IEEE TIE期刊论文学习——基于元学习与小样本重训练的锂离子电池健康状态估计方法
Hi,大家好,我是半亩花海。现对领域内一篇SCI一区TOP期刊论文进行阅读,文献记录如下。本文提出一种基于元学习与并行TCN-Transformer架构的锂离子电池健康状态(SOH)估计方法。针对传统方法依赖大规模数据、跨工况适应性差的问题,该方法通过:1)从随机充电片段提取容量增量特征;2)构建并行网络同步捕捉局部与全局老化特征;3)采用MAML元学习实现小样本快速适配。实验表明,在温度、电流变
Hi,大家好,我是半亩花海。现对领域内一篇SCI一区TOP期刊论文进行阅读,文献记录如下。本文提出一种基于元学习与并行TCN-Transformer架构的锂离子电池健康状态(SOH)估计方法。针对传统方法依赖大规模数据、跨工况适应性差的问题,该方法通过:1)从随机充电片段提取容量增量特征;2)构建并行网络同步捕捉局部与全局老化特征;3)采用MAML元学习实现小样本快速适配。实验表明,在温度、电流变化及不同电池材料下,仅需10%目标数据即可实现SOH误差<3%,数据需求减少50%。该方法显著提升了BMS在实际复杂工况中的适应性,为电池健康管理提供了高效解决方案。未来将拓展至变放电条件及电池组场景研究。
目录
本篇期刊论文的具体信息如下:
- 引用信息:Shu X, Yang H, Chen Z, et al. Meta Learning Based State of Health Estimation of Lithium-Ion Batteries With Small Sampling Retraining[J]. IEEE Transactions on Industrial Electronics, 2025.
- DOI:10.1109/TIE.2025.3613630
一、背景/痛点——解决方法
(1)传统机器学习局限性
传统机器学习方法高度依赖大规模离线测试数据集,耗时又费资源——引入迁移学习实现跨数据集的知识共享 [CNN+迁移学习,variable-length LSTM (Var-LSTM)+迁移学习]。
(2)迁移学习局限性(解决迁移学习的局限性):
- 当目标任务与源任务高度相似时,迁移学习效果显著提升;而数据分布差异过大则会导致负迁移现象,从而降低预测精度;
- 仍依赖大规模源数据集,这可能限制跨环境(如温度、充电电流变化)应用中目标任务的适应性和泛化能力;
- 电池在实际应用中常面临温度波动、充电电流差异等复杂工况以及不同电池类型变化,现有方法多在统一充电条件下训练验证,难以适应这些变化,导致特征提取和算法设计复杂化,影响状态估计的准确性。
——减少对大型数据集的依赖,开发能够快速适应多样化运行条件和新任务的模型(模型跨场景适配)。
二、具体方法与创新点
1. 方法
本研究提出一种融合元学习与Transformer-TCN并行架构的电池SOH融合估计方法。
