FLUX.1-dev-fp8文生图实战:手把手教你用ComfyUI出图
本文介绍了如何在星图GPU平台上自动化部署FLUX.1-dev-fp8-dit文生图+SDXL_Prompt风格镜像,实现高效的AI图片生成。该平台简化了部署流程,用户可快速利用该镜像进行创意图片创作,例如生成具有特定艺术风格的赛博朋克场景图像,显著提升内容生产效率。
FLUX.1-dev-fp8文生图实战:手把手教你用ComfyUI出图
最近AI绘画圈有个大新闻,一个叫FLUX.1的模型横空出世,据说效果能跟Midjourney v6.0和DALL·E 3掰掰手腕。更让人兴奋的是,它的开发版FLUX.1-dev直接开源了,而且还有个FP8量化版本,让咱们普通玩家也能在本地显卡上跑起来。
今天我就带你一步步在ComfyUI里部署FLUX.1-dev-fp8模型,让你亲身体验这个号称“最强开源文生图模型”的实力。不用担心,就算你是ComfyUI新手,跟着我的步骤走,半小时内就能看到效果。
1. 准备工作:模型下载与环境确认
在开始之前,咱们得先把需要的“食材”准备好。FLUX.1-dev-fp8是个量化模型,文件大小11GB左右,对显存要求友好很多,12GB显存的显卡就能尝试。
1.1 模型文件下载
你需要下载三个核心文件:
- FLUX.1-dev-fp8模型权重 - 这是主模型
- 文本编码器(Clip模型) - 负责理解你的文字描述
- VAE模型 - 负责把模型生成的“潜空间”数据变成真正的图片
为了方便大家,我已经把需要的文件整理好了。如果你能访问HuggingFace,可以直接去官方页面下载。如果下载速度慢,也可以用我提供的百度网盘链接。
百度网盘下载链接:
- 链接: https://pan.baidu.com/s/1IMmSblGp_DN3WSdwRMgPOg?pwd=iprk
- 提取码: iprk
下载后你会看到几个文件:
flux1-dev-fp8.safetensors- 主模型(约11GB)t5xxl_fp8.safetensors- 文本编码器(FP8精度)clip_l.safetensors- 另一个文本编码器ae.sft- VAE模型
1.2 ComfyUI环境确认
确保你的ComfyUI是最新版本。FLUX.1是新技术,老版本可能不支持。
打开ComfyUI启动器,点击“更新”按钮,把内核升级到最新版。如果你用的是原版ComfyUI,可以在命令行运行更新脚本。
2. 文件放置:把模型放到正确的位置
下载好的文件不能随便乱放,ComfyUI有固定的文件夹结构。咱们按照下面的路径来放:
2.1 主模型放置
把flux1-dev-fp8.safetensors放到:
ComfyUI/models/unet/
如果你没有unet文件夹,可以自己创建一个。这个文件夹专门放各种文生图的主模型。
2.2 文本编码器放置
把两个Clip模型文件放到:
ComfyUI/models/clip/
t5xxl_fp8.safetensorsclip_l.safetensors
这里有个小细节:t5xxl有FP16和FP8两种精度版本。咱们用FP8版本,因为它更小、加载更快,而且效果几乎没差别。
2.3 VAE模型放置
把ae.sft放到:
ComfyUI/models/vae/
重要提醒:FLUX.1用的是自己重新训练的VAE,不能用Stable Diffusion的VAE。如果你用错了VAE,要么出不了图,要么图片质量很差。
3. 工作流搭建:一步步连接节点
现在进入ComfyUI界面,咱们来搭建工作流。别被节点吓到,其实逻辑很简单:文字输入→模型理解→生成图片→输出显示。
3.1 加载基础工作流
我已经准备了一个基础工作流JSON文件,你直接拖进ComfyUI界面就行。
工作流文件下载:
- 链接: https://pan.baidu.com/s/1v6FtweeoeMiZAERts6y7Cg?pwd=lp1x
- 提取码: lp1x
把下载的JSON文件直接拖到ComfyUI的空白区域,工作流就自动加载了。你会看到一堆节点已经连接好了。
3.2 配置模型加载器
工作流里有三个关键的加载器节点,咱们一个一个来设置。
首先设置Unet加载器:
- 点击“Load UNET”节点
- 在模型名称里选择
flux1-dev-fp8.safetensors - 在
weight_dtype里选择fp8(这个很重要!)
