统计小白|一文搞懂二元Logistic回归分析全流程
4 个哑变量的偏回归系数均为负数,说明其与“曾经违约”存在负相关关系,相对应的 OR 值均小于 1,OR 值 95% CI 不包括 1,说明变量对“是否违约”起抑制作用,“当前居住时长”“当前工作时长”越长(相对于参照项—最低水平哑变量时长越长)越不容易出现还贷违约的情况。如果边际效应值显著且小于0,则意味着X的增加会带来负向效应变化。是否为二分类、多分类、有序分类的其中一种,是则采用对应的二元L
二元Logistic回归是一种用于研究因变量为二分类变量的统计方法,广泛应用于医学、社会科学、金融等领域。它的主要目的是通过分析自变量(连续或分类变量)对二分类因变量的影响,预测事件发生的概率。本文将详细介绍二元Logistic回归分析的流程,包括在构建回归模型前的单因素筛查,SPSSAU软件操作以及Logistic回归分析结果解读。
一、Logistic回归
1、logistic回归类型
根据数据资料的情况,Logistic回归可分为成组资料的非条件Logistic回归与配伍资料的条件Logistic回归。其中,非条件Logistic回归根据因变量的分类水平个数,可分为二元Logistic回归、多分类Logistic回归和有序Logistic回归。
(1)二元Logistic回归:因变量为二分类变量,且结局是互斥的,如是与否、死亡与未死亡等。
(2)多分类Logistic回归:因变量是无序多分类变量,如某研究想了解不同性别、年龄等对于手机品牌偏好的不同,该因变量即为无序多分类变量,该问题适合采用多分类Logistic 回归进行分析。
(3)有序Logistic回归:因变量为有序分类变量(等级数据),如医学研究中关于某病的治疗效果,无效=1,有效=2,痊愈=3,如果要研究疗效的影响因素,则采用有序Logistic回归。
(4)条件Logistic回归:又称配对 Logistic 回归,其主要用于配对资料或分层资料的多因素分析,包括1:1和1:M配对资料的研究及分析。
2、Logistic回归适用条件
Logistic回归因变量须是二分类、无序多分类、有序分类变量,自变量可以是定量数据也可以是定类数据,多水平的分类自变量应考虑先转换为哑变量。主要包括以下适用条件:
(1) 定量数据的自变量与因变量的Logit转换值之间存在线性关系,这是由Logistic回归原理决定的,一般情况下该条件是满足的;
(2) 自变量之间无多重共线性,和线性回归类似,在考察多个自变量的影响时,如果存在共线性问题会影响Logistic回归的拟合结果;
(3) 样本量的经验要求,结局中比例较低的分组样本量应是自变量个数的10~20倍以上,比如结局阳性与阴性,普遍来说阳性人群比例较低,100个阳性样本最多只能支持10个自变量,或者说研究者需要考察8个自变量那么要求阳性样本至少有80例。
