多样本整合Banksy空间聚类分析(Visium HD, Xenium, CosMx)
在空间数据分析中,传统的单细胞聚类算法,例如Seurat和Scanpy中的lovain和leiden等聚类算法,通常在处理空间数据时忽略了空间信息。然而,由于细胞状态受其周围细胞的影响,将转录组数据与细胞的空间信息结合起来进行聚类分析,有助于揭示细胞在组织中的分布和相互作用。之前我们介绍了Banksy的python版本代码使用(针对单个样本)。我们知道BANKSY是一种空间组学数据的聚类方法,通过将每个细胞的特征(基因表达)与其空间近邻特征的平均值以及邻域特征梯度相结合来进行聚类,这样就结合了细胞分子邻域特征,增强了空间结构识别。
这里我们介绍下针对有多个样本情况下,从一个包含多个样本细胞的Anndata对象开始,先对多样本空间坐标进行错位处理(Staggering,解决多个样本合并时坐标重叠问题),然后怎样构建空间最近邻图,再降维和harmony去批次,最后整合起来进行聚类。
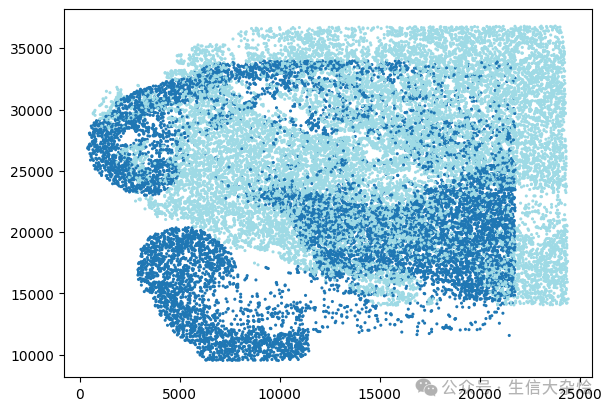
1. 未经坐标偏移的两个样本空间坐标(原始)
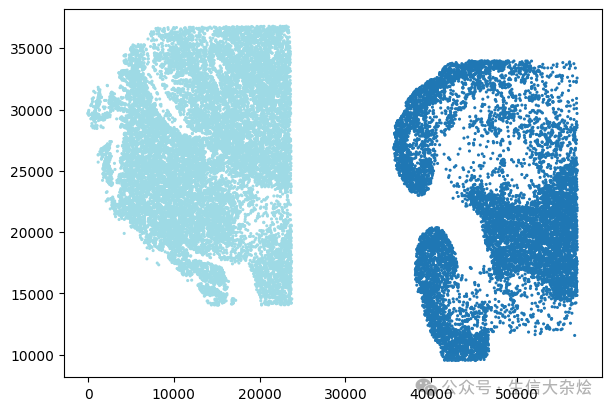
2. Stagger the spatial coordinates across the samples, so that spots from different samples do not overlap (sample specific treatment)
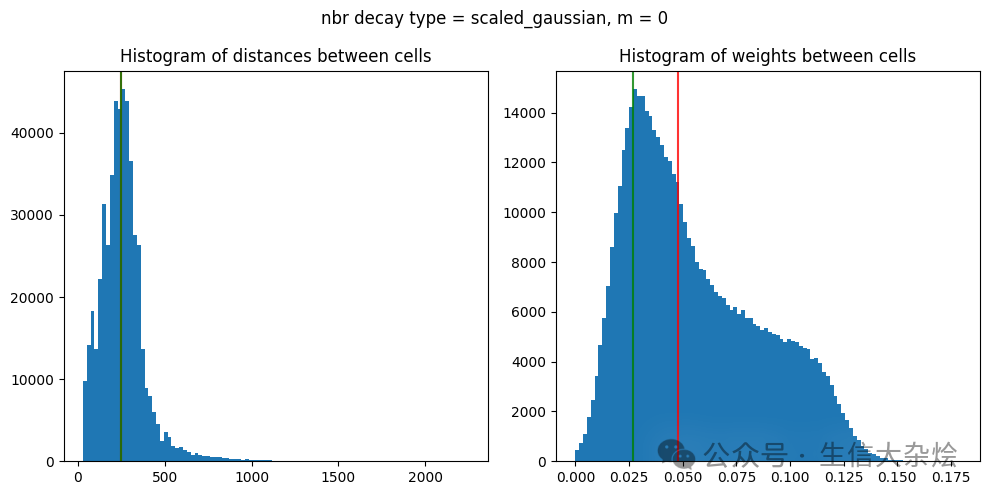
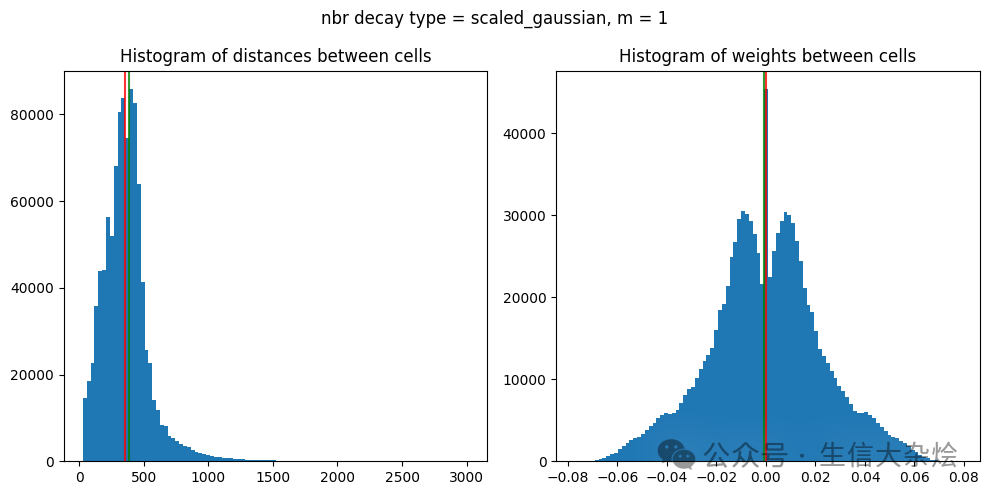
3. Calculate Banksy matrix
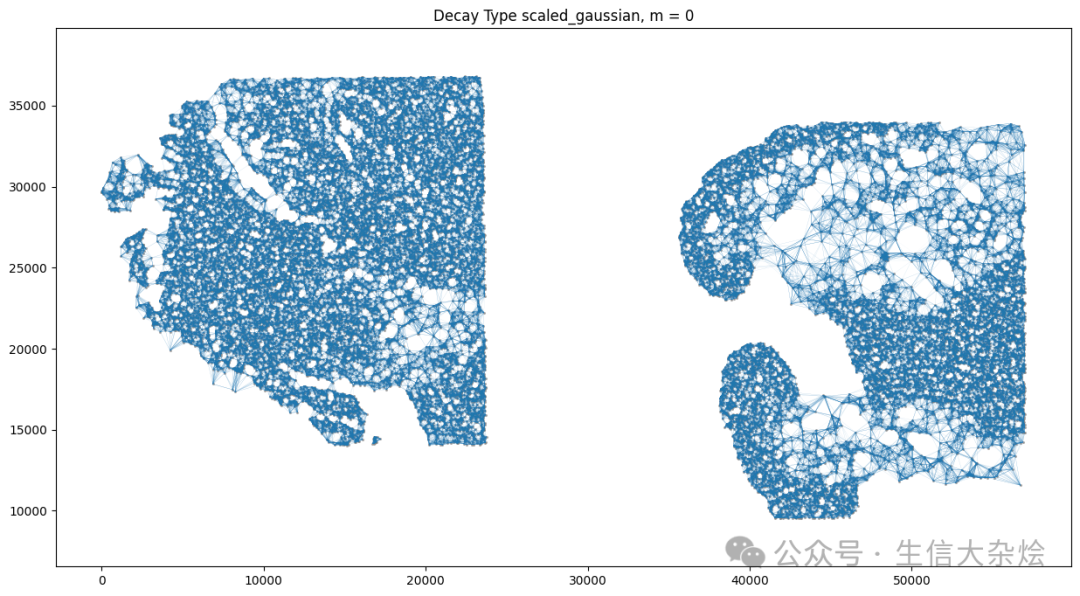
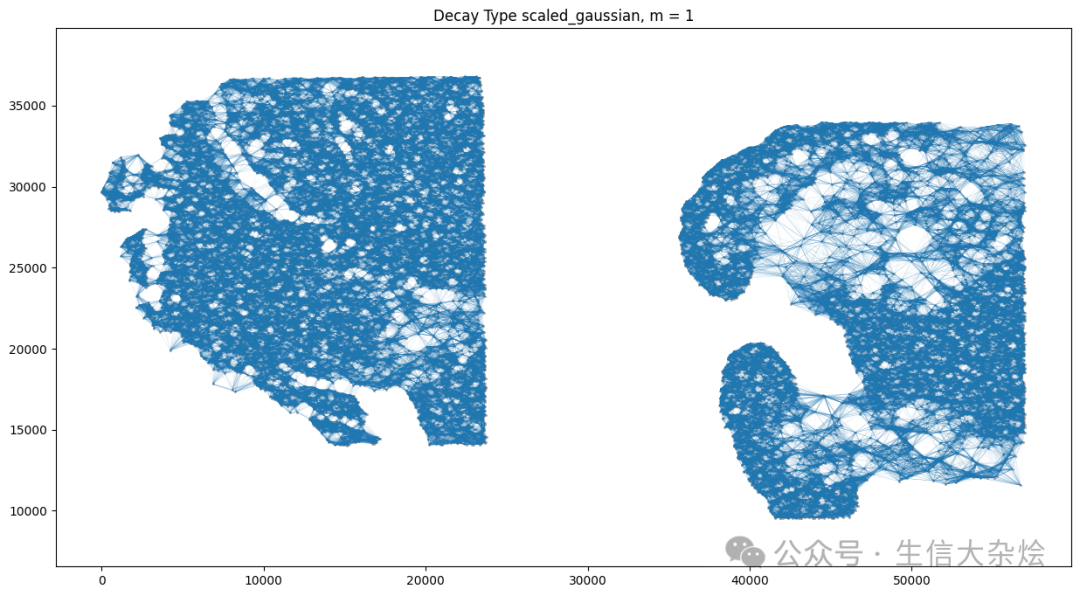
4. 多样本Banksy后空间及UMAP结果
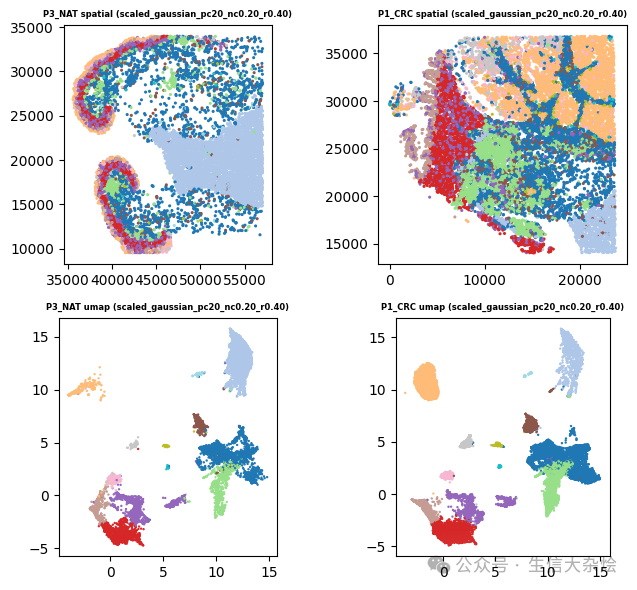
代码实现:
分析环境加载
import osimport umapimport randomimport numpy as npimport pandas as pdimport scanpy as scfrom harmony import harmonizefrom banksy.initialize_banksy import initialize_banksyfrom banksy.embed_banksy import generate_banksy_matrixfrom banksy.main import