Boosting算法【AdaBoost、GBDT 、XGBoost 、LightGBM】理论介绍及python代码实现
·
1.Boosting算法整体介绍
1.1 Boosting 的基本思想
Boosting 基于这样一种思想:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好。实际上就是“三个臭皮匠顶个诸葛亮”。
1.2 Boosting的发展

AdaBoost和提升树都属于集成学习中的Boosting方法,但它们在实现机制和应用特性上有显著差异。以下是两者的详细对比分析: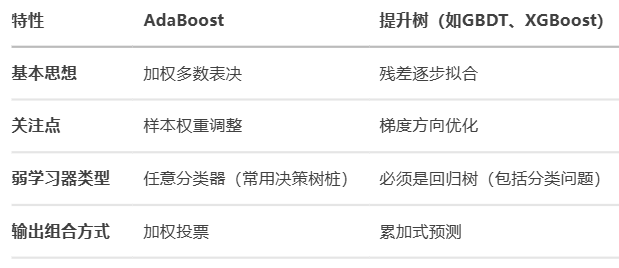
1.2.1 工作原理
AdaBoost工作原理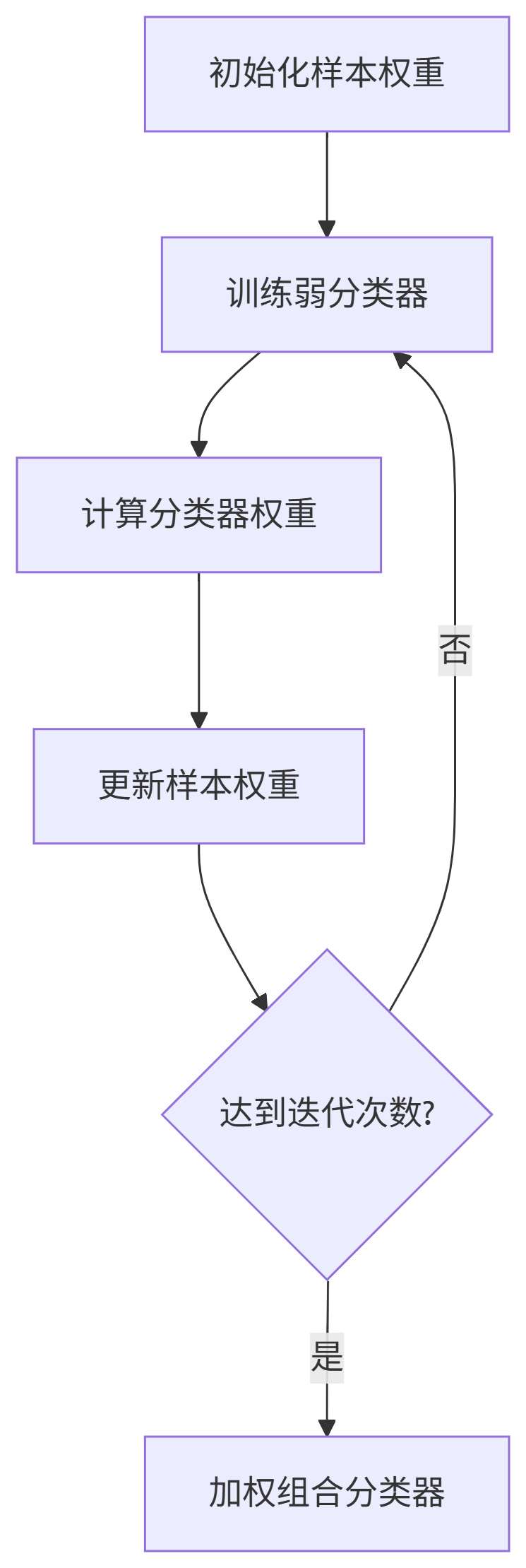
提升树工作原理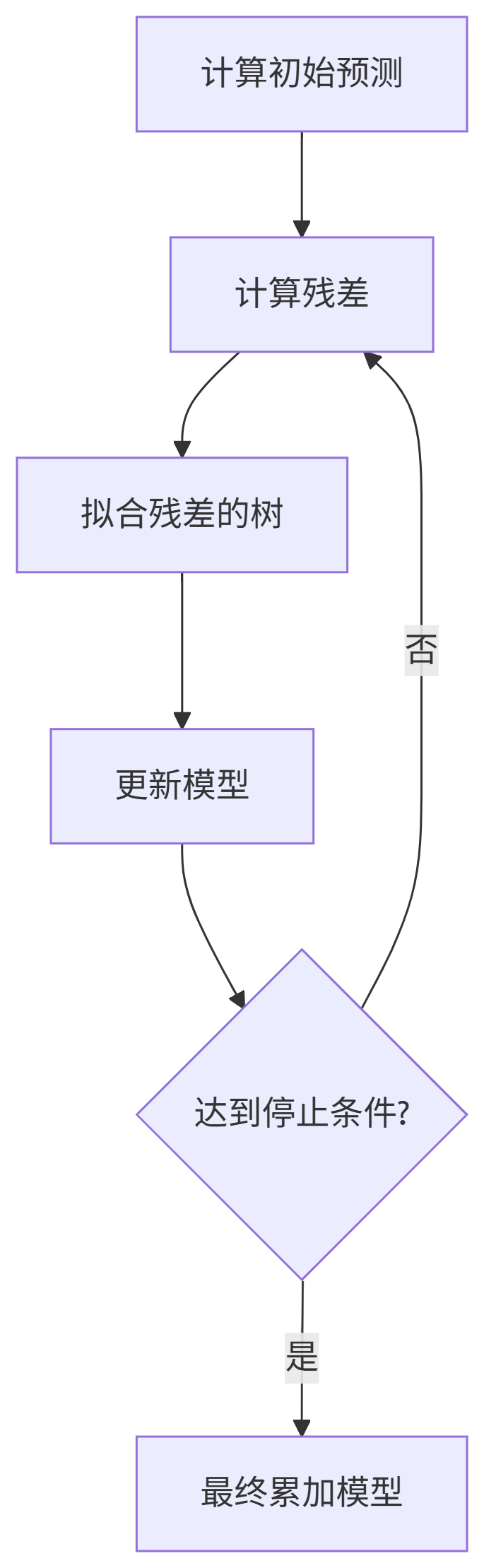
1.2.2 其他对比
损失函数处理方面AdaBoost和提升树的对比差异

实际应用中计算效率对比
2.AdaBoost
- AdaBoost采取加权多数表决的方法,即加大分类误差率小的弱分类器的权重,使其在表决中起较大的作用;减小分类误差率大的弱分类器的权重,使其在表决中起较小的作用。
- AdaBoost最基本的性质是它能在学习过程中不断减少训练误差,即在训练数据集上的分类误差率。
- AdaBoost的训练误差是以指数速率下降的。
- AdaBoost具有适用性,即它能适应弱分类器各自的训练误差率。这也是它的名称(适应的提升)的由来,Ada是Adaptive的简写。
- AdaBoost算法是前向分步加法算法的特例。这时,模型是由基本分类器组成的加法模型,损失函数是指数函数。
2.1 AdaBoost的算法



2.2 AdaBoost的例子


2.3 AdaBoost的python代码实现
2.3.1 自己写python实现逻辑
用表8.1 的数据写一下过程
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
class AdaBoost:
def __init__(self, n_estimators=50):
"""
