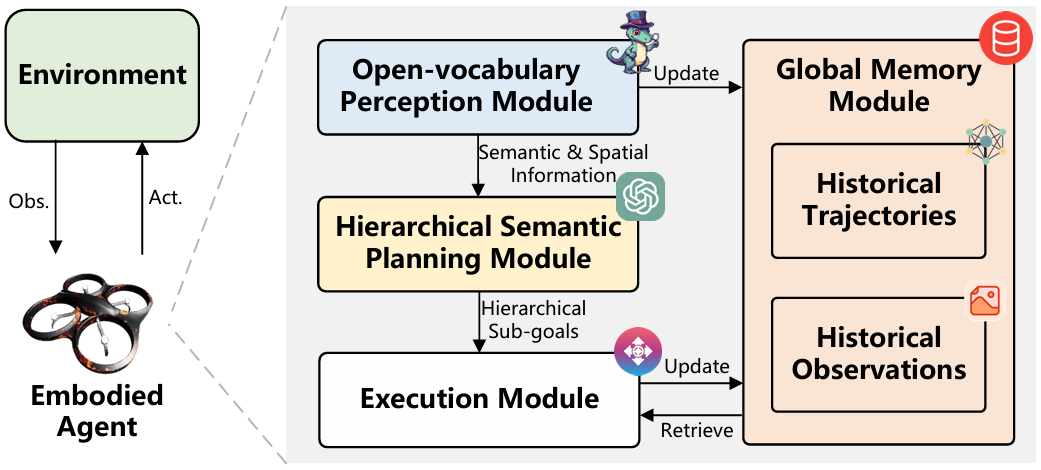
清华大学无人机城市空间导航探索!CityNavAgent:基于层次语义规划与全局记忆的空中视觉语言导航
CityNavAgent通过利用基础模型中的预训练知识和历史经验,有效解决了城市空间中的长期导航问题。

- 作者: Weichen Zhang, Chen Gao, Shiquan Yu, Ruiying Peng, Baining Zhao, Qian Zhang, Jinqiang Cui, Xinlei Chen, Yong Li
- 单位:清华大学
- 论文标题:CityNavAgent: Aerial Vision-and-Language Navigation with Hierarchical Semantic Planning and Global Memory
- 论文链接:https://www.arxiv.org/pdf/2505.05622
- 代码链接:https://github.com/VinceOuti/CityNavAgent (coming soon)
主要贡献
- 提出了用于城市空中视觉语言导航(VLN)的智能体CityNavAgent,它借助大模型(LLM)实现零样本导航,有效解决了复杂城市环境中无人机的导航问题。
- 设计了开放词汇感知模块,能够理解城市场景中的复杂语义信息,以及一个层次化语义规划模块(HSPM)和全局记忆模块,显著降低了动作规划的复杂性。
- 在两个空中VLN基准测试中进行了广泛的实验,结果表明该方法在成功率和路径遵循方面达到了最先进的性能,并通过消融研究验证了CityNavAgent各组件的有效性。
背景介绍
-
视觉语言导航(VLN)是一项基础任务,要求智能体根据语言指令导航到指定的地标或位置。随着无人机的普及,空中VLN受到更多关注,它使无人机能够在复杂的大规模户外环境中导航,降低人机交互成本,并在救援、运输和城市检查等领域具有显著优势。
-
现有的地面VLN智能体在室内和室外环境中取得了显著成果,但在空中VLN中表现不佳,因为空中VLN缺乏预定义的导航图,并且在长视界探索中动作空间呈指数级增长。
-
相关工作:
- 视觉语言导航(VLN):R2R是首个定义良好的VLN基准测试,此后出现了许多方法以提高机器人的具身导航能力。然而,这些方法大多局限于室内场景和离散动作空间,限制了其在现实世界中的应用。
- LLM在具身导航中的应用:随着LLM的发展,许多方法利用其推理能力实现零样本VLN。但现有方法在将LLM应用于户外环境时面临挑战,主要是因为需要构建环境的语义地图,以便LLM能够基于语义信息进行推理和预测下一个航点。
