python b站黑马程序员学习笔记
基于b站黑马程序员python课程的学习笔记
第二章
字面量
在代码中,被写下来的固定的值,称为字面量
常用的6种值(数据)的类型
| 类型 | 描述 |
|---|---|
| 数字 | int、float、complex、bool |
| 字符串 | 描述文本 |
| 列表 | 有序的可变序列 |
| 元组 | 有序的不可变序列 |
| 集合 | 无序不重复集合 |
| 字典 | 无序key-value集合 |
注释
在程序中进行解释说明的文字
(# 和注释内容一般建议以一个空格隔开)
变量
变量名称 = 变量的值
数据类型
: 使用type(被查看的数据)
name = "nihao"
name_type = type(name)
print(name_type)
(通过type查看的是数据的类型,不是变量的类型)
数据类型转换
| 语句(函数) | 说明 |
|---|---|
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
| str(x) | 将x转换为一个字符串 |
(字符串必须全部是数字才能转换为int,float)
(float转换为int会丢失精度)
标识符
(不能数字开头,不推荐中文,区分大小写)
运算符
| 运算符 | 描述 |
|---|---|
| / | 除 |
| // | 取整数 |
| % | 取余 |
| ** | 指数 |
字符串拓展
三种定义
- 单引号
- 双引号
- 三引号(支持换行操作)
字符串拼接
+号拼接(字符串和字符串)
字符串格式化
用%s %,其中%s表示占位,s表示字符串
%d,%f整数,浮点数占位
name = "柘锐"
message = "我是: %s" % name
print(message)
快速写法:
f"内容{变量}"
格式化的精度控制
我们可以使用.n来控制精度(四舍五入)
例:
%.3f表示小数点的精度为3,11.23452结果为11.235
输入(input)
无论输入什么,永远都是字符串类型
第三章
比较运算符(返回true,false)
| 运算符 | 描述 |
|---|---|
| == | 判断是否相等 |
| != | 判断是否不等于 |
| > | 判断是否大于 |
| < | 判断是否小于 |
if
格式:
if 判断的条件:
条件成立时,要做的事
if else
if 条件1:
满足条件1对应的事
elif 条件2:
满足条件2对应的事
elif 条件n:
满足条件n对应的事
else:
所有条件都不满足对应的事
x = 13
if int(input("请输入第一个数字:")) == x:
print("猜对啦")
elif int(input("不对,再猜一次:")) == x:
print("恭喜你猜对啦")
elif int(input("最后再猜一次:")) == x:
print("恭喜你猜对啦")
else:
print("你全部猜错了")
嵌套使用
if 条件1:
满足条件1做的事1
满足条件1做的事2
if 条件2:# 注意空格缩进
满足条件2做的事1
满足条件2做的事2
例:
# 随机产生一个数字,范围1-10
# 有三次机会
# 每次猜不中,会提示大了还是小了
import random
num = random.randint(1,10)
a = int(input("请猜一次:"))
if a == num:
print("恭喜你,第一次就猜对了")
else:
if a > num:
print("大了")
else:
print("小了")
