【强化学习】基于DDPG的二阶弹簧阻尼系统轨迹跟踪控制
综上可见,强化学习控制器与PID相比各有优劣,不过由于强化学习的训练时长和训练效率很不确定,始终感觉强化学习很不稳定,对参数也很敏感,很玄学,没想象中好用。另外,目前看来,强化学习对于阶跃和斜坡的给定输入来说比较合适,还能跟得上,像正余弦这种强化学习就搞不明白了,得要更多的训练,时间和成本都上去了,并且强化学习目前也只能停留于理论层面,实际落地也还早,感觉强化学习缺点大于优点,总的来说,对强化学习
最近在看控制领域研究热门–强化学习相关的东西,跟着matlab官方强化学习教程一边看一边学,感觉需要补很多机器学习相关的知识,高数概率论那些,感觉现在只大概会用,原理啥的还没特别透彻。
1. 强化学习概述
- obsinfo与actinfo:定义观测信号与控制信号的维度与范围。
- env:观测向量与输出动作的定义以及eposide每次调用的resetfcn定义。
- agent:智能体,强化学习控制器
- reward:奖励函数,目前看来使用定性定量目标和使用连续可导的函数均比较合适
- 强化学习算法
– 基于价值函数求解:MD、DP、Q-Learning等
– 基于策略梯度求解:DPG、SAC、TD3、DDPG等
官方案例用的是DDPG算法,于是我对DDPG进行了一些了解,DDPG结合了深度神经网络和强化学习策略,通过神经网络来拟合策略函数和价值函数,包含两大部分:Critic和Actor,Critic输出当前状态下的价值函数,Actor输出智能体的动作,DDPG适用于连续动作空间的任务。DDPG原理的通俗理解==>深度确定性策略梯度 DDPG
2. 仿真示例
考虑如下带外部扰动的二阶弹簧阻尼系统
m x ¨ + c x ˙ + k x = u + d m\ddot{x}+c\dot{x}+kx=u+d mx¨+cx˙+kx=u+d其中,x为位移;u为控制输入;m为质量;c为阻尼系数;k为弹簧刚度;d为加在控制输入端的外部扰动,设为d=0.5*sin(t);
目标:通过DDPG控制器,实现系统的常值或正弦信号跟踪控制。
DDPG设计过程中需要注意:
- 观测信号输入的有误差、误差微分、误差积分。目的是防止最终的跟踪控制存在稳态误差,因此需要尽可能输入较多的信息给控制器。如果想要精度更高可再输入误差的二阶导等信息。
- 奖惩函数(非常重要):决定了是否能收敛,reward函数综合考虑误差、误差微分、误差积分以及控制输入的权重,当跟踪误差小于某个阈值给一个正向激励。
- is done:这里不设置停止条件,当迭代满足最大次数时或者奖惩值满足某个阈值时停止迭代。
- localResetFcn 设置不同的参考信号和初始条件(如常值 or 正弦),从而让 agent 学会应对不同类型的参考信号。
DDPG算法参数设置:
- 最大迭代次数 600,仿真时长Ts 10s,采样时间 0.05s。
- 其余超参数设为一般值。
基于 Simulink 环境(rlSimulinkEnv) + M 函数定义的训练脚本,搭建的simulink仿真框图如下所示: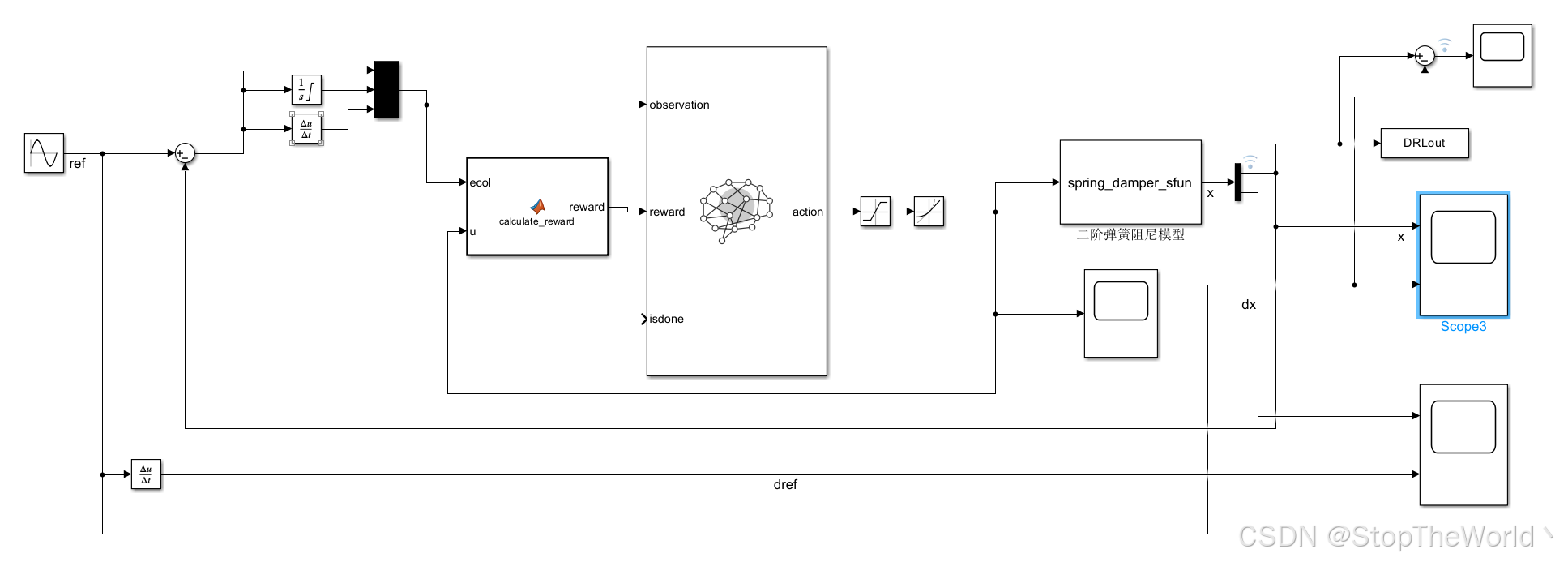
2.1 训练过程
观察整体训练过程,Episode reward 和 Average reward 逐步上升,最终收敛,q0值也稳步上升,说明了训练是有效的。

2.2 仿真验证
训练完成后,分别对不同的参考信号进行仿真分析:
1. 对正弦信号0.89*sin(0.905*t)的跟踪效果如下所示:

模型的初始状态值为0.3,观察曲线可得,基本实现了正弦信号的跟踪,跟踪效果良好,稳态误差约为0.04,这个可通过(增加更多的观测信息、切换到更深的网络、使用TD3或SAC)来进一步缩小误差。
2. 对常值信号的跟踪效果如下所示:

总体来说,也基本实现了常值信号的跟踪,跟踪效果良好,稳态误差约为0.05左右。
总结
综上所述,DDPG强化学习控制器基本实现了正弦信号与常值信号的跟踪,目前觉得强化学习:
优点在于能够处理复杂系统、强非线性系统、模型的不确定性、多目标优化(考虑跟踪和能耗)。
缺点在于reward需要精细设计、设计复杂度需要调参的个数较多、在线计算量较高、安全场景下不能单独使用。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)