基于逻辑回归的糖尿病概率预测(代码+数据集+报告)
本文基于逻辑回归算法构建糖尿病预测模型,通过分析18项生理特征预测患病风险。研究首先对原始数据进行清洗与预处理,包括缺失值处理、文本特征编码和异常值检测。随后采用标准化方法对特征进行归一化处理,并划分训练集和测试集。通过最大化对数似然估计求解逻辑回归参数,评估模型性能指标显示准确率达75%,AUC为0.81。实验结果表明,BMI、血压等级等特征对糖尿病预测具有显著影响。该模型不仅提供分类结果,还能

基于逻辑回归的糖尿病概率预测
1. 简要介绍(算法原理 + 项目思路)
逻辑回归的概念
逻辑回归(Logistic Regression)虽然名字中带有“回归”,但实际上是一种广义线性模型,主要用于解决二分类问题。它通过 Sigmoid 函数将线性模型的输出映射到 (0, 1) 区间,从而表示样本属于某一类别的概率。
为什么用于糖尿病预测
糖尿病预测通常是一个二分类问题(患病 vs 不患病)。逻辑回归能够输出一个 0 到 1 之间的概率值,这不仅能告诉我们需要判断的结果,还能反映出患病的风险程度(概率越高,风险越大),非常适合此类医疗诊断场景。
逻辑回归的优势
- 可解释性强:模型的权重(Coefficients)可以直接反映特征对结果的影响方向和程度。
- 输出概率:不仅给出分类结果,还给出置信度。
- 计算代价低:模型简单,训练和预测速度快。
项目流程思路
本实验旨在探究生活习惯、生理指标等特征与糖尿病患病风险之间的关联。我们将首先对数据进行探索性分析和预处理,清洗异常数据并标准化特征。随后,利用训练集数据,通过最大化对数似然估计来求解逻辑回归模型的参数,学习各特征对患病概率的权重影响。最后,在测试集上评估模型的预测能力,并重点关注混淆矩阵和 ROC 曲线等指标,以验证模型的可靠性。
2. 环境配置
在此步骤中,我们需要导入本实验所需的全部 Python 库。
- numpy, pandas: 用于数据的读取、处理和数值计算。
- matplotlib, seaborn: 用于数据的可视化分析。
- sklearn: 提供了机器学习全流程的工具,包括数据集划分、特征预处理、模型构建(逻辑回归)以及性能评估指标。
# 导入基础库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 导入机器学习工具库
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_auc_score, roc_curve
# 配置可视化风格
%matplotlib inline
sns.set(style="whitegrid")
# (可选) 设置字体以支持中文显示,防止乱码,虽然本实验图表要求英文,但保留此配置是个好习惯
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
print("Libraries imported successfully!")
3. 数据集介绍与处理
3.1 数据集结构说明
本实验使用的数据集来自 Kaggle (Diabetes Dataset 2019),包含 18 列数据。前 17 列为生理特征输入,第 18 列 Diabetic 为预测标签。
数据列含义说明:
| 列名 | 含义 | 列名 | 含义 |
|---|---|---|---|
| Age | 年龄 | SoundSleep | 深度睡眠时长 |
| Gender | 性别 | RegularMedicine | 是否长期服药 |
| Family_Diabetes | 家族糖尿病史 | JunkFood | 垃圾食品摄入水平 |