问题定义
- 任务目标:给定一条自然语言指令 III 和无人机(agent)的自身视角观察 OOO,无人机需要在连续的三维空间中确定一系列动作,以到达目标位置 pdp_dpd。
- 动作预测:在每个动作步骤 ttt,无人机根据当前观察 oto_tot 和指令 III,通过策略 π\piπ 预测下一个动作 ata_tat,并通过其运动模型 FFF 移动到位置 ptp_tpt。这一过程可以用以下公式表示:
pt=F(pt−1,π(ot,I)) p_t = F(p_{t-1}, \pi(o_t, I)) pt=F(pt−1,π(ot,I))
其中,pt−1p_{t-1}pt−1 是无人机在上一步的位置,FFF 是无人机的动力学模型,描述了其如何根据动作 ata_tat 从当前位置移动到下一个位置。 - 成功概率:无人机到达目标位置的成功概率 PsP_sPs 定义为最终位置与目标位置之间的欧几里得距离小于某个阈值 ϵ\epsilonϵ 的概率,即:
Ps=P(∣∣F(π(p0,O,I))−pd∣∣<ϵ) P_s = P(||F(\pi(p_0, O, I)) - p_d|| < \epsilon) Ps=P(∣∣F(π(p0,O,I))−pd∣∣<ϵ)
其中,ϵ\epsilonϵ 是一个预定义的阈值,用于判断无人机是否到达目标位置。 - 目标:空中 VLN 的目标是找到一个策略 π∗\pi^*π∗,使得成功概率 PsP_sPs 最大化,即:
π∗=argmaxπPs \pi^* = \arg\max_{\pi} P_s π∗=argπmaxPs
这意味着需要设计一个能够最大化无人机到达目标位置概率的导航策略。
CityNavAgent
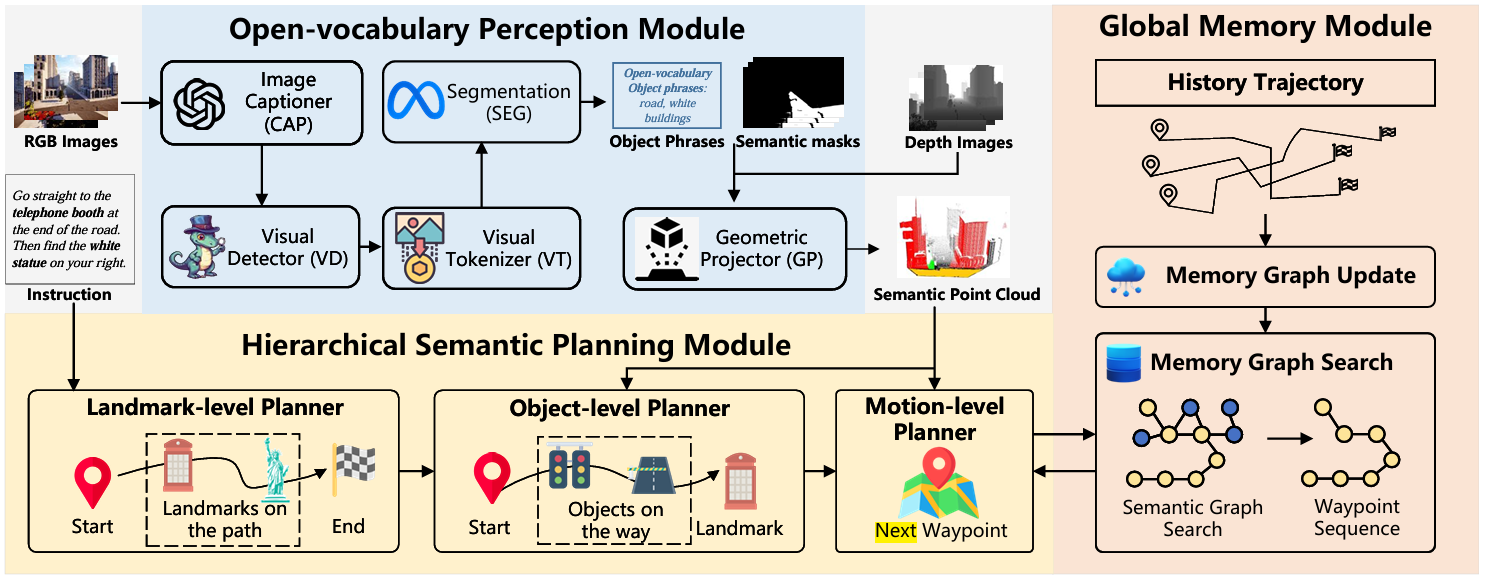
开放词汇感知模块
场景语义感知
为了提取城市场景中的语义信息,该模块使用了一个基于LLM的开放词汇图像描述器(captioner)和一个视觉检测器(detector)。具体步骤如下:
- 使用GPT-4V作为图像描述器,为每张全景图像生成描述对象的标题(caption):
cti=CAP(Iti) c_t^i = \text{CAP}(I_t^i) cti=CAP(Iti) - 使用GroundingDINO作为视觉检测器,根据标题生成对象的边界框:
obbi=VD(cti,Iti) \text{obb}^i = \text{VD}(c_t^i, I_t^i) obbi=VD(cti,Iti) - 使用视觉标记器将边界框标记化,并输入到分割模型中生成对象的细粒度语义掩码:
ItS=SEG(VT(obbi),Iti) I_t^S = \text{SEG}(\text{VT}(\text{obb}^i), I_t^i) ItS=SEG(VT(obbi),Iti)
场景空间感知
由于单一视角的图像存在视角重叠和无法捕捉3D空间关系的问题,该模块通过将分割掩码投影到度量3D空间中,构建一个3D点云图。具体步骤如下:
- 使用RGB-D传感器的深度图和无人机的姿态(R, T),将每个分割像素pik=(u,v)∈ItSp_{ik} = (u, v) \in I_t^Spik=(u,v)∈ItS标记为标题ctikc_t^{ik}ctik,并将其投影到3D点PikP_{ik}Pik:
Pik=R⋅ID(u,v)⋅K−1⋅p+T P_{ik} = R \cdot I_D(u, v) \cdot K^{-1} \cdot p + T Pik=R⋅ID(u,v)⋅K−1⋅p+T
其中,KKK是相机的内参矩阵,R∈SO(3)R \in \text{SO}(3)R∈SO(3)和T∈R3T \in \mathbb{R}^3T∈R3分别表示无人机在世界坐标系中的瞬时方向和位置。 - 将对象标题从2D掩码映射到3D点云,构建局部语义点云:
{(Pik,ctik)∣i=1,…,n,k=1,…,m} \{(P_{ik}, c_t^{ik}) \mid i = 1, \ldots, n, k = 1, \ldots, m\} {(Pik,ctik)∣i=1,…,n,k=1,…,m}
其中,nnn是全景图像的数量,mmm是像素的数量。
层次化语义规划模块
该模块通过将导航任务分解为不同语义层次的子目标,逐步降低规划的复杂性。
地标级规划
该模块利用LLM解析自由形式的指令,提取沿路径的地标序列作为子目标。具体步骤如下:
- 使用LLM(如GPT-4V)解析指令TTT,提取地标序列LLL:
L=LLM(T) L = \text{LLM}(T) L=LLM(T) - 通过prompt工程,将指令分解为有序的地标序列。
对象级规划
该模块利用LLM的常识知识,进一步将地标级子目标分解为更具体的对象级子目标。具体步骤如下:
- 使用LLM根据当前观测到的对象和子目标,推断出最相关的对象区域(OROI):
ctOROI=OP(T,Li,ct) c_t^{\text{OROI}} = \text{OP}(T, L_i, c_t) ctOROI=OP(T,Li,ct) - 通过prompt工程,让LLM根据指令、子目标和观测到的对象,列出最相关的对象。
