文本分类模型_一文读懂文本分类基线深度模型从fastText到Transformer(上)
传统机器学习文本分类的主要问题是对文本表示是高纬度稀疏的,特征表达能力弱,还需要特征工程,成本很高。深度学习最初在之所以图像和语音取得巨大成功,一个很重要的原因是图像和语音原始数据是连续和稠密的,有局部相关性。深度学习模型完成文本分类任务,首先对文本进行embedding表示,再利用深度模型自动获取特征表达能力,去掉繁杂的人工特征工程,实现端到端的文本分类。文本分类模型训练过程文本分类模型预测过程

传统机器学习文本分类的主要问题是对文本表示是高纬度稀疏的,特征表达能力弱,还需要特征工程,成本很高。深度学习最初在之所以图像和语音取得巨大成功,一个很重要的原因是图像和语音原始数据是连续和稠密的,有局部相关性。深度学习模型完成文本分类任务,首先对文本进行embedding表示,再利用深度模型自动获取特征表达能力,去掉繁杂的人工特征工程,实现端到端的文本分类。
文本分类模型训练过程

文本分类模型预测过程
fastText
源自:https://arxiv.org/pdf/1607.01759.pdf
fastText模型来自16年Tomas Mikolov力作,作者2013年在Google提出了Word2Vec,后来到Facebook提出了fastText。从word representation到sentence classification,Tomas Mikolov的工作对NLP影响很多。虽然有个别模型和实验结果曾遭受质疑,但瑕不掩瑜。
fastText核心有三方面:
1)模型架构
类似CBOW(Continuous Bag-of-Words)模型,fastText模型输入的是词的序列(一段文本或者一句话),输出这个词序列属于各个类别的概率。序列中的词或词组构成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。
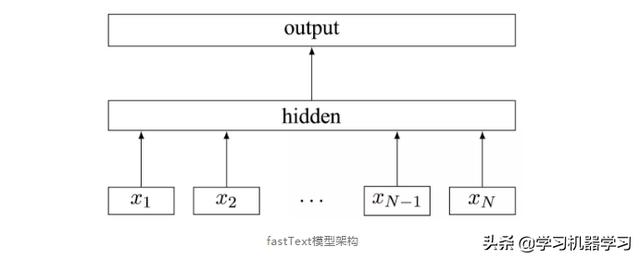
fastText模型架构和CBOW模型架构类似,不同之处是:fastText预测标签,而CBOW预测中间词。
2) 层次softmax
当分类类别数较多时,扁平式架构的线性分类器复杂度高。fastText模型使用了层次softmax:基于哈弗曼编码树(Huffman coding tree),对类别进行编码,极大缩小模型预测目标的计算空间,由O(kh)减少至O(hlog2(k),其中k是类别数,h是隐含层维数。
fastText利用了类别不均衡的特点(一些类别出现次数比其他的更多),通过哈弗曼算法建立树形结构来表征类别,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,进一步提升计算效率。
3) n-gram特征
n-gram增加了词组或固定搭配(原文叫做“local word order”)对类别的贡献,用于丰富文本特征。
下图源自:https://arxiv.org/pdf/1702.05531.pdf
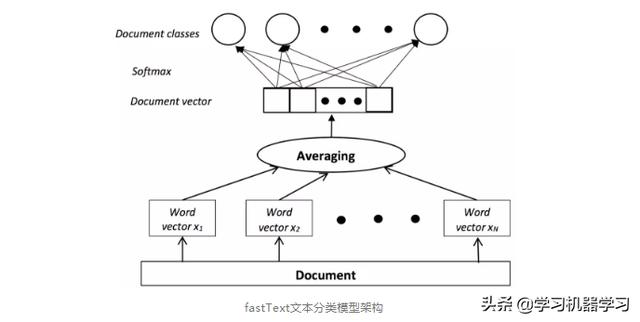
上图是基于fastText的模型架构,其中document vector是文本所有词(或n-gram词组)向量的均值。
小结
