P1177 【模板】排序 - 用六种排序算法实现
本文介绍了六种排序算法在解决数组排序问题中的应用。摘要如下: 本文通过一道数组排序题目,系统介绍了六种排序算法的实现及其时间复杂度表现。题目要求将输入的随机数组排序为升序输出。作者首先提供了解题框架,并重点分析了各排序算法的核心思想。
前言
本道题是一道模拟排序的题目,最近刚学完六种排序的内容。想用所学的六种排序算法,通过这道题。因为六种排序中,插入排序、选择排序以及冒泡排序的最坏的时间复杂度是O(N * N),在这道题的某些测试点会出现超时问题,但不影响这三种算法的整体逻辑结构。另外三种排序,堆排序、快速排序以及归并排序的最坏时间复杂度是O(N * logN),能比较轻松通过这道题的所以测试点。
题目背景和描述

输入
5
4 2 4 5 1
输出
1 2 4 4 5
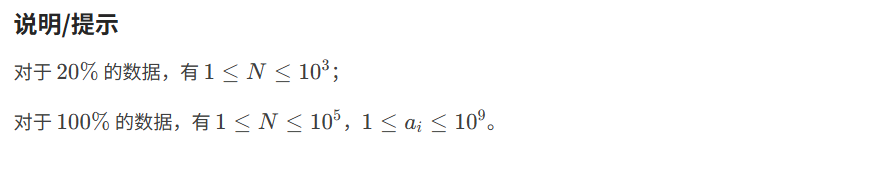
解题框架
本道题通过输入一个无序数组通过排序算法变成一个有序数组,核心代码即是排序函数,所以直接上代码框架如下
#include<iostream>
using namespace std;
const int N = 1e5 + 10;
int n;
int a[N];
//排序函数
void sort()
{
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
//排序函数
sort();
for(int i = 1; i <= n; i++) cout << a[i] << " ";
cout << endl;
return 0;
}
因为这道题的输入和输出都比较简单, 只需要完成排序函数即可
约定 - 下面都会以升序排序的方式来描述算法思想
1 - 插入排序 - 时间复杂度O(N * N)
插入排序的算法思想:
1, 假设在某个区间 [ left, right ] 其中 [ left, mid ] 是有序区间, [ mid + 1, right ] 是待排序区间。当数组遍历到下标为 mid + 1 元素时,在前面有序区间 [ left, mid ] 找 前面小于这个元素,后面大于这个元素这个位置插入进去这个有序数组
假设 有个数组是 {1, 2, 7,5,6},此时5是下标 mid + 1的元素 此时会通过插入排序算法把5插入2到7之间的位置 最后插入完成的数组 {1, 2, 5,7,6},此时数组前面4个元素已经是有序数组,当mid + 1走到最后一个元素时重复上述操作
2,在某个区间开始遍历时,第一个元素默认是有序数组, 只需要遍历[ 2 , right ] 之间的元素即可,第二个元素按照大小插入第一个元素的左边或者后面。
#include<iostream>
using namespace std;
const int N = 1e5+10;
int n;
int a[N];
void insert_sort()
{
//依次枚举待排序的元素
for(int i = 2; i <= n; i++)//因为第一个元素默认是有序的,所以从第二个元素开始
{
int key = a[i];//提前保存这次枚举的元素 因为后面会覆盖这个额元素
int j = i - 1;//本次枚举的元素的前一个元素
while(j >= 1 && a[j] > key)//找到插入的位置 直到前面的元素比这个元素小
{
a[j + 1] = a[j];
j--;
}
//走到这里时 已经找到这个位置
a[j + 1] = key;
}
}
