基于主动学习的藻华监测
本文提出一种基于摄像头传感器网络和分布式机器学习的藻华识别算法(DMLAR),通过主动学习构建高效图像分类模型,实现实时、低成本的藻华数量估计。系统在真实湖泊环境中部署,实验结果表明其在精度和执行时间上优于传统方法。
使用主动学习相机传感器网络监测藻华
摘要
产毒藻华的频繁发生对内陆水体的生态状况以及人类和动物健康构成了严重威胁。本文首次利用摄像头传感器网络对湖泊中的藻华进行监测。提出了一种基于分布式机器学习的藻华识别(DMLAR)算法,并在嵌入式传感器节点上实现。DMLAR基于水面图像,能够准确识别藻华并实时估计其数量。DMLAR所使用的机器学习模型通过设计主动学习任务构建,该任务由协作式嵌入式传感器节点以分布式方式完成。自2010年5月起,在部署于湖泊中的系统上使用大规模数据集进行了大量实地实验。实验结果表明,DMLAR在估计精度和执行时间方面均优于两种广泛使用的方法,同时消耗几乎相同的内存和能耗。
关键词 :藻华监测;摄像头传感器网络;主动学习;图像分割。
1 引言
蓝藻,也称为蓝绿藻,是自然存在于湖泊和溪流中的微生物,通常数量较少。当条件适宜(如光照、温度等)时,蓝藻会迅速繁殖形成藻华,导致氧气耗尽并遮挡其他生物生存所需的阳光。接触其产生的毒素也会对人类、宠物、牲畜和野生动物构成风险。
许多方法已被提出用于监测湖泊或河流中的藻华,这些方法可分类为三类,相关工作部分对此进行了详细讨论。基于遥感的方法的缺点是监测周期较长(通常为一到两天,由卫星轨道决定),因此不适合实时藻华监测。而基于实验室分析的方法需要专业实验室设施(如设备和试剂)以及技术专长,导致分析在人力、时间和金钱上成本较高。对于在线水质参数监测方法,多参数水质传感器价格昂贵(约1.5万美元)。此外,目前尚无模型能够准确地将这些水质参数映射到藻华的数量。总而言之,这些方法均无法以低成本实现实时藻华数量的精确估计。
本文介绍了一种自2010年5月起部署在湖泊中的新型传感器系统,该系统利用摄像头传感器网络对藻华进行远程监测。通过悬挂在水面之上的摄像头拍摄的图像,系统可自动识别藻华并估计其数量。估算结果将为藻华打捞提供位置和人力需求信息(例如打捞船和工人的数量)。与传统方法相比,该系统能够准确估计藻华的数量(基于所捕获图像中藻华的覆盖面积),并实现近实时预警(约10秒,如第4.3节所示)。此外,整个过程无需人工参与,且相机传感器成本极低(低于500美元),相较于多参数水质传感器便宜得多。因此,该系统在人力和资金方面的成本都大大降低。据我们所知,这是首个用于藻华监测的实地运行的摄像头传感器网络系统。
本文的主要贡献如下:
- 本文详细介绍了所提出系统的架构与实现,旨在分享我们在部署野外传感器网络方面的经验,不仅限于藻华监测领域。
- 主动学习任务旨在构建用于藻华识别中图像分类的机器学习模型。该主动学习任务是由协作式嵌入式传感器节点(具有与市售无线传感器节点类似的资源,例如 Imote2)以分布式方式分配并完成。因此,可以在显著降低成本的情况下(模型训练和数据传输成本均减少 50%)构建具有高分类准确率的图像分类模型。
- 基于构建的图像分类模型,提出了一种快速、准确且高效的基于分布式机器学习的藻华识别(DMLAR)算法,并在嵌入式传感器节点上实现了该算法。通过融合多个分布式节点的信息,DMLAR将水面图像分割为藻华区域和背景水体,并实时估计藻华的数量。
- 通过大规模数据集(四个月超过8000张图片)进行了广泛的现场实验,以评估DMLAR的性能。结果表明,DMLAR在识别准确率(分别提升8.5%和45.4%)和执行时间(分别提升40%和49%)方面均优于两种广泛使用的方法,同时几乎消耗相同的资源(内存和能耗)。
本文组织如下。我们在第2节中介绍系统架构及其实施细节。DMLAR算法在第3节中提出。第4节展示了实地实验结果并与其它方法进行了比较。第5节回顾了相关工作。我们在第6节对全文进行总结。
2 系统概述
整个系统由一个数据中心和多个传感器站以及基于浮标的传感器节点组成,如图1所示。传感器站建在湖泊内部或湖岸沿线,相距数公里,位于监测区域的中心。以下监测区域经过精心选择:
- 饮用水源地
- 重要的旅游和工业区
- 藻华通常聚集的区域(根据风向和历史记录确定)
基于浮标的传感器节点部署在某些传感器站周围(相距30–40 米),以扩展覆盖范围。位于同一水域的传感器站和基于浮标的传感器节点被分组成簇。选择一个传感器站作为
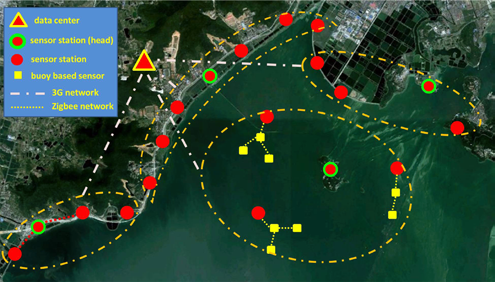
簇头负责向同一簇内的其他传感器站分配任务。所有信息都被收集并显示在数据中心的地理信息系统(GIS)系统上。
传感器站(如图2(a)–(c)所示)旨在监测藻华,作为基于浮标的传感器节点的数据汇聚点,并协作完成主动学习任务,以构建DMLAR所使用的机器学习模型。其中一个传感器站建在坚固的铁质平台上,其组成部分如图3所示。摄像头传感器采用1/4′′索尼CCD,有效像素为 752 × 582。它悬挂在距水面约5米的高度,并通过电机控制旋转至适当角度,以避免镜面反射,从而能够清晰拍摄约30 m²的水域图像。摄像头传感器安装在特殊的机械装置上,用于防抖。当前白天的拍摄周期为10分钟,可远程调整。捕获的图像将通过电缆传输至处理板进行分析,电缆由聚氯乙烯(PVC)管保护。

处理板是一个基于ARM-Linux平台的系统,配备416 MHz的Intel PXA270处理器、32兆字节SDRAM和 Linux 2.6.9内核。其计算和内存资源与现成的无线传感器节点(例如Imote2)相似。外设电路(如以太网端口、USB端口)集成在处理板上,用于与摄像头和Zigbee模块通信。由于传感器站之间相距数公里,因此使用远距离 3G无线路由器将每个簇内的传感器站(以及数据中心)连接起来。为了节省能耗,处理板、摄像头传感器和3G无线路由器均处于睡眠模式,直到处理板被周期性唤醒信号唤醒