3、Logistic回归一般步骤
线性回归一般采用最小二乘法进行参数估计,而Logistic回归采用的是最大似然估计法,虽然原理上有所不同,但是整体的分析思路是类似的。针对非条件Logistic回归其一般步骤如下图所示,适合二元logistic回归与多分类logistic回归。

(1) 基本条件判断
首先检查因变量是否为二分类、多分类、有序分类的其中一种,是则采用对应的二元Logistic回归、多分类Logistic回归、有序Logistic回归,如果因变量为定量数据则采用线性回归。
建议在回归开始前检查异常值情况,以及通过【线性回归】模块以结局变量为因变量,输出各自变量的VIF用来判断有无多重共线性的影响。如发现共线性、异常值等问题,考虑进行有针对性的处理措施,常见的比如剔除或替换个别异常值数据,下一步采取逐步回归等操作。
(2) 建立Logistic回归模型
建立Logistic回归模型的过程,最常见的是“先单后多”,即先通过单因素分析筛选自变量,然后仅保留有显著影响的自变量进行多因素回归。这种场景在探索性研究目的和样本量不足的情况下应用较多。
当研究目的为探索性影响因素分析时,研究者一般会从众多潜在因素中筛选探究哪些因素对因变量有影响。在此种场景下,常见的研究思路是先采用单因素分析筛选出现显著的自变量,然后再做多因素分析。单因素分析可以帮助研究者明确单个因素和因变量的关系,另外在样本量较小的情况下,也可以提前将一些影响作用较小的变量剔除,以简化多因素Logistic回归。
- 单因素分析常见的方法包括卡方检验、t检验、方差分析或秩和检验,差异的显著性水平可以由0.05适当放宽至0.1、0.15,甚至放宽到0.2,单因素分析显著的自变量保留下来继续做多因素Logistic回归。
- 有一点必须明确,多因素Logistic回归前进行单因素分析并不是绝对的,在样本量充足,研究目标明确,有足够专业理论支持的情况下,可以所有自变量一起进行多因素Logistic回归。
和线性回归类似,多因素Logistic回归时,也可以采用逐步回归的方式对变量进行筛选,比如向前逐步、向后逐步或逐步法,尤其是逐步法Logistic回归在科研中使用较多。
(3) Logistic回归模型的检验与评价
- 和线性回归模型检验类似,先对模型总体显著性进行检验。具体判断时,可以直接读取似然比卡方检验的概率p值,如果p值小于0.05则认为模型总体有统计学意义;反之如果p值大于0.05则说明模型无效。
- Logistic回归常用Hosmer-Lemeshow 检验(简称HL检验)进行拟合优度的评价,适用于含有定量自变量的模型拟合优度评价。原假设模型拟合值和观测值的吻合程度一致,如果p值大于0.05则说明通过HL检验,可认为模型拟合良好;反之p值小于0.05则说明模型没有通过HL检验,模型拟合优度一般或较差。
