数据处理与统计分析 —— 缺失数据处理(附代码与数据集)
本文介绍了数据集中缺失值的表现形式、判断方法和处理技巧。缺失值在不同环境中可能表示为NULL、NA、空字符串或NaN(在Pandas中)。判断缺失值时,推荐使用pd.isnull()而非np.isnan,因其能处理更多数据类型。处理缺失值主要包括两种方法:删除(dropna)和填充(fillna)。删除适用于少量缺失值,填充则可采用固定值、前后值或线性插值等方式。文章以泰坦尼克号数据集为例,演示了
目录
文章中涉及的数据集文件:
链接:https://pan.quark.cn/s/171a98289398?pwd=VvJt
提取码:VvJt
一、概述
好多数据集都含缺失数据。缺失数据有多重表现形式
- 数据库中,缺失数据表示为NULL
- 在某些编程语言中用NA表示 缺失值也可能是空字符串(’’)或数值
- 在Pandas中使用NaN表示缺失值
Pandas中的NaN值来自NumPy库,NumPy中缺失值有几种表示形式:NaN,NAN,nan,他们都一样缺失值和其它类型的数据不同。
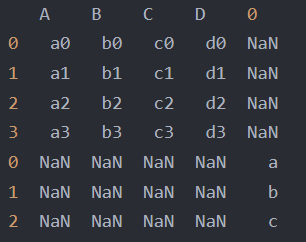
它毫无意义,NaN不等于0,也不等于空串
# 验证:
import numpy as np
import pandas as pd
print(np.NaN == True)
print(np.NaN == False)
print(np.NaN == 0)
print(np.NaN == '')
# 结果均为FalseNaN ≠ NAN ≠ nan
# 2: 缺失值的判断,三种表现形式的判断
print(np.NaN == np.NAN) # False
print(np.NaN == np.nan) # False
print(np.nan == np.NAN) # False二、判断缺失值
Pandas提供了isnull / isna方法,用于测试某个值是否为缺失值
在pandas中,np.isnan和np.isnull的主要区别如下:
功能范围:
np.isnan:只能检测NaN值,专门用于数值型数据
pd.isnull:可以检测NaN、None以及其他类型的缺失值,适用范围更广
处理对象:
np.isnan:只能处理数值型数据,遇到非数值型数据会报错
pd.isnull:可以处理各种数据类型,包括字符串、数值、时间等
对None的处理:
np.isnan:无法处理None值,会抛出异常