定时器(目前为10分钟)。然后处理板将依次唤醒摄像头传感器和3G无线路由器,以拍摄水面图像并传输分析后的数据。

整个传感器站由太阳能供电,太阳能通过太阳能板收集并储存在储能电池中。充放电过程由能量控制模块控制。太阳能板的尺寸和储能电池的容量经过精心选择,以确保在两个晴天内收集的电量能够支持整个系统运行一整周。处理板、3G无线路由器和能量控制模块安装在一个防水控制箱内。目前共有19个传感器站,分为四个簇。更多传感器站正在建设中。
基于浮标的传感器节点设计用于拍摄图像并估算藻华的数量。目前正在开发的一个原型如图2(d)所示。由于负载限制,基于浮标的传感器节点上的太阳能板比传感器站上的要小得多。受电源限制,电机控制相机和远距离3G无线路由器无法在基于浮标的传感器节点上使用。因此,我们计划将低功耗相机、ZigBee传输模块以及低功耗处理单元(Intel PXA271和32M SDRAM)集成在一块处理板上,并采用简化Linux内核。
对于基于浮标的传感器节点而言,考虑到电源受限,将捕获的图像传输(或中继)到传感器站将消耗大量能耗。而对于传感器站来说,如果所有捕获的图像都传回数据中心,传输费用将随着数据量的增加而变得很高。因此,捕获的图像必须在前端嵌入式传感器节点进行处理,仅将分析结果传输回数据中心。因此,所提出的 DMLAR算法必须快速、准确且高效,以便在这两个平台上运行。
3 藻华识别算法
在本节中,我们首先介绍从水面图像中提取的用于藻华识别的特征,这是所有图像识别方法的第一步。然后,我们介绍所提出的DMLAR算法的基本思路,该思路进一步分为两个子问题:图像分类和图像分割。我们通过设计主动学习任务并将该任务分配给嵌入式传感器节点,由多个节点以分布式方式协作构建图像分类模型,从而解决第一个子问题。通过融合来自多个分布式节点的信息并推导图像分割阈值,进而解决第二个子问题,该阈值用于将图像分割为藻华和背景水体。
3.1 特征选择
户外摄像系统的主要挑战之一是光照条件的变化。水面的动态环境(例如本案例中的水波)使情况更加复杂。为了实现鲁棒且准确的藻华识别,关键在于选择一种特征,该特征能够在不同光照条件和动态环境下高效地区分图像中的藻华与背景水体。我们采用监督学习方法,在若干候选特征中选择最佳特征,具体如下。
3.1.1 候选特征
颜色特征是图像识别中最广泛使用的特征之一,可以在多种颜色空间中表示,例如 RGB和 HSV(Gonzalez and Woods, 2002)。图像中的每个像素可以通过三个通道 R、G和 B(或 H、S和 V)中的 r、g、b(或h、s、v)值来表示。在众多颜色特征中,本文采用颜色直方图和颜色矩,因其具有计算简单性和低存储需求。
图片的颜色直方图(Stricker and Orengo, 1995)定义为一个一维数组:
$$
\text{His} c = (h {c,x_1}, h_{c,x_2}, …, h_{c,x_i}, …, h_{c,x_n}) \tag{1}
$$
其中 $ h_{c,x_i} $ 是图像中在通道 c(例如,通道 R)上值为 $ x_i $ 的像素数量,n是通道 c中可能的取值数量。
图像中通道c的颜色矩(Swain and Ballard, 1991)由前三个低阶矩组成,即均值 $ E_c $、方差 $ \sigma_c $ 和偏度 $ s_c $。
在 RGB和 HSV颜色空间中,颜色直方图与颜色矩的以下组合被视为特征候选:
- RGB :在 RGB颜色空间的 R、G和 B通道中,颜色直方图的一维组合(His R ,His G ,His B )。
- HS :在 HSV颜色空间的 H和 S通道中,颜色直方图的一维组合(His H ,His S )。V通道被舍弃,因为它容易受到光的影响。
- RGBMom :RGB颜色空间中 R、G和 B通道的颜色矩,($ E_R, \sigma_R, s_R, E_G, \sigma_G, s_G, E_B, \sigma_B, s_B $)。
- HSMom :HSV颜色空间中 H和 S通道的颜色矩,($ E_H, \sigma_H, s_H, E_S, \sigma_S, s_S $)。
- 2G−R−B :通过将每个像素在灰度图像中的值设置为 $ 2g - r - b $,将具有三个通道的原始彩色图像转换为具有一个通道的灰度图像,其中 r、g、b分别为原始彩色图像中对应像素的 R、G、B通道的值(Meyer 和 Neto,2008)。该灰度图像的颜色直方图His 2G−R−B 被用作特征。
- G−B :类似于特征 2G−R−B,但使用变换函数 $ g - b $。
- G−R :类似于特征 2G−R−B,但使用变换函数 $ g - r $。
3.1.2 特征选择过程和结果
数据集 。从不同季节、不同光照条件下的多个水域采集的1000张水面图像被随机选取,并由人工标注图像中是否存在藻华。从前一节介绍的七个候选特征中,从这些图像中提取特征。从一张图像中提取的特征数据(例如,His RGB )及其标签构成该特征在数据集中的一条样本。
特征选择过程 。对于每个候选特征,相应的数据集被随机分为训练集和测试集,大小分别为700和300。使用训练集训练分类器,并在测试集上进行测试。该过程重复 10次,能够在测试中平均获得更高分类准确率的特征应能高效地区分藻华与背景水体。
Classifier 。LIBSVM (Chang 和 Lin,2011) 用于实现分类器。径向基函数 (RBF) 被用作核函数。采用网格搜索结合交叉验证来寻找分类器所使用的最佳参数。
