深度学习06——图像分类实战
如何使用无标签数据。如图当模型进过一定训练且拥有一定准确率后,可以将无标签数据投入模型中进行预测,将预测结果作为真实标签用于模型的进一步训练。某点的计算梯度并不完全等于当前点的梯度,而是如公式所示不仅要考虑当前点的梯度,同时还要考虑前点的梯度值。已经训练好的模型提取出了优秀的图片特征,计算好了相关参数,因此我们可以直接利用已经训练好的编码器,再使用自己的分类头。为了解决这一问题,在训练之初就将图片
一、项目介绍
安装包——CV2和timm
项目介绍:ML2021春季-HW3。(网址:ml2021spring-hw3)
共有11类食物。 其中带标签的数据有 280 *11张照片 ;不带标签的训练数据有 6786 张照片;验证集有30*11张照片 ;测试集有3347张照片。
二、数据增广
当训练好模型后,譬如模型可以很好的分辨一张照片是猫还是狗,但当将同样内容但是尺寸更小或者角度不同的照片输入模型,模型依旧不能成功分辨。原因可能是因为不同尺寸照片对应的卷积核大小不同,因此训练出的模型并没有那么“智能”。
为了解决这一问题,在训练之初就将图片进行各种缩放、翻转、对比度调大等变化输入模型,让模型训练各种形式的图片,以达到训练效果,这一过程称为数据增广。
三、优化器Adam、AdamW和SGD
SGD仅利用当前点的梯度进行参数的更新。
Adam相对于SGD存在两个变换。1.梯度改变为:θ*η(old)+(1-θ)*η(now)。某点的计算梯度并不完全等于当前点的梯度,而是如公式所示不仅要考虑当前点的梯度,同时还要考虑前点的梯度值。2.Adam会自动调整学习率。当梯度过大,学习率会自动减小;当梯度过小,学习率会自动增大。
权重衰减(Weight Decay)是深度学习中一种常用的正则化技术,通过在损失函数中添加参数的 L2 范数惩罚项,限制模型参数的大小,从而防止过拟合。AdamW即在Adam的基础上加上了改变了权重衰减的处理方式,从而具有了更加稳定的收敛能力。
四、迁移学习
数据量少时的最佳选择。当个人在做图像分类时,硬件差、数据少,因此模型训练结果差。此时可以直接借用已经训练好的模型。
如图,将模型训练步骤可以分为编码器与分类图。已经训练好的模型提取出了优秀的图片特征,计算好了相关参数,因此我们可以直接利用已经训练好的编码器,再使用自己的分类头。
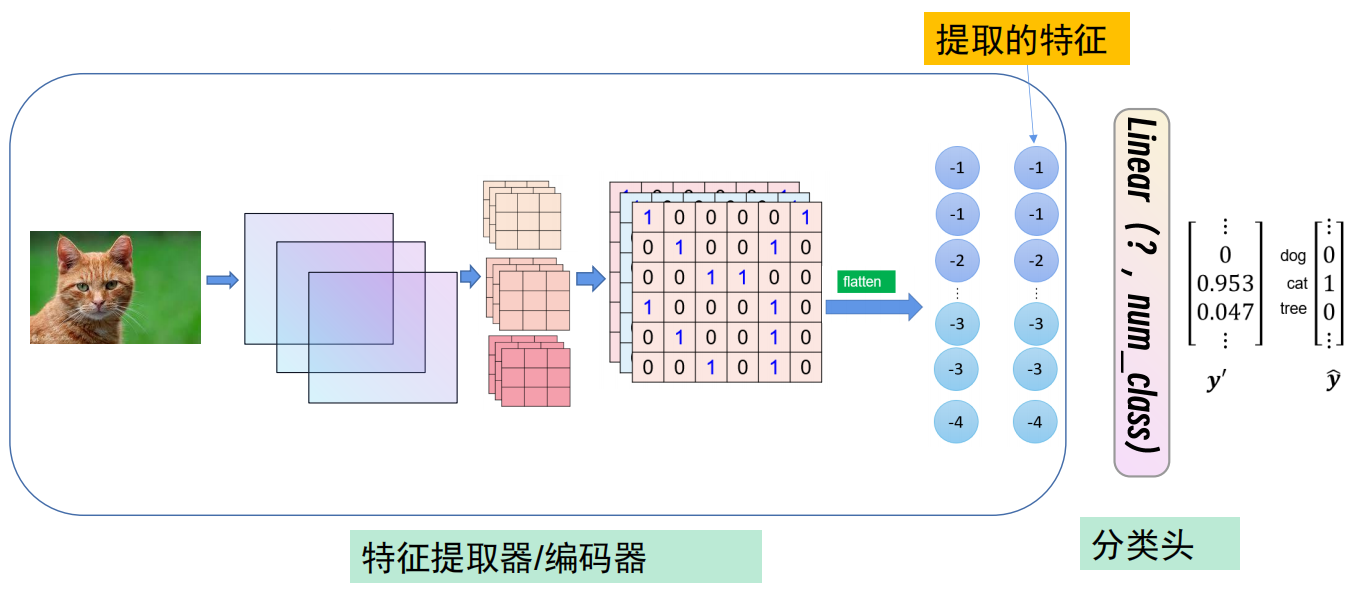
五、半监督学习
监督学习,即通过有标签的数据与训练结果求Loss值来更新模型。半监督学习则是既有有标签数据也有无标签数据。
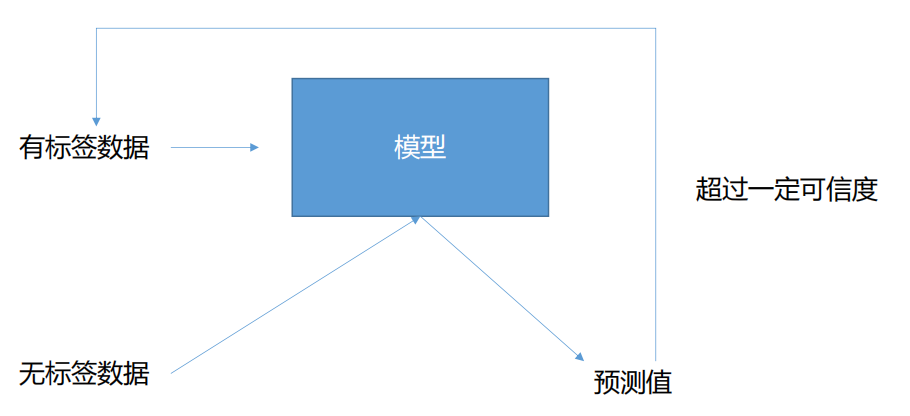
如何使用无标签数据。如图当模型进过一定训练且拥有一定准确率后,可以将无标签数据投入模型中进行预测,将预测结果作为真实标签用于模型的进一步训练。当然并非所有预测结果都会被认为是可靠的,而是必须超过一定可信度,即一定概率,才认为这个预测结果可以用于下一步模型训练。(如同样都是类别1,【0.9 0.05 0.05】认为是可靠的预测结果,而【0.4 0.3 0.3】则认为是不可靠的)
六、项目实战
import random
import torch #深度学习框架的核心库
import torch.nn as nn #用于构建神经网络的模块,包含了各种层(如卷积层、全连接层)、激活函数等
import numpy as np #用于数值计算
import os #与操作系统交互的库
from PIL import Image #读取图片数据
from tqdm import tqdm #进度条库,它可以为循环、迭代过程添加可视化的进度条
from torchvision import transforms #用于数据增广
import time
import matplotlib.pyplot as plt
form import initialize_model #引入初始化参数
from torch.utils.data import Dataset, DataLoader #Dataset类,其用于封装自定义数据集,需要子类继承的两个核心方法:__len__()返回数据集的总样本数;__getitem__(index)根据索引index返回一个样本
def seed_everything(seed): #固定所有可能影响随机性的种子,从而保证实验结果的可重复性
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
#################################################################
seed_everything(0)
###############################################
###数据处理
HW=224 #定义图片大小
train_transform=transforms.Compose( #通过transforms.Compose将多个增广操作组合成一个序列
[
transforms.ToPILImage(), #将数组输出为(3,H,w)大小的PIL图片
transforms.RandomResizedCrop(224), #随机放大并裁切
transforms.RandomRotation(50), #图片在50度以内随机旋转
transforms.RandomHorizontalFlip(),
autoaugment.AutoAugment(), #自动选择增广方式
transforms.ToTensor() #将图片转为张量
]
)
val_transform=transforms.Compose( #用原图进行验证
[
