山东大学软件学院人工智能导论期末知识点整理
自然界的四大奥秘:智能的发生、物质的本质、宇宙的起源、生命的本质智能:智能是智力与知识的总和。其中,知识是一切智能行为的基础,而智力是获取知识并应用知识求解问题的能力。感知能力:视觉、听觉、触觉、嗅觉等感觉器官感知外部世界记忆与思维能力:记忆与思维是人脑最重要的功能,记忆是存储由感知器官感知到的外部信息以及由思维所产生的知识;思维用于对记忆的信息进行整理。学习能力行为能力(表达能力)人工智能:用人
Chapter 1 绪论
1.1 人工智能的基本概念
1.1.1 智能的概念
-
自然界的四大奥秘:智能的发生、物质的本质、宇宙的起源、生命的本质
-
智能:智能是智力与知识的总和。其中,知识是一切智能行为的基础,而智力是获取知识并应用知识求解问题的能力。
1.1.2 智能的特征
- 智能的特征有以下几点:
-
感知能力:视觉、听觉、触觉、嗅觉等感觉器官感知外部世界
-
记忆与思维能力:记忆与思维是人脑最重要的功能,记忆是存储由感知器官感知到的外部信息以及由思维所产生的知识;思维用于对记忆的信息进行整理。
- 逻辑思维(抽象思维)
- 依靠逻辑进行思维
- 思维过程是串行的
- 容易形式化
- 思维过程具有严密性、可靠性
- 形象思维(直感思维)
- 依据直觉
- 思维过程是并行协同式的
- 形式化困难
- 在信息变形或缺少的情况下仍有可能得到较为满意的结果
- 顿悟思维(灵感思维)
- 不定期的突发性
- 非线性的独创性及模糊性
- 穿插于形象思维与逻辑思维中
- 逻辑思维(抽象思维)
-
学习能力
- 学习既可能是自觉的、有意识的,也可能是不自觉的、无意识的;既可以是有教师指导的,也可以是通过自己实践的
-
行为能力(表达能力)
- 人们的感知能力:用于信息的输入
- 行为能力:信息的输出
1.1.3 人工智能
-
人工智能:用人工的方法在机器(计算机)上实现的智能;或者说人们使机器具有类似于人的智能
-
人工智能学科:一门研究如何枯燥智能机器或智能系统,使它能模拟、延伸、扩展人类智能的学科
-
图灵测试:1950年图灵发表的《计算机与智能》中设计的一个测试,用以说明人工智能的概念
1.2 人工智能的发展简史
可以分为三个阶段孕育、形成和发展。
-
孕育(1956年以前)
-
形成(1956——1969年)
-
发展(1970年——
-
大数据驱动发展期(2011年——
-
物联网、大数据、云计算、人工智能相互促进
-
人工智能大体可以分为专用人工智能和通用人工智能
-
专用人工智能:面向特定任务(如下棋)的人工智能;
- 任务需求明确、应用边界清晰、领域知识丰富,在局部智能水平的测试中往往能够超越人类智能
-
通用人工智能:可处理视觉、听觉、判断、推理、学习、思考、规划、设计等各类问题
- 人工智能的发展方向式通用人工智能。通用人工智能目前尚处于起步阶段
-
1.3 人工智能研究的基本内容
-
知识表示
- 知识表示定义:将人类知识形式化或模型化
- 知识表示方法包括:符号表示法、连接机制表示法
- 符号表示法:用各种包含具体含义的符号,以各种不同的方式和顺序组合起来表示知识的一类方法。例如,一阶谓词逻辑、产生式等
- 连接机制表示法:把各种物理对象以不同的方式及顺序连接起来,并在其间互相传递及加工各种包含具体意义的信息,以此来表示相关的概念及知识。例如,神经网络
-
机器感知
使机器具有类似于人的感知能力,以机器视觉(machine vision)与机器听觉为主
-
机器思维
对通过感知得来的外部信息以及机器内部的信息进行有目的地处理
-
机器学习
研究如何使计算机具有类似于人的学习能力,使它能通过学习自动地获取知识
-
机器行为
计算机的表达能力,即“说”“写”“画”等能力
1.4 人工智能的主要研究领域
自动定理证明
- 自动定理证明的实质是由前提P得到结论Q的永真性
博弈
- 如下棋、打牌、战争等一类竞争性的智能活动
- 为什么研究打牌、下棋,因为棋类游戏计算复杂性很高
- 围棋
模式识别
- 研究对象描述和分类方法的学科。分析和识别的模式可以是信号、图像和普通数据
- 文字识别:邮政编码、车牌识别、汉字识别
- 人脸识别:反恐、商业
- 物体识别:导弹、机器人
机器视觉/计算机视觉
-
用机器代替人眼睛进行测量和判断,应用在半导体及电子、汽车、冶金、制药、视频饮料、印刷等
-
文字识别:邮政编码、车牌识别、手写体识别。计算机、手机等输入
-
人脸识别:反恐、商业
-
物体识别:导弹、机器人
智慧医疗
医学影像识别
- 黑色素瘤识别
自然语言理解
- 研究如何让计算机理解人类自然语言,包括回答问题、生成摘要、翻译等
机器听觉
- 计算机语音输入:计算机、智能手机等的重要组成
- 计算机语音录入、手机语音呼叫、机器人语音控制、语音锁、机器故障诊断等
- 语音识别用语音作为计算机的输入
- 语言识别的重要过程:语音信号采集、预处理(预滤波、采样、预加重、端点检测)、特征参数提取、向量量化、识别
机器翻译
智能信息检索
功能包括:
- 能理解自然语言
- 具有推理能力
- 系统具有一定的常识性知识
数据挖掘与知识发现
- 目的是从数据库中找出有意义的模式(一组规则、聚类、决策树、依赖网络或其它方式表示的知识)
- 数据挖掘过程:数据预处理、建模、模型评估及模型应用
专家系统
自动程序设计
-
将自然语言描述的程序自动转换成可执行程序的技术
-
程序综合:用户只需要告诉计算机要做什么,无须说明“怎么做”,计算机就可自动实现程序的设计
-
程序正确性的验证:研究出一套理论和方法,通过运用这套理论和方法就可证明程序的正确性
机器人
- 指可模拟人类行为的机器
无人驾驶
- 机器在感知上比人类强很多
- 机器比人类精力充沛
- 机器比人更理性
- 无人驾驶商业化的四个关键要素:
- 硬件组件
- 软件组件
- 整车制造
- 网络
组合优化能力
- 组合优化问题:旅行商问题、生产计划与调度、物流中的车辆调度、智能交通、通信中的路由调度、计算机网络信息调度等
- NP完全问题:用目前知道的最好的方法求解,问题求解需要花费的时间是随问题规模增大以指数关系增长。
人工神经网络
- 机器学习的第二次浪潮:深度学习
- 人的视觉系统的信息处理是分级的
分布式人工智能与多智能体
- 分布式人工智能系统以鲁棒性作为控制系统质量的标准,并具有互操作性,即不同的异构系统在快速变化的环境中,具有交换信息和协同工作的能力
- 分布式问题求解:把一个具体的求解问题划分为多个相互合作和知识共享的模块或结点
- 多智能体系统:研究各智能体之间行为的协调
智慧物流
智能控制
- 两个显著特点:
- 智能控制是同时具有知识表示的非数学广义世界模型和传统数学模型混合表示的控制过程
- 智能控制的核心在高层控制,其任务在于实际环境或过程进行组织,即决策与规划,以实现广义问题求解
- 基本类型:专家智能控制、模糊控制、神经网络控制
智能仿真
- 将AI引入仿真领域,建立智能仿真系统
智能管理与智能决策
- 智能管理就是把人工智能技术引入管理领域,建立智能管理系统,研究如何提高计算机管理系统的智能水平,以及智能管理系统的设计理论、方法与实现技术。
- 智能决策就是把人工智能技术引入决策过程,建立智能决策支持系统。
- 智能决策支持系统是由传统决策支持系统再加上相应的智能部件就构成了智能决策支持系统。
- 智能部件可以是专家系统模式、知识库模式等。
人工生命
- 人工生命是以计算机为研究工具,模拟自然界的生命现象,生成表现自然生命系统行为特点的仿真系统
- 研究具有自治性、通信性、反应性、预动性和社会性的智能主体的形式化模型、通信方式、协作策略
智能操作系统
- 基本模型是以智能机为基础、并能支撑外层的AI应用程序
- 三大特点:并行性、分布性和智能性
Chapter 2 知识表示和知识图谱
2.1 知识与知识表示的概念
2.1.1 知识的概念
- 知识:在长期的生活及社会实践中,在科学研究及实验中积累起来的对客观世界的认识与经验
- 知识:把有关信息关联在一起所形成的信息结构
- 知识反应了客观世界中事物之间的关系,不同事物或相同事物间的不同关系
2.1.2 知识的特性
- 相对正确性
- 任何知识都是在一定的条件及环境下产生的,在这种条件及环境下才是正确的
-
不确定性
-
随机性引起的不确定性
-
由随机事件所形成的知识不能简单地用“真”或“假来刻画”
-
火烧赤壁——借风;如果头疼流涕,有可能感冒
-
-
模糊性引起的不确定性
天气冷热、雨的大小、风的强弱、年龄大小、个子高低、人的胖瘦
-
经验引起的不确定性
老马识途
-
不完全性引起的不确定性
- 火星上可能有水、生命?
-
-
知识的可表示性:知识可以用适当的形式表示出来,如语言、文字、图形、神经网络等
-
知识的可利用性:知识可以被利用
2.1.3 知识的表示
- 知识表示就是将人类知识形式化或模型化
- 选择知识表示方法的原则
- 充分表示领域知识
- 有利于对知识的利用
- 便于对知识的组织、维护与管理
- 便于理解和实现
2.2 一阶谓词逻辑表示法
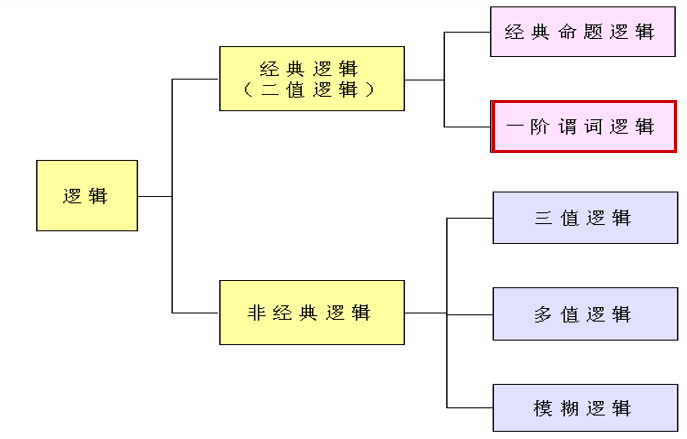
逻辑可分为经典逻辑(二值逻辑)和非经典逻辑(三值逻辑、多值逻辑、模糊逻辑)
2.2.1 命题
- 命题:一个非真即假的陈述句。
- 若命题的意义为真,称真值为真,记为T。例:3《5
- 若命题的意义为假,称真值为假,记为F。例:太阳从西边升起
- 一个命题可在一种条件下为真,在另一种条件下为假。例:1+1=10;十进制和二进制
- 命题逻辑:研究命题及命题之间关系的符号逻辑系统;例:北京是中华人民共和国的首都
- 命题逻辑表示法:无法把它所描述的事物的结构及逻辑特征反映出来(P:老李是小李的父亲),也不能把不同事物之间的共同特征表述出来(P:李白是诗人;Q:杜甫也是诗人)。
2.2.2 谓词
谓词的一般形式P($ x_1,x_2,…,x_n$)
个体$ x_1,x_2,…x_n$:某个独立存在的事物或者某个抽象的概念
谓词名P:刻画个体的性质、状态或个体间的关系
一阶谓词:在谓词P(x1,x2,…xn)P(x_1,x_2,…x_n)P(x1,x2,…xn)中,若xi(i=1,…,n)x_i(i=1,…,n)xi(i=1,…,n)都是个体常量、变元或函数,称它为一阶谓词
-
个体是常量:一个或者一组指定的个体
- 例:老张是一个教师:一元谓词Teacher(Zhang)
- 5>3:二元谓词Greater(5,3)
- Smith作为一个工程师为IBM工作,三元谓词Works(Smith,IBM,engineer)
-
个体是变元(变量):没有指定的一个或一组个体
eg. x<5,可表示为Less(x,5)
-
个体是函数:一个个体到另一个个体的映射
eg.小李的父亲是教师 Teacher(Father(Li))
小李的妹妹和小张的哥哥结婚 Married(sister(Li),brother(Zhang))
-
个体是谓词
eg.SMITH作为一个工程师为IBM工作
Works(Engineer(SMITH),IBM)
-
函数可以递归调用。例如小李的祖父father(father(Li))
函数和谓词表面上很相似,其实完全不同;谓词的真值是真或假,而函数的值是个体域中的某个个体,无真值可言,知识一个个体到另一个个体的映射
2.2.3 谓词公式
-
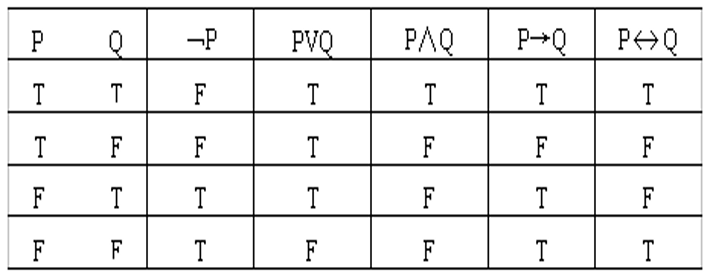
连接词(连词)
- 否定 ¬\neg¬:或“非”,表示否定位于它后面的命题
- 析取 ∨\vee∨:表示被它连接的两个命题具有”或”关系
- 合取 ∧\wedge∧:表示被它连接的两个命题具有”与”关系
- →\rightarrow→: 蕴涵,或者“条件” P→Q表示P蕴涵Q,即表示如果P则Q,其中,P称为条件的前件,Q称为条件的后件;例:如果刘华跑得快,那么他取得冠军RUN(Liuhua,faster)→WINS(Liuhua,champion)RUN(Liuhua,faster) \rightarrow WINS(Liuhua,champion)RUN(Liuhua,faster)→WINS(Liuhua,champion)
- →\rightarrow→ 只在P为真,F为假的时候才为假
- ↔\leftrightarrow↔ :等价,或“双条件”P→Q表示P当且仅当Q
-
量词(quantifier)
- 全称量词(universal):∀x\forall x∀x 对个体域中的所有个体x
- 存在量词(existential):∃x\exists x∃x 在个体域中存在x
- ∀x\forall x∀x∃yF(x,y)\exists yF(x, y)∃yF(x,y)表示对于个体域中的任何个体x都存在个体y,x与y是朋友。
∃x\exists x∃x∀yF(x,y)\forall yF(x, y)∀yF(x,y) 表示在个体域中存在个体x,与个体域中的任何个体y都是朋友。
∃x\exists x∃x∃yF(x,y)\exists yF(x, y)∃yF(x,y) 表示在个体域中存在个体x与个体y,x与y是朋友。
∀x\forall x∀x∀yF(x,y)\forall yF(x, y)∀yF(x,y) 表示对于个体域中的任何两个个体x和y,x与y都是朋友。 - 全称量词和存在量词出现的次序将影响命题的意思
-
谓词公式
(1) 单个谓词是谓词公式,称为原子谓词公式。
(2) 若A是谓词公式,则﹁A也是谓词公式。
(3) 若A,B都是谓词公式,则A∧B,A∨B,A→B,A↔BA\wedge B,A\vee B,A\rightarrow B,A\leftrightarrow BA∧B,A∨B,A→B,A↔B也都是谓词公式。
(4)若A是谓词公式,则 ( ∀\forall∀x) A,( ∃\exists∃x)A也是谓词公式。
(5)有限步应用(1)-(4)生成的公式也是谓词公式。- 连接词的优先级级别
¬,∧,∨,→,↔ \neg,\wedge,\vee,\rightarrow,\leftrightarrow ¬,∧,∨,→,↔
- 连接词的优先级级别
-
量词的辖域
-
位于量词后面的单个谓词或者用括弧括起来的谓词公式称为量词的辖域
-
辖域内与量词中同名的变元称为约束变元,不受约束的变元称为自由变元
eg.
(∃x)(P(x,y)→Q(x,y))∧R(x,y),R(x,y)中的x是自由变元,y全部都是自由变元 (\exists x)(P(x,y)\rightarrow Q(x,y)) \wedge R(x,y), R(x,y)中的x是自由变元,y全部都是自由变元 (∃x)(P(x,y)→Q(x,y))∧R(x,y),R(x,y)中的x是自由变元,y全部都是自由变元 -
2.2.4 谓词公式的性质
-
谓词公式的解释:
- 谓词公式在个体域上的解释:个体域中的实体对谓词演算表达式中每个常量、变量、谓词和函数符号的指派。对每个解释,都可求出一个真值
-
谓词公式的永真性、可满足性、不可满足性
- 如果谓词公式P对个体域D上的任何一个解释都取得真值T,则称P在D上是永真的;如果P在每个非空个体域上均永真,则称P永真。
- 如果谓词公式P对个体域D上的任何一个解释都取得真值F,则称P在D上是永假的;如果P在每个非空个体域上均永假,则称P永假。
- 对于谓词公式P,如果至少存在一个解释使得P在此解释下的真值为T,则称P是可满足的,否则,则称P是不可满足的。
-
谓词公式的等价性
- 设P与Q是两个谓词公式,D是它们共同的个体域,若对D上的任何一个解释,P与Q都有相同的真值,则称公式P和Q在D上是等价的。如果D是任意个体域,则称P和Q是等价的,记为P⟺QP\Longleftrightarrow QP⟺Q
-
谓词逻辑的永真蕴含
- 对于谓词公式P与Q,如果P→Q永真,则称公式P永真蕴含Q,且称Q为P的逻辑结论,称P为Q的前提,记为P⇒QP\Rightarrow QP⇒Q。
-
谓词逻辑的其他推理规则
-
P规则:在推理的任何步骤上都可引入前提。
-
T规则:在推理过程中,如果前面步骤中有一个或多个公式永真蕴含公式S,则可把S引入推理过程中
-
CP规则:如果能从任意引入的命题R和前提集合中推出S来,则可从前提集合推出R → S来。
-
例:
所有人都是会死的,诸葛亮是人,所以诸葛亮会死
∀x(Human(x)→Die(x))P规则\forall x(Human(x)\rightarrow Die(x)) P规则∀x(Human(x)→Die(x))P规则
Human(zhugeliang)P规则Human(zhugeliang) P规则Human(zhugeliang)P规则
Die(Zhugeliang)T规则Die(Zhugeliang) T规则Die(Zhugeliang)T规则
-
反证法:P⇒QP\Rightarrow QP⇒Q,当且仅当P∧¬Q⟺FP\wedge \neg Q \Longleftrightarrow FP∧¬Q⟺F,即Q为P的逻辑结论,当且仅当 P∧¬QP\wedge \neg QP∧¬Q是不可满足的。
Q为P1,P2,…,PnP_1,P_2,…,P_nP1,P2,…,Pn 的逻辑结论,当且仅当(P1∧P2∧…∧Pn)∧¬Q(P_1\wedge P_2 \wedge … \wedge P_n )\wedge \neg Q(P1∧P2∧…∧Pn)∧¬Q是不可满足的。
-
2.2.5 一阶谓词逻辑知识表示方法
谓词公式表示知识的步骤:
- 定义谓词及个体
- 对变元赋值
- 用连接词连接各个谓词,形成谓词公式
优点:自然性、精确性、严密性、容易实现
局限性:不能表示不确定的知识、组合爆炸、效率低
应用:自动问答系统、机器人行动规划系统、机器博弈系统、问题求解系统
2.3 产生式表示法
2.3.1 产生式
产生式常用于表示事实、规则以及它们的不确定性度量,适合于表示事实性知识和规则性知识
-
确定性规则知识的产生式表示
基本形式: if P THEN Q 或 P → Q
eg. if 动物会飞 and 会下蛋 then 该动物是鸟
-
不确定性规则知识的产生式表示
基本形式: if P THEN Q(置信度) 或 P→Q(置信度)
-
确定性事实性知识的产生式表示
三元组表示:(对象,属性,值)或(关系,对象1,对象2)
eg.老李年龄40 (Li,age,40)
老王和老李是朋友(friend,Li,Wang)
-
不确定性事实性知识的产生式表示
四元组表示:(对象,属性,值,置信度)或
(关系,对象1,对象2,置信度)
-
产生式与谓词逻辑中的蕴含式的区别:
(1)除逻辑蕴含外,产生式还包括各种操作、规则、变换、算子、函数等。例如,“如果炉温超过上限,则立即关闭风门”是一个产生式,但不是蕴含式。
(2)蕴含式只能表示精确知识,而产生式不仅可以表示精确的知识,还可以表示不精确知识。蕴含式的匹配总要求是精确的。产生式匹配可以是精确的,也可以是不精确的,只要按某种算法求出的相似度落在预先指定的范围内就认为是可匹配的。 -
产生式的形式描述及语义——巴科斯范式BNF
符号“::=”表示“定义为”;符号“|”表示“或者是”;符号“[ ]”表示“可缺省”。
2.3.2 产生式系统
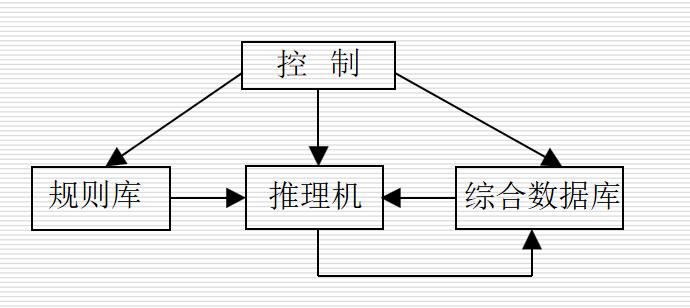
把一组产生式放在一起,让它们互相配合,协同作用,一个产生式生成的结论可以供另一个产生式作为已知事实使用,以求得问题的解
规则库:用于描述相应领域内知识的产生式集合
综合数据库:(事实库、上下文、黑板等)一个用于存放问题求解过程中各种当前信息的数据结构,如问题的初始状态、原始证据、推理中得到的中间结论以及最终结论
推理机(控制系统):由一组程序组成,除了推理算法,还控制整个产生式系统的运行,实现对问题的求解;推理机主要做以下几项工作
-
推理:从规则库中选择与综合数据库中的已知事实进行匹配。
-
冲突消解:匹配成功的规则可能不止一条,进行冲突消解。
-
执行规则:(1)执行某一规则时,如果其右部是一个或多个结论,则把这些结论加入到综合数据库中:如果其右部是一个或多个操作,则执行这些操作。(2)对于不确定性知识,在执行每一条规则时还要按一定的算法计算结论的不确定性。
-
检查推理终止条件:检查综合数据库中是否包含了最终结论,决定是否停止系统的运行。
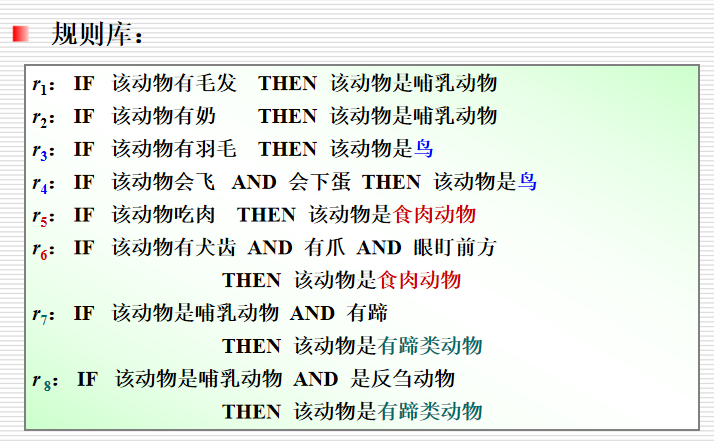



