我的数据可视化学习心得:拆解 B 站尚硅谷数据分析教程:3 步解决numpy/pandas/matplotlib 卡点
跟着尚硅谷《Python 数据分析与可视化》教程学 numpy、pandas、matplotlib 时,我踩过的坑能凑成一本 “错题集”:numpy 的reshape和resize总搞混,明明跟着视频敲代码,数组维度还是错;pandas 处理 Excel 数据时,遇到缺失值不知道该用dropna()还是fillna(),反复拖进度条找讲解,20 分钟才定位到片段;matplotlib 画热力图时,调颜色映射和坐标轴标签花了 1 小时,最后图表还是歪的 —— 直到用 Vgen 解析视频,才把 “边看边忘、实操卡壳、学完没底” 的问题全解决,还摸透了数据分析学习的 “实战心法”。
第一步:视频解析 ——15 分钟理清数据工具核心逻辑,我的 “概念混淆” 破局点
数据分析三工具的知识点又多又杂:numpy 的数组操作有 20 + 种,pandas 的 DataFrame 方法能列满一屏,matplotlib 的图表参数更是五花八门。之前我靠 “抄笔记” 学,结果笔记记了 30 页,遇到实际数据还是不会处理。用 视频解析工具解析视频后,才发现 “结构化梳理” 比 “死记硬背” 管用 10 倍。
1. 智能切割 “工具模块”,精准定位高频卡点
自动识别数据分析教学场景,把 3 小时的长视频拆成 9 个核心模块,每个模块都戳中我之前的痛点,还标注了对应时间戳,直接跳过 15 分钟的环境介绍和重复讲解:
- numpy 基础(00:10-00:35):数组创建(
np.array/np.zeros)、维度理解(1D/2D/3D)(解决 “维度搞混” 卡点) - numpy 核心运算(00:36-01:00):
reshapevsresize、数组广播(解决 “运算维度不匹配” 卡点) - pandas 数据读取(01:01-01:20):