初始化AdaBoost
:param n_estimators: 弱分类器的数量
"""
self.n_estimators = n_estimators
self.estimators = [] # 存储弱分类器
self.estimator_weights = [] # 存储每个弱分类器的权重
self.estimator_errors = [] # 存储每个弱分类器的错误率
def fit(self, X, y):
"""
训练AdaBoost模型
:param X: 训练数据,形状为(n_samples, n_features)
:param y: 目标值,形状为(n_samples,)
"""
n_samples = X.shape[0]
# 初始化样本权重为均匀分布
sample_weights = np.ones(n_samples) / n_samples
for _ in range(self.n_estimators):
# 训练一个弱分类器(这里使用决策树桩,max_depth=1)
estimator = DecisionTreeClassifier(max_depth=1)
estimator.fit(X, y, sample_weight=sample_weights)
# 计算预测结果和错误率
y_pred = estimator.predict(X)
incorrect = (y_pred != y)
estimator_error = np.sum(sample_weights * incorrect) / np.sum(sample_weights)
# print('误差率:',estimator_error)
# 如果错误率大于0.5,则丢弃这个分类器(
if estimator_error >= 0.5:
continue
# 计算当前分类器的权重
estimator_weight = np.log((1 - estimator_error) / estimator_error) / 2
# print('当前分类器的权重:',estimator_weight)
# 更新样本权重
sample_weights *= np.exp(estimator_weight * incorrect)
