从零入门大模型:最全学习路线、实战案例与资源汇总(2025最新版)
人工智能大模型(如ChatGPT、DeepSeek等)正驱动着技术变革,掌握相关技术已成为提升竞争力的关键。然而,大模型技术涉及领域广泛,学习曲线陡峭。为了帮助大家系统性地学习和掌握大模型技术,我们整理了一份资源包,旨在提供从理论基础到实践应用的全面支持。提供清晰的学习路径,帮助学习者了解不同阶段的学习目标和所需技能。收录了重要的大模型相关论文,涵盖Transformer架构、预训练模型、微调技术
人工智能大模型(如ChatGPT、DeepSeek等)正驱动着技术变革,掌握相关技术已成为提升竞争力的关键。然而,大模型技术涉及领域广泛,学习曲线陡峭。为了帮助大家系统性地学习和掌握大模型技术,我们整理了一份资源包,旨在提供从理论基础到实践应用的全面支持。
这份资源包包含以下内容:
大模型学习路线与阶段规划: 提供清晰的学习路径,帮助学习者了解不同阶段的学习目标和所需技能。
人工智能论文PDF合集: 收录了重要的大模型相关论文,涵盖Transformer架构、预训练模型、微调技术等关键领域,方便深入研究。
52个大模型落地案例合集: 汇集了不同行业的大模型应用案例,展示了如何将大模型技术应用于实际问题,并提供参考实现思路。
100+本数据科学必读经典书: 涵盖机器学习、深度学习、自然语言处理等领域的基础理论和算法,为理解大模型技术奠定基础。
600+套大模型行业研究报告: 提供市场分析、技术趋势、竞争格局等信息,帮助了解大模型技术的行业应用和发展前景。
这份资源包对于想要系统学习大模型技术的人来说,无疑是一份极具价值的指南。首先,要充分利用其中的“大模型学习路线与阶段规划”,这相当于你的学习地图,这份指南出自于我们体系教程《NLP大模型人才培养计划》。
务必仔细研读,了解每个阶段的目标、所需技能和学习内容,并根据自身情况进行调整,制定个性化的学习计划。可以将大的学习路线分解为更小的、可实现的目标,并设定完成时间,这有助于保持学习动力和跟踪进度。
大模型学习路线与阶段规划
本路线旨在帮助学员掌握大模型相关技术栈,以及大模型在行业场景中的应用,包含企业级大模型项目实战。
各阶段详细学习内容:
阶段一:自然语言处理(NLP)与AI基础
- 目标: 掌握NLP与深度学习AI的基础知识,为后续大模型学习打下坚实基础。
- 学习内容:
- 人工智能的发展路径
- 机器学习优化方法和应用
- 实践任务一: 从0实现逻辑回归模型
- 深度学习的发展和应用范式的演变
- 实践任务二: 深度学习开发环境搭建
- 卷积神经网络(CNN)
- 卷积神经网络结构拆解
- 基于PyTorch实现CNN代码架构
- 卷积网络中的经典层(Layer)及其实现方法
- 卷积网络中的经典模块(Module)及其实现方法
- 使用卷积网络建模的经典模型介绍
- 实践任务: 使用CNN搭建文本分类模型
- 循环神经网络(RNN)
- 循环神经网络结构拆解
- 如何解决长序列的知识遗忘问题?—长短期记忆神经网络
- 基于PyTorch实现RNN代码架构
- 如何赋予模型双向学习能力?
- 在不同任务中的RNN的用法区别:分类、序列标注等
- 实践任务: 基于RNN的分词任务实战
- Transformer架构
- 自注意力机制(self-attention)
- 如何让模型学习到文本中不同语段的上下文联系?
