(可当毕业设计)基于大数据的玉米产量数据可视化分析系统 |Hadoop+Spark+Hive |大数据毕业设计定制 |
本文介绍了一个基于大数据的玉米产量数据可视化分析系统,采用Hadoop+Spark+Hive技术栈构建。系统通过数据采集与清洗、大数据处理分析、可视化展示等功能模块,对玉米产量及影响因素进行多维度分析。开发技术包括Python、Django、Vue和K-means算法,实现了数据管理、词云图、可视化分析及系统管理等功能。该系统为农业决策提供数据支持,有助于提升产量预测精准度和农业资源利用效率,助力
🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于大数据的玉米产量数据可视化分析系统 |Hadoop+Spark+Hive(可用于毕业设计)
1、玉米产量数据可视化分析系统-前言介绍
1.1背景
随着全球人口的持续增长,粮食安全问题日益受到各国政府和科研机构的关注。玉米作为世界上主要的粮食作物之一,不仅是人类食物的主要来源之一,还是动物饲料和工业原料的重要组成部分。玉米产量的稳定性直接关系到农业生产的经济效益以及国家粮食安全。因此,对玉米产量的监测和分析具有重要意义。近年来,随着大数据技术的发展,如何通过大数据分析技术对玉米产量进行精确预测、分析和优化成为了一个亟待解决的问题。