read_excel/read_csv参数设置(解决 “中文乱码、表头错位” 卡点) - pandas 数据清洗(01:21-01:50):缺失值(
dropna/fillna)、重复值(drop_duplicates)处理(解决 “清洗逻辑乱” 卡点) - pandas 数据聚合(01:51-02:15):
groupby+agg统计、merge表连接(解决 “分组统计漏参数” 卡点) - matplotlib 基础(02:16-02:35):画布(
figure)、子图(subplot)创建(解决 “多图布局乱” 卡点) - 折线图 / 柱状图实战(02:36-02:50):
plot/bar参数(颜色、标签、图例)(解决 “图表样式调不对” 卡点) - 热力图 / 散点图实战(02:51-03:05):
heatmap数据格式、scatter相关性展示(解决 “复杂图表不会画” 卡点) - 综合案例:电商销售数据可视化(03:06-03:20)(解决 “工具串联不会用” 卡点)
比如我之前总分不清 numpy 的reshape和resize,点击 “numpy 核心运算” 模块,视频秒跳至 00:45 的讲解 —— 原来reshape不改变原数组,resize会直接修改原数组,还能自动填充值。这个点我之前看了 2 遍视频都没记住,靠 Vgen 的模块切割 1 分钟就懂了。
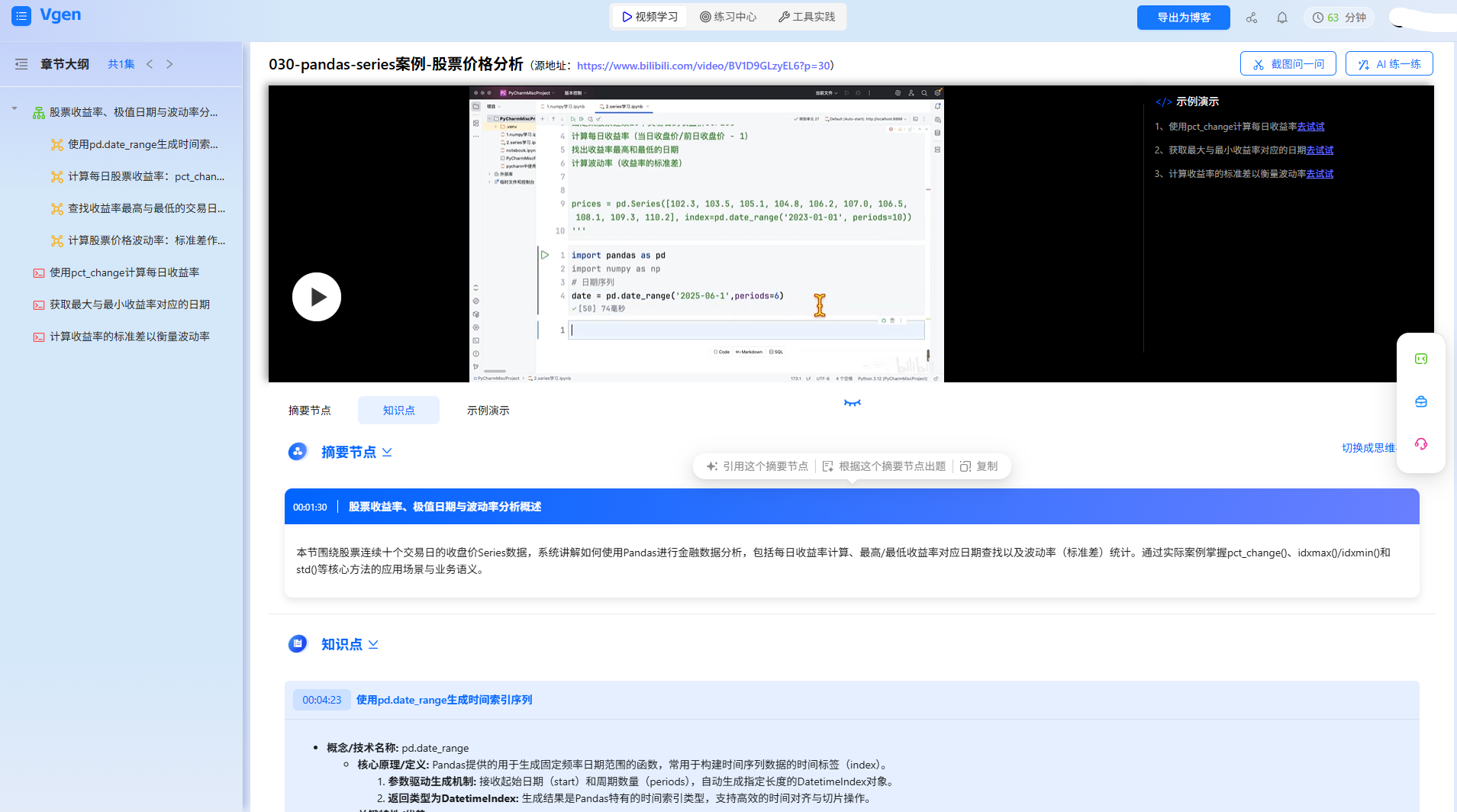
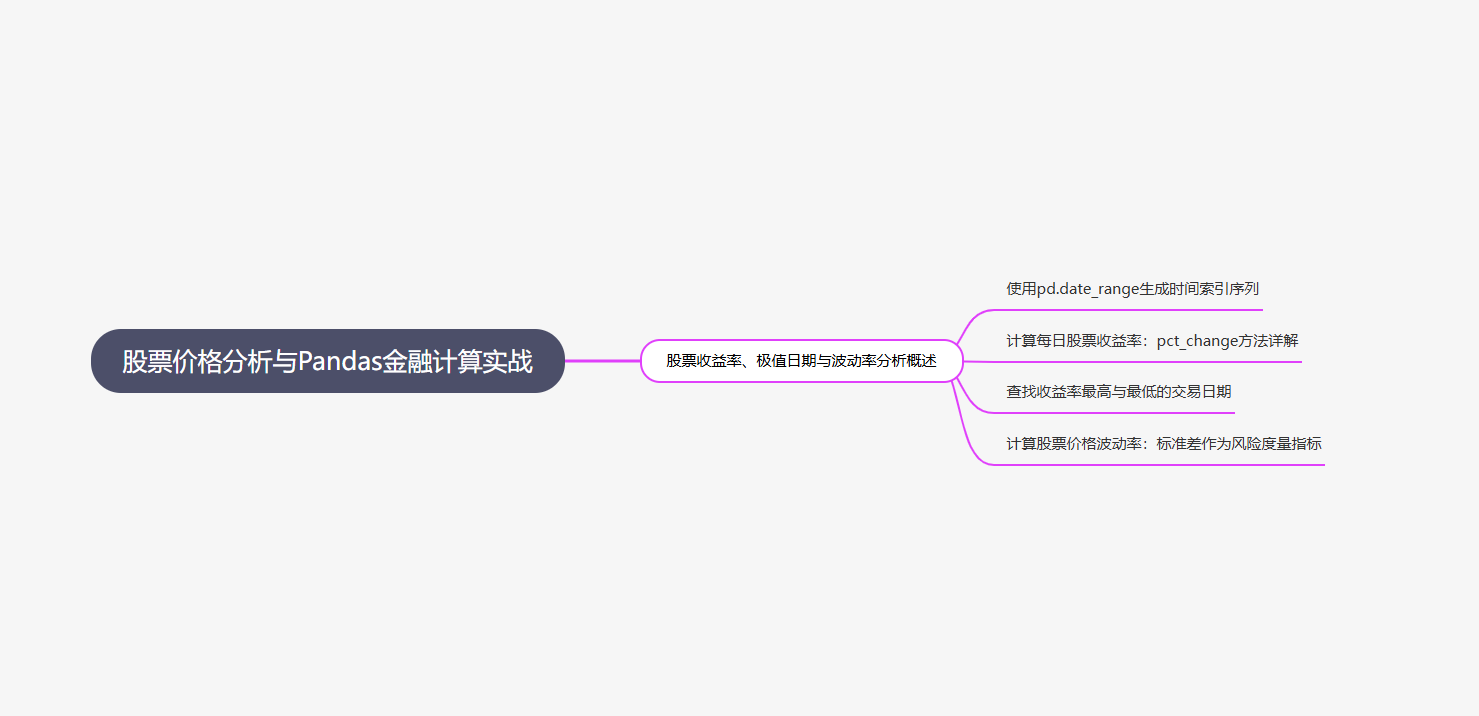
2. 生成 “工具逻辑导图”,破解 “方法记混” 难题
每个工具的核心逻辑做成 “图文 + 代码” 的思维导图,比如 pandas 数据清洗的导图里,用流程图标注:
- 读取数据(
pd.read_excel)→ 查看数据概况(df.info()/df.describe()) - 处理缺失值:连续型数据用
