window平台使用lama_factory Qlora微调qwen2.5-3B-instruct实践
·
文章目录
推荐大佬文章
环境说明
- OS:window 10
- GPU:3090 24G
- CUDA Version: 13.0
- nvcc:13.0
- llama_factory:0.9.3
- python:3.11
- torch:2.4.0
- model:
Qwen2.5-3B-Instruct
- 如果本地环境无法满足,可以使用租用在线机器优云智算
训练环境搭建和模型下载
- 使用anaconda创建虚拟环境,安装依赖
conda create -n llama_factory python=3.11 conda activate llama_factory conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia - 下载llama_factory项目源代码到本地,或者手动下载https://github.com/hiyouga/LLaMA-Factory
git clone https://github.com/hiyouga/LLaMA-Factory.git - 进入项目目录,安装依赖
cd C:\code\LLaMA-Factory pip install -r requirements.txt pip install -e ".[torch,metrics]"
- 需完整功能(包括量化支持),建议安装扩展依赖
pip install -e ".[torch,metrics,deepspeed,liger-kernel,bitsandbytes]"
- 如果需要使用tensorborad查看训练过程,可以顺便将依赖安装
pip install tensorFlow pip install tensorboard pip install tf-keras - 安装modelscope,并下载qwen2.5-3B-instruct模型文件(建议提前创建
../models/Qwen2.5-3B-Instruct文件夹)pip install modelscope modelscope download --model Qwen/Qwen2.5-3B-Instruct --local_dir ../models/Qwen2.5-3B-Instruct - 启动llama_factory
llamafactory-cli webui
数据集下载和处理
- 打开BAAI/IndustryInstruction_Travel-Geography,直接点击下载训练和验证数据集内容。

- 创建
convert.py,将其放置在数据同目录下
import json
import argparse
