【CVPR2025】| SCSegamba: 用于结构裂纹分割的轻量级结构感知视觉Mamba
一个轻量级结构感知视觉Mamba网络(SC-Segamba),利用裂纹像素的形态信息和纹理线索,以最小的计算成本生成高质量的像素级分割图。
《SCSegamba: Lightweight Structure-Aware Vision Mamba for Crack Segmentation in Structures》
文章针对的是不同场景下(如道路缺陷、金属内部缺陷等)结构裂缝的像素级分割的问题。当前的方法在有效地建模裂缝形态和纹理方面遇到了挑战,在低计算资源使用率下平衡分割质量也面临着挑战。为了解决这些问题,作者提出了一个轻量级结构感知视觉Mamba网络(SC-Segamba),利用裂纹像素的形态信息和纹理线索,以最小的计算成本生成高质量的像素级分割图。
主要涉及三个模块,分别是结构感知的视觉状态空间模块Structure Aware Visual State Space module (SAVSS)、一个轻量级的门控瓶颈卷积Gated Bottleneck Convolution (GBC) 和结构感知扫描策略Structure-Aware Scanning Strategy (SASS)。使用Multi-scale Feature Segmentation head (MFS)以相对较少的计算资源生成分割图。
GBC是对裂纹形态信息建模有效,SASS通过加强裂纹像素之间的语义信息的连续性来增强裂纹拓扑和纹理的感知。