a = int(input("再次猜一次:"))
if a == num:
print("恭喜你,第二次猜对了")
else:
if a > num:
print("大了")
else:
print("小了")
a = int(input("最后猜一次:"))
if a == num:
print("恭喜你,第三次猜对了")
else:
print("很抱歉你没有猜对")
第四章
while循环
基础语法
while 条件:
条件满足时,做的事1
条件满足时,做的事2
条件满足时,做的事3
例:
i = 1
sum = 0
while i <= 100:
sum = sum + i
i +=1
print(sum)
题目:判断输入的数字是否等于随机数
import random
num = random.randint(1,100)
i = 0
while True :
a = int(input("请输入数字:"))
if a > num:
print("大了")
elif a < num :
print("小了")
else:
print("恭喜你猜对啦")
break
i +=1
print(f"你已经猜了{i}次,请再猜一次")
while循环嵌套
while 条件1:
条件1满足时,做的事1
条件1满足时,做的事2
条件1满足时,做的事3
while 条件2:
条件2满足时,做的事1
条件2满足时,做的事2
条件2满足时,做的事3
例:99乘法表
i = 1
while i <= 9:
j = 1
while j <= i:
print(f"{j}*{i}={j*i}\t",end = '')
j +=1
# end = ''是内循环不换行的意思
i +=1
print() # print()是外循环换行的意思
for循环
for循环就是将“待办事项”逐个完成的循环机制
基础语法
for 临时变量 in 待处理数据集:
循环满足条件时执行的代码
例:统计a的个数
name = 'itheima is a brand of itcast'
count = 0
for x in name:
if x == 'a':
count +=1
print(f"a一共有{count}个")
range语句
语法1:
range(num)
获取从0开始,到num结束的数字序列(不含num本身)
语法2:range(num1,num2)
获取从num1开始,到num2结束的数字序列(不含num2本身)
语法3:range(num1,num2,step)
获取从num1开始,到num2结束的数字序列(不含num2本身),数字之间的步长以step为准,step默认为1
如,range(5,10,2)获取的数据是:[5,7,9]
变量作用域
临时变量,在编程规范上,作用范围(作用域),只限定在for循环内部
如果想在循环外部使用临时变量,需要把临时变量提前定义
for循环嵌套
for 临时变量 in 待处理数据集:
循环满足条件应作的事1
循环满足条件应作的事2
for 临时变量 in 待处理数据集:
循环满足条件应作的事1
循环满足条件应作的事2
例:99乘法表
for i in range(1,10):
for j in range(1,i+1):
print(f"{j}*{i}={j*i}\t",end='')
print()
break和continue
continue(只作用于所在循环)
中断本次循环,直接进入下一次循环
break(只作用于所在循环)
直接结束循环
案例:
import random
salary = 10000
for i in range(1,21):