传统的产量预测方法多依赖于人工统计和经验分析,这些方法不仅效率低下,而且精确度不足,无法有效应对复杂多变的农业环境和生产因素。针对这一问题,开发一个集成大数据技术、精准分析和实时监控的玉米产量数据可视化分析系统,不仅能够有效提升玉米产量预测的准确性,还能够为农业管理者提供实时决策支持,助力精准农业的发展。
1.2课题功能、技术
随着全球人口的持续增长,粮食安全问题日益受到各国政府和科研机构的关注。玉米作为世界上主要的粮食作物之一,不仅是人类食物的主要来源之一,还是动物饲料和工业原料的重要组成部分。玉米产量的稳定性直接关系到农业生产的经济效益以及国家粮食安全。因此,对玉米产量的监测和分析具有重要意义。近年来,随着大数据技术的发展,如何通过大数据分析技术对玉米产量进行精确预测、分析和优化成为了一个亟待解决的问题。传统的产量预测方法多依赖于人工统计和经验分析,这些方法不仅效率低下,而且精确度不足,无法有效应对复杂多变的农业环境和生产因素。针对这一问题,开发一个集成大数据技术、精准分析和实时监控的玉米产量数据可视化分析系统,不仅能够有效提升玉米产量预测的准确性,还能够为农业管理者提供实时决策支持,助力精准农业的发展。
1.3 意义
