【完整源码+数据集+部署教程】道路障碍物分割系统源码&数据集分享 [yolov8-seg-repvit等50+全套改进创新点发刊_一键训练教程_Web前端展示]
【完整源码+数据集+部署教程】道路障碍物分割系统源码&数据集分享[yolov8-seg-repvit等50+全套改进创新点发刊_一键训练教程_Web前端展示]
背景意义
随着城市化进程的加快,城市道路的安全性和通行效率日益受到关注。道路障碍物,如井盖、坑洞、减速带等,不仅影响了交通流畅性,还可能对行人和车辆造成安全隐患。因此,及时、准确地识别和分割这些障碍物,对于城市交通管理、道路维护及智能驾驶系统的实现具有重要意义。近年来,深度学习技术的迅猛发展为图像分割任务提供了新的解决方案,其中YOLO(You Only Look Once)系列模型因其高效的实时检测能力而备受青睐。特别是YOLOv8的推出,进一步提升了目标检测和分割的精度与速度,使其在道路障碍物检测中展现出广阔的应用前景。
本研究旨在基于改进的YOLOv8模型,构建一个高效的道路障碍物分割系统。该系统将针对特定的障碍物类别进行优化,包括井盖、开放井盖、坑洞、减速带和未标记的减速带等五类。我们使用的数据集包含3500张图像,涵盖了上述五类障碍物的多样性和复杂性。这一数据集的构建不仅考虑了不同环境下的障碍物特征,还兼顾了光照、天气等因素对图像质量的影响,为模型的训练和验证提供了丰富的样本。
在实际应用中,传统的道路障碍物检测方法往往依赖于人工巡查和图像处理技术,效率低下且容易受到人为因素的影响。而基于深度学习的自动化检测系统,能够通过实时图像分析,快速识别和定位障碍物,极大地提高了工作效率。此外,随着智能交通系统的发展,如何将障碍物检测与自动驾驶技术相结合,成为了研究的热点。通过对道路障碍物的精准分割,智能驾驶系统能够更好地理解周围环境,从而做出更为安全的行驶决策。
然而,现有的YOLOv8模型在处理道路障碍物分割任务时,仍存在一些挑战。例如,模型在复杂背景下的障碍物识别能力、不同障碍物之间的相似性导致的混淆等问题。因此,本研究将对YOLOv8进行改进,采用数据增强、特征融合等技术,提升模型在道路障碍物分割任务中的表现。通过引入更为丰富的训练样本和优化算法,我们期望能够提高模型的鲁棒性和准确性,使其在各种实际场景中均能稳定运行。
综上所述,基于改进YOLOv8的道路障碍物分割系统的研究,不仅具有重要的理论意义,也为实际应用提供了切实可行的解决方案。通过实现高效、准确的障碍物检测与分割,我们将为城市交通管理、道路安全维护以及智能驾驶技术的发展做出积极贡献。
图片效果
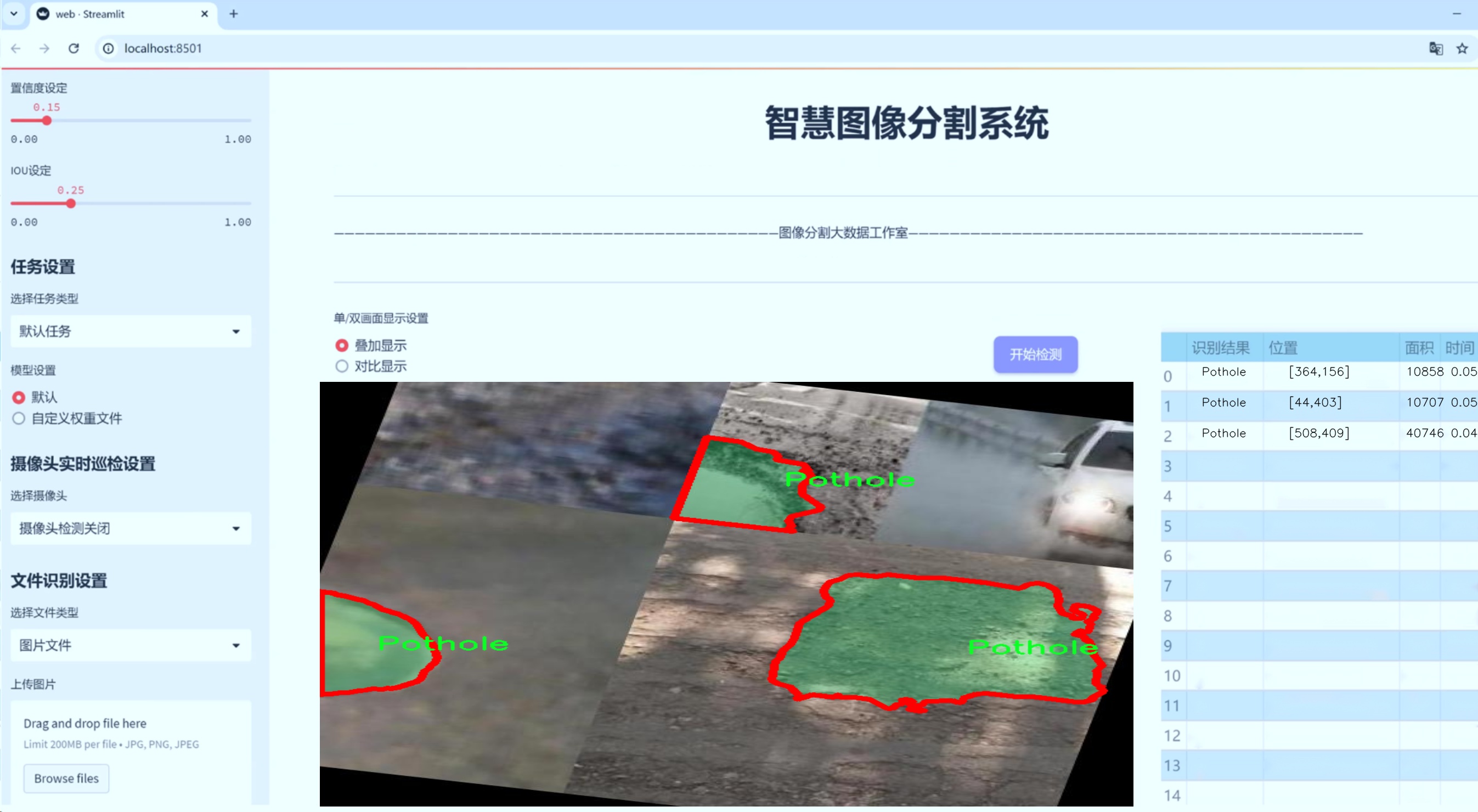
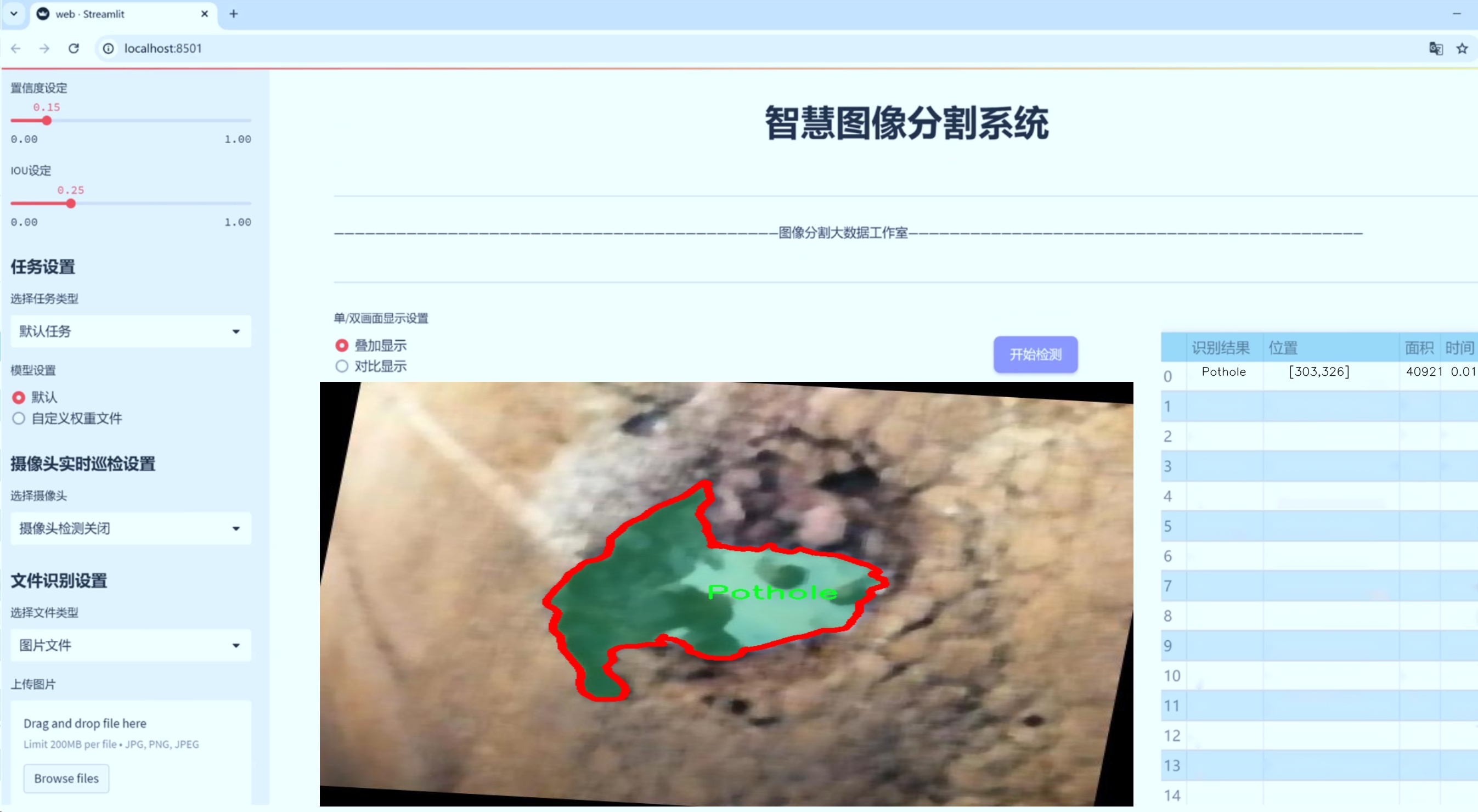
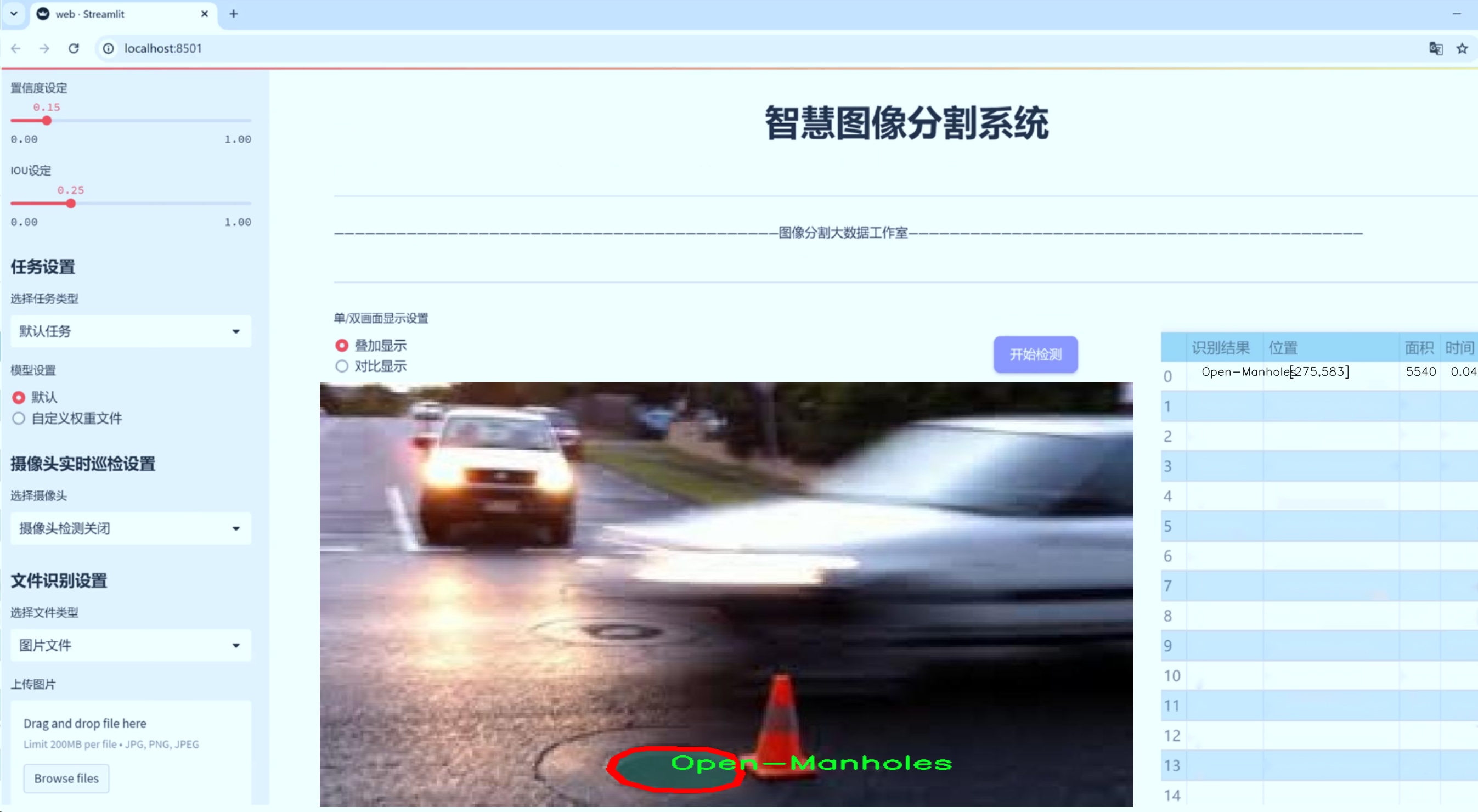
数据集信息
在现代智能交通系统的研究与应用中,障碍物检测与分割技术显得尤为重要。为了提升YOLOv8-seg在道路障碍物分割任务中的性能,我们构建了一个名为“testErr”的数据集,专门用于训练和评估模型的准确性与鲁棒性。该数据集涵盖了五种主要的道路障碍物类别,分别是“Manhole”(井盖)、“Open-Manholes”(敞开的井盖)、“Pothole”(坑洼)、“Speed Bump”(减速带)和“Unmarked Bump”(未标记的隆起)。这些类别的选择不仅考虑了城市道路环境中常见的障碍物类型,还反映了在实际应用中可能遇到的各种情况。