score = random.randint(1, 10)
if score < 5:
print(f"员工{i}绩效不达标,不发放工资")
if salary >= 1000:
salary -= 1000
print(f"员工{i}绩效达标,发放工资")
else:
print("余额不足,下个月再来")
break
第五章-函数
定义:
def 函数名(传入参数):
函数体
return 返回值
调用:函数名(参数)
函数的传入参数
功能:在函数进行计算的时候,接受外部(调用时)提供的数据
def add(x,y):
result = x + y
print(f"{x}+{y}的结果是:{result}")
add(5,6)
函数的返回值
所谓“返回值”,就是程序中函数完成事情后,最后给调用者的结果
语法:
def 函数名(参数)
函数体
return 返回值
变量 = 函数名(参数)
例如:
def add(a,b):
result = a + b
return result
x = add(2,4)
print(x)
None类型
- 用在函数无返回值上
- 用在if判断语句上:1.在if判断中,None等同于False 2.一般用于在函数中主动返回None,分配和if判断做相关处理
def check(age):
if age > 18:
return "success"
else:
return None
result = check(16)
if not result:
print("未成年,不可以进入")
- 用在声明无内容的变量上
函数的嵌套
是指一个函数里面又调用了另外一个函数
变量的作用域
局部变量:
定义在函数内部的变量,只在函数体内生效
全局变量:
在函数体内,体外都生效的变量
global关键字
使用global关键字,可以在函数内部声明变量为全局变量
第六章-数据容器
列表(list)
定义:
变量名称 = [ ]
取列表中的元素:list[索引]
(从前往后从0开始,从后向前从-1开始)
额外补充:
在python中,如果将函数定义为class(类)的成员,那么函数会被称为:方法
方法和函数功能一样,有传入参数,有返回值,只是方法的使用格式不同
函数的使用:num = add(1,2)
方法的使用:student = student()
num = student.add(1,2)
查找某元素的下标:.index(元素)
mylist = [1,"asd","dae"]
mylist.index("asd")
修改特定位置(索引)的元素值:
mylist = [1,"asd","dae"]
mylist[2] = "adfa"
插入元素:.insert(索引,元素)
mylist = [1,"asd","dae"]
mylist.insert(1,"adsfa")
追加元素方式1:.append(元素)
mylist = [1,"asd","dae"]
mylist.append("wef")
追加元素方式2:.extend
mylist = [1,"asd","dae"]
mylist.extend([1,2,4])
删除元素:del(索引)
mylist = [1,"asd","dae"]
del mylist[0]
删除某元素在列表中的第一个匹配项:.remove(元素)
mylist = [1,"asd","dae"]
mylist.remove("asd)
清空列表:.clear()
mylist = [1,"asd","dae"]
mylist.clear()
统计某元素在列表内的数量:.count(元素)
mylist = [1,"asd","dae"]
