Spec Kit 大模型规约编程 手把手教程
详细介绍了Spec-Kit工具的应用实践。通过可执行规格文档来约束AI编码过程。实践部分详细记录了Spec-Kit环境搭建过程,包括安装、初始化项目、解决API报错等步骤,并展示了如何使用/speckit.constitution等命令建立项目开发宪法。该工具通过模板填充系统和版本控制机制,将AI生成的代码与明确业务定义绑定,显著提高了代码质量和可维护性。
一、背景
从 Prompt 驱动到 Workflow 约束,AI 编码的下一站在哪里?当「需求规格」成为可执行的开发蓝图,当每一行代码都能追溯到明确的业务定义,我们是否能终结「AI 烂摊子」的收拾循环?
需求文档与代码实现存在鸿沟、AIcoding思路和过程不清晰、存在于一次性的黑盒中,中间产物无法干预。
而spec-kit已经用”可执行规格”的理念,将代码编写转向需求定义。也被称为”需求规格驱动开发”(Spec-Driven Development)
本文将进行spec-kit编码实践、手把手教程演示,亲测生成的代码效果可用率较高,由于敏感性,博主不放实际的需求实践内容。
Vibe Coding的缺陷
程序员通过自然语言驱动 AI 生成代码,确实实现了开发周期缩短 70% 的突破(如 Trae 工具将电商原型开发从 4.5 小时压缩至 8 分钟), 这确实很惊人。但 18 位受访的CTO中的 6位报告了生产环境中的严重 Bug —《凌晨2点查Bug、成天收拾AI“烂摊子”》, 从深层次来说,这些实践暴露了AI编程的三大技术陷阱:
- 上下文腐烂效应:AI 工具的有限上下文窗口导致代码逻辑碎片化。某金融系统因 AI 生成的权限校验逻辑与整体架构冲突,造成已禁用账号仍可访问后台(Cirrus Bridge 案例),结果造成修复耗时超 48 小时。
- 性能悬崖现象:AI 生成的数据库查询在测试环境表现正常,但真实流量下因全表扫描导致 CPU 占用率飙升至 98%(Sketch.dev 案例),印证了 “语法正确≠架构合理” 的行业共识。
- 安全暗门风险:AI 对开源代码的倾向性引用导致供应链攻击面扩大。英国程序员因 GPT 生成代码引用恶意 GitHub 项目,造成私钥泄露损失 1.8 万元人民币,这一事件直接导致了大家对AI编码心存疑虑。
Spec-Driven AI Coding
编程模式演进:从 Prompt 到 Workflow。高准确率的 AI Coding 必须被规则约束。这意味着:
Prompt 有层次、有模板、有约束。
上下文通过工具、接口、数据库动态注入。
工作流可复用、可编排、可监控。
二、Spec Kit 环境搭建并应用在项目中
我使用的是cursor+Spec kit
安装 Spec Kit
GitHub 推荐用 uv 来装:
# 持久化安装(推荐)
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
# 一次性使用
uvx --from git+https://github.com/github/spec-kit.git specify init <PROJECT_NAME>