fastText学习速度较快,适用于分类类别非常大而且数据量足够多的情况,当分类类别比较小或者数据集比较少的话,很容易过拟合。fastText可以无监督学习词向量,也可以用于有监督的文本分类任务。
TextCNN
TextCNN模型架构如下图所示,输入数据先通过embedding layer,对输入语句进行embedding表示,然后通过convolution layer提取语句的特征,最后通过fully connected layer得到输出。
源自:https://arxiv.org/pdf/1408.5882.pdf
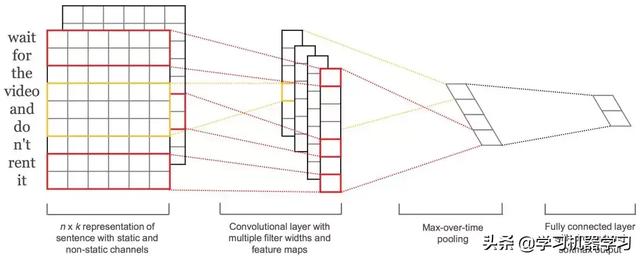
TextCNN模型架构
- Embedding Layer
将输入的词序列(通过如word2vec、Glove、fastText等词预训练方法获得词向量)编码成distributed representation,也可以先词向量随机初始化,然后再训练TextCNN过程中对词向量进行训练(称为CNN-rand)。如果使用预训练好的词向量,这种方法又可以分为静态方式和非静态方式:前者(称为CNN-static)是在训练textCNN过程中不再调节词向量的参数,后者(称为CNN-non-static)在训练过程中调节词向量的参数,所以,后者的结果比前者要好。更为一般的做法是:不要在每一个batch中都调节embedding层,而是每n个batch调节一次,这样可以减少训练的时间,又可以微调词向量。
- Convolution Layer
通过卷积提取不同的n-gram特征。输入词序列(一段文本或者一句话),通过embedding layer后,会转变成一个二维矩阵。假设文本的长度为|T|,词向量的大小为|d|,则该二维矩阵的大小为|T|×|d|,对这个|T|×|d|的二维矩阵进行卷积,卷积核的大小一般设定为n×|d|,n是卷积核的长度(又称作filter size),|d|是卷积核的宽度,这个宽度和词向量的维度是相同的,也就是卷积只是沿着文本序列进行的。通常n可以有多种选择,比如2、3、4、5,获取不同宽度的视野。对于一个|T|×|d|的文本,如果选择卷积核kernel的大小为2×|d|,则卷积后得到的结果是|T-2+1|×1的一个向量(称作feature map)。卷积层本质上是一个n-gram特征提取器,不同的卷积核提取的特征不同。
上图中有2个channels,图像中利用(R, G, B)作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如word2vec或Glove),也可利用静态词向量和fine-tunning词向量作为不同channel。2个channels对应2个卷积核(filter_size=2、3),卷积后得到4个卷积核。
- Max-pooling Layer
最大池化(Max-pooling)层卷积后得到的若干个一维向量取最大值,然后拼接后作为本层的输出值。如果卷积核的size=2、3、4、5,每个size有128个kernel,则经过卷积层后会得到4x128个一维的向量(注意这4×128个一维向量的大小不同,但是不妨碍取最大值),再经过Max-pooling之后,会得到4×128个scalar值,拼接在一块,得到最终的结构是512×1的向量。Max-pooling层的意义在于对卷积提取的n-gram特征,选取激活程度最大的特征。