2.3.4 产生式表示法的特点
-
优点
- 自然性
- 模块性
- 有效性
- 清晰性
-
缺点
- 效率不高
- 不能表达具有结构性的知识
-
适合产生式表达的知识
- 领域知识间关系不密切,不存在结构关系。
- 经验性及不确定性的知识,且相关领域中对这些知识没有严格、统一的理论。
- 领域问题的求解过程可被表示为一系列相对独立的操作,且每个操作可被表示为一条或多条产生式规则。
2.4 框架表示法
2.4.1 框架的一般结构
-
框架(frame):一种描述所论对象(一个事物、事件或概念)属性的数据结构
-
一个框架由若干个被称为槽(slot)的结构组成;
-
每一个槽可根据实际情况划分为若干个侧面(facet);
-
一个槽用于描述所论对象某一方面的属性;一个侧面用于描述相应属性的一个方面;
框架名: <教师>
姓名:单位(姓、名)
年龄:单位
......

- 当把具体的信息填入槽或侧面后,就得到了相应框架的一个事例框架
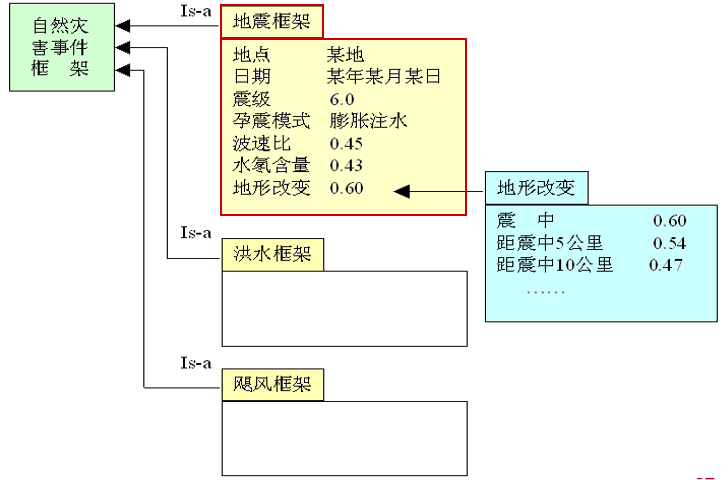
2.4.3 框架表示法的特点
-
结构性
便于表达结构性知识,能够将知识的内部结构关系及知识间的联系表示出来
-
继承性
框架网络中,下层框架可以继承上层框架的槽值,也可以进行补充和修改
-
自然性
框架表示法与人在观察事物时的思维活动是一致的,比较自然
2.5 知识图谱
2.5.1 知识图谱的提出
- 互联网内容有大规模、异质多元、组织结构松散等特点
- 知识图谱是一种互联网环境下的知识表示方法,目的是为了提高搜索引擎的能力,改善用户的搜索质量以及搜索体验。
2.5.2 知识图谱的定义
-
知识图谱:又称科学知识图谱,用各种不同的图形等可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系
-
知识图谱由一些相互连接的实体及其属性构成的
-
三元组是知识图谱的一种通用表示方式(实体1-关系-实体2)(实体-属性-属性值)
2.5.3 知识图谱的表示
知识图谱也被看作是一张图,图中的节点表示实体或概念,而图中的边则由属性或关系组成。
2.5.4 知识图谱的架构
- 知识图谱的逻辑结构
- 模型层和数据层
- 数据层由一系列事实组成,而知识以事实为单位进行存储
- 模型层构建在数据层之上,是知识图谱的核心
- 知识图的体系架构
-
结构化数据:知识定义和表示都比较完备的数据
-
半结构化数据:部分数据是结构化的,但存在大量结构化程度较低的数据
-
非结构化数据:没有定义和规范约束的“自由”数据
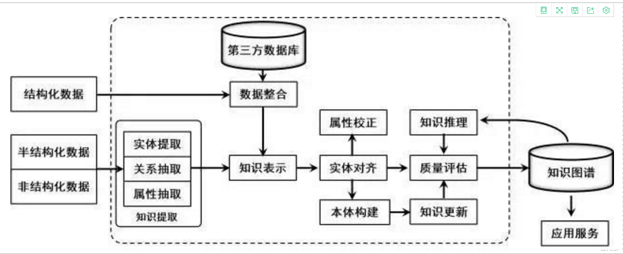
2.5.5 知识图谱的构建
- 自顶向下:先为知识图谱定义好本体与数据模式,再将实体加入到知识库
- 自底向上:从一些开放链数据中提取出实体,选择其中置信度较高的加入到知识库,再构建顶层的本体模式
- 应用:维基百科
Chapter 3 确定性推理方法
3.1 推理的基本概念
3.1.1 推理的定义
人们在对各种事务进行分析、综合并做出最后决策时,通常是从已知事实出发,并运用已掌握的知识,找出其中蕴涵的试试,或归纳出新的事实,这一过程通常称为推理
3.1.2 推理方式及其分类
-
演绎推理、归纳推理、默认推理
-
演绎推理(deductive reasoning) 一般 → 个别
三段论式(三段论法)
eg. 足球运动员的身体都是强壮的;(大前提)
A是一名足球运动员(小前提) ⇒ A的身体是强壮的(结论)
-
归纳推理(inductive reasoning) 个别 → 一般
完全归纳推理(必然性推理)
不完全归纳推理(非必然性推理)
eg.检验所有产品(完全归纳推理) vs 抽取部分样品检验(不完全归纳推理)
-
默认推理 (default reasoning缺省推理):知识不完全的情况下假设某种条件已经具备所进行的推理
-
-
确定性推理&不确定性推理
- 确定性推理:推理时所用的知识和证据都是确定的,推出的结论也是确定的,其真值为真或假
- 不确定性推理:推理时所用的知识和证据不都是确定的,推出的结论也是不确定的
- 似然推理(概率论)
- 近似推理或模糊推理(模糊逻辑)
-
单调推理&非单调推理
-
单调推理:随着推理向前推进及新知识的加入,推出的结论越来越接近最终目标,基于经典逻辑的演绎推理
-
非单调推理:由于新知识的加入,不仅没有加强已推出的结论,反而要否定它,使推理退回到前面的某一步,重新开始默认推理是非单调推理
- 启发式推理&非启发式推理
- 启发性知识:与问题有关且能加快推理过程,提高搜索效率的知识

3.1.3 推理的方向
-
正向推理:以已知事实作为出发点的一种推理,已知事实→\rightarrow→结论
-
基本思想:
(1)从初始已知事实出发,在知识库KB中找出当前可适用的知识,构成可适用知识集KS。
(2)按某种冲突消解策略从KS中选出一条知识进行推理,并将推出的新事实加入到数据库DB中作为下一步推理的已知事实,再在KB中选取可适用知识构成KS 。
(3)重复(2),直到求得问题的解或KB中再无可适用的知识。
-
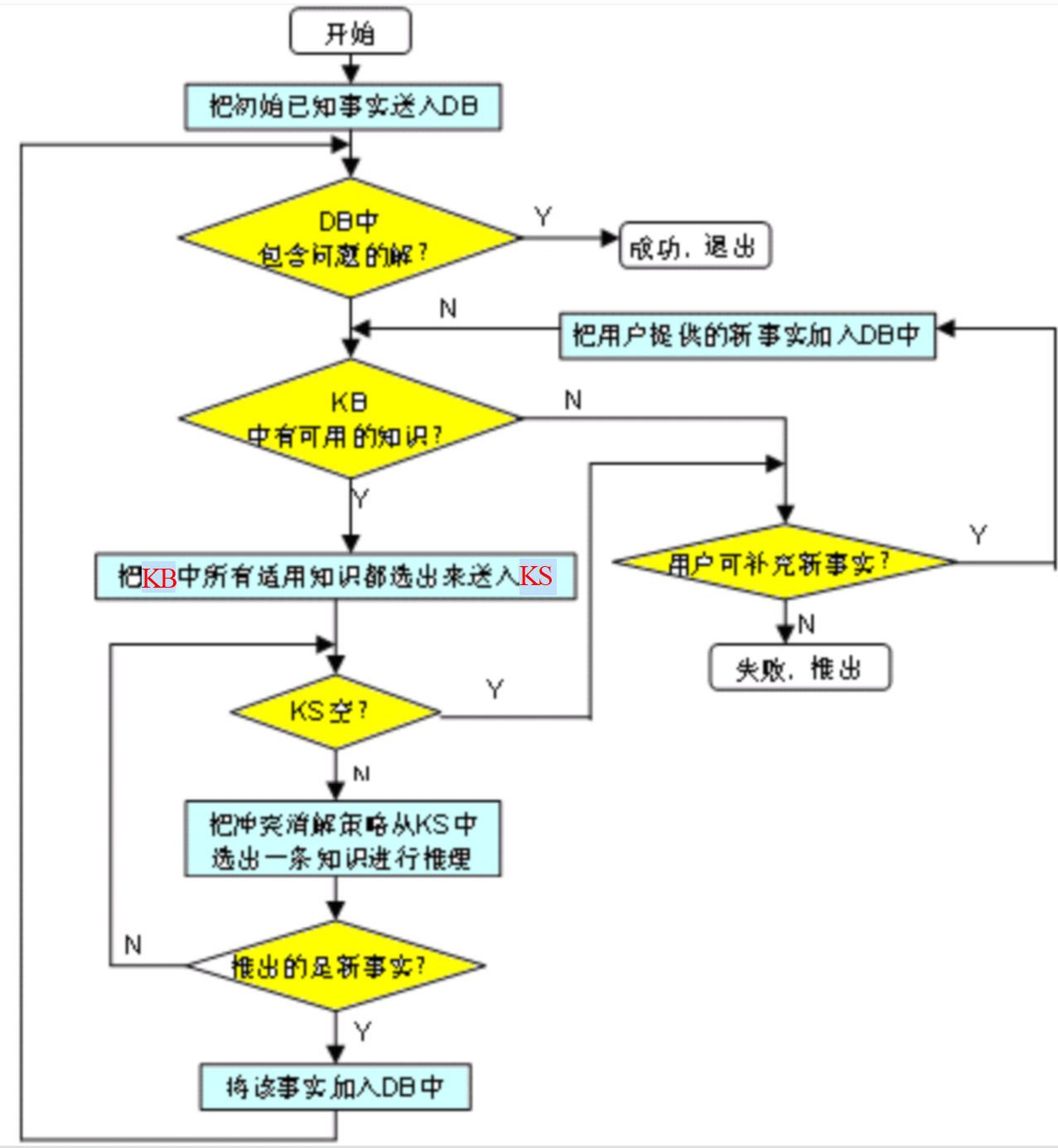
实现正向推理需要解决的问题:
- 确定匹配(知识与已知事实)的方法
- 按什么策略搜索知识库
- 冲突消解策略
特点:正向推理简单,易实现,但目的性不强,效率低
-
逆向推理(目标驱动推理):以某个假设目标作为出发点
基本思想:
- 选定一个假设目标。
- 寻找支持该假设的证据,若所需的证据都能找到,则原假设成立;若无论如何都找不到所需要的证据,说明原假设不成立的;为此需要另作新的假设。
主要优点:不必使用与目标无关的知识,目的性强,同时他还有利于向用户提供解释
主要缺点:起始目标的选择具有盲目性
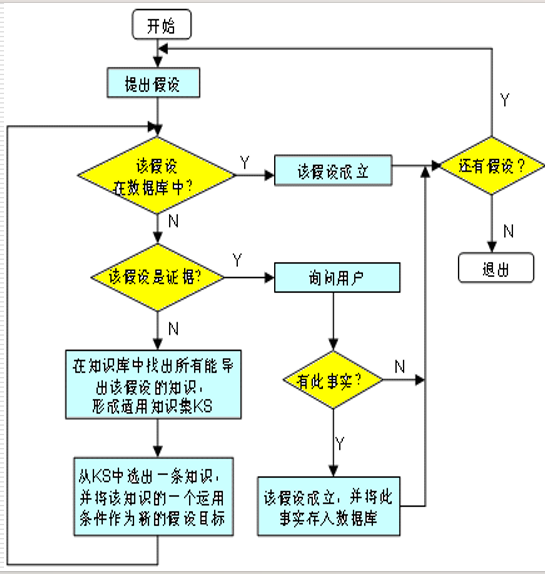
需要解决的问题:
- 如何判断一个假设是否是证据
- 当导出假设的知识有多条时,如何确定先选哪一条
- 一条知识的运用条件一般都有多个,当其中的一个经验证成立后,如何自动地转换为对另一个的验证
逆向推理:目的性强,利于向用户提供解释,但选择初始目标时具有盲目性,比正向推理复杂
-
混合推理
- 正向:盲目,效率低
- 逆向:若提出的假设目标不符合实际,会降低效率
-
先正向后逆向:先正向推理,帮助选择某个目标,即从已知事实演绎出部分结果,然后再用逆向推理证实该目标或提高其可信度
-
先逆向后正向:先假设一个目标进行逆向推理,然后再利用逆向推理中得到的信息再进行正向推理,以推出更多的结论
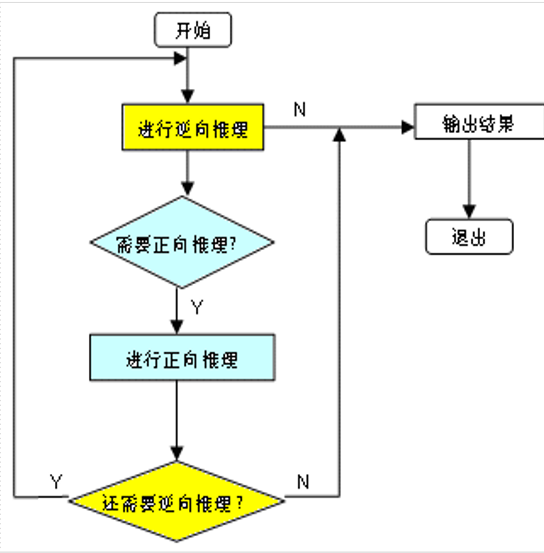
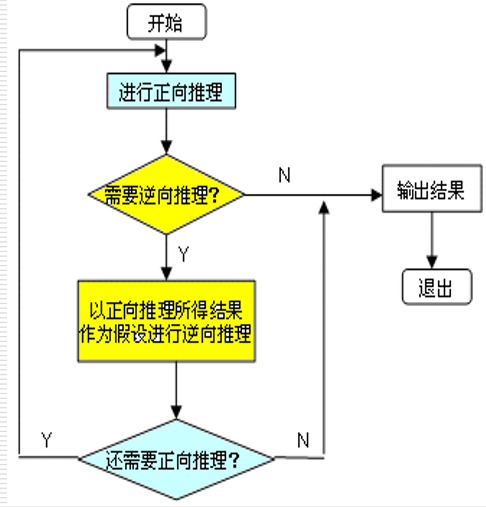
在下述情况中,也需要进行混合推理
-
已知事实不充分
-
正向推理推出的结论可信度不高
-
希望得到更多结论
-
双向推理:正向推理和逆向推理同时进行,且在推理过程中的某一步骤上“碰头”
3.1.4 冲突消解策略
已知事实与知识的三种匹配情况
- 恰好匹配成功(一对一)
- 不能与任何知识匹配成功:知识库中缺少某些必要的知识
- 多种匹配成功(一对多、多对一、多对多)——这时候就需要进行冲突消解
多种冲突消解策略
- 按针对性排序
- 按已知事实的新鲜性排序
- 按匹配度排序
- 按条件个数排序(优先应用条件少的产生式规则,因为条件少的规则匹配时花费的时间少)
3.2 自然演绎推理
-
定义:从一组已知为真的事实出发,运用经典逻辑的推理规则推出结论的过程
-
推理规则:P规则、T规则、假言推理、拒取式推理
假言推理:P,P→Q⇒QP,P\rightarrow Q \Rightarrow QP,P→Q⇒Q
如果x是金属,则x能导电,铜是金属,推出“铜能导电”
拒取式推理:P→Q,¬Q⇒¬PP\rightarrow Q, \neg Q \Rightarrow \neg PP→Q,¬Q⇒¬P
如果下雨,则地上就湿,地上不湿,没有下雨
-
拒取式推理有可能出现两个错误
-
否定前件,如果下雨,地上湿;没下雨,地上不湿
-
肯定后件,如果下雨,地上湿;地上湿,下雨
如果行星系统以太阳为中心,则金星会有相位变化;金星有相位变化,所以,行星系统以太阳为中心
-
-