推荐使用持久化安装,后续在多个项目中使用时也会更方便。
安装完成后,可以用specify check来检查一下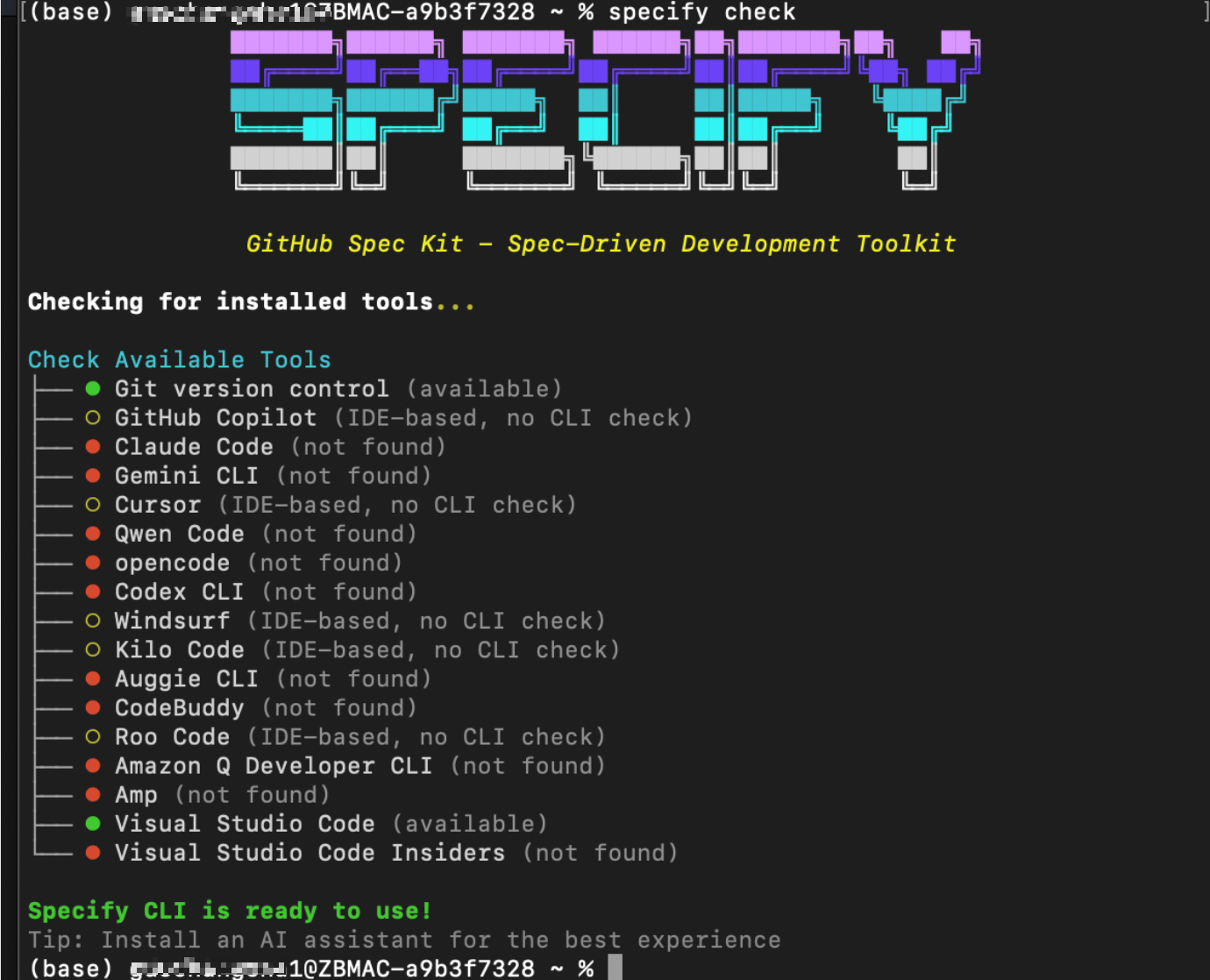
初始化项目
# 创建新项目
specify init my-taskify-app --ai claude
# 也支持已有项目
cd <project-path>
specify init . --ai claude
这里我使用现有的代码库、由于没有claude、在命令中增加后缀
specify init . --ai claude --ignore-agent-tools
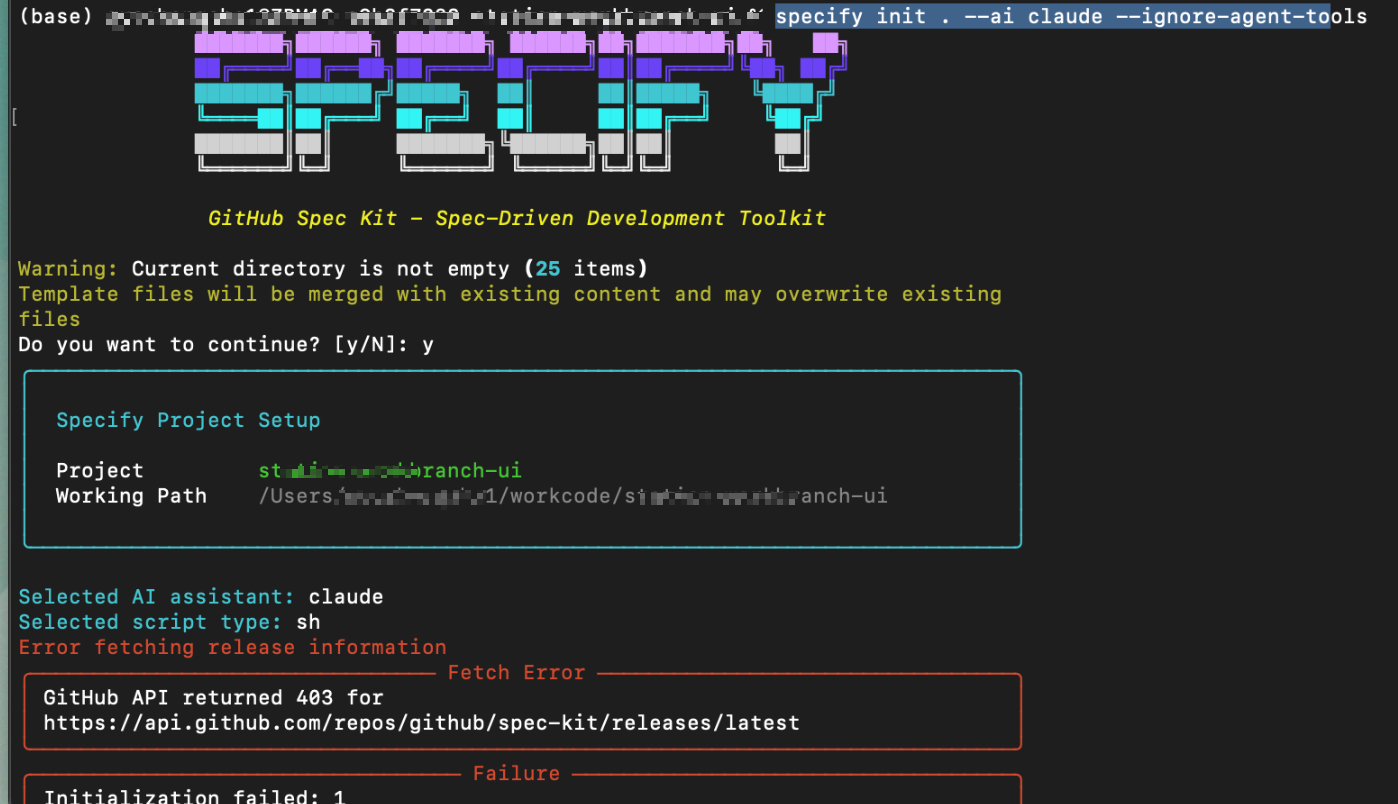
报错+解决方案
Error fetching release information GitHub API returned 403 for https://api.github.com/repos/github/spec-kit/releases/latest
这里官方的issues中给了解决方案
但我的实践方法是使用 https://github.com/settings/personal-access-tokens生成
uvx --from git+ https://github.com/github/spec-kit.git并指定 init . --github-token=xxxxxxxxxx
首先生成 token
然后执行