mylist.count("asd")
统计列表内的元素:len(列表)
mylist = [1,"asd","dae"]
len(mylist)
元组(tuple)
定义:变量名称 = ( )
index,count,len同list
(如果元组里面有列表,列表可以修改)
字符串(str)
查找特定字符串的下标索引值:.index(字符串)
mystr = "itcast and itheima"
mystr.index("and")
字符串替换:.replace(字符串1,字符串2)
(将字符串1替换为字符串2;不是修改字符串本身,而是得到一个新的字符串)
mystr = "afdag ae aew efdg"
a = mystr.replace("af","程序")
print(a)
字符串分割:.split
(字符串本身不变,得到一个列表对象)
mystr = "afdag ae aew efdg"
mylist = mystr.split(" ")
print(mylist)
index,count,len同list
序列的切片
语法:序列[起始下标:结束下标:步长]
(不是修改序列本身,而是得到一个新的序列)
例:输出“黑马程序员”
my_str = "万过薪月 员序程马黑来, nohtyp学"
a = my_str[-11:-16:-1]
print(a)
集合(set)
不支持重复的元素、无序
定义:变量名称 = { }
取两个集合的差集:集合1.difference(集合2)
(集合1有而集合2没有的,得到一个新集合 )
set1 ={1,2,3}
set2 = {2,3,4}
set3 = set1.difference(set2)
print(set3)
| 操作 | 说明 |
|---|---|
| 集合.add(元素) | 集合内添加一个元素 |
| 集合.remove(元素) | 移除集合内的指定元素 |
| 集合.pop(元素) | 从集合随机取出一个元素 |
| 集合.clear() | 将集合清空 |
| 集合1.difference(集合2) | 得到一个新集合 |
| 集合1.union(集合2) | 得到1个新集合,内含两个集合的全部元素 |
字典(dict)
可变,无序,可嵌套
定义:
变量名称 = {key:value,key:value,key:value}
字典的key和value可以是任意数据类型(key不可以是字典)
| 操作 | 说明 |
|---|---|
| 字典[key] | 获取指定key对应的value值 |
| 字典[key]=value | 添加或更新键值对 |
| 字典.pop(key) | 取出key对应的value并在字典内删除此key的键值对 |
| 字典.clear() | 清空字典 |
| 字典.keys() | 获取字典的全部key,可用于for循环遍历字典 |
| len(字典) | 计算字典内的元素数量 |
数据容器特点对比
| 列表 | 元组 | 字符串 | 集合 | 字典 | |
|---|---|---|---|---|---|
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | key:value(key除自字典外任意类型) |
| 索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
容器通用排序功能:sorted(容器,reverse=True)
set1 ={2,5,3,6}
print(set1)
print(sorted(set1,reverse=True))