- Fully-connected Layer
Fully-connected layer在max-pooling layer后再连一层全连接层,作为输出结果。实际中为了提高模型学习能力,也可以连接多个全连接层。
下面是一个TextCNN详细过程原理图。
源自:https://arxiv.org/pdf/1510.03820v3.pdf
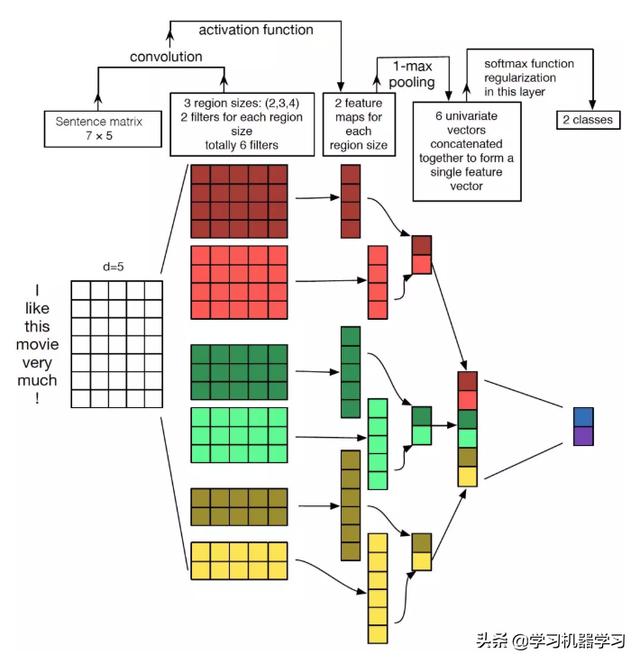
图中最左边第一层是7乘5的句子矩阵,每行是词向量,维度=5。然后经过卷积层有filter_size=(2,3,4)的一维卷积层,每个filter_size有两个输出channel。第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了,最后接一层全连接的softmax层,输出每个类别的概率。
单层CNN进行文本分类参数建议:
- 词嵌入维度: 300维, 主要针对预训练;
- Filter大小:filter=7最优,不同数据集上最优组合不一致, 但相差不多;
- Filter的个数:推荐100~600个,最好接近600;
- 激活函数:任何激活函数、ReLU、tanh比sigmoid、cube效果要好;
- Pooling:推荐1-max pooling,不要用average,效果不好;
- 正则化:dropout rate不要超过0.5,l2正则化效果不明确。
小结
TextCNN可看做是一个n-gram特征提取器,对于输入词序列需要做定长处理, 超过要截断, 不足的要补0。补充0是因为后面Max-pooling只会选择最大值,补零的项会被过滤掉,对后面的结果没有影响。
TextRNN
尽管TextCNN最大问题是需要固定视野(filter size),一方面无法建模更长的序列信息,另一方面filter_size的超参调节也很繁琐。TextCNN本质是做文本的特征表达工作。
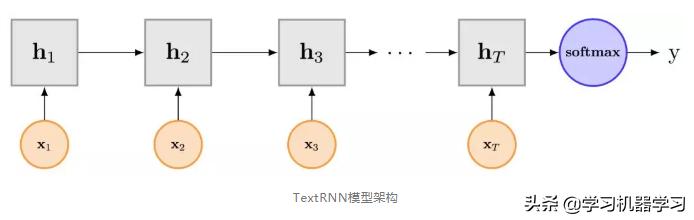
递归神经网络(Recurrent Neural Network,RNN),相比于TextCNN,能够更好表达上下文信息。其中双向的递归神经网络(Bi-directional RNN)从某种意义上可以理解为可以捕获变长且双向的n-gram信息。
源自:http://univagora.ro/jour/index.php/ijccc/article/download/3142/pdf
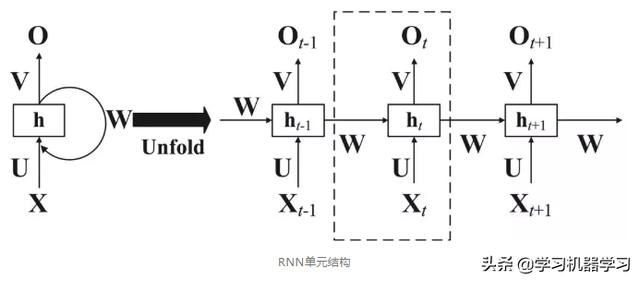
上图是RNN结构,RNN的输入是将词序列(一段文本或者一句话)的每一个词从前到后一个一个的输入:xt是时刻t的输出,就是词序列的第t个词的词向量;ht是时刻t的隐层状态,隐层状态(即隐层神经元活性值)不仅和当前时刻的输入xt相关,也和上一个时刻的隐层状态ht-1相关;ot是时刻t的输出, 通常接全连接层softmax分类输出;U、V、W是模型需要学习的参数。
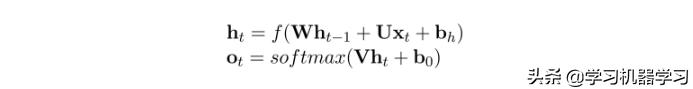
图中虚线框描述的是第t个单元的计算过程,如公式所示,f(·)是非线性激活函数,通常为logistic函数或tanh函数,W为状态-状态权重矩阵,U为状态-输入权重矩阵,b为偏置。循环神经网络具有短期记忆能力,ot是对ht连一层全连接网络接softmax函数进行分类。