本课题的研究和实施对于推动农业现代化,提升玉米生产的效率与可持续性具有重要意义。通过大数据技术的应用,不仅能够提高玉米产量预测的准确性,还能够帮助农业管理者科学评估环境因素的影响,优化生产决策,从而提高农业资源的利用效率,降低生产成本。系统能够为农业科研机构、政府部门及农民提供有效的工具和支持,推动农业产业向数字化、智能化方向发展。此外,随着系统的推广应用,能够为更多的农业生产领域提供数据驱动的决策支持,推动农业大数据技术的普及和发展,助力全球粮食安全问题的解决。通过对玉米产量的精准分析和预测,系统不仅为玉米种植业提供科学依据,还为全球粮食生产的可持续发展提供了技术支撑。
2、玉米产量数据可视化分析系统-研究内容
(1)数据采集与清洗:通过集成多个数据源,系统自动采集玉米产量、气象、土壤等环境因素的数据。采集到的数据经过预处理,包括数据去重、缺失值填补、异常值处理等步骤,确保数据的准确性和完整性,为后续分析奠定基础。
(2)大数据处理与分析:利用Hadoop、Spark和Hive等大数据技术,对大量的玉米产量数据进行分布式存储和处理。通过数据挖掘和机器学习算法,分析产量波动、气候变化等因素的影响,提供数据支持和预测模型,为决策提供依据。
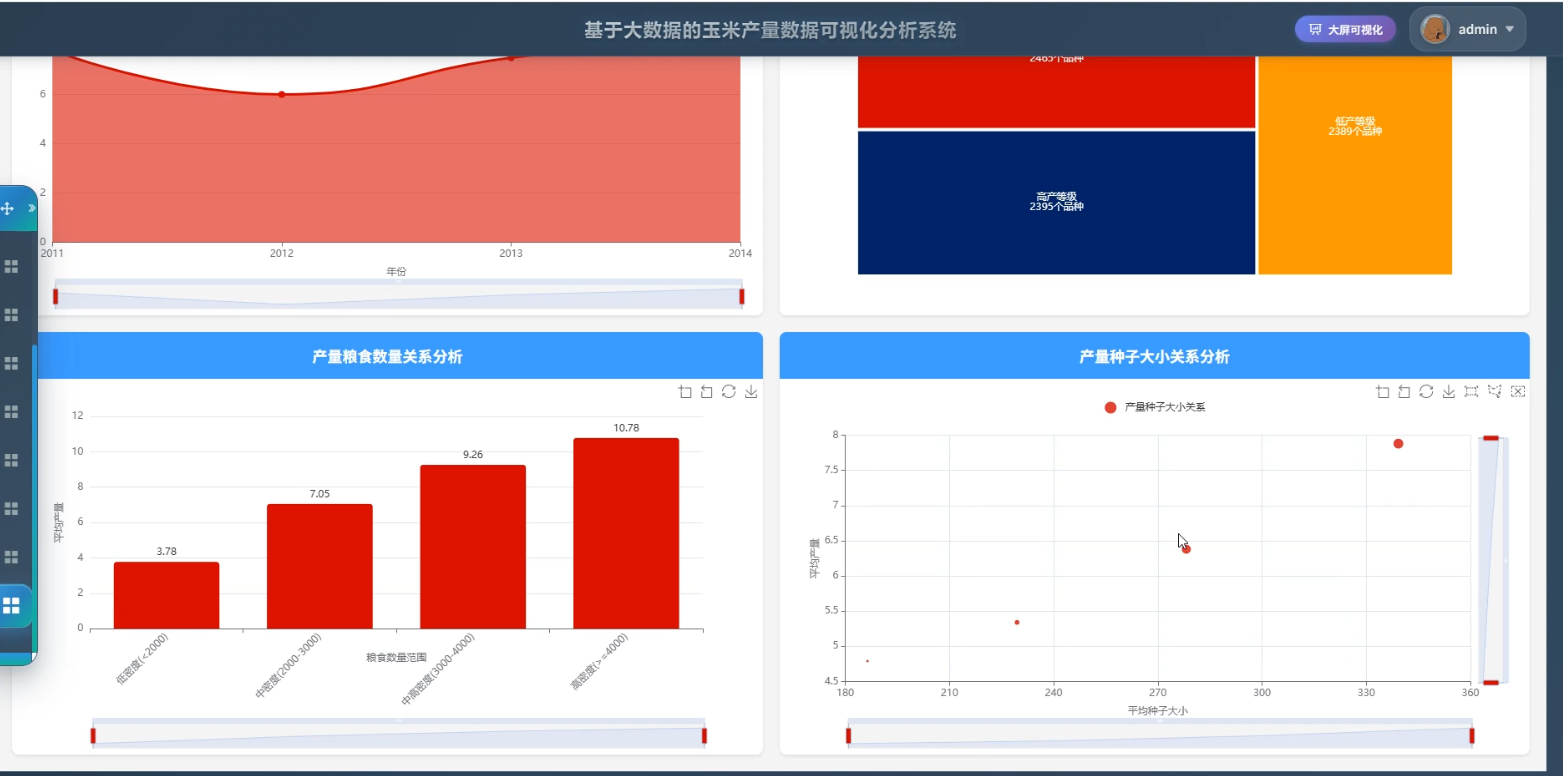
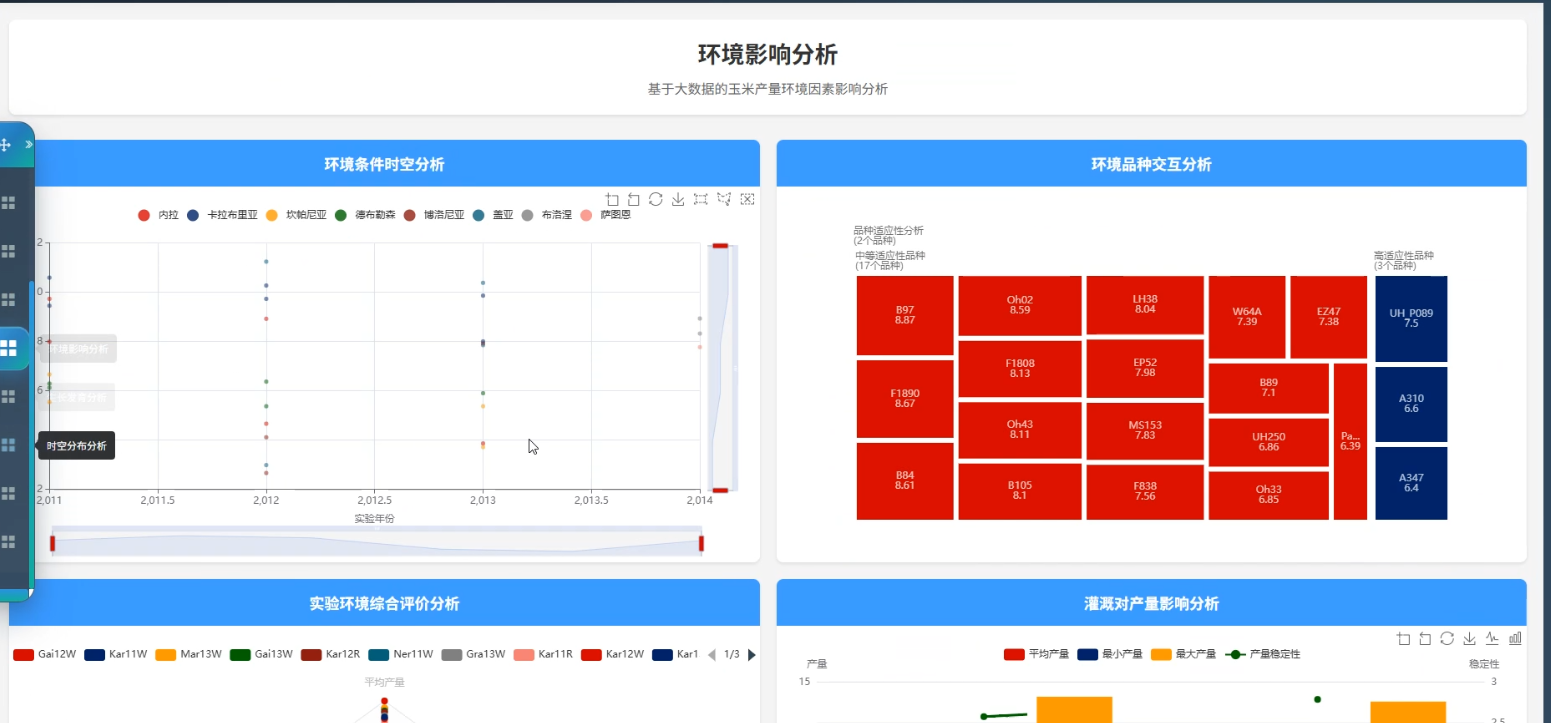