fillna(df.mean())填充,离散型数据用fillna(df.mode()[0])填充,完全空白行用dropna(axis=0)删除 - 处理重复值:
df.drop_duplicates(subset=['订单号'], keep='first')(按订单号去重,保留第一条) - 格式统一:
df['日期'] = pd.to_datetime(df['日期'])(转换日期格式)
导图还关联了视频里的演示代码,比如处理缺失值的代码片段:
python
import pandas as pd
df = pd.read_excel('销售数据.xlsx')
# 查看缺失值
print(df.isnull().sum())
# 填充连续型字段(销量)的缺失值
df['销量'] = df['销量'].fillna(df['销量'].mean())
# 删除完全空白的行
df = df.dropna(axis=0, how='all')我之前学数据清洗时,总不知道 “先看什么、再做什么”,对着导图看代码,才总结出规律:数据分析第一步永远是 “用 info ()/isnull () 摸清数据情况”,再针对性处理,别上来就删数据。这种 “流程化理解” 比记零散方法牢固太多。
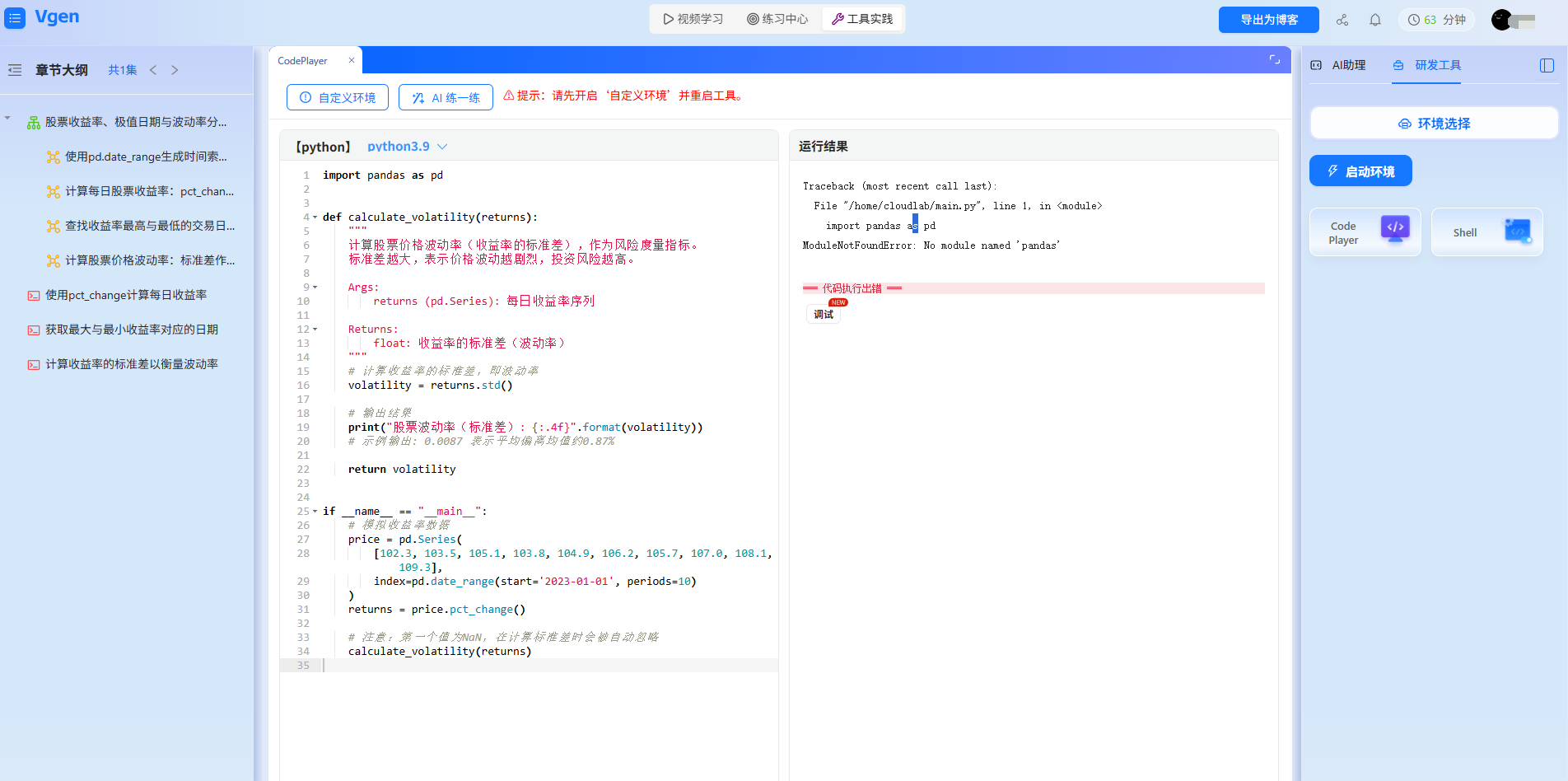
第二步:在线实操 —— 零配置练数据可视化,我的 “看会敲错” 解决方案
数据分析的核心是 “动手练”,但本地学习总有一堆麻烦:numpy、pandas 版本冲突导致代码报错,matplotlib 中文字体显示乱码,找不到视频里的测试数据……在线实操环境直接把这些问题全解决了,让我能专注在 “代码逻辑” 上。
1. 预配环境 + 测试数据,不用再为 “搭环境浪费时间”
