YOLOv8改进 - 注意力机制 | SimAM:轻量级注意力机制,解锁卷积神经网络新潜力
本文介绍了将SimAM注意力模块与YOLOv8结合的方法。SimAM是一种简单且无参数的注意力模块,其设计灵感源自神经科学理论,通过优化能量函数找出每个神经元的重要性,进而为特征图推断3D注意力权重。该模块无需添加额外参数,且多数操作符基于能量函数的解选择,避免了大量结构调整工作。我们将SimAM集成进YOLOv8,替换部分模块。实验证明,结合SimAM的YOLOv8在相关视觉任务中展现出良好的效
前言
本文介绍了将SimAM注意力模块与YOLOv8结合的方法。SimAM是一种简单且无参数的注意力模块,其设计灵感源自神经科学理论,通过优化能量函数找出每个神经元的重要性,进而为特征图推断3D注意力权重。该模块无需添加额外参数,且多数操作符基于能量函数的解选择,避免了大量结构调整工作。我们将SimAM集成进YOLOv8,替换部分模块。实验证明,结合SimAM的YOLOv8在相关视觉任务中展现出良好的效果,为卷积神经网络性能提升提供了有效方案。
文章目录: YOLOv8改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv8改进专栏
介绍

摘要
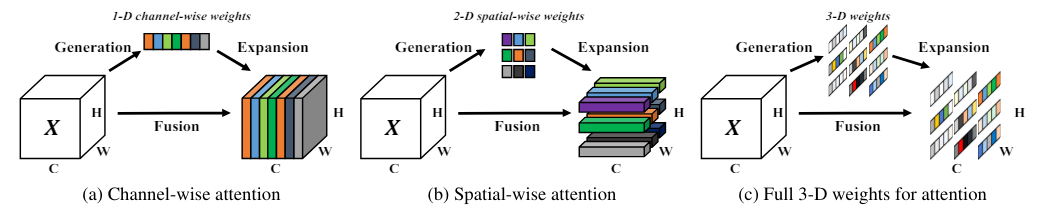
在本文中,我们提出了一种概念上简单但非常有效的卷积神经网络(ConvNets)注意力模块。与现有的通道注意力和空间注意力模块不同,我们的模块为特征图推断3D注意力权重,而无需向原始网络添加参数。具体来说,我们基于一些知名的神经科学理论,提出通过优化能量函数来找出每个神经元的重要性。我们进一步推导出一个快速的闭式解,并展示该解可以在不到十行代码中实现。该模块的另一个优点是大多数操作符是基于能量函数的解选择的,避免了大量结构调整的工作。对各种视觉任务的定量评估表明,所提出的模块灵活且有效,可以提高许多卷积神经网络的表示能力。我们的代码可在 Pytorch-SimAM 获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
SimAM(Simple Attention Module)是一种简单且无参数的注意力模块,用于卷积神经网络(Convolutional Neural Networks,ConvNets)。SimAM的设计灵感源自哺乳动物大脑中的神经科学理论,特别是基于已建立的空间抑制理论设计了一个能量函数来实现这一理论。SimAM通过推导出一个简单的解决方案来实现这个函数,进而将该函数作为特征图中每个神经元的注意力重要性。该注意力模块的实现受到这个能量函数的指导,避免了过多的启发式方法。SimAM通过推断特征图的3D注意力权重,优化能量函数以找到每个神经元的重要性,从而在各种视觉任务上提高性能。
- 基于空间抑制理论设计能量函数:SimAM利用空间抑制理论设计了一个能量函数,用于计算每个神经元的注意力重要性。
- 推导简单解决方案:为了实现这个能量函数,SimAM推导出了一个简单的解决方案,使得实现过程更加高效。
- 实现注意力权重:通过计算得到的注意力重要性,SimAM可以为每个神经元分配相应的注意力权重,从而提高特征图的表征能力。
SimAM 的计算公式如下:
$$
w_i = \frac{1}{k} \sum_{j \in N_i} s(f_i, f_j)
$$
公式说明:
- w_i 是第 i 个像素的注意力权重
- k 是归一化常数
- N_i 是第 i 个像素的相邻像素集合
- s(f_i, f_j) 是第 i 个像素和第 j 个像素之间的相似性
核心代码
import torch
import torch.nn as nn
class SimAM(torch.nn.Module):
def __init__(self, channels=None, e_lambda=1e-4):
super(SimAM, self).__init__()
# 初始化Sigmoid激活函数和e_lambda参数
self.activation = nn.Sigmoid() # Sigmoid激活函数用于映射输出到(0, 1)之间
self.e_lambda = e_lambda # 控制分母的平滑参数
def __repr__(self):