字符串大小比较:基于数字的码值进行比较的(ASCII码表)
字符串是按位比较,也就是一位位进行比较,只要有一位大,那么整体就大
第七章-函数进阶
函数的多返回值
按返回值的顺序,写对应顺序的多个变量接收即可(支持不同类型的数据return)
def test():
return 1,2
x,y = text()
print(x)
print(y)
函数多种传参方式
位置参数
(传递的参数和定义的参数的顺序及个数必须一致)
def user(name,age,gender):
print(f"您的名字是{name},年龄是{age}岁,性别是{gender}")
user('tom',20,'男')
关键字参数
函数调用时通过“键 = 值”形式传递参数,不在意顺序
def user(name,age,gender):
print(f"您的名字是{name},年龄是{age}岁,性别是{gender}")
user(name ='tom',age = 20,gender ='男')
缺省参数
为参数提供默认值,调用函数时可不传递默认参数的值(放在最后)
def user(name,age,gender = '男'):
print(f"您的名字是{name},年龄是{age}岁,性别是{gender}")
user('tom',20)
不定长参数
也叫可变参数,用于不确定调用的时候会传递多少个参数
不定长参数的类型:
- 位置传递
- 关键字传递
位置传递:(传进的所有参数都会被args变量收集,最后合并为一个元组,args是元组类型)
def user(*args):
name,age,gender = args
print(f"您的名字是{name},年龄是{age}岁,性别是{gender}")
user('tom',20,'男')
关键字传递:(参数是“键 = 值”形式,所有的“键 = 值”都会被kwargs接受,最后组成字典)
def user(**kwargs):
name = kwargs.get('name')
age = kwargs.get('age')
gender = kwargs.get('gender')
print(f"您的名字是{name},年龄是{age}岁,性别是{gender}")
user(name = 'tom',age = 20)
匿名函数
函数作为参数传递
(传入计算逻辑,而非传入数据)
def test(complute):
result = complute(1,2)
print(result)
def complute(x,y):
return x + y
test(complute)
lambda匿名函数
函数定义中:
- def关键字,可以定义带有名称的函数
- lanbda关键字,可以定义匿名函数(无名称)
- 无名称的匿名函数,只可临时使用一次
匿名函数定义语法:
lambda 传入参数:函数体(一行代码)
def test(complute):
result = complute(1,2)
print(result)
test( lambda x,y:x+y)
第八章-文件操作
文件的编码
计算机中有许多的编码:
- UTF-8
- GBK
- Big5
- 等
不同编码,将内容翻译为二进制也是不同的
文件的读取
| 模式(mode) | 描述 |
|---|---|
| r | 只读,文件的指针将会放在文件的开头 |
| w | 写入。如果该文件已存在则打开文件,并从头开始编辑,原有内容会被删除。如果该文件不存在,创建新文件 |
| a | 打开一个文件用于追加。如果该文件已存在则打开文件,新的内容会被写入到已有内容之后。如果该文件不存在,创建新文件 |