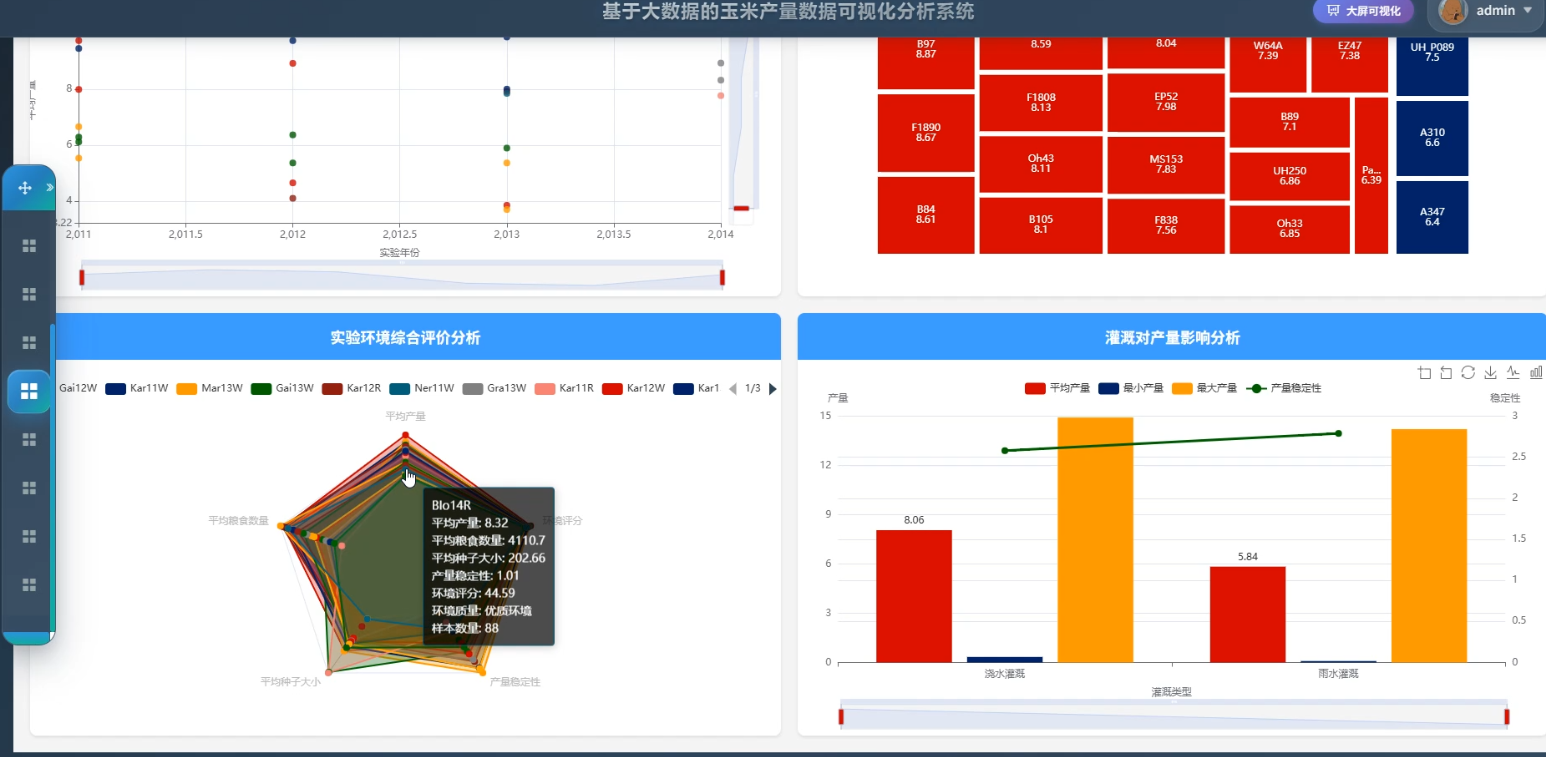
(3)数据可视化:通过Echarts实现玉米产量及环境影响因素的可视化展示,提供趋势图、热力图、柱状图等多种图表形式,帮助用户直观理解数据分析结果。系统支持交互式图表,用户可动态查看不同时间和地区的数据变化。
(4)Web框架搭建:基于Django框架搭建后端,提供数据接口和业务逻辑处理;前端采用Vue框架,构建用户友好的界面。通过前后端分离架构,实现高效的数据交互和界面响应,保证系统的稳定性和扩展性。
(5)系统测试:对系统进行全面的测试,包括功能测试、性能测试和安全性测试。确保系统在数据处理、大数据分析、可视化展示等方面的准确性和稳定性,同时对系统的用户权限管理和数据安全性进行严格审查,防止潜在风险。
3、玉米产量数据可视化分析系统-开发技术与环境
- 开发语言:Python
- 大数据:Hadoop+Spark+Hive
- 数据处理:pandas
- 后端框架:Django
- 前端:Vue
- 数据库:MySQL
- 算法:K-means算法
- 开发工具:Pycharm
4、玉米产量数据可视化分析系统-功能介绍
1、数据管理:信息列表展示。
2、词云图:词云图。
3、可视化分析:玉米产量数据分析、数据质量分析、环境影响分析
