Z-Image-Turbo图像生成模型部署全攻略(附GPU优化技巧)
部署阶段:优先使用脚本,避免手动配置错误生产环境:建议搭配Docker容器化部署,提升可移植性资源受限设备:务必开启和fp16双优化提示词编写:采用“主体+动作+环境+风格”四段式结构长期运行:配置systemd服务守护进程,防止意外中断。
Z-Image-Turbo图像生成模型部署全攻略(附GPU优化技巧)
部署背景与核心价值
随着AI图像生成技术的快速发展,阿里通义推出的Z-Image-Turbo凭借其高效的推理速度和高质量输出,在开发者社区中迅速走红。该模型基于扩散机制实现,支持1步快速生成,同时在多步迭代下仍能保持卓越画质表现。本文将围绕由开发者“科哥”二次开发构建的 Z-Image-Turbo WebUI 版本,系统性地讲解从环境搭建、服务启动到性能调优的完整部署流程,并重点分享适用于消费级GPU的显存优化与加速策略。
本项目不仅提供了直观易用的Web界面,还开放了Python API接口,便于集成至自动化工作流或企业级应用中。对于希望在本地高效运行AI绘图任务的技术人员而言,掌握其部署与优化方法具有极强的工程实践意义。
环境准备与依赖配置
基础软硬件要求
| 项目 | 推荐配置 | |------|----------| | 操作系统 | Ubuntu 20.04 / CentOS 7+ / WSL2 | | Python版本 | 3.9+(建议使用Conda管理) | | GPU型号 | NVIDIA RTX 3060及以上(≥12GB显存更佳) | | 显存需求 | ≥8GB(1024×1024尺寸单图生成) | | 存储空间 | ≥20GB(含模型缓存与输出文件) |
提示:首次加载模型需下载约5-8GB参数文件,请确保网络稳定且具备足够磁盘空间。
Conda环境初始化
推荐使用Miniconda进行环境隔离:
# 初始化conda(如未配置)
source /opt/miniconda3/etc/profile.d/conda.sh
# 创建独立环境
conda create -n z-image-turbo python=3.9
conda activate z-image-turbo
# 安装核心依赖
pip install torch==2.1.0+cu118 torchvision==0.16.0+cu118 --extra-index-url https://download.pytorch.org/whl/cu118
pip install gradio diffsynth-studio modelscope
确保CUDA驱动正常识别:
nvidia-smi
python -c "import torch; print(f'GPU可用: {torch.cuda.is_available()}, 数量: {torch.cuda.device_count()}')"
启动服务与WebUI访问
使用脚本一键启动(推荐方式)
项目提供自动化启动脚本,简化部署流程:
bash scripts/start_app.sh
该脚本内部执行以下关键操作: - 激活指定conda环境 - 设置模型缓存路径 - 启动FastAPI后端并绑定Gradio前端 - 输出日志至/tmp/webui_*.log
手动启动命令详解
若需调试或自定义参数,可手动执行:
source /opt/miniconda3/etc/profile.d/conda.sh
conda activate torch28
python -m app.main --host 0.0.0.0 --port 7860 --device cuda:0
常见启动参数说明: - --host:监听地址(设为0.0.0.0允许局域网访问) - --port:HTTP服务端口 - --device:指定运行设备(cuda:0为主GPU) - --offload:启用CPU offload以节省显存(低显存设备必选)
成功启动标志
当终端出现如下信息时,表示服务已就绪:
==================================================
Z-Image-Turbo WebUI 启动中...
==================================================
模型加载成功!