“testErr”数据集的构建过程经过了精心设计,旨在确保数据的多样性和代表性。我们从不同城市和地区收集了大量的图像数据,涵盖了不同的天气条件、光照变化以及不同的道路状况。这种多样性使得模型在训练过程中能够学习到更为丰富的特征,从而在实际应用中具备更强的适应能力。例如,井盖和敞开的井盖在城市道路中经常出现,而坑洼和减速带则是影响车辆行驶安全的重要因素。未标记的隆起则代表了那些可能被忽视但同样会对驾驶造成影响的障碍物。因此,这五种类别的设置不仅具有现实意义,也为模型的训练提供了丰富的样本。
在数据集的标注过程中,我们采用了高精度的分割标注技术,确保每一张图像中的障碍物都得到了准确的标识。标注工作由经验丰富的人工标注团队完成,他们对每一类障碍物的特征有着深入的理解。这种细致的标注工作为YOLOv8-seg模型的训练提供了坚实的基础,使得模型能够在分割任务中实现更高的准确率和召回率。
此外,为了进一步提升模型的泛化能力,我们还对数据集进行了数据增强处理。这包括随机裁剪、旋转、缩放以及颜色变换等多种技术,以增加数据的多样性并减少模型对特定样本的过拟合。通过这些处理,数据集“testErr”不仅丰富了样本的多样性,也提高了模型在不同场景下的表现能力。
在评估阶段,我们将“testErr”数据集分为训练集、验证集和测试集,以确保模型在不同阶段的性能评估具有科学性和可靠性。通过对模型在这些数据集上的表现进行全面分析,我们能够更好地理解模型的优缺点,从而为后续的优化提供指导。
总之,“testErr”数据集的构建与应用,为改进YOLOv8-seg的道路障碍物分割系统提供了强有力的支持。通过对多样化障碍物的深入研究与准确标注,我们期望该数据集能够推动智能交通领域的进一步发展,提升道路安全与行车体验。




核心代码
```python
import random
import numpy as np
import cv2
class BaseTransform:
"""
基础图像变换类,提供图像处理的基本框架。
"""
def __init__(self) -> None:
"""初始化基础变换对象。"""
pass
def apply_image(self, labels):
"""应用图像变换到标签。"""
pass
def apply_instances(self, labels):
"""应用变换到标签中的对象实例。"""
pass
def apply_semantic(self, labels):
"""应用语义分割变换到图像。"""
pass
def __call__(self, labels):
"""应用所有标签变换到图像、实例和语义掩码。"""
self.apply_image(labels)
self.apply_instances(labels)
self.apply_semantic(labels)
class Compose:
"""
组合多个图像变换的类。
"""
def __init__(self, transforms):
"""初始化组合对象,接受变换列表。"""
self.transforms = transforms
def __call__(self, data):
"""依次应用变换到输入数据。"""
for t in self.transforms:
data = t(data)
return data
class RandomFlip:
"""
随机水平或垂直翻转图像的类。
"""
def __init__(self, p=0.5, direction='horizontal') -> None:
"""
初始化随机翻转类。
参数:
p (float): 翻转的概率,范围在0到1之间。
direction (str): 翻转方向,'horizontal'或'vertical'。
"""
assert direction in ['horizontal', 'vertical'], f'支持方向为`horizontal`或`vertical`,但得到了{direction}'
assert 0 <= p <= 1.0
self.p = p
self.direction = direction
def __call__(self, labels):
"""
应用随机翻转到图像并更新实例。
参数:
labels (dict): 包含图像和实例的字典。
"""
img = labels['img']
if self.direction == 'vertical' and random.random() < self.p:
img = np.flipud(img) # 垂直翻转
if self.direction == 'horizontal' and random.random() < self.p:
img = np.fliplr(img) # 水平翻转
labels['img'] = img
return labels
class RandomPerspective:
"""
随机透视变换类,执行旋转、平移、缩放和剪切等变换。
"""
def __init__(self, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0):
"""初始化随机透视变换对象。"""
self.degrees = degrees
self.translate = translate
self.scale = scale
self.shear = shear
self.perspective = perspective
def __call__(self, labels):
"""应用透视变换到图像和标签。"""
img = labels['img']
# 透视变换逻辑...
# 返回变换后的标签
labels['img'] = img # 更新标签中的图像
return labels
class LetterBox:
"""
用于图像检测和实例分割的图像调整和填充类。
"""
def __init__(self, new_shape=(640, 640)):
"""初始化LetterBox对象。"""
self.new_shape = new_shape
def __call__(self, labels):
"""调整图像大小并添加边框。"""
img = labels['img']
# 计算调整比例和填充...
# 返回更新后的标签
labels['img'] = img # 更新标签中的图像
return labels
def v8_transforms(dataset, imgsz, hyp):
"""将图像转换为适合YOLOv8训练的大小。"""