降维 。采用两种方法主成分分析(PCA)和 BIN对数据集中的样本进行降维,以加快训练和测试过程。对于 PCA方法,使用95%的累计贡献率(例如 e > 95%)来确定主成分的数量。前 L个主成分的累计能耗 $ e $ 计算公式为:
$$
e = \sum_{k=1}^{L} \lambda_k / \sum_{k=1}^{n} \lambda_k
$$
其中 $ \lambda_k $ 是训练集 TS m×n (包含 m个维度为 n的训练样本)的协方差矩阵R n×n 的特征值。对于 BIN方法,将相邻特征值分组到区间中,如 His bin c = ($ h^w_1, …, h^w_k, …, h^w_l $),其中
$$
h^w_k = \sum_{i=(k-1) w+1}^{k w} h_{c,x_i}
$$
w为区间宽度且 l = n/w。经过 PCA和 BIN过程后候选特征的维度如表1所示。
结果 。平均结果(分类准确率、假阳性(FP)和假阴性(FN),包括均值和 variance(var))的百分比在表2中显示。我们可以看到特征 2G−R−B(His 2G−R−B )具有最佳
| 特征 | 原始 | BIN(w) | PCA |
|---|---|---|---|
| RGB | 768 | 96(8,8,8) | 43 |
| 2G‐R‐B | 1024 | 64(16) | 22 |
| G-B | 512 | 64(8) | 39 |
| G-R | 512 | 64(8) | 8 |
| HS | 436 | 62(6,8) | 56 |
表1 降维结果
| 特征 | 准确率 Mean | 准确率 Var. | FN Mean | FN Var. | FP Mean | FP Var. |
|---|---|---|---|---|---|---|
| RGB | 85.70 | 1.71 | 9.38 | 1.29 | 4.93 | 1.87 |
| RGB二值化 | 85.20 | 1.23 | 9.78 | 1.03 | 5.03 | 1.98 |
| RGB主成分分析 | 85.00 | 0.92 | 10.43 | 1.70 | 4.57 | 1.38 |
| RGB矩特征 | 81.20 | 10.92 | 14.53 | 1.26 | 4.28 | 0.90 |
| 2G‐R‐B | 89.28 | 1.40 | 8.25 | 1.71 | 2.48 | 0.79 |
| 2G‐R‐B二值化 | 88.78 | 2.01 | 7.68 | 1.73 | 3.55 | 1.19 |
| 2G‐R‐B主成分分析 | 87.33 | 1.31 | 7.97 | 1.20 | 4.70 | 1.21 |
| G-B | 88.15 | 1.50 | 8.40 | 1.72 | 3.45 | 1.38 |
| G‐B二值化 | 85.93 | 2.27 | 10.73 | 3.41 | 3.35 | 1.85 |
| G‐B主成分分析 | 85.70 | 1.64 | 9.22 | 1.73 | 5.08 | 1.08 |
| G-R | 74.35 | 6.66 | 24.35 | 8.46 | 1.30 | 2.14 |
| G‐R二值化 | 64.73 | 11.00 | 26.83 | 9.25 | 8.45 | 20.08 |
| G‐R主成分分析 | 67.65 | 0.84 | 29.20 | 1.72 | 3.15 | 2.19 |
| HSV | 88.98 | 1.54 | 8.03 | 1.52 | 3.00 | 1.35 |
| HS二值化 | 88.13 | 1.45 | 8.10 | 1.46 | 3.78 | 0.38 |
| HS主成分分析 | 86.45 | 1.05 | 9.45 | 1.42 | 4.10 | 1.49 |
| HSMom | 81.48 | 1.57 | 12.75 | 1.69 | 5.78 | 0.91 |
表2 分类结果
原始数据集和降维数据集的性能。特征 HS具有相似的性能,但由于颜色空间转换,其计算成本高于 2G−R−B。显然,降维不影响分类性能,且 BIN方法在分类准确率和计算成本方面优于 PCA方法。
3.2 基本思路
基本思路受到从捕获的图像中提取的His 2G−R−B 特征数据分布模式的启发。如图4所示,图4(a)和(b)中没有藻华,而图4(c)中有藻华。从这些图像中提取的 His 2G−R−B 特征数据分别以红色点、绿色虚线和蓝色实线曲线的形式绘制在图4(d)中。曲线使用邻近平均法进行平滑处理以去除噪声。

很明显,可以从无藻华图片中提取的平滑 His 2G−R−B 特征数据分布中得出一个合适的阈值 T(约为100,单位为2G‐R‐B值,如图4(d)所示)。对于含有藻华的图片,可使用 T通过将图片分割为藻华像素和背景水体像素来识别藻华。为了识别藻华,首先需要一个图像分类模型来判断图片中是否存在藻华;其次,我们需要随着时间动态调整 T,并使用 T 来分割图像。
基于基本思路,我们提出了一种基于分布式机器学习的藻华识别(DMLAR)算法。
DMLAR 被分为两个子问题:构建图像分类模型和推导用于图像分割的 T。
3.3 构建图像分类模型
水环境会随着水域和季节的变化而变化。因此,使用从某一水域拍摄的标注图片构建的图像分类模型无法用于对从其他水域拍摄的图片进行分类。 Consequently,我们需要为每个特定水域构建一个图像分类模型,并随着时间推移不断优化该模型。