优点:
- 表达定理证明过程自然,易理解
- 拥有丰富的推理规则,推理过程灵活
- 便于嵌入领域启发式知识
缺点:
易产生组合爆炸,得到的中间结论一般呈指数式递增
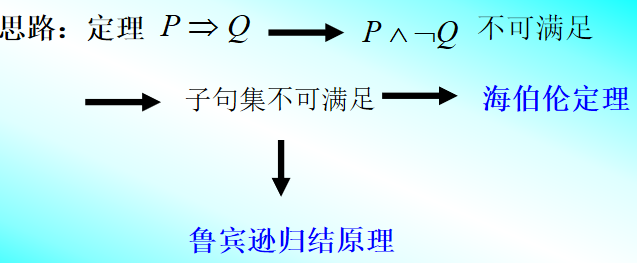
3.3 谓词公式化为子句集的方法(归结演绎推理)
反证法: 反证法:P⇒QP\Rightarrow QP⇒Q,当且仅当P∧¬Q⟺FP\wedge \neg Q \Longleftrightarrow FP∧¬Q⟺F,即Q为P的逻辑结论,当且仅当 P∧¬QP\wedge \neg QP∧¬Q是不可满足的。
Q为P1,P2,…,PnP_1,P_2,…,P_nP1,P2,…,Pn 的逻辑结论,当且仅当(P1∧P2∧…∧Pn)∧¬Q(P_1\wedge P_2 \wedge … \wedge P_n )\wedge \neg Q(P1∧P2∧…∧Pn)∧¬Q是不可满足的。
思路:
- 原子(atom)谓词公式:一个不能再分解的命题
- 文字(literal):原子谓词公式及其否定
- P:正文字;¬P\neg P¬P:负文字
- 子句(clause):任何文字的析取式。任何文字本身也都是子句
- 空子句(NIL):不包含任何文字的子句;空子句是永假的,不可满足的
- 子句集:由子句构成的集合
空子句不能被任何解释按住,是永假的、不可满足的
将谓词公式化为子句集
-
消去谓词公式中的→\rightarrow→和 ↔\leftrightarrow↔ 符号
- 利用谓词的等价关系:
P→Q⇔P∨QP↔Q⇔(P∧Q)∨(¬P∧¬Q) P\rightarrow Q \Leftrightarrow P \vee Q \\ P\leftrightarrow Q \Leftrightarrow (P\wedge Q)\vee (\neg P \wedge \neg Q) P→Q⇔P∨QP↔Q⇔(P∧Q)∨(¬P∧¬Q)
- 利用谓词的等价关系:
-
把否定符号移到紧靠谓词的位置上
-
双重否定律
¬(¬P)⇔P \neg(\neg P)\Leftrightarrow P ¬(¬P)⇔P -
德摩根律
¬(P∧Q)⇔¬P∨¬Q¬(P∨Q)⇔¬P∧¬Q \neg(P\wedge Q)\Leftrightarrow\neg P \vee \neg Q \\ \neg(P\vee Q)\Leftrightarrow\neg P \wedge \neg Q \\ ¬(P∧Q)⇔¬P∨¬Q¬(P∨Q)⇔¬P∧¬Q -
量词转换律
¬(∀x)P⇔(∃x)¬P¬(∃x)P⇔(∀x)¬P \neg(\forall x)P\Leftrightarrow (\exists x)\neg P \\ \neg(\exists x)P\Leftrightarrow (\forall x)\neg P ¬(∀x)P⇔(∃x)¬P¬(∃x)P⇔(∀x)¬P
-
-
变量标准化
使不同的量词约束变元有不同的名字
-
消去存在量词
一种情况是存在量词不出现在全称量词的辖域内
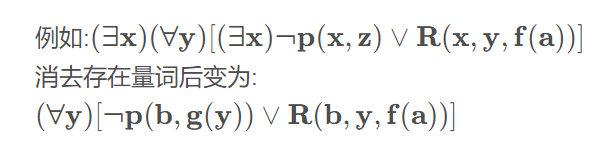
另一种情况是存在量词出现在一个或多个全称量词的辖域内
!!!这个怎么换的看课本
-
化为前束形
前束型=(前缀){母式}
-
化为Skolem标准形
标准形式为
(∀x1)(∀x2)…(∀xn)M (\forall x_1)(\forall x_2)…(\forall x_n)M (∀x1)(∀x2)…(∀xn)M
M是子句的合取式,一般利用
P∨(Q∧R)⇔(P∨Q)∧(P∨R)P∧(Q∨R)⇔(P∧Q)∨(P∧R) P\vee (Q\wedge R)\Leftrightarrow (P\vee Q)\wedge(P\vee R) \\ P\wedge (Q\vee R)\Leftrightarrow (P\wedge Q)\vee(P\wedge R) P∨(Q∧R)⇔(P∨Q)∧(P∨R)P∧(Q∨R)⇔(P∧Q)∨(P∧R) -
略去全称量词
-
消去合取词
把所有的合取符号去掉,变成词组
-
子句变量标准化:使每个子句中变量符号不同
谓词公式不可满足的充要条件是其子句集不可满足
3.4 鲁宾逊归结原理
子句集中子句之间是合取关系,只要有一个子句不可满足,则子句集就不可满足。
鲁宾逊归结原理(消解原理)的基本思想
- 检查子句集S中是否包含空子句,若包含,则S不可满足
- 若不包含,在S中选择合适的子句进行归结,一旦归结出空子句,就说明S是不可满足的
这里一堆推论定义看课本
- 对与谓词逻辑,归结式是其亲本子句的逻辑结论
- 对于一阶谓词逻辑,则若子句集是不可满足的,则必存在一个从该子句集到空子句的归结演绎;若从子句集存在一个到空子句的演绎,则该子句集是不可满足的
- 如果没有归结出空子句,则既不能说S不可满足,也不能说S是可满足的
3.5 归结反演
应用归结原理证明定理的过程称为归结反演
用归结反演证明的步骤是
- 将已知前提表示为谓词公式F
- 将待证明的结论表示为谓词公式Q,并否定得到非Q
- 把谓词公式集{F,非Q}化为子句集S
- 应用归结原理对子句集S中的子句进行归结,并把每次归结得到的归结式都并入到S中。如此反复进行,若出现了空子句,则停止归结,此时就证明了Q为真。
3.6 应用归结原理求解问题
看课本例题
Chapter 4 不确定性推理方法
现实世界存在随机性和模糊性反应到知识和证据上,就形成了不确定性的知识和不确定性的证据。
4.1 不确定性推理的基本问题
推理:从已知事实(证据)出发,通过运用相关知识逐步推出结论或者证明某个假设成立或不成立的思维过程
不确定性推理:从不确定性的初始证据出发,通过运用不确定性的知识,最终推出具有一定程度的不确定性但却是合理或者近乎合理的结论的思维过程
- 不确定性的表示与度量
-
知识不确定性的表示:在专家系统中知识的不确定性一般是由领域专家给出的,通常是一个数值,它表示相应知识的不确定性程度,称为知识的静态强度
-
证据不确定性的表示
- 用户在求解问题时提供的初始证据;
- 在推理中用前面推出的结论作为当前推理的证据
-
不确定性的度量
- 能充分表达相应知识及证据不确定性的程度
- 度量范围的指定便于领域专家及用户对不确定性的估计
- 便于对不确定性的传递进行计算,而且对结论算出的不确定性量度不能超出度量规定的范围
- 度量的确定应当是直观的,同时应有相应的理论依据
- 不确定性匹配算法及阈值
-
不确定性匹配算法:用来计算匹配双方相似程度的算法
-
阈值:用来指出相似的限度
- 组合证据不确定性的算法
- 最大最小方法、Hamacher方法、概率方法、有界方法、Einstein方法等。
- 不确定性的传递算法
-
在每一步推理中,如何把证据及知识的不确定性传递给结论
-
在多步推理中,如何把初始证据的不确定性传递给最终结论
- 结论不确定性的合成
4.2 可信度方法
- 可信度方法:1975年肖特里菲等人在确定性理论的基础上,结合概率论等提出的一种不确定性推理方法
-
优点:直观、简单,且效果好
-
可信度:根据经验对一个事物或现象为真的相信程度
-
可信度带有较大的主观性,其准确性难以把握
-
C-F模型是基于可信度表示的不确定性推理的基本方法
-
知识的不确定性的表示
IF E THEN H (CF(H,E))
CF(H,E):可信度因子,反映前提条件与结论的联系强度
CF(H,E)取值范围是[-1,1]
- 若由于相应证据的出现增加结论H为真的可信度,则CF(H,E)>0,证据的出现越是支持H为真,就使CF(H,E)的值越大。
- 反之,CF(H,E)<0,证据的出现越是支持H为假,CF(H,E)的值就越小
- 若证据的出现与否与H无关,则CF(H,E)=0
-
证据不确定性的表示
CF(E)=0.6:E的可信度为0.6
证据E的可信度取值范围[-1,1]
- 对于初始证据,若所有观察S能肯定它为真,则CF(E)=1;若肯定为假,-1
- 若以某种程度为真,则0<CF(E)<1
- 若以某种程度为假,则-1<CF(E)<0
- 若未获得任何相关观察,则CF(E)=0
- 静态强度CF(H,E):知识的强度,即当E所对应的证据为真时对H的影响强度
- 动态强度CF(E):证据E当前的不确定程度
-
组合证据的不确定性的算法
-
组合证据:多个单一证据的合取
E=E1 AND E2… EnE= E_1 \ AND \ E_2…\ E_nE=E1 AND E2… En
CF(E)=min{CF(E1),CF(E2),…CF(En)}CF(E)=min\{ CF(E_1),CF(E_2),…CF(E_n)\}CF(E)=min{CF(E1),CF(E2),…CF(En)}
-
组合证据:多个单一证据合取
E=E1 OR E2… OR EnE= E_1 \ OR \ E_2…\ OR\ E_nE=E1 OR E2… OR En
CF(E)=max{CF(E1),CF(E2),…,CF(En)}CF(E)=max\{CF(E_1),CF(E_2),…,CF(E_n)\}CF(E)=max{CF(E1),CF(E2),…,CF(En)}
-
-
不确定性的传递算法
- C-F模型中的不确定性推理:从不确定的初始证据出发,通过运用相关的不确定性知识,最终推出结论并求出结论的可信度值。结论 H 的可信度由下式计算:
CF(E)=CF(H,E)×max{0,CF(E)}当CF(E)<0时,则CF(H)=0当CF(E)=1时,则CF(H)=CF(H,E) CF(E)=CF(H,E)×max\{0,CF(E)\} \\ 当CF(E)<0时,则CF(H)=0 \\ 当CF(E)=1时,则CF(H)=CF(H,E) CF(E)=CF(H,E)×max{0,CF(E)}当CF(E)<0时,则CF(H)=0当CF(E)=1时,则CF(H)=CF(H,E)
- C-F模型中的不确定性推理:从不确定的初始证据出发,通过运用相关的不确定性知识,最终推出结论并求出结论的可信度值。结论 H 的可信度由下式计算:







4.3 证据理论
- 证据理论又称D-S理论
4.3.1 概率分配函数
-
设 D 是变量 x 所有可能取值的集合,且 D 中的元素是互斥的,在任一时刻 x 都取且只能取 D 中的某一个元素为值,则称 D 为 x 的样本空间。
-
在证据理论中,D 的任何一个子集 A 都对应于一个关于 x 的命题,称该命题为“ x 的值是在 A 中”。
-
设 x :所看到的颜色,D={红,黄,蓝},
则 A={红}:“ x 是红色”;
A={红,蓝}:“x 或者是红色,或者是蓝色”。


-
对以上说明,分别有以下几个例子


4.3.2 信任函数



4.3.3 似然函数
似然函数:不可驳斥函数或上限函数

4.3.4 概率分配的正交和(证据的组合)



4.3.5 基于证据理论的不确定性推理
-
基于证据理论的不确定性推理的步骤
- 建立问题的样本空间D
- 由经验给出,或者由随机性规则和事实的信度度量求得基本概率分配函数
- 计算所关心的子集信任函数值、似然函数值
- 由信任函数值、似然函数值得出结论




4.4 模糊推理方法
4.4.1 模糊逻辑的提出和发展
4.4.2 模糊集合
- 模糊集合的定义:
-
论域:所讨论的全体对象,用U等表示
-
元素:论域中的每个对象,用a,b,c,x,y,za,b,c,x,y,za,b,c,x,y,z表示
-
集合:论域中具有某种相同属性的、确定的、可以彼此区别的元素的全体,用A、B表示
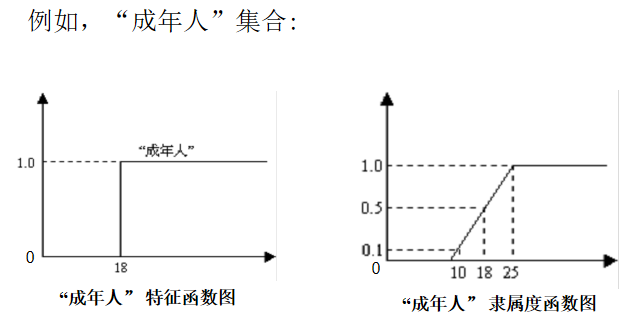
-
隶属度:模糊逻辑给集合中每一个元素赋予一个介于0和1之间的实数,描述其属于一个集合的强度,该实数称为属于一个集合的隶属度
-
隶属函数:集合中所有元素的隶属度全体构成集合的隶属函数
-
模糊集合对的表示方法
- 模糊集合中不仅要列出属于这个集合的元素,还要注明这个元素属于这个集合的隶属度

-
Zadeh表示法
- 论域是离散且元素数目有限

- 论域是连续的,或元素数目无限(积分表示)
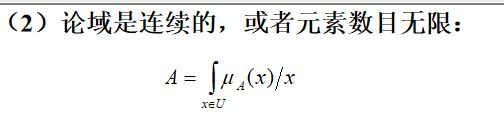
- 序偶表示法
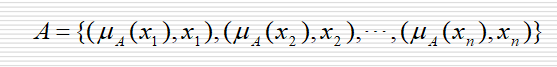
- 向量表示法
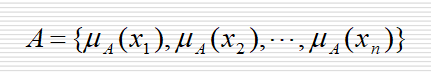
- 隶属函数
-
常见的隶属函数有正态分布、三角分布、梯形分布等
-
确定方法
- 模糊统计法
- 专家经验法
- 二元对比排序法
- 基本概念扩充法

4.4.3 模糊集合的运算
-
模糊集合的包含关系
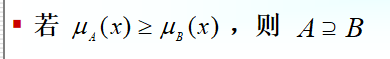
-
模糊集合的相等关系
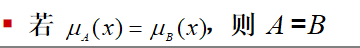
-
模糊集合对的交并补运算
- 交运算
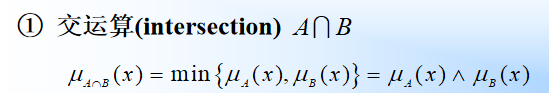
- 并运算
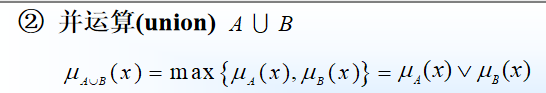
- 补运算
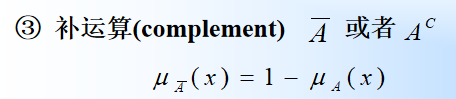
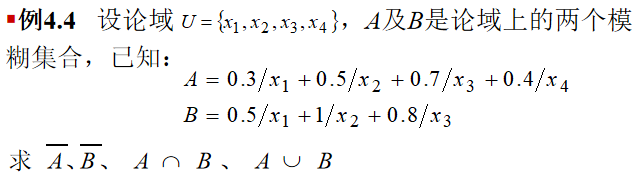

-
模糊集合的代数运算
- 代数积
- 代数和
- 有界和
- 有界积
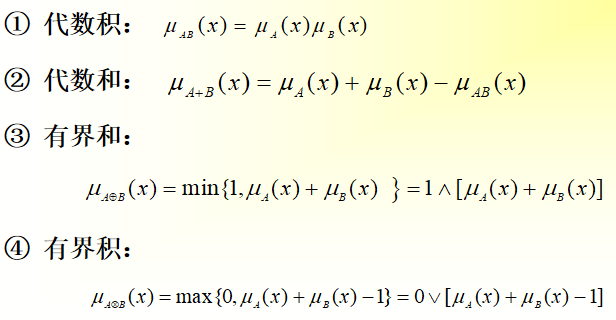

4.4.4 模糊关系与模糊关系的合成
普通关系:描述两个集合中的元素之间是否有关联
模糊关系:两个模糊集合中的元素之间的关联程度
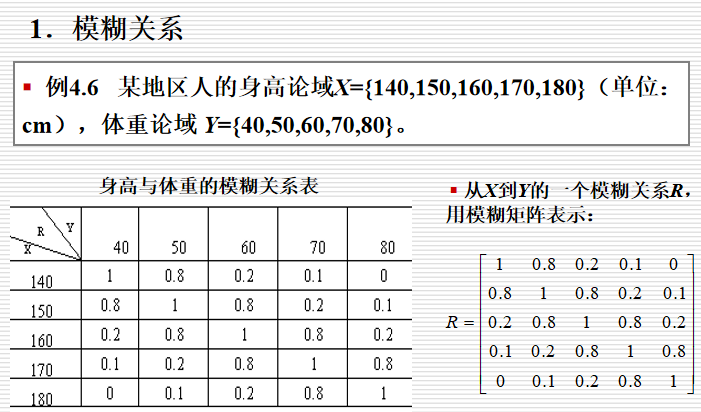
- 模糊关系