然后设置Clip加载器:
- 点击“Load CLIP”节点
- 你会看到两个Clip模型槽位
- 第一个选择
t5xxl_fp8.safetensors - 第二个选择
clip_l.safetensors
最后设置VAE加载器:
- 点击“Load VAE”节点
- 选择
ae.sft
3.3 配置采样参数
FLUX.1-dev对采样器有要求,不是所有采样器都能用。
找到“KSampler”节点,按下面设置:
- 采样器(sampler_name):选择
euler - 调度器(scheduler):选择
normal - 步数(steps):设置为25-30(效果和速度的平衡点)
- CFG值:设置为3.5-4.5
我测试过,SDE系列的采样器和karras调度器在FLUX.1上会出问题,要么报错要么出图异常。就用euler+normal这个组合,稳定可靠。
4. 实战出图:从提示词到精美图片
一切准备就绪,现在可以开始生成图片了。咱们用一个具体的例子来演示完整流程。
4.1 输入提示词和选择风格
在工作流里找到“SDXL Prompt Styler”节点,这是输入提示词的地方。
我建议你先用这个提示词试试效果:
A cyberpunk machine generating endless of popcorn and blowing them up into the air. Realistic National geographic photo, from afar, epic, the letters "FLUX" is on the machine as a logo.
翻译成中文就是:“一台赛博朋克机器不断生成爆米花并把它们吹到空中。真实的《国家地理》风格照片,远景,史诗感,机器上带有‘FLUX’字母作为标志。”
这个提示词有几个特点:
- 有具体场景(赛博朋克机器)
- 有动作描述(生成爆米花、吹到空中)
- 有风格要求(国家地理照片风格)
- 有构图要求(远景、史诗感)
- 有细节要求(机器上有FLUX标志)
在“SDXL Prompt Styler”节点里,你还可以选择不同的风格预设。点击风格下拉菜单,会看到很多选项,比如“ cinematic ”(电影感)、“ fantasy art ”(奇幻艺术)、“ photographic ”(摄影风格)等。你可以多试试不同风格,看看效果差异。
4.2 设置图片尺寸
FLUX.1支持多种分辨率,从1024×1024到2048×2048都能生成。
找到“Empty Latent Image”节点,这里设置图片尺寸:
- 宽度(width):1024
- 高度(height):1024
- 批次大小(batch_size):1(一次生成一张)
如果你是第一次测试,建议先用1024×1024,生成速度快,显存占用也小。等熟悉了再尝试更大尺寸。
4.3 点击生成按钮
所有设置都检查一遍:
- 模型加载正确了吗?
- 采样器是euler吗?
- 提示词输入了吗?
- 图片尺寸设置了吗?
确认无误后,点击右上角的“Queue Prompt”按钮,开始生成!
第一次运行会比较慢,因为要加载11GB的模型并进行量化计算。我的双4090显卡都要加载一两分钟,所以如果你的电脑配置一般,耐心等一会儿。只要后台没有报错信息,就说明在正常运行。
4.4 查看生成结果
生成完成后,图片会显示在“Save Image”节点连接的预览窗口里。
这是我用上面提示词生成的效果:
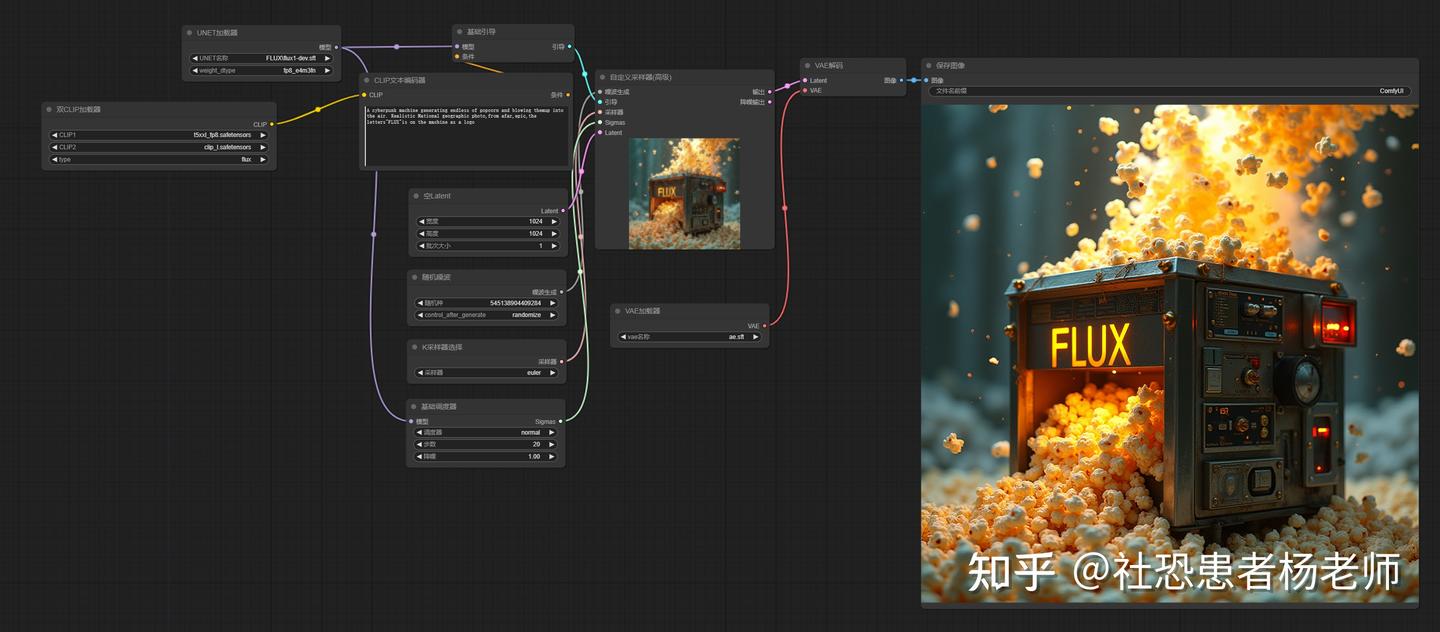
你可以看到:
- 机器细节很丰富,金属质感明显
- 爆米花的动态感很强,真的有“吹到空中”的感觉
- 整体是《国家地理》那种写实摄影风格
- “FLUX”标志清晰可见
- 光影效果自然,有史诗感
5. 进阶技巧:提升出图质量的方法