def convert_to_sharegpt_format(input_file, output_file, limit):
sharegpt_format = []
with open(input_file, 'r', encoding='utf-8') as file:
for i, line in enumerate(file):
if i >= limit:
break
try:
entry = json.loads(line.strip())
conversation = []
conversations = entry.get("conversations", [])
# 遍历每个交互
for interaction in conversations:
conversation.append({
"from": interaction["from"],
"value": interaction["value"]
})
# 将当前对话添加到最终的格式中
sharegpt_format.append({
"conversations": conversation
})
except json.JSONDecodeError as e:
print(f"Failed to decode JSON on line {i + 1}: {line}")
print(e)
with open(output_file, 'w', encoding='utf-8') as output_file_handle:
json.dump(sharegpt_format, output_file_handle, ensure_ascii=False, indent=4)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Convert given .jsonl data to ShareGPT format and specify the number of entries to process.")
parser.add_argument("input_file", type=str, help="Path to the input .jsonl file")
parser.add_argument("output_file", type=str, help="Path to the output JSON file")
parser.add_argument("--limit", type=int, default=10000, help="Number of entries to process (default: 10000)")
args = parser.parse_args()
convert_to_sharegpt_format(args.input_file, args.output_file, args.limit)
- 执行python文件,分别将训练集和验证集文件转化为sharegpt格式,方便后续训练使用。
python convert.py industry_instruction_semantic_cluster_dedup_旅游_地理_valid_train.jsonl sharegpt_valid_train_4k.json --limit 4000
python convert.py industry_instruction_semantic_cluster_dedup_旅游_地理_valid_val.jsonl sharegpt_valid_val.json
- 在llama_factory中配置数据文件信息,将转化后的两个文件复制到
llama_factory/data目录下,同时修改dataset_info.json文件,在开头的第一个{下添加即可
"sharegpt_valid_train_4k": {
"file_name": "sharegpt_valid_train_4k.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations"
}
},
"sharegpt_valid_val": {
"file_name": "sharegpt_valid_val.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations"
}
},
训练配置
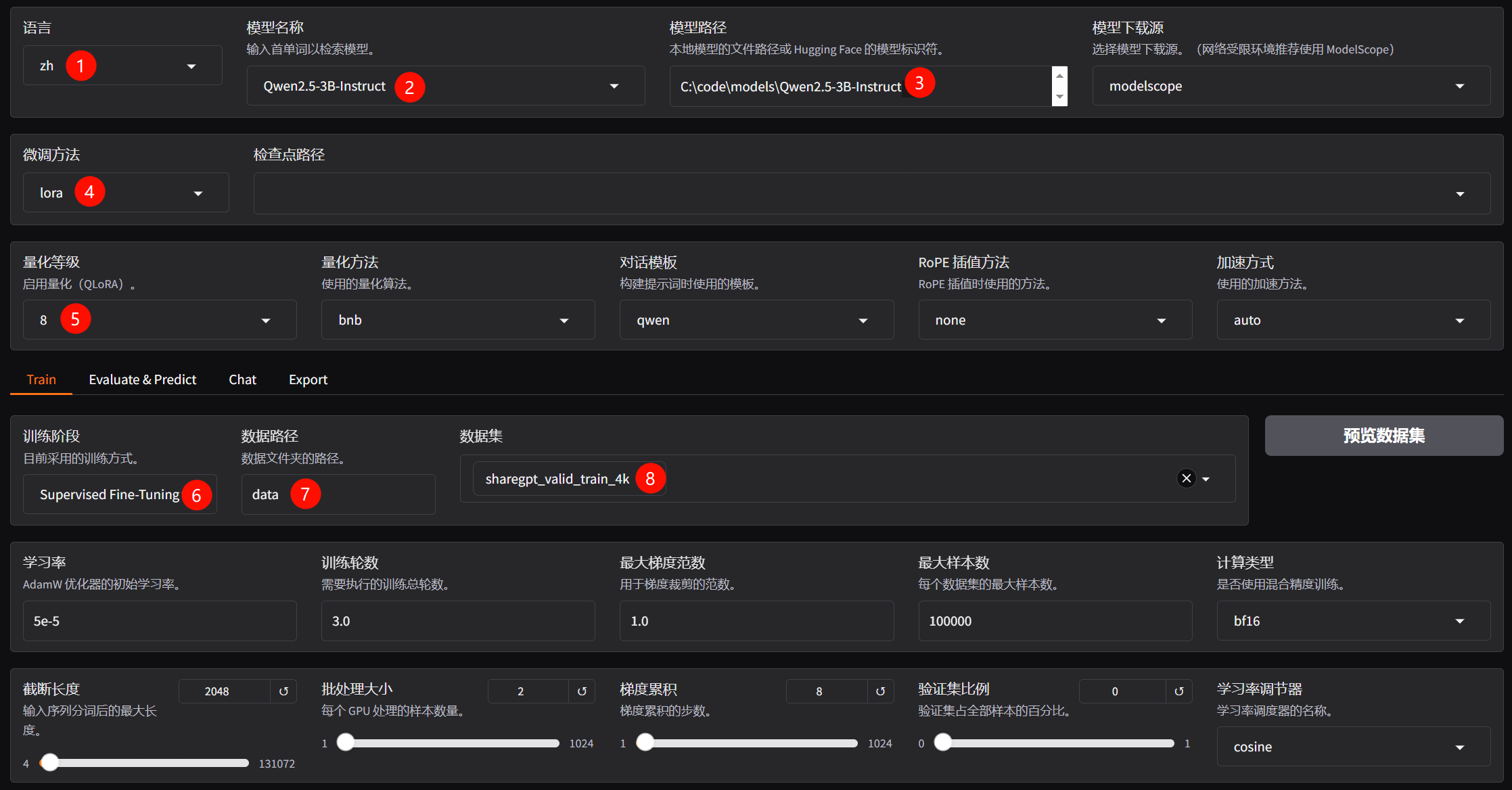
- 训练参数预览
llamafactory-cli train `
--stage sft `
--do_train True `
--model_name_or_path C:\code\models\Qwen2.5-3B-Instruct `
--preprocessing_num_workers 16 `
--finetuning_type lora `
--template qwen `
--flash_attn auto `
--dataset_dir data `
--dataset sharegpt_valid_train_4k `
--cutoff_len 2048 `
--learning_rate 5e-05 `
--num_train_epochs 3.0 `
--max_samples 100000 `
--per_device_train_batch_size 2 `
--gradient_accumulation_steps 8 `
--lr_scheduler_type cosine `