int main()
{
cin >> n;
//输入
for(int i = 1; i <= n; i++)
{
cin >> a[i];
}
//插入排序
insert_sort();
//输出
for(int i = 1; i <= n; i++)
{
cout << a[i] << " ";
}
cout << endl;
return 0;
}
因为插入排序的时间复杂度是O(N * N),所以不能通过本道题的所有测试点。会出现某些测试点超时的情况。但不代表整体代码逻辑不对,后续可以通过更快的排序算法通过本道题。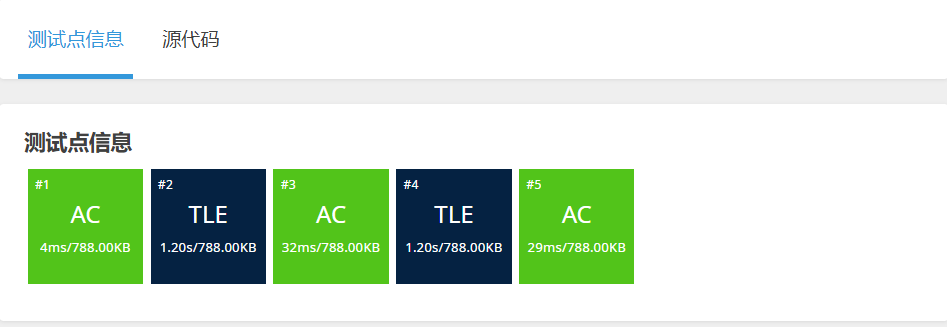
2 - 选择排序 - 时间复杂度O(N * N)
选择排序的算法思想:
1,设置一个变量,记录待排序区间最小的元素。遍历区间时,找到待排序区间中最小的一个元素的下标。在遍历完一遍区间后。此时变量已经记录这个待排序区间最小的元素下标。然后使他与第一个元素交换,然后继续从下标为2的区间开始向后遍历。
2,在区间只剩会最后一个元素时,此时这个元素就是这个区间最大的一个元素。因此,只需要循环n - 1次。
假设有有数组{6, 4, 1, 2},首先找到最小元素的下标 - 也就是元素 1的下标,然后与首元素交换{1, 4, 6, 2},。此时1这个位置就排序好的区间,然后继续执行一次上述操作{1, 2, 6, 4},此时这个数组的前两个元素已经是有序的,最后在执行一次操作{1, 2, 4, 6}。此时数组已经完成排序。数组只剩下6这个排序区间,此时无需再进行一次循环操作
#include<iostream>
using namespace std;
const int N = 1e5 + 10;
int n;
int a[N];
void selection_sort()
{
//因为到最后一个元素会自动排序 所以这里的范围到 1 - n-1
for(int i = 1; i < n; i++)
{
int pos = i;//默认最小元素是 i
//向后查找比这个元素小的元素
for(int j = i + 1; j <= n; j++)// i+1 - n 区间
{a
//找到这个元素的下标
if(a[j] < a[pos])
{
pos = j;//替换最小元素的下标
}
}
//本次待排序的元素与最小元素的值交换
swap(a[i], a[pos]);
}
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
//选择排序
selection_sort();
for(int i = 1; i <= n; i++) cout << a[i] << " ";
cout << endl;
return 0;
}
选择排序的时间复杂度和插入排序的时间复杂度都是O(N * N)级别的,所以在某些测试点会超时。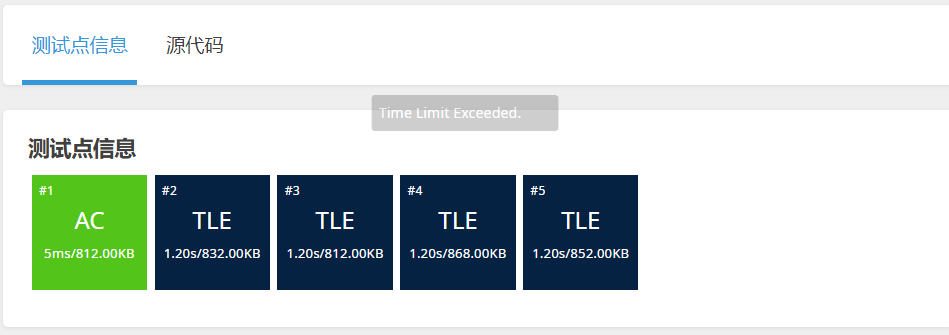
3 - 冒泡排序 - 时间复杂度O(N * N)
冒泡排序的算法思想:
1,冒泡排序是通过循环嵌套完成的,外层循环可以理解层趟数,内层循环是交换次数。也就可以理解成每一趟交换多少次。
2,每一次比较两个相邻的元素,左边元素如果比右边元素大就交换元素,交换完后,在于交换完后的右边元素的右边元素进行比较。如果左边元素小于右边元素,则不交换。然后右边元素与另一个相邻的元素进行比较。
假设数组{5, 2, 6,4},每一趟完成数组的一个元素排序,此时5和2进行比较,5 > 2,此时 5 和 2交换{2, 5, 6, 4}