sample_weights /= np.sum(sample_weights) # 归一化
# 保存分类器及其权重
self.estimators.append(estimator)
self.estimator_weights.append(estimator_weight)
self.estimator_errors.append(estimator_error)
# 如果错误率为0,提前终止
if estimator_error == 0:
break
def predict(self, X):
"""
使用训练好的模型进行预测
:param X: 输入数据,形状为(n_samples, n_features)
:return: 预测结果,形状为(n_samples,)
"""
# 初始化预测值为0
pred = np.zeros(X.shape[0])
# 对每个分类器的预测结果进行加权求和
for estimator, weight in zip(self.estimators, self.estimator_weights):
pred += weight * estimator.predict(X)
# 返回符号函数的结果(大于0为1,小于0为-1)
return np.sign(pred)
def score(self, X, y):
"""
计算模型在给定数据上的准确率
:param X: 输入数据
:param y: 真实标签
:return: 准确率
"""
y_pred = self.predict(X)
return accuracy_score(y, y_pred)
if __name__ == "__main__":
# 生成模拟数据
X = np.array([[0],[1],[2],[3],[4],[5],[6],[7],[8],[9]])
y = np.array([1,1,1,-1,-1,-1,1,1,1,-1])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=429)
# 训练AdaBoost模型
ada = AdaBoost(n_estimators=50)
ada.fit(X_train, y_train)
