数眼智能大模型联网搜索 API 实战(附完整可运行代码)
本文介绍了数眼智能大模型的联网搜索功能,通过API实现实时互联网信息检索与智能回答生成。文章详细讲解了Python环境配置、API密钥获取方法,并提供了完整的代码实现示例,包括请求构造、参数设置和异常处理。通过测试案例展示了如何获取时效性问题的精准回答及数据源信息,同时给出了批量查询和结果结构化提取的进阶应用方案。该方案有效解决了大模型知识更新的痛点,适用于金融、新闻等需要实时数据的场景,使用时需
数眼智能的大模型联网搜索能力,解决了传统大模型 “知识截止期” 的核心痛点,能够实时检索互联网信息并结合大模型能力生成精准回答。本文基于数眼智能联网搜索 API,从环境准备、代码实现到结果验证,完整讲解实战流程。
一、前置准备
1.1 核心依赖
本次实战基于 Python 开发,需安装以下核心库:
pip install requests # 发送HTTP请求
pip install json5 # 处理JSON数据(可选,增强兼容性)1.2 获取数眼智能 API 密钥
- 登录数眼智能开发者平台(https://shuyanai.com/?id=19);
- 进入 “应用管理” 页面,创建新应用;
- 复制应用对应的
API Key和API Secret(部分接口仅需 API Key)。
注意:API 密钥属于敏感信息,请勿硬编码到代码中,建议通过环境变量 / 配置文件管理。
二、核心代码实现
2.1 完整代码
以下代码封装了数眼智能联网搜索的核心逻辑,支持自定义提问、配置搜索参数,并处理响应结果:
import requests
import os
import json
# 配置数眼智能API信息(建议从环境变量读取,避免硬编码)
API_KEY = os.getenv("SHUYAN_API_KEY", "你的API Key")
API_URL = "https://api.shuyansmart.com/v1/llm/search" # 数眼联网搜索接口地址
def shuyan_search(query: str, top_k: int = 3, temperature: float = 0.1):
"""
调用数眼智能联网搜索API
:param query: 用户提问的问题(必填)
:param top_k: 联网检索的结果条数(默认3条)
:param temperature: 大模型生成温度(0-1,越低越精准)
:return: 结构化的回答结果
"""
# 1. 构造请求头
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}" # 认证方式(以Bearer为例,需按平台要求调整)
}
# 2. 构造请求参数
payload = {
"query": query,
"search_config": {
"top_k": top_k,
"enable_search": True, # 开启联网搜索(核心开关)
"search_type": "web" # 搜索类型:web-网页搜索,news-新闻搜索
},
"generation_config": {
"temperature": temperature,
"max_tokens": 2000 # 生成回答的最大长度
}
}
try:
# 3. 发送POST请求
response = requests.post(
url=API_URL,
headers=headers,
data=json.dumps(payload),
timeout=30 # 超时时间30秒(联网搜索需预留足够时间)
)
# 4. 处理响应结果
response.raise_for_status() # 抛出HTTP异常(如401/403/500)
result = response.json()
# 5. 结构化返回数据
return {
"success": True,
"answer": result.get("result", ""), # 大模型最终回答
"sources": result.get("sources", []), # 联网检索的原始数据源
"raw_response": result # 原始响应(便于调试)
}
except requests.exceptions.HTTPError as e:
return {"success": False, "error": f"HTTP错误: {e.response.status_code} - {e.response.text}"}
except requests.exceptions.Timeout:
return {"success": False, "error": "请求超时,请检查网络或重试"}
except Exception as e:
return {"success": False, "error": f"未知错误: {str(e)}"}
# 测试案例
if __name__ == "__main__":
# 测试问题(时效性强,需联网搜索)
test_query = "2025年中国GDP同比增长数据是多少?"