传统的被动监督学习方法需要包含数百甚至数千个标注样本的训练集,才能构建达到特定准确率的分类模型。请回顾第3.1.2节所示结果,仅针对一个传感器站在一个季节内构建图像分类模型并达到平均准确率达到 90%,就需要700个标注样本(图片)。为整个系统标注如此大量的样本是一项繁琐且耗时的工作。此外,将如此大量的图片传输回数据中心也会导致很高的通信成本。
我们设计了一项主动学习任务,该任务仅选择最具信息量的未标记实例进行标注并加入训练集。因此,可以利用更少的标注样本构建具有高分类准确率的图像分类模型。从而显著降低标注和通信成本。应采用何种策略来选择最具信息量的未标记实例,以及如何以分布式方式将任务分配给协作式嵌入式传感器节点并由其完成,是主要的挑战。
3.3.1 实例选择策略
我们设计了一种基于主动学习的实例选择策略(简称 AC),利用不确定性和多样性作为指标,从一组未标记实例池中一次性选出 K最具信息量的样本。
不确定性度量基于分类模型对未标记实例的置信度。对于二元 SVM分类模型(如本例中所使用的),未标记实例的分类模型的绝对决策值(dv,简称)被用作不确定性的度量(Andreas, 2004)。 dv越小,分类的不确定性越高。一旦通过求解公式(2)中的优化问题,利用训练集 TS构建了二元 SVM分类模型,则可通过公式(3)计算未标记实例 x的 dv,其中 $ x_i \in R^n $ 是 n维数据(例如 His 2G−R−B ),$ y_i \in [+1,-1] $ 是 $ x_i $ 的标签(例如图像中有或无藻华),$ (x_i, y_i) \in TS, i=1…m $, m是 TS中标注样本的数量, $ e=[1,…,1] $ 是全1向量, $ Q_{ij} = y_i y_j K(x_i, x_j) $ 是一个 m×m半正定矩阵, $ K(x_i, x_j) $ 是核函数, C和 b是参数。
$$
\min_\alpha \frac{1}{2} \alpha^T Q \alpha - e^T \alpha \
\text{s.t. } y^T \alpha = 0, \quad 0 \leq \alpha_i \leq C, \quad i=1,…,m \tag{2}
$$
$$
dv = \left| \sum_{i=1}^{m} y_i \alpha_i K(x, x_i) + b \right| \tag{3}
$$
简单地查询最 K不确定的未标记实例效果不佳,因为它忽略了 K样本所包含信息之间的相似性。多样性度量用于选择多样化的未标记实例,其通过两个未标记实例 $ x_i $ 和 $ x_j $ 在 SVM分类模型的高维空间中的距离 $ dis(x_i, x_j) $ 来衡量(Mirroshandel 等,2011)。 $ dis(x_i, x_j) $ 可按如下方式计算:
$$
dis(x_i, x_j) = \exp(-\gamma |x_i - x_j|^2) \tag{4}
$$
AC结合了这两个指标,以如下方式选择 K最具信息量的未标记实例。首先,从池中选择满足 dv < 1的未标记实例,构成候选集 CS。该距离限制将确保对应于 CS中(归一化)实例的超平面与版本空间相交(Brinker,2003)。然后,使用公式(4)计算 CS中每对实例之间的距离,并形成距离矩阵(记为 DM), $ DM_{ij} = dis(x_i, x_j) $。接着,使用 DM作为距离度量,将 CS中的实例划分为 K个簇,并选择每个簇的质心进行标注。通过这种方式,所选的未标记实例既具有不确定性又具有多样性。具体而言,我们采用了Pham等(2004)提出的方法,自动计算合适的簇数量 K,并将其作为Park和Jun(2009)提出的kmedoids算法中用于聚类的输入参数。
使用主动学习相机传感器网络监测藻华
3.3.2 主动学习任务分配与分布式执行
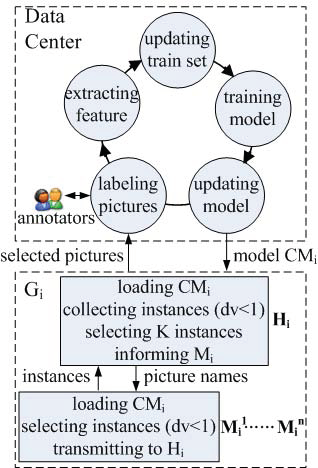
如第1节所述,同一水域内的相邻传感器站被分组为簇(表示为 $ G_i, i=1..m $),它们可以共享同一个图像分类模型。其中一个传感器站根据位置被指定为簇头(表示为 $ H_i $),其余的则为组成成员(表示为 $ M_i $)。当一组传感器站在新的水域部署或季节变化时,需要重建一个或多个图像分类模型。此时,数据中心将向相应的 $ G_i $ 分配主动学习任务。 $ H_i $ 和 $ M_i $ 在 $ G_i $ 中将以分布式方式协作完成所分配的主动学习任务。
主动学习框架 。我们采用基于池的批量模式主动学习框架,该框架假设有少量标注样本 $ L $ 和大量未标记实例 $ U $ 可供使用。基于由 $ L $ 构建的分类模型,根据设计的策略 AC从 $ U $ 中谨慎选择多个信息量丰富的未标记实例,并在分布式并行环境中由标注者进行标注,然后一次性加入 $ L $ 中。接着,利用更新后的 $ L $ 重构新的分类模型,此过程不断迭代,直到分类模型达到特定准确率。
初始分类模型构建 。 $ H_i $ 和 $ M_i $ 将分别捕获水面图像,捕获的图像数量将在 $ H_i $ 处汇总。当总共捕获50张图像后, $ H_i $ 将通知 $ M_i $ 通过3G无线网络将所有图像传回数据中心进行标注(如下所述)。在数据中心,通过从这些标注图片中提取 His 2G−R−B−bin 特征来构建初始训练集 $ L_i $,并基于 $ L_i $ 构建初始图像分类模型(表示为 $ CM_i $),然后将其传输至 $ G_i $ 中的 $ H_i $ 和 $ M_i $。
池构建 。发送前50张图像后, $ H_i $ 和 $ M_i $ 将在 $ G_i $ 中继续在本地内存中缓存捕获的图像,并从这些图像中提取 His 2G−R−B−bin 特征作为未标记实例,直到 $ G_i $ 中的未标记实例总数达到预定义池大小。