具体而言:通过(1)提取多段充电过程中的容量增量序列作为健康特征,表征电池退化状态并解决随机充电行为带来的复杂性。随后(2)构建并行混合网络,将时间卷积网络与增强注意力机制的Transformer相结合,捕捉健康特征中的局部与全局信息,实现精准的SOH预测。通过(3)梯度学习优化混合网络的初始化参数,使系统能快速适应新任务,并(4)在小样本重训练下实现稳健的估计算法。通过(5)在不同温度、充电电流及多种电池类型下的实验验证表明,所提出的方法实现了精确的电池SOH估计,最大误差低于3%,同时将训练数据需求减少50%,充分彰显其高效性与实用性。
【元学习是一种自适应学习方法,通过利用先前任务的已有知识和经验来应对新任务(元学习的核心)。其核心原理在于训练过程中识别不同任务间的共性模式与结构,使模型在面对全新挑战时,仅需少量数据和梯度更新即可实现快速收敛与高性能表现。】
2. 创新点
(1)该方法不依赖完整或固定的充电电压范围,而是从随机充电片段中提取容量增量(△Q)作为健康特征,更贴合实际充电行为的变异性与随机性;
(2)提出结合Transformer与时间卷积网络(TCN)的并行架构,同步捕捉局部与全局模式,有效建模锂离子电池的非线性老化特性;
(3)将元学习融入并行网络,显著提升算法对新电池数据的泛化能力,将新电池训练数据需求从70%降至20%。
三、实验与健康特征提取
1. 电池老化试验
(1)实验条件
实验中,三节镍锰钴(NMC)电池(每节容量5Ah,标称电压3.65V)在不同环境温度和充电电流条件下进行循环测试。实验前,将电池置于10℃、25℃和40℃的温控箱中,以稳定其内部温度和工作温度。每个温度循环测试采用恒流恒压(CC-CV)充电策略,直至端电压达到4.2V且电流降至0.02C的截止电流。三节电池的CC充电电流分别设定为0.5C、1.5C和1.5C。经过5分钟静置后,采用2C电流的CC放电模式对电池进行放电,直至端电压降至2.75V。
(2)容量校准与老化规律验证
- 容量校准:为保证SOH计算的准确性,每20个充放电循环进行一次容量校准——在室温下以0.5C恒流充电至4.2 V(减少热效应影响),再以1C恒流放电至截止电压(模拟实际使用工况),符合电池厂商提供的标准测试协议。
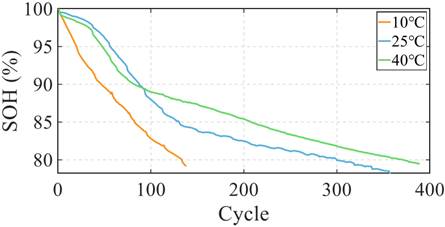
- 老化规律呈现:不同温度下电池的SOH降解轨迹存在显著差异,10℃时因电解液粘度升高、离子传输受阻,电池老化最快;40℃时离子电导率提升使 SEI 膜快速稳定,初期老化速率较慢;25℃下电池衰减趋势最平稳,这些规律均通过图2清晰展示,如图2所示。
2. 健康特征提取
(1)特征提取思路与方法
针对实际场景中用户充电行为的随机性(如未充满、充电起点不固定(比如0%~100% / 30%~80%)),摒弃传统依赖“完整充电曲线”的特征提取方式,转而从随机充电片段中挖掘健康特征,提升方法的实用性。
首先将恒流充电曲线(Q(V)曲线)按电压区间ΔV(Vstart~Vstop)、切片步长S分割为多个大段,再将每个大段细分为m个小段;对每个小段,按ΔV/m的电压间隔采集充电容量值,通过“当前容量减去该段初始容量”计算容量增量ΔQ,形成容量增量序列[ΔQ1, ΔQ2,…, ΔQm]作为健康特征,该提取流程的示意图如图3(a)所示。
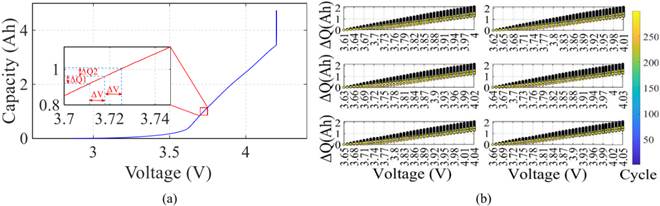