打开文件
open(name,mode,encoding)
- name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
- mode:设置打开文件的模式:只读,写入,追加等
- encoding:编码格式(推荐使用utf-8)
读写文件
-
read()方法:
文件对象.read(num)
num表示要从文件中读取的数据的长度,如果没有num,那么就表示读取所有的数据 -
readlines()方法:
按照行的方式读取整个内容,返回一个列表,每一行的数据为一个元素 -
for循环读取文件行
f = open("D:\gua_data.csv","r",encoding="UTF-8")
for line in f:
print(line)
关闭文件
- f.close()
- with open(name,mode,encoding) as f:
f.readlines()
文件的写入
# 打开文件
f = open("","w")
# 文件写入
f.write("hello world")
# 内容刷新
f.flush()
- 直接调用write,内容会存在程序的内存中,称之为缓冲区
- 当调用flush时,内容会被真正写入文件
- 这样是为了避免频繁操作硬盘,导致效率下降
文件的追加
# 打开文件
f = open("","a")
# 文件写入
f.write("hello world")
# 内容刷新
f.flush()
fr = open("","r",encoding="UTF-8")
fw = open("","w",encoding="UTF-8")
for line in fr:
line = line.strip()
if line.split(",")[4] == "测试":
continue
fw.write(line)
fw.write("\n")
fr.close()
fw.close()
第九章python异常,模块,包
异常的捕获方法
bug的两种情况:
- 整个程序因为一个bug停止运行
- 对bug进行提醒,整个程序继续运行
捕获常规(所有)异常
语法:
try :
可能发生错误的代码
except:
如果出现异常需要处理的代码
捕获指定异常
语法:
try :
print(name)
except NameError as e:
print("name变量名称未定义错误")
捕获多个异常
使用元组的方式进行书写
try :
print(name)
except (NameError,ZeroDivisionError):
print("name变量名称未定义错误")
异常else
语法:
try :
print(name)
except NameError as e:
print("name变量名称未定义错误")
else:
print("没有出现异常")
异常的finally
无论是否出现异常,都需要执行的代码,例如关闭文件
python模块(就是python文件)
模块的导入
[from 模块名] import [模块 | 类 | 变量 | 函数 | * ] [as 别名]
自定义模块
新建一个文件,命名my_module1.py,并定义test函数(必须在同一文件夹下)
import my_module1
if __name__=="__mian__"表示,只有当程序是直接执行的才会进入if内部,如果是被导入的,则if无法进入
def add(x, y):
return x + y
if __name__ == '__main__':