--max_grad_norm 1.0 `
--logging_steps 5 `
--save_steps 100 `
--warmup_steps 0 `
--packing False `
--enable_thinking False `
--report_to tensorboard `
--output_dir saves\Qwen2.5-3B-Instruct\lora\train_2025-11-14-21-32-37 `
--bf16 True `
--plot_loss True `
--trust_remote_code True `
--ddp_timeout 180000000 `
--include_num_input_tokens_seen True `
--optim adamw_torch `
--quantization_bit 8 `
--quantization_method bnb `
--double_quantization True `
--lora_rank 8 `
--lora_alpha 16 `
--lora_dropout 0 `
--lora_target all
- 下图为Qlora int8实际损失函数图像变化。
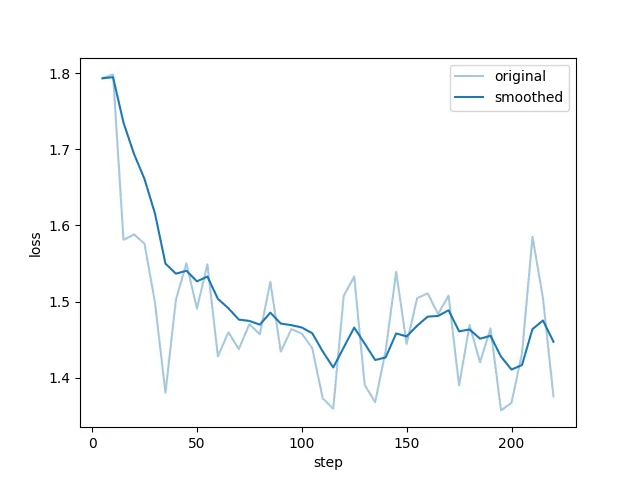

- 未完全训练结束,手动终端,损失函数图像不会,但是如果开启tensorboard记录,即可在预览命令设置的导出目录下,查看训练过程中的具体信息。
tensorboard --logdir runs
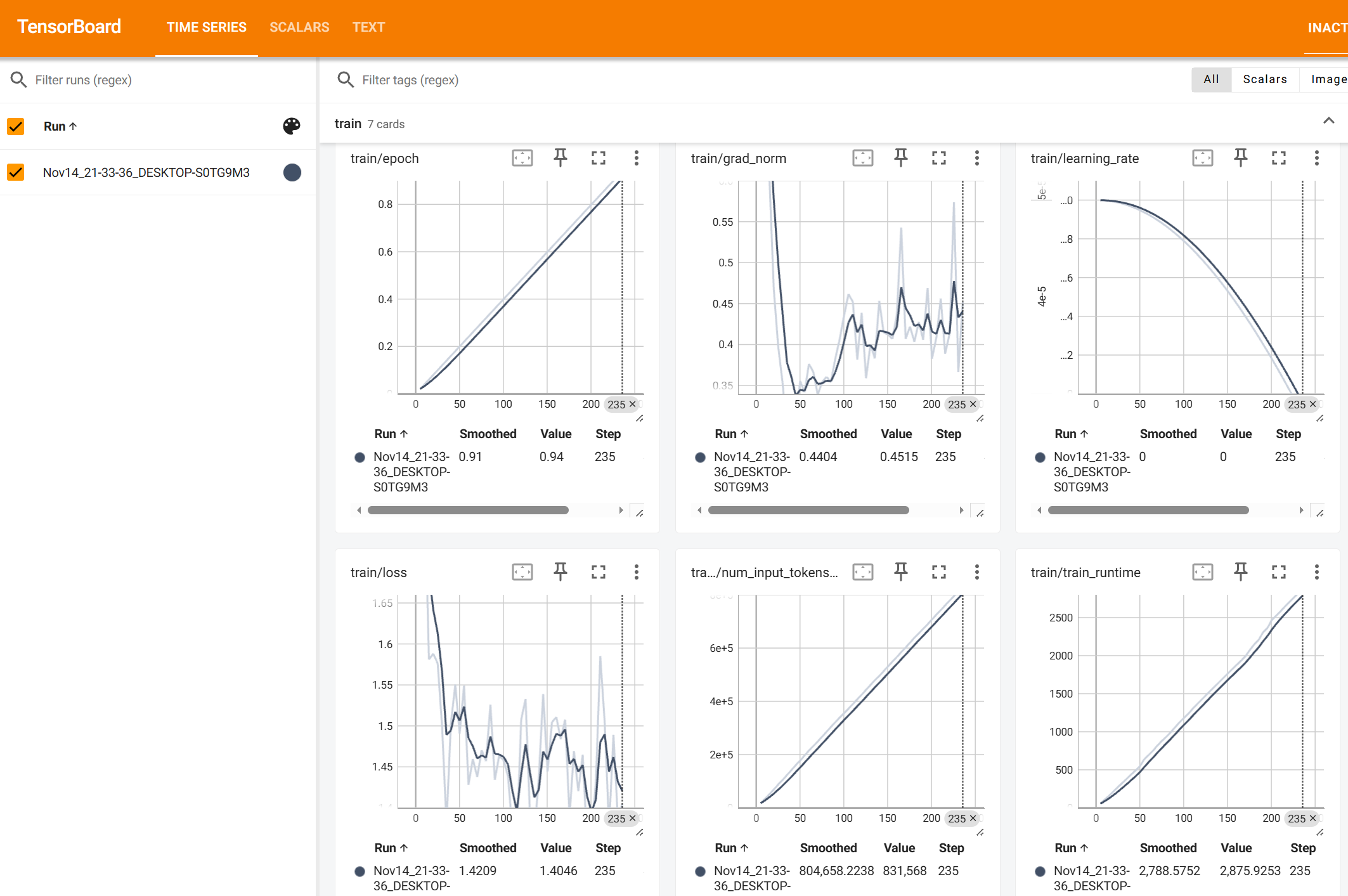
- 完整训练结束后的效果(仅供参考,未Qlora量化下的训练)

完整模型导出(fail)
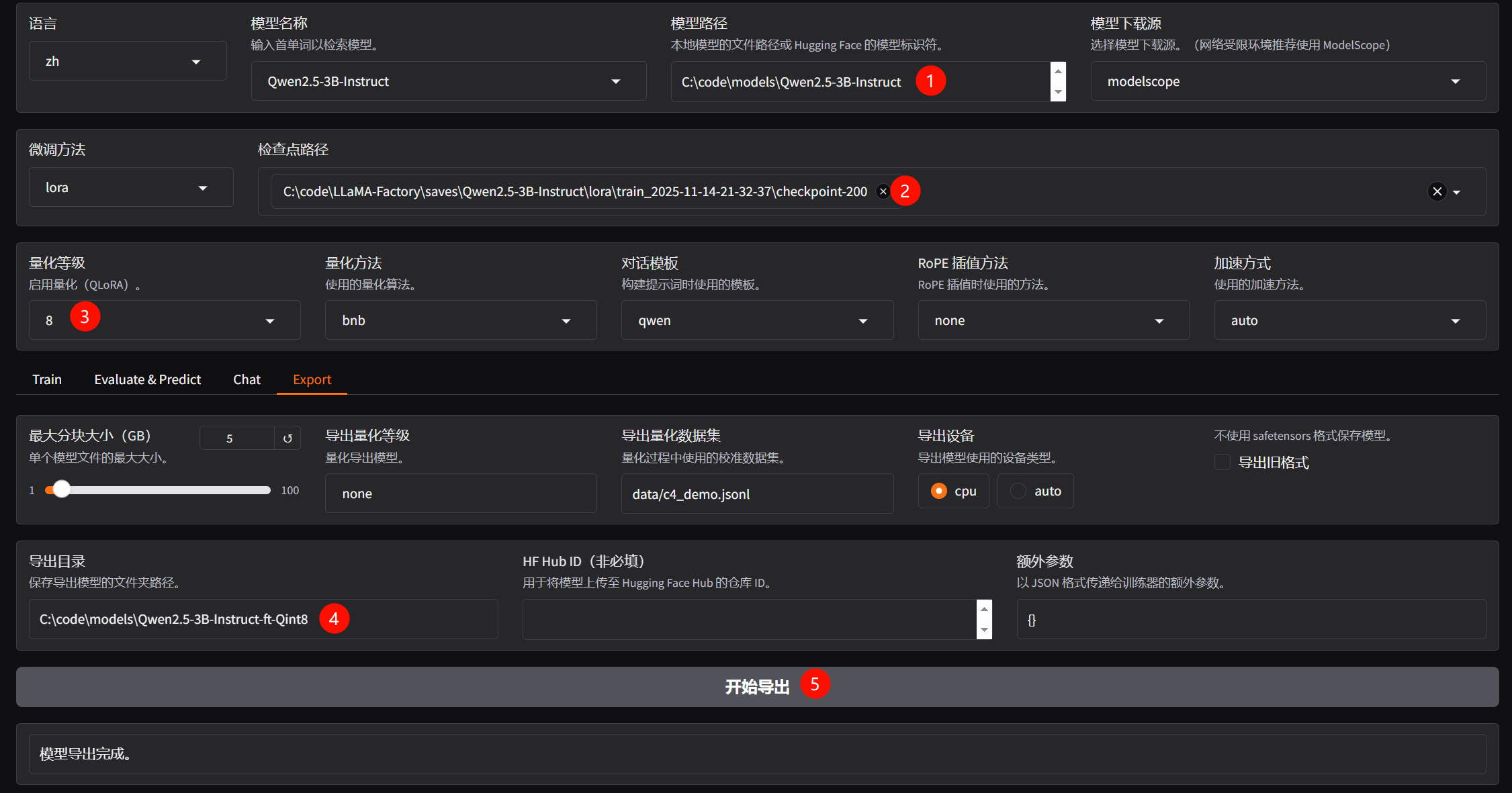
- 注意,这里导出的仍然是未量化的版本,如果需要量化可以使用GPTQModel进行操作。
- 如果需要量化导出,目前的解决方案是使用GPTQModel,有关内容还需要后续深入学习,并非简单的导出。
- GPTQ 是一个后训练量化(Post-Training Quantization)技术。它的目的不是训练,而是部署优化。它接收一个已经训练好的完整模型(也就是您上一步导出的那个模型),然后分析它的权重,将其压缩成更小的体积(比如4位),以便在推理时占用更少的显存,并可能跑得更快。
报错解决和讨论
量化问题报错
ValueError: Calling `to()` is not supported for `4-bit` quantized models with the installed version of bitsandbytes.