concatenate_allfrom banksy_utils.umap_pca import pca_umapfrom banksy.cluster_methods import run_Leiden_partitionimport matplotlib.pyplot as pltimport warningswarnings.filterwarnings("ignore")plt.style.use('default')plt.rcParams['figure.facecolor'] = 'white'seeds = [0]random.seed(seeds[0])np.random.seed(seeds[0])
多样本数据读取及预处理
adata = sc.read_h5ad('/data/VisiumHD/CRC_demo/adata_raw.h5ad')# 这里只是为了快速演示,所以抽了百分之十细胞进行后续分析sc.pp.sample(adata, 0.1)adata.var["mt"] = adata.var_names.str.startswith("MT-")adata.var["ribo"] = adata.var_names.str.startswith(("RPS", "RPL"))sc.pp.calculate_qc_metrics(adata, qc_vars=["mt", "ribo"], inplace=True, log1p=True)sc.pp.filter_cells(adata, min_counts=30)sc.pp.filter_genes(adata, min_cells=10)adata = adata[adata.obs['pct_counts_mt']<20, :]# Normalizeadata.layers["counts"] = adata.X.copy()sc.pp.normalize_total(adata)
Stagger the spatial coordinates across the samples, so that spots from different samples do not overlap (sample specific treatment)
adata.obs['x_pixel'] = adata.obsm['spatial'][:, 0]adata.obs['y_pixel'] = adata.obsm['spatial'][:, 1]# 为每个样本生成颜色unique_samples = adata.obs['sample'].unique()colors = plt.cm.tab20(np.linspace(0, 1, len(unique_samples)))color_dict = {sample: colors[i] for i, sample in enumerate(unique_samples)}sample_colors = [color_dict[s] for s in adata.obs['sample']]# 绘制散点图fig = plt.figure(figsize=(6, 4), constrained_layout=True)scatter = plt.scatter(x=adata.obs['x_pixel'],y=adata.obs['y_pixel'],c=sample_colors,alpha=1,s=1.5)# Staggeringcoords_df = pd.DataFrame(adata.obs[['x_pixel', 'y_pixel', 'sample']])coords_df['x_pixel'] = coords_df.groupby('sample')['x_pixel'].transform(lambda x: x - x.min())global_max_x = max(coords_df['x_pixel']) * 1.5#Turn samples into factorscoords_df['sample_no'] = pd.Categorical(coords_df['sample']).codes#Update x coordinatescoords_df['x_pixel'] = coords_df['x_pixel'] + coords_df['sample_no'] * global_max_x#Update staggered coords to AnnData objectadata.obs['x_pixel'] = coords_df['x_pixel']adata.obs['y_pixel'] = coords_df['y_pixel']# AFTER staggering the spatial coordinatesfig = plt.figure(figsize=(6, 4), constrained_layout=True)scatter = plt.scatter(x=adata.obs['x_pixel'],y=adata.obs['y_pixel'],c=sample_colors,alpha=1,s=1.5)
Subset to 2000 HVGs and Running BANKSY (with AGF)