uvx --from git+https://github.com/github/spec-kit.git specify init . --ai claude --ignore-agent-tools --github-token=xxxxx
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
选择sh
然后提示你有以下sh可执行
1. You're already in the project directory! │
│ 2. Start using slash commands with your AI agent: │
│ 2.1 /speckit.constitution - Establish project principles │
│ 2.2 /speckit.specify - Create baseline specification │
│ 2.3 /speckit.plan - Create implementation plan │
│ 2.4 /speckit.tasks - Generate actionable tasks │
│ 2.5 /speckit.implement - Execute implementation │
│ │
╰──────────────────────────────────────────────────────────────────────────────╯
╭──────────────────────────── Enhancement Commands ────────────────────────────╮
│ │
│ Optional commands that you can use for your specs (improve quality & │
│ confidence) │
│ │
│ ○ /speckit.clarify (optional) - Ask structured questions to de-risk │
│ ambiguous areas before planning (run before /speckit.plan if used) │
│ ○ /speckit.analyze (optional) - Cross-artifact consistency & alignment │
│ report (after /speckit.tasks, before /speckit.implement) │
│ ○ /speckit.checklist (optional) - Generate quality checklists to validate │
│ requirements completeness, clarity, and consistency (after /speckit.plan)
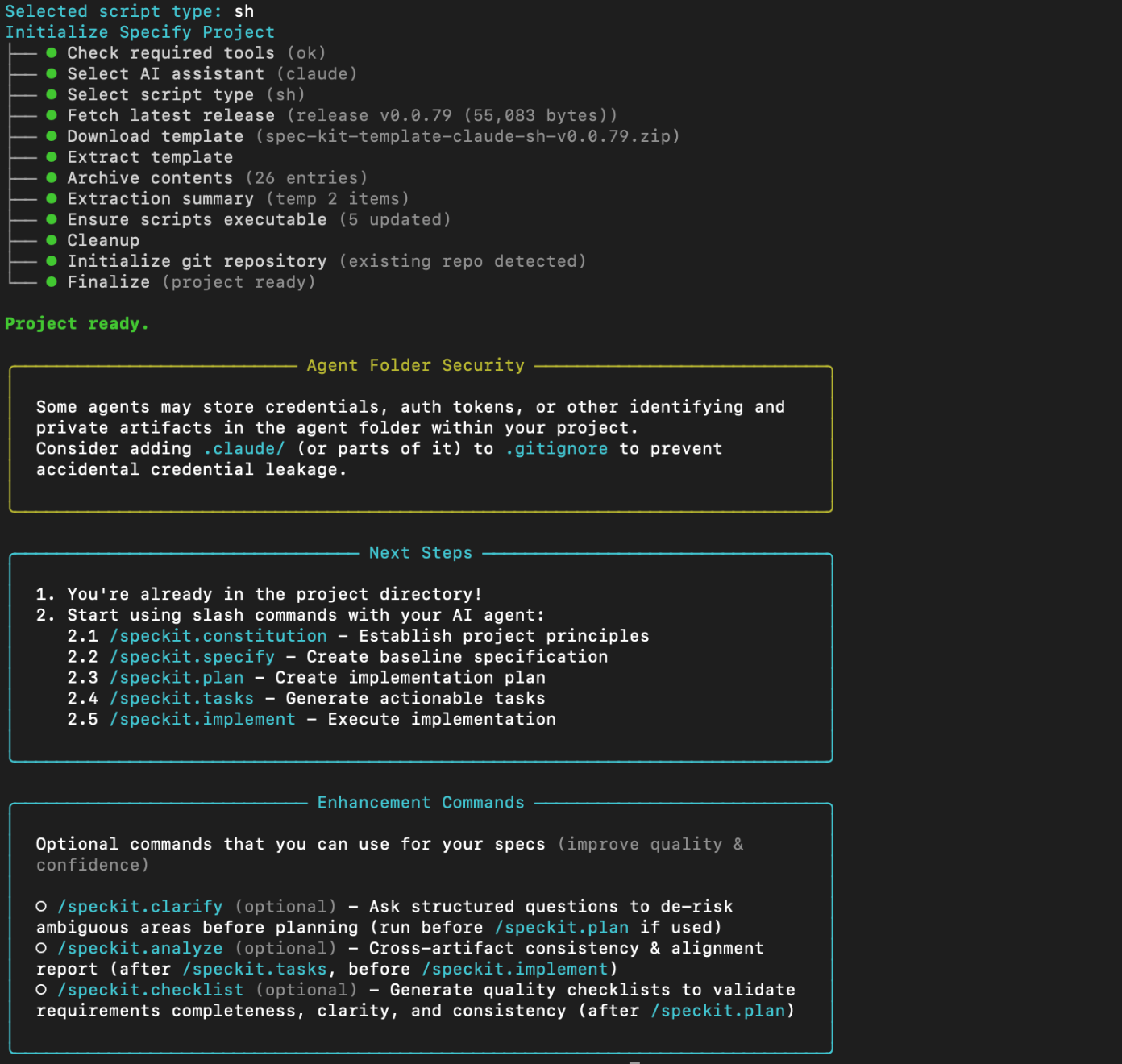
执行成功
你的项目中会初始化这些文件,包含脚本和模版;
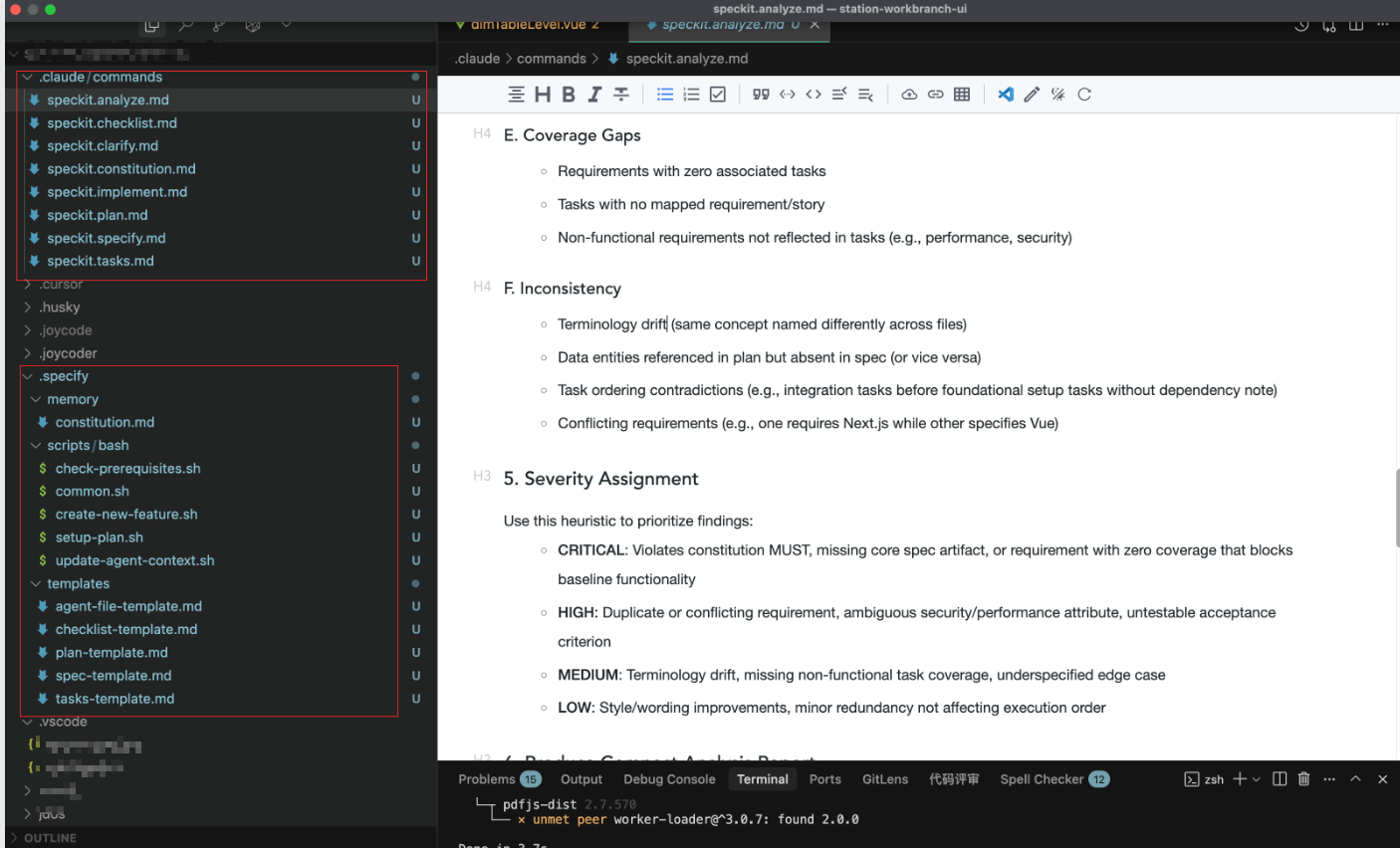
三、如何使用命令?如何管理自己的项目模板?