🧸动机
第一个动机在各种不同的场景(沥青路面、金属、混凝土等)中实现像素级别的裂缝分割较复杂;
第二个动机是CNN有限的感受野限制了它们在整个图像中建立大范围不规则依赖关系的能力,从而导致不连续分割和弱背景噪声抑制;
第三个动机就是基于Transformer的序列长度的注意力计算的二次复杂度导致高分辨率图像的高内存使用和训练挑战,限制了在资源受限的边缘设备上的部署和实际应用;
第四个动机就是虽然有基于Transformer的网络可以通过稀疏或线性化注意力来减少计算需求,但会牺牲网络对不规则依赖和像素纹理进行建模的能力,就是难以平衡分割性能和计算效率;
第五个动机就是在低对比度图像中,裂纹区域的不规则扩展和多个分支,往往受到不相关区域和阴影的影响,这对现有的Mamba VSS(Visual State Space Model)块结构和扫描策略提出了挑战。
🏸方法
文章提出的SCSegamba网络结构包括用于提取裂缝形状和纹理的SAVSS和用于有效特征处理的MFS,在前者的初始阶段和后者的最后阶段整合了GBC。对于一个输入是RGB的图像,空间信息可以被分解为n个patches,形成序列,这个序列通过SAVSS块进行处理,将关键裂缝像素信息嵌入到多尺度特征图中。最后,在MFS中,所有信息都被合并到一个张量中,产生一个细化的分割输出,通道数就成1了。
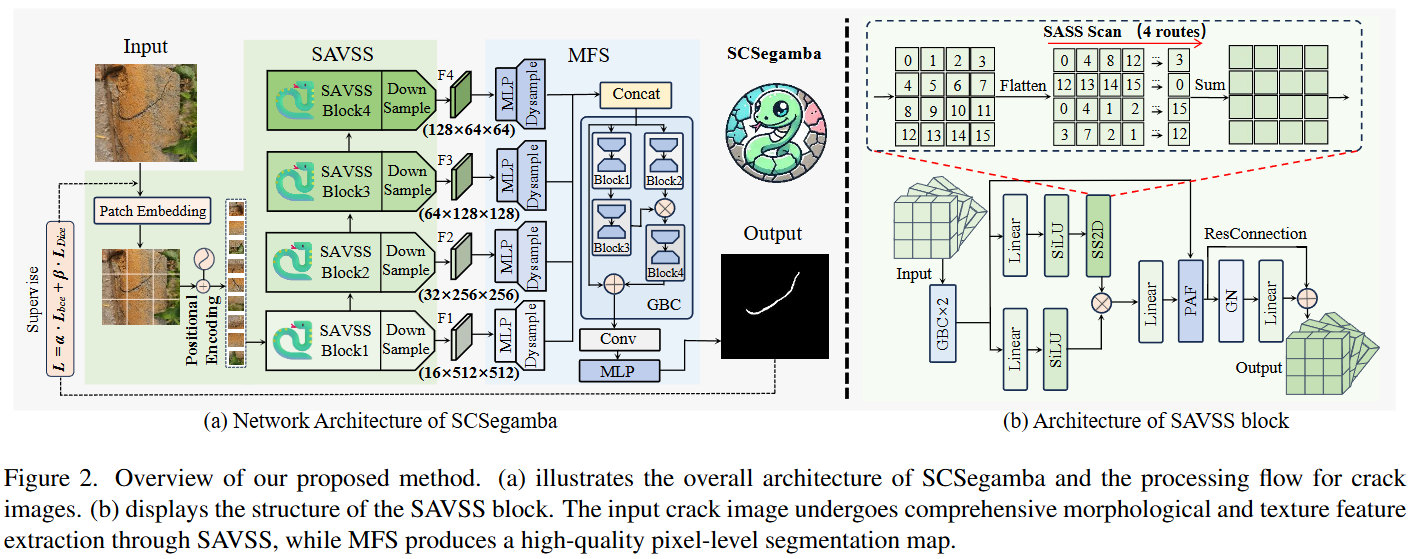
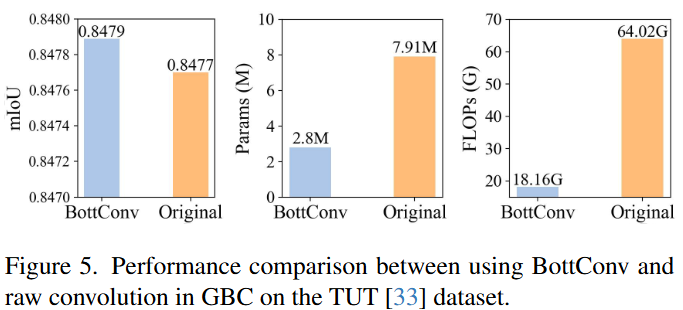
