接
代码说明:
CrossLayerPosEmbedding3D: 该类用于计算3D位置嵌入,包括相对位置和绝对位置偏置的初始化和前向传播计算。
CrossLayerSpatialAttention: 该类实现了跨层空间注意力机制,负责计算输入特征的注意力权重并生成输出。
ConvPosEnc: 该类实现了卷积位置编码,使用深度可分离卷积对输入特征进行处理,并通过激活函数进行非线性变换。
这些核心部分构成了跨层注意力机制的基础,能够有效地捕捉不同层之间的特征关系。
这个程序文件 cfpt.py 实现了一个深度学习模型中的跨层注意力机制,主要包括两个类:CrossLayerSpatialAttention 和 CrossLayerChannelAttention。这些类用于处理图像数据,利用空间和通道的注意力机制来增强特征提取的能力。
首先,文件中引入了一些必要的库,包括 torch、math、einops、torch.nn 等。einops 库用于简化张量的重排操作,timm.layers 提供了一些常用的层和功能。
接下来,定义了一个 LayerNormProxy 类,它是对 nn.LayerNorm 的封装,主要用于在特征图的最后一个维度上进行层归一化。CrossLayerPosEmbedding3D 类则用于生成跨层的位置信息嵌入,支持空间和通道的相对位置编码。
ConvPosEnc 类实现了一个卷积位置编码模块,利用卷积操作来增强输入特征。DWConv 类实现了深度可分离卷积,适用于处理高维特征。Mlp 类则是一个简单的多层感知机,用于特征的非线性变换。
接下来,定义了一些辅助函数,如 overlaped_window_partition 和 overlaped_window_reverse,这些函数用于在特征图上进行重叠窗口的划分和重构,支持在注意力机制中对局部区域的处理。
CrossLayerSpatialAttention 类实现了空间注意力机制。它的构造函数中初始化了一些参数,包括层数、头数、窗口大小等。该类的 forward 方法接受多个特征图作为输入,进行注意力计算并返回处理后的特征图。在这个过程中,使用了卷积位置编码、层归一化、注意力计算等步骤。
CrossLayerChannelAttention 类实现了通道注意力机制,结构与空间注意力类似,但在处理上更加侧重于通道维度的特征。它同样包含了位置编码、注意力计算和特征融合的步骤。
整体来看,这个文件实现了一个复杂的跨层注意力机制,结合了空间和通道的特征提取能力,适用于图像处理任务。通过对输入特征图的不同层次进行处理,模型能够更好地捕捉图像中的重要信息,提高下游任务的性能。
10.3 mamba_yolo.py
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
from einops import rearrange
class LayerNorm2d(nn.Module):
“”“自定义的二维层归一化类”“”
def __init__(self, normalized_shape, eps=1e-6, elementwise_affine=True):
super().__init__()
# 初始化LayerNorm
self.norm = nn.LayerNorm(normalized_shape, eps, elementwise_affine)
def forward(self, x):
# 将输入张量从 (B, C, H, W) 转换为 (B, H, W, C)
x = rearrange(x, 'b c h w -> b h w c').contiguous()
# 应用归一化
x = self.norm(x)
# 再次转换回 (B, C, H, W)
x = rearrange(x, 'b h w c -> b c h w').contiguous()
return x
class CrossScan(torch.autograd.Function):
“”“交叉扫描功能类”“”
@staticmethod
def forward(ctx, x: torch.Tensor):
B, C, H, W = x.shape
ctx.shape = (B, C, H, W)
# 创建一个新的张量用于存储交叉扫描结果
xs = x.new_empty((B, 4, C, H * W))
xs[:, 0] = x.flatten(2, 3) # 原始张量展平
xs[:, 1] = x.transpose(dim0=2, dim1=3).flatten(2, 3) # 转置后展平
xs[:, 2:4] = torch.flip(xs[:, 0:2], dims=[-1]) # 反转
return xs
@staticmethod
def backward(ctx, ys: torch.Tensor):
B, C, H, W = ctx.shape
L = H * W
# 反向传播时的计算
ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, -1, L)
y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, -1, L)
return y.view(B, -1, H, W)
class SelectiveScanCore(torch.autograd.Function):
“”“选择性扫描核心功能类”“”
@staticmethod
@torch.cuda.amp.custom_fwd
def forward(ctx, u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=False, nrows=1, backnrows=1):
# 确保输入张量是连续的
if u.stride(-1) != 1:
u = u.contiguous()
if delta.stride(-1) != 1:
delta = delta.contiguous()
if D is not None and D.stride(-1) != 1:
D = D.contiguous()
if B.stride(-1) != 1:
B = B.contiguous()
if C.stride(-1) != 1:
C = C.contiguous()
# 保存上下文信息
ctx.delta_softplus = delta_softplus
ctx.backnrows = backnrows