,然后5 和 4 进行比较,此时因为5 < 6 不需要进行交换。最后6和4比较,完成这一趟最后一次交换{2, 5, 4, 6}
此时最后一个元素已经是有序了。接着每一趟处理一个元素。
#include<iostream>
using namespace std;
const int N = 1e5 + 10;
int n;
int a[N];
void bubble_sort()
{
//依次枚举待排序的元素 也可以理解成躺数
for(int i = n; i > 1; i--)
{
//每一趟交换的次数 随着趟数的增加而减少交换次数
for(int j = 1; j < i; j++)
{
if(a[j] > a[j + 1])//判断左边元素是否大于右边元素
{
swap(a[j], a[j + 1]);//交换
}
}
}
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
bubble_sort();
for(int i = 1; i <= n; i++) cout << a[i] << " ";
cout << endl;
return 0;
}
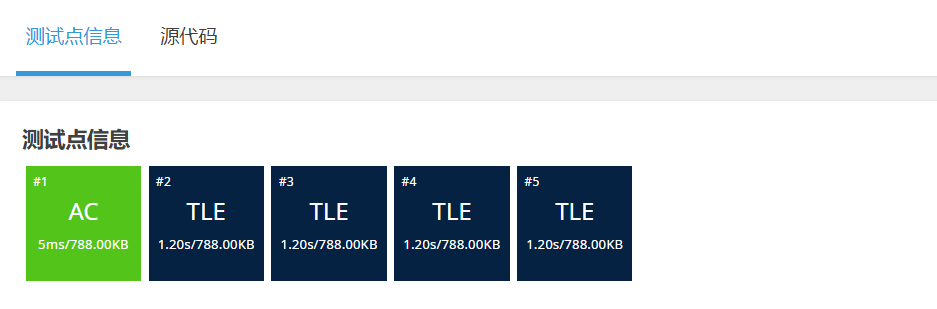
此时,只通过一个测试点,但是这个冒泡排序还可以优化,假设在某一趟中并没有交换元素。此时,这个数组已经是有序数组。不许要在执行剩下的趟数,可以大大的节省时间复杂度。
void bubble_sort()
{
for(int i = n; i > 1; i--)
{
bool flag = false;// 优化部分
for(int j = 1; j < i; j++)
{
if(a[j] > a[j + 1])
{
swap(a[j], a[j + 1]);
flag = true;//优化部分
}
}
//优化部分 加入某趟没有实现交换操作的话 后续就不用继续执行代码
if(flag == false) return;//很大程度下节省时间复杂度
}
}
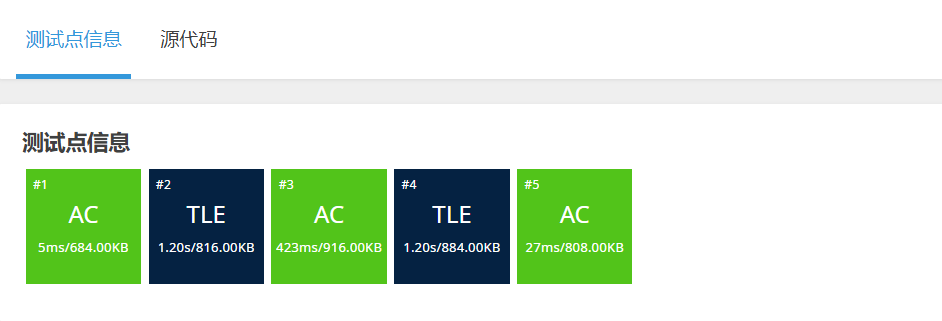
此时优化之后的冒泡排序比没有优化的冒泡排序多通过两个测试点。但是冒泡排序的时间复杂度依然是O(N * N)
,后面3种的排序算法的时间复杂度可以通过所有的测试点。
4 - 堆排序 - 时间复杂度O(N * logN)
堆排序的算法思想:
堆排序算法是一种利用堆这种数据结构所设计的一种排序算法。本质上是优化了选择排序,如果把数据放在堆种就可以更快的找到最大值和最小值。
堆排序的过程可以分两步:
1,建堆:升序大根堆,降序小根堆。从倒数第一个非叶子节点的子树开始,执行向下调整算法,知道根节点。
2,排序:每次将堆顶元素与最后一个元素交换,堆大小减一,然后将堆顶元素向下调整,重复过程,直到只剩下最后一个元素。
#include<iostream>
using namespace std;
const int N = 1e5 + 10;
int n;
int a[N];
//向下调整算法
void down(int parent, int len)//父节点,长度
{
int child = parent * 2;
while(child <= len)
{
//判断父节点的两个子节点谁大
if(child + 1 <= len && a[child + 1] > a[child]) child++;