对于轻量化门控瓶颈卷积模块来说,为了进一步减少参数量和计算的消耗,文章嵌入了一个具有low-rank近似(CVPR 2024 Open Access Repository)的瓶颈卷积(BottConv),将矩阵从高维空间映射到低维空间,显著降低了计算复杂度。具体是这样实现的:
在卷积层,假设滤波器的空间大小为p,输入通道数为d,输入是s(通常是一个多维张量),卷积操作后产生的输出结果,也就是该层计算出的特征图可以使用以下公式表示:
Q是一个大小为的矩阵,f是一个输出的通道数,c是原始的偏置项。进一步假设z是位于秩
的低秩子空间(如果一个矩阵的秩远小于它的行数和列数,我们就称它为低秩矩阵。低秩 (Low-rank)就意味着矩阵中的行或列存在很强的相关性或冗余。数据可以用一个比原始维度低得多的内在维度来近似表示。低秩子空间指的是一个维度较低的子空间,并且数据(或矩阵)可以被很好地近似或表示在这个子空间中。更具体地说:它描述的是数据所实际占据或主要分布的那个低维空间。在这个子空间中,数据点可以用少量的基向量(Basis vectors)的线性组合来表示)中,可以表示为
,
可以抽象为特征的平均向量,作为辅助向量便于理论推导和校正特征偏移量。其中,
表示低秩投影矩阵,那么有
。
在GBC中为了便于残差连接,将输入特征保留为
。随后,特征
经过BottConv层,再经过归一化和激活函数,得到特征
和
:
为了生成门控特征图,和
通过Hadamard product(哈达玛积就是逐元素相乘)结合起来:
然后进一步使用BottConv处理门控特征图,细化细粒度的细节。最后应用残差连接,得到结果:
BottConv和更深门控分支的设计使模型在保留基本裂缝特征的同时,动态细化主分支的细粒度特征表征,从而在详细区域得到更精确的分割图。
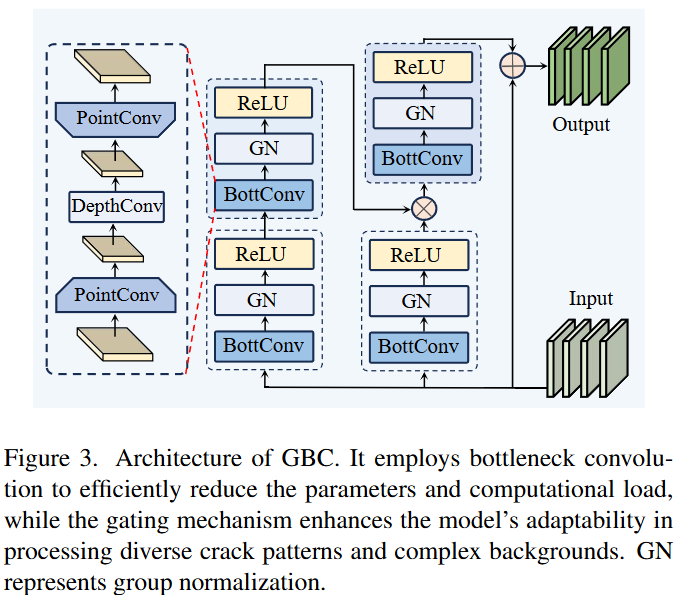
在BottConv中,逐点卷积将特征投影到低秩子空间中或从低秩子空间中取出,从而大大降低了复杂度,而深度卷积在子空间中进行空间信息充分提取,保证了可以忽略的低复杂度。与原始卷积相比,GBC设计中的BottConv显著减少了参数计数和计算负载,对性能的影响最小。
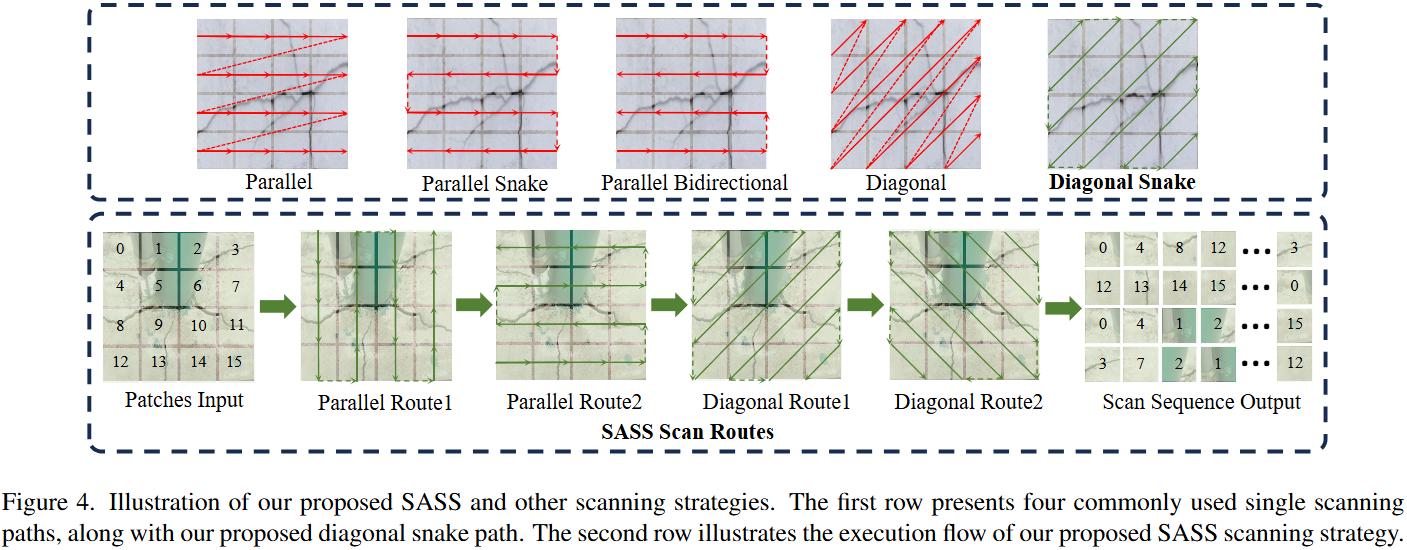
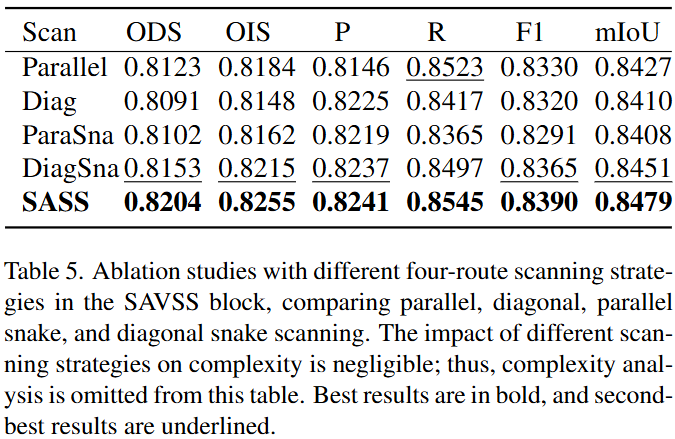
文章所提出的SAVSS具有专为视觉任务定制的二维选择性扫描。不同的扫描策略会影响模型捕捉连续裂缝纹理的能力。目前的视觉Mamba网络使用不同的扫描方向,其中平行和对角线扫描在行或对角线之间缺乏连续性,这限制了它们对裂纹方向的敏感性。虽然双向扫描和蛇形扫描在水平或垂直路径上保持语义连续性,但它们很难捕捉对角线或交织的纹理。为了解决这个问题,文章提出的对角线蛇形扫描旨在更好地捕捉复杂的裂缝纹理线索。
SASS由四条路径组成:两条平行的蛇形路径和两条对角的蛇形路径。该设计既能有效提取规则裂缝区域连续的语义信息,又能保持纹理在多个方向上的连续性,适用于背景复杂的多场景裂缝图像。一个RGB的裂缝图像输入会经过Patch Embedding和Position Encoding后,以序列的形式输入到SAVSS块中。文章中使用了4层该块,以使网络轻量化,处理过程如下:
输入的,
是控制隐藏的空间状态,
用于初始化输入的跳跃连接,
表示时间步长为k的特定隐藏状态,
和
分别是通过选择性扫描SS2D获得的具有隐藏空间维数G和时间维数D的矩阵。
表示时间步长k的输出。SASS建立了多向邻接关系,允许隐藏状态
捕获更复杂的拓扑和纹理细节
为了有效地将初始序列x与通过SS2D处理的序列结合起来,文章引入了像素注意力导向融合(Pixel Attention-oriented Fusion, PAF),增强了SAVSS捕获裂纹形状和纹理细节的能力。在选择性扫描后,对融合信息进行残差连接,以保留细节并促进特征流。此外,GBC对SAVSS内部的层间输出进行了细化,加强了裂缝信息提取,提高了后期的性能。
MLP可以快速学习特征和标签之间的映射关系,从而降低了模型的复杂性。当四个经过SAVSS处理的四个特征图输入到MFS中,通过高效的MLP运算和动态上采样进行单独处理,将分辨率恢复到原始大小,有以下公式:
表示层的序号。
为了整合所有多尺度裂纹形状和纹理表示,将这些特征映射聚合到一个张量中,得到高质量的裂缝分割图:
文章使用二进制交叉熵损失函数(BCE)和Dice loss作为目标函数,总体损失函数表示:
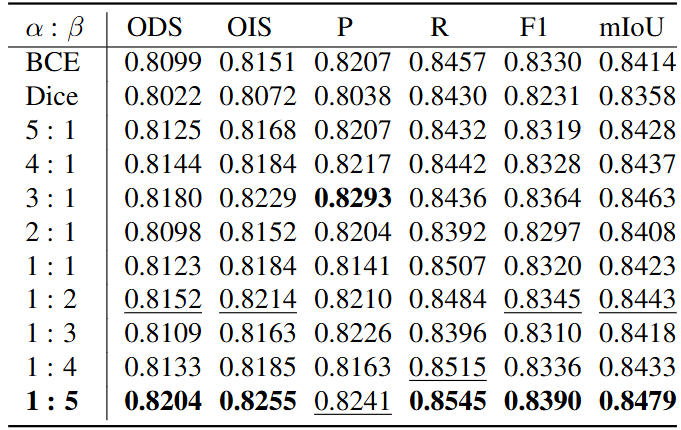
和
的比率设置为了1:5。
🏓实验