- 决定系数作为线性回归模型拟合优度的重要指标,其结果得到重视和应用。Logistic回归也提供,常见的包括McFadden 、Cox & Snell 、Nagelkerke ,它们被称之为伪,其含义和线性回归的决定系数类似,但是经验上在Logistic回归中较少使用。
此外模型预测准确率也可用作模型拟合优度的评价,没有严格的标准,具体由专业经验决定。
(4) 偏回归系数与OR值解释与分析
对Logistic回归方程中各自变量偏回归系数、OR值及其置信区间进行解读,分析哪些因素对研究结局有影响,哪些因素无影响,以及通过OR值对影响的程度进行分析。
(5) 结论报告
综合回归模型显著性检验、模型拟合评价,以及偏回归系数和OR值情况,总结呈现最终的分析结果和结论。
二、二元Logistic回归分析原理
逻辑回归中二元Logistic回归最为常用。二元Logistic回归分析适用于研究因变量为二分类变量的数据,二分类变量即为那些结局只有两种可能性的变量。
- 因变量Y:只能用数字0、1表示;若不是,需要进行数据编码。
- 自变量X:既可以是定量数据也可以是定类数据,定类数据要进行哑变量处理。
1、模型公式解读
二元Logistic回归模型公式如下: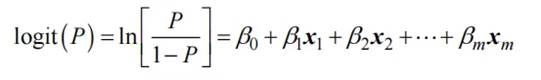
整个模型以最大似然法进行参数估计,以医学、流行病学为例,模型中有以下主要概念:
(1) P/1-P:称为比值或优势(Odds),ln(P/1-P)=logit(P)称为优势的对数,大量实践证明logit(P)与定量自变量呈线性关系。
(2)OR(Odds Ratio)值:又称比值比、优势比,主要指病例组中的比值P/1-P除以对照组中的比值P/1-P,是流行病学、医学研究中的一个常用指标。
(3) 偏回归系数 βj(j=1,2,…,m):表示在其他条件不变情况下,自变量每改变一个单位时logit(P)的改变量。回归系数如果是正数,表示自变量与因变量正相关;如果是负数则表示自变量与因变量负相关。
(4) 回归系数与OR值的关系:回归系数主要解读自变量的显著性以及对因变量影响的正负方向,OR值用于衡量自变量对因变量作用程度,OR值等于回归系数的自然对数值。例如自变量X的偏回归系数为0.6,则其OR=exp(0.6)==1.822。
2、逐步法筛选自变量
二元logistic回归分析可通过自动筛选对因变量有显著影响的自变量,解决多重共线性问题并优化模型简洁性。SPSSAU进行分析时,如果需要自动寻找显著的X,共提供3种方式,逐步法、向前法、向后法,一般情况下使用逐步法最多。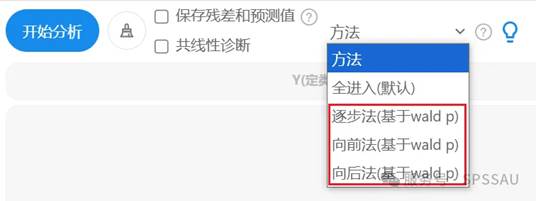