【我的理解:图3(b)可能是作者举了一个例子展现特征情况,如第一个子图所示,初始电压为3.61V、ΔV=0.1V、S=0.1V,m=10(10个细小间隔),每个电压值对应的ΔQ代表以Vi为起点、间隔长度为0.01V的小段区间的ΔQ;比如恒流充电范围终止电压到4.2V,那么可分为3.61~3.71,3.71~3.81,3.81~3.91,3.91~4.01,4.01~4.11这样的5个窗口,每个窗口再细分10小段,每小段间隔长度为0.01V,此时这个循环一共有5×10=50个特征值。】
(2)特征有效性验证
以25℃下的老化电池为例,设置初始电压3.6 V、ΔV=0.1V、S=0.1V进行特征提取,结果显示:随着电池循环次数增加(老化程度加深),各充电段的容量增量ΔQ呈明显下降趋势,能直观区分不同老化状态的电池,如图3(b)所示。
定量验证:计算10℃、25℃、40℃下容量增量序列与SOH的皮尔逊相关系数,结果均高于0.98,证明该特征与电池老化状态存在强线性关联;同时,随机分割策略适配了用户不规则的充电习惯,进一步验证了该特征在实际应用中的适用性。
四、网络架构
本文提出的电池SOH估计方法框架如图4所示,该框架通过并行TCN-Transformer架构与元学习相结合,有效应对温度变化和充电电流波动的影响。具体实验流程如下:
1. 数据处理
对原始循环数据进行处理,提取容量增量特征作为模型输入。
2. 任务分类
这些特征根据不同温度条件被划分为多个任务模块(10℃、25℃、40℃三种温度对应三个任务,两个任务作为源域,一个任务作为目标域),每个任务模块又分为支持集和查询集。
3. 并行网络构建
(1)TCN支路(捕捉局部特征)
TCN 模块的核心功能是捕捉电池健康特征中的局部时序模式(如某一充电片段内的容量增量波动),为后续全局特征融合提供细粒度基础信息。
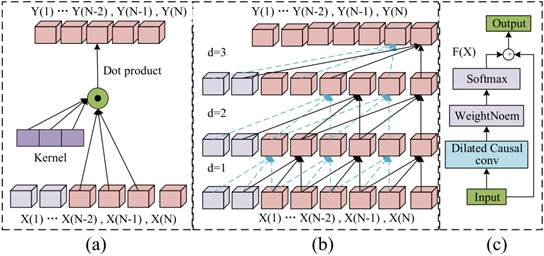
核心结构与功能如图5所示,TCN的核心组件包括因果卷积、扩张卷积与残差连接:
- 因果卷积:确保网络输出仅依赖当前及历史时刻的输入特征,避免“未来信息泄露”,完全贴合充电容量序列的时序特性(充电过程不可逆,后续数据无法影响前期特征);
- 扩张卷积:通过在卷积核中设置间隙,在不增加模型参数与计算量的前提下,显著扩大特征感受野,能精准捕捉短周期内“电压-容量”的关联变化(如某一电压区间内的容量增量细微波动);
- 残差连接:通过“输入特征直接叠加卷积层输出”的设计,缓解深层网络训练中的梯度消失问题,让TCN能稳定学习到电池老化的局部细微特征。
相比传统循环神经网络(RNN/LSTM),TCN支持卷积操作并行化,大幅提升时序特征处理效率;同时,其对局部细节的捕捉能力更强,能有效提取充电片段中与电池老化直接相关的局部特征(如某一电压段容量增量的下降趋势),为SOH估计提供精准的“局部证据”。
(2)Transformer支路(利用自注意力机制(Self-Attention),捕捉全局依赖)
Transformer模块的核心功能是捕捉健康特征中的全局依赖关系(如不同循环次数、不同充电片段间的容量衰减规律),与TCN形成“局部-全局”特征互补。