The current device is `cuda:0`. If you intended to move the model, please install bitsandbytes >= 0.43.2.
- 如果在window平台使用Qlora量化时,出现报错,大概率是bitsandbytes未安装,在虚拟环境中执行安装命令即可(N卡 GPU环境)。具体支持可参看bitsandbytes github
pip install bitsandbytes python -m bitsandbytes # 执行后出现success即可通过
有趣的现象
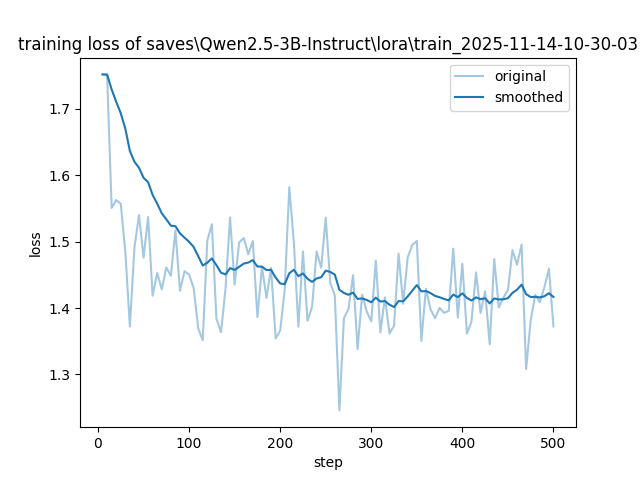
- 使用lora sft微调导出未量化的模型后,再次使用训练集使用Qlora int8进行训练,loss下降缓慢。
- loss异常相关的文章:Qwen14B-Chat-int4 微调loss不收敛、LLaMA-Factory有监督(full/lora)微调Qwen2-1.5B
- 未量化lora微调loss图像
- int8量化lora微调loss图像(未保存下来,使用log日志手动绘制一下),由于直接使用sft的lora训练后,可能模型已经学到了数据集的相关内容,导致loss损失不是很稳定,下降非常缓慢。
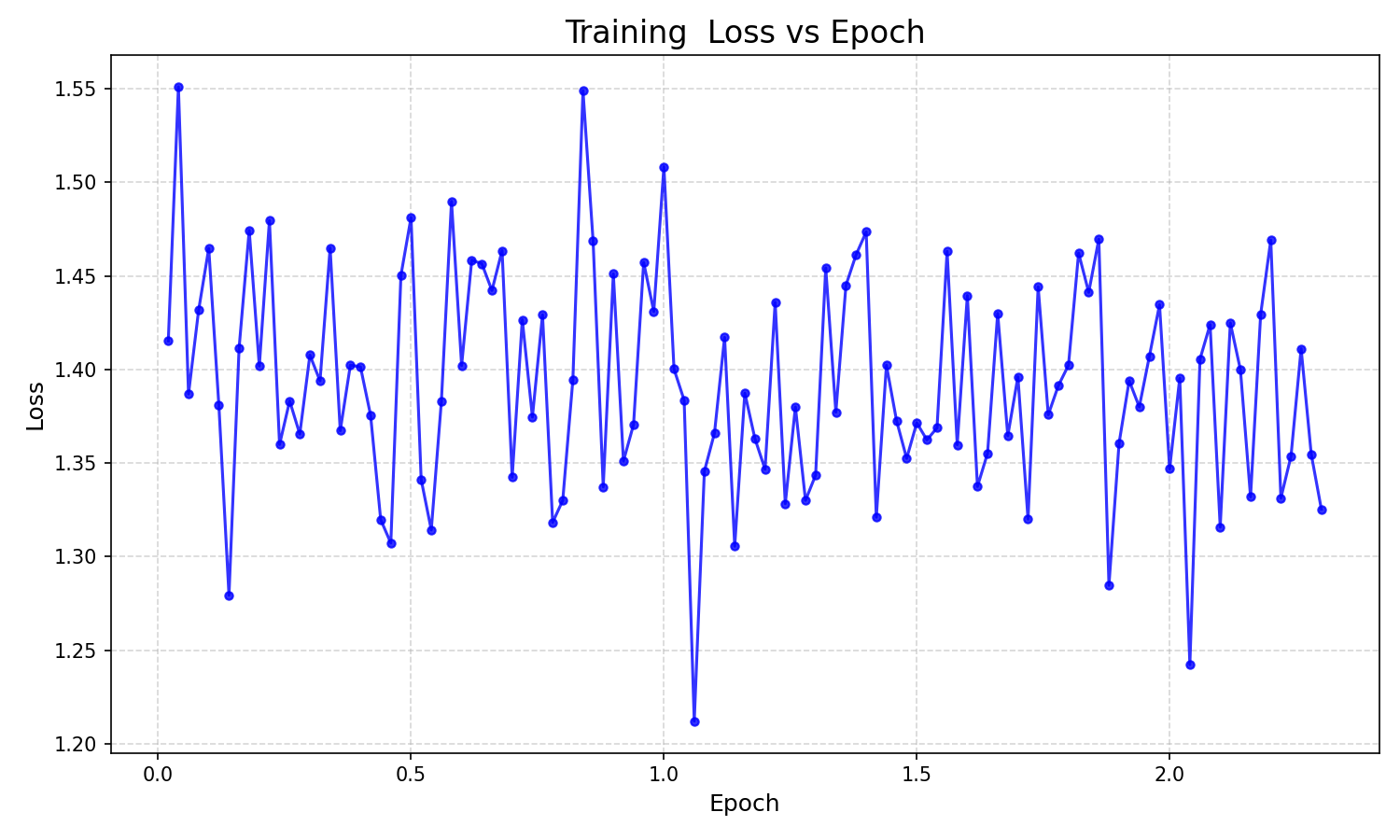
import re
import matplotlib.pyplot as plt
# 日志文件路径(请根据实际情况修改)
log_file = 'running_log.txt'
epochs = []
losses = []
# 正则表达式匹配包含 loss 和 epoch 的行
pattern = r"'loss': ([\d.]+),.*'epoch': ([\d.]+)"
with open(log_file, 'r', encoding='utf-8') as f:
for line in f:
match = re.search(pattern, line)
if match:
loss = float(match.group(1))
epoch = float(match.group(2))
losses.append(loss)
