一.Yolov8量化感知训练微调(QAT)第三篇: 感知量化训练QAT,onnx导出,engine导出
int8 --fp16: 启用INT8(8位整数)和–fp16量化精度, 对不支持量化的层默认转fp16. 如果模型finetune时, 全部层都做了int8量化, 那么只需要–int8即可;–workspace=4096 : 转engine模型用到, 模型小可以设置1024, 但如果模型大, 要设置大一些, 例如2048, 4096, 8192等,但不能大于GPU显存大小.可以自行设置, 例如设
一.Yolov8量化感知训练微调(QAT)第一篇:QAT原理和微调训练流程
一.Yolov8量化感知训练微调(QAT)第二篇: 单batch和多batch导出onnx和engine模型 (Tensorrt推理)
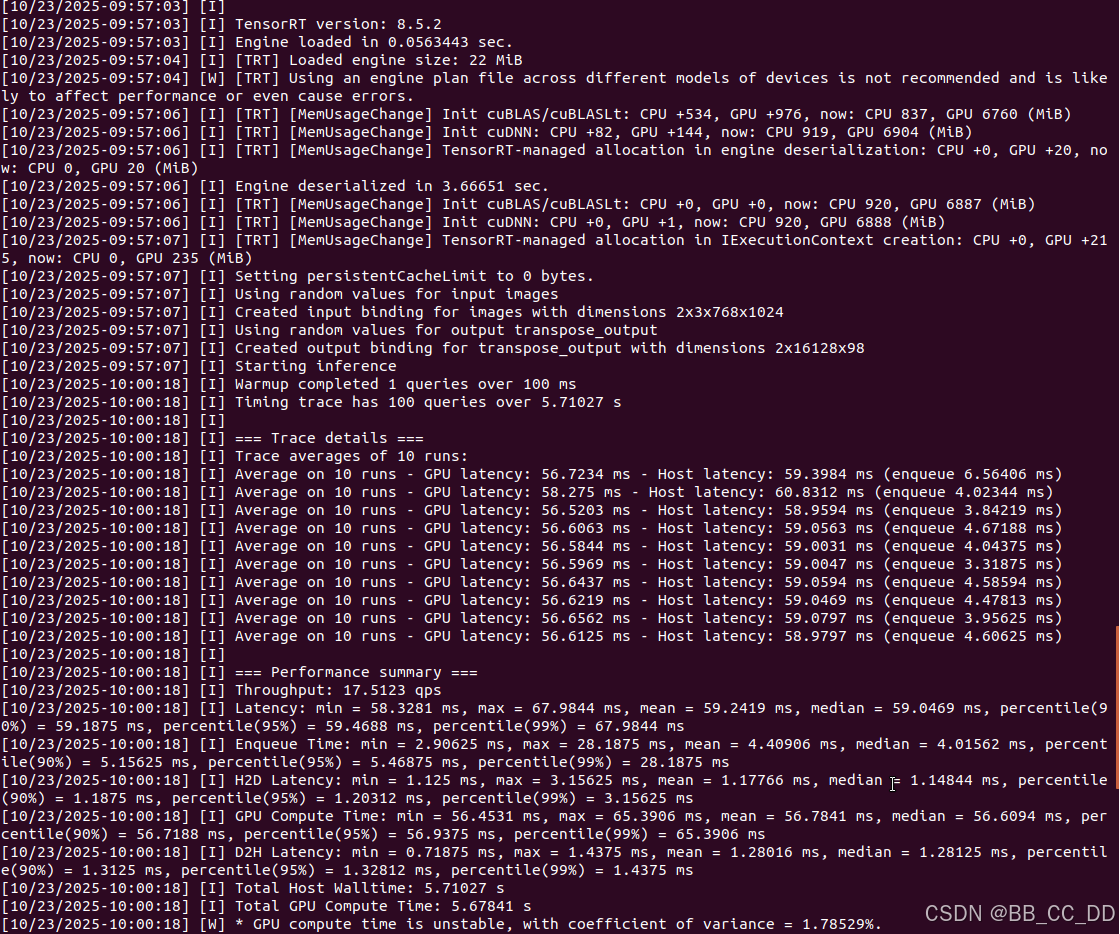
如果你的QAT finetune ---> onnx ---> engine, 到下面打印信息, 说明你的QAT训练到部署的流程都是正确的!
# 在tensorrt的环境中执行:
/usr/src/tensorrt/bin/trtexec \
--loadEngine=qat_multi_batch.engine \
--shapes=images:2x3x768x1024 \
--warmUp=100 \
--duration=10 \
--iterations=100
一. 先做数据校准Calibrate
根据训练数据集数量, 来设置数据校准Calibrate迭代次数, 如何设置图像样本校准的迭代次数?
我的训练数据是19580张:
初始设置:
num_batch=30~40
- 理由:
约占总样本的1.5-2.5%,既有足够代表性,又不会过度耗时.