运动级规划
- 负责将高级规划模块的输出转换为无人机可到达的航点和可执行动作。
- 首先从语义点云中确定与推理出的 ctOROIc_{t}^{\text{OROI}}ctOROI 对应的点 {(Pk,ck)∣ck==ctOROI}\{(P_k, c_k) | c_k == c_{t}^{\text{OROI}}\}{(Pk,ck)∣ck==ctOROI},并通过计算这些点的坐标平均值来确定下一个航点。
- 然后将路径分解为一系列可执行动作。如果无人机接近记忆图中的位置,运动规划器将直接使用记忆图来预测无人机的未来动作。
全局记忆模块
该模块通过存储历史轨迹,帮助智能体在重复访问目标或地标时减少动作空间,提高导航的鲁棒性。
记忆图构建
每个历史轨迹HiH_iHi表示为一个拓扑图Gi(Ni,Ei)G_i(N_i, E_i)Gi(Ni,Ei),其中节点NiN_iNi包含遍历航点的坐标及其全景观测,边EiE_iEi根据相邻航点之间的距离加权。记忆图MMM通过合并所有历史轨迹图构建:
M=G(N,E),N=N1∪⋯∪Nd,E=E1∪⋯∪Ed M = G(N, E), \quad N = N_1 \cup \cdots \cup N_d, \quad E = E_1 \cup \cdots \cup E_d M=G(N,E),N=N1∪⋯∪Nd,E=E1∪⋯∪Ed
其中,ddd是历史轨迹的数量。
记忆图更新
通过合并新生成的历史轨迹图GhistG_{\text{hist}}Ghist来更新记忆图。如果两个图中的节点距离小于阈值H=15H = 15H=15米,则认为这两个节点是相邻的,并在合并图中添加一条新边。
记忆图搜索
当智能体到达记忆图中的一个节点时,直接利用记忆图确定路径和动作序列,以完成剩余的子目标。目标是找到一条路径V∗V^*V∗,使得按顺序遍历地标序列L(r)L(r)L(r)的概率最高:
V∗=argmaxV∏k=1rP(lk∣ovmk) V^* = \arg\max_V \prod_{k=1}^{r} P(l_k \mid o_{v_{m_k}}) V∗=argVmaxk=1∏rP(lk∣ovmk)
其中,P(lk∣ovmk)P(l_k \mid o_{v_{m_k}})P(lk∣ovmk)表示节点vmkv_{m_k}vmk观测到地标lkl_klk的概率。使用图搜索算法(如Dijkstra算法)解决该问题。
实验
- 数据集
- 在由Liu等人提供的新型空中VLN基准测试AirVLN-S上评估CityNavAgent。