# 调用CUDA核心进行前向计算
out, x, *rest = selective_scan_cuda_core.fwd(u, delta, A, B, C, D, delta_bias, delta_softplus, 1)
ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)
return out
@staticmethod
@torch.cuda.amp.custom_bwd
def backward(ctx, dout):
u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensors
if dout.stride(-1) != 1:
dout = dout.contiguous()
# 调用CUDA核心进行反向计算
du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda_core.bwd(
u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, 1
)
return (du, ddelta, dA, dB, dC, dD, ddelta_bias, None, None, None, None)
class SS2D(nn.Module):
“”“SS2D模块,结合选择性扫描和其他操作”“”
def __init__(self, d_model=96, d_state=16, ssm_ratio=2.0, act_layer=nn.SiLU, dropout=0.0):
super().__init__()
self.in_proj = nn.Conv2d(d_model, d_model * ssm_ratio, kernel_size=1)
self.out_proj = nn.Conv2d(d_model * ssm_ratio, d_model, kernel_size=1)
self.dropout = nn.Dropout(dropout) if dropout > 0. else nn.Identity()
self.act = act_layer()
def forward(self, x: torch.Tensor):
x = self.in_proj(x) # 输入投影
x = self.act(x) # 激活
x = self.dropout(x) # Dropout
x = self.out_proj(x) # 输出投影
return x
class VSSBlock_YOLO(nn.Module):
“”“YOLO模型中的VSS块”“”
def __init__(self, in_channels: int, hidden_dim: int, drop_path: float = 0):
super().__init__()
self.proj_conv = nn.Conv2d(in_channels, hidden_dim, kernel_size=1)
self.ss2d = SS2D(d_model=hidden_dim) # 选择性扫描模块
self.drop_path = nn.Dropout(drop_path)
def forward(self, input: torch.Tensor):
input = self.proj_conv(input) # 投影
x = self.ss2d(input) # 选择性扫描
x = self.drop_path(x) # Dropout
return x
代码说明:
LayerNorm2d: 实现了二维层归一化,适用于图像数据。
CrossScan: 实现了交叉扫描的前向和反向传播逻辑,用于处理输入张量的不同排列。
SelectiveScanCore: 实现了选择性扫描的核心功能,支持前向和反向传播,使用CUDA加速。
SS2D: 结合选择性扫描的模块,进行输入的投影和输出的处理。
VSSBlock_YOLO: YOLO模型中的一个块,使用选择性扫描模块和投影层,结合Dropout操作。
以上是核心部分的代码和详细注释,帮助理解其功能和实现逻辑。
这个程序文件 mamba_yolo.py 实现了一种基于深度学习的神经网络模块,主要用于计算机视觉任务,特别是目标检测。代码中使用了 PyTorch 框架,并引入了一些自定义的模块和函数来实现复杂的网络结构。
首先,文件导入了一些必要的库,包括 PyTorch 和其他一些用于深度学习的工具,如 einops 和 timm。这些库提供了张量操作、网络层和其他深度学习功能。
接下来,定义了一个 LayerNorm2d 类,该类实现了二维层归一化,适用于图像数据。它通过重排张量的维度来应用 LayerNorm,使得归一化操作能够在通道维度上进行。
然后,文件中定义了一些辅助函数和类,例如 autopad 函数用于自动计算卷积操作的填充,确保输出尺寸与输入相同。CrossScan 和 CrossMerge 类则实现了交叉扫描和合并操作,这在处理图像特征时非常有用。
SelectiveScanCore 类实现了选择性扫描的前向和反向传播,允许在计算过程中进行高效的特征选择。cross_selective_scan 函数则是对选择性扫描的封装,整合了多个输入参数,并进行相应的处理。
接下来的 SS2D 类是一个重要的模块,负责处理输入特征并进行变换。它包含多个参数,如模型维度、状态维度、卷积层的设置等。这个模块通过多个线性层和卷积层进行特征提取和变换,使用了自定义的前向传播逻辑。
此外,RGBlock 和 LSBlock 类实现了特征提取的不同模块,分别使用卷积和激活函数来处理输入特征。XSSBlock 和 VSSBlock_YOLO 类则结合了之前定义的模块,构建了更复杂的网络结构,适用于特定的任务。
SimpleStem 类用于构建网络的初始部分,通过卷积层和激活函数将输入特征进行处理。VisionClueMerge 类则实现了特征的合并操作,整合来自不同层的特征以增强模型的表达能力。
总体而言,这个文件实现了一个复杂的神经网络架构,结合了多种深度学习技术和自定义模块,旨在提高计算机视觉任务中的性能。通过这些模块的组合,模型能够有效地提取和处理图像特征,适应不同的视觉任务需求。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 18
18 0
0- 0



 已为社区贡献145条内容
已为社区贡献145条内容

所有评论(0)