transforms.ToPILImage(), #将数组输出为(3,H,w)大小的PIL图片
transforms.ToTensor() #将图片转为张量
]
)
class food_Dataset(Dataset) #继承Dataset抽象基类
def __init__(self,path,mode="train"):
self.mode=mode
if mode=="semi": #半监督学习只返回数据内容
self.X=self.read_file(path)
else:
self.X,self.Y=self.read_file(path)
self.Y=torch.LongTensor(self.Y) #将标签转化为长整型
if mode=="train":
self.transforms=train_transforms #数据增广
else:
self.transforms=val_transforms
def read_file(self,path): #用于读取图片的函数
if self.mode=="semi":
file_list=os.listdir(path) #列出文件夹下所有文件名字
xi=np.zeros((len(file_list),HW,HW,3),dtype=np.uint8) #搭建一个全为0的数组空间,用于放入图片;dtype=np.unit8数组空间读为整型
for j,img_name in enumerate(tqdm(path)): #内置函数enumerate()会将列表转换为一个可迭代的枚举对象,每次迭代返回一个元组(索引, 元素)
img_path=os.path.join(path,img_name) #os提供的官方模块,拼接多个路径片段
img=Image.open(img_path) #打开路径下的图片
img=img.resize((HW,HW)) #调整图片大小
xi[j,...]=img #将图片放入数组中去
print("读到了%d个数据"%len(xi))
return xi
else:
for i in tqdm(range(11)):
file_dir=path+"/%02d"%i #写入每个食物类型文件夹的地址
file_list=os.listdir(file_dir) #列出文件夹下所有文件名字
xi=np.zeros((len(file_list),HW,HW,3),dtype=np.uint8) #搭建一个全为0的数组空间,用于放入图片;dtype=np.unit8数组空间读为整型
yi=np.zeros((len(file_list),dtype=np.uint8)
for j,img_name in enumerate(tqdm(file_list)): #内置函数enumerate()会将列表转换为一个可迭代的枚举对象,每次迭代返回一个元组(索引, 元素)
img_path=os.path.join(file_dir,img_name) #os提供的官方模块,拼接多个路径片段
img=Image.open(img_path) #打开路径下的图片
img=img.resize((HW,HW)) #调整图片大小
xi[j,...]=img #将图片放入数组中去
yi[j]=i
if i==0:
X=xi
Y=yi
else:
X=np.concatenate((X,xi),axis=0) #沿着指定的轴拼接多个数组
Y=np.concatenate((Y,yi),axis=0)
print("读到了%d个数据"%len(Y))
return X,Y
def __getitem__(self,item): #返回数据
if self.mode=="semi":
return self.transforms(self.X[item]),self.X[item]
else:
return self.transforms(self.X[item]),self.Y[item]
def __len__(self):
return len(self.X)
###半监督学习
class semiDataset(Dataset)
def __init__(self,no_label_loader,model,device,thres=0.7): #传入对无标签数进行分类所需参数,置信度0.99
x, y=self.get_label(no_label_loader,model,device,thres)
if x==[]: #如果数据为空
self.flag=False
else:
self.flag=True
self.X=np.array(x) #将列表转为数组
self.Y=torch.LongTensor(y) #将列表转为长整型张量
self.transform=train_transform
def get_label(self,no_label_loader,model,device,thres) #对无标签数进行分类的函数
model=model.to(device)
pred_prob=[] #创建空列表存放预测结果
labels=[]
x=[] #创建空列表存放最后合格的结果
y=[]
soft=nn.softmax() #创建一个Softmax激活函数的实例
with torch.no_grad(): #关闭梯度计算
for bat_x,_ in no_label_loader:
bat_x=bat_x.to(device)
pred=model(bat_x) #获得预测值
pred_soft=soft(pred) #将模型输出的原始分数转换为概率分布
pred_max,pred_value=pred_soft.max(1) #返回一个元组(第1维最大值,所在的索引)