pre_transform = Compose([
RandomFlip(direction='horizontal', p=hyp.flipud),
RandomPerspective(degrees=hyp.degrees, translate=hyp.translate, scale=hyp.scale)
])
return Compose([
pre_transform,
LetterBox(new_shape=(imgsz, imgsz))
])
代码说明
- BaseTransform: 这是一个基础类,定义了图像变换的基本接口。
- Compose: 该类用于组合多个变换,可以依次应用多个图像处理操作。
- RandomFlip: 随机翻转图像的类,支持水平和垂直翻转。
- RandomPerspective: 实现随机透视变换的类,可以进行旋转、平移、缩放等操作。
- LetterBox: 用于调整图像大小并添加边框的类,常用于目标检测任务。
- v8_transforms: 定义了YOLOv8模型的图像预处理和增强步骤。
这些类和方法构成了图像处理的核心部分,适用于目标检测和图像增强任务。```
这个文件是Ultralytics YOLO项目中的数据增强模块,主要用于图像处理和数据增强,以提高模型的鲁棒性和准确性。文件中定义了多个类,每个类负责不同的图像变换和增强操作。
首先,BaseTransform类是一个基类,定义了一些基本的图像变换方法,包括应用于图像、实例和语义分割的变换。它的主要作用是提供一个统一的接口,方便后续的具体变换类进行扩展。
接下来,Compose类用于将多个变换组合在一起。它接受一个变换列表,并在调用时依次应用这些变换。这个类的设计使得可以灵活地添加或修改变换。
BaseMixTransform类是一个基类,专门用于实现混合增强(如MixUp和Mosaic)。它提供了一个基本的框架,子类可以在此基础上实现具体的混合增强方法。Mosaic类是其子类之一,负责将多个图像合成一个马赛克图像。该类支持4个或9个图像的组合,并提供了获取随机索引和应用混合变换的方法。
MixUp类也是BaseMixTransform的子类,主要用于实现MixUp增强。它通过对两张图像进行加权平均来生成新的图像,并更新相应的标签。
RandomPerspective类实现了随机透视变换和仿射变换,可以对图像及其对应的边界框、分割和关键点进行变换。它支持旋转、平移、缩放和剪切等操作,并可以根据指定的概率条件应用这些变换。
RandomHSV类负责对图像的HSV通道进行随机调整,包括色调、饱和度和亮度的变化。这种调整可以增加图像的多样性,帮助模型更好地适应不同的光照条件。
RandomFlip类用于随机翻转图像,支持水平和垂直翻转,并根据翻转的方向更新相应的实例(如边界框和关键点)。
LetterBox类用于调整图像大小并进行填充,以适应目标检测和实例分割的需求。它通过计算比例和填充尺寸来确保图像在保持纵横比的同时适应新的形状。
CopyPaste类实现了图像的复制粘贴增强,允许在图像中随机插入其他实例,以增加数据的多样性。
Albumentations类是一个可选的增强模块,使用Albumentations库提供的多种图像处理功能,如模糊、对比度调整等。
Format类用于格式化图像注释,以便在PyTorch的DataLoader中使用。它将图像、类标签和边界框标准化为统一的格式,方便后续的训练和评估。