//判断是否父节点和子节点 满足跳出函数
if(a[parent] > a[child]) return;
swap(a[parent], a[child]);//交换父子节点
parent = child;
child = parent * 2;
}
}
void heap_sort()
{
//建堆
//最后一个叶子节点是 n,则最后一个非叶子节点是 n / 2
for(int i = n / 2; i >= 1; i--)
{
down(i, n);
}
//排序
//堆只剩下最后一个元素时 已经是有序了 执行 n - 1 次
for(int i = n; i > 1; i--)
{
swap(a[1], a[i]);//与最后一个元素交换
down(1, i - 1);//这里向下调整算法 堆要减少一位
}
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
//堆排序
heap_sort();
for(int i = 1; i <= n; i++) cout << a[i] << " ";
cout << endl;
return 0;
}
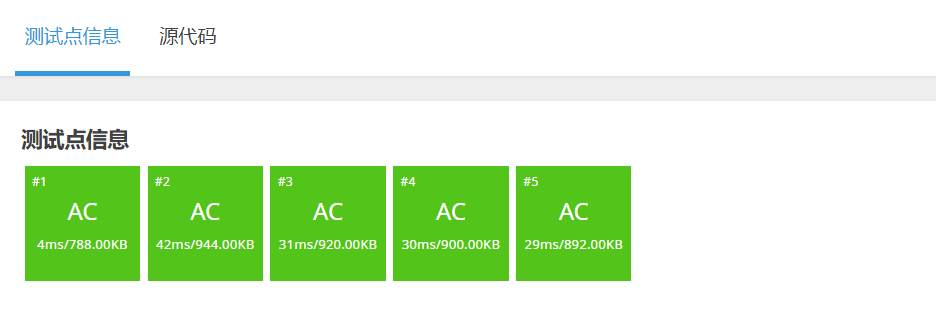
因为堆排序的时间复杂度是O(N * logN),所以比前面三种排序快,即可通过所以测试点。
5 - 快速排序 - 时间复杂度O(N * logN)
快速排序的算法思想:
快速排序的算法原理可以分两步
1,从待排序区间选择一个基准元素,按照基准元素的大小将区间分为两部分。小于等于基准元素在左区间,大于基准元素在右区间。
2,然后递归处理左右区间,直到区间长度为一。
朴素的快速排序会有两个缺陷。
缺陷一:基准元素选择不当,递归层数会增加,时间复杂度越高。
缺陷二:当有大量重复的元素时,递归就增加层数。
如何解决这两个缺陷
解决缺陷一:可以用一个随机函数选择基准元素。
解决缺陷二:把区间分为3分。小于基准元素、等于基准元素以及大于基准元素。
上述两种方法可以快速解决这两种缺陷
#include<iostream>
#include<ctime>
using namespace std;
const int N = 1e5 + 10;
int n;
int a[N];
//随机函数 返回一个基准元素
int get_random(int left, int right)
{
return a[rand() % (right - left + 1) + left];
}
//快速排序
void quick_sort(int left, int right)
{
//判断是否只有一个区间 或者区间是否存在
if(left >= right) return;
//生成一个基准元素
int p = get_random(left, right);
//荷兰国旗问题 把区间分成三份
// [left, l] [l + 1, r - 1] [r, right]
int l = left - 1, i = left, r = right + 1;
while(i < r)
{
if(a[i] < p) swap(a[++l], a[i++]);
else if(a[i] == p) i++;
else swap(a[--r], a[i]);
}
//递归 处理左右两个区间
quick_sort(left, l);
quick_sort(r, right);
}
int main()
{
srand(time(0));//随机函数种子