pred_prob.extend(pred_max.cpu().numpy().tolist()) #.extend()可以合并俩个列表;.numpy().tolist()将张量转化为数组再转化为列表
labels.extend(pred_value..cpu().numpy().tolist())
for index,prob in enumerate(pred_prob):
if prob>thres: #若概率大于置信度
x.append(no_label_loader.dataset[index][1]) #利用.dataset指向Dataloader所包装的原始数据集对象来获取原始图片
y.append(labels[index])
return x,y
def __getitem__(self,item):
return self.transform(self.X[item]),self.Y[item]
def __len__(self)
return len(self.X)
def get_semi_loader(no_label_loader,model,device,thres):
semiset=semiDataset(no_label_loader,model,device,thres)
if semiset.flag==Flase:
return None
else:
semi_loader=DataLoader(semiset,batch_size=4,shuffle=False)
return semi_loader
###模型
class myModel(nn.Module) #继承nn.Module类的核心功能
def __init__(self,num_class):
super(myModel,self).__init__()
self.conv1=nn.Conv2d(3,64,3,1,1) #第一层卷积层。特征图尺寸变化3*224*224->64*224*224
self.bn1=nn.BatchNorm2d(64) #参数归一化
self.relu1=nn.ReLU() #激活函数
self.pool1=nn.MaxPool2d(2) #第一层池化层。64*224*224->64*112*112
self.layer1=nn.Sequential( #将一系列层封装成一个模块
nn.Conv2d(64,128,3,1,1), #—>128*112*112
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2), #—>128*56*56
)
self.layer2=nn.Sequential(
nn.Conv2d(128,256,3,1,1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2), #—>256*28*28
)
self.layer3=nn.Sequential(
nn.Conv2d(256,512,3,1,1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2), #—>512*14*14
)
self.pool2=nn.MaxPool2d(2) #—>512*7*7
self.fc1=nn.Linear(25088,1000) #第一层全连接层
self.relu2=nn.ReLU()
self.fc2=nn.Linear(1000,num_class)
def forward(self,x):
x=self.conv1(x)
x=self.bn1(x)
x=self.relu1(x)
x=self.pool1(x)
x=self.layer1(x)
x=self.layer2(x)
x=self.layer3(x)
x=self.pool2(x)
x=x.view(x.size[0],-1) #拉直特征图
x=self.fc1(x)
x=self.relu2(x)
x=self.fc2(x)
return x
#model=myModel(11)
###迁移学习
from torchvision.models import resnet18 #导入模型
model=resnet18(pretrained=True) #不仅使用模型架构,还保留参数,不从0开始训练
in_fetures= model.fc.in_fetures #获取模型的分类头输入维度
model.fc=nn.Linear(in_fetures,11)
###训练函数
def train_val(model,train_loader,val_loader,no_label_loader,device,epochs,optimizer,loss,thres,save_path) #定义训练函数
model=model.to(device)
semi_loader=None
plt_train_loss=[] #创建记录loss值的空列表,记录所有轮次的loss值
plt_val_loss=[]
plt_train_acc=[] #创建记录loss值的空列表,记录模型的准确率
plt_val_acc=[]
max_acc=0.0 #记录最高准确率
for epoch in range(epochs):
train_loss=0.0 #初始化loss值
val_loss=0.0
train_acc=0.0 #初始化准确率
val_acc=0.0
semi_loss=0.0 #初始化semi相关值
semi_acc=0.0
start_time=time.time()
model.train() #模型调整为训练模式,确保Dropout、BatchNorm等层使用训练模式的逻辑