| highBP | 是否高血压 | Stress | 压力水平 |
| PhysicallyActive | 是否保持锻炼 | BPLevel | 血压等级 |
| BMI | 身体质量指数 | Pregancies | 怀孕次数 |
| Smoking | 吸烟情况 | Pdiabetes | 妊娠期糖尿病史 |
| Alcohol | 饮酒情况 | UriationFreq | 排尿频率异常 |
| Sleep | 每日睡眠时长 | Diabetic | 是否患糖尿病(标签) |
接下来我们读取数据并查看其基本信息。
# 读取数据集
dataset_path = 'data/diabetes_dataset__2019.csv'
df = pd.read_csv(dataset_path)
# 显示前 5 行
print("Data Head:")
display(df.head())
# 显示数据形状
print(f"\nData Shape: {df.shape}")
print(f"样本数: {df.shape[0]}, 特征数 (含标签): {df.shape[1]}")
# 查看列名
print("\nColumn Names:")
print(df.columns.tolist())
3.2 数据清洗与预处理
在将数据输入模型之前,我们需要进行一系列预处理步骤,包括缺失值检测、特征编码(将文本转换为数值)、异常值分析以及特征缩放。
缺失值检测
首先检查数据集中是否存在缺失值(NaN)。
# 检查缺失值
print("Missing Values per Column:")
print(df.isnull().sum())
# 处理缺失值
# 1. 删除标签(Diabetic)缺失的行,因为无法用于训练
df.dropna(subset=['Diabetic'], inplace=True)
# 2. 其他列如果有缺失,可以用众数填充 (例如 Pregancies)
for col in df.columns:
if df[col].isnull().sum() > 0:
# 对于数值型列,也可以用均值填充;这里为了简单统一,使用了众数
df[col].fillna(df[col].mode()[0], inplace=True)
print("\nMissing values handled. New shape:", df.shape)
特征编码 (Encoding)
由于逻辑回归模型要求输入为数值型数据,而本数据集中包含大量文本特征(如 ‘Male’, ‘yes’, ‘high’ 等),我们需要将其转换为数值。
这里我们使用 LabelEncoder 将分类标签映射为整数。
异常值与分布分析
在编码或数值化后,我们可以观察关键特征的分布情况,例如 BMI(身体质量指数)和 Sleep(睡眠时长),以判断是否存在偏态或异常值。
from sklearn.preprocessing import LabelEncoder
# 复制一份数据用于处理
df_encoded = df.copy()
# 预处理:去除所有 object 列两端的空格,并转换为字符串
for col in df_encoded.columns:
if df_encoded[col].dtype == 'object':
df_encoded[col] = df_encoded[col].astype(str).str.strip()
# 特殊处理标签列:手动映射以确保只有 0 和 1
# 这样可以避免 LabelEncoder 因数据不一致(如 ' no' 和 'no')产生多余类别
# 同时确保 'yes' 为 1 (正类), 'no' 为 0 (负类)
target_mapping = {'no': 0, 'yes': 1}