-
模糊关系的合成
设模糊关系Q∈X×Y,R∈Y×Z,则模糊关系S∈X×Z称为模糊关系Q与R的合成。模糊关系Q与模糊关系R的合成S是模糊矩阵的叉乘S=Q∘R 设模糊关系Q\in X×Y,R\in Y×Z,则模糊关系S\in X×Z称为模糊关系Q与R的合成。\\ 模糊关系Q与模糊关系R的合成S是模糊矩阵的叉乘S=Q\circ R 设模糊关系Q∈X×Y,R∈Y×Z,则模糊关系S∈X×Z称为模糊关系Q与R的合成。模糊关系Q与模糊关系R的合成S是模糊矩阵的叉乘S=Q∘R -
- 最大-最小合成法:写出矩阵乘积QR中的每个元素,然后将其中的乘积运算用小运算代替,求和用大运算代替
- 最大-代数积合成法:写出矩阵乘积QR中的每个元素,然后将其中的求和运算用取大运算代替,而乘积运算不变
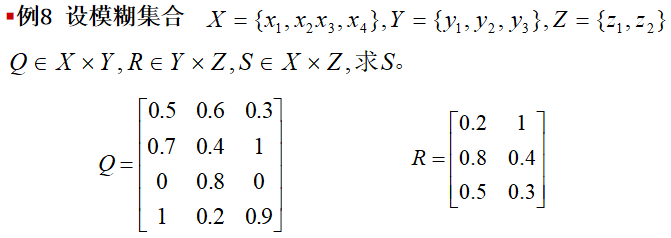

4.4.5 模糊推理
-
模糊知识表示:人类思维判断的基本形式
如果(条件) → 则(结论)
这种隶属度表示法,一般是一种针对对象的表示方法。
模糊知识表示一般形式为(<对象>,<属性>(<属性值>,<隶属度>))
模糊规则:从条件论域到结论论域的模糊关系矩阵R,通过条件模糊向量与模糊关系R的合成进行模糊推理,得到的模糊向量,然后采用“清晰化”方法将模糊结论转换为精确量。
-
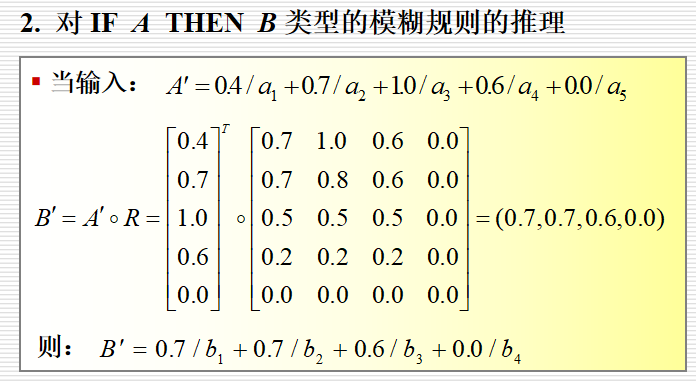
对IF A THEN B类型的模糊规则的推理

4.4.6 模糊决策
-
由上述模糊推理得到的结论或者操作是一个模糊向量,不能直接应用,需要先转化为确定值。将模糊推理得到的模糊向量,转换为确定值的过程叫做“模糊决策”或者“模糊判决”“清晰化”“反模糊化”(defuzzification)等等
-
最大隶属度法:在模糊向量中,取隶属度最大的量作为推理结果。
- 优点是简单易行,缺点是完全排除了其他隶属度较小的量的影响和作用,没有充分利用推理过程取得的信息。
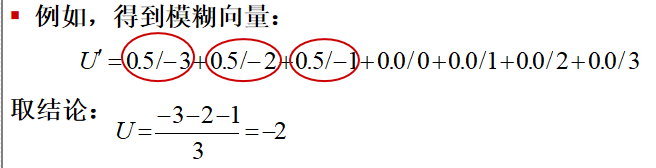
- 加权平均判决法:为克服最大隶属度法的缺点

-
中位数法:就是把模糊集的中位数作为系统控制量
- 与最大隶属度法相比,利用了更多的信息,但计算比较复杂,特别是在连续隶属度函数时,需要求解积分方程,因此应用场合比加权平均法少
- 加权平均法比中位数法有更好地性能,而中位数法的动态性能要优于加权平均法,静态性能略逊于加权平均法。使用中位数法的模糊控制器类似于多级继电器控制,加权平均法类似于PI控制器。一般情况下,都优于最大隶属度法。
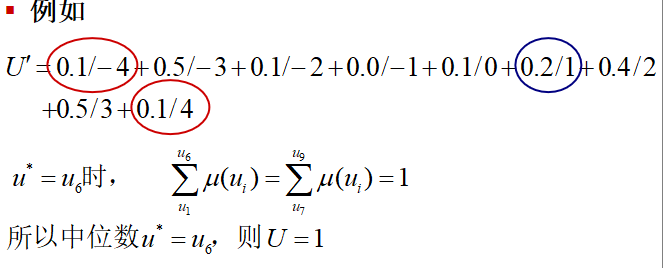
4.4.7 模糊推理的运用


Chapter 5 搜索求解策略
求解问题时,涉及两个方面,一是该问题的表示,而是选择合适的求解方法。问题求解的基本方法有搜索法、归约法、归结法、推理法及产生式等。
5.1 搜索的概念
搜索的基本问题与主要过程
在搜索中需要解决的基本问题
- 是否一定能找到一个解
- 找到的解是否为最佳解
- 时间与空间复杂性如何
- 搜索过程是否终止运行或是否会陷入一个死循环
搜索的主要过程
- 从初始或目的状态出发,并将它作为当前状态
- 扫描操作算子集,将适用当前状态的一些操作算子作用在其上而得到新的状态,并建立指向其父节点的指针
- 检查所生成的新状态是否满足结束状态,如果满足,则得到问题的一个解,并可沿着有关指针从结束状态反向到达开始状态,给出一解答路径;否则,将新状态作为当前状态,返回第(2)步再进行搜索。
5.1.2 搜索策略
-
搜索方向
- 数据驱动:从初始状态出发的正向搜索(从问题给出的条件出发)
- 目的驱动:从目的状态出发的逆向搜索(从想达到的目的入手,看哪些操作算子能产生该目的以及应用这些操作段子产生目的时需要哪些条件
- 双向搜索:从开始状态出发作正向搜索,同时从目的状态出发作逆向搜索,直到汇合
-
盲目搜索与启发式搜索
- 盲目搜索:在不具有对特定问题的任何有关信息的条件下,按固定的步骤(依次或随机调用操作算子的步骤)进行的搜索
- 启发式搜索:考虑特定问题领域可应用的知识,动态的确定调用操作算子的步骤,优先选择较适合的操作算子,尽量减少不必要的搜索,以求尽快的到达结束状态。
5.2 状态空间的搜索策略
5.2.1 状态空间表示法
状态空间表示法是知识表示的一种基本方法
状态:表示系统状态、事实等叙述型知识的一组变量或数组
Q=[q1,q2,…,qn]T Q=[q_1,q_2,…,q_n]^T Q=[q1,q2,…,qn]T
操作:表示引起状态变化的过程型知识的一组关系或函数
F={f1,f2,…,fm} F=\{f_1,f_2,…,f_m\} F={f1,f2,…,fm}
状态空间:利用状态变量和操作符号,表示系统或问题的有关知识的符号体系,是一个四元组(S,O,S0,G)(S,O,S_0,G)(S,O,S0,G)
S:状态集合,S中每一个元素表示一个状态,状态是某种结构的符号和数据。
O:操作算子集合,利用算子可以从一种状态转换为另一种状态
S0S_0S0:初始状态集合,S的非空子集
G:若干具体状态,或满足某些性质的路径信息描述,包含问题的目的状态
求解路径:从S0S_0S0结点到GGG结点的路径
状态空间解:一个有限的操作蒜子序列。

O1,…,OKO_1,…,O_KO1,…,OK称为状态空间的一个解
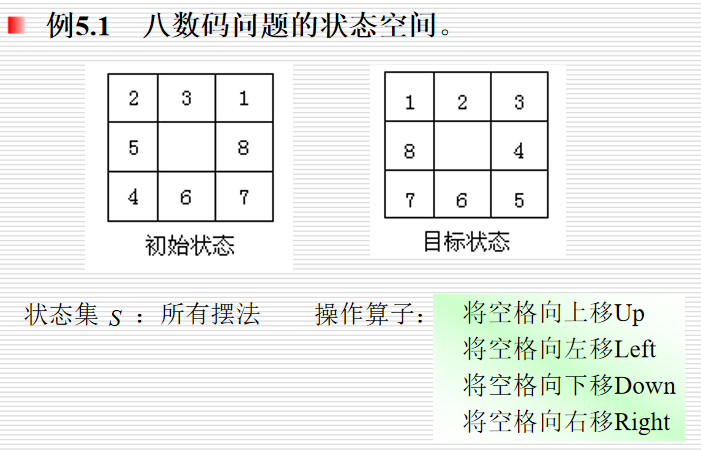
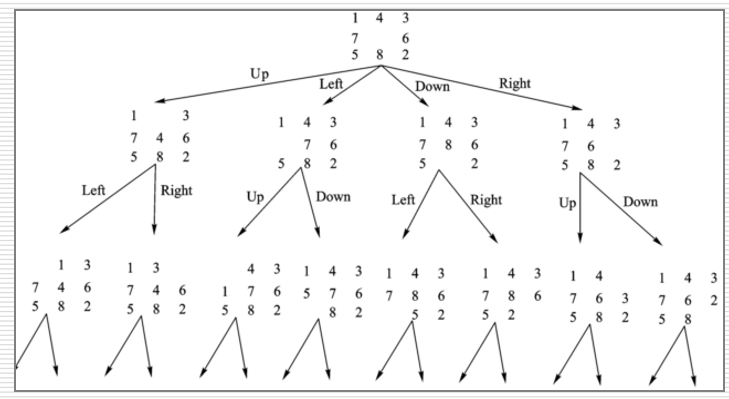
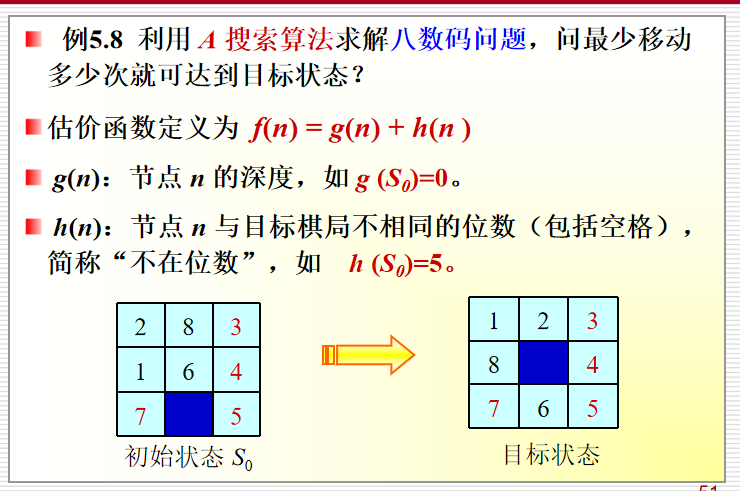
例:八数码问题
(移的是空格)
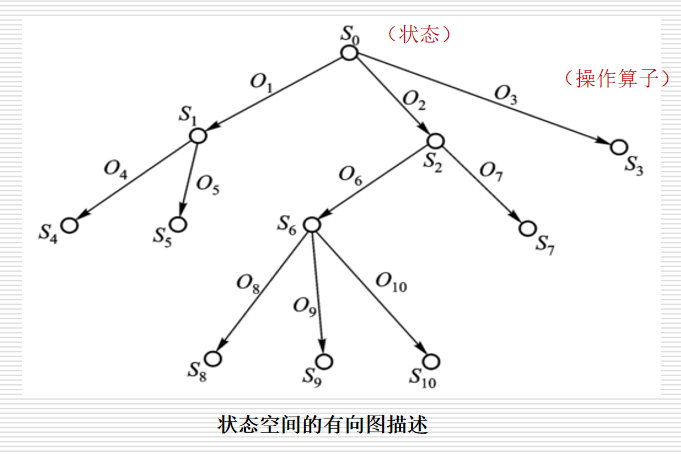
5.2.2 状态空间的图描述
状态空间可以用有向图来描述,图的结点表示问题的状态,图的弧表示状态之间的关系,就是求解问题的步骤
例:旅行商问题: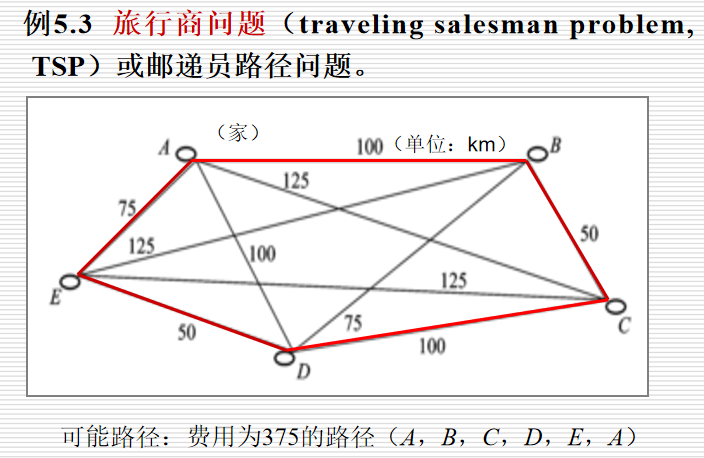
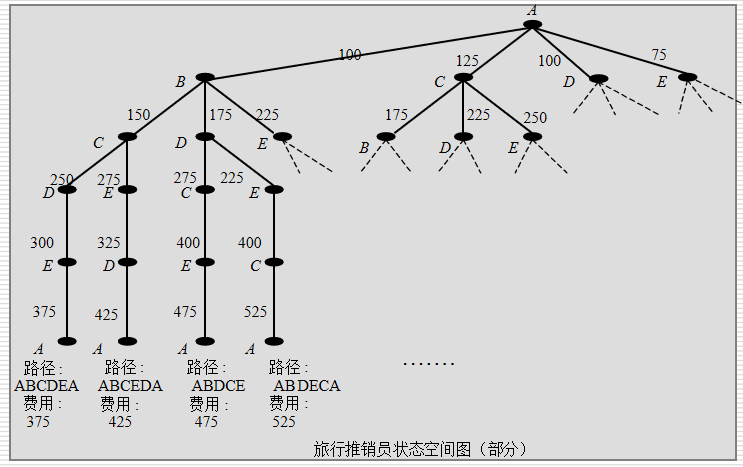
状态空间搜索是搜索某个状态空间以求得操作算子序列的一个解答的过程。这种搜索是状态空间问题求解的基础
搜索策略的主要任务是确定选取操作算子的方式,有盲目搜索和启发式搜索。
5.3 盲目的图搜索策略
5.3.1 回溯策略
-
带回溯策略对的搜索:从初始状态出发,不停地、试探性地寻找路径,直到它到达目的或“不可解结点”,即“死胡同”为止
-
若它遇到不可解结点就回溯到路径中最近的父结点上,查看该结点是否还有其他的子结点未被扩展。若有,则沿这些子结点继续搜索;如果找到目标,就成功退出搜索,返回解题路径。
- 回溯策略的算法
- PS(path states)表:保存当前搜索路径上的状态
- NPS(new path states)表:新的路径状态表,它包含了等待搜索的状态,其后裔状态还未被搜索到,即未被生成扩展
- NSS(no solvable states)表:不可解状态表,列出了找不到解题路径的状态,如在搜索中扩展出的状态是它的元素,则可立即将之排除,不必沿该状态继续搜索。
-
图搜索算法(深度优先,宽度优先,最好优先搜索等)思想:
(1)用未处理状态表(NPS)使算法能返回(回溯)到其
中任一状态。
(2)用一张“死胡同”状态表(NSS)来避免算法重新搜索
无解的路径。
(3)在PS 表中记录当前搜索路径的状态,当满足目的时可
以将它作为结果返回。
(4)为避免陷入死循环必须对新生成的子状态进行检查,
看它是否在该三张表中 。
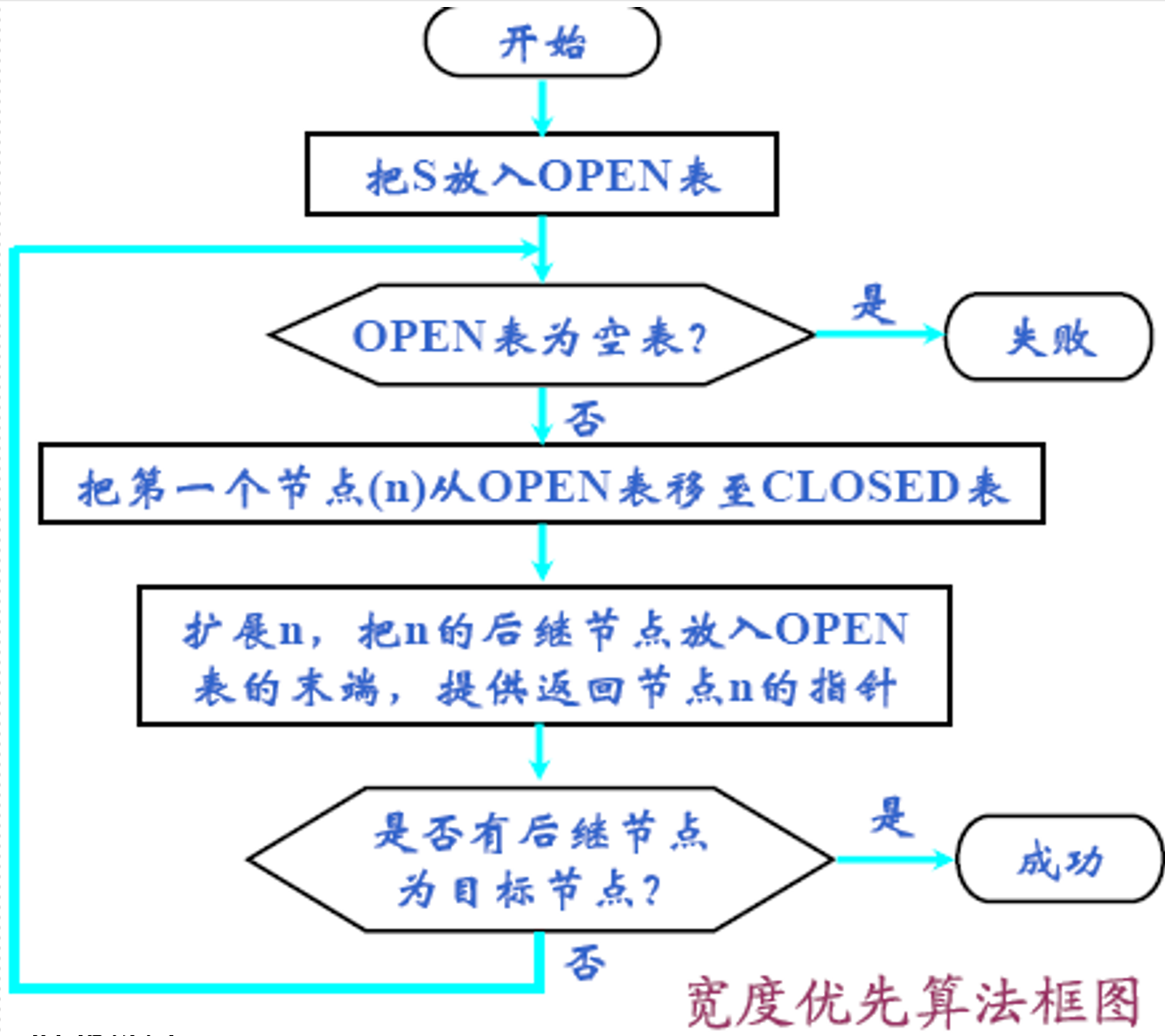
5.3.2 宽度优先搜索(广度优先搜索,breadth-first search)
-
以接近起始节点的程度为依据,进行逐层扩展的节点搜索方法
-
特点:
- 每次选择深度最浅的节点首先扩展,搜索是逐层进行的;
- 一种高价搜索,但若有解存在,则必能找到它
存两个表
- open表(NPS表):已经生成出来但其子状态未被搜索的状态;特点:先进先出
- closed表(PS和NSS表的合并):记录了已被生成扩展过的状态
区别在于open表的子状态没有被搜索到,而closed的子状态已经搜索到了
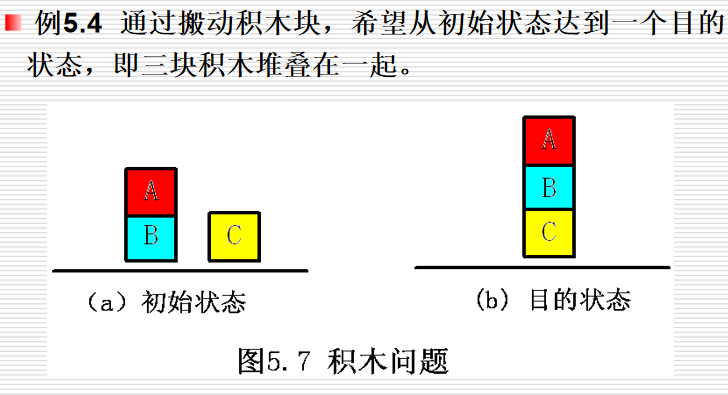
例:搬积木