三、案例分析全流程
二元Logistic回归分析一般步骤如下:
案例背景:研究者收集了银行贷款客户的个人负债信息,以及曾经是否有过还贷违约记录,数据赋值说明如下表所示,试分析是否违约的相关因素。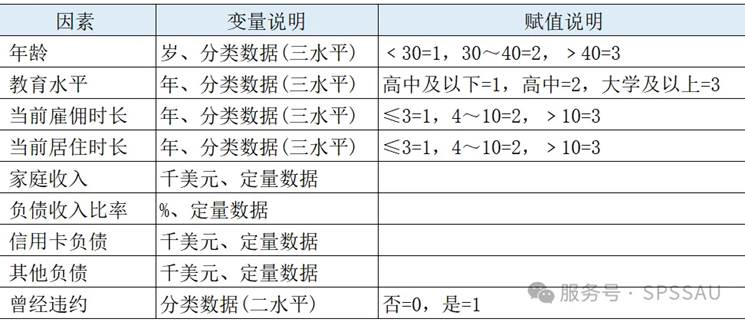
接下来进行二元Logistic回归分析。
1、基本条件判断
(1)因变量类型:研究贷款违约发生的相关因素,因变量“曾经违约”有两种结局“是”与“否”,因此选择使用二元Logistic 回归。
(2)多重共线性判断:SPSSAU中二元logistic回归可进行共线性诊断,其原理是利用线性回归进行分析并且输出VIF值及容忍度指标。如果出现某项VIF值大于10(严格情况下为VIF>5),则说明该项具有共线性问题,可考虑将其移出模型后再次分析;进行二元logistic回归时勾选“共线性诊断”,操作如下图:

SPSSAU输出共线性诊断结果如下:

分析上表可知,自变量VIF值均小于5,容忍度均大于0.2,故自变量间不存在共线性问题。
2、建立Logistic回归模型
建立Logistic回归模型进行单因素筛查、因变量0-1编码和分类自变量哑变量处理。
(1)单因素筛查
Logistic 回归建模常采用“先单后多”的分步筛选法:先通过单因素分析初筛自变量,再将显著变量引入多因素模型。此方法在探索性研究、自变量较多或小样本场景中应用广泛。
单因素分析依据变量类型选择检验方法(如卡方检验用于分类变量,t 检验/方差分析用于连续变量)。为防止遗漏关键变量,单因素筛选的显著性水平可适当放宽至 0.1、0.15 或 0.2。
针对本研究的自变量——四个连续变量(家庭收入等)和四个分类变量(年龄等),单因素筛查分别采用 t 检验(连续变量)和卡方检验(分类变量),显著性水平放宽至 0.1。
- 连续变量进行t检验
将因变量“曾经违约”作为因变量,“家庭收入”等4个连续变量作为自变量进行独立样本t检验,SPSSAU操作如下图:
SPSSAU输出独立样本t检验结果如下:
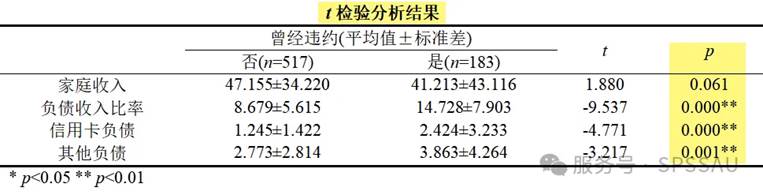
分析上表可知,四个定量自变量的p值均小于0.1(显著性水平放宽),均会对因变量“曾经违约”产生显著影响,均保留。
- 分类变量进行卡方检验
将因变量“曾经违约”作为因变量,“年龄”等4个分类变量作为自变量进行卡方检验,SPSSAU操作如下图:
SPSSAU输出卡方检验分析结果如下:
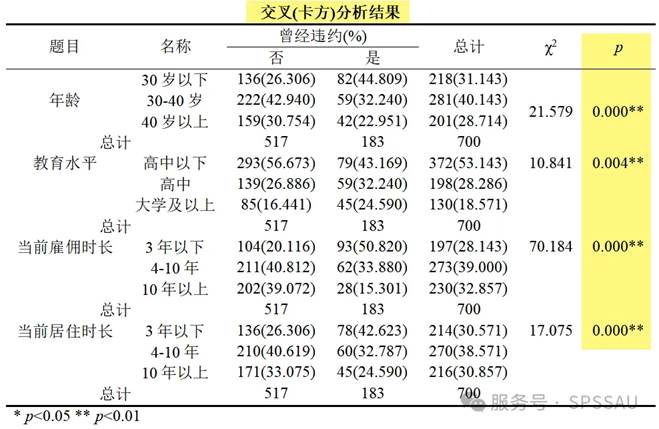
分析上表可知:“年龄”等4个定类自变量的p值均小于0.05,均会对“曾经违约”产生显著影响,均保留。