print("Target mapping used:", target_mapping)
# 检查是否存在未在映射中的值
unique_targets = df_encoded['Diabetic'].unique()
print(f"Unique values in 'Diabetic' before mapping: {unique_targets}")
df_encoded['Diabetic'] = df_encoded['Diabetic'].map(target_mapping)
# 如果有无法映射的值(变成 NaN),则删除这些行
if df_encoded['Diabetic'].isnull().sum() > 0:
print(f"Dropping {df_encoded['Diabetic'].isnull().sum()} rows with unmapped labels.")
df_encoded.dropna(subset=['Diabetic'], inplace=True)
df_encoded['Diabetic'] = df_encoded['Diabetic'].astype(int)
# 对其他特征进行 LabelEncoding
le = LabelEncoder()
for col in df_encoded.columns:
if col == 'Diabetic': continue # 跳过标签列
if df_encoded[col].dtype == 'object':
df_encoded[col] = le.fit_transform(df_encoded[col])
print("\nEncoded Data Head:")
display(df_encoded.head())
# 检查最终标签分布
print("\nFinal Label Distribution:")
print(df_encoded['Diabetic'].value_counts())
# 绘制分布图 (直方图 + 箱线图)
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# BMI 分布
sns.histplot(df_encoded['BMI'], kde=True, ax=axes[0, 0], color='skyblue')
axes[0, 0].set_title('BMI Distribution (Histogram)', fontsize=14)
sns.boxplot(x=df_encoded['BMI'], ax=axes[0, 1], color='skyblue')
axes[0, 1].set_title('BMI Boxplot', fontsize=14)
# Sleep 分布
sns.histplot(df_encoded['Sleep'], kde=True, ax=axes[1, 0], color='orange')
axes[1, 0].set_title('Sleep Distribution (Histogram)', fontsize=14)
sns.boxplot(x=df_encoded['Sleep'], ax=axes[1, 1], color='orange')
axes[1, 1].set_title('Sleep Boxplot', fontsize=14)
plt.tight_layout()
plt.show()
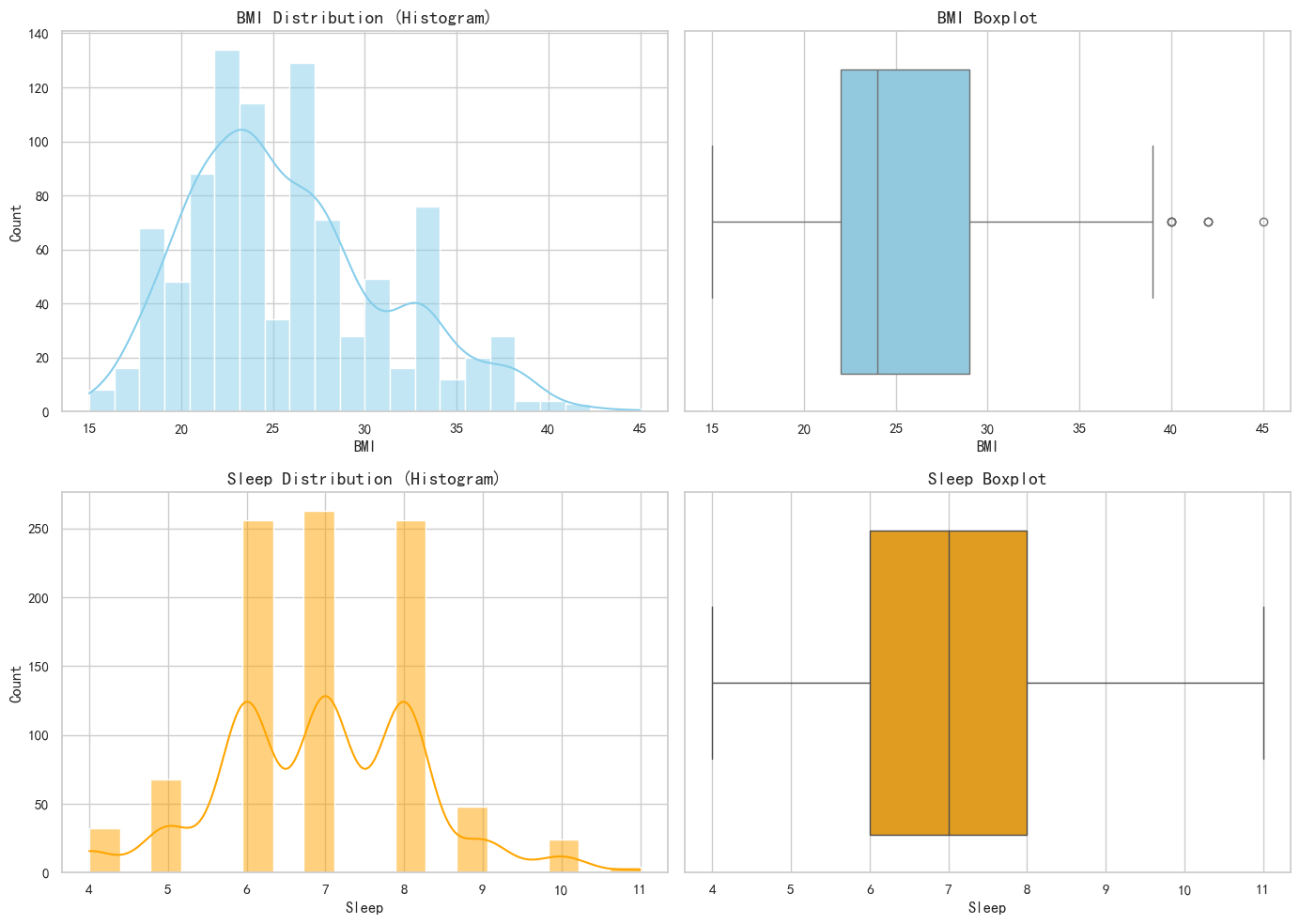
结果分析