# 返回模型的字符串表示,包括e_lambda参数的值
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
# 静态方法,返回模型的名称
return "simam"
def forward(self, x):
# 前向传播函数,接收输入张量x,返回处理后的张量
b, c, h, w = x.size() # 获取输入张量的batch大小、通道数、高度和宽度
n = w * h - 1 # 计算像素数量减一,用于标准化
# 计算每个像素与平均值的差的平方
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
# 计算SimAM激活函数的输出
# 分子部分:每个像素的平方差除以分母的加权平均
# 加上0.5是为了映射输出到(0.5, 1)之间
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5
# 返回经过SimAM激活函数处理后的特征图
return x * self.activation(y)
引入代码
在根目录下的ultralytics/nn/目录,新建一个 attention目录,然后新建一个以 SimAM为文件名的py文件, 把代码拷贝进去。
import torch
import torch.nn as nn
def autopad(k, p=None, d=1): # kernel, padding, dilation
# Pad to 'same' shape outputs
if d > 1:
k = (
d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]
) # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(
c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False
)
self.bn = nn.BatchNorm2d(c2)
self.act = (
self.default_act
if act is True
else act if isinstance(act, nn.Module) else nn.Identity()
)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class SimAM(torch.nn.Module):
def __init__(self, e_lambda=1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
y = (
x_minus_mu_square
/ (
4
* (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)
)
+ 0.5
)
return x * self.activaton(y)
class SimAM_Bottleneck(nn.Module):
def __init__(
self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5
): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.simam = SimAM(e_lambda=1e-4)
self.add = shortcut and c1 == c2
def forward(self, x):
return (
x + self.simam(self.cv2(self.cv1(x)))
if self.add
else self.simam(self.cv2(self.cv1(x)))
)
class C2f_SimAM(nn.Module):
def __init__(
self, c1, c2, n=1, shortcut=False, g=1, e=0.5
): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(
SimAM_Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0)
for _ in range(n)