根据视频内容,自动匹配 Python 3.9+numpy 1.23+pandas 1.5+matplotlib 3.6 的兼容环境,还预存了视频里的所有测试数据(如 “销售数据.xlsx”“学生成绩.csv”)。比如学 pandas 读取 Excel 时,在线编辑器里直接有代码:
import pandas as pd
# 读取Excel,解决中文乱码和表头问题
df = pd.read_excel('销售数据.xlsx', encoding='utf-8', header=0)
# 查看前5行数据
print(df.head())不用本地装 Anaconda、不用手动下载数据,点击 “运行” 就能看到输出。之前我在本地学的时候,光解决read_excel的中文乱码就花了 20 分钟(后来才知道要加encoding='utf-8-sig'),现在完全不用管环境,精力全放在 “怎么调整参数让数据读得更准” 上。
2. 实时调试 + 效果预览,解决 “图表调不对” 痛点
matplotlib 的图表参数是最让我头疼的 —— 比如画柱状图时,想把 x 轴标签旋转 45 度,却不知道该加哪个参数;调颜色时,写color='red'太单调,想用地道的颜色映射又记不住参数。在线环境支持 “边改代码边看效果”,还能断点调试。
比如跟着视频学画 “电商月度销量柱状图”,初始代码是:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_excel('销售数据.xlsx')
monthly_sales = df.groupby('月份')['销量'].sum()
# 画柱状图
plt.figure(figsize=(10, 6))
plt.bar(monthly_sales.index, monthly_sales.values)
plt.title('月度销量统计')
plt.xlabel('月份')
plt.ylabel('销量')