4、系统管理:登录注册、个人信息修改。
5、玉米产量数据可视化分析系统-论文参考
6、玉米产量数据可视化分析系统-成果展示
6.1演示视频
6.2演示图片
☀️首页☀️
☀️登录☀️
☀️可视化分析☀️
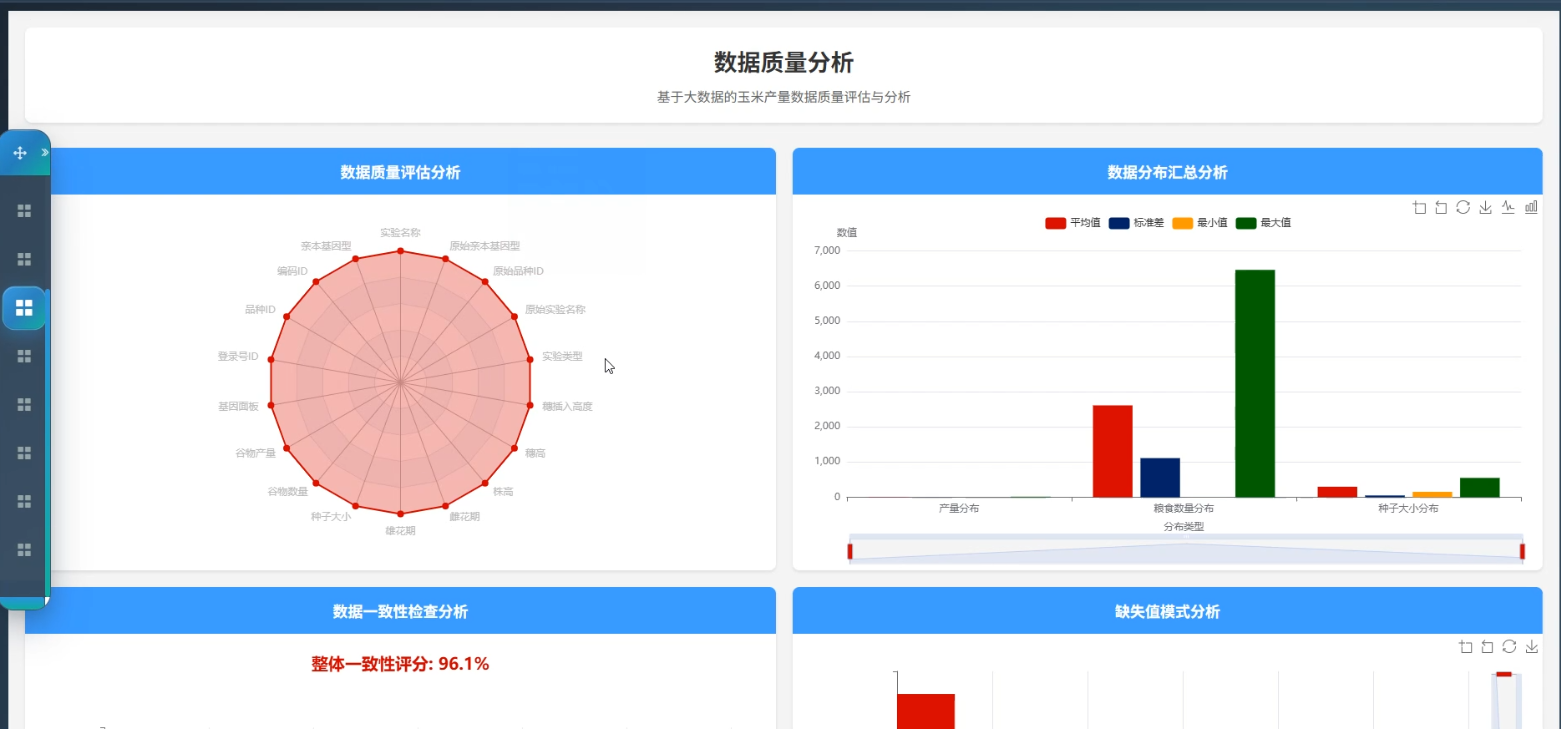
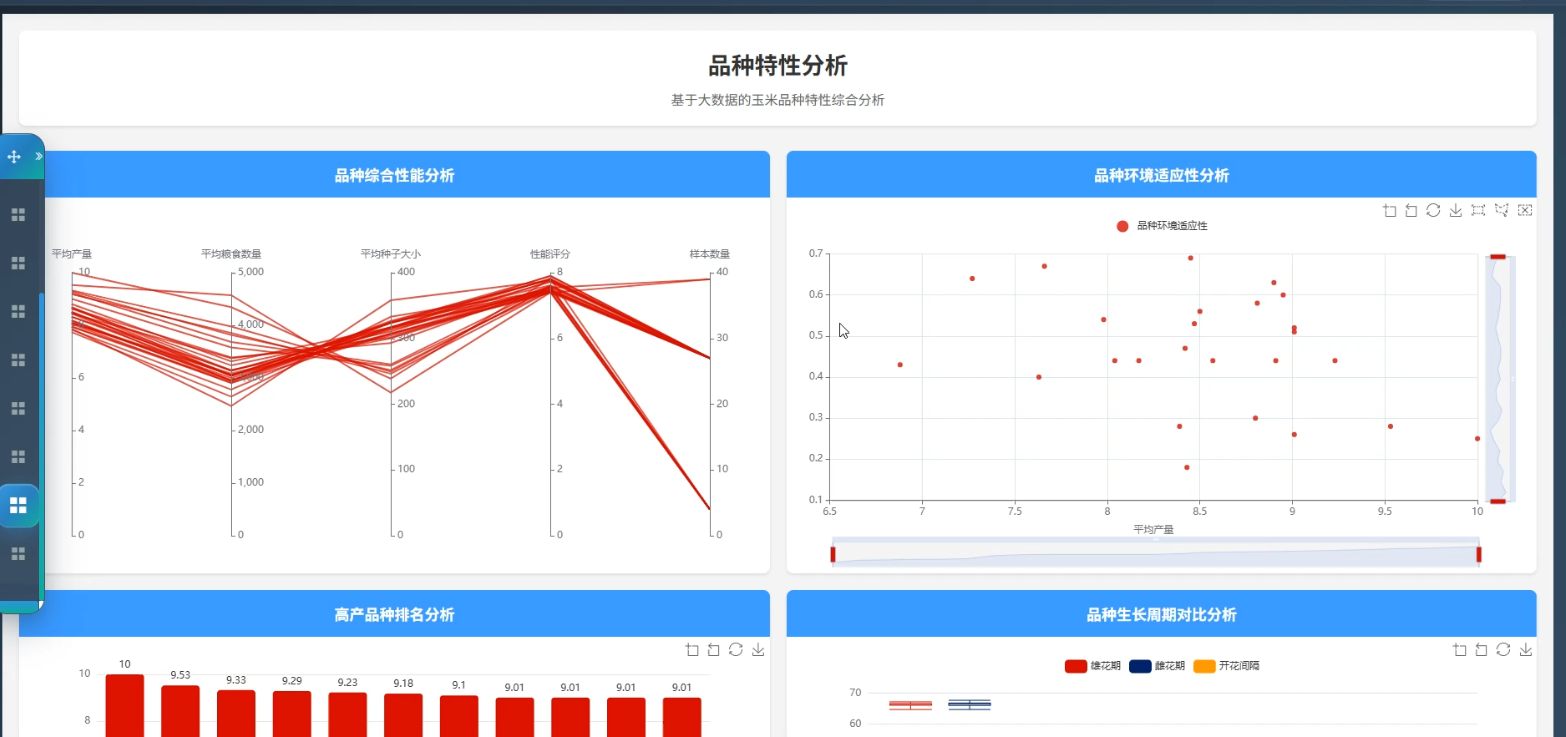
☀️大屏☀️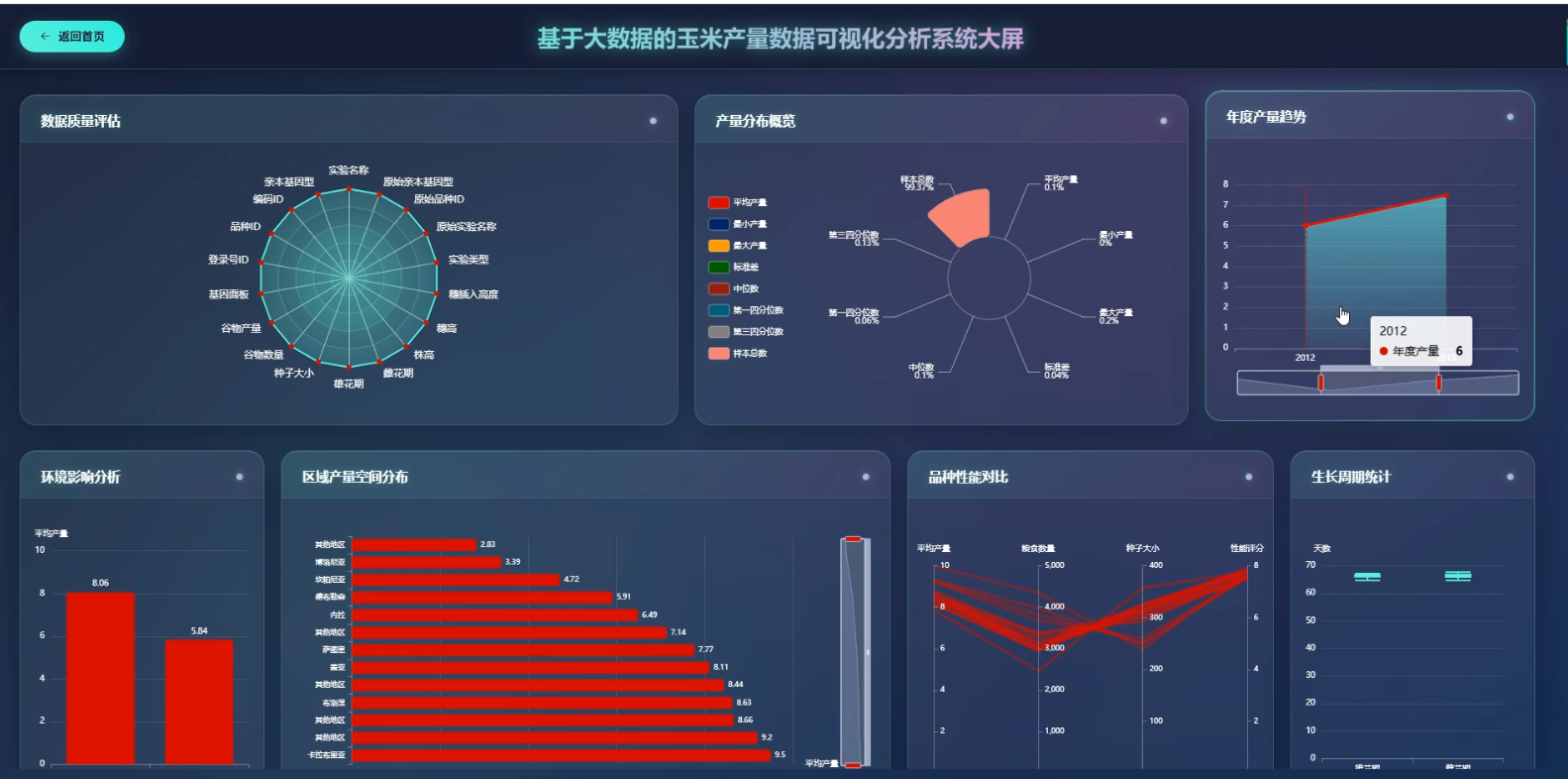
☀️XX数据管理☀️
7、代码展示
1.数据清洗【代码如下(示例):】
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_csv('corn_yield_data.csv')
# 数据清洗函数
def clean_data(df):
# 删除重复数据
df.drop_duplicates(inplace=True)
# 处理缺失值:使用中位数填充数值型数据的缺失值
for column in df.select_dtypes(include=[np.number]).columns:
df[column].fillna(df[column].median(), inplace=True)