验证方法:
(19580张图片覆盖了各种场景、光照、目标大小等)
- 先用30次校准,记录PTQ精度
- 如果PTQ精度和原始pt精度差异较大,可逐步增加到50次
- 观察35次→50次的精度提升幅度
- 如果提升很小(<0.5% mAP),说明30次已足够
渐进式校准测试代码:
# 建议从小到大测试
test_values = [30, 35, 40, 50]
for num_batch in test_values:
quantize.calibrate_model(model, train_dataloader, device, num_batch=num_batch)
# 评估PTQ精度
ap = evaluate_coco(model, val_dataloader)
print(f"num_batch={num_batch}, AP={ap}")
二. 再进行感知量化finetune训练
finetune训练运行指令: 用1024x1024进行训练
我的yolov8不需要跳过量化层, 所有的层都能量化到int8
但yolov11需要跳过一些量化层
# yolov8 QAT finetune
python qat-yolov8-obb.py \
--finetune \
--weight best.pt \
--cocodir datasets \
--size 1024 1024 \
--calib-batches 30 \
--device 1 \
--nepoches 10 \
--batchsize 16 \
--eval-origin --eval-ptq
>> QAT_finetune_result.txt 2>&1
# yolov11 QAT finetune
python qat-yolov8-obb.py \
--finetune \
--weight best.pt \
--cocodir datasets \
--size 1024 1024 \
--calib-batches 30 \
--ignore-policy "model\.10\.m\.0\.attn\..*|model\.10\.m\.0\.attn\.pe\.conv.*|model\.10\.m\.0\.attn\.Add" \
--device 1 \
--nepoches 10 \
--batchsize 16 \
--eval-origin --eval-ptq
>> QAT_finetune_result.txt 2>&1
参数解释:
–device: 指定训练显卡
–weight best.pt: best.pt是yolov8训练的算法pt模型
–cocodir datasets: datasets是我们要训练的数据集目录, 里面存有images和labels.
–size 1024 1024: 表示训练微调的图像尺寸大小, 顺序是h w;可以自行设置, 例如设置成768 1024, 即导出的onnx模型的h=768, w=1024.
–eval-origin: 表示在数据校准calibrate之后, finetune训练之前, 会先根据val验证集评估一个原始pt模型的精度.
–eval-ptq: 表示在数据校准calibrate之后, finetune训练之前, 会先根据val验证集评估一个后处理量化后(PTQ)的模型的精度.
–calib-batches 30: 表示要进行30次数据校准
–nepoches: 全部数据总训练迭代次数
–ignore-policy: 表示需要跳过的量化节点, 禁用量化. 原因:有些层支持量化, 有些层不支持, 转engine会报错;有些层转量化会影响精度.也可以这么写: “model.10.m.0.attn…*” 但这样写有个问题, 这样会禁用所有的.attn的层, 就不能指定某几层了.
三. qat.pt导出qat.onnx模型
把1024x1024尺寸的pt模型转换成768x1024尺寸的onnx模型.(768是h, 1024是w)
python qat-yolov8-obb.py \
--weight qat.pt \
--export \
--save qat.onnx \
--size 768 1024 \
--dynamic
–size 768 1024: 导出的onnx支持的图像最大分辨率是h=768, w=1024;
–dynamic: 表示支持batch推理onnx, 导出engine时也能支持batch推理
此时得到的qat.onnx依旧是带有量化节点的onnx模型, 但本质上类型还是float32
四. qat.onnx模型导出int8量化qat.engine模型
把768x1024尺寸的onnx模型转换成768x1024尺寸的engine模型.(768是h, 1024是w)
sudo /usr/src/tensorrt/bin/trtexec\
--onnx=qat_multi_batch.onnx \
--saveEngine=qat_multi_batch.engine \
--workspace=4096 \ # TensorRT ≤ 8.4写法
# --memPoolSize=workspace:4096 #TensorRT ≥ 8.5写法
--int8 --fp16\
--verbose \
--useCudaGraph \
--minShapes=images:1x3x768x1024 \
--optShapes=images:2x3x768x1024 \
--maxShapes=images:4x3x7681024
参数解释:
–workspace=4096 : 转engine模型用到, 模型小可以设置1024, 但如果模型大, 要设置大一些, 例如2048, 4096, 8192等,但不能大于GPU显存大小.
–int8 --fp16: 启用INT8(8位整数)和–fp16量化精度, 对不支持量化的层默认转fp16. 如果模型finetune时, 全部层都做了int8量化, 那么只需要–int8即可; 如果模型finetune时, 有部分层没有做int8量化, 那么需要加上–fp16, 否则转模型时会报错;
–verbose: 打印转换模型的信息, 方便查找转换模型的问题
–useCudaGraph: 启用 CUDA 图优化来提高推理性能, 优化内核执行, 减少 GPU 资源的切换和同步, 从而加速推理过程 (但按照640*640测试下来, 推理时间没有减少)
–minShapes, --optShapes, --maxShapes: 是为了能batch推理engine模型, 我这里设置的是最高支持同时推理4个模型
五. 测试engine模型是否可运行 (无代码方案测试engine模型)
(768是h, 1024是w)
/usr/src/tensorrt/bin/trtexec \
--loadEngine=qat_multi_batch.engine \
--shapes=images:2x3x768x1024 \
--warmUp=100 \
--duration=10 \
--iterations=100

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 33
33 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)