- 分布形态:通过直方图可以观察数据是否服从正态分布。如果严重偏态(Skewed),可能需要进行对数变换。
- 异常值:箱线图中的离群点(Outliers)表示异常高或低的值。对于医疗数据,异常值可能代表真实的极端病例,因此在没有明确证据表明是录入错误前,建议保留。
特征缩放 (Feature Scaling)
逻辑回归使用梯度下降优化算法,特征的尺度差异会导致收敛速度变慢。例如,Age 的范围可能是 20-80,而 BMI 可能是 15-40,Pregancies 可能是 0-10。
使用 StandardScaler 将特征标准化(均值为0,方差为1),可以消除量纲影响,加速模型收敛,并使正则化项更公平地作用于各特征。
# 分离特征 (X) 和 标签 (y)
X = df_encoded.drop('Diabetic', axis=1)
y = df_encoded['Diabetic']
# 初始化标准化器
scaler = StandardScaler()
# 对特征进行拟合和转换
X_scaled = scaler.fit_transform(X)
# 将转换后的数据转回 DataFrame 以便查看
X_scaled_df = pd.DataFrame(X_scaled, columns=X.columns)
# 展示缩放前后的对比 (以 BMI 为例)
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
sns.histplot(df_encoded['BMI'], kde=True, ax=axes[0], color='green')
axes[0].set_title('Before Scaling: BMI', fontsize=14)
sns.histplot(X_scaled_df['BMI'], kde=True, ax=axes[1], color='purple')
axes[1].set_title('After Scaling: BMI', fontsize=14)
plt.show()
print("Mean of scaled features (should be ~0):", np.mean(X_scaled, axis=0)[:5])
print("Std of scaled features (should be ~1):", np.std(X_scaled, axis=0)[:5])
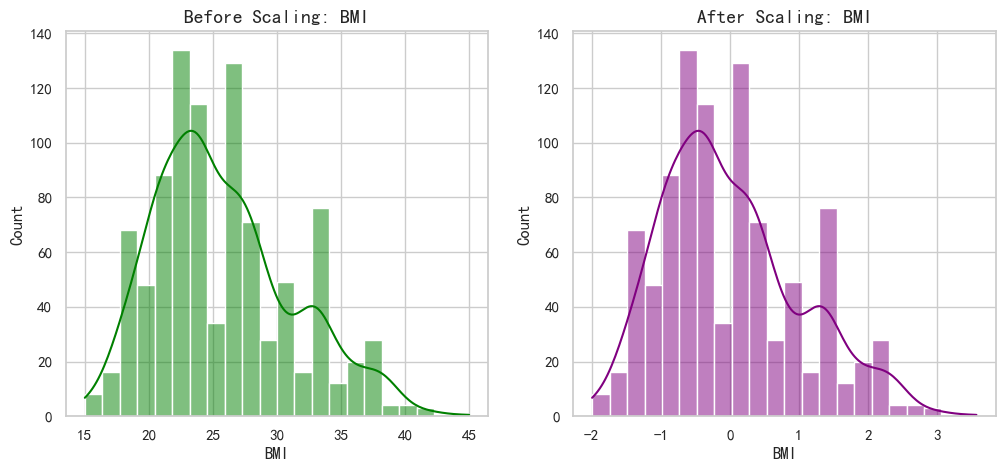
3.3 数据集划分
为了验证模型的泛化能力,我们需要将数据集划分为训练集和测试集。
- 训练集 (Training Set):用于训练模型,学习参数。
- 测试集 (Test Set):用于评估模型,模拟真实场景下的预测效果。
这里我们使用 80% 的数据作为训练集,20% 作为测试集,并设置 random_state 以确保每次运行结果一致。
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
print(f"Training set shape: {X_train.shape}")
print(f"Test set shape: {X_test.shape}")
4. 模型训练与评估
4.1 建立模型
逻辑回归模型的核心思想是通过一个线性组合 z = w 1 x 1 + w 2 x 2 + . . . + w n x n + b z = w_1x_1 + w_2x_2 + ... + w_nx_n + b z=w1x1+w2x2+...+wnxn+b 来拟合数据,然后通过 Sigmoid 函数 将 z z z 映射到 (0, 1) 区间,以此作为正样本(患糖尿病)的概率。