- 并针对AirVLN中指令较为模糊的问题,收集了101个细粒度指令路径对,构建了名为AirVLNEnriched的指令丰富的空中VLN基准测试。
- 评估指标:
- 采用与AirVLN相同的指标,包括成功率(SR)、按Oracle成功率(OSR)、导航误差(NE)、按归一化动态扭曲加权的成功率(SDTD)和按路径长度加权的成功率(SPL)。
- 基线方法:
- 选择了三种主流类型的连续VLN基线方法,包括基于统计的方法、基于学习的方法和基于零样本LLM的方法。
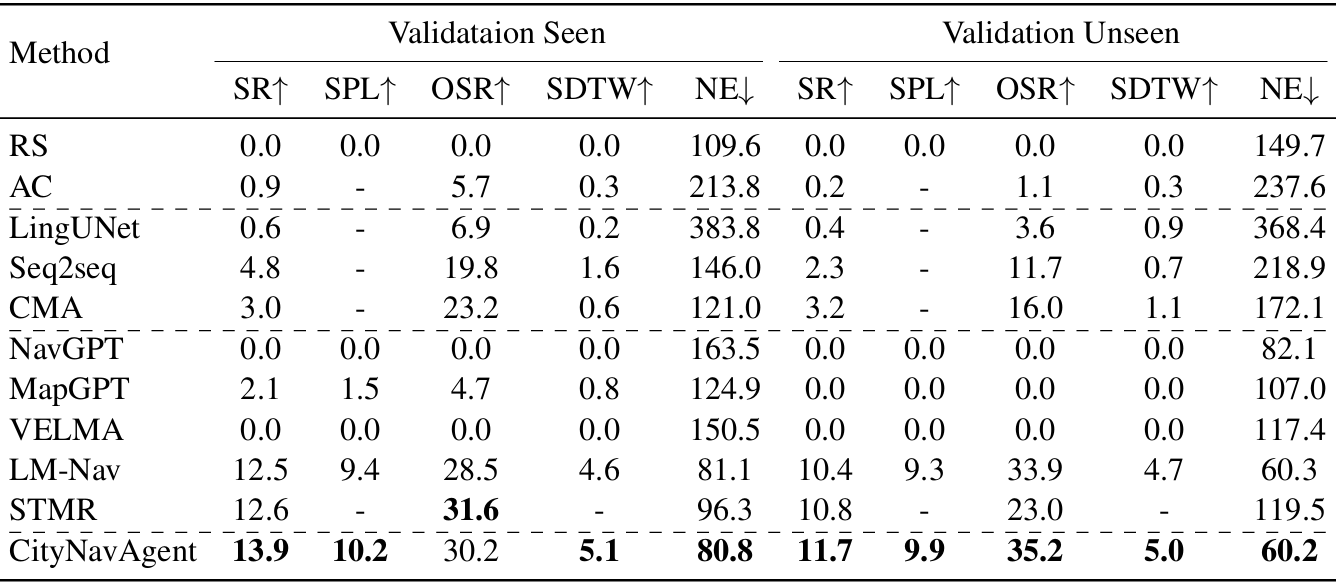
- 整体性能:
- CityNavAgent在两个空中VLN基准测试中的表现显著优于以往的最佳方法,在成功率、路径遵循性能等方面均有提升;
- 在AirVLNEnriched数据集上的性能提升更为明显,表明丰富指令有助于提高导航性能。
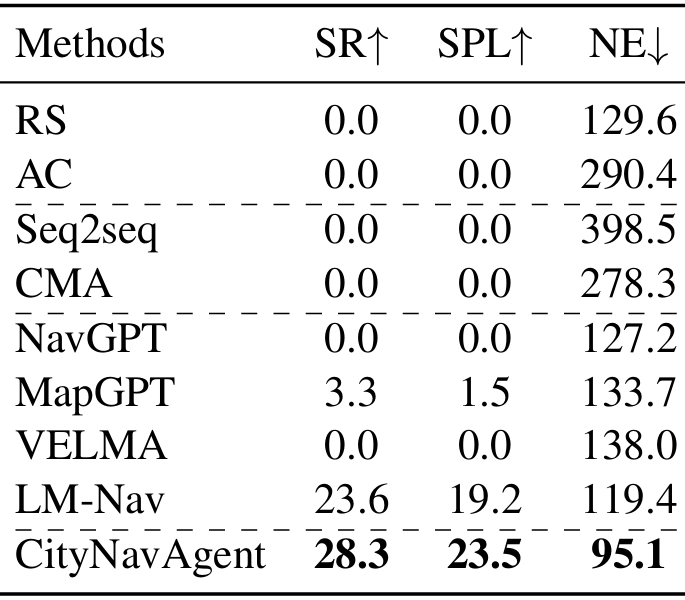
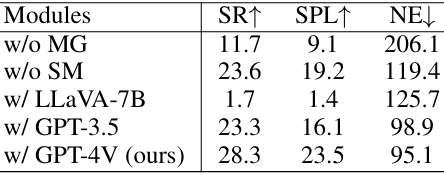
- 消融研究:
- 验证了语义地图和记忆图在导航中的有效性,结果表明语义地图能够帮助智能体更准确、高效地导航,而记忆图则在长距离户外导航中对稳定性的提升更为显著;
- 此外,使用不同LLM进行对象级规划时,GPT-4V由于其更强的推理能力和更低的幻觉率,使智能体的性能得到进一步提升。
- 室内航点预测的有效性:
- 比较了CWP方法在室内外环境中预测航点的质量,发现其在室内环境中表现较好,但在室外环境中由于室内外环境的尺度差异和维度差异,预测的航点与目标航点存在较大偏差。
- 案例分析:
- 分析了不同数据集上的失败案例,并将其分为三种类型:指令歧义、感知失败和推理模块失败。
- 对于AirVLN-S数据集,大多数失败案例来自指令歧义;而对于AirVLN-E数据集,由于其具有细粒度的地标,大多数失败案例来自感知失败。

结论与未来工作
- 结论:
- CityNavAgent通过利用基础模型中的预训练知识和历史经验,有效解决了城市空间中的长期导航问题。
- 实验结果从不同角度证明了该方法的有效性和鲁棒性。
- 未来工作:
- 该研究的局限性在于整个系统尚未在真实无人机上部署,且智能体缺乏回溯机制。
- 未来的工作可以考虑将该方法应用于真实无人机,并进一步改进智能体的导航能力,例如引入回溯机制以提高导航的可靠性。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 13
13 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)