plt.show()运行后发现 x 轴标签挤在一起,我直接在代码里加plt.xticks(rotation=45),点击 “运行” 秒看到效果;想让颜色更有层次感,把plt.bar改成plt.bar(monthly_sales.index, monthly_sales.values, cmap='viridis'),立刻看到柱状图变成渐变色。
这种 “实时预览” 比视频里 “一次性演示” 高效太多 —— 之前我看视频学热力图时,老师直接给出cmap='YlOrRd',但我想换其他颜色却不知道有哪些选项,试了cmap='Blues'“cmap='Reds'`,对比效果后才记住 “暖色调适合突出高值,冷色调适合展示趋势”。
3. 综合案例实操 + 我的心得:工具串联才是核心
学完单个工具后,最难得是 “怎么把 numpy 的运算、pandas 的数据处理、matplotlib 的可视化串起来”。在线环境里有视频里的 “电商销售数据综合案例”,我跟着练了一遍,才摸清流程:
- 用 pandas 读取销售数据,清洗缺失值和重复值(
dropna/drop_duplicates) - 用 numpy 计算 “客单价”(
np.divide(df['销售额'], df['销量'])),新增到 DataFrame - 用 pandas 按 “地区 + 月份” 分组,计算销量总和(
groupby(['地区','月份'])['销量'].sum().unstack()) - 用 matplotlib 画热力图(
sns.heatmap,seaborn 是 Vgen 预配的),展示各地区月度销量分布
练完这个案例我才明白:数据分析不是 “单独用某个工具”,而是 “用 pandas 处理数据、用 numpy 做计算、用 matplotlib 展示结果” 的闭环。之前我总孤立地学每个工具,结果做项目时不知道从哪下手,靠这个案例才打通了 “数据→计算→可视化” 的逻辑。
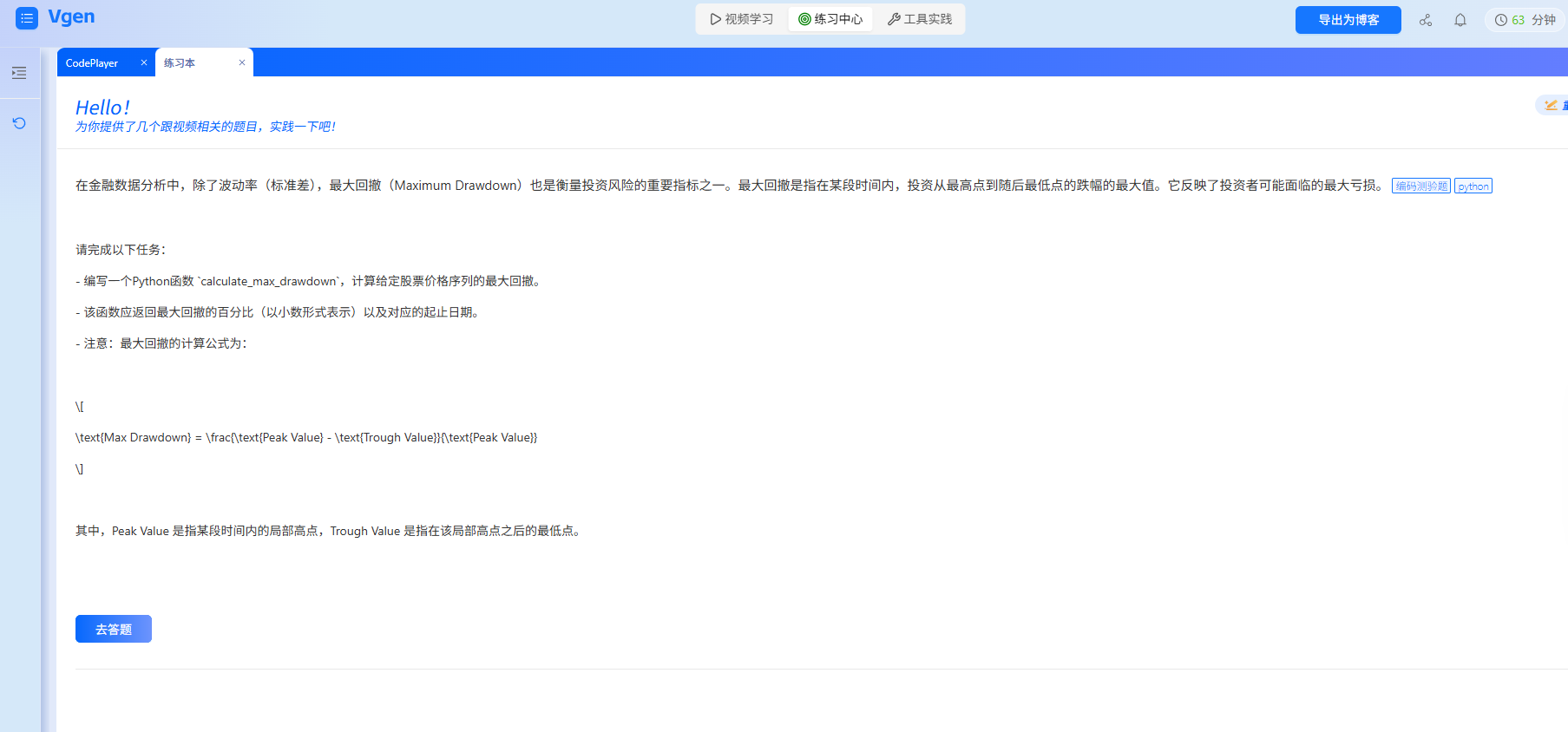