5.3.3 深度优先搜索策略(Depth-first Search)
-
首先扩展最新产生的节点,深度相等的节点按生成次序的盲目搜索
-
特点:扩展最深的节点的结果使得搜索沿着状态空间某条单一的路径从起始节点向下进行下去;仅当搜索到达一个死胡同
-
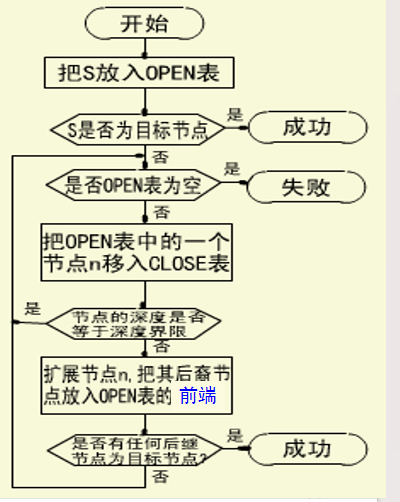
算法:
- 防止搜索过程沿着无益的路径扩展下去,往往给出一个节点扩展的最大深度——深度界限;
- 与宽度优先搜索算法的最根本不同:扩展的后继节点放在open表的前端。(open表是后进先出的)
-
在深度优先搜索中,当搜索到某一个状态时,它所有的子状态以及子状态的后裔状态都必须先于该状态的兄弟状态被搜索(我还以为这么长是啥呢……)
-
深度优先搜索不能保证第一次搜索到的某个状态时的路径是到这个状态的最短路径
-
对任何状态而言,以后的搜索有可能到另一条通向他的路径。如果路径的长度对解题很关键的话,当算法多次搜索到同一个状态时,它应保留最短路径。
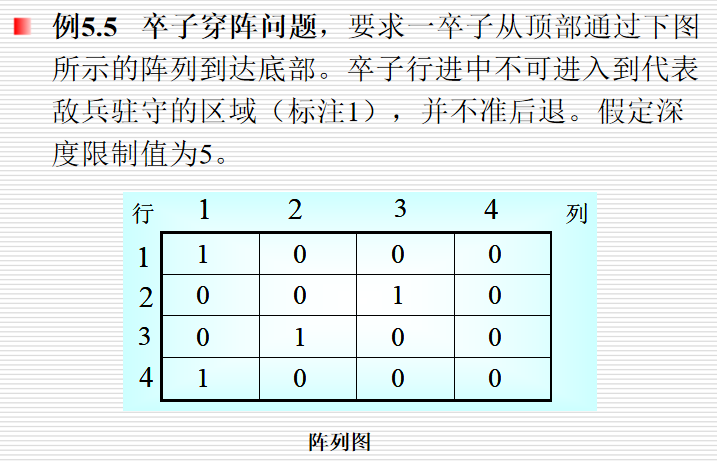
例题:卒子穿阵问题
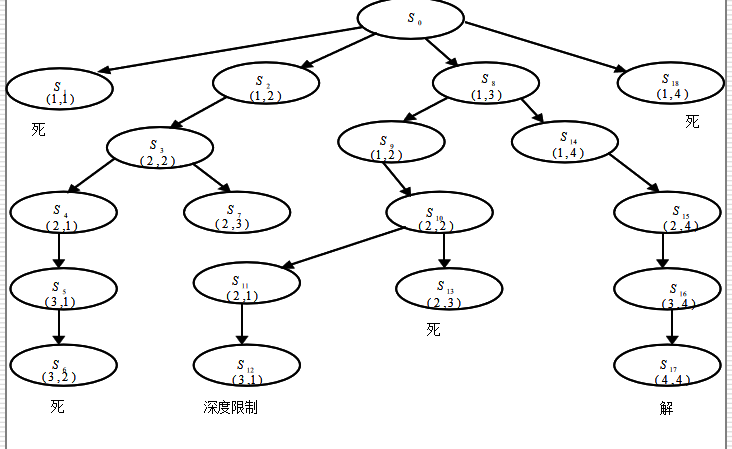
5.4 启发式图搜索策略
5.4.1 启发式策略
-
启发式信息:用来简化搜索过程有关具体问题领域的特性的信息叫做启发信息
-
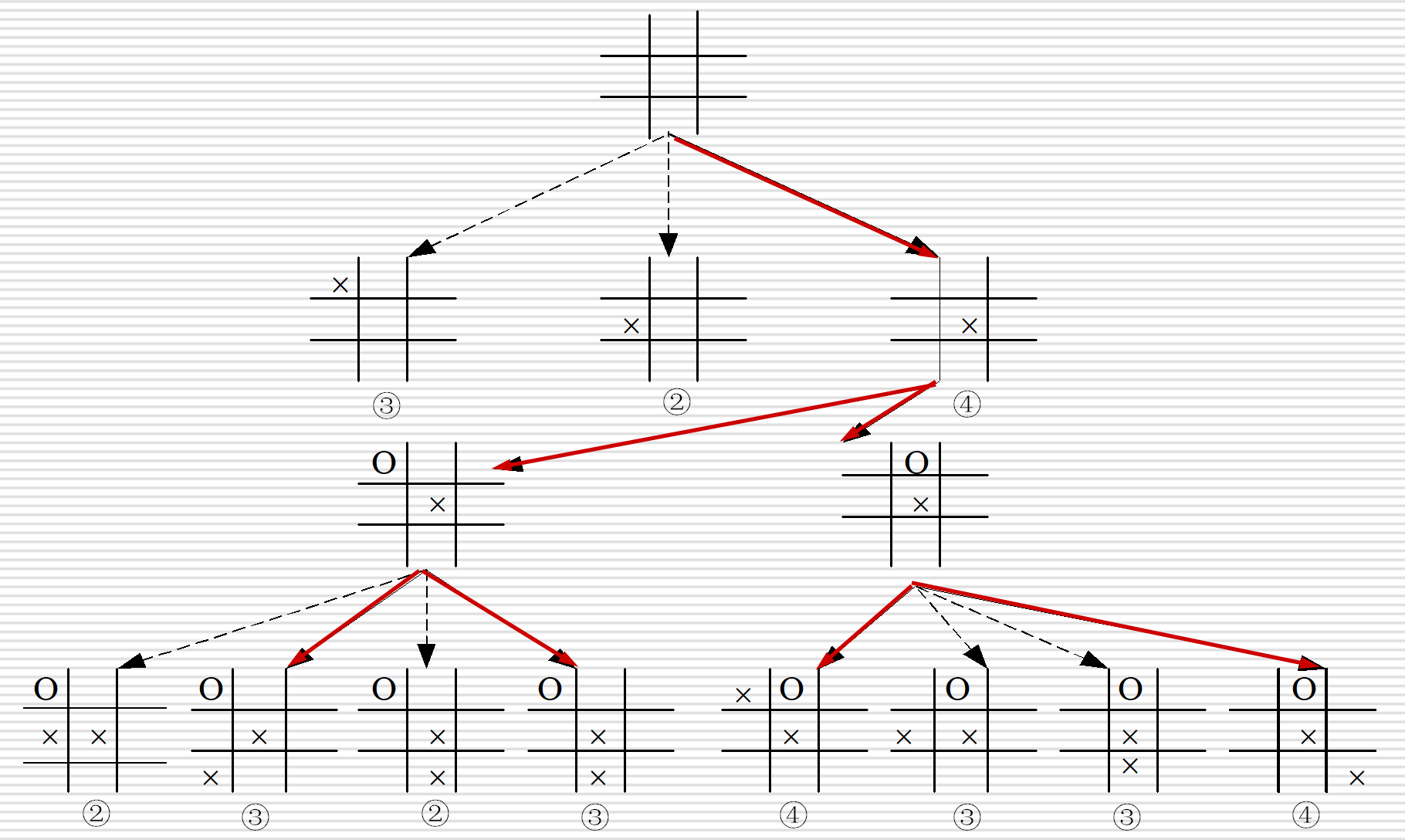
启发式图搜索策略(利用与问题有关的启发信息进行搜索)的特点:重排OPEN表,选择最有希望的节点加以扩展
种类:A算法、A*算法
-
运用启发式策略的两种基本情况
-
一个问题由于存在问题陈述和数据获取的模糊性,可能会使它没有一个确定的解,盲目搜索可能进入无止境的搜索过程
-
虽然一个问题可能有确定解,但是其状态空间特别大,搜索中生成扩展的状态会随着搜索的深度呈指数级增长
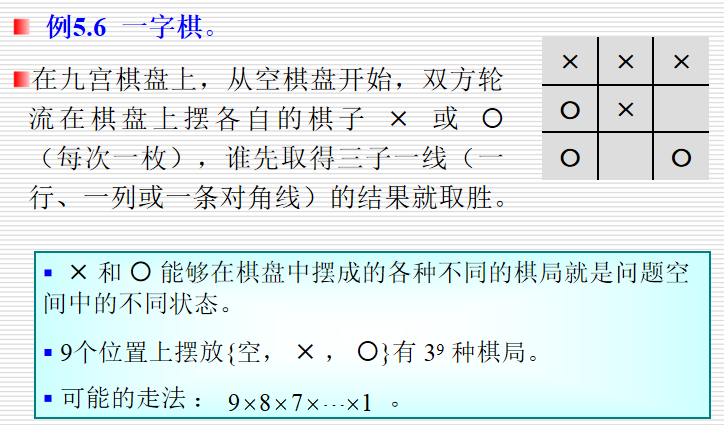
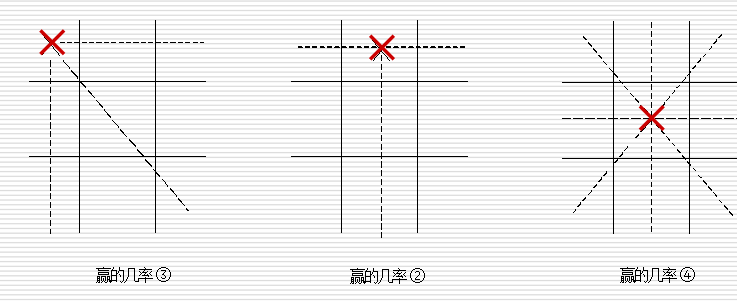
例: 一字棋
5.4.2 启发信息和估价函数
求解问题中能利用的大多是非完善的启发式信息
(1)求解问题系统不可能知道与实际问题有关的全部信息,因而无法知道该问题的全部状态空间,也不可能用一套算法来求解所有的问题。
(2)有些问题在理论上虽然存在着求解算法,但是在工程实践中,这些算法不是效率太低,就是根本无法实现。
按运用的方法分类:
- 陈述式启发信息:用于更准确、更精炼的描述状态
- 过程性启发信息:用于构造操作算子
- 控制性启发信息:表示控制策略的知识
- 利用控制性启发信息有两种比较极端的情况,一种是没任何控制信息作为搜索的依据,因而搜索的每一步都是随意的;另一种是有充分的控制信息作为依据,因而选择的每一步都是正确的。
按作用分类
- 用于扩展节点的选择:即用于决定先扩展哪一个节点,以免盲目扩展
- 用于生成节点的选择:即用于决定要先生成哪些后继节点,以免盲目生成过多无用的节点
- 用于删除节点的选择:即用于决定删除哪些无用节点,以免造成进一步的时空浪费
估价函数:估算节点希望程度的量度
估价函数值f(n)f(n)f(n):从初始节点经过n节点到达目标节点的路径的最小代价估计值,其一般形式是:f(n)=g(n)+h(n)f(n)=g(n)+h(n)f(n)=g(n)+h(n)
- g(n)g(n)g(n)从初始节点S0S_0S0到节点n的实际代价
- h(n)h(n)h(n)从节点n到目标节点SgS_gSg的最优路径的估计代价,称为启发函数
h(n)比重大:降低搜索工作量,但可能找不到最优解
h(n)比重小:工作量大,极限情况下变为盲目搜索,但可能可以找到最优解
例:八数码问题设计启发函数