文章使用了四套数据集,Crack500文章对此做了数据增强扩展到了3368张;DeepCrack包含537张不同条件下的水泥、砖和沥青裂缝的RGB图像,包括细裂缝、宽裂缝、染色裂缝和模糊裂缝,确保了多样性和代表性;CrackMap和包含8种场景中的1408张图像的TUT。所有数据集按7:1:2的比例分为训练集、验证集和测试集。
SCSegamba网络使用PyTorch v1.13.1,在Intel Xeon Platinum8336C CPU和8块Nvidia RTX 4090 GPUs上训练的,优化器使用了AdamW,初始学习率设定为了5e-4,PolyLR调度,权重衰减为0.01,随机种子为42。对网络进行50次epoch的训练,选取验证性能最好的模型进行测试。
评价指标处了常规的P、R、F1分数和mIoU外,还有Optimal Dataset Scale (ODS)和Optimal Image Scale (OIS),ODS以固定阈值m衡量模型对不同尺度数据集的适应性,OIS以最优阈值n衡量模型跨图像尺度的适应性。
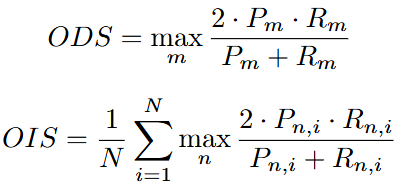
mIoU用于测量真实值与预测结果相交/并的平均比例。计算公式为:
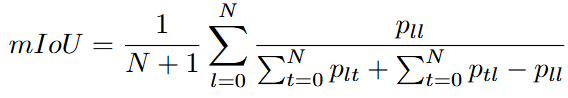
是类别的数量,设为
;
是GT;
是预测值;
是分类为
但属于
的像素数。
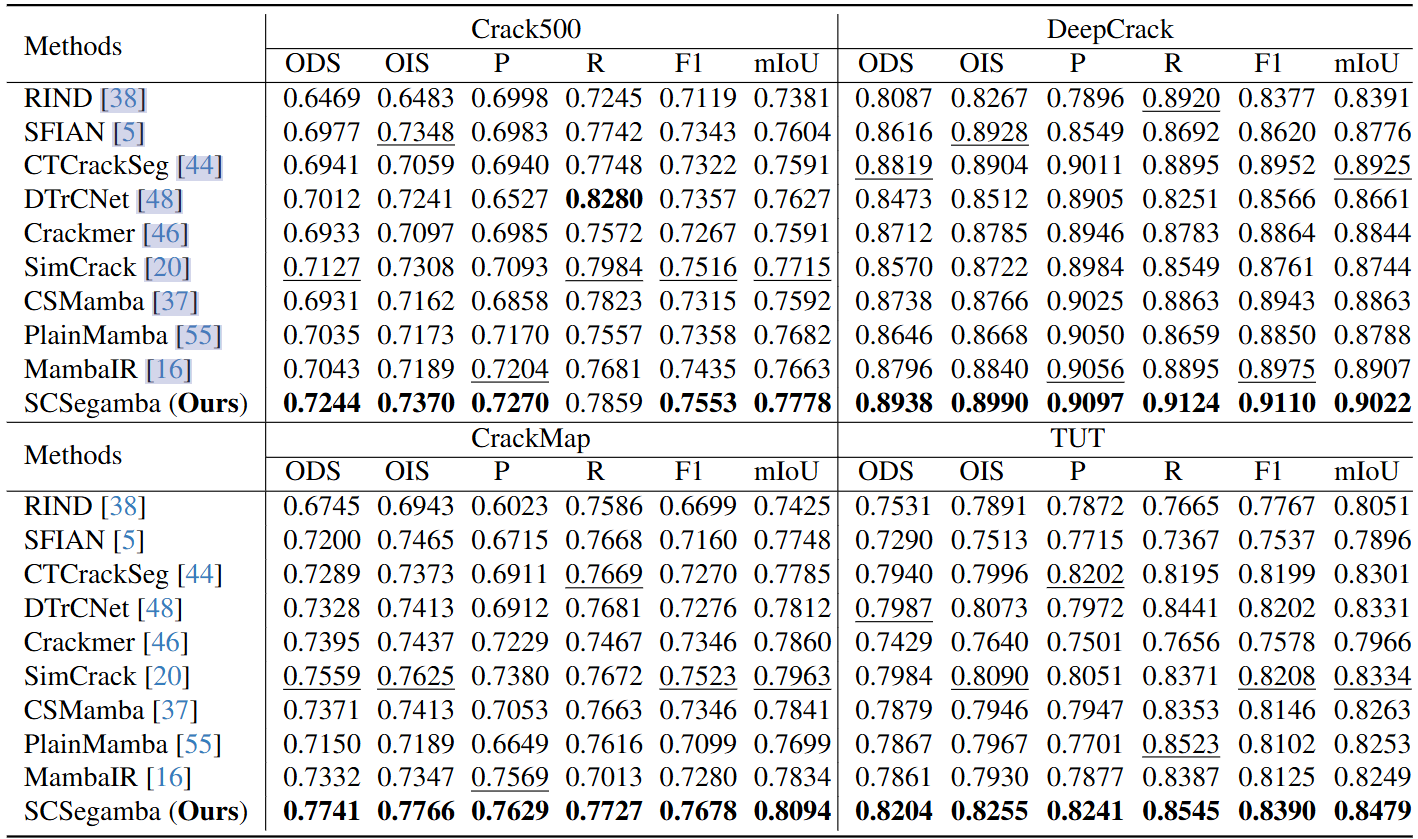