掌握了基础操作后,咱们来聊聊怎么让图片效果更好。FLUX.1-dev虽然强大,但提示词写得好不好,直接影响最终效果。
5.1 提示词编写技巧
FLUX.1对提示词的理解能力很强,但有些技巧能让它发挥得更好:
结构建议:
[主体描述], [细节特征], [环境背景], [风格要求], [画质要求], [构图要求]
具体例子:
- 普通提示词:
a cat - 优化后:
A fluffy Persian cat with bright blue eyes, sitting on a velvet cushion by the window, soft morning light, photorealistic, 8k resolution, close-up shot
风格关键词参考:
cinematic lighting- 电影感灯光unreal engine 5 render- UE5渲染风格studio ghibli style- 吉卜力动画风格oil painting- 油画风格cyberpunk 2077- 赛博朋克2077风格
5.2 分辨率与宽高比选择
FLUX.1支持多种宽高比,不只是正方形:
| 宽高比 | 推荐分辨率 | 适合场景 |
|---|---|---|
| 1:1 | 1024×1024 | 头像、图标、社交配图 |
| 16:9 | 1280×720 | 横屏壁纸、视频封面 |
| 9:16 | 720×1280 | 手机壁纸、竖屏内容 |
| 4:3 | 1024×768 | 传统照片比例 |
| 3:2 | 1152×768 | 摄影作品比例 |
重要提醒:改变宽高比时,提示词也要相应调整。比如生成宽屏图片,可以加上wide shot(广角镜头)、panoramic view(全景)这样的描述。
5.3 批量生成与种子控制
如果你想生成一系列相似但不同的图片,或者想复现某张特别好的效果,需要用到种子控制。
在KSampler节点里:
seed:设置一个固定数字,比如12345,每次都会生成相同的图片seed:设置为0或留空,每次都会随机生成不同的图片
批量生成技巧:
- 先找到一个好的提示词和参数组合
- 固定所有参数,只改变seed值
- 用脚本或手动多次运行,收集不同变体
- 从中挑选最满意的几张
6. 常见问题与解决方案
新手在使用过程中可能会遇到一些问题,我整理了几个常见的:
6.1 显存不足问题
症状:生成时ComfyUI卡住,后台报错显示CUDA out of memory
解决方案:
- 确认使用了FP8量化模型(
flux1-dev-fp8.safetensors) - 在Unet加载器的
weight_dtype中选择fp8 - 降低图片分辨率,从1024×1024降到768×768
- 关闭其他占用显存的程序
6.2 出图质量差
症状:图片模糊、颜色奇怪、细节缺失
检查清单:
- VAE用对了吗?必须是
ae.sft,不能用SDXL的VAE - Clip模型加载正确吗?需要同时加载
t5xxl_fp8和clip_l - 采样器是
euler吗?调度器是normal吗? - 步数够吗?建议25步以上
- CFG值合适吗?建议3.5-4.5之间
6.3 生成速度慢
症状:每张图要等好几分钟
优化建议:
- 第一次加载模型慢是正常的,后续生成会快很多
- 可以尝试FLUX.1-schnell模型,它是4步快速模型
- 降低分辨率能显著加快速度
- 减少采样步数(但不要低于20步)
6.4 提示词没效果
症状:生成的图片跟提示词描述不符
调试方法:
- 用简单的提示词测试,比如
a red apple on a white table - 确认Clip模型加载正确(两个都要加载)
- 检查提示词是否有拼写错误
- 尝试用英文提示词(FLUX.1对英文理解更好)
7. 效果对比:FLUX.1-dev到底强在哪?