启动服务器: 0.0.0.0:7860
请访问: http://localhost:7860
此时可通过浏览器访问 http://<服务器IP>:7860 进入交互界面。
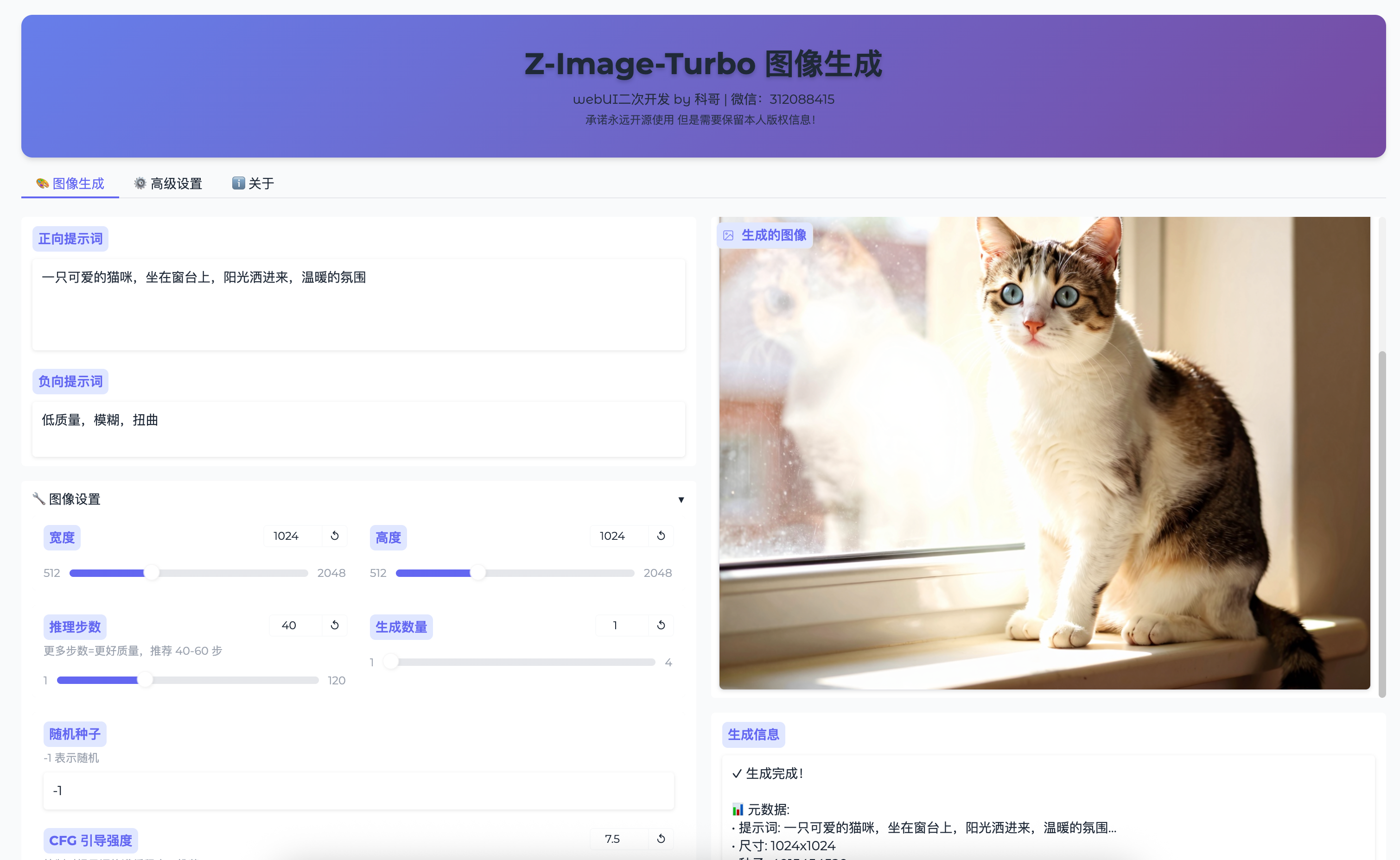
核心功能模块解析
图像生成主界面详解
提示词工程最佳实践
正向提示词(Prompt)设计结构:
-
主体描述:明确对象类型与特征
示例:
一只金毛犬,毛发蓬松,眼神温柔 -
场景与动作:增强画面叙事感
示例:
坐在阳光下的草地上,前爪抱着一个红色皮球 -
风格控制:引导生成质量与艺术倾向
示例:
高清照片,浅景深,细节丰富,自然光效 -
组合示例:
一只金毛犬,毛发蓬松,眼神温柔, 坐在阳光下的草地上,前爪抱着一个红色皮球, 高清照片,浅景深,细节丰富,自然光效
负向提示词(Negative Prompt)作用机制
用于抑制不良视觉元素,提升整体质量。常用关键词包括:
- 质量类:
低质量,模糊,噪点,失真 - 结构类:
扭曲,畸形,多余手指,不对称眼睛 - 光影类:
过曝,阴影过重,反光强烈
建议固定模板:
低质量,模糊,扭曲,丑陋,多余的手指,水印,文字
参数调优矩阵分析
| 参数 | 推荐值 | 影响维度 | 工程建议 | |------|--------|---------|----------| | 宽度/高度 | 1024×1024 | 分辨率 & 显存占用 | 必须为64倍数;超过1536可能OOM | | 推理步数 | 40 | 生成质量 & 时间 | ≥20步显著改善细节;1步仅用于预览 | | CFG引导强度 | 7.5 | 提示词遵循度 | <5创意强但偏离主题;>12易过饱和 | | 随机种子 | -1(自动) | 可复现性 | 固定种子可用于A/B测试对比 | | 生成数量 | 1~2 | 并行负载 | 每增加1张约多占2GB显存 |
GPU显存优化实战技巧
问题定位:显存溢出(OOM)典型症状
- 生成过程中报错
CUDA out of memory - 图像输出残缺或全黑
- 服务崩溃重启
五种有效优化方案
✅ 方案一:启用模型分片加载(Model Offloading)
修改启动脚本中的生成器初始化逻辑:
from app.core.generator import get_generator
generator = get_generator(
enable_offload=True, # 将非活跃层移至CPU
chunk_size=64 # 分块处理大尺寸图像
)
效果:可在8GB显存上运行1024×1024生成任务,速度降低约30%
✅ 方案二:使用FP16半精度推理
在模型加载时强制使用float16:
pipe = DiffusionPipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.float16,
device_map="auto"
)
优势:显存占用减少近50%,推理速度提升15%-20%
✅ 方案三:梯度检查点(Gradient Checkpointing)
适用于训练或微调场景,大幅降低中间激活内存:
model.enable_gradient_checkpointing()
注意:会轻微增加计算时间,但对部署推理影响较小
✅ 方案四:限制并发与批大小
避免多用户同时高负载请求导致瞬时OOM:
# 在app/main.py中设置最大并发
MAX_CONCURRENT_REQUESTS = 2
可通过Nginx或Gunicorn做反向代理限流。
✅ 方案五:动态分辨率缩放策略
根据当前显存状态智能调整输出尺寸:
import torch
def get_optimal_resolution():
free_mem = torch.cuda.mem_get_info()[0] / (1024**3)
if free_mem > 10:
return 1024, 1024
elif free_mem > 6:
return 768, 768
else:
return 512, 512
高级应用场景与API集成