- 巧用位置编码,传递语句前后顺序关系
- 核心计算流程:编码(Encoder)和解码(Decoder)
- 实践任务一: 使用Pytorch手撸Transformer
- 实践任务二: 全能的Transformer,解决时序预测问题
阶段二:自然语言处理实战
- 目标: 结合实际场景,掌握NLP技术栈中的任务分类及相关技术。
- 学习内容:
- 第一个自然语言处理流程
- 问题定义
- 数据获取方法
- 数据探索(EDA)&数据整理(Wrangling)&预处理(Initial Preprocessing)
- 如何将数据转化成机器可识别的语言?— 特征工程
- 算法的高级艺术:抽象方法和建模策略
- 如何衡量算法模型的好坏?—评估方法及其重要性
- 将自然语言处理算法部署成应用能力
- 实践任务: 数据分析和预处理实战
- 文本表示方法
- 数据准备: 准备训练数据、基础文本预处理
- 最简单的编码方法:One-Hot
- 词袋表示(N-Grams词袋)
- 基于词频统计的表示方法(TF-IDF)
- 词嵌入(Word2vec、Glove、FastText)
- 可视化词向量
- 实践任务: 手写Word2vec
- 预训练模型 - BERT
- BERT的模型结构解析
- BERT预训练方法
- Mask掩码机制:让模型自己做「完形填空」
- 长段落上下文信息增强,预测下一句(NSP训练策略)
- 第一个自然语言处理流程
阶段三:多模态大模型与知识图谱自动化构建
- 目标: 掌握多模态大模型架构,以及如何利用大模型自动化构建知识图谱。
- 学习内容:
- 多模态大模型
- 学习如何构建指令模板