最后,v8_transforms和classify_transforms函数提供了具体的变换组合,用于YOLOv8模型的训练和分类任务。它们将不同的变换组合在一起,形成一个完整的图像处理管道。
总的来说,这个文件通过定义多个类和函数,实现了丰富的图像增强功能,为YOLO模型的训练提供了强大的数据处理支持。
```python
import torch
import torch.nn.functional as F
from torch.autograd import Function
from torch.cuda.amp import custom_bwd, custom_fwd
class DCNv3Function(Function):
@staticmethod
@custom_fwd
def forward(ctx, input, offset, mask, kernel_h, kernel_w, stride_h, stride_w, pad_h, pad_w, dilation_h, dilation_w, group, group_channels, offset_scale, im2col_step, remove_center):
# 保存前向传播所需的参数到上下文中
ctx.kernel_h = kernel_h
ctx.kernel_w = kernel_w
ctx.stride_h = stride_h
ctx.stride_w = stride_w
ctx.pad_h = pad_h
ctx.pad_w = pad_w
ctx.dilation_h = dilation_h
ctx.dilation_w = dilation_w
ctx.group = group
ctx.group_channels = group_channels
ctx.offset_scale = offset_scale
ctx.im2col_step = im2col_step
ctx.remove_center = remove_center
# 调用DCNv3的前向函数
output = DCNv3.dcnv3_forward(input, offset, mask, kernel_h, kernel_w, stride_h, stride_w, pad_h, pad_w, dilation_h, dilation_w, group, group_channels, offset_scale, ctx.im2col_step)
# 保存输入以便在反向传播中使用
ctx.save_for_backward(input, offset, mask)
return output
@staticmethod
@custom_bwd
def backward(ctx, grad_output):
# 从上下文中获取保存的张量
input, offset, mask = ctx.saved_tensors
# 调用DCNv3的反向函数
grad_input, grad_offset, grad_mask = DCNv3.dcnv3_backward(input, offset, mask, ctx.kernel_h, ctx.kernel_w, ctx.stride_h, ctx.stride_w, ctx.pad_h, ctx.pad_w, ctx.dilation_h, ctx.dilation_w, ctx.group, ctx.group_channels, ctx.offset_scale, grad_output.contiguous(), ctx.im2col_step)