批量图像生成脚本示例
利用Python API实现定时批量创作:
# batch_generate.py
from app.core.generator import get_generator
import time
prompts = [
"樱花树下的少女,动漫风格,粉色长发",
"未来城市夜景,赛博朋克,霓虹灯光",
"雪山湖泊倒影,清晨薄雾,摄影风格"
]
negative_prompt = "低质量,模糊,扭曲"
generator = get_generator()
for i, prompt in enumerate(prompts):
start_time = time.time()
output_paths, gen_time, metadata = generator.generate(
prompt=prompt,
negative_prompt=negative_prompt,
width=1024,
height=1024,
num_inference_steps=50,
cfg_scale=8.0,
num_images=1,
seed=-1
)
print(f"[{i+1}/3] 生成完成: {output_paths[0]}, 耗时: {gen_time:.2f}s")
运行方式:
python batch_generate.py
故障排查与稳定性保障
日志监控与诊断命令
实时查看服务状态:
# 查看端口占用
lsof -ti:7860
# 监控GPU使用情况
nvidia-smi dmon -s u,m,p -d 1
# 跟踪WebUI日志
tail -f /tmp/webui_*.log | grep -E "(ERROR|WARNING)"
常见问题解决方案汇总
| 问题现象 | 可能原因 | 解决措施 | |--------|---------|----------| | 页面无法打开 | 服务未启动或端口被占 | 检查进程、更换端口 | | 首次生成极慢 | 模型未缓存 | 等待首次加载完成即可 | | 图像内容异常 | 提示词冲突或负向词缺失 | 添加多余手指等通用负向词 | | 多次生成相同结果 | 种子未重置 | 确保seed=-1或动态更新 | | 中文提示词无效 | 编码问题 | 统一使用UTF-8保存脚本 |
性能基准测试数据(RTX 3090)
| 尺寸 | 步数 | 精度 | 平均耗时(s) | 显存占用(GB) | |------|------|-------|-------------|---------------| | 512×512 | 1 | FP16 | 1.8 | 4.2 | | 768×768 | 40 | FP16 | 14.3 | 6.1 | | 1024×1024 | 40 | FP16 | 22.7 | 9.8 | | 1024×1024 | 60 | FP16+Offload | 38.5 | 7.3 |
测试环境:CUDA 11.8 + PyTorch 2.1 + Intel Xeon Gold 6248R
最佳实践总结
- 部署阶段:优先使用
scripts/start_app.sh脚本,避免手动配置错误 - 生产环境:建议搭配Docker容器化部署,提升可移植性
- 资源受限设备:务必开启
enable_offload和fp16双优化 - 提示词编写:采用“主体+动作+环境+风格”四段式结构
- 长期运行:配置systemd服务守护进程,防止意外中断
技术支持与生态链接
- 原始模型地址:Z-Image-Turbo @ ModelScope
- 框架源码仓库:DiffSynth Studio GitHub
- 开发者联系:微信 312088415(科哥)
本文档适用于 v1.0.0 版本,更新日志详见项目README。祝您创作愉快!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 22
22 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)