- 学习如何微调训练多模态大模型
- 搭建图像要素自动识别和多模态问答demo系统
- 基于大模型的知识图谱自动化构建项目实战
- 知识图谱Schema建设方案
- 基于大模型的实体识别和关系构建方法
- 基于大模型的输入存储和图谱查询方法
- 自动化迭代策略
- 实践内容:
- 学习如何使用大模型根据行业数据特点帮助简历并完善知识图谱schema
- 学习如何在Prompt中通过ICL增强大模型对任务的理解
- 学习如何通过微调大模型,优化实体识别和关系关系构建效果
- 学习如何让大模型理解知识图谱的总体架构,从而让大模型能够根据用户输入去自动生成数据存储和查询知识图谱的指令
- 如何驱动大模型周期性得评估知识图谱结构的优劣,自动生成优化方案
- 多模态大模型
阶段四:企业级大模型应用落地方案 - RAG实战
- 目标: 从0-1搭建通用性RAG应用框架,并应用于多个行业场景。
- 学习内容:
- RAG任务介绍 & 技术发展历程
- RAG依赖哪些组件和能力?(向量数据库、大模型推理服务)
- 模块化RAG系统架构设计 — 从理论到实战
- 主流的(开源)RAG应用开发框架
- RAG生态工具和能力
- 实践内容:
- 企业级应用框架设计与实现
- 三个标准流程的抽象与搭建方法(RAG.Chain)
- 灵活的功能组件实现策略(RAG.Module)
- 自定义文档加载器:PDF图文信息增强识别
- 自定义开发文档分割组件:中文段落切分优化方案
- 依赖服务的接入方法:向量数据库、大模型推理服务、embedding、重排序模型
- RAG评估流程搭建