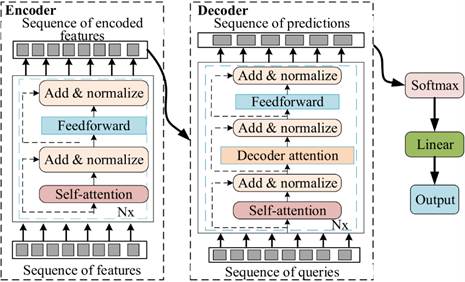
核心结构与功能如图6所示,Transformer的核心组件包括编码器、自注意力机制、位置编码与全连接层:
- 自注意力机制:通过计算“查询(Q)-键(K)-值(V)”之间的相似度,自动量化不同充电片段特征的重要性(如第50次循环与第100次循环的容量增量关联度),让模型聚焦对SOH影响更大的关键特征;
- 多注意力头设计:多个注意力头并行工作,可同时学习不同维度的全局依赖关系(如“循环次数-容量增量”“电压区间-容量增量”的关联),提升全局特征的全面性;
- 位置编码:通过正弦/余弦函数为输入特征赋予时序信息,弥补Transformer本身“无天然时序感知能力”的缺陷,确保模型能区分“早期循环”与“晚期循环”的特征差异,贴合电池老化的时序性。
相比TCN的“局部聚焦”,Transformer能跨循环、跨充电片段挖掘全局老化规律(如“随着循环次数增加,所有电压区间的容量增量均呈下降趋势”);同时,其并行处理机制对长序列数据的适配性更强,能高效处理多循环、多片段的健康特征,为SOH估计提供“全局视角”。
(3)并行网络(拼接两个支路的输出,最后通过全连接层(fc)输出SOH预测值)
传统方法中TCN与Transformer多采用串行连接(如“TCN提取局部特征→Transformer再处理全局特征”),易导致“局部特征被全局特征覆盖”“信息传递延迟(latency)高”的问题,因此本文设计并行架构实现特征协同提取。
并行架构设计逻辑如图4所示,并行网络的核心是让TCN与Transformer独立处理同一健康特征输入,具体流程为:
- 特征输入:将提取的容量增量序列(features)同时输入TCN与Transformer分支;
- 独立特征提取:TCN分支专注捕捉局部时序模式,Transformer分支专注挖掘全局依赖关系,两分支并行计算,互不干扰;
- 特征融合:将两分支输出的特征向量直接拼接,再通过线性变换将高维拼接特征投影为统一维度的融合特征,最终输入全连接层输出SOH估计值。
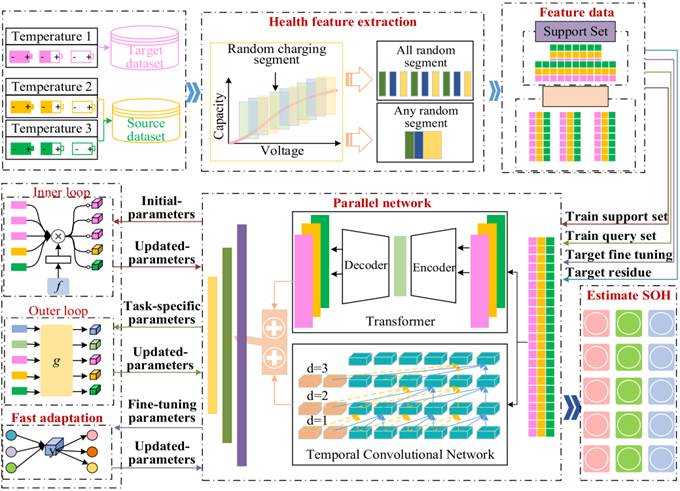
4. 元学习(内外循环)
(1)介绍
元学习的核心功能是解决“小样本适配”问题——让模型利用过往任务(如某一温度、某一电池类型的SOH估计)的知识,仅用少量目标任务(如新温度、新电池类型)数据快速调整,本文采用模型无关元学习(MAML)框架融入并行网络。MAML核心原理与框架适配如图4所示,元学习通过“双层优化”对并行网络的初始参数进行优化。
(2)关键概念定义
- 任务(Task):一种具体的工况,比如“10℃下的SOH估计”就是一个任务。我的第一个数据集有三个任务:10℃、25℃、40℃(其中,两个作为源域训练,一个作为目标域测试)。
- 支持集(Support Set):每个任务里的少量已知数据(比如目标电池的前10%老化循环数据+对应的真实SOH标签)。用于“快速微调”模型。
- 查询集(Query Set):每个任务里的另外一部分数据(剩余的循环数据+SOH标签),不用于微调,只用于评估/计算损失。