pd.isnull:可以正确识别None为缺失值
使用建议:
在pandas中通常推荐使用pd.isnull()np.isnan()(两者功能相同)
对于纯数值数据且确定只有NaN值时,可以使用np.isnan
np.isnull在pandas环境中更安全,因为它能处理更多类型的缺失值
总的来说,在pandas数据处理中,pd.isnull比np.isnan更加通用和安全。
print(np.isnan(np.NAN)) # True
print(np.isnan(np.nan)) # True
print(np.isnan(np.NaN)) # TruePandas的notnull/notna方法也可以用于判断某个值是否为缺失值,即:判断是否不是缺失值
print(pd.isnull(10)) # False
print(pd.isnull('abc')) # False
print(pd.notnull(10)) # True
print(pd.notnull('abc')) # True三、加载缺失值
1、缺失值的来源
- 原始数据包含缺失值
- 数据整理过程中产生缺失值
2、加载缺失值
# 加载数据时可以通过keep_default_na 与 na_values 指定加载数据时的缺失值
pd.read_csv('data/survey_visited.csv')
# 加载数据,不包含默认缺失值
pd.read_csv('data/survey_visited.csv',keep_default_na = False)
# 加载数据,手动指定缺失值
pd.read_csv('data/survey_visited.csv',na_values=["NaN"],keep_default_na = False)
四、处理缺失值
1、读取数据
# 1.1:读取训练数据集
train=pd.read_csv('data/titanic_train.csv')
# 1.2:读取测试数据集
test=pd.read_csv('data/titanic_test.csv')
# 2:查看数据信息
print(train.shape) # (891, 12) (行数,列数)
print(train.head())字段说明:

2、统计 train 数据集中 Survived 列的不同取值及其出现次数
在泰坦尼克号乘客生存预测的经典数据集中,Survived 列通常包含两个值:0:表示乘客未存活 ; 1:表示乘客存活