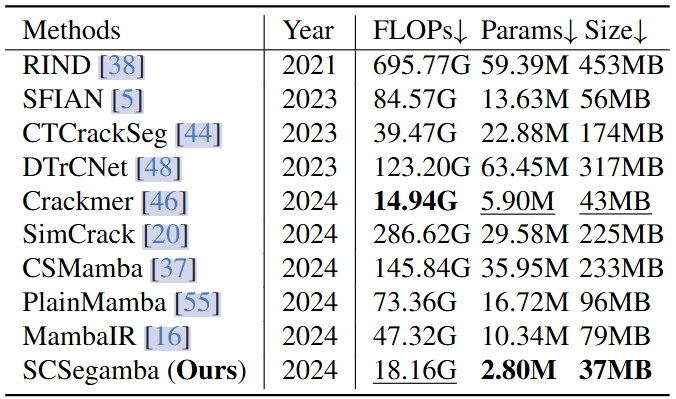


从上述的定量和定性的结果来看,SCSegamba取得了很不错的效果。GBC和SAVSS里面的特征的流向和残差连接对裂缝检测起到了至关重要的作用。
在具有代表性的多场景数据集TUT上进行了消融实验。
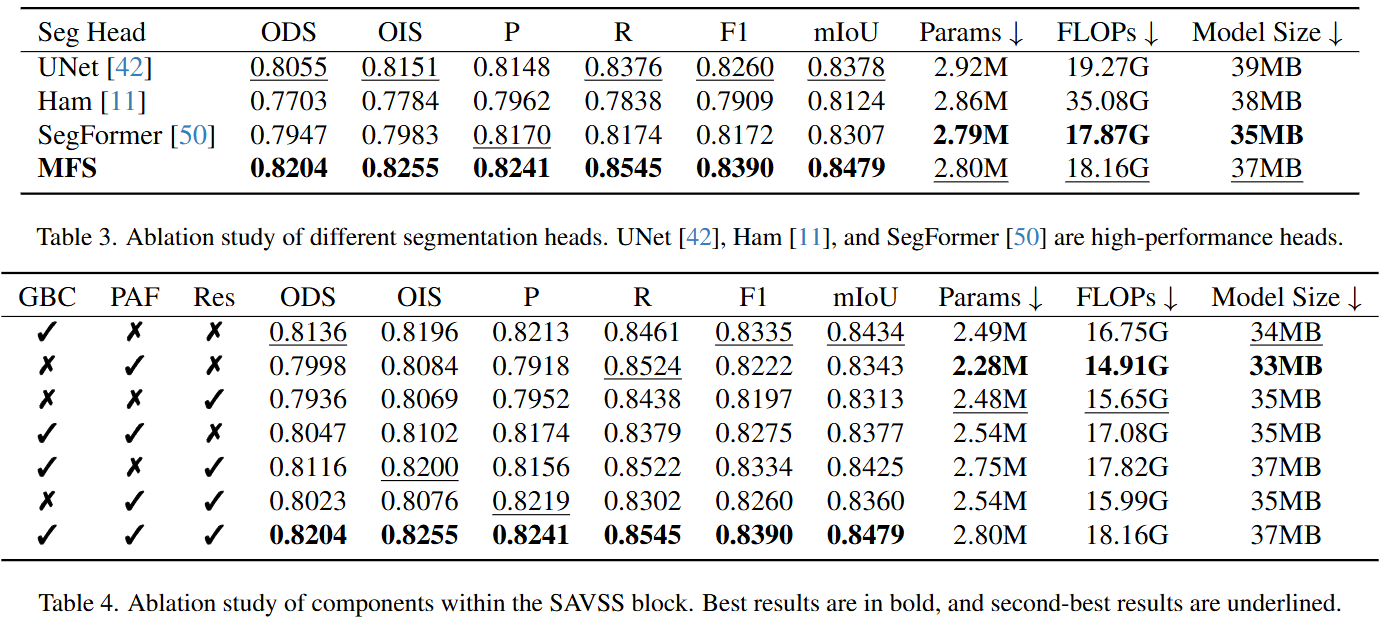
SCSegamba结合了SAVSS和MFS,以低参数计数增强裂缝形状和纹理感知,SAVSS包含GBC和SASS扫描可以捕获各种结构中的不规则裂缝纹理,实验结果很不错的。如果裂缝的纹理非常弱,拓扑形态很难以捕捉的情况,SCSegamba不知道会不会表现得更好一些。
为了评估SASS中使用四种扫描路径的必要性,文章在TUT上进行了不同扫描策略下不同路径数的消融实验。实验结果表明:使用四条路径时所有策略的表现都明显好于使用两条路径,这可能是因为四条路径允许SAVSS捕获更精细的裂缝细节和拓扑线索。
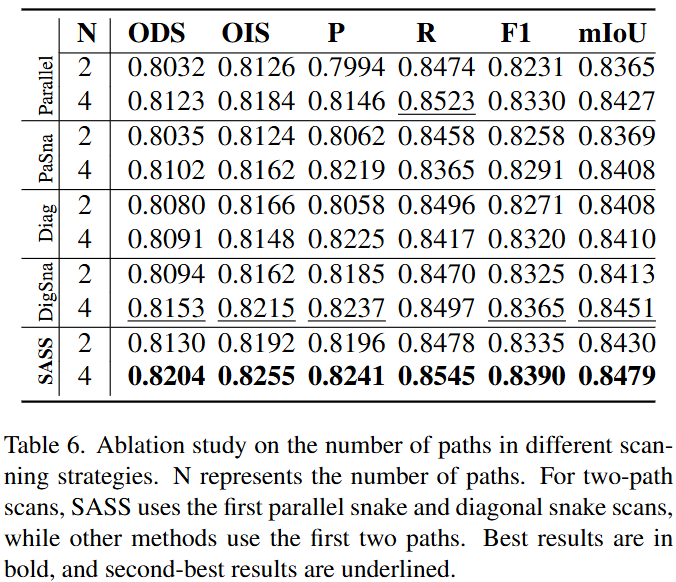
分析SAVSS的层数对模型性能和精度的影响。
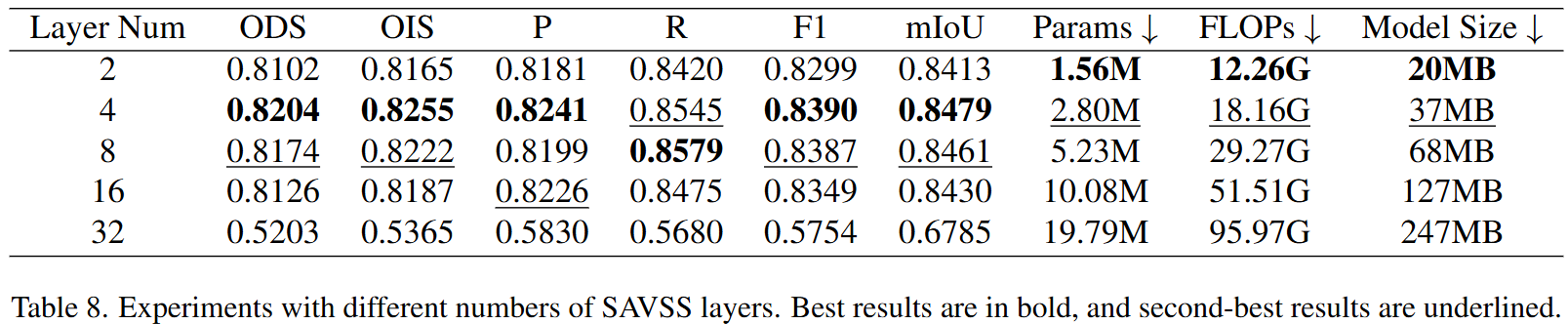
在SAVSS中,Patch Embedding期间,分析Patch Size需要设定多少能取得很好的效果和泛化性能。
SASS的算法和代码实现可以参考这篇文章,接下来我们再来看看总的损失函数权重的选取:
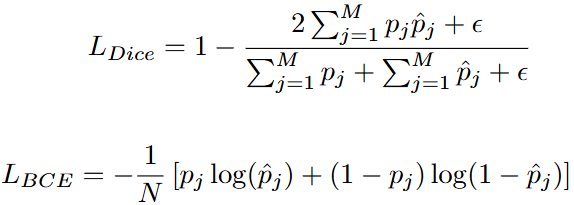