- 内循环(Inner Loop):针对单个任务的快速学习过程。用支持集做几步(通常1-5步)梯度下降,得到任务专属的模型参数(从初始θ变成θi)。
- 外循环(Outer Loop):针对很多任务的元优化过程。看内循环后的模型在查询集上表现如何,然后调整共享的初始参数θ,让下次遇到新任务时初始点更好。
(3)MAML训练流程(Meta-Training)
训练时,同时处理多个任务(比如一批batch里有几个不同温度的任务)。假设我们用10℃和25℃做训练(源域),目标是让模型学会怎么适应未来可能的40℃(目标域)。
①采样一批任务(meta-batch)
- 比如采样3个任务:任务A(10℃)、任务B(25℃)、任务C(40℃)。
- 每个任务都有自己的支持集(support)和查询集(query)。
②对于单个任务,做内循环(任务级快速适应)
- 当前模型的共享初始参数是θ(全局的,好比“通用起点”)。
- 用这个任务的支持集计算损失L_support(θ)。
- 做几步梯度下降,参数更新为:θi= θ – α*∇L_support(θ)(α是内循环学习率,小步快调)。
- 现在得到一个自适应模型θi,它已经“微调”适应了比如10℃这个任务的温度特性。
③此时仍在内循环,用查询集评估这个临时模型的表现
- 在自适应模型θi上跑查询集,计算损失L_query(θi)。
- 这个损失代表:“用支持集快速学了几步后,在剩余数据上还能预测多准?”。
- 如果L_query很大,说明初始θ不够好(适应后还差很多)
④外循环:元优化,更新初始参数θ
- 把所有任务的L_query(θi)加起来(或平均)。
- 计算这个总损失对原始θ的梯度:∇_θ[sum L_query(θi)]。【注意:这个梯度是通过内循环链式传播过来的(二阶梯度,很贵,但能学到好的初始化)】
- 用外循环学习率β更新:θ'←θ-β*∇_θ[sum L_query]。
- 结果:θ变得更好——下次遇到新任务,从这个θ开始,只需很少支持集就能快速达到高精度。
⑤重复以上过程,遍历很多epoch,直到θ收敛。
(4)测试阶段(Meta-Testing)
- 给你一个全新任务(比如45℃,从来没见过)。
- 你只有少量数据:支持集(几条循环的容量增量特征+SOH标签)。
- 从训练好的初始参数θ开始,用支持集做内循环(几步梯度下降),得到适应后的θi。
- 然后直接用θi在查询集(剩余数据,无标签或有标签验证)上预测SOH。
- 因为θ已经被元学习优化过,所以几步就适应得很好,预测准。
五、实验验证与讨论
1. 超参数调优
(1)超参数优化目标与方法
为确保模型性能最优,研究通过单变量敏感性分析确定关键超参数——即独立调整某一超参数、固定其他参数为初始值,观察其对平均绝对误差(MAE)、平均绝对误差(AAE)、均方根误差(RMSE)的影响,最终筛选出最优参数组合,分析结果汇总于表I中。
表 I 超参数调优的单变量扫描结果
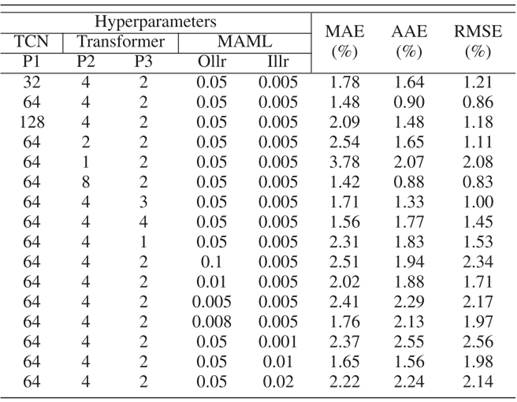
(2)核心超参数最优值与影响分析