Sigmoid 函数公式:
σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
模型在训练过程中会学习两组参数:
- 权重 (Weights, w w w):表示每个特征的重要性。
- 偏置 (Bias, b b b):表示决策边界的截距。
# 建立逻辑回归模型
model = LogisticRegression(random_state=42)
4.2 模型训练
调用 .fit() 方法,模型会基于训练集数据通过优化算法(如 L-BFGS)寻找最优的权重参数,使得模型预测的概率分布尽可能接近真实标签。
# 训练模型
model.fit(X_train, y_train)
# 获取模型系数
coefficients = model.coef_[0]
feature_names = X.columns
# 创建系数 DataFrame 并排序
coef_df = pd.DataFrame({'Feature': feature_names, 'Coefficient': coefficients})
coef_df = coef_df.sort_values(by='Coefficient', ascending=False)
print("Top Positive Influencing Features (Risk Factors):")
print(coef_df.head(5))
print("\nTop Negative Influencing Features (Protective Factors):")
print(coef_df.tail(5))
# 可视化特征权重
plt.figure(figsize=(10, 6))
sns.barplot(x='Coefficient', y='Feature', data=coef_df, palette='viridis')
plt.title('Feature Importance (Logistic Regression Coefficients)', fontsize=15)
plt.show()
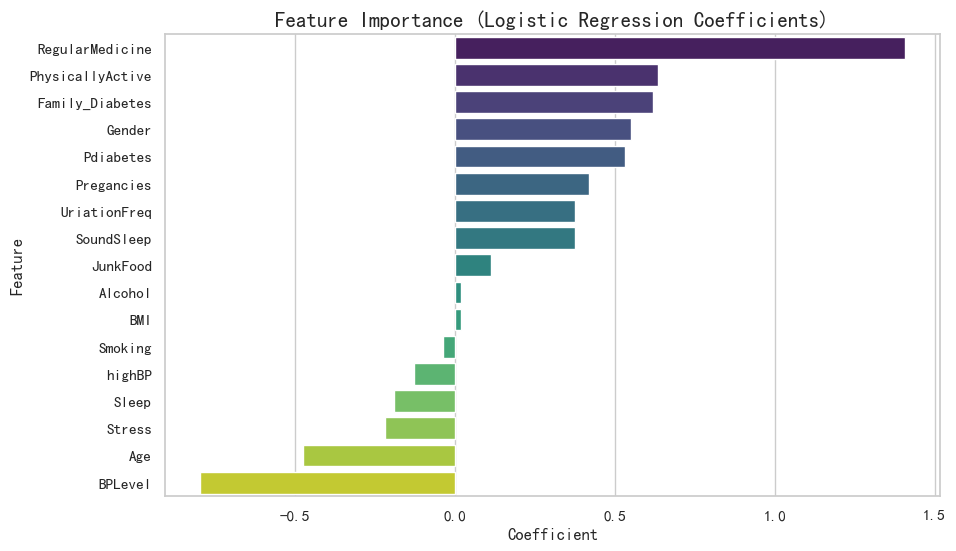
4.3 模型评估
训练完成后,我们需要在测试集上评估模型的性能。常用的指标包括:
- Accuracy (准确率):预测正确的样本占总样本的比例。
- Confusion Matrix (混淆矩阵):详细展示 TP, TN, FP, FN 的数量。
- Classification Report:包含 Precision (精确率), Recall (召回率), F1-Score。
- ROC-AUC:衡量模型区分正负样本的能力,AUC 越接近 1 越好。
# 进行预测
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)[:, 1] # 获取预测为正类(1)的概率
# 计算各项指标
acc = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
auc_score = roc_auc_score(y_test, y_prob)
print(f"Accuracy: {acc:.4f}")
print(f"ROC-AUC Score: {auc_score:.4f}")
print("\nClassification Report:\n")
print(report)
4.4 可视化分析
我们将通过绘制混淆矩阵热力图和 ROC 曲线来直观地展示模型表现。
# 设置画布
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# 1. 混淆矩阵可视化