estimator_weights = ada.estimator_weights #每个弱分类器的权重
estimators = ada.estimators #每个弱分类器的权重
estimator_errors = ada.estimator_errors #个弱分类器的错误率
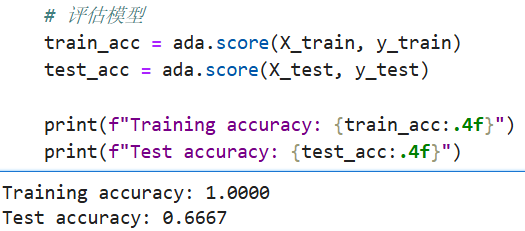
# 评估模型
train_acc = ada.score(X_train, y_train)
test_acc = ada.score(X_test, y_test)
print(f"Training accuracy: {train_acc:.4f}")
print(f"Test accuracy: {test_acc:.4f}")
2.3.2 scikit-learn提供的AdaBoostClassifier实现
基本用法
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.tree import DecisionTreeClassifier
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=429)
# 创建AdaBoost分类器
# 使用决策树桩(max_depth=1)作为弱分类器
ada_clf = AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=50,
algorithm='SAMME.R',
random_state=42
)
# 训练模型
ada_clf.fit(X_train, y_train)
# 预测
y_pred = ada_clf.predict(X_test)
# 评估
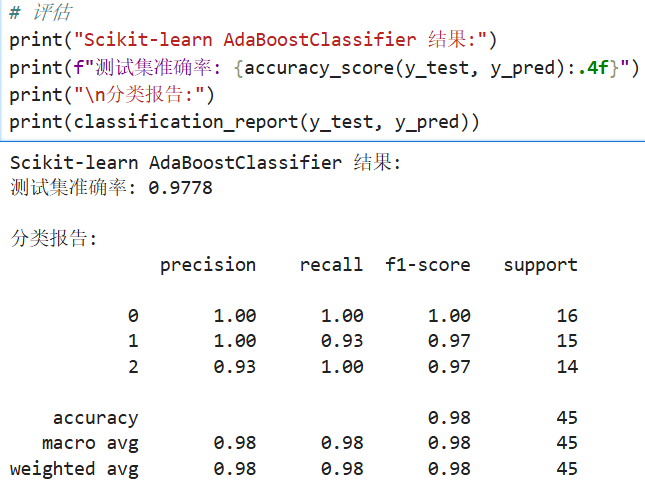
print("Scikit-learn AdaBoostClassifier 结果:")
print(f"测试集准确率: {accuracy_score(y_test, y_pred):.4f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))