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
//快速排序
quick_sort(1, n);
for(int i = 1; i <= n; i++) cout << a[i] << " ";
cout << endl;
return 0;
}
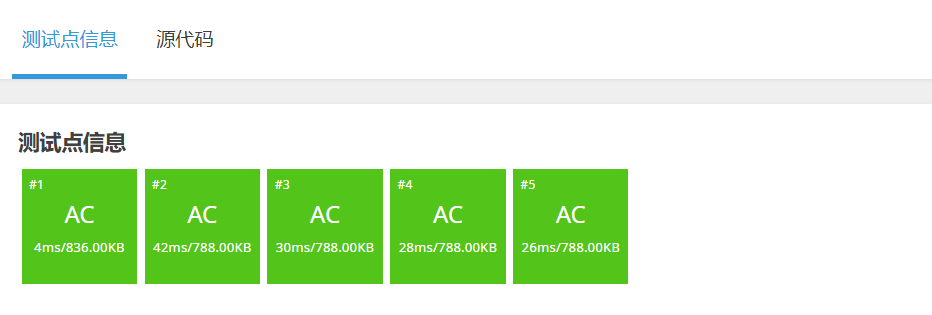
因为快速排序的时间复杂度和堆排序的时间复杂度是一样的(O(N * logN)),因此可以通过所以测试点。
6 - 归并排序 - 时间复杂度O(N * logN)
归并排序的算法思想:
归并排序是一种无论数据是什么特性,时间复杂度都能稳定到O(N * logN)的算法。
归并排序主要分两步
1,只要还能分,就递归把整个区间总中间一分为二,先将左区间排序和右区间排序。
2,最后将两个左右排好序的区间合并在一起。其中,如何让两边有序,就交给递归的归并排序。
也就是将数组的所以元素,利用递归算法。分成元素为一的区间,然后将两个区间合并成有序区间
#include<iostream>
using namespace std;
const int N = 1e5 + 10;
int n;
int a[N];
int tmp[N];//辅助数组
//归并排序
void merge_sort(int left, int right)
{
//递归出口 - 区间只有一个元素或者区间不存在
if(left >= right) return;
//区间一分为二 [left, mid] [mid + 1, right]
int mid = (left + right) >> 1;
//排成有序区间
merge_sort(left, mid);
merge_sort(mid + 1, right);
//合并两个有序区间
int cur1 = left, cur2 = mid + 1, i = left;
while(cur1 <= mid && cur2 <= right)
{
if(a[cur1] <= a[cur2]) tmp[i++] = a[cur1++];
else tmp[i++] = a[cur2++];
}
//执行到这里时 肯定有个区间还有元素
while(cur1 <= mid) tmp[i++] = a[cur1++];
while(cur2 <= right) tmp[i++] = a[cur2++];
//把原数组的元素替换成辅助数组的元素
for(int j = left; j <= right; j++) a[j] = tmp[j];
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
//归并排序
merge_sort(1, n);
for(int i = 1; i <= n; i++) cout << a[i] << " ";
cout << endl;
return 0;
}
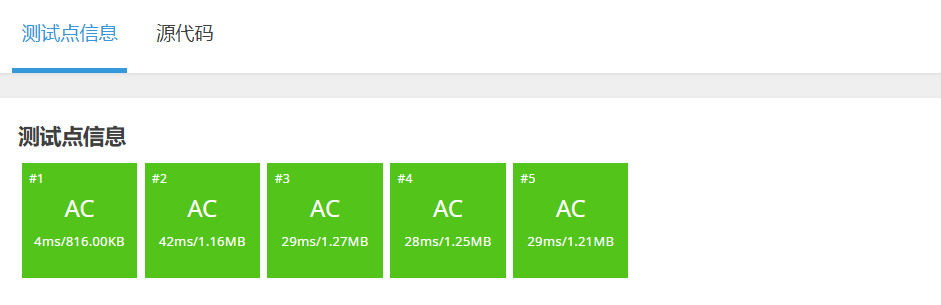
因为最后三种排序的时间复杂度都是一样的(O(N * logN)),所以都能通过所以测试点。
结语
以上就是我总结的六种排序的内容,虽然有些算法不能通过这道算法题,但不代表整体逻辑就错了。如果O(N * N)的算法过不了,可以以用更快一点的排序算法O(N * logN)。
完

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)