实例选择 。基于相同的共享 $ CM_i $, $ H_i $ 和 $ M_i $ 将各自选择未标记实例(His 2G−R−B−bin 特征)并结合 $ dv < 1 $,利用本地缓存的图片构建局部候选集 $ CS_p $。完整的候选集 $ CS $ 将在 $ H_i $ 处汇总。 $ H_i $ 最终将使用策略 AC从 $ CS $ 中选取 $ K $ 个未标记实例,并通知 $ M_i $ 相应图片的名称(如果这些图片在 $ H_i $ 处未被缓存)。然后, $ H_i $ 和 $ M_i $ 将把所选未标记实例对应的图片发送至数据中心。
图像标注与模型构建 。在数据中心接收到的图片将通过 WiFi分发至多台智能手机或平板电脑。标注者只需按下单选按钮(指示图片中是否存在藻华),即可完成对一张图片的标注,并将标签发送至数据中心。在 Android平台上开发的标注软件界面如图5所示。

His 2G−R−B−bin 特征数据从标注图片中提取为标注样本,添加到 $ L_i $ 中。基于更新后的 $ L_i $ 重构 $ CM_i $,并发送至 $ G_i $。该过程如图6所示重复进行。

停止准则 。当达到一定的分类准确率时,主动学习任务即完成,该准确率可通过从池中选择的未标记实例数量进行估计,如第4节所示。最终的 $ CM_i $ 被分发至 $ H_i $、 $ M_i $,并中继到基于浮标的传感器节点用于图像分类。
3.4 图像分割阈值的推导
3.4.1 单个传感器站点的阈值计算
如图4(d)所示,无藻华图像的平滑 His 2G−R−B 曲线服从高斯分布 $ f(u, d) $,其中 $ u $ 为均值, $ d $ 为标准差。已知对于 $ f(u, d) $,其96%的值位于 $ u - 2d $ 和 $ u + 2d $ 之间。我们将阈值 $ T $ 设为 $ u + 2d $,该阈值可排除无藻华图像中98%的像素(视为背景水体),其余2%的像素被视为由颜色失真引起的噪声。该阈值通过基于数百张图像的实验验证。
拟合高斯曲线(例如使用 EM方法(Nirjon 和 Stankovic,2012))计算成本较高,该方法将确定 $ f(u, d) $ 并得到 $ u + 2d $。在本例中,当 $ Ratio_T $ 达到2%时确定阈值 $ T $,其计算公式为:
$$
Ratio_T = \frac{\sum_{i=T}^{n} x^{\text{smooth}-5} i}{\sum {i=1}^{n} x^{\text{smooth}-5}_i} \tag{5}
$$
其中 $ x^{\text{smooth}-5}_i $ 是使用五点邻近平均法对 His 2G−R−B 曲线平滑处理后的第 $ i $ 个值, $ n $ 是平滑后 His 2G−R−B 数据的维度。
3.4.2 分布式阈值融合
请记住,在 $ M_i $ (或 $ H_i $)构建的图像分类模型无法达到100%准确率,这意味着含有藻华的图片可能会被错误分类。因此,基于被错误分类的图片所得出的阈值 $ T $ 使用公式(5)计算的图片阈值会很高,从而导致藻华数量被低估(如图4(d)所示)。为了排除这些不正确的阈值,用于 $ G_i $ 中图像分割的最终阈值 $ T_{\text{seg}} $ 通过融合来自 $ M_i $(和 $ H_i $)的多个阈值得出,并在 $ H_i $ 处进行动态调整,具体如下。
在每个感知周期(例如10分钟)内,当前捕获图像(CurPic i )将由 $ CM_i $ 在 $ M_i $ 处进行分类,并计算 $ CM_i $ 对于 CurPic i 的绝对决策值( $ dv_i $)。如果 CurPic i 被分类为背景水体,则 $ M_i $(以及基于浮标的传感器节点)将使用公式(5)计算 $ T_i $,并将 $ T_i $ 和 $ dv_i $ 发送至 $ H_i $。由于从同一水域内捕获的背景水体图像中提取的 His 2G−R−B 数据分布应相似,因此正确的 $ T_i $ 应彼此相近。因此,可将由被错误分类的 CurPic i 导出的不正确 $ T_i $ 在 $ H_i $ 处识别为异常值,方法如下:将 $ G_i $ 中导出的所有 $ T_i $ 建模为高斯模型 $ M(\mu, \sigma^2) $,其中
$$
\mu = \frac{\sum_{i=1}^{CN} T_i}{CN}, \quad \sigma^2 = \frac{\sum_{i=1}^{CN} (T_i - \mu)^2}{CN}
$$
$ CN $ 为 $ G_i $ 中传感器节点的数量。若 $ |T_i - \mu| > \sigma $,则被视为异常值。然后,用于 $ G_i $ 中图像分割的最终阈值 $ T_{\text{seg}} $ 计算为
$$
T_{\text{seg}} = \frac{\sum_{j=1}^{N} dv_j \cdot T_j}{\sum_{j=1}^{N} dv_j}, \quad \text{其中 } |T_j - \mu| \leq \sigma
$$
$ N $ 为正确 $ T_i $ 的数量。 $ H_i $ 将把 $ T_{\text{seg}} $ 发送给 $ M_i $(以及基于浮标的传感器节点),用于当前感知周期的图像分割。
3.4.3 藻华数量估算
在收到 $ T_{\text{seg}} $ 后, $ H_i $ 和 $ M_i $(以及基于浮标的传感器节点)将根据以下规则把当前感知周期中捕获的图像分割为藻类爆发像素和水体像素:如果 $ 2g - r - b > T_{\text{seg}} $,则该像素被分类为藻华,否则被分类为水。藻华的数量估计为 $ N_c / N_p $,其中 $ N_c $ 是藻类爆发像素的数量, $ N_p $ 是图像中像素的总数。该信息可用于估算在相应传感器站附近水域打捞藻类爆发物所需的人力需求(例如船只数量、工人数量)。