for batch_x,batch_y in train_loader:
x,target=batch_x.to(device),batch_y.to(device) #将函数放置GPU计算
pred=model(x) #利用已经定义好的类,得到预测值
train_bat_loss=loss(pred,target,model) #loss值为一批的平均值
train_bat_loss.backward #梯度回传
optimizer.step() #更新模型
optimizer.zero_grad() #梯度清零
train_loss+=train_bat_loss.cpu().item() #.item()取出数值;.cpu()将模型放回cpu
train_acc+=np.sum(np.argmax(pred.detach().cpu().numpy(),axis=1)==target.cpu().numpy()) #.detach()从计算图中分离张量pred;.numpy()将张量转换为数组,便于使用NumPy的函数进行后续计算;np.argmax()返回沿指定轴的最大值索引;np.sum()用于对布尔数组求和,True会被当作1,False当作0;这段代码用于计算当前批次中模型预测正确的样本数量
plt_train_loss.append(train_loss/train_loader.__len__()) #.append()用于在列表的末尾添加一个新元素;train_loss/train_loader.__len__()计算每一个样本的平均loss值
plt_train_acc.append(train_acc/train_loader.dataset.__len__()) #预测对的数量除以总长等于准确率
if semi_loader!=None: #倘若某次semi_loader不为空,开始训练里面的数据
for batch_x,batch_y in semi_loader:
x,target=batch_x.to(device),batch_y.to(device) #将函数放置GPU计算
pred=model(x) #利用已经定义好的类,得到预测值
semi_bat_loss=loss(pred,target,model) #loss值为一批的平均值
semi_bat_loss.backward #梯度回传
optimizer.step() #更新模型
optimizer.zero_grad() #梯度清零
semi_loss+=train_bat_loss.cpu().item()
semi_acc+=np.sum(np.argmax(pred.detach().cpu().numpy(),axis=1)==target.cpu().numpy()) #.detach()从计算图中分离张量pred;.numpy()将张量转换为数组,便于使用NumPy的函数进行后续计算;np.argmax()返回沿指定轴的最大值索引;np.sum()用于对布尔数组求和,True会被当作1,False当作0;这段代码用于计算当前批次中模型预测正确的样本数量
print("半监督数据集的训练准确率为:",semi_acc/semi_loader.dataset.__len__())
model.eval() #模型调整为验证模式
with torch.no_grad(): #停止梯度计算
for batch_x,batch_y in val_loader:
x,target=batch_x.to(device),batch_y.to(device)
pred=model(x)
val_bat_loss=loss(pred,target,model)
val_loss+=val_bat_loss.cpu().item()
val_acc+=np.sum(np.argmax(pred.detach().cpu().numpy(),axis=1)==target.cpu().numpy())
plt_val_loss.append(val_bat_loss/val_loader.__len__())
plt_acc.append(val_acc/val_loader.dataset.__len__())
if epoch%5==0 and plt_val_acc[-1]>0.7: #若模型已经训练到一定效果,可以开始使用无标签数据集
semi_loader=get_semi_loader(no_label_loader,model,device,thres)
if val_acc>max_acc: #判断模型是否是最优
torch.save(model,save.path) #保存当前模型
max_acc=val_acc
print("[%03d/%03d] %2.2f sec(s) Trainloss:%.6f |valloss:%.6f Trainacc:%.6f |valacc:%.6f" %
(epoch,epochs,time.time()-start_time,plt_train_loss[-1],plt_val_loss[-1],plt_train_acc[-1],plt_val_acc[-1])) #%后面直接跟随元组参数
plt.plot(plt_train_loss) #画图
plt.plot(plt_val_loss)
plt.title("loss图") #显示标题
plt.legend["train","val"] #显示图例
plt.plot(plt_train_acc) #画图
plt.plot(plt_val_acc)
plt.title("acc图") #显示标题