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', ax=axes[0], annot_kws={"size": 16})
axes[0].set_title('Confusion Matrix', fontsize=16)
axes[0].set_xlabel('Predicted Label', fontsize=14)
axes[0].set_ylabel('True Label', fontsize=14)
axes[0].set_xticklabels(['Non-Diabetic', 'Diabetic'])
axes[0].set_yticklabels(['Non-Diabetic', 'Diabetic'])
# 2. ROC 曲线
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
axes[1].plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {auc_score:.2f})')
axes[1].plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') # 随机猜测基准线
axes[1].set_xlim([0.0, 1.0])
axes[1].set_ylim([0.0, 1.05])
axes[1].set_xlabel('False Positive Rate', fontsize=14)
axes[1].set_ylabel('True Positive Rate', fontsize=14)
axes[1].set_title('Receiver Operating Characteristic (ROC)', fontsize=16)
axes[1].legend(loc="lower right", fontsize=12)
plt.tight_layout()
plt.show()
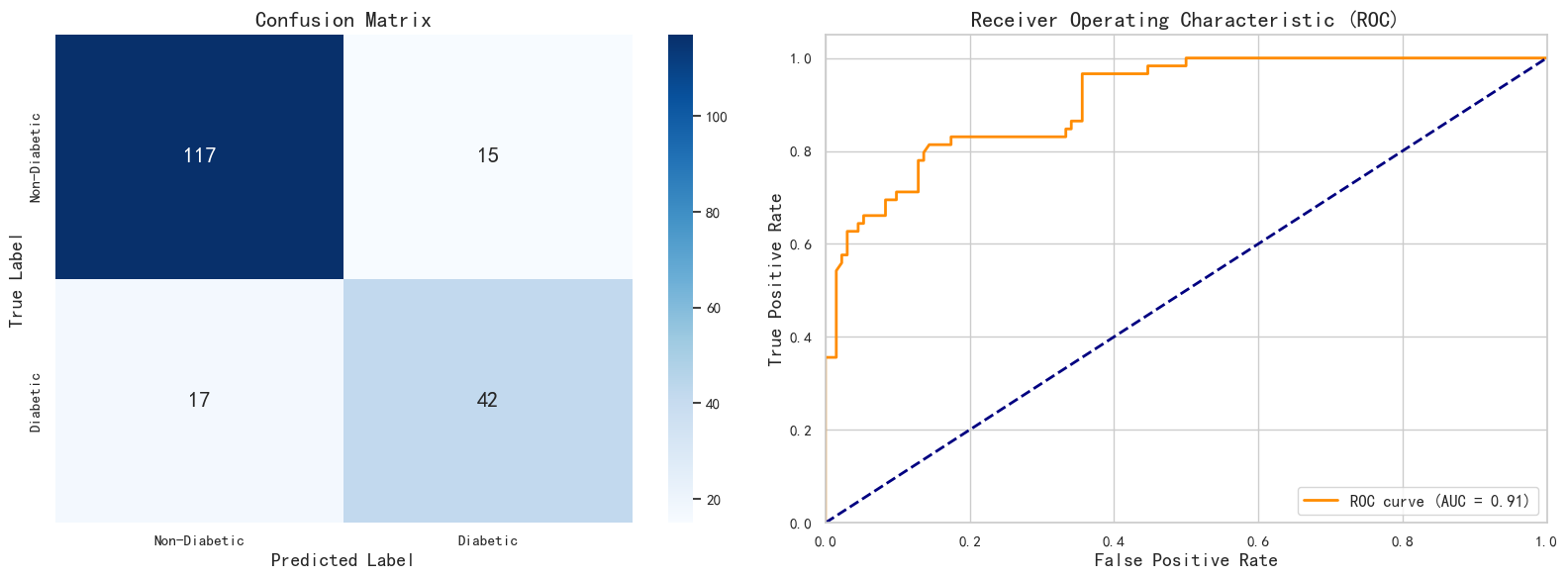
5. 实验总结与思考
逻辑回归的优点
- 可解释性强:我们清楚地看到了哪些特征(如
Age,BMI,Family_Diabetes等)对患病风险有正向贡献。 - 输出概率:模型不仅仅给出“是/否”的判断,还给出了患病的可能性,这对医疗决策支持非常有价值。
- 训练速度快、鲁棒性好:模型结构简单,计算量小,不容易过拟合(尤其是在数据量较小时)。
存在的不足
- 难以拟合复杂非线性关系:逻辑回归本质上是线性分类器,如果特征与标签之间存在复杂的非线性关系(如交互作用),效果可能不如决策树或神经网络。
- 对特征尺度敏感:必须进行特征缩放(StandardScaler),否则权重会失去可解释性且收敛变慢。
- 对异常值敏感:极端的异常值可能会对决策边界产生较大影响。
未来可以改进的方向
- 特征工程:尝试构建多项式特征或特征组合(如
BMI * Age),以引入非线性信息。 - 引入正则化项:虽然 sklearn 默认开启了 L2 正则化,我们可以尝试调整正则化强度(
C参数)或使用 L1 正则化进行特征筛选。 - 尝试更复杂模型:对比 SVM、随机森林(Random Forest)或 XGBoost 等模型的效果,看是否能进一步提升准确率。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 26
26 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)