sc.pp.highly_variable_genes(adata, n_top_genes=2000, flavor='seurat_v3', layer='counts', batch_key="sample")adata = adata[:, adata.var['highly_variable']]## banksy parameters ##nbr_weight_decay = 'scaled_gaussian'k_geom = 18resolutions = [0.40] # clustering resolution for UMAPpca_dims = [20] # Dimensionality in which PCA reduces tolambda_list = [0.2] # list of lambda parametersm = 1c_map = 'tab20' # specify color map# Include spatial coordinates informationcoord_keys = ('x_pixel', 'y_pixel', 'coord_xy')x_coord, y_coord, xy_coord = coord_keys[0], coord_keys[1], coord_keys[2]raw_y, raw_x = adata.obs[y_coord], adata.obs[x_coord]adata.obsm[xy_coord] = np.vstack((adata.obs[x_coord].values, adata.obs[y_coord].values)).T### run banksy ###banksy_dict = initialize_banksy(adata,coord_keys,k_geom,nbr_weight_decay=nbr_weight_decay,max_m=m,plt_edge_hist= True,plt_nbr_weights= True,plt_agf_angles=False,plt_theta=False)banksy_dict, banksy_matrix = generate_banksy_matrix(adata,banksy_dict,lambda_list,max_m=m)banksy_dict["nonspatial"] = {# Here we simply append the nonspatial matrix (adata.X) to obtain the nonspatial clustering results0.0: {"adata": concatenate_all([adata.X], 0, adata=adata), }}print(banksy_dict['nonspatial'][0.0]['adata'])
Dimensionality Reduction and Harmony

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)