# 查看是否获救数据(无缺失值情况)
train['Survived'].value_counts()运行结果:
urvived
0 549
1 3423、可视化
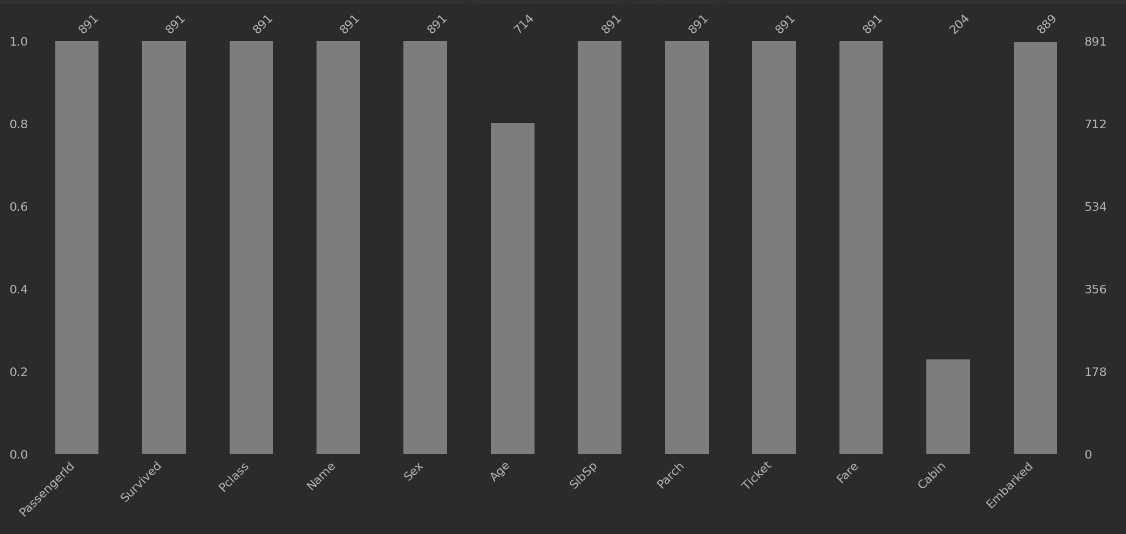
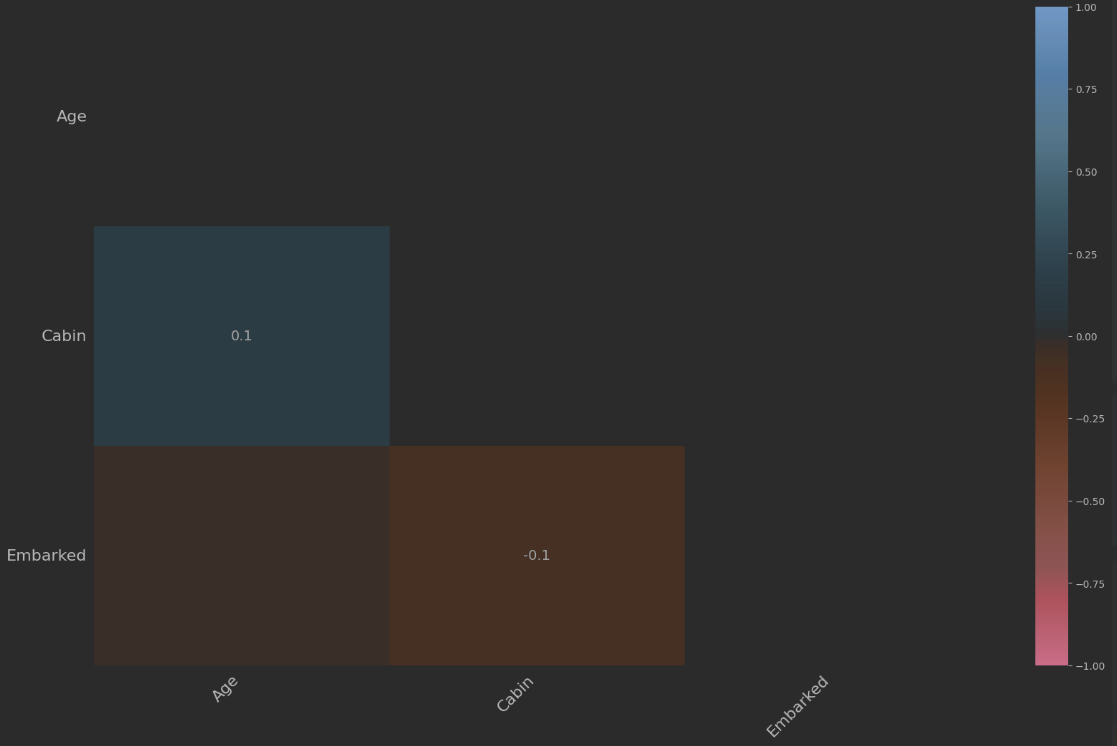
—— 查看缺失值的分布情况
import missingno as msno
import matplotlib.pyplot as plt
# 绘制条形图,查看缺失值的分布情况
msno.bar(train)
plt.show()
# 绘制热力图,查看缺失值的关系
msno.heatmap(train)
plt.show()运行结果:
4、方法一:删除缺失值
如果缺失值占比比较少,可以采用直接删除的方式
参数解释:how: 删除方式:any-任意列有缺失值就删除,all-所有列都有缺失值才删除
axis(默认是0):0-表示删除行,1-表示删除列
inplace(默认是False):True-表示在原数据上操作,False-表示不在原数据上操作,返回新的数据集
# 删除任意有缺失值的行
train.dropna(how='any',inplace=True)
# 删除所有列都有缺失值的行
train.dropna(how='all',inplace=True)
# 删除年龄列中任意有缺失值的行
train.dropna(how='any', subset=['Age'],inplace=True)
# 删除任意有缺失值的列
train.dropna(how='any',axis=1) 删除缺失值:
dropna()
参数:
axis:要删除的轴,0表示行,1表示列,默认0
how:删除的方式,any表示有缺失值就删除,all表示所有值都缺失才删除,默认any
inplace:是否在原数据上操作,True表示在原数据上操作,False表示不在原数据上操作,默认False
返回值:
如果inplace=True,返回None
如果inplace=False,返回新的对象
示例:
df.dropna()
df.dropna(axis=1)
df.dropna(how='all')
df.dropna(inplace=True)
df.dropna(axis=1, inplace=True)
df.dropna(how='all', inplace=True)