return grad_input, grad_offset, grad_mask, None, None, None, None, None, None, None, None, None, None, None, None, None
def dcnv3_core_pytorch(input, offset, mask, kernel_h, kernel_w, stride_h, stride_w, pad_h, pad_w, dilation_h, dilation_w, group, group_channels, offset_scale, remove_center):
# 对输入进行填充
input = F.pad(input, [0, 0, pad_h, pad_h, pad_w, pad_w])
N_, H_in, W_in, _ = input.shape
_, H_out, W_out, _ = offset.shape
# 计算参考点和采样网格
ref = _get_reference_points(input.shape, input.device, kernel_h, kernel_w, dilation_h, dilation_w, pad_h, pad_w, stride_h, stride_w)
grid = _generate_dilation_grids(input.shape, kernel_h, kernel_w, dilation_h, dilation_w, group, input.device)
# 计算采样位置
sampling_locations = (ref + grid * offset_scale).repeat(N_, 1, 1, 1, 1)
if remove_center:
sampling_locations = remove_center_sampling_locations(sampling_locations, kernel_w=kernel_w, kernel_h=kernel_h)
sampling_locations = sampling_locations.flatten(3, 4) + offset * offset_scale / torch.tensor([W_in, H_in]).reshape(1, 1, 1, 2).to(input.device)
# 使用grid_sample进行采样
sampling_input_ = F.grid_sample(input.view(N_, H_in * W_in, group * group_channels).transpose(1, 2).reshape(N_ * group, group_channels, H_in, W_in), sampling_locations, mode='bilinear', padding_mode='zeros', align_corners=False)