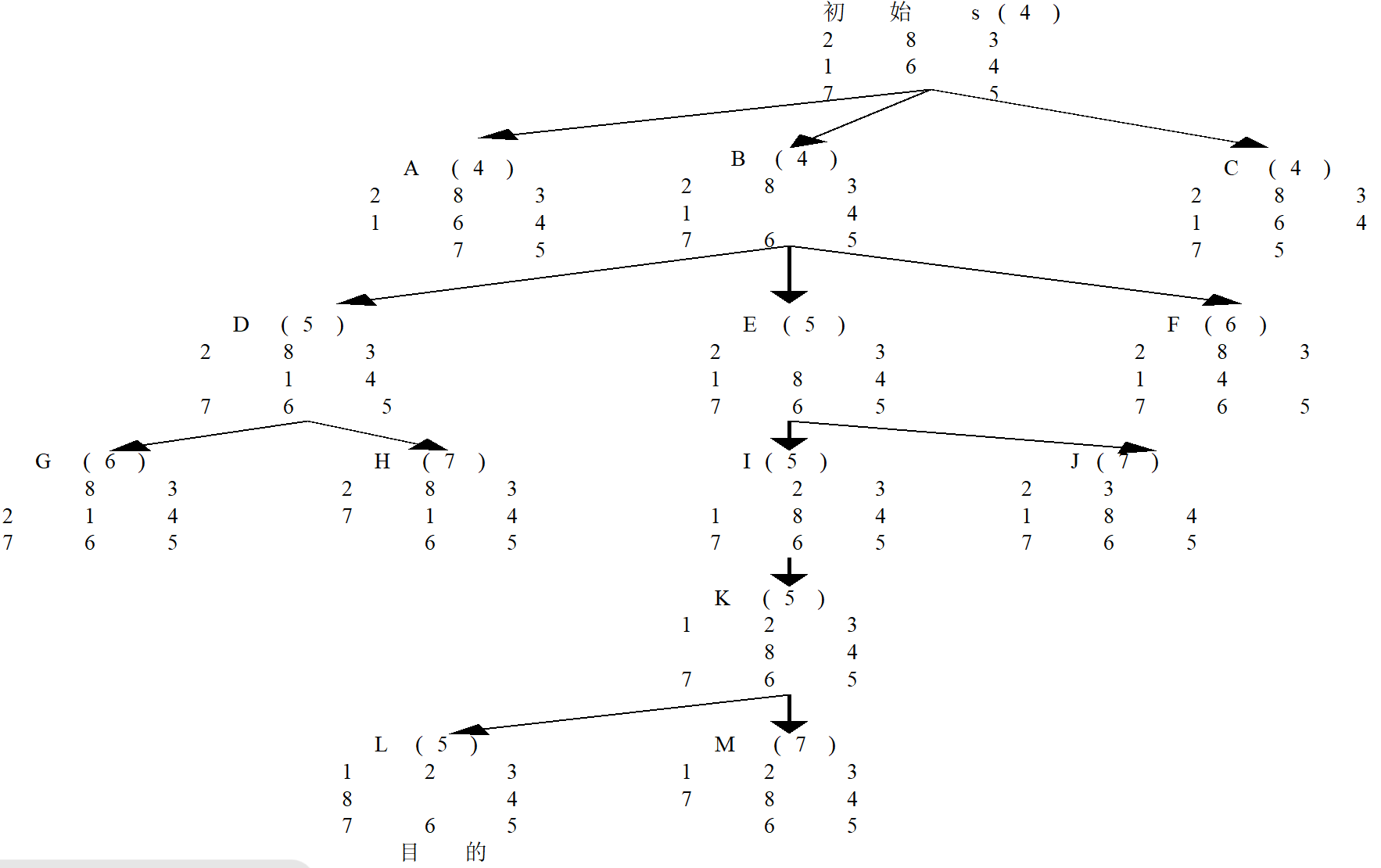
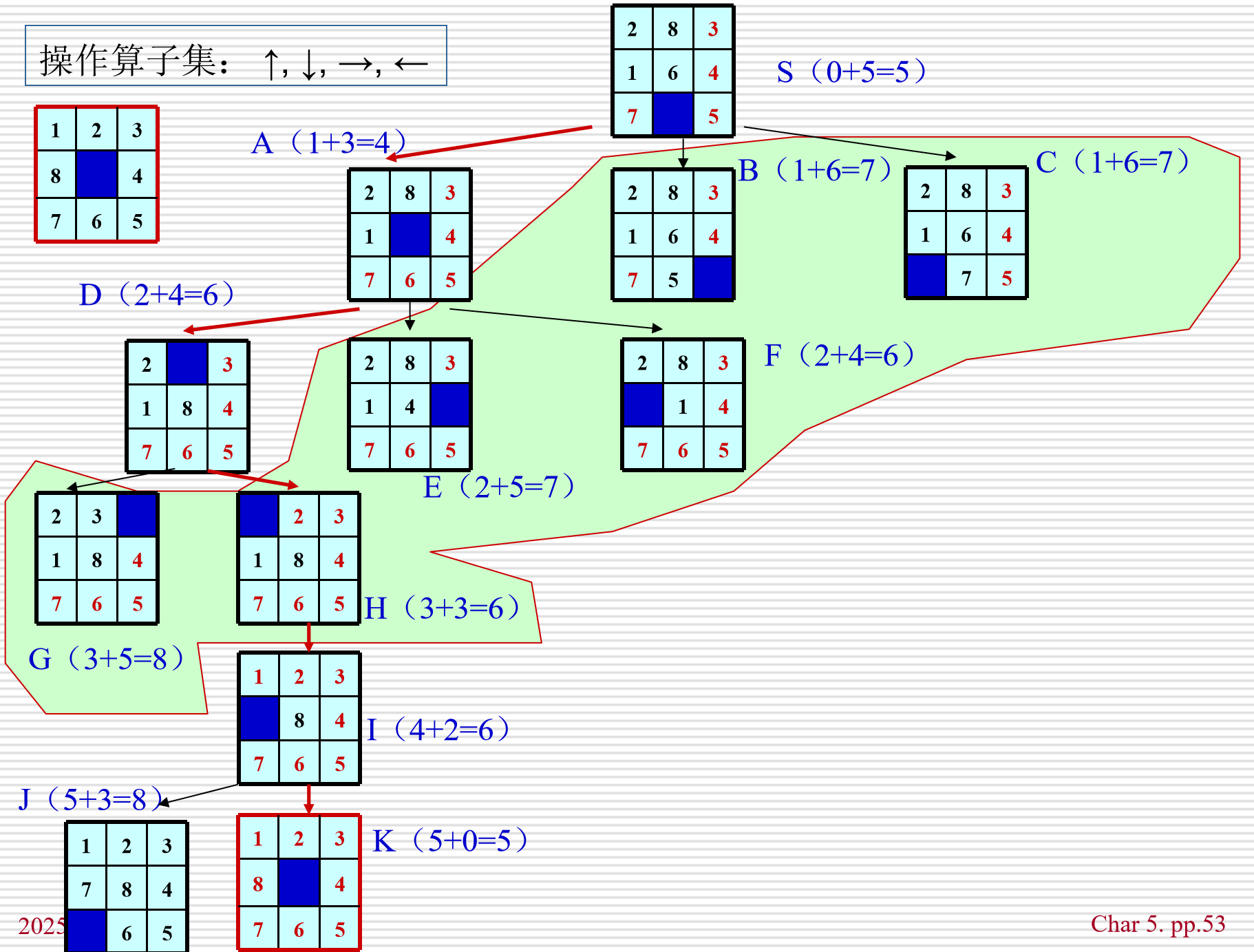
5.4.3 A搜索
A搜索算法:使用了估价函数f的最佳优先搜索,基于估价函数的一种启发式图搜索算法
估价函数f(n)=g(n)+h(n)f(n) = g(n)+h(n)f(n)=g(n)+h(n)
如何寻找并设计启发函数h(n),然后以f(n)的大小来排列open表中待扩展状态的次序,每次选择f(n)值最小者进行扩展
例:八数码问题
5.4.4 A*搜索算法及其特性分析
如果某一问题有解,那么利用A*搜索算法对该问题进行搜索则一定能搜索到解
特性
-
可采纳性:当一个搜索算法在最短路径存在时能保证找到它,就称该算法是可采纳的
A*搜索算法是可采纳的
若h(n)=0;A*搜索算法 <⇒宽度优先搜索
-
单调性:A*搜索算法并不要求g(n)=g * (n),则可能会沿着一条非最佳路径搜索到某一中间状态;如果对启发函数h(n)加上单调性的限制,就可以总从祖先状态沿着最佳路径到达任一状态
-
如果某一启发函数h(n)满足:
1)对所有状态nin_ini和njn_jnj,其中njn_jnj是nin_ini的后裔,满足h(ni)−h(nj)<=cost(ni,nj)h(n_i)-h(n_j)<=cost(n_i, n_j)h(ni)−h(nj)<=cost(ni,nj),其中cost(ni,nj)cost(n_i, n_j)cost(ni,nj)是从nin_ini到njn_jnj的实际代价。
2)目的状态的启发函数值为0。
则称h(n)是单调的。A*搜索算法中采用单调性启发函数,可以减少比较代价和调整路径的工作量,从而减少搜索代价。
-
-
信息性:在两个A*启发策略的h1h_1h1和h2h_2h2中,如果对搜索空间中的任一状态n都有h1(n)≤h2(n)h_1(n)≤h_2(n)h1(n)≤h2(n),就称策略h_2比h_1具有更多的信息性
- 如果某一搜索策略的h(n)越大,则A*算法搜索的信息性越多,所搜索的状态越少。
- 但更多的信息性需要更多的计算时间,可能抵消减少搜索空间带来的益处。
Chapter 6 智能计算及其应用
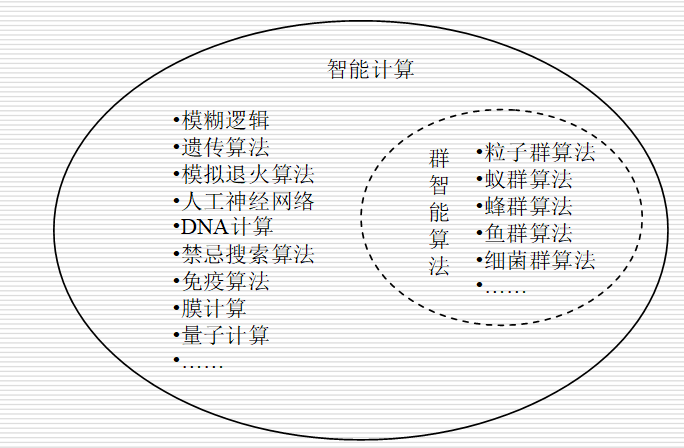
智能计算:受自然界和生物界规律的启迪,人们根据其原理模仿设计了许多求解问题的算法,包括人工神经网络、模糊逻辑、遗传算法、DNA计算、模拟退火算法、禁忌搜索算法、免疫算法、膜计算、量子计算、粒子群优化算法、蚁群算法、人工蜂群算法、人工鱼群算法以及细菌群体优化算法等,这些算法称为智能计算也称为计算智能(computational intelligence, CI)。
智能优化方法通常包括进化计算和群智能等两大类方法,是一种典型的元启发式随机优化方法
6.1 进化算法的产生与发展
6.1.1 进化算法的概念
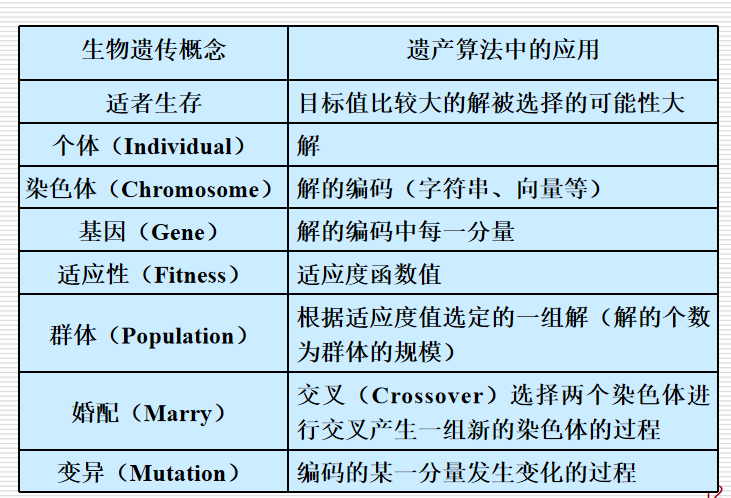
进化算法(evolutionary algorithms,EA)基于自然选择和自然遗传等生物进化机制的一种搜索算法。
生物进化是通过繁殖、变异、竞争和选择实现的;而进化算法则主要通过选择、重组和变异这三种操作实现优化问题的求解;
进化算法是一个算法簇,包括遗传算法(GA,genetic algorithm)、遗传规划(genetic programming)、进化策略(evolution strategies)和进化规划(evolution programmiing)
6.1.2 进化算法的生物学背景
适者生存:最适合自然环境的群体往往产生了更大的后代群体
生物进化的基本过程
染色体chromosome:生物的遗传物质的主要载体
基因gene:扩展生物性状的遗传物质的功能单元和结构单位
基因座locus:染色体中基因的位置
等位基因alleles:基因所取的值
6.1.3 进化算法的设计原则
- 适用性原则:一个算法的适用性指该算法所能适用的问题种类,它取决于算法所需的限制与假定;
- 可靠性原则:算法的可靠性是指算法对于所涉及的问题,以适当的精度求解其中大多数问题的能力;
- 收敛性原则:指算法能否收敛到全局最优,在收敛的前提下,希望算法具有较快的收敛速度;
- 稳定性原则:指算法对其控制参数及问题的数据的敏感度
- 生物类比原则:生物界有效方法及操作可以通过类别方法引入到算法中,有时会带来较好的结果
6.2 基本遗传算法
遗传算法(genetic algorithms,GA):一类借鉴生物界自然选择和自然遗传机制的随机搜索算法,非常适用于处理传统搜索方法难以解决的复杂和非线性优化的问题
遗传算法可广泛应用于组合优化……
6.2.1 遗传算法的基本思想
遗传算法的基本思想:在求解问题时从多个解开始,然后通过一定的法则进行逐步迭代以产生新的解
6.2.2 遗传算法的发展历史
1962年,Fraser提出自然遗传算法
1965年,Holland提出人工遗传操作的重要性
1967年,Bagley首次提出遗传算法这一术语
1970年,Cavicchio把遗传算法应用于模式识别
6.2.3 编码
-
位串编码:一种一维染色体编码方法,将问题空间的参数编码为一维排列的染色体的方法
-
二进制编码:用若干二进制数表示一个个体,将原问题的解空间映射到位串空间B={0,1}上,然后用位串空间
优点:类似于生物染色体的组成,算法易于用生物遗传理论解释,遗传操作如交叉、变异等易实现;算法处理的模式数最多
缺点:
-
相邻整数的二进制编码可能具有较大的Hamming距离,降低了遗传算子的搜索效率,如01111和10000
-
要先给出求解的精度
-
求解高维优化问题的二进制编码串长,算法的搜索效率高
-
-
Gray编码:将二进制编码通过一个变换进行转换得到的编码
-
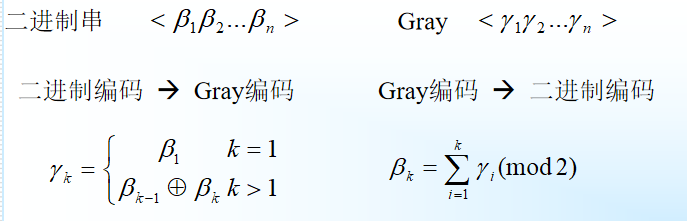
-
实数编码
- 采用实数表达法不必进行数制转换,可直接在节点表现型上进行遗传操作
- 多参数映射编码的基本思想:把每个参数先进性二进制编码得到字串,再把这些子串连成一个完整的染色体
- 多参数映射编码中的每个子串对应各自的编码数,所以,可以有不同的串长度和参数的取值范围
6.2.4 群体设定
- 初始种群的产生
- 随机产生群体规模数目的个体作为初始群体;
- 随机产生一定数目的个体,从中挑选最好的个体加入到初始群体中,不断迭代,直到初始群体中个体数目达到了预先确定的规模
- 根据问题固有知识,把握最优解所占空间在整个问题空间中所占范围,然后,在此分布范围内设定初始群体
- 群体规模的确定
- 群体规模太小,遗传算法的优化性能不太好,易陷入局部最优解
- 群体规模太大,计算复杂
- 模式定理:若群体规模为M,则遗传操作可以从这M个个体中,生成和检测M3M^3M3个模式,并在此基础上能够不断形成和优化积木块,直到找到最优解
6.2.5 适应度函数
-
将目标函数映射成适应度函数的方法
若目标函数为最大化问题,则Fit(f(x)) = f(x)
若目标函数为最小化问题,则Fit(f(x)) = 1/f(x)
- 将目标函数转换为求最大值的形式,且保证函数值非负

- 适应度函数的尺度变换
-
在遗传算法中,将所有妨碍适应度值高的个体产生,从而影响遗传算法正常工作的问题统称为欺骗问题
-
过早收敛:缩小这些个体的适应度
-
停滞现象:改变原始适应值的比例关系
-
尺度变换或定标:对适应度函数值域的某种映射比例
(1)线性变换f’=af+bf’ = af + bf’=af+b

(2)函数变换 f′=fKf'=f^Kf′=fK
(3)指数变换 f′=e−aff'=e^{-af}f′=e−af
6.2.6 选择
-
个体选择概率分配方法
-
选择操作也称为复制操作:从当前群体中按照一定概率选出的优良个体,使他们有机会作为父代繁殖下一代子孙
-
判断个体优良与否的准则是各个个体的适应度值;个体适应度越高,其被选择的机会就越多
-
适应度比例方法或蒙特卡罗法:各个个体被选择的概率和其适应度值成比例,则第i个个体被选的概率为
-
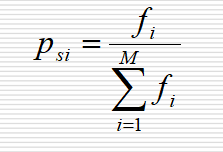
-
排序方法
-
排序方法是计算每个个体的适应度后,根据适应度的大小顺序对群体中个体进行排序,然后把事先设计好的概率按顺序分配给个体,作为各自的选择概率
-
线性排序:

-
非线性排序

-
可以用其他非线性函数来选择分配概率,只要满足以下条件:

-
-
选择个体方法
-
转盘赌选择:按个体的选择概率产生一个轮盘,轮盘每个区的角度与个体的选择概率成比例;产生一个随机数,它落入转盘的哪个区域就选择相应的个体交叉
-
锦标赛选择方法:从群体中随机选择个体,将其中适应度最高的个体保存到下一代。这一过程反复执行,直到保存到下一代的个体数达到预先设定的数量为止
随机竞争方法:每次按赌轮选择方法选取一对个体,然后让这两个个体进行竞争,适应度高者获胜。如此反复,直到选满为止。
-
最佳个体保存方法:把群体中适应度最高的个体不进行交叉而直接复制到下一代中,保证遗传算法终止时得到的最后结果一定是历代出现过的最高适应度的个体
-
6.2.7 交叉
交叉或者重组:当两个生物体配对或者复制时,他们的染色体相互混合,产生一对由双方基因组成的新的让你瑟提
-
基本的交叉算子
-
一点交叉:在个体串中随机设定一个交叉点,实行交叉时,该点前或后的两个个体的部分结构进行互换,并生成两个新的个体
-
两点交叉:将两个交叉点进行互换,也能产生两个新的个体
-
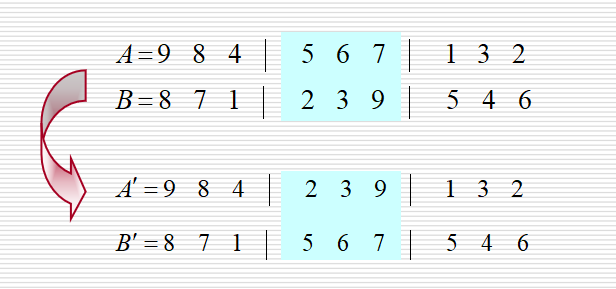
修正的交叉方法:部分匹配交叉
-
6.2.8 变异
- 位点变异:群体中的个体码串,随机挑选一个或多个基因座,并对这些基因座的基因值以变异概率作变动
- 逆转变异:在个体码串中随机选择两点(逆转点),然后将两点之间的基因值以逆向排序插入到原位置
- 插入变异:在个体码串中随机选择一个码,然后将此码插入随机选择的插入点中间
- 互换变异:随机选取染色体的两个基因进行简单互换
- 移动变异:随机选取一个基因,向左或向右移动一个随机位数
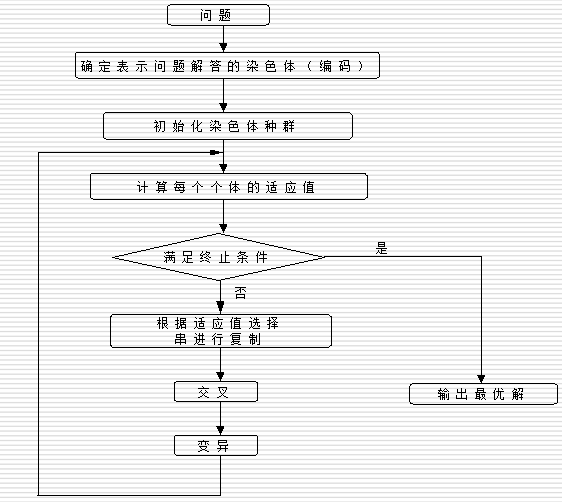
6.2.9 遗传算法的一般步骤
6.2.10 遗传算法的特点
遗传算法是一种全局优化概率算法
- 遗传算法对所求解的优化问题没有太多的数学要求,由于进化特性,搜索过程中不需要问题的内在性质,可直接对结构对象进行操作
- 利用随机技术指导对一个被编码的参数空间进行高效率搜索
- 采用群体搜索策略,易于并行化
- 仅用适应度函数值来评估个体,并在此基础上进行遗传操作,使种群中个体之间进行信息交换
- 遗传算法能够非常有效的进行概率意义的全局搜索
6.3 遗传算法的改进算法
6.3.1双倍体遗传算法
-
双倍体遗传算法采用显性和隐性两个染色体同时进行进化,提供了一种记忆以前有用的基因块的功能。
-
双倍体遗传算法采用显性遗传。
-
双倍体遗传延长了有用基因块的寿命,提高了算法的收敛能力,在变异概率低的情况下能保持一定水平的多样性。
-
双倍体遗传算法的设计:
(1)编码/解码:两个染色体(显性、隐性)
(2)复制算子:计算显性染色体的适应度,按照显性染色体 的复制概率将个体复制到下一代群体中。
(3)交叉算子:两个个体的显性染色体交叉、隐性染色体也同时交叉。
(4)变异算子:个体的显性染色体按正常的变异概率变异;隐性染色体按较大的变异概率变异。
(5)双倍体遗传算法显隐性重排算子:个体中适应值较大的染色体设为显性染色体,适应值较小的染色体设为隐性染色体。
6.3.2 双种群遗传算法
-
基本思想:
- 在遗传算法中使用多种群同时进化,并交换种群之间优秀个体所携带的遗传信息,以打破种群内的平衡态达到更高的平衡态,有利于算法跳出局部最优。
- 多种群遗传算法:建立两个遗传算法群体,分别独立地运行复制、交叉、变异操作,同时当每一代运行结束以后,选择两个种群中的随机个体及最优个体分别交换。
-
双种群遗传算法的设计:
设种群A与种群B,当A与B种群都完成了选择、交叉、变异算子后,产生一个随机数num,随机选择A中num个个体与A中最优个体,随机选择B中num个个体与B中最优个体,交换两者,以打破平衡态。