- TCN隐藏层维度:对模型性能影响最显著,设置为64时效果最佳——降至32会导致特征提取不充分(MAE=1.78%),升至128则引发过拟合(MAE=2.09%),只有64能在精度与过拟合风险间达到平衡;
- Transformer参数:注意力头数设为4、编码器层数设为2最优——头数增至8虽能小幅降低误差(MAE=1.42%),但会显著提升计算复杂度;层数少于2时特征捕捉能力不足(1层时MAE=2.31%),多于2层则精度提升有限(3层时MAE=1.71%);
- MAML学习率:外循环学习率0.05、内循环学习率0.005最稳定——任一学习率偏离该值(如外循环0.1或内循环0.001),都会导致训练波动加剧,MAE最高升至2.51%,证明精细调优对模型稳定性的重要性。
2. 与不同算法的对比
(1)对比算法与实验条件
选取4种主流深度学习算法作为对照组:纯Transformer、CNN-LSTM、串行TCN-Transformer、并行TCN-Transformer,以25℃下的电池老化数据为实验对象,从估计曲线趋势、误差波动、定量指标(MAE/RMSE/AAE)三方面对比性能,结果如图7所示。
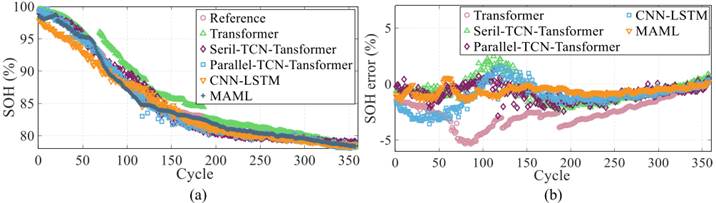
(2)对比结果分析(对比+消融)
- 纯Transformer缺陷:如图7(b)所示,其初期估计误差波动极大(最高达5.3%),原因是缺乏局部特征提取能力,仅依赖自注意力机制难以捕捉电池短期老化波动;
- 串行与并行架构差异:并行TCN-Transformer因能同时提取局部(TCN)与全局(Transformer)特征,相比串行架构的AAE、RMSE分别降低11.6%、12.9%,估计曲线更贴近参考值(如图7(a)中“Parallel-TCN-Transformer”曲线);
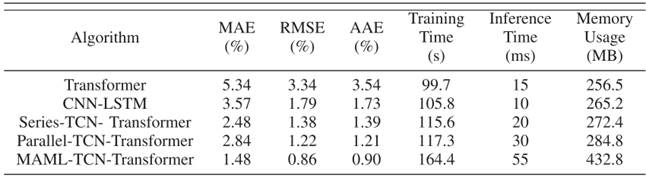
- 融合MAML的优势:本文提出的“MAML-TCN-Transformer”方法性能最优,如图7(b)所示,其估计误差始终控制在2%以内,定量指标上实现RMSE=0.86%、MAE=1.48%、AAE=0.90%(表II),且虽训练时间(164.4s)与推理时间(55ms)略长,但符合SOH“按充放电循环估计”的实际场景,实用性不受影响。
表 II 不同方法的对比结果
3. 不同场景的影响
(1)场景变量与实验设计
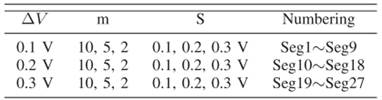
以“电压区间ΔV(0.1/0.2/0.3V)、细分段数m(2/5/10)、切片步长S(0.1/0.2/0.3V)”为变量,设计3×3×3=27种特征提取场景(Seg1~Seg27),如表III所示,验证不同参数组合对SOH估计精度的影响,结果如图8所示。
表 III 不同数据段的组合
(2)关键结论
- 场景鲁棒性:如图8(a)-(c)所示,所有场景下估计曲线均与参考SOH高度吻合,最大误差未超过3%,证明所提方法对特征提取参数的变化具有强适应性;