# 计算输出
mask = mask.view(N_, H_out * W_out, group, -1).transpose(1, 2).reshape(N_ * group, 1, H_out * W_out, -1)
output = (sampling_input_ * mask).sum(-1).view(N_, group * group_channels, H_out * W_out)
return output.transpose(1, 2).reshape(N_, H_out, W_out, -1).contiguous()
代码注释说明:
-
DCNv3Function类:这是一个自定义的PyTorch函数,包含前向和反向传播的实现。
forward方法:执行前向传播,保存必要的参数以供反向传播使用。backward方法:执行反向传播,计算输入、偏移和掩码的梯度。
-
dcnv3_core_pytorch函数:这是DCNv3的核心实现,负责执行实际的深度可变卷积操作。
- 首先对输入进行填充以适应卷积操作。
- 计算参考点和采样网格。
- 计算采样位置并使用
grid_sample函数进行采样。 - 最后计算输出并返回。
通过这些注释,可以更好地理解代码的结构和功能。```
这个程序文件 dcnv3_func.py 是实现了一个深度学习中的可微分卷积操作,具体是 DCNv3(Deformable Convolutional Networks v3)的功能。该文件主要依赖于 PyTorch 框架,并且使用了 CUDA 加速以提高计算效率。
首先,文件引入了一些必要的库,包括 PyTorch 的核心功能和一些用于自定义前向和反向传播的工具。DCNv3 是一种可变形卷积,它允许在卷积操作中引入空间变形,从而更好地适应输入特征图的形状和内容。
在 DCNv3Function 类中,定义了前向传播和反向传播的静态方法。前向传播方法 forward 接收多个参数,包括输入特征图、偏移量、掩码以及卷积核的各种参数(如大小、步幅、填充等)。在该方法中,首先将参数保存到上下文中,然后调用 DCNv3 的前向函数进行计算,最后返回输出特征图。
反向传播方法 backward 负责计算梯度。它使用保存的输入、偏移量和掩码,以及来自上游的梯度,调用 DCNv3 的反向函数计算输入、偏移量和掩码的梯度,并返回这些梯度。
此外,文件中还定义了一些辅助函数,例如 _get_reference_points 和 _generate_dilation_grids,用于生成参考点和膨胀网格,这些都是可变形卷积计算中重要的步骤。remove_center_sampling_locations 函数用于移除中心采样位置,确保卷积核的形状和采样位置的合理性。
dcnv3_core_pytorch 函数是 DCNv3 的核心实现,负责具体的卷积计算过程。它首先对输入进行填充,然后计算参考点和采样位置,最后通过 F.grid_sample 函数进行采样,并结合掩码生成最终的输出。
整体来看,这个文件实现了 DCNv3 的前向和反向传播逻辑,能够在深度学习模型中使用可变形卷积操作,从而提高模型对复杂形状和变形的适应能力。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 23
23 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)