print(add(1,2))
python包(就是装有python模块(python文件)的文件夹)
必须有__init__.py文件才是包
导入包:
import 包名.模块名
# 两种方式都可以
from 包名 import 模块名
json
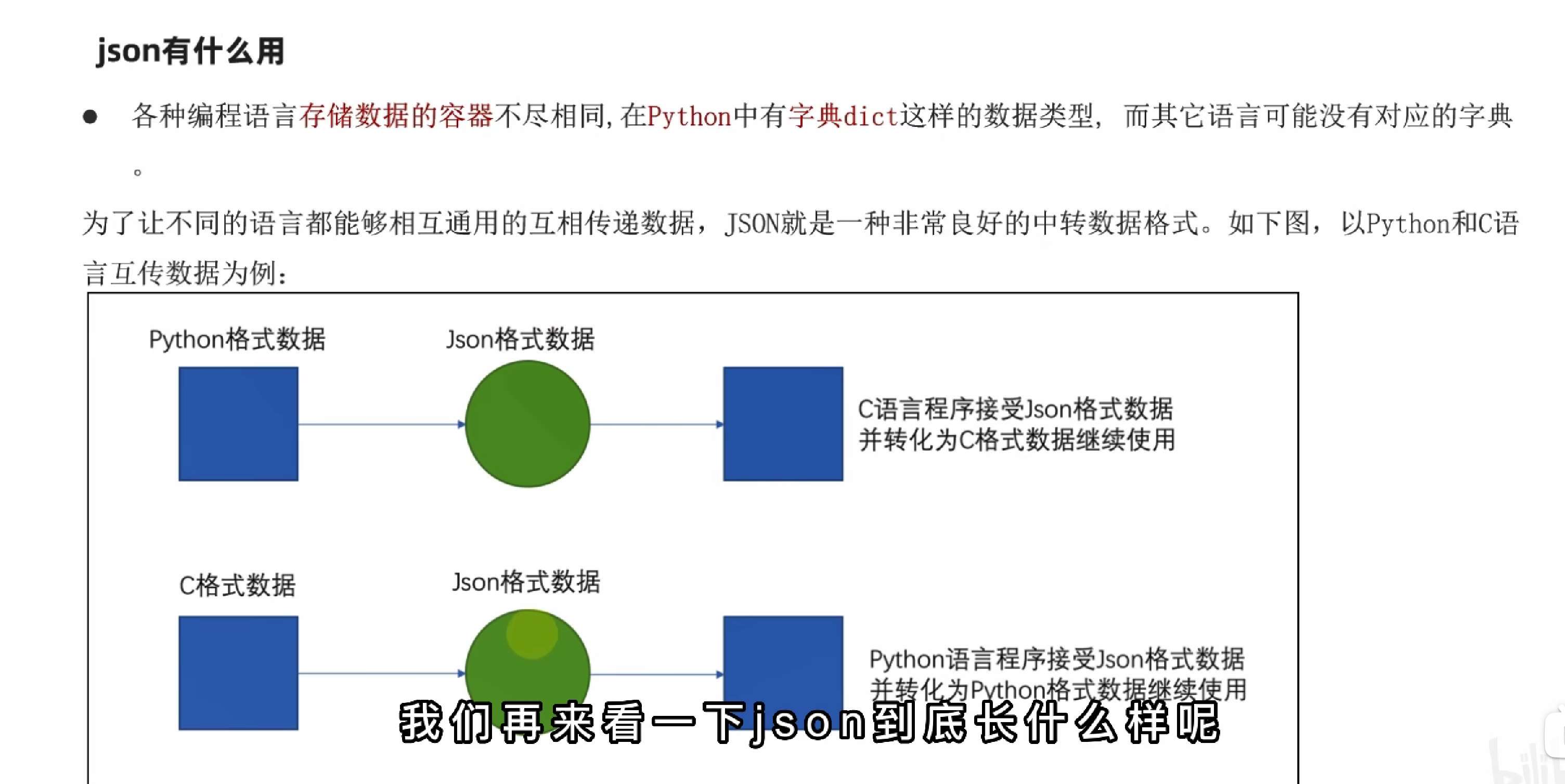
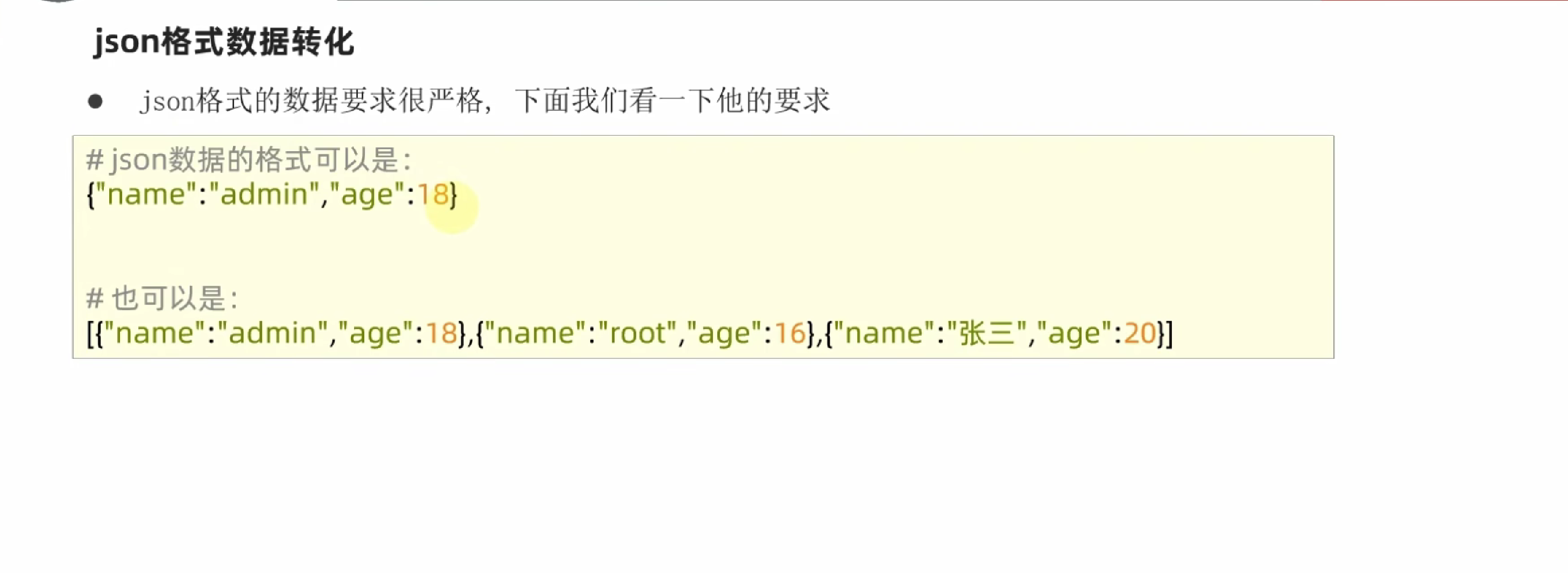
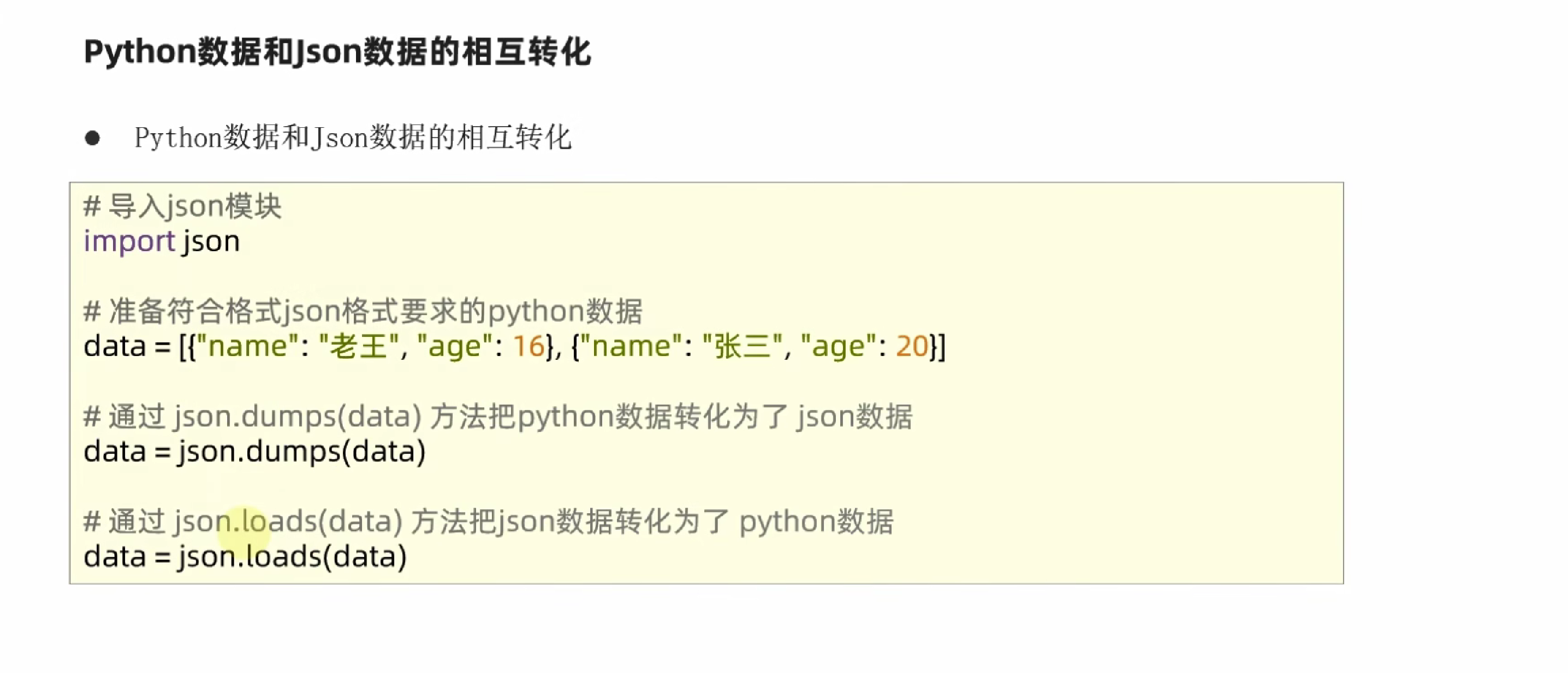
第十章
类
class 类名称:
类的属性
类的行为
- 类的属性:即定义在类中的变量(成员变量)
- 类的行为:即定义在类中的函数(成员方法)
# 设计一个类(设计表格)
class students:
name = None
gender = None
age = None
# 创建一个对象(打印表格)
stu_1 = students()
# 给对象啊进行赋值(填写表格)
stu_1.name = "zherui"
stu_1.age = 21
stu_1.gender = "nan"
成员方法的定义语法:
def 方法名(self,形参1,形参2,...):
方法体
- self关键字是成员方法定义的时候,必须填写的
- self用来表示类对象自身的意思
- 在方法内部,想要访问类的成员变量,必须使用self
- self关键字,尽管在参数列表中,但是传参的时候可以忽略它
示例:
class student():
name = None
def say_hi(self):
print(f"大家好,我是{self.name},欢迎大家多多关照")
stu = student()
stu.name = "zherui"
stu.say_hi()
类和对象
类只是一种传程序内的“设计图纸”,需要基于图纸生产实体(对象),才能工作,这种套路,称之为:面向对象编程
构造方法
pyhon类可以使用__init__()方法,称之为构造方法
- 在创建类对象的时候,会自动执行
- 在创建类对象的时候,将传入参数自动传递给__init__ 方法使用

其他内置方法(魔术方法)
| 方法 | 功能 |
|---|---|
__init__ |
构造方法 |
__str__ |
用于实现类对象转字符串的行为 |
__lt__ |
用于2个类对象进行小于或大于比较 |
__le__ |
用于2给类对象进行小于等于或大于等于比较 |
__eq__ |
用于2个类对象进行相等比较 |
class student():
def __init__(self,name,age):
self.name = name
self.age =age
stu = student("柘锐",21)
print(stu)
print(stu.name)
print(stu.age)
输出结果为:
<main.student object at 0x00000282C3C3CE10>
柘锐
21
class student():
def __init__(self,name,age):
self.name = name
self.age =age
def __str__(self):
return f"{self.name},{self.age}"
stu = student("柘锐",21)
print(stu)
输出结果为:
柘锐,21
封装、继承、多态
面向对象包含3大主要特性:
- 封装
- 继承
- 多态
封装
定义私有成员:
- 私有成员变量:变量名以__开头(2个下划线)
- 私有成员方法:方法名以__开头(2个下划线)