所提出的分布式机器 DMLAR 算法的整个过程总结于算法 1 中。
算法1 DMLAR
1: 输入:在 $ M_i $(Pic i )拍摄的水面图像
2: 输出: Pic i 中的藻华数量估计值
3: 加载 Pic i
4: 对于 Pic i 中的每个像素执行
5: 计算值 $ 2g - r - b $
6: 更新 His 2G−R−B 和 His 2G−R−B−bin
7: 结束循环
8: 加载 $ CM_i $
9: 使用 His 2G−R−B−bin 将 Pic i 分类为样本
10: 如果 Pic i 中没有藻华则
11: 平滑 His 2G−R−B
12: 使用公式5从平滑后的 His 2G−R−B 计算 $ T_i $
13: 使用公式3计算 $ dv_i $
14: 将 $ T_i $ 和 $ dv_i $ 发送到 $ H_i $
15: 结束条件
16: 等待 $ H_i $ 计算 $ T_{\text{seg}} $
17: 使用 $ T_{\text{seg}} $ 对 Pic i 进行分割
18: 估计 Pic i 中藻华的数量
19: 返回藻华数量估计值
4 实验结果
4.1 图像分类模型构建
在本节中,我们展示了用于 DMLAR 算法的图像分类模型(简称为 CM)构建的实验结果。我们首先验证了所设计的实例选择策略能够选择更具信息量的样本,以更少的样本构建高准确率的 CM,从而降低图像标注成本。然后,我们证明了通过分布式方式由协作的嵌入式传感器节点完成的主动学习任务,降低了构建 CM 的传输成本。
我们将第3.3.1节中介绍的实例选择策略(简称为 AC)与另外两种策略进行了比较:基于不确定性的实例选择策略(简称 HY)和随机实例选择策略(简称 RA)。 HY通过样本到超平面的距离( $ dv $)来衡量其不确定性。 RA将随机选择一定数量的样本。在基于池的批量模式主动学习框架的每一次迭代中, AC将从池中选择 $ K $ 个不确定且多样化的样本。 HY将从池中选择25个最不确定的实例(例如,具有最小 $ dv $ 的实例)。 RA将从池中随机选择25个样本。
针对每种实例选择策略,实验按如下方式进行:将1200个标注样本随机分为三个集合:测试集(大小为400)、初始训练集(大小为50)和池集(大小为750)。首先使用初始训练集训练初始分类模型,然后在每次迭代中根据特定的实例选择策略从池集中选取新样本以更新训练集。基于更新后的训练集构建新的分类模型,并使用测试集评估其分类准确率。当池集为空或没有新样本加入训练集时,迭代停止。对于每种策略,均在相同的初始数据集配置下重复整个过程30次。

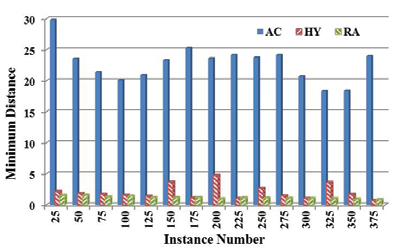
图7显示了三种策略下,随着已选实例数量的增加,所选样本中任意一对之间的最小距离(使用公式(3)计算)的变化情况。显然, AC所选的样本比 HY和 RA所选的样本具有更高的多样性。
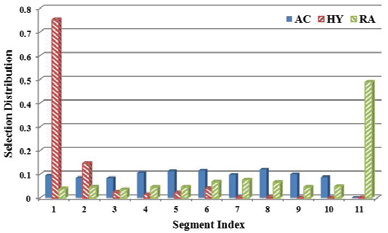
图8显示了已选实例的分布,其计算公式为 $ n_i / n_{\text{all}} $,其中 $ n_i $ 是所选样本中其 $ dv $ 落在 $ seg_i $( $ seg_1 \in [0, 0.1) $、 $ seg_2 \in [0.1, 0.2) $、…、 $ seg_{11} \in [1,+\infty) $)的数量, $ n_{\text{all}} $ 是所有已选样本的数量。我们可以看到, RA选择的大多数样本信息量较少(具有 $ dv > 1 $)。 HY倾向于选择最不确定的样本(其 $ dv $ 接近0)。而由 AC选择的样本则分布更为均匀。

图9显示了随着所选样本数量的增加,分类准确率也随之提高。准确率的提升(百分比)表明,当选择更多的样本时,有更多的水面图像被正确分类(无论是否有藻华)。图9左下角的起始准确率为79.4%。
显然, AC仅用更少的样本(325个样本)就实现了比 RA(625个样本)和 HY(450个样本)更高的准确率。与 RA和 HY的标注成本相比, AC的标注成本分别降低了48%和28%。图9还表明,当藻华监测系统的一个簇中选中并标注325个样本时,主动学习任务即可完成。
对于某些实例选择策略,如前所述的主动学习任务的传输成本由分布式传感器站完成,包括以下几个部分:
- 将样本(His 2G−R−B−bin 数据)从 $ M_i $ 发送到 $ H_i $,用于样本池构建
- 在每次迭代中,将 $ CM_i $ 从数据中心发送到 $ H_i $ 和 $ M_i $
- 将从 $ H_i $ 和 $ M_i $ 选择的图片发送到数据中心
如图9所示, HY的迭代时间为 $ 450/25 = 18 $。而在实验中, AC的平均迭代次数为20。对于 RA,无论使用何种 $ CM $,图片都是随机选择的,因此传输 $ CM $ 没有成本。
根据表3所示的参数,可计算出传输成本为:
$$
\begin{aligned}
\text{TX} {\text{costAC}} &= 0.5K \times 750 + 10K \times 20 + 50K \times 325 = 16825K \
\text{TX} {\text{costHY}} &= 10K \times 18 + 50K \times 450 = 22680K \