RNN循环神经网络中的隐状态h存储了历史信息,可以看作是一种记忆,但是记忆容量有限,解决方案是引入门控来控制信息的累积速度,包括有选择地加入新的信息,并有选择地遗忘之前累积的信息。这一类网络称为基于门控的循环神经网络(Gated RNN)。主要有两种基于门控的循环神经网络:长短期记忆(LSTM)网络和门控循环单元(GRU)网络。
需要注意的是:在数字电路中,门(gate)为一个二值变量{0,1},0代表关闭状态,不许任何信息通过;1代表开放状态,允许所有信息通过。LSTM网络中的“门”是一种“软”门,取值在(0,1)之间,表示以一定的比例运行信息通过。
LSTM(长短期记忆网络)
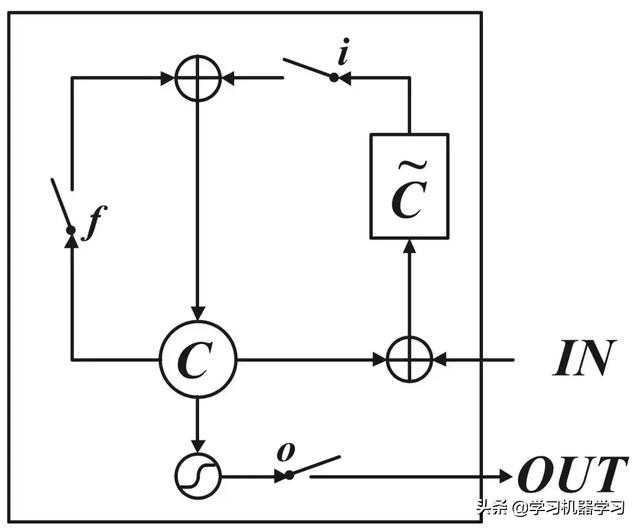
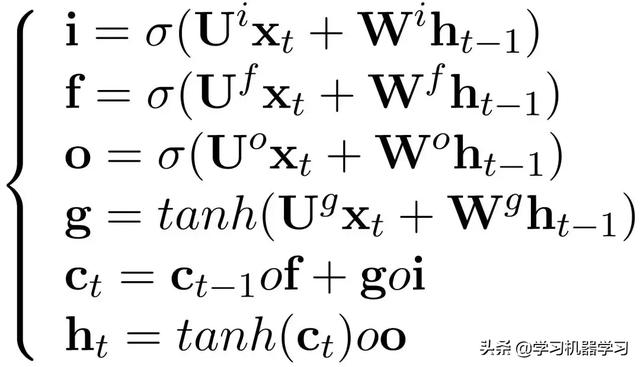
LSTM单元结构
上图给出了LSTM的循环单元结构,计算过程为:1) 首先利用上一时刻的外部状态ht−1和当前时刻的输入xt,计算出三个门:遗忘门ft(控制上一个时刻的内部状态ct−1需要遗忘多少信息)、输入门it(控制当前时刻的候选状态c̃t有多少信息需要保存)、输出门ot(控制当前时刻的内部状态ct有多少信息需要输出给外部状态ht),以及候选状态c̃t;2) 结合遗忘门ft和输入门it来更新记忆单元ct;3) 结合输出门ot,将内部状态的信息传递给外部状态ht。σ(·)为logistic函数(sigmoid)。o表示向量元素乘积。
在简单循环网络中,隐状态每个时刻都会被重写,因此可以看作是一种短期记忆(short-term memory)。长期记忆(long-term memory) 可以看作是网络参数,隐含了从训练数据中学到的经验,并更新周期要远远慢于短期记忆。而在LSTM网络中,记忆单元c可以在某个时刻捕捉到某个关键 信息,并有能力将此关键信息保存一定的时间间隔。记忆单元c中保存信息的生命周期要长于短期记忆h,但又远远短于长期记忆,因此称为长的短期记忆(long short-term memory)。
GRU(门控循环单元网络)
GRU网络比LSTM网络简单,LSTM网络中输入门和遗忘门是互补关系,用两个门比较冗余。GRU网络将输入门与和遗忘门合并成一个门:更新门(update gate)。GRU不引入额外的记忆单元,直接在当前状态ht和历史状态ht−1之间引入线性依赖关系。rt为重置门(reset gate),控制候选状态h ̃t的计算是否依赖上一时刻的状态ht−1。
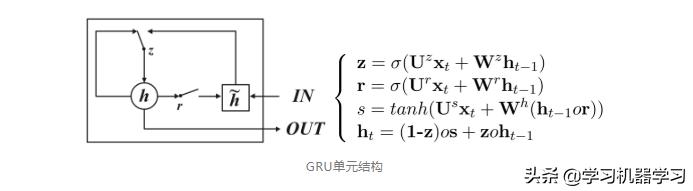
上图给出了GRU网络的循环单元结构,其计算过程为:1) 首先利用上一时刻的外部状态ht−1和当前时刻的输入xt,计算出两个门:更新门zt(控制当前状态需要从历史状态中保留多少信息,以及需要从候选状态中接受多少新信息)、重置门rt(控制候选状态h ̃t的计算是否依赖上一时刻的状态ht−1);2) 结合重置门rt来更新候选状态h ̃t;3) 结合更新门zt,将内部状态的信息传递给外部状态ht。
分类任务中,一个时刻的输出不仅和过去时刻的信息有关,也和后续时刻的信息有关。比如给定一个句子,其中一个词的词性由它的上下文决定,即包含左右两边的信息。因此,在分类任务中,可以增加一个按照时间的逆序来传递信息的网络层,增强网络能力。