私有成员无法被类对象使用,但是可以被其他的成员使用
继承
单继承
class 类名(父类名):
类内容体
多继承
class 类名(父类名1,父类名2,...父类名n):
类内容体
多个父类中,如果出现同名的成员,那么默认以继承顺序(从左到右)为优先级
pass
pass是占位语句,用来保证类定义的完整性,表示空的意思
复写
子类继承父类的成员属性和成员方法后,如果对其“不满意”,可以进行复写
调用父类同名成员
一旦复写父类成员,那么类对象调用成员的时候,就会调用复写后的新成员,如果需要使用被复写的父类的成员,需要用到特殊的调用方式
方式1:使用成员变量:父类名.成员变量
方式2:使用成员方法:父类名.成员方法(self)
类型注解
变量的类型注解
语法1:变量:类型
语法2:# type:类型
函数(方法)的类型注解
- 形参的数据注解
- 返回值的数据注解
def 函数方法名(形参名:类型,形参名:类型,...) -> 返回值类型:
pass
Union类型
my_list : list[Union[str,int]] = [1,2,"zherui","iecast"]
my_dict : dict[str,Union[str,int]] = {"name":"xixi","age" :13}
def func(data:Union[int,str]) -> Uinon[int,str]
pass
多态
同样的行为(函数),传入不同的对象,得到不同的状态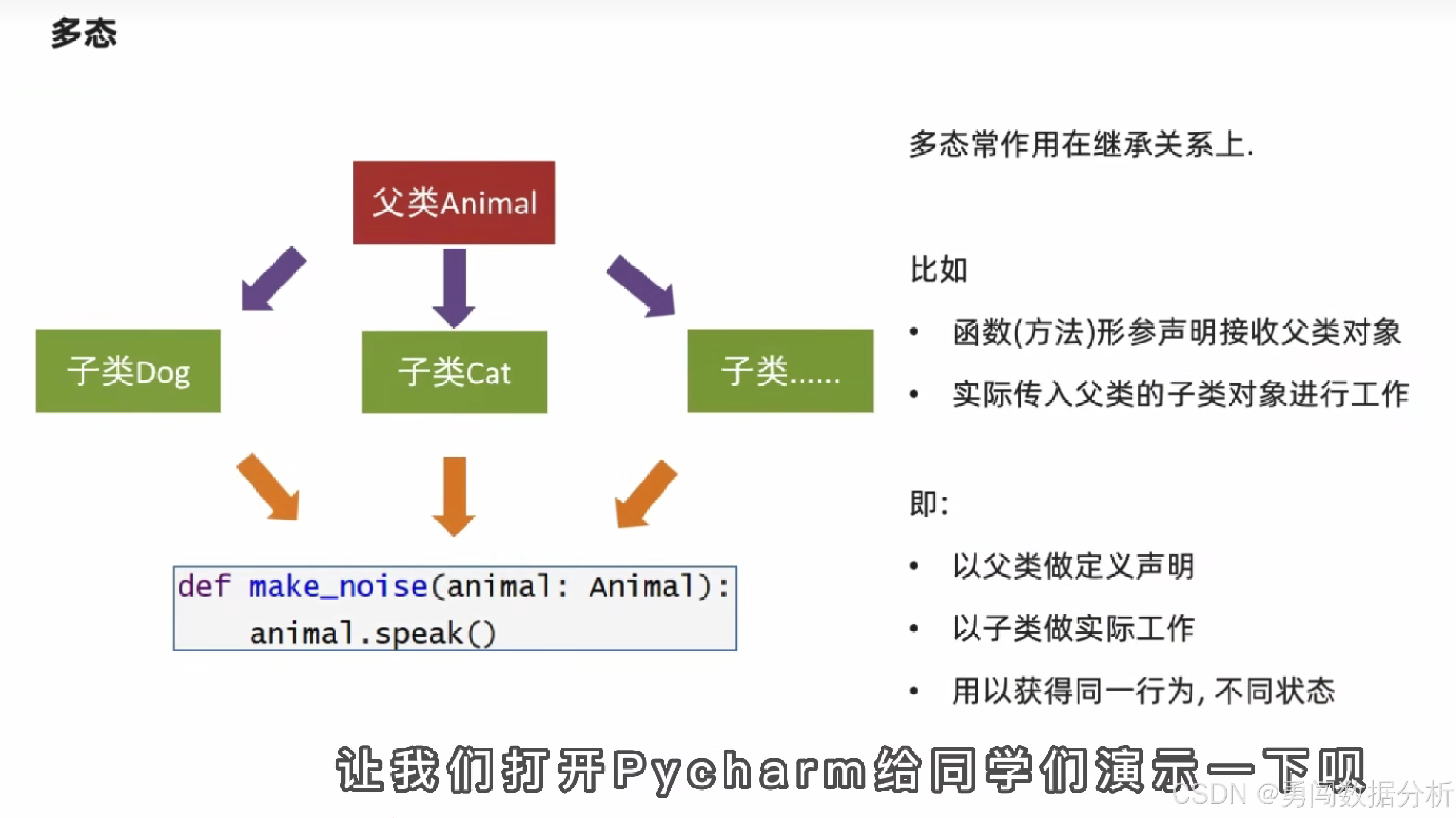
抽象类(接口):pass
抽象类就好比定义一个标准,包含了一些抽象的方法,要求子类必须实现
class ac:
def cool_wind(self):
# 制冷
pass
def hot_wind(self):
# 制热
pass
def swing_l_r(self):
# 左右摆风
pass
第十一章
python连接mysql
1.使用指令:pip isntall pymysql 安装这个pymysql包
2.使用如下代码连接到mysql:
from pymysql import Connection
conn=Connection(
host="localhost", #主机名
port=3306, #端口
user="root", #账户
password="zerui1012" #密码
)
print(conn.get_proto_info()) #打印mysql数据库软件信息
如果打印成功,说明连接数据库成功
cursor = conn.cursor() #创建游标对象
conn.select_db("test") #获取数据库
cursor.execute("select * from student") #获取查询语句,可以省略分号
results : tuple= cursor.fetchall() #用fetchall成员方法得到results变量
for x in results: #遍历元组
print(x)
conn.close() #关闭数据库的连接
commit提交
pymysql在执行插入或产生其他数据更改的sql语句时,默认时需要提交更改的:通过conn.commit()代码实现;如果想自动提交,可以在创建conn类对象时添加:autocommit=True 代码来实现

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 55
55 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)