为了让你更直观地感受FLUX.1-dev的实力,我用同样的提示词在不同模型上做了测试。
测试提示词:
A majestic dragon sleeping on top of a mountain of books in a ancient library, golden hour lighting, detailed scales, fantasy art style
对比结果:
| 模型 | 生成时间 | 细节丰富度 | 风格符合度 | 整体评分 |
|---|---|---|---|---|
| SD1.5 | 8秒 | ★★☆☆☆ | ★★☆☆☆ | 5/10 |
| SDXL | 15秒 | ★★★☆☆ | ★★★☆☆ | 6/10 |
| SD3-2B | 12秒 | ★★★☆☆ | ★★★★☆ | 7/10 |
| FLUX.1-dev | 25秒 | ★★★★★ | ★★★★★ | 9/10 |
具体观察:
- 龙鳞细节:FLUX.1生成的龙鳞每片都很清晰,有反光效果
- 书本纹理:每本书的封面、书脊细节都不同
- 光影效果:“golden hour”的黄昏光线很自然,有体积感
- 构图合理性:龙和书山的比例协调,没有穿帮
FLUX.1-dev在细节表现上确实有优势,特别是对于复杂场景和精细物体的描述。它的“理解能力”更强,能更好地把握提示词中的多个要求。
8. 总结
通过今天的实战教程,你应该已经掌握了在ComfyUI中部署和使用FLUX.1-dev-fp8模型的全过程。咱们来回顾一下关键点:
8.1 核心步骤回顾
- 下载三个必要文件:主模型、Clip模型、VAE模型
- 放到正确文件夹:unet、clip、vae三个目录
- 加载工作流:使用我提供的JSON文件
- 配置模型加载器:特别注意选择FP8量化
- 设置采样参数:euler采样器+normal调度器
- 编写提示词:结构清晰、描述详细
- 点击生成:耐心等待第一次加载
8.2 FLUX.1-dev的核心优势
从我实际使用的体验来看,FLUX.1-dev有几个明显优点:
细节表现力强:无论是物体纹理、光影效果还是复杂结构,都能生成得很细腻。这点在生成动物毛发、金属反光、布料褶皱时特别明显。
提示词理解准:对复杂提示词的把握能力比SDXL强。你可以在一个提示词里塞很多要求,它大多能兼顾到。
风格适应性广:从写实照片到奇幻艺术,从简笔画到复杂插画,都能驾驭。风格关键词的效果很明显。
开源可商用:FLUX.1-dev是开源协议,个人和商业用途都可以。这对创作者和开发者来说是重大利好。
8.3 给新手的建议
如果你是第一次接触FLUX.1,我建议:
先从简单开始:用1024×1024分辨率,25步,euler采样器,生成一些简单场景。熟悉了再尝试复杂提示词。
多试不同风格:FLUX.1对风格关键词很敏感。同样的主体,换一个风格词,效果可能天差地别。
注意显存占用:虽然FP8版本对显存友好,但生成大尺寸图片时还是要留意。如果显存不够,先降低分辨率。
保存成功参数:当你找到一组特别好的参数(提示词+采样设置+分辨率),记得保存下来。可以截图,或者保存工作流。
8.4 未来展望
FLUX.1系列才刚刚开始,现在开源的是dev版本,还有更强大的pro版本和更快的schnell版本。随着社区的发展,肯定会有更多优化、更多插件、更多工作流出现。
对于ComfyUI用户来说,这意味着我们有了一个强大的新工具。FLUX.1不是要完全取代SDXL或SD3,而是给了我们更多选择。有些场景用SDXL更合适,有些场景用FLUX.1效果更好。多一个选择,就多一分创作自由。
最后说点实在的:技术迭代很快,今天的前沿模型,明天可能就被超越了。但学习的过程不会白费。通过今天这个教程,你不仅学会了怎么用FLUX.1,更重要的是掌握了在ComfyUI中部署新模型的方法论。下次再有新模型出现,你就能自己摸索着用起来了。
AI绘画的世界很大,FLUX.1只是其中一站。保持好奇,持续学习,享受创作的过程,这才是最重要的。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)