6.3.3 自适应遗传算法
使交叉概率PcP_cPc和编译概率PmP_mPm能够随是印度变化自动改变
自适应遗传算法的步骤:
(1) 编码/解码设计。
(2) 初始种群产生:N(N 是偶数)个候选解,组成初始解
(3) 定义适应度函数:f=1/abf=1/abf=1/ab,计算适应度fif_ifi
(4) 按轮盘赌规则选择N 个个体,计算favg和fmaxf_{avg}和f_{max}favg和fmax。
(5)将群体中的各个个体随机搭配成对,共组成N/2对, 对每一对个体,按照自适应公式计算自适应交叉概率 ,随机产生R(0,1),如果R<PcR<P_cR<Pc则对该对染色体进行交叉操作。
(6)对于群体中的所有个体,共N个,按照自适应变异公式计算自适应变异概率PmP_mPm,随机产生 R(0,1),如果R<PmR<P_mR<Pm则对该染色体进行交叉操作。
(7)计算由交叉和变异生成新个体的适应度,新个体与父代一起构成新群体。
(8)判断是否达到预定的迭代次数,是则结束;否则转 (4)
自适应的交叉概率与变异概率
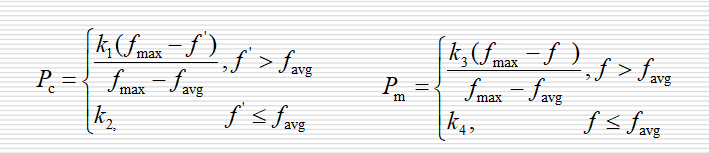
- 普通自适应算法中,当个体适应度值越接近最大适应度值时,交叉概率与变异概率就越小;当等于最大适应度值时,交叉概率和变异概率为零。
- 改进的思想:当前代的最优个体不被破坏,仍然保留(最优保存策略);但较优个体要对应于更高的交叉概率与变异概率。
6.4 遗传算法的应用
-
流水车间调度问题
假设:
(1) 每个工件在机器上的加工顺序是给定的。
(2) 每台机器同时只能加工一个工件。
(3) 一个工件不能同时在不同的机器上加工。
(4) 工序不能预定。
(5) 工序的准备时间与顺序无关,且包含在加工时间中。
(6) 工件在每台机器上的加工顺序相同,且是确定的。
6.5 群智能算法产生的背景
群智能算法(swarm algorithms,SI):受动物群体智能启发的算法
群体智能:由简单个体组成的群落与环境以及个体之间的互动行为
群智能算法包括:粒子群优化算法、蚁群算法、蜂群算法
6.6 粒子群优化算法及其应用
产生背景:粒子群优化算法是由美国普渡大学于1995年提出,它的基本概念源于对鸟群觅食行为的研究
6.6.1 粒子群优化算法的基本原理
基本思想:将每个个体看作n维搜索空间中一个没有体积质量的粒子,在搜索空间中以一定的速度飞行,该速度决定粒子飞行的方向和距离,所有粒子有一个由优化函数决定的适应值
基本原理:PSO初始化为一群随机粒子,然后通过迭代找到最优解。在每一次迭代中,粒子通过跟踪两个“极值”来更新自己。第一个是粒子本身所找到的最优解,这个解称为个体极值。另一个是整个种群目前找到的最优解,称为全局极值
算法定义
在n维连续搜索空间中,对粒子群中的第i个粒子进行定义
- 搜索空间中粒子的当前位置
- 该粒子至今所获得的具有最优适应度的位置(个体极值)
- 该粒子的搜索方向


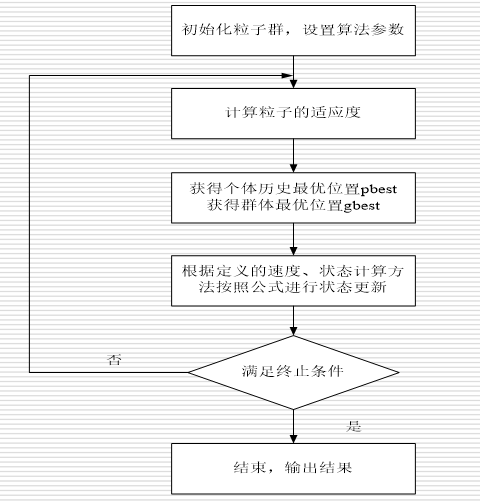
粒子群优化算法的流程
-
初始化每个粒子。在允许范围内随机设置每个粒 子的初始位置和速度。
-
评价每个粒子的适应度。计算每个粒子的目标函数
-
设置每个粒子的pip_ipi,对每个粒子,将其适应度与其经 历过的最好位置PiP_iPi进行比较,如果优于PiP_iPi,则将其作为该粒子的最好位置PiP_iPi。
-
设置全局最优值pgp_gpg。对每个粒子,将其适应度与群体经历过的最好位置PgP_gPg进行比较,如果优于PgP_gPg,则将其作为当前群体的最好位置PgP_gPg。
-
更新粒子的速度和位置
-
检查终止条件。如果未达到设定条件(预设误差或者迭代的次数),则返回第(2)步。
6.6.2 粒子群优化算法的参数分析
-
群体规模m,惯性权重,加速度ϕ1 ϕ2\phi _1 \ \ \phi_2ϕ1 ϕ2,最大速度Vmax, 最大代数Gmax。
-

-

-

-

6.7 蚁群算法及其应用
一组应用于组合优化问题的启发式搜索方法
在解决离散组合优化方面具有良好的性能
基本思想:
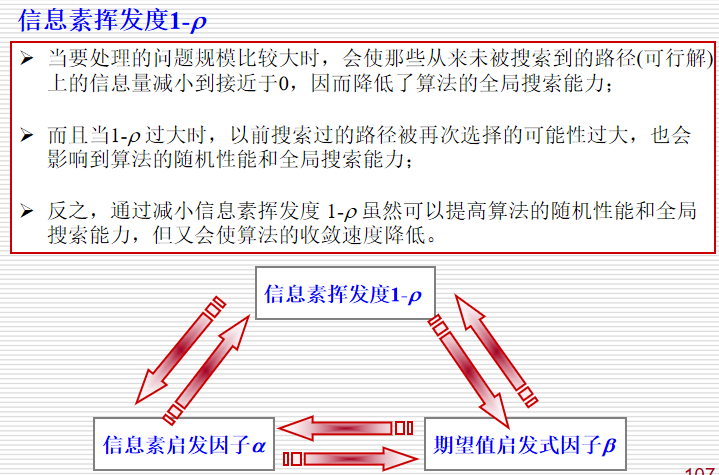
- 信息素跟踪:按照一定的概率沿着信息素较强的路径觅食
- 信息素遗留:会在走过的路上释放信息素,使得在一定的范围内的其他蚂蚁能够察觉到并由此影响他们的行为
(1)环境:有障碍物、有其他蚂蚁、有信息素。
(2)觅食规则:范围内寻找是否有食物,否则看是否有信息素,每只蚂蚁都会以小概率犯错。
(3)移动规则:都朝信息素最多的方向移动,无信息素则继续朝原方向移动,且有随机的小的扰动,有记忆性。
(4)避障规则:移动的方向如有障碍物挡住,蚂蚁会随机选择另一个方向。
(5)信息素规则:越靠近食物播撒的信息素越多,越离开食物播撒的信息素越少。
6.7.1 基本蚁群算法模型


全局更新方法:
优点:
- 保证了残留信息素不至于无限累积;
- 如果路径没有被选中,那么上面的残留信息素会随时间的推移而逐渐减弱,这使算法能“忘记”不好的路径;
- 即使路径经常被访问也不至于因为累积,而产生使期望值的作用无法体现;
- 充分体现了算法中全局范围内较短路径(较好解)的生存能力
- 加强了信息正反馈性能;
- 提高了系统搜索收敛的速度
6.7.2 蚁群算法的参数选择