- 基于LangSmith和langfuse搭建RAG流程监控系统
- RAG场景化进阶:基于知识图谱的增强策略(接入现有图谱数据、GraphRAG)
阶段五:Agent项目实战
- 目标: 掌握Agent技术,应对系统状态变化不可控的复杂场景。
- 学习内容:
- Agent通用架构介绍
- Agent中的规划(Planning)和推理(Reasoning)能力
- Agent的文本输出和工具调用
- 经典AI Agent案例分析
- ModelScope-Agent项目拆解
- 实践内容:
- 学习如何通过Prompt引导Agent进行推理
- 学习Agent推理和验证流程的实现方法
- 学习如何让Agent在合适任务上调用外部能力来增强效果
- 学习如何搭建多Agent系统
- 学习如何解决多跳问题:ReAct的实现方法
- 「人人都是AI开发专家」实践一:基于ModelScope Agent搭建一个应用开发助手
- 「人人都是AI开发专家」实践二:基于Coze搭建一个知识问答机器人
阶段六:大模型应用算法工程师面试辅导
- 目标: 提升面试技巧,成功斩获大模型应用算法工程师职位。
- 学习内容:
- 面试攻略及指导
- 优秀简历模板讲解
- 典型简历抽样点评
- 大模型面试知识点整理和分享(八股文)
- 一线互联网大厂的面试流程及侧重点
- 面试技巧分享
- 面试时的几大忌讳
- 大模型应用算法工程师的职业规划
- 在企业中的发展路径
- 职业规划:如何快速升职加薪
- 技术层面如何持续性的自我提升
- 面试攻略及指导
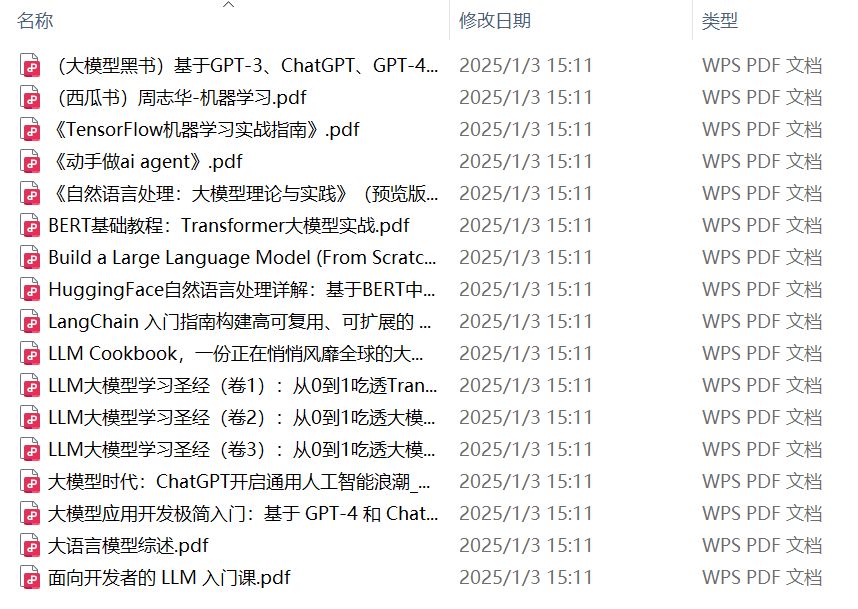