AdaBoostClassifier里的参数介绍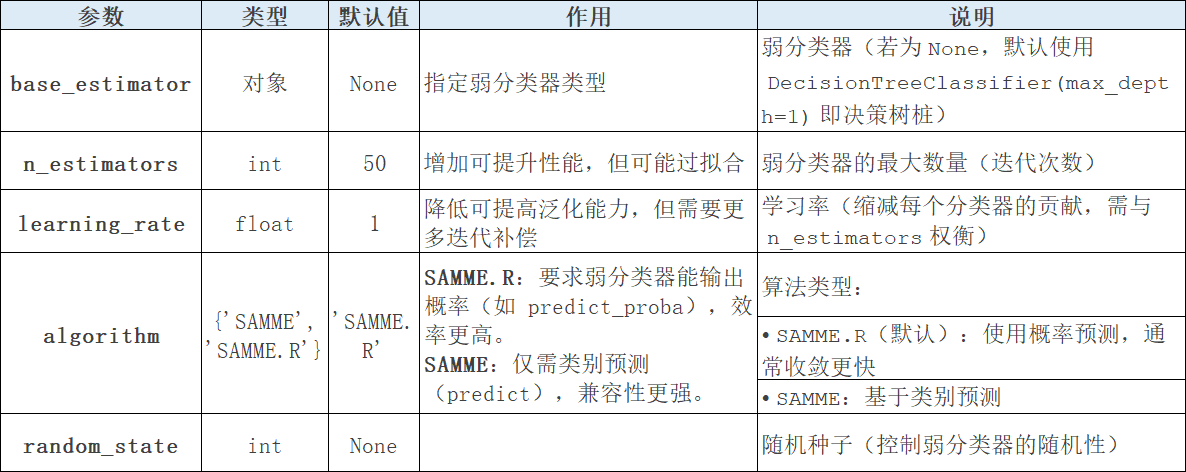
自定义弱分类器
from sklearn.svm import SVC
# 使用SVM作为弱分类器(需设置probability=True)
svc = SVC(kernel='linear', probability=True, random_state=42)
self_clf = AdaBoostClassifier(estimator=svc, n_estimators=50)
self_clf.fit(X_train, y_train)
# 预测
y_pred = self_clf.predict(X_test)
# 评估
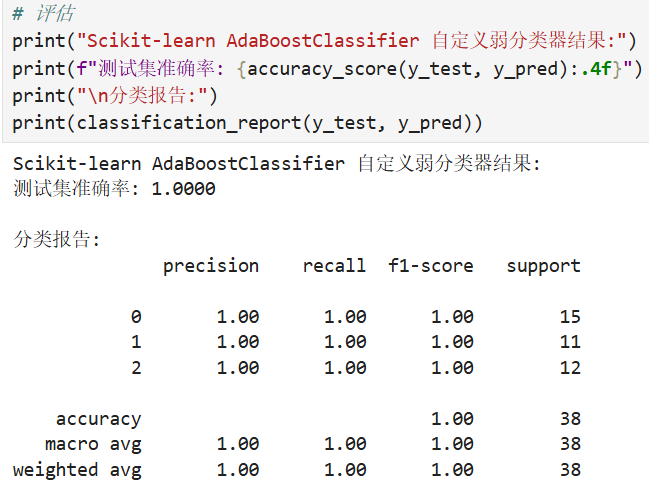
print("Scikit-learn AdaBoostClassifier 自定义弱分类器结果:")
print(f"测试集准确率: {accuracy_score(y_test, y_pred):.4f}")
print("\n分类报告:")
print(classification_report(y_test, y_pred))
3.提升树之——【GBDT、XGBoost 、LightGBM综合比较】
1. Boosting 实际采用加法模型(即基函数的线性组合)与前向分步算法。
2. 以决策树为基函数的Boosting称为提升树(boosting tree), 针对不同问题的提升树学习算法,其主要区别在于使用的损失函数不同。
3. 对回归问题的提升树算法来说,只需简单地拟合当前模型的残差。
3.0 提升树理论




3.1 核心原理对比
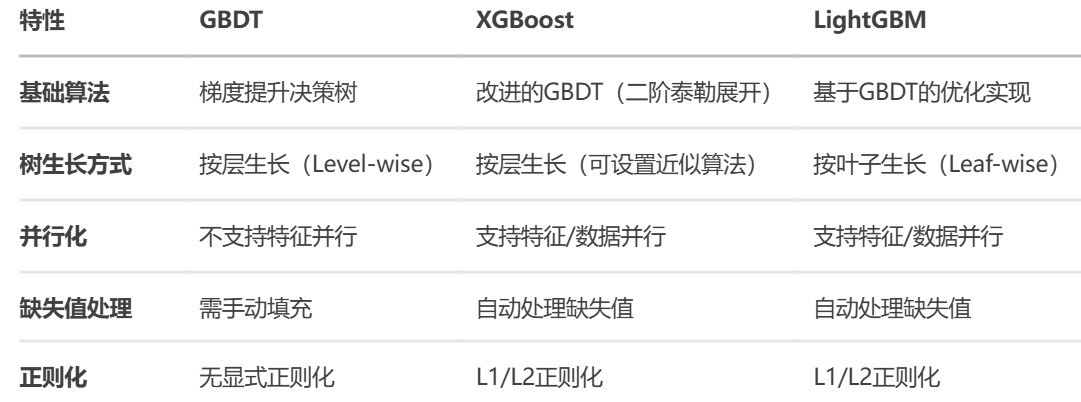
3.2 性能与效率对比
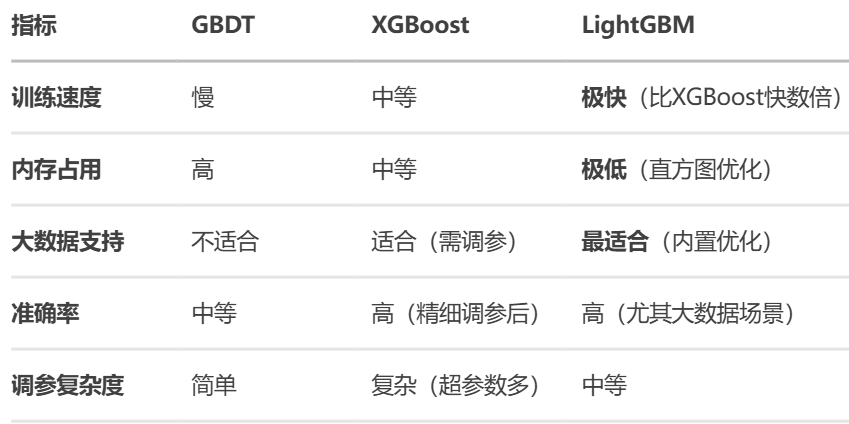
3.3 模型优缺点


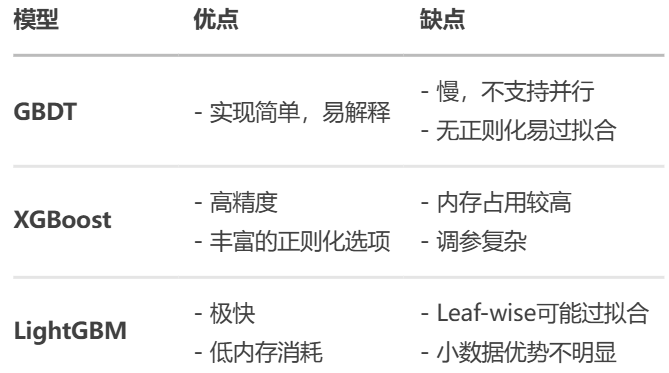
4.模型分别实现
4.1 GDBT
4.2 XGBoost
4.3 LightGBM

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)