- 最优参数组合:当ΔV=0.1V、m=5、S=0.3V时,MAE与RMSE最小(分别为0.88%、0.83%),该组合既能减少对完整充电数据的依赖,又能保留足够的老化特征;
- 最差场景边界:当ΔV=0.3V、m=10、S=0.3V时误差最大(MAE=2.57%、RMSE=1.51%),但仍在可接受范围内,如图8(g)-(i)中“Seg27”对应的误差柱所示,进一步验证方法的可靠性。
4. 不同温度下的验证
(1)对比策略与实验设置
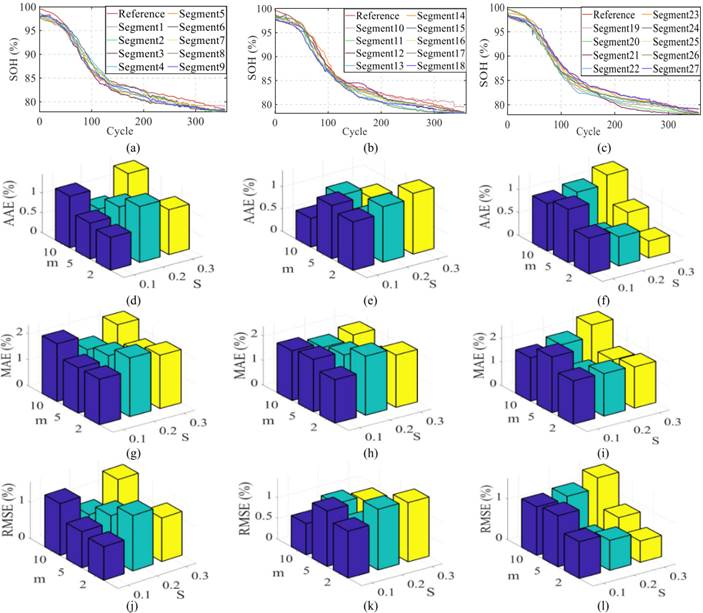
设置两组训练策略:①本文元学习方法(源域预训练+目标域10%数据重训练);②非预训练并行TCN-Transformer(目标域70%数据直接训练)(普通训练--七三开),在10℃、25℃、40℃下测试SOH估计性能,结果如图9所示。
(2)结果解读
- 精度对比:如图9(d)所示,元学习方法在10℃、25℃、40℃下的最大误差分别为2.58%、2.79%、2.14%,与非预训练方法(2.63%、2.95%、2.18%)几乎持平,但数据用量仅为后者的1/7,证明小样本适配的有效性;
- 误差分布:如图9(e)-(f)所示,元学习方法的误差集中在2.0%左右,虽分布略分散于非预训练方法,但无系统性偏差,且在低温(10℃)下仍能稳定跟踪SOH衰减(如图9(a)中“MAML”曲线),凸显跨温度适应性;
- 数据量阈值:如图9(g)-(i)所示,当重训练数据从5%增至10%时,MAE从3.63%(10℃)降至2.58%,RMSE从1.64%降至1.22%;但数据量超过10%后,误差下降幅度不足5%,因此10%是“数据效率-精度”的最优平衡点。
5. 不同电池材料的验证
(1)跨材料实验设计
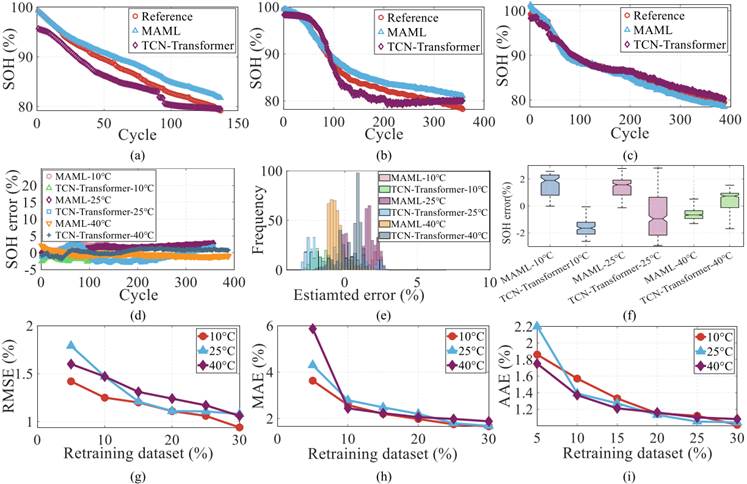
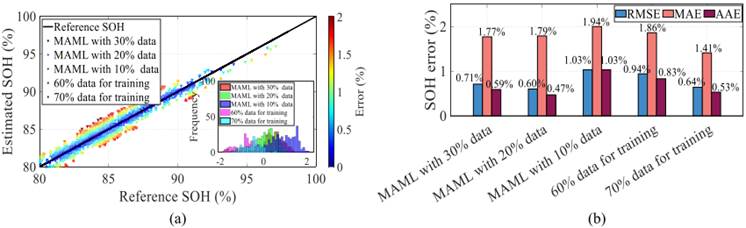
以锂钴氧(LiCoO2)电池为测试对象(与训练用NMC电池化学体系不同),其充放电电流(0.55/1A、室温)与预训练数据(10℃、5/10A)差异显著;设置3种重训练数据量(10%/20%/30%),并与“70%数据训练的并行TCN-Transformer”对比,同时引入CALCE数据集(40%-100%SOC循环)验证部分充电场景性能,结果如图10、图11所示。
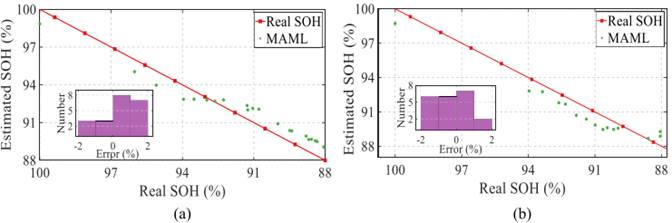
(2)发现
- 跨材料泛化性:如图10(b)所示,用20%LiCoO2数据重训练时,MAE=1.79%、RMSE=0.60%,仅比70%数据训练的结果(MAE=1.41%、RMSE=0.64%)略差,数据需求减少50%;且误差频率集中在0附近(如图10(a)的误差分布直方图),证明方法对不同化学体系电池的适配性;
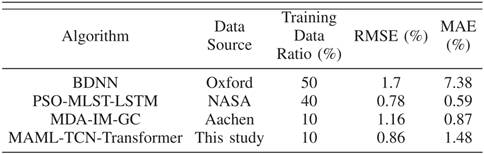
- 与现有方法对比:相比BDNN、PSO-MLST-LSTM等方法(表IV),本文方法在数据量减少40%-30%的同时,RMSE降低25.86%以上,且对异常值的鲁棒性更强(更低RMSE);
表 IV 不同方法的对比结果