)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.attention.SimAM import SimAM, C2f_SimAM
步骤2
修改def parse_model(d, ch, verbose=True):
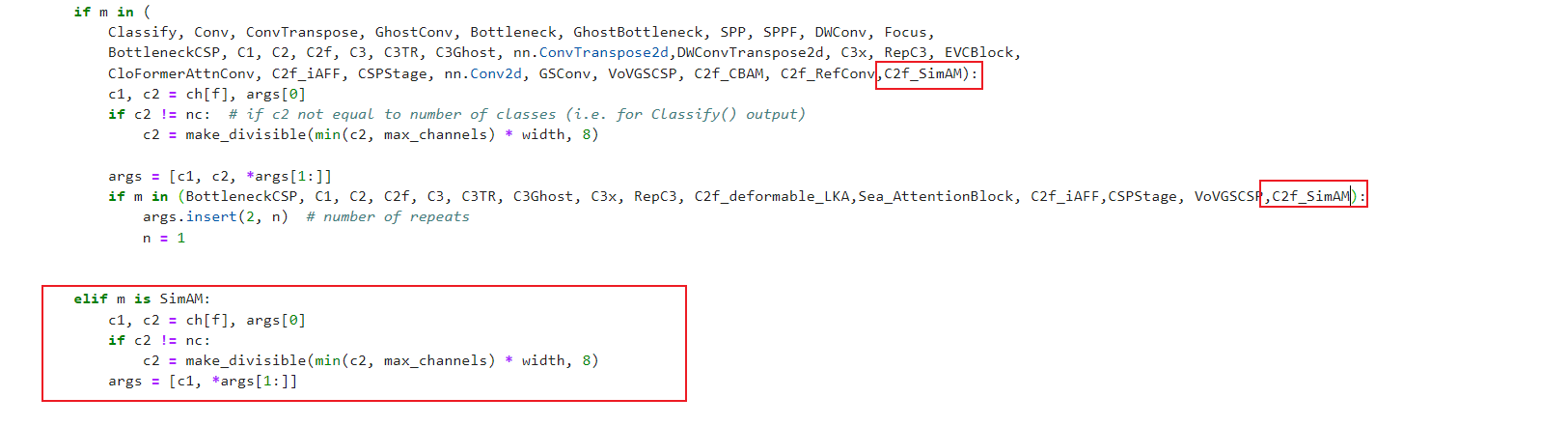
if m in (
Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d,DWConvTranspose2d, C3x, RepC3, EVCBlock,
CloFormerAttnConv, C2f_iAFF, CSPStage, nn.Conv2d, GSConv, VoVGSCSP, C2f_CBAM, C2f_RefConv,C2f_SimAM):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, C3x, RepC3, C2f_deformable_LKA,Sea_AttentionBlock, C2f_iAFF,CSPStage, VoVGSCSP,C2f_SimAM):
args.insert(2, n) # number of repeats
n = 1
elif m is SimAM:
c1, c2 = ch[f], args[0]
if c2 != nc:
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, *args[1:]]
配置yolov8_SimAM.yaml
ultralytics/cfg/models/v8/yolov8_SimAM.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 4 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
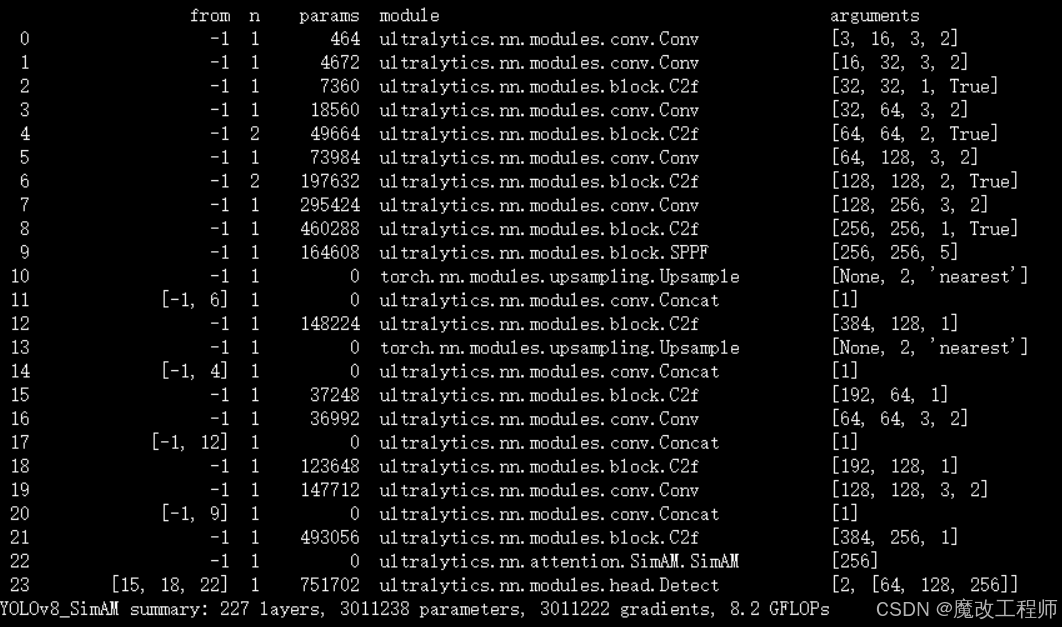
- [-1, 3, SimAM, [1024]]
- [[15, 18, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 4 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
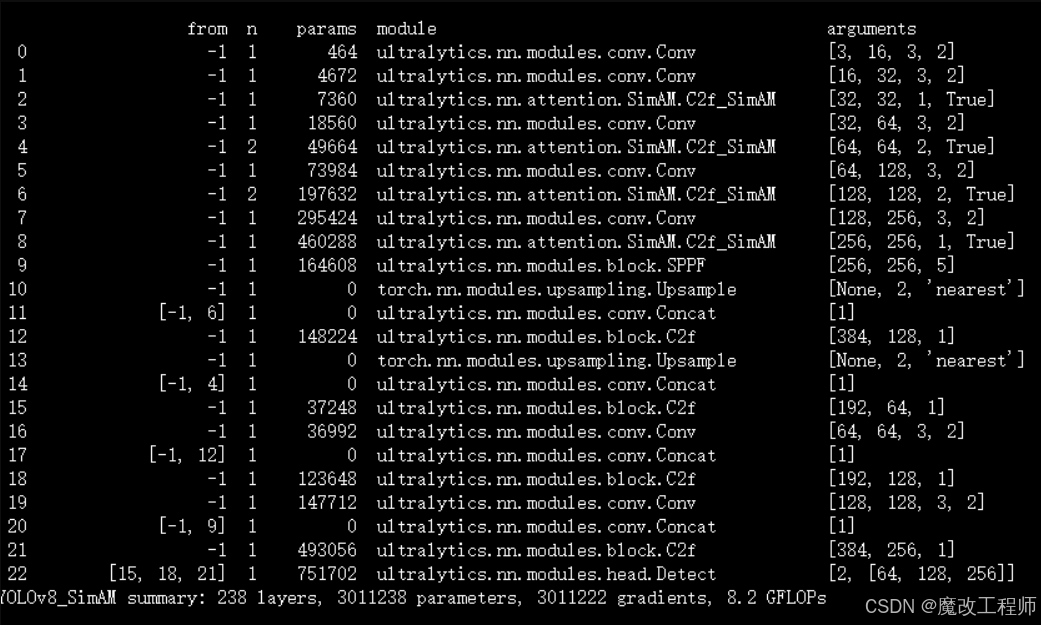
- [-1, 3, C2f_SimAM, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f_SimAM, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f_SimAM, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f_SimAM, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
实验
脚本
import os
from ultralytics import YOLO
# Define the configuration options directly
yaml = 'ultralytics/cfg/models/v8/yolov8_SimAM.yaml'
# Initialize the YOLO model with the specified YAML file
model = YOLO(yaml)
# Print model information
model.info()
if __name__ == "__main__":
# Train the model with the specified parameters
results = model.train(data='ultralytics/datasets/original-license-plates.yaml',
name='yolov8_SimAM',
epochs=10,
workers=8,
batch=1)
结果

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)