【提示】:需要说明的是,在样本量充足、研究目标明确且具备充分理论依据的情况下,可省略单因素筛选步骤,直接将所有自变量纳入多因素 Logistic 回归模型。
(2)因变量0-1编码
进行二元Logistic回归分析,因变量必须为使用数字0、1表示(本案例为0、1表示),若非如此,需要使用SPSSAU【数据处理】模块的【数据编码】进行处理,操作如下图: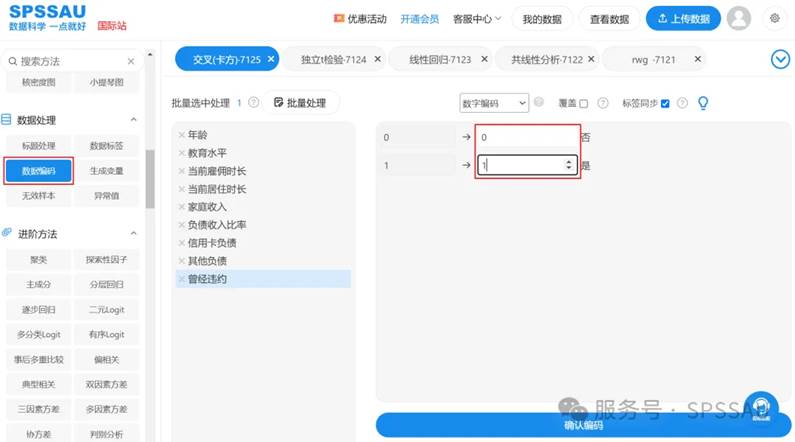
(3)定类自变量哑变量处理
回归分析时,需要对定类自变量进行哑变量处理,在【数据处理】模块,选择【生成变量】,选中定类自变量然后点击生成“虚拟(哑)变量”,操作如下图:
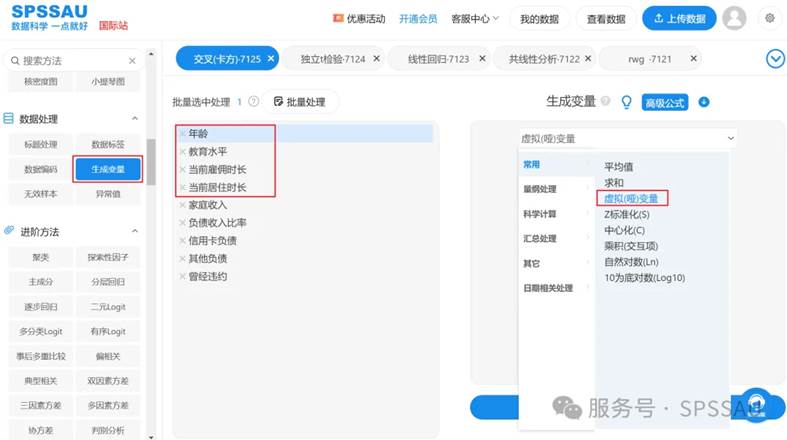
(4)二元Logistic回归分析
在SPSSAU【进阶方法】模块选择【二元Logit】,自变量拖拽到右侧分析框,注意本例全部选择定类变量的第一个水平作为参照项,参照项不移入分析框中,选择变量进入方法为“逐步法”,操作如下图:
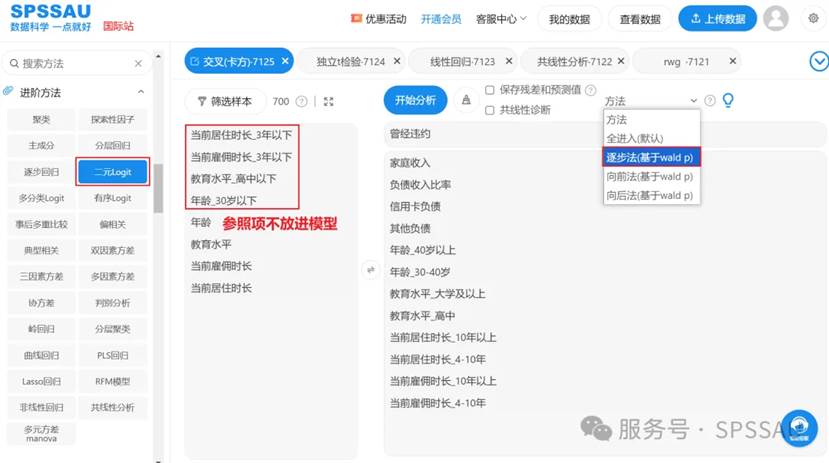
点击“开始分析”按钮得到二元logistic回归分析结果,下面按顺序解读分析结果。
3、模型整体检验与评价
(1)似然比卡方检验
似然比检验用于检验模型整体的有效性,如果p值小于0.05,则说明模型有效;反之则说明模型无效。

分析上表可知:χ2 =229.287,p<0.01,认为二元 Logistic 回归模型总体上有统计学意义,模型中引入的自变量至少有一个对因变量有影响,模型是有效的。
表中的AIC和BIC值用于多次分析时的对比,此两值越低越好。如果多次进行分析,可对比此两个值的变化情况,综合说明模型构建的优化过程。
(2)Hosmer-Lemeshow检验
H-L检验原假设为,模型拟合值和观测值的拟合状况良好,如果p值大于0.05则说明通过HL检验,反之则说明模型没有通过HL检验,模型拟合优度差。

分析上表可知:χ2=5.219,p=0.734>0.05,说明模型拟合良好。
(3)决定系数R方
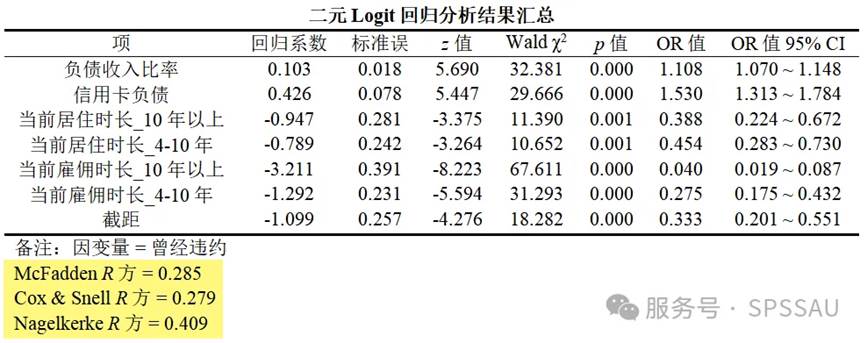
在模型分析结果汇总表(偏回归系数解释时使用),即下表的底部,SPSSAU提供了3个伪 R2指标,其含义类似线性回归中的决定系数R2 ,取值越大越好,在实际分析中应用较少,可以不做关注。
(4)模型预测准确率

本例二元 Logistic 回归模型对结局 0 即未违约的预测准确率为 93.037%(481/517),对结局为 1 即违约的预测准确率为 45.902%,总体预测准确率为 80.714%。从银行贷款业务风险预警角度来看,本例更关注对违约结局的预测能力,显然 45.902%是比较低的,该模型的实用价值有待进一步提高。