第三步:AI 自测 —— 精准补漏,我的 “学完没底” 解决办法
数据分析学习最怕 “以为会了,一处理实际数据就错”:比如学完 pandas 的groupby,自己做时总漏agg参数,导致统计结果不对;学完 matplotlib 的热力图,不知道 “数据必须是二维的”,用一维数组去画结果报错。AI 自测能精准找出这些 “隐性漏洞”。
1. 实战型考题 + 我的错题:贴合实际数据分析场景
生成的自测题不是 “死记概念”,贴合实际工作场景,比如:
- numpy 题:“用 numpy 计算数组
np.array([[1,2],[3,4]])的每行均值和每列方差,写出代码”(我之前漏了axis参数,写成np.mean(arr),系统提示 “需加axis=1计算行均值,axis=0计算列方差”) - pandas 题:“现有‘学生成绩.csv’,包含‘姓名、科目、成绩’,请用 pandas 计算每个科目的平均分和最高分(需用
groupby+agg)”(我之前写成df.groupby('科目')['成绩'].mean(),只算平均分,漏了agg({'成绩': ['mean', 'max']}),系统标红并关联视频 “pandas 数据聚合” 片段) - matplotlib 题:“用 matplotlib 画‘地区销量散点图’,x 轴为‘地区’,y 轴为‘销量’,要求添加趋势线并标注异常值(销量> 10000 的为异常)”(我之前不知道怎么加趋势线,系统提示用
np.polyfit拟合直线,再用plt.plot画趋势线)
这些错题被自动存入 “数据分析专题错题本”,每个错题都标了 “错误原因” 和 “对应工具知识点”,比如 “groupby漏agg参数→pandas 聚合统计逻辑”。现在我复习时,不用翻 3 小时的视频,15 分钟就能回顾所有易错点。
2. 我的复习心得:“错题 + 代码片段” 才是最好的笔记