\text{TX}_{\text{costRA}} &= 50K \times 625 = 31250K
\end{aligned}
$$
我们可以看到,使用 AC策略的主动学习任务的传输成本相比使用 RA和 HY策略分别降低了46%和26%。
| 参数 | 值 |
|---|---|
| 图片大小 | 50K |
| His 2G−R−B−bin 大小 | 0.5K |
| CM大小 | 10K |
| 池大小 | 750 |
表3 传输成本分析的参数
4.2 藻华识别
我们将 DMLAR 算法与广泛使用的迭代阈值算法(记为 ITT)和 OTSU 算法(Sezgin 和 Sankur,2004)在主观和客观方面进行了比较。选择这两种对比算法是因为它们都是基于阈值的图像分割方法,具有简单实现和快速执行时间的图像识别算法,可与 DMLAR 相比较。
4.2.1 主观比较
通过两个示例图片(如图10(a)和(e)所示),首先利用主观人眼视觉对三种算法的图像识别结果进行比较。 DMLAR 的结果如图10(b)和(f)所示。图10(c)和(g)是 ITT 的结果。图10(d)和(h)显示了 OTSU 的结果。结果图像中的黑白区域分别代表藻华和背景水体。对于没有藻华的图像,显然 ITT 和 OTSU 在混淆藻华和水体方面表现不佳。对于有藻华的图像, DMLAR 的性能明显优于其他方法。
与 ITT 相似,但与 OTSU 不同,难以通过人眼进行比较。因此,我们将在下一节中使用客观指标来比较结果。
4.2.2 客观比较
比较指标 。建立图像识别结果的真实值以进行客观比较非常困难。即使使用 Photoshop 软件,手动识别数百张图片也是一项繁琐且耗时的工作。目前,也没有其他参数(如水体中的 pH 值)可用于准确推断藻华的数量。因此,采用四种广泛使用的客观比较指标进行结果对比,即 $ F $、 $ F’ $、 $ Q $(Zhang 等,2008)和 $ E $(Hao 等,2009)。 $ F $ 用于衡量各分割区域的平均平方色差,并通过与分割区域数量的平方根成比例的加权方式对过分割进行惩罚。 $ F’ $ 对具有大量相同尺寸小区域的分割结果进行惩罚。 $ Q $ 减少了对过分割和欠分割的偏向性。 $ E $ 用于衡量分割区域内像素特征的均匀性。这些评估函数的值越低,表示分割结果越好。
设 $ I $ 为分割图像, $ S_I $ 为整幅图像的大小(以像素数量衡量)。分割是将图像划分为 $ N $ 个任意形状区域的过程。设 $ R_j $ 为区域 $ j $ 中的像素集合, $ S_j = |R_j| $ 为区域 $ j $ 的大小。令 $ N(a) $ 表示分割图像中大小恰好为 $ a $ 的区域的数量, $ MaxSize $ 为分割图像中最大区域的大小。对于像素 $ p $ 的分量 $ x $(例如灰度图像的强度值),令 $ C_x(p) $ 表示像素 $ p $ 的分量 $ x $ 的值。分量 $ x $ 在区域 $ j $ 中的平均值为 $ \hat{C} x(R_j) = (\sum {p \in R_j} C_x(p))/S_j $。区域 $ j $ 的平方色差为 $ e^2_j = \sum_x \sum_{p \in R_j} (C_x(p) - \hat{C}_x(R_j))^2 $。
$$
F(I) = \sqrt{N} \sum_{j=1}^{N} \frac{e^2_j}{\sqrt{S_j}} \tag{6}
$$
$$
F’(I) = \frac{1}{1000 \times S_I} \sqrt{\sum_{a=1}^{MaxSize} [N(a)]^{1+1/a} \sum_{j=1}^{N} \frac{e^2_j}{\sqrt{S_j}}} \tag{7}
$$
$$
Q(I) = \frac{1}{1000 \times S_I} \sqrt{N} \sum_{j=1}^{N} \left[ \frac{e^2_j}{1 + \log S_j} + \left( \frac{N(S_j)}{j} \right)^2 \right] \tag{8}
$$
设 $ V_{x,R_j} $ 为 $ R_j $ 中与分量 $ x $ 相关联的所有可能值的集合,我们使用 $ L_{R_j}(m) $ 表示在原始图像中 $ R_j $ 内分量 $ x $ 取值为 $ m $ 的像素数量(例如, $ C_x(p) == m $)。 $ R_j $ 的熵为 $ H(R_j) = -\sum_{m \in V_{x,R_j}} \frac{L_{R_j}(m)}{S_j} \log \frac{L_{R_j}(m)}{S_j} $。
$$
E(I) = \frac{\sum_{j=1}^{N} H(R_j) - H(I)}{H(I)} \tag{9}
$$
其中 $ H(I) = -\sum_{m \in V_{x,I}} \frac{L_I(m)}{S_I} \log \frac{L_I(m)}{S_I} $ 是图像 $ I $ 的熵。
客观比较结果 。两个示例图片(图10(a)和(e))的客观比较结果列于表4和表5中。为清晰起见,所有指标值均已缩放到0到1之间的数值。我们可以看到, DMLAR 在所有指标上对两张图片均表现出最佳性能。尽管从人眼视觉上看, ITT 对图10(e)的结果似乎与 DMLAR 相似,但实际上 DMLAR 比 ITT 提高了约8%,如表5所示。
统计结果也基于2010年5月–2010年8月四个月期间拍摄的8878张图片在表6中给出。显然, DMLAR 在所有指标上均优于 ITT 和 OTSU,平均分别提高了8.5%和45.4%。
| 指标 | 方法 | DMLAR | ITT | OTSU |