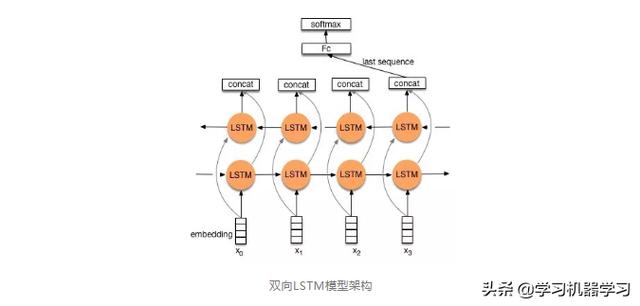
上图是双向LSTM网络(bidirectional LSTM,Bi-LSTM)用于分类问题的网络结构原理示意图,它是两层LSTM组成。这两层LSTM的输入是相同的,只是信息传递的方向不同。黄色的节点分别是前向和后向RNN的输出,示例中的是利用最后一个词的结果连全连接层接softmax输出,进行类目预测。
总结
TextRNN可看做是自然语言处理领域的标配网络了,能够更好的表达上下文信息。在文本分类任务中,双向LSTM从某种意义上可以理解为捕获变长且双向的的n-gram信息。
TextRCNN
源自:https://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/download/9745/9552
TextRNN可以获取上下文信息,但是单向RNN是有偏的模型(biased model),后面的词占得重要性更大。TextCNN是无偏的模型(unbiased model),能够通过最大池化获得最重要的特征,但是特征提取器大小固定,设定小了容易造成信息丢失,设定大了造成巨大的参数空间。
为了解决TextRNN和TextCNN的模型缺陷,循环卷积神经网络(Recurrent Convolutional Neural Networks,RCNN)提出了:①双向循环结构:比传统的基于窗口的神经网络噪声要小,能够最大化地提取上下文信息;②max-pooling池化层:自动决策哪个特征更有重要作用。
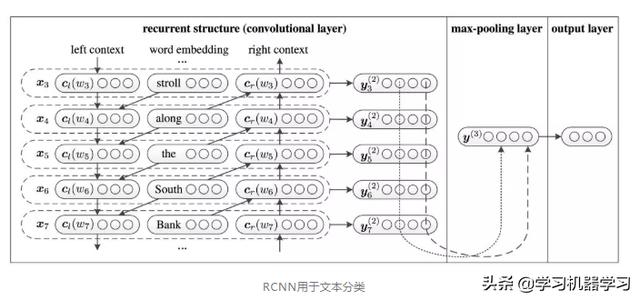
代码实现如下:
源自:https://github.com/roomylee/rcnn-text-classification
1# Placeholders for input, output and dropout 2self.input_text = tf.placeholder(tf.int32, shape=[None, sequence_length], name='input_text') 3self.input_y = tf.placeholder(tf.float32, shape=[None, num_classes], name='input_y') 4self.dropout_keep_prob = tf.placeholder(tf.float32, name='dropout_keep_prob') 5 6text_length = self._length(self.input_text) 7 8# Embeddings 9with tf.device('/cpu:0'), tf.name_scope("embedding"):10 self.W_text = tf.Variable(tf.random_uniform([vocab_size, word_embedding_size], -1.0, 1.0), name="W_text")11 self.embedded_chars = tf.nn.embedding_lookup(self.W_text, self.input_text)1213# Bidirectional(Left&Right) Recurrent Structure14with tf.name_scope("bi-rnn"):15 fw_cell = self._get_cell(context_embedding_size, cell_type)16 fw_cell = tf.nn.rnn_cell.DropoutWrapper(fw_cell, output_keep_prob=self.dropout_keep_prob)17 bw_cell = self._get_cell(context_embedding_size, cell_type)18 bw_cell = tf.nn.rnn_cell.DropoutWrapper(bw_cell, output_keep_prob=self.dropout_keep_prob)19 (self.output_fw, self.output_bw), states = tf.nn.bidirectional_dynamic_rnn(cell_fw=fw_cell, cell_bw=bw_cell, inputs=self.embedded_chars, sequence_length=text_length, dtype=tf.float32)2021with tf.name_scope("context"):22 shape = [tf.shape(self.output_fw)[0], 1, tf.shape(self.output_fw)[2]]23 self.c_left = tf.concat([tf.zeros(shape), self.output_fw[:, :-1]], axis=1, name="context_left")24 self.c_right = tf.concat([self.output_bw[:, 1:], tf.zeros(shape)], axis=1, name="context_right")2526with tf.name_scope("word-representation"):27 self.x = tf.concat([self.c_left, self.embedded_chars, self.c_right], axis=2, name="x")28 embedding_size = 2 * context_embedding_size + word_embedding_size2930with tf.name_scope("text-representation"):31 W2 = tf.Variable(tf.random_uniform([embedding_size, hidden_size], -1.0, 1.0), name="W2")32 b2 = tf.Variable(tf.constant(0.1, shape=[hidden_size]), name="b2")33 self.y2 = tf.tanh(tf.einsum('aij,jk->aik', self.x, W2) + b2)3435with tf.name_scope("max-pooling"):36 self.y3 = tf.reduce_max(self.y2, axis=1)3738with tf.name_scope("output"):39 W4 = tf.get_variable("W4
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)