之前我学数据分析总爱抄 “完美笔记”,把每个方法的参数都记下来,但遇到实际数据还是不会用。错题本和 “代码片段库”(解析视频时自动保存的核心代码),才发现:数据分析的笔记不用全,要 “精”—— 把错题对应的代码、实战案例的流程记下来,比抄参数表管用。比如我把 “热力图数据格式错误” 的错题代码存在片段库,下次画热力图时,直接复制过来改数据,不用再翻视频找 “二维数据怎么准备”。
结语:数据分析学习的 3 个核心心得 + Vgen 的价值
回顾我学 numpy、pandas、matplotlib 的过程,总结出 3 个关键心得,适合所有数据分析初学者:
- 别孤立学工具,要 “流程化理解”:比如用导图理清 “数据读取→清洗→计算→可视化” 的流程,比单独记
read_excel或plt.bar的参数更重要; - 一定要用真实数据练:利用测试数据(Excel/CSV)和在线环境,能让你摆脱 “环境困扰”,专注在 “怎么用工具解决数据问题” 上;
- 错题要 “关联场景”:比如 “
groupby漏agg” 不是 “记不住参数”,而是 “没理解聚合统计的逻辑”,把错题和实际场景绑定,下次才不会再错。
把视频里的零散知识点变成 “结构化流程”,把 “麻烦的环境配置” 变成 “开箱即用的实操场”,把 “学完没底” 变成 “精准自测补漏”。现在我做数据分析项目时,不用再翻视频找代码,直接用视频解析工具来解析视频的 “代码片段库” 和 “错题本”,效率比之前高了 3 倍。
相信你也能像我一样,从 “会用工具” 变成 “能解决实际数据问题”,真正入门 Python 数据分析。
- 我用的免费视频解析工具:https://t.cloudlab.top/2IvdLC
- 我学习的B站视频:https://www.bilibili.com/video/BV1D9GLzyEL6/?p=30

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)