|---|---|---|---|---|
| F/10³ | 0.099 | 0.117 | 0.198 | |
| F′×10² | 0.245 | 0.288 | 0.488 | |
| Q×10³ | 0.180 | 0.210 | 0.380 | |
| E | 0.514 | 0.591 | 0.649 |
表4 图10(a)的客观结果
| 指标 | 方法 | DMLAR | ITT | OTSU |
|---|---|---|---|---|
| F/10³ | 0.106 | 0.120 | 0.156 | |
| F′×10² | 0.261 | 0.295 | 0.384 | |
| Q×10³ | 0.200 | 0.220 | 0.290 | |
| E | 0.668 | 0.671 | 0.681 |
表5 图10(e)的客观结果
| 指标 | 方法 | DMLAR | ITT | OTSU |
|---|---|---|---|---|
| F/10³ | 0.109 | 0.119 | 0.236 | |
| F′×10² | 0.268 | 0.294 | 0.583 | |
| Q×10³ | 0.199 | 0.217 | 0.448 | |
| E | 0.527 | 0.575 | 0.643 |
表6 统计结果
4.3 执行性能
我们将 DMLAR 与 ITT 和 OTSU 在传感器站所使用的处理板上的平均执行时间进行了比较。如表7所示, DMLAR 的执行时间明显短于 ITT 和 OTSU,分别提升了40%和49%。 DMLAR 的内存使用与其他两者基本相同,仅因加载图像分类模型而增加了3%。我们发现,由于即使不运行任何算法,整个处理板的电流也会在139 mA到162 mA之间波动,因此很难准确测量三种算法引起的电流。于是我们测量了每个算法运行时处理板的平均电流,结果表明它们的能耗几乎相同。
| 指标 | 方法 | DMLAR | ITT | OTSU |
|---|---|---|---|---|
| 时间(秒) | 11.46 | 19.20 | 22.54 | |
| 内存(KB) | 4512 | 4372 | 4396 | |
| 电流(mA) | 151.2 | 151.1 | 151.2 |
表7 算法执行结果
4.4 讨论
图11显示了估计的藻华数量以及同步测量的水温在加利福尼亚州的同一传感器站,从2010年5月到2010年7月中旬。为清晰起见,藻华数量的数值已乘以100。蓝色虚线箭头所指出的水温突然上升是由于约三天的数据缺失所致。部分夜晚无法获取水面图像,因此藻华数量存在一些零值。如图11所示,当水温低于25摄氏度时,藻华数量较低;当水温接近30摄氏度时,藻华数量将增加至0.15以上。此外,水温上升与藻华数量增加之间存在一定的时间间隔,如绿色实线箭头和椭圆所指出。这些时间间隔被认为是藻华的生长期。这些结果与许多水环境研究人员得出的结论一致,表明藻华与水温密切相关。
5 相关工作
5.1 基于遥感的方法
藻华的存在会影响水体的光谱反射率(例如近红外区域的吸收峰),这些特征可以被安装在卫星上的高光谱传感器捕获,并用于识别藻华(Gurlin 等,2011; Hunter 等,2010; Gitelsona 等,2008)。这类方法覆盖范围大,因此分析结果可以从全球视角提供藻华的分布和移动情况。然而,它们的结果受天气条件(如云层)影响,且监测周期较长(通常为一到两天),由卫星轨道决定。因此,这些方法不适用于实时藻华监测。
5.2 基于实验室分析的方法
在野外采集的水样可在实验室中使用专用设备和化学试剂进行分析(Anjosa 等,2006; Pobela 等,2011; Ahn 等,2007)。叶绿素a浓度和藻细胞密度通常被用作判定藻华警报级别的双重标准。水样采集需要专业实验室设施和技术专长,且分析过程耗时耗资。换句话说,这是一个昂贵、耗时、劳动密集型且高技能要求的过程。所有这些因素限制了采样和分析频率(通常为每月一次),因此所提出的方法不足以提供及时的预警。
5.3 基于在线水质参数监测的方法
一些水质参数(如pH值、浊度、电导率、溶解氧等)可以反映藻华的存在。多参数水质传感器被用于采集水质参数数据,并在数据中心进行分析,以估算藻华的规模(Smith 等,2009; Sukhatme 等,2007; Stauffer 等,2006)。与上述其他方法相比,这类方法在人力和时间成本方面具有低成本优势。然而,多参数水质传感器本身价格昂贵(约1.5万美元)。此外,尽管可以通过回归或神经网络方法(Teles 等,2006)建立这些参数与藻华数量之间的关系,但由于缺乏标准参考,准确地将这些参数映射到藻华数量仍然困难,因此这些方法仅用于对水体生态质量进行大致评估。
6 结论与未来工作
本文介绍了一种利用摄像头传感器网络监测湖泊藻华的系统,该系统自2010年5月起部署。水面图像被用作数据源以识别藻华。提出了一种基于分布式机器学习的藻华识别(DMLAR)算法,用于实时识别藻华并估计其数量。 DMLAR 所使用的机器学习模型通过设计一个主动学习任务来构建,该任务由协作式嵌入式传感器节点以分布式方式完成。实地实验结果表明, DMLAR 在估计精度和执行时间方面均优于 ITT 和 OTSU,且使用的内存和能耗几乎相同。
未来,我们计划安装水质参数传感器,并与水面图像同步收集水质参数数据(如pH值、溶解氧等)。然后可以分析藻华数量与水质参数之间的关系。此外,可以根据所有这些数据预测每个传感器站的藻华数量,从而提前触发警报。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)