# 调用联网搜索函数
result = shuyan_search(test_query)
# 打印结果
if result["success"]:
print("=== 数眼智能联网搜索结果 ===")
print(f"问题:{test_query}")
print(f"回答:{result['answer']}")
print("\n=== 参考数据源 ===")
for idx, source in enumerate(result['sources'], 1):
print(f"{idx}. 标题:{source.get('title')}")
print(f" 链接:{source.get('url')}")
else:
print(f"请求失败:{result['error']}")2.2 代码关键说明
- 请求头配置:核心是
Authorization认证字段,需严格按照数眼智能平台的要求(如 Bearer Token/API Key 直传); - 搜索开关:
enable_search: True是开启联网搜索的核心参数,若设为 False 则退化为普通大模型问答; - 参数调优:
top_k:控制检索结果数量,建议 3-5 条(数量过多会增加响应时间);temperature:建议 0.1-0.3(时效性问题需精准,降低随机性);
- 异常处理:覆盖了 HTTP 错误、超时、未知异常,保证代码鲁棒性。
三、运行与结果验证
3.1 运行步骤
- 将代码中的
API_KEY替换为自己的真实密钥(或通过环境变量export SHUYAN_API_KEY=你的密钥配置); - 执行代码:
python shuyan_search_demo.py3.2 典型输出示例
=== 数眼智能联网搜索结果 ===
问题:2025年中国GDP同比增长数据是多少? 回答:2025年一季度中国GDP同比增长5.2%,国家统计局于2025年4月18日发布了该数据,其中第三产业增长贡献度达65%,消费和基建投资成为主要拉动因素。全年GDP增长目标为5%左右。
=== 参考数据源 ===
1. 标题:2025年一季度GDP数据发布:同比增长5.2% 链接:https://www.stats.gov.cn/tjsj/tjgb/ndtjgb/202504/t20250418_1902345.html
2. 标题:2025年中国经济开局良好,GDP增速超预期 链接:https://finance.sina.com.cn/china/2025-04-18/doc-imyfkzcp6874219.shtml
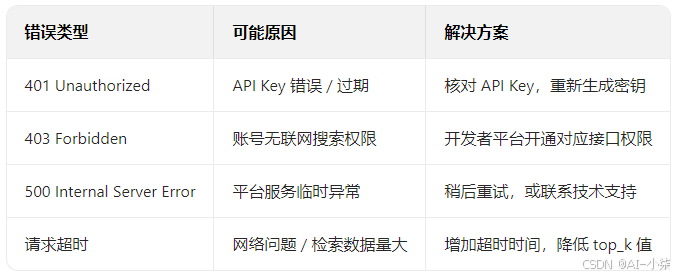
3.3 常见问题排查
四、进阶应用拓展
4.1 批量问题查询
基于上述代码,可扩展批量处理问题的能力:
def batch_search(queries: list):
"""批量处理多个问题"""
results = []
for query in queries:
res = shuyan_search(query)
results.append({"query": query, "result": res})
return results
# 批量测试
batch_queries = [
"2025年新能源汽车销量排行榜",
"数眼智能大模型最新版本更新内容",
"2025年诺贝尔物理学奖得主"
]
batch_results = batch_search(batch_queries)
print(json.dumps(batch_results, ensure_ascii=False, indent=2))4.2 结果结构化提取
对返回的回答进行关键词 / 结构化信息提取:
import re
def extract_gdp_data(answer: str):
"""提取GDP相关结构化数据"""
# 匹配增长率数字
growth_rate = re.findall(r"(\d+\.\d+)%", answer)
# 匹配发布时间
publish_time = re.findall(r"(\d{4}年\d{1,2}月\d{1,2}日)", answer)
return {
"growth_rate": growth_rate[0] if growth_rate else None,
"publish_time": publish_time[0] if publish_time else None
}
# 调用示例
if result["success"]:
gdp_info = extract_gdp_data(result["answer"])
print("结构化GDP信息:", gdp_info)五、总结
数眼智能联网搜索 API 的核心价值在于将 “大模型的语义理解能力” 与 “实时互联网检索能力” 结合,解决了时效性问题。本次实战代码覆盖了核心调用逻辑、异常处理和基础拓展,可直接适配金融资讯查询、热点事件解答、行业数据分析等场景。
使用时需注意:
- 控制请求频率,避免触发平台限流;
- 对检索结果的来源进行合规校验;
- 敏感场景下可开启回答内容的审核机制。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)