人工智能论文PDF合集
切忌贪多嚼不烂。建议从综述性论文入手,了解特定领域的整体情况和关键研究方向。同时,关注奠定大模型基础的经典论文,例如 Transformer 架构的论文。阅读时,精读与泛读结合,对于重要的论文仔细阅读并理解细节,对于其他论文则快速浏览以了解主要思想。务必做好笔记,记录论文的关键信息、创新点和实验结果,方便以后回顾。
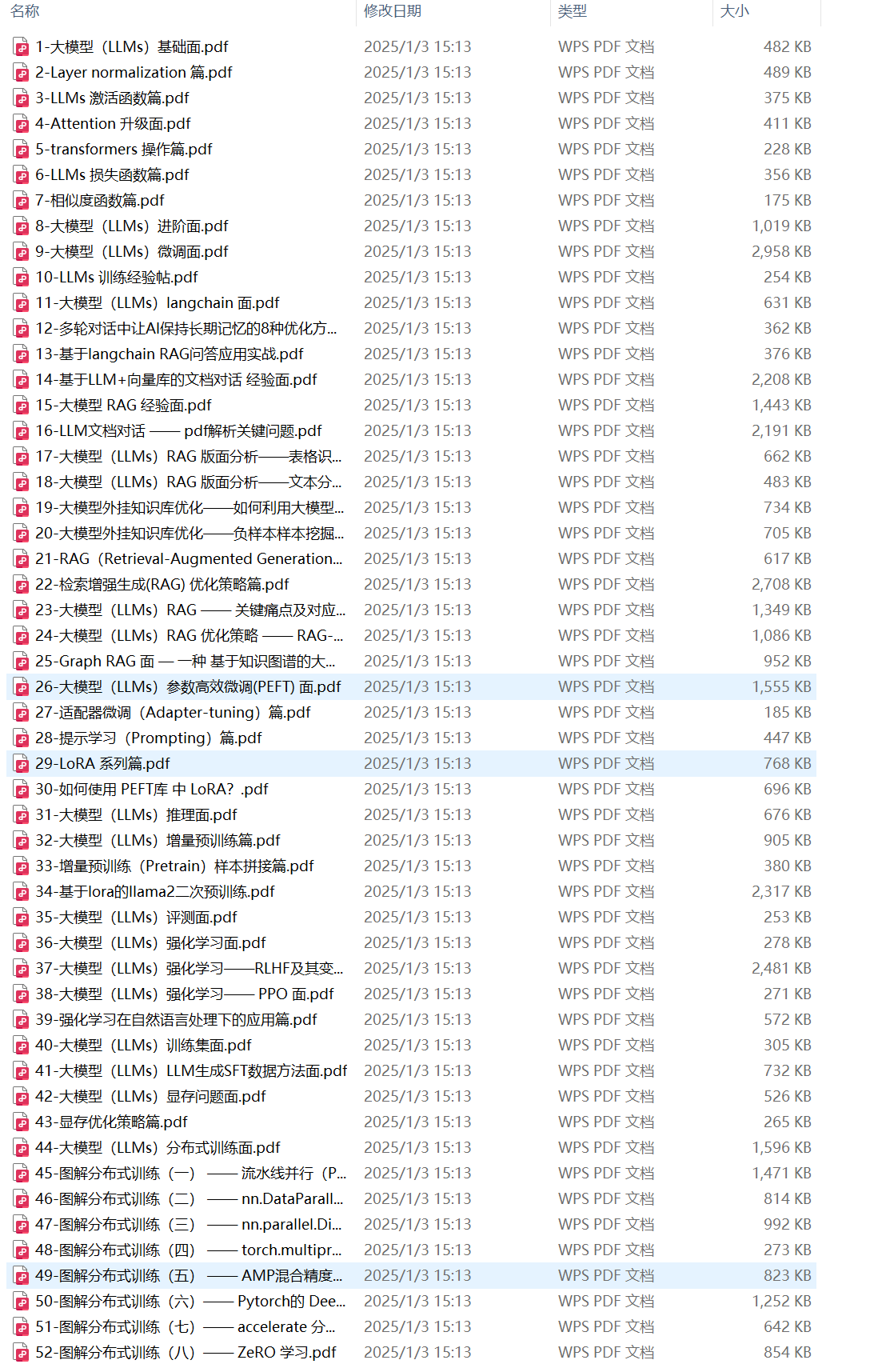
52个大模型落地案例合集
52个大模型落地案例合集”是理论联系实际的绝佳素材。通过案例分析,了解大模型是如何应用于实际问题的,并思考这些案例是否可以应用于你感兴趣的领域。学习案例中的成功经验和遇到的挑战,并尝试复现一些简单的案例,加深理解。
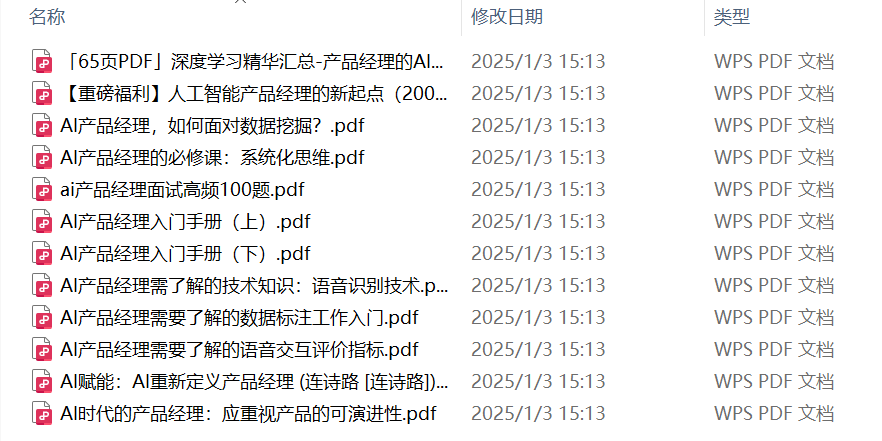
100+本数据科学必读经典书
“100+本数据科学必读经典书”是夯实基础的基石。将书籍按照主题进行分类,例如机器学习、深度学习、自然语言处理、统计学、编程等,并根据自身背景和学习目标,选择合适的书籍。
从入门书籍开始,逐步深入。阅读时,参考其他读者的评论和推荐,选择高质量的书籍,并避免贪多嚼不烂,一次只读几本书,确保理解并掌握内容。
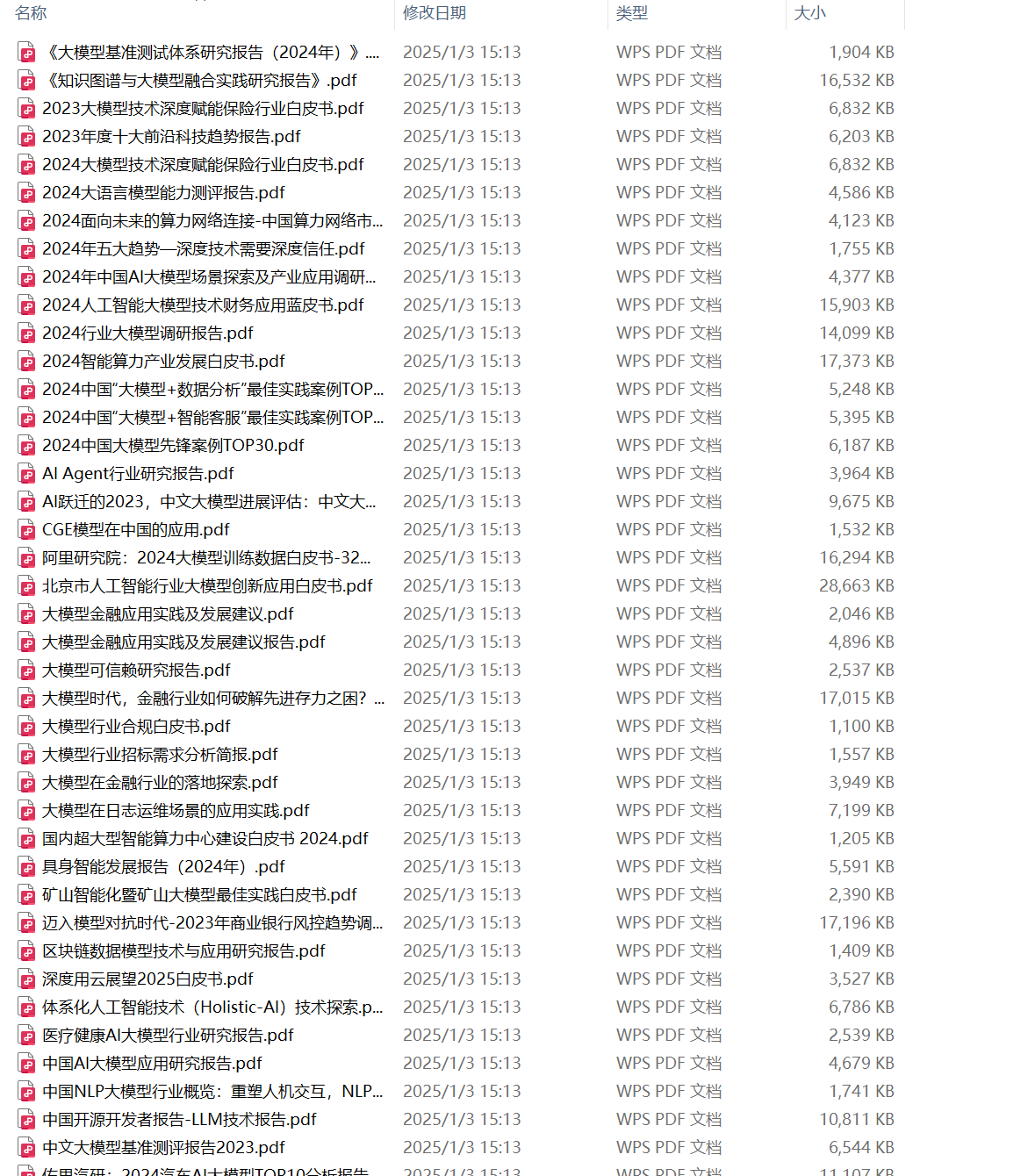
600+套大模型行研报告
“600+套大模型行研报告”是了解行业趋势的重要窗口。通过阅读行研报告,了解大模型技术的最新发展趋
部分资源内容展示

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)