- 部分SOC场景适配:如图11所示,对CALCE数据集中“40%-100%SOC循环”的电池,用20%数据重训练后,估计SOH与真实值的最大误差<2%,误差分布对称且无偏,证明方法能适配实际中“非满充满放”的使用场景。
六、讨论与局限性
(1)方法设计逻辑
- 双挑战应对:元学习(MAML)通过双层优化解决“跨工况数据分布不均”问题——找到对任务变化敏感的初始参数,实现小样本快速适配;TCN-Transformer并行架构则解决“电池老化时序依赖”问题——TCN捕捉短期容量波动,Transformer挖掘长期衰减趋势,二者结合符合电池老化的物理本质(如SEI膜平稳生长与锂沉积突发波动);
- 实际价值:相比传统方法,本文方法将离线测试周期缩短50%,且无需完整充电数据,更贴近电动汽车BMS的实际应用需求。
(2)现有局限性与未来方向
- 元学习算法单一:未对比Reptile、ProtoNet等其他元学习方法,未来需验证不同元学习框架对SOH估计性能的影响;
- 特征提取缺陷:若充电过程未覆盖任何电压分割段,则无法提取特征,后续需细化电压分割(如减小区间),或融合“部分电压重构完整曲线”的技术;
- 放电条件简化:当前实验假设放电电流恒定,未来需纳入变放电电流、脉冲放电等复杂实际工况;
- 电池组适配不足:未考虑电池组内单体不一致性,后续需研究组级SOH估计方法。
七、总结
本研究提出了一种基于并行时间卷积网络(TCN)-Transformer架构的元学习方法,结合模型无关元学习(MAML),用于多工况下锂离子电池的健康状态(SOH)估计。该方法旨在解决数据变异性与小样本估计难题,为不同类型电池及多运行条件下的SOH精准估计提供了稳健方案。具体而言,研究采用TCN与Transformer相结合的并行架构,强化了跨环境下可迁移关键特征的提取能力;其中,预训练阶段提升了网络的泛化能力,而重训练则确保了小样本场景下SOH的精准估计。通过与Transformer、串行TCN-Transformer、串行CNN-LSTM等主流架构的对比分析,本方法的显著优势得到充分体现:在环境温度与充电电流双重变化的工况下,仅需使用目标电池老化数据的10%,即可实现稳健的SOH估计,且估计误差低于3%。此外,将该方法应用于不同化学体系的电池时,其性能显著优于未预训练的并行TCN-Transformer架构,在均方根误差(RMSE)、平均绝对误差(MAE)与平均绝对误差(AAE)方面分别提升了70.86%、61.52%和74.65%。同时,该方法将离线测试数据需求降低了50%,表明元学习框架能有效缩短电池测试周期。这些研究结果充分证明,所提元学习框架在多场景SOH估计中具有优异效果,凸显了其在实际电池管理系统(BMS)中的应用潜力。
尽管所提方法在不同温度与充电电流条件下均实现了SOH的精准估计,但该方法假设所有实验设置下放电电流保持恒定。未来研究将重点纳入复杂实际放电条件对电池SOH的影响;此外,解决电池组内单体电池一致性差异对SOH估计的影响,也将是未来研究的关键方向。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)