epochs.append(epoch)
# 绘图
plt.figure(figsize=(10, 6))
plt.plot(epochs, losses, marker='o', linestyle='-', color='b', markersize=4, alpha=0.8)
plt.title('Training Loss vs Epoch', fontsize=16)
plt.xlabel('Epoch', fontsize=12)
plt.ylabel('Loss', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.5)
plt.tight_layout()
# 显示图像
plt.show()
gptq>=2.0.0 conflict
raise importlib.metadata.PackageNotFoundError(
importlib.metadata.PackageNotFoundError: No package metadata was found for The 'gptqmodel>=2.0.0' distribution was not found and is required by this application.
To fix: run `pip install gptqmodel>=2.0.0`.
- LLaMA-Factory gptq>=2.0.0 讨论区,可以使用GPTQModel进行量化操作。
使用Qlora训练比纯lora训练更耗时
- 反量化操作引入额外开销:QLoRA int8在训练过程中需频繁将8位整数量化权重反量化为浮点数(如FP16)进行计算(前向/反向传播),计算结束后再重新量化存储。这种反复的量化-反量化(Q/DQ)操作显著增加了计算步骤。相比之下,未量化模型直接使用FP16/BF16计算,减少了中间转换消耗。
- 显存降低但计算量未减少:QLoRA的核心优势是通过量化减少显存占用(例如int8显存需求仅为FP16的1/2),使大模型能在有限显存设备运行。然而,模型的计算量(FLOPs)并未减少,反因量化操作增加额外计算负担。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)