df.dropna(axis=1, how='all', inplace=True)
df.dropna(axis=1, how='all', inplace=True)5、方法二:缺失值填充
1、非时间序列数据填充
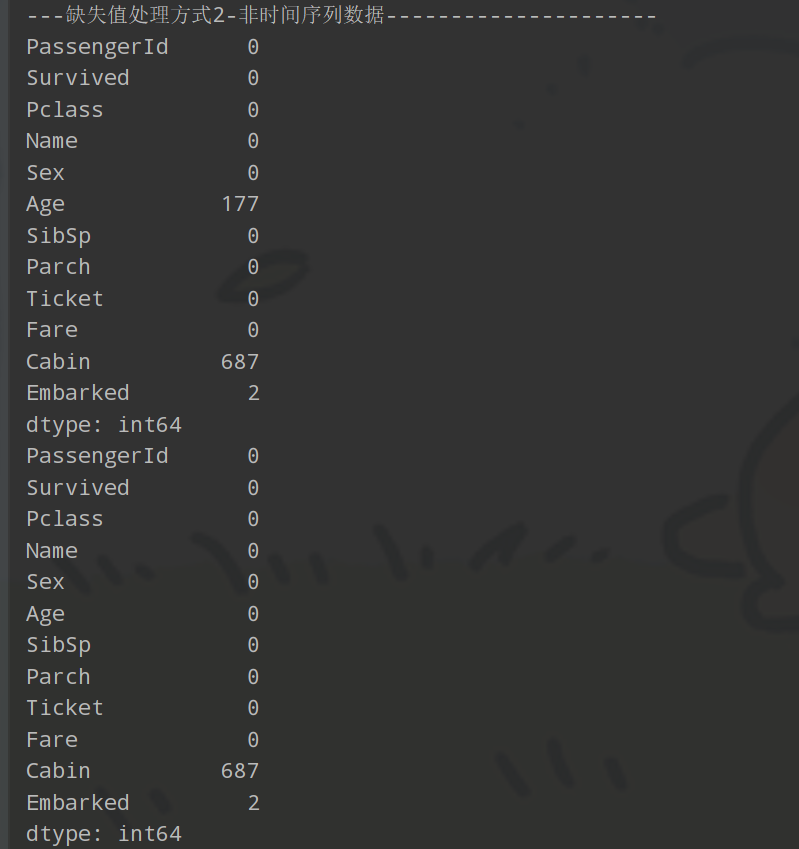
# 打印每列的缺失值数量
print(train.isnull().sum())
# 使用 fillna() 方法将 Age 列中的缺失值填充为 0
train['Age'] = train['Age'].fillna(0)
print(train.isnull().sum())运行结果如下,可以看到空缺值都用0填充
2、时间序列数据填充
try:
city_day = pd.read_csv('data/city_day.csv', parse_dates=['Date'], index_col='Date')
except FileNotFoundError:
raise FileNotFoundError("时间序列数据文件 'data/city_day.csv' 未找到")
city_day_filled = city_day.copy()
# 获取 Xylene 列中索引 50 到 68 的数据用于观察缺失值填充效果
print(city_day_filled['Xylene'][50:68])
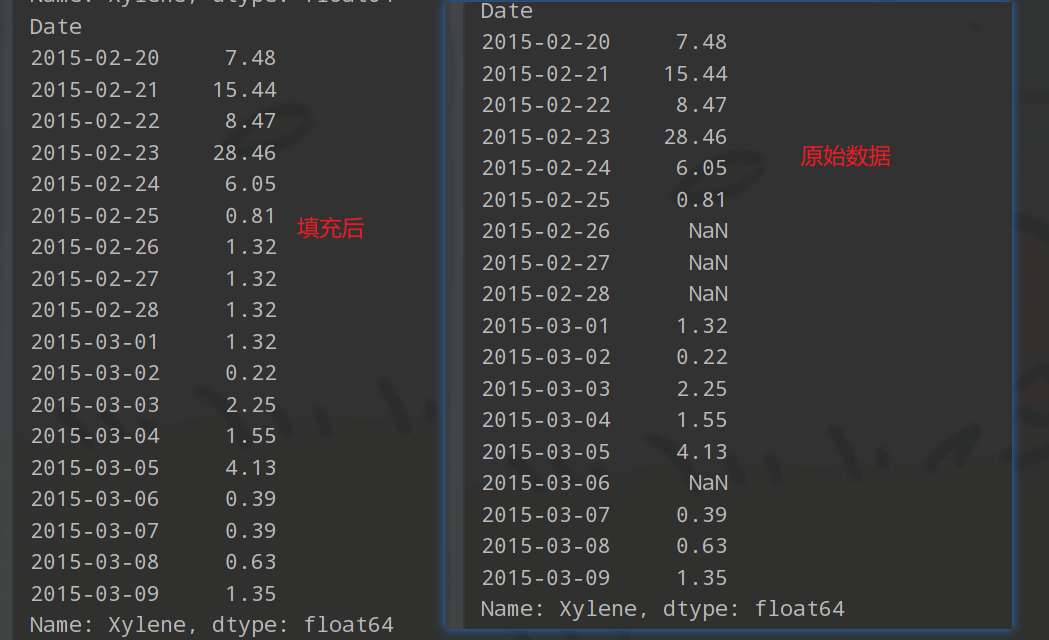
# 使用 bfill 方法(后向填充)填充 Xylene 列中的缺失值
city_day_filled['Xylene'] = city_day_filled['Xylene'].bfill()
print(city_day_filled['Xylene'][50:68])运行结果如下,缺失值由下方的值复制填充上去
3、线性插值方法填充缺失值
# 使用 interpolate 方法进行线性插值填充所有列的缺失值
# limit_direction 参数说明:
# - 'both': 同时使用前向和后向值进行插值
# - 'forward': 只使用前向值进行插值
# - 'backward': 只使用后向值进行插值
city_day_filled = city_day_filled.interpolate(limit_direction="both")