# 处理缺失值:使用众数填充分类数据的缺失值
for column in df.select_dtypes(include=[object]).columns:
df[column].fillna(df[column].mode()[0], inplace=True)
# 去除异常值:使用z-score方法去除异常值
from scipy import stats
numeric_cols = df.select_dtypes(include=[np.number]).columns
z_scores = np.abs(stats.zscore(df[numeric_cols]))
df = df[(z_scores < 3).all(axis=1)]
# 日期格式化
df['Date'] = pd.to_datetime(df['Date'], format='%Y-%m-%d')
# 标准化/归一化数据(如有需要)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[numeric_cols] = scaler.fit_transform(df[numeric_cols])
# 将清洗后的数据类型转为适当的类型
df['Region'] = df['Region'].astype('category')
return df
# 清洗数据
cleaned_data = clean_data(data)
print(cleaned_data.head())
# 保存清洗后的数据
cleaned_data.to_csv('cleaned_corn_yield_data.csv', index=False)
2.大数据处理【代码如下( 示例):】
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, max, min, sum
from pyspark.sql.types import StructType, StructField, IntegerType, StringType, FloatType
import time
# 初始化Spark会话
spark = SparkSession.builder.appName("CornYieldAnalysis").getOrCreate()
# 定义数据的Schema
schema = StructType([
StructField("Region", StringType(), True),
StructField("Date", StringType(), True),
StructField("CornYield", FloatType(), True),
StructField("Temperature", FloatType(), True),
StructField("Rainfall", FloatType(), True),
StructField("SoilQuality", FloatType(), True)
])
# 加载数据
start_time = time.time()
data = spark.read.csv("corn_yield_data.csv", header=True, schema=schema)
# 显示数据基本信息
data.show(5)
# 数据清洗
# 去掉包含空值的行
cleaned_data = data.dropna()
# 异常值处理:剔除温度大于100度的记录
cleaned_data = cleaned_data.filter(col("Temperature") < 100)
8、结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python大数据项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)