表示样本数量,
为第
个样本的真值标签,
为第
个样本的预测概率,
是一个小常数,是为了防止分母为零。实验结果:
🎉 部署应用
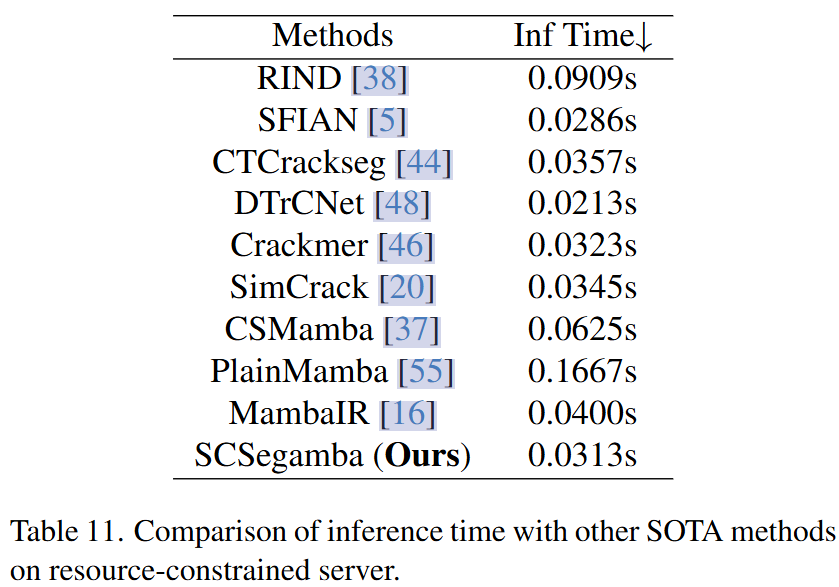
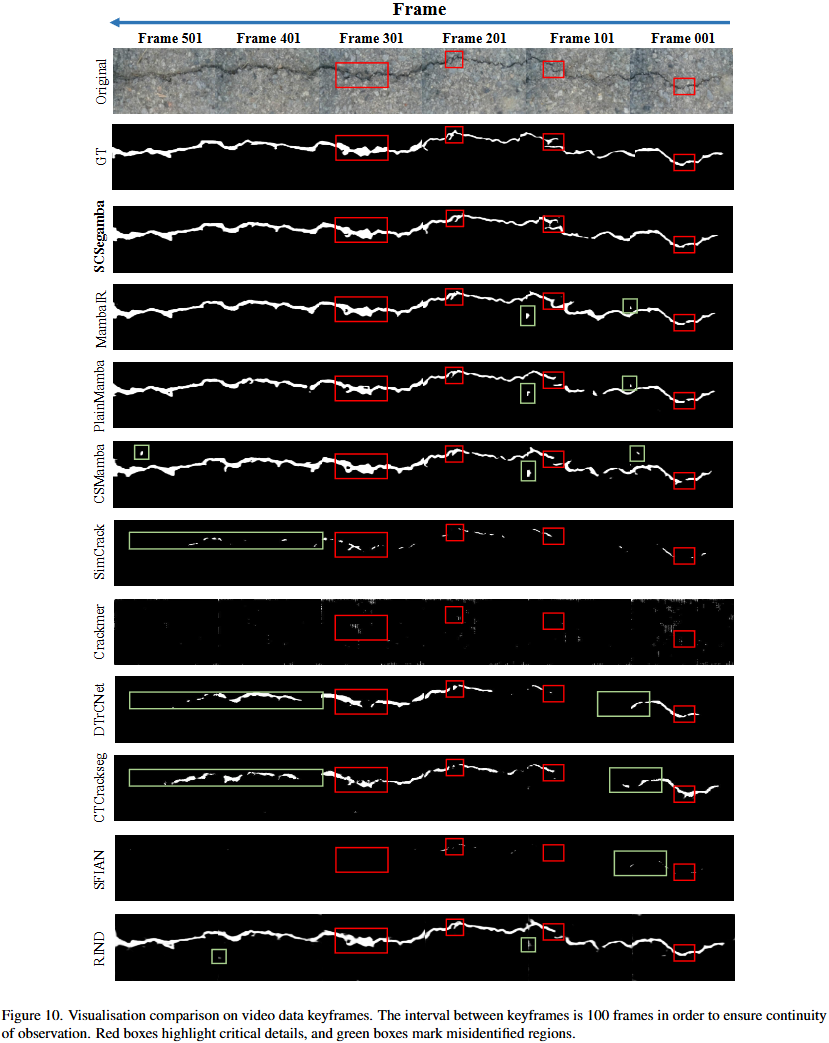
一个高精度且计算复杂度和参数量不高的模型是如何部署到实际应用中的呢?我们来看看这篇文章的做法。文章的部署环境的硬件有智能车和服务器,智能车是由树莓派4驱动的Turtlebot4 Lite,配备了激光雷达和摄像头。相机型号为OAK-D-Pro,配有能够捕捉高质量裂缝图像的OV9282的图像传感器;服务器是一台配备酷睿i9-13900 CPU的笔记本电脑,运行Ubuntu 22.04。

智能车以0.15m/s的速度直线前进,摄像机以每秒30帧的帧率拍摄视频,车辆通过网络将视频数据实时传输到服务器,分辨率是512*512。服务器接收到视频后,会先将每帧为图片保存下来,然后送入到预训练的SCSegamba模型中,该模型会在所有数据集(Crack500、CrackMap、DeepCrack、TUT)上进行训练然后在其他数据上做推理,将处理过后的每一帧再重新组合成视频,产生最终输出的形式。
这是与其他方法进行对比:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 23
23 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)