print(city_day_filled['Xylene'][50:68])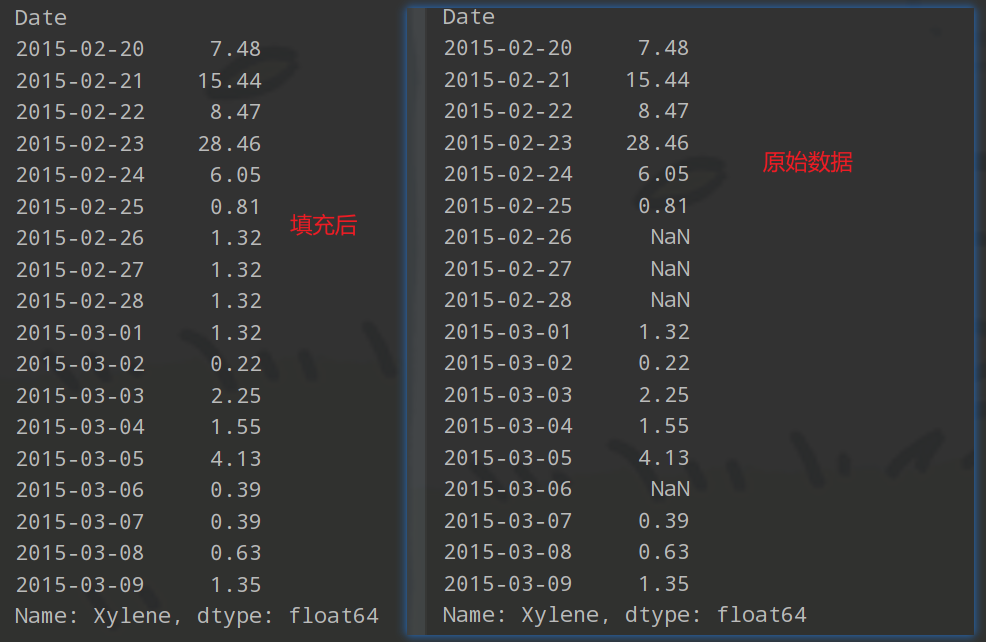
fillna()
参数:
value:要填充的值
method:填充的方式,ffill表示前向填充,bfill表示后向填充,默认是None
axis:要填充的轴,0表示行,1表示列,默认0
inplace:是否在原数据上操作,True表示在原数据上操作,False表示不在原数据上操作,默认False
返回值:
如果inplace=True,返回None
如果inplace=False,返回新的对象
示例:
df.fillna(0)
df.fillna(method='ffill')
df.fillna(method='bfill')
df.fillna(method='ffill', axis=1)
df.fillna(method='bfill', axis=1)
df.fillna(method='ffill', axis=1, inplace=True)
df.fillna(method='bfill', axis=1, inplace=True)
interpolate()
作用:填充缺失值
参数:
method:填充的方式,linear表示线性填充,默认是linear
axis:要填充的轴,0表示行,1表示列,默认0
inplace:是否在原数据上操作,True表示在原数据上操作,False表示不在原数据上操作,默认False
返回值:
如果inplace=True,返回None
如果inplace=False,返回新的对象
示例:
df.interpolate()
df.interpolate(method='linear')
df.interpolate(method='linear', axis=1)
df.interpolate(method='linear', axis=1, inplace=True)
df.interpolate(method='linear', axis=1, inplace=True)
df.interpolate(method='linear', axis=1, inplace=True)
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 42
42 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)