【注意】:有些研究并不看中模型的预测能力,而主要关注的是因变量的相关影响因素。
4、回归系数/OR值解读
回归系数与OR值的关系:OR 值等于回归系数的自然对数值,若自变量X的偏回归系数为0.6,则其OR=exp(0.6)
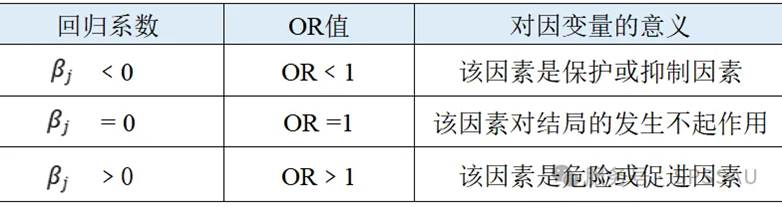
- 若 β j < 0,则 OR 值小于 1,表示该因素是保护或抑制因素。
- 若 β j = 0,则 OR 值等于 1,表示该因素对结局的发生与否不起作用。
- 若 β j > 0,则 OR 值大于 1,表示该因素是危险或促进因素。
SPSSAU输出二元Logistic回归分析结果如下。通过逐步法,模型能自动根据显著性情况对自变量进行引入或剔除,最终保留了以下变量,这些变量均会对因变量“曾经违约”产生显著影响。
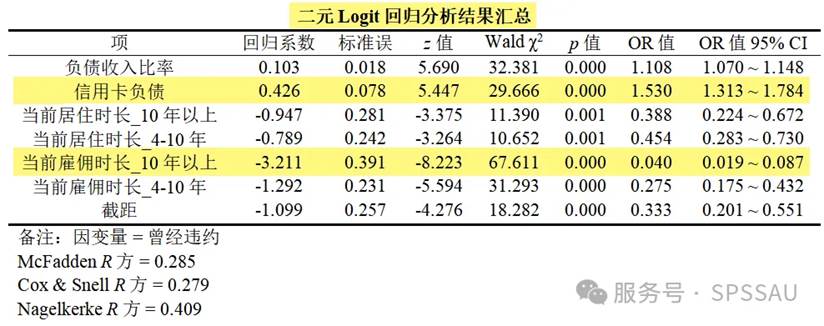
对于二元logistic回归分析结果,重点应该关注的是各因素的回归系数、OR 值及其95%CI。对于不同类型变量其回归系数与OR值解读略有不同,下面分别以一个变量进行举例说明。
(1)定量变量解读
两个定量数据“负债收入比率”“信用卡负债”的回归系数为正数,认为其与“是否违约”存在正向相关关系。相对应的 OR 值大于 1,OR 值 95% CI 不包括 1,说明“负债收入比率”“信用卡负债”越高越容易出现偿还贷款违约的情况。
以“信用卡负债”为例:
- Wald χ2=29.666,p<0.01,认为其对“是否违约”的影响有统计学意义。
- 回归系数为0.426,说明二者存在正相关关系。
- OR=1.530>1,说明其为发生违约的危险因素或促进因素,“信用卡负债”每增加一个单位,其发生违约的可能性是原来的 1.530 倍,或发生违约的可能性比原来增加 53%。
(2)定类变量解读
4 个哑变量的偏回归系数均为负数,说明其与“曾经违约”存在负相关关系,相对应的 OR 值均小于 1,OR 值 95% CI 不包括 1,说明变量对“是否违约”起抑制作用,“当前居住时长”“当前工作时长”越长(相对于参照项—最低水平哑变量时长越长)越不容易出现还贷违约的情况。
以“当前雇佣时长_10 年以上”为例:
- Wald χ2=67.611,p<0.01,相较于“当前雇佣时长_4 年以下”认为其对“是否违约”的影响有统计学意义。
- 回归系数为-3.211,说明二者存在负相关关系。
- OR=0.040<1,说明其为发生违约的保护因素或抑制因素,“当前雇佣时长”每改变一个等级,其发生违约的可能性是原来的 0.040 倍,或发生违约的可能性比原来降低 99.6%。
5、结果报告
- 本例建立的贷款违约二元 Logistic 回归模型为:
ln(P/1-P)=-1.099-0.947×当前居住时长_10 年以上-0.789×当前居住时长_4~10 年-3.211×当前雇佣时长_10 年以上-1.292×当前雇佣时长_4~10 年+0.103×负债收入比率+0.426×信用卡负债
其中,P 代表“曾经违约”为 1 的概率,1-P 代表“曾经违约”为 0 的概率。总体而言模型有统计学意义。“负债收入比率”和“信用卡负债”正向影响违约的发生,而“当前居住时长”和“当前雇佣时长”则反向抑制违约的发生。
OR值95%CI可直观地展示模型中引入的自变量,以及各自变量对因变量影响的 OR值情况。SPSSAU输出二元Logistic回归的OR值结果绘制的图形如下图所示:
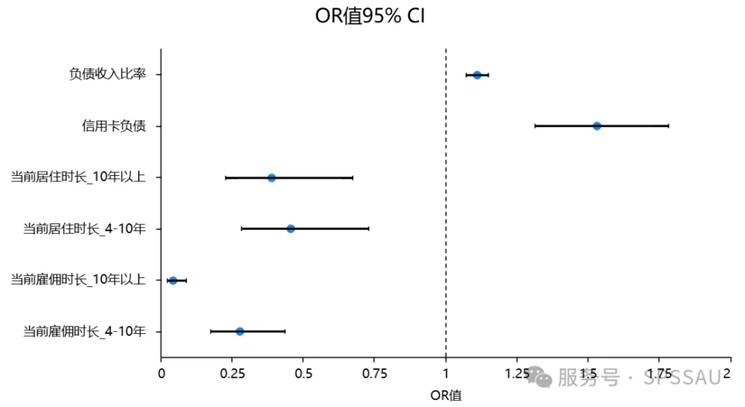
图中垂直的虚线代表 OR 值等于 1,为无效线,图中的横线段为各自变量的 OR 值 CI,线段中间的圆点为具体的 OR 值。若各自变量的 OR 值 CI 和虚线无交叉或重叠,则表示对应的自变量有显著性,位于虚线右侧表示 OR 值大于 1,为危险因素;位于虚线左侧表示 OR 值小于 1,为保护因素。
若不会解读分析结果,可以参考SPSSAU分析结果表格下方的智能分析与分析建议,如下图:
- 其他结果:
除以上结果外,SPSSAU还会给出边际效应结果。边际效应指增加一个单位时额外带来的效应情况,通常在经济计量领域使用较多;
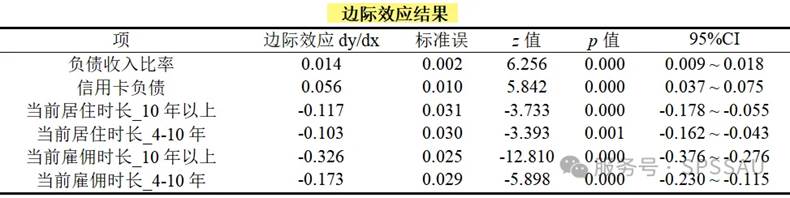
如果边际效应值呈现出显著性,则意味着有着显著的边际效应,反之则说明没有显著的边际效应。如果边际效应值显著且大于0,则意味着X的增加会带来正向效应变化;如果边际效应值显著且小于0,则意味着X的增加会带来负向效应变化。
迭代SPSSAU还会给出中间过程表格,展示二元logistic回归分析时的每一次迭代过程回归系数及p值等,更多结果以及疑难解惑可点击下方按钮查看SPSSAU帮助手册:二元logit回归帮助手册
四、总结
划重点
1、应用:二元Logistic回归分析因变量为二分类变量,自变量可以为定量数据或者定类数据,定类数据时需要进行哑变量处理再分析。
2、单因素筛查:当自变量较多时,先通过单因素分析筛选自变量,然后仅保留有显著影响的自变量进行多因素Logistic回归。同时为避免遗漏重要变量,差异的显著性水平可以适当放宽。
3、哑变量参照项:进行回归分析时,针对定类变量生成的哑变量,需要留一项作为参照项,一般为最低水平。
4、回归系数与OR值:解读的时候需要注意二者的关系,定量变量与定类变量解读方式略有不同。
参考文献:周俊,马世澎. SPSSAU科研数据分析方法与应用.第1版[M]. 电子工业出版社,2024.

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)