plt.legend["train","val"] #显示图例
###数据与超参数
train_path=r" " #文件路径。r用于禁用字符串中反斜杠\的转义功能,仅作为普通字符存在
val_path=r" "
no_label_path=r" "
train_set=food_Dataset(train_path,"train")
val_set=food_Dataset(val_path,"val")
no_label_set=food_Dataset(no_label_path,"semi")
train_loader=DataLoader(train_set,batch_size=4,shuffle=True) #数据批处理并打乱数据
val_loader=DataLoader(val_set,batch_size=4,shuffle=True)
no_label_loader=DaraLoader(no_label_set,batch_size=4,shuffle=False)
lr=0.001 #学习率
loss=nn.CrossEntropyLoss() #交叉熵损失,自带Softmax操作
optimizer=torch.optim.AdamW(model.parameters(),lr=lr,weight_decay=1e-4)
device="cuda" if torch.cuda.is_available() else"cpu"
save_path="model_save/best_model.pth"
epochs=20
thres=0.7
train_val(model,train_loader,val_loader,no_label_loader,device,epochs,optimizer,loss,thres,save_path)初始化模型代码,可以引入经典模型
#传入模型名字,和分类数, 返回你想要的模型
def initialize_model(model_name, num_classes, linear_prob=False, use_pretrained=True):
# 初始化将在此if语句中设置的这些变量。
# 每个变量都是模型特定的。
# linear_prob为线性探测,即不改变预训练参数;与之相反称为微调,即在新的数据集上继续训练
model_ft = None
input_size = 0
if model_name =="MyModel":
if use_pretrained == True:
model_ft = torch.load('model_save/MyModel')
else:
model_ft = MyModel(num_classes)
input_size = 224
elif model_name == "resnet18":
""" Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained) # 从网络下载模型 pretrain true 使用参数和架构, false 仅使用架构。
set_parameter_requires_grad(model_ft, linear_prob) # 是否为线性探测,线性探测: 固定特征提取器不训练。
num_ftrs = model_ft.fc.in_features #分类头的输入维度
model_ft.fc = nn.Linear(num_ftrs, num_classes) # 删掉原来分类头, 更改最后一层为想要的分类数的分类头。
input_size = 224
elif model_name == "resnet50":
""" Resnet50
"""
model_ft = models.resnet50(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "googlenet":
""" googlenet
"""
model_ft = models.googlenet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
# 处理辅助网络
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# 处理主要网络
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model_utils name, exiting...")
exit()
return model_ft, input_size
使用官方数据集
from torchvision.datasets import FashionMNIST
train_set=FashionMNIST(root="FashionMnist",train=True,download=False,transform=train_transform)
"""
FashionMNIST 包含 10 个类别的灰度图像(尺寸 28×28),类别包括:T 恤、裤子、套衫、连衣裙、外套、凉鞋、衬衫、运动鞋、包、短靴。
"""
"""
root="FashionMnist"指定数据集的存储路径(本地文件夹)。
train=True表示加载的是训练集(包含 60,000 个样本)。
download=False表示不自动下载数据集.若首次使用该数据集,需改为download=True
transform=train_transform指定对数据进行的预处理操作(如缩放、归一化、数据增强等)。
"""
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)