Chapter 7 专家系统与机器学习
专家系统成为人工智能的重要分支
7.1 专家系统的产生和发展
第一阶段:初创期
DENDRAL系统:推断化学分子结构的专家系统
特点:高度的专业化;专门问题求解能力强;结构功能不完整;移植性差;缺乏解释功能
第二阶段:成熟期(20世纪70年代中期-20世纪80年代初)
特点
- 单学科专业型专家系统
- 系统结构完整,功能较全面,移植性好
- 具有推理解释功能,透明性好
- 采用启发式推理、不精确推理
- 用产生式规则、框架、语义表达知识
- 用限定性英语进行人机交互
第三阶段:发展期(20世纪80年代至今)
7.2 专家系统的概念
7.2.1 专家系统的定义
-
定义:(费根鲍姆)专家系统是一种智能的计算机程序,它运用知识和推理来解决只有专家才能解决的复杂问题
一类包含知识和推理的计算机程序
-
专家系统的基本组成
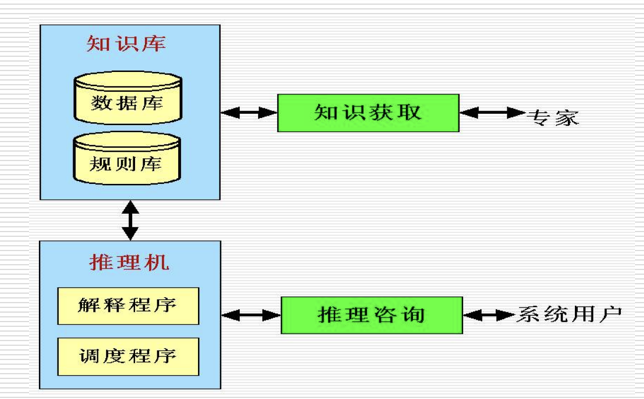
7.2.2 专家系统的特点
- 具有专家水平的专业知识
- 能进行有效的推理
- 具有启发性
- 具有灵活性
- 具有透明性
- 具有交互性
专家系统与传统程序比较
-
编程思想
传统程序 = 数据结构 + 算法
专家系统 = 知识 + 推理
-
传统程序:关于问题求解的知识隐含于程序中
专家系统:知识单独组成知识库,与推理机分离
-
处理对象:
传统程序:数值计算和数据处理
专家系统:符号处理
-
传统程序:不具有解释功能。
专家系统:具有解释功能。
-
传统程序:产生正确的答案。
专家系统:通常产生正确的答案,有时产生错误的答案。
-
系统的体系结构不同
7.2.3 专家系统的类型
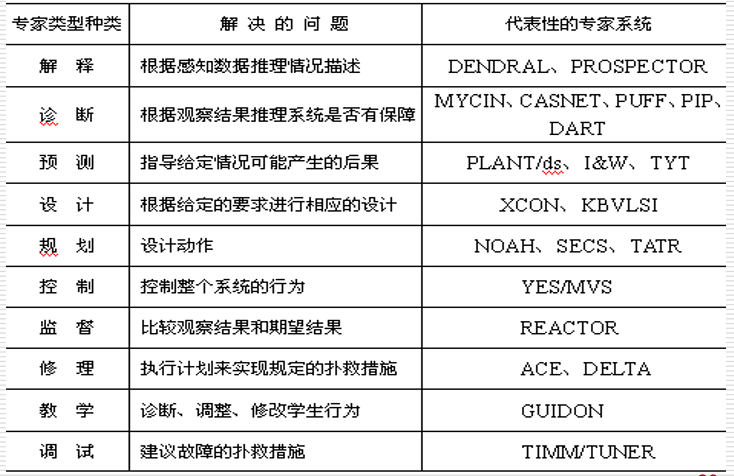
7.2.4 专家系统的应用
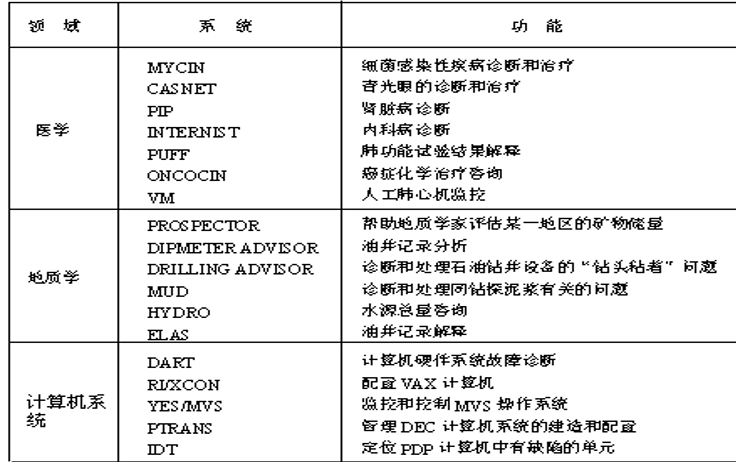
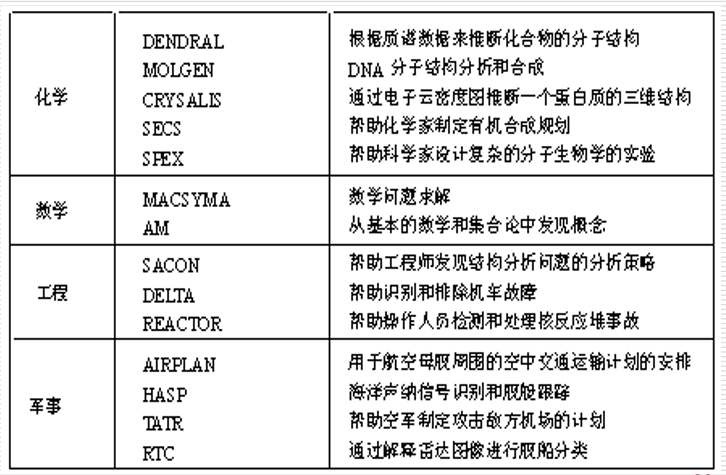
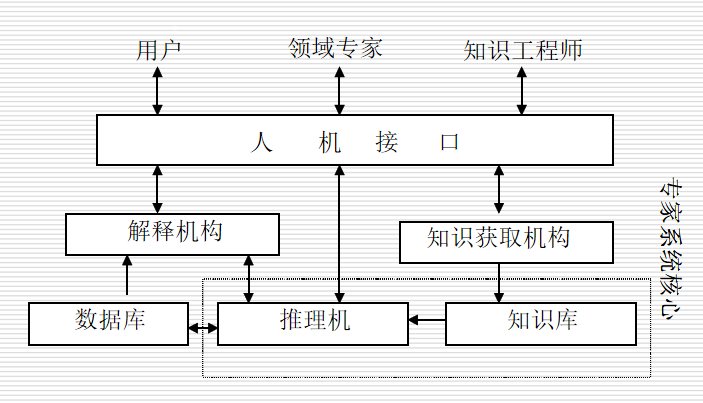
7.3 专家系统的工作原理
专家系统的一般结构:
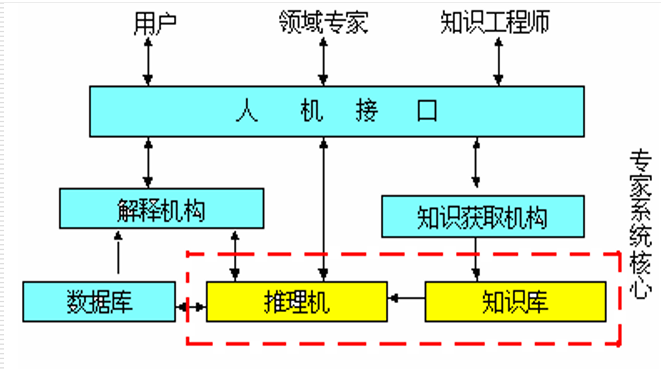
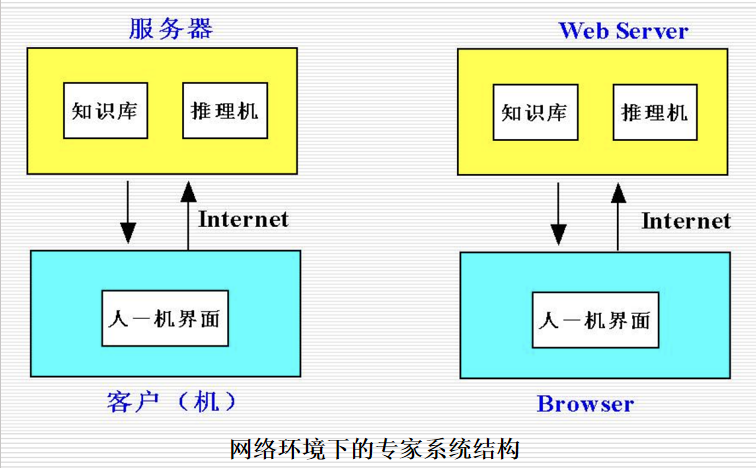
网络环境下的专家系统结构:
7.4 知识获取的主要过程与模式
7.4.1 知识获取的过程
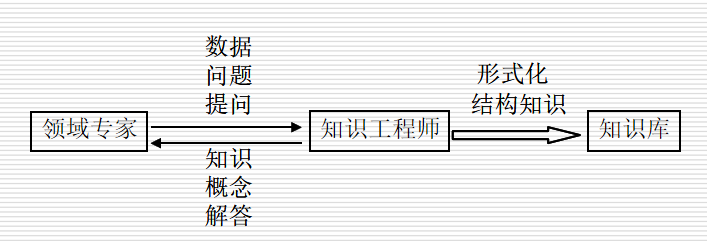
抽取知识、知识的转换、知识的输入、知识的检测
知识获取主要是把用于问题求解的专门知识从某些知识源中提炼出来,并转化为计算机的表示形式存入知识库
7.4.2 知识获取的模式
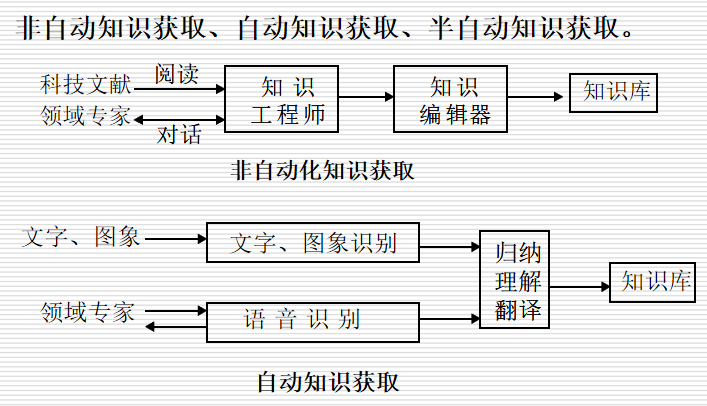
自动和非自动的区别在于没有知识工程师这个模块
半自动知识获取:介于两者之间,没有实现完全自动
7.5 机器学习
7.5.1 机器学习的基本概念
机器学习:使计算机能模拟人的学习行为,自动地通过学习来获取知识和技能,不断改善性能,实现自我完善
机器学习主要研究一下三方面问题
- 学习机理:人类获取知识、技能和抽象概念的天赋能力
- 学习方法:机器学习方法额度构造是在对生物学习机理进行简化的基础上,用计算的方法进行再现
- 学习系统:能够在一定程度上实现机器学习的系统
一个学习系统一般应该有环境、学习、知识库、执行与评价等四个基础部分组成
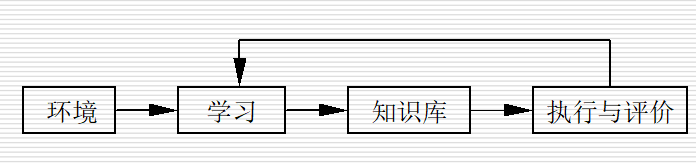
7.5.2 机器学习的分类
-
按学习方法分类
机械式学习、指导式学习、示例学习、类比学习、解释学习等
-
按学习能力分类
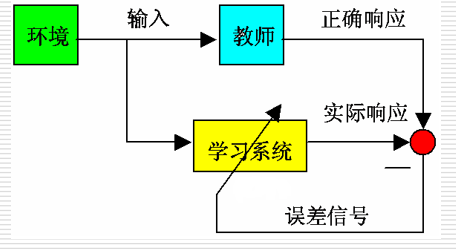
- 监督学习(有教师学习):在学习时需要老师的示教或训练
-
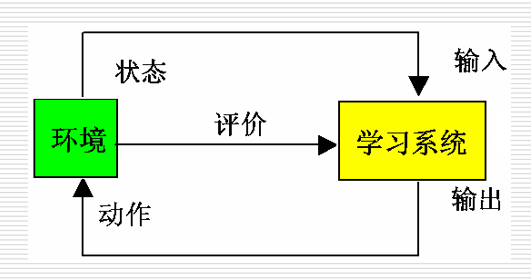
强化学习(再励学习或增强学习)
-
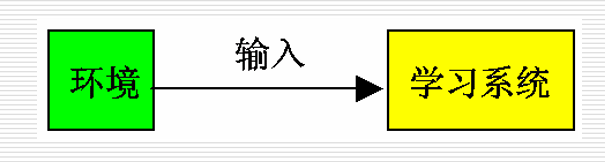
非监督学习(无教师学习):用评价标准来代替人的监督工作
-
若监督学习结合了有监督学习和无监督学习的优点,利用不完全的标签数据进行有监督学习,同时利用大量无标签数据进行无监督学习
-
按推理方式分类
- 基于演绎的学习(解释学习)
- 基于归纳的学习(示例学习、发现学习等)
-
按综合属性分类
归纳学习、分析学习、连接学习、遗传式学习等
7.5.3 机械式学习
机械式学习(rote learning):又称记忆学习,或死记式学习.通过直接记忆或者存储外部环境所提供的信息达到学习的目的,并在以后通过对知识库的检索得到相应的知识直接用来求解问题
机械式学习实质是用存储空间来换取处理时间
例:塞缪尔的跳棋程序
机械学习的主要问题
-
存储组织信息:要采用适当的存储方式,使检索速度尽可能地快
-
环境的稳定性与存储信息的适用性问题:机械学习系统必须保证所保存的信息适用于外界环境变化的需要
-
存储与计算之间的权衡:对于机械学习来说很重要的一点是它不能降低系统的效率
7.5.4 指导式学习
又称嘱咐式学习或教授式学习:由外部环境向系统提供一般性的指示或建议,系统把它们具体地转化为细节知识并送入知识库中。在学习过程中要反复对形成的知识进行评价,使其不断完善。
指导式学习的学习过程
-
征询指导者的指示或建议
简单征询:指导者给出一般性的意见,系统将其具体化
复杂征询:系统不仅要求指导者给出一般性的建议,而且还要具体的鉴别知识库中可能存在的问题,并给出修改建议
被动征询:系统只是被动的等待指导者提供意见
主动征询:系统不只是被动的接收指示,而且还能主动的提出询问,把指导者的注意力集中在特定的问题上
-
把征询意见转换为可执行的内部形式
学习系统应具有把用约定形式表示的征询意见转化为计算机内部可执行形式的能力,并且能在转化过程中进行语法检查及适当的语义分析
-
加入知识库
在加入过程中要对知识进行一致性检查,以防止出现矛盾、冗余、环路等问题
-
评价
评价方法:对新知识进行经验测试,即执行一些标准例子,然后检查执行情况是否与已知情况一致。
7.5.5 示例学习
又称实例学习或从例子中学习:通过从环境中取得若干与某概念有关的例子,经归纳得出一般性概念的一种学习方法
示例学习中,外部环境(教师)提供一组例子(正例和反例),然后从这些特殊知识中归纳出适用于更大范围的一般性知识,它将覆盖所有的正例并排除所有反例。
示例学习的学习模型
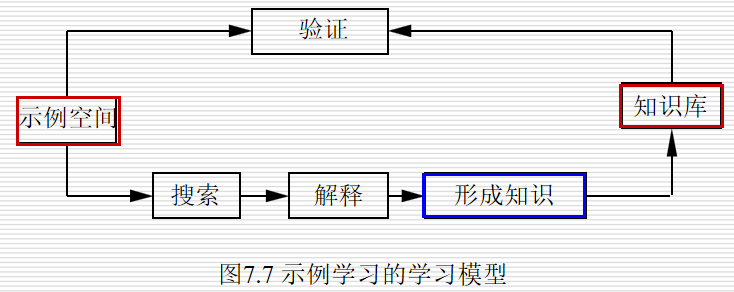
7.6 知识发现与数据挖掘
7.6.1 知识发现与数据挖掘的概念
知识发现的全称是从数据库中发现知识(KDD)
数据挖掘(DM)是从数据库中挖掘知识
目的:从数据集中抽取和精华一般规律或模式
7.6.2 知识发现的一般过程
数据准备:数据选取、数据预处理和数据变换
- 数据选取就是根据用户的需要从原始数据库中抽取的一组数据。
- 数据预处理一般可能包括消除噪声、推导计算缺值数据、消除重复记录、完成数据类型转换等。
- 数据变换是从初始特征中找出真正有用的特征以减少数据开采时要考虑的特征或变量个数。
数据挖掘
- 确定挖掘的任务或目的是什么。如数据总结、分类、聚类、关联规则或序列模式等。
- 使用什么样的挖掘算法。同样的任务可以用不同的算法来实现。
- 选择实现算法有两个考虑因素:
- 不同的数据的特点,因此需要用与之相关的算法来挖掘;
- 用户或实际系统的要求,有的用户可能希望获取描述型的、容易理解的知识,而有的用户系统的目的是获取预测准确度尽可能高的预测型知识。
结果的解释与评估
- 数据挖掘阶段发现的知识模式中可能存在冗余或无关的模式,所以还要经过用户或机器的评价。
- 若发现所得模式不满足用户要求,则需要退回到发现阶段之前,如重新选取数据,采用新的数据变换方法,设定新的数据挖掘参数值,甚至换一种挖掘算法。
- 对发现的模式进行可视化,或者把结果转换为用户易懂的另一种表示,如把分类决策树转换为“if-then…”规则。
7.6.3 知识发现的任务
- 数据总结:对数据进行浓缩,给出它的紧凑描述。
- 概念描述:从学习任务相关的数据中提取总体特征。
- 分类:提出一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的一个。
- 聚类:根据数据的不同特征,将其划分为不同的类。包括统计方法、机器学习方法、神经网络方法和面向数据库的聚类方法等。
- 相关性分析:发现特征之间或数据之间的相互依赖关系。
- 偏差分析:寻找观察结果与参照量之间的有意义的差别。
- 建模:通过数据挖掘,构造出能描述一种活动、状态或现象的数学模型。
7.6.4 知识发现的主要方法:
- 统计方法:从事物的外在数量上的表现去推断事物可能的规律性。常见的有回归分析、判别分析、聚类分析以及探索分析等。
- 粗糙集:粗糙集是具有三值隶属函数的模糊集,即是、不是、也许。常与规则归纳、分类和聚类方法结合起来使用。
- 可视化:把数据、信息和知识转化为图形等,使抽象的数据信息形象化。信息可视化也是知识发现的一个有用的手段。
- 机器学习方法:包括符号学习和连接学习。
7.6.5 知识发现的对象:
- 数据库:当前研究比较多的是关系数据库的知识发现。
- 数据仓库:数据挖掘为数据仓库提供深层次数据分析的手段,数据仓库为数据挖掘提供经过良好预处理的数据源。
- Web信息:Web知识发现主要分内容发现和结构发现。内容发现是指从Web文档的内容中提取知识;结构发现是指从Web文档的结构信息中推导知识。
- 图像和视频数据:图像和视频数据中也存在有用的信息。比如,地球资源卫星每天都要拍摄大量的图像或录像。
7.7 专家系统的建立
7.7.1 适合于专家系统求解的问题
什么情况下开发专家系统是可能的
- 主要依靠经验性知识,不需运用大量常识性知识就可解决的任务
- 存在真正的领域专家
- 有明确的开发目标,且任务不太难实现
什么情况下开发专家系统是合理的
- 具有较高的经济效益
- 人类专家奇缺,但在许多地方又十分需要
- 人类专家经验不断丢失
- 危险场合需要专业知识
什么情况下开发专家系统是合适的
- 本质:问题能通过符号操作和符号结构进行求解,且需使用启发式知识、经验规则才能得到答案
- 复杂性
- 范围:所选任务的大小可驾驭、任务有实用价值
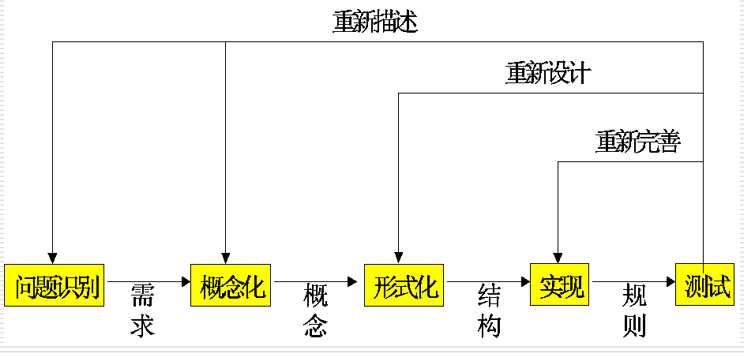
7.7.2 专家系统的设计原则与开发步骤
设计原则
- 专门的任务
- 专家合作
- 原型设计
- 用户参与
- 辅助工具
- 知识库与推理机分离
专家系统的开发步骤
7.7.3 专家系统的评价
1.正确性
系统设计的正确性
- 系统设计思想的正确性。
- 系统设计方法的正确性。
- 设计开发工具的正确性。
系统测试的正确性
- 测试目的、方法、条件的正确性。
- 测试结果、数据、记录的正确性。
系统运行的正确性的
- 推理结论、求解结果、咨询建议的正确性。
- 推理解释及可信度估算的正确性。
- 知识库知识的正确性。
有用性
- 推理结论、求解结果、咨询建议的有用性
- 系统的知识水平、可用范围、易扩展性、易更新性等
- 问题的求解能力,可能场合和环境
- 人机交互的友好性
- 运行可靠性、易维护性、可移植性
- 系统的经济性
7.8 专家系统实例及其骨架系统
7.8.1 骨架系统的概念
将描述领域知识的规则从原系统中挖掉,只保留其知识表示方法和与领域无关的推理机等部分,就得到了一个专家系统的骨架系统,保留了原有系统的主要框架。
骨架系统是由已有的成功的专家系统演化而来的,他抽出了原系统中具体的领域知识,而保留了原系统的体系结构和功能,再把领域专用的界面改为通用界面
7.8.2 EMYCIN骨架系统
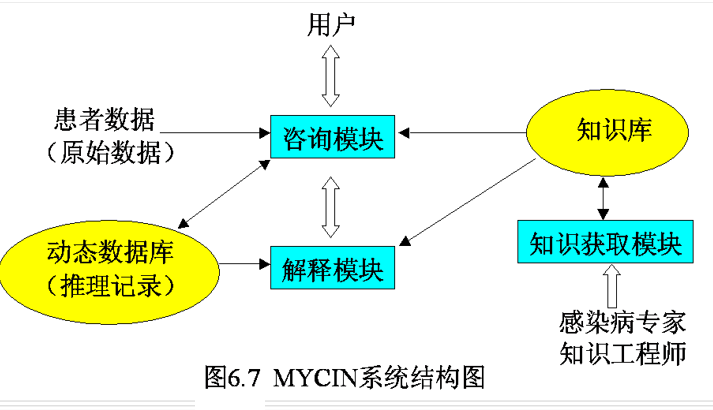
EMYCIN系统的功能:
(1)解释程序。
(2)知识编辑程序及类英语的简化会话语言。
(3)知识库管理和维护手段。
(4)跟踪和调试功能。
EMYCIN系统的工作过程:
(1)专家系统建立过程。
(2)咨询过程。
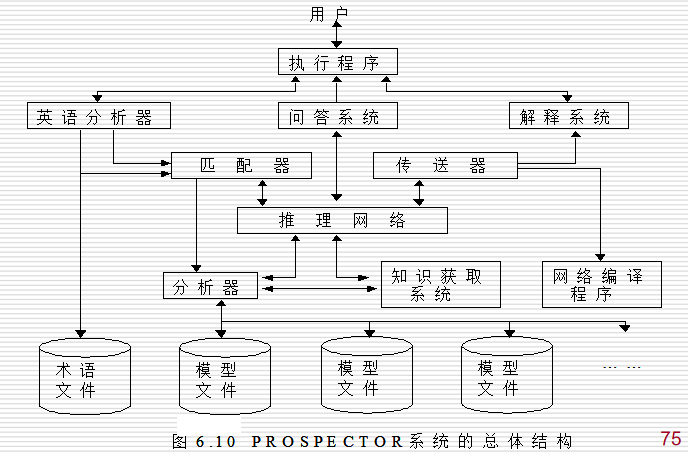
7.8.3 KAS骨架系统
KAS系统:由PROSPECTOR系统抽去原有的地质勘探知识而形成的,适用于开发解释型专家系统。
KAS系统:采用产生式规则和语义网络相结合的知识表达方法及启发式正反向混合推理控制策略。
网络编辑程序:把用户输入的信息转化为相应的语义网络,并检测语法错误和一致性等。
网络匹配程序:分析任意两个语义网络之间的关系,是否具有等价、包含、相交等关系,从而决定是否匹配,同时检测知识库中的知识是否存在矛盾、冗余等。
7.9 专家系统开发环境
专家系统开发环境(专家系统开发工具包):可为专家系统的开发提供多种方便的构件,例如知识获取的辅助工具、适用各种不同知识结构的知识表示模式、各种不同的不确定推理机制、知识库管理系统等
AGE(attempt to generalize):一种典型的模块组合式开发工具
通过AGE构造专家系统的途径:
(1) 用户使用AGE现有的各种组件作为构造材料,方便地组
合设计所需系统。
(2) 用户通过AGE的工具界面,定义和设计各种所需的组成
部件,以构成自己的专家系统。
-
符号处理语言(面向AI的语言或AI语言)
PROLOG语言:基于演绎推理的逻辑型程序设计语言
LISP语言:表处理语言,许多早期专家系统(MYCIN、PROSPECTOR)是用LISP建立的
-
面向对象的语言:Python、C、C++(迷惑
Chapter 8 人工神经网络及其应用
-
人工神经网络(ANN)是对人脑或生物神经网络若干基本特征的抽象和模拟。为机器学习等许多问题的研究提供了一条新的思路,目前已经在模式识别、机器视觉、联想记忆、自动控制、信号处理、软测量、决策分析、智能计算、组合优化问题求解、数据挖掘等方面获得成功应用。
-
神经网络(neural networks,NN)
- 生物神经网络( natural neural network, NNN): 由中枢神经系统(脑和脊髓)及周围神经系统(感觉神经、运动神经等)所构成的错综复杂的神经网络,其中最重要的是脑神经系统。
- 人工神经网络(artificial neural networks, ANN): 模拟人脑神经系统的结构和功能,运用大量简单处理单元经广泛连接而组成的人工网络系统。
-
神经网络方法:隐式的知识表示方法
-
神经网络工作方式:
- 同步(并行)方式:任一时刻神经网络中所有神经元同时调整状态。
- 异步(串行)方式:任一时刻只有一个神经元调整状态,而其它神经元的状态保持不变。
-
正向传播:输入信息由输入层传至隐层,最终在输出层输出。
反向传播:修改各层神经元的权值,使误差信号最小。 -
用神经网络方法求解优化问题的一般步骤:
(1)将优化问题的每一个可行解用换位矩阵表示。
(2)将换位矩阵与由 n 个神经元构成的神经网络相对应:每一个可行解 的换位矩阵的各元素与相应的神经元稳态输出相对应。
(3)构造能量函数,使其最小值对应于优化问题的最优解,并满足约束条 件。
(4)用罚函数法构造目标函数,与 Hopfield 神经网络的计算能量函数表达 式相等,确定各连接权和偏置参数。
(5)给定网络初始状态和网络参数等,使网络按动态方程运行,直到稳定 状态,并将它解释为优化问题的解。
神经网络优化计算目前存在的问题:
(1)解的不稳定性。
(2)参数难以确定。
(3)能量函数存在大量局部极小值,难以保证最优解。
BP
- 简述BP神经网络的学习过程
(1)隐层数及隐层神经元数的确定:目前尚无理论指导。
(2)初始权值的设置:一般以一个均值为 0 的随机分布设置网络的初始权值。
(3)训练数据预处理:线性的特征比例变换,将所有的特征变换到[0,1]或者[-1,1]区间内,使得在每个训练集上,每个特征的均值为 0,并且具有相同的方差。
(4)后处理过程:当应用神经网络进行分类操作时,通常将输出值编码成所谓的名义变量,具体的值对应类别标号。 - BP网络:多层前向网络(输入层、隐层、输出层)。
连接权值:通过Delta学习算法进行修正。
神经元传输函数:S形函数。
学习算法:正向传播、反向传播。
层与层的连接是单向的,信息的传播是双向的。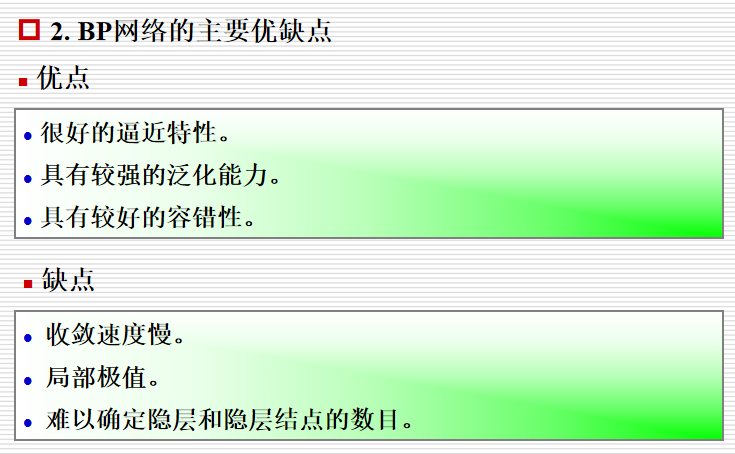
CNN
- CNN 是一个多层的神经网络,每层由多个二维平面组成,而每个平面 由多个独立神经元组成。
- C 层为特征提取层(卷积层)
- S 层是特征映射层(下采样层)。
- CNN 中的每一个 C 层都紧跟着一个 S 层。
- 对不同位置的特征进行聚合统计,称为池化 (pooling)。
- 平均池化、最大池化
- 卷积神经网络在池化层丢失大量的信息,从而降低了空间分辨率,导致了对于输入微小的变化,其输出几乎是不变的
胶囊网络
- 胶囊是一个包含多个神经元的载体,每个神经元表示了图像中出现的 特定实体的各种属性。
- 胶囊不是传统神经网络中的一个神经元,而是一组神经元。
- 胶囊网络的核心思想:胶囊里封装的检测特征的相关信息是以向量的形式 存在的,胶囊的输入是一个向量,是用一组神经元来表示多个特征。
- 使用胶囊神经网络需要的训练数据量,远小于卷积神经网络,它采用动态路由协议算法,仅使用三层网络便可表现出很出色的性能,能够与深度卷积神经网络相当。
- 胶囊网络解决了卷积神经网络存在的信息丢失、视角变化等问题。
- 由于胶囊网络具有分别处理不同属性的能力,相比于CNN可以提高对图像变换的鲁棒性,在图像分割中也会有出色的表现。
- 胶囊网络相对于卷积网络的工作机理更接近人脑的工作方式。
GAN
-
深度学习模型分为判别式模型和生成式模型。
-
判别模型是将一个高维的感官输入映射为一个类别标签。
-
生成网络把随机点变成与数据集相似的图片。
-
目前深度学习取得的成果主要集中在判别式模型
-
GAN 的两个相互交替的训练阶段:
-
固定生成网络,训练判别网络
-
固定判别网络,训练生成网络
-
两个网络相互对抗的过程,就是各自网络参数不断调整的过程,即学习过程。
-
-
GAN在训练中容易出现一些问题,训练过程具有强烈的不稳定性,实验结果随机,具体表现:
- 训练过程难以收敛,经常出现震荡;
- 训练收敛,但是出现模式崩溃(model collapse)。
- 训练收敛,但是GAN还会生成一些没有意义或者现实中不可能出现的图片。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)