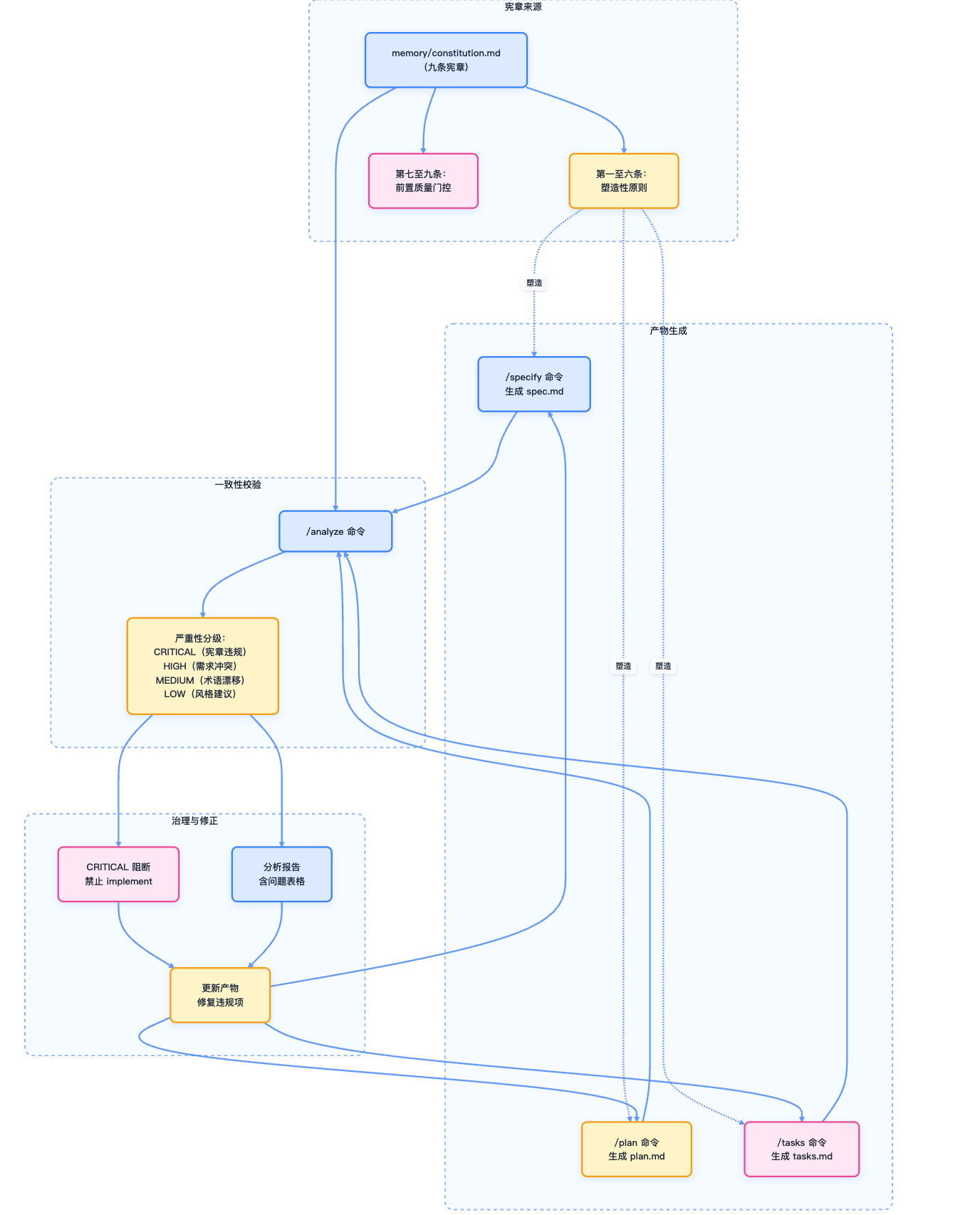
实践
第一步、/speckit.constitution 建立项目开发宪法
用 /constitution 命令建立项目的管理原则和开发指导方针,这些原则将指导所有后续的开发工作。
这个命令实际上是处理一个 模板填充系统。它会:
1、加载 constitution 模板:读取 .specify/memory/constitution.md 中的模板;
2、识别占位符:找到所有 [ALL_CAPS_IDENTIFIER] 格式的占位符,如 [PROJECT_NAME]、[PRINCIPLE_1_NAME] 等;
3、收集具体值:从用户输入、已有仓库上下文、或推断中获取占位符的实际值;
4、版本控制:按语义版本规则自动更新 CONSTITUTION_VERSION(MAJOR、MINOR、PATCH);
5、一致性传播:检查并更新所有相关模板文件,确保新原则在整个工具链中生效;
6、生成同步报告:在文件顶部添加 HTML 注释,记录修改历史和影响的模板。
关键设计:Constitution 不只是一个文档,它是整个工具链的“基本法则”,所有后续命令都必须严格遵守这里定义的原则。比如你在这里定义了“必须使用 TypeScript”,那么后续的 plan 和 tasks 都会自动遵循这个约束。
接下来实践:
我们无需制定rules,指令会自动阅读你的代码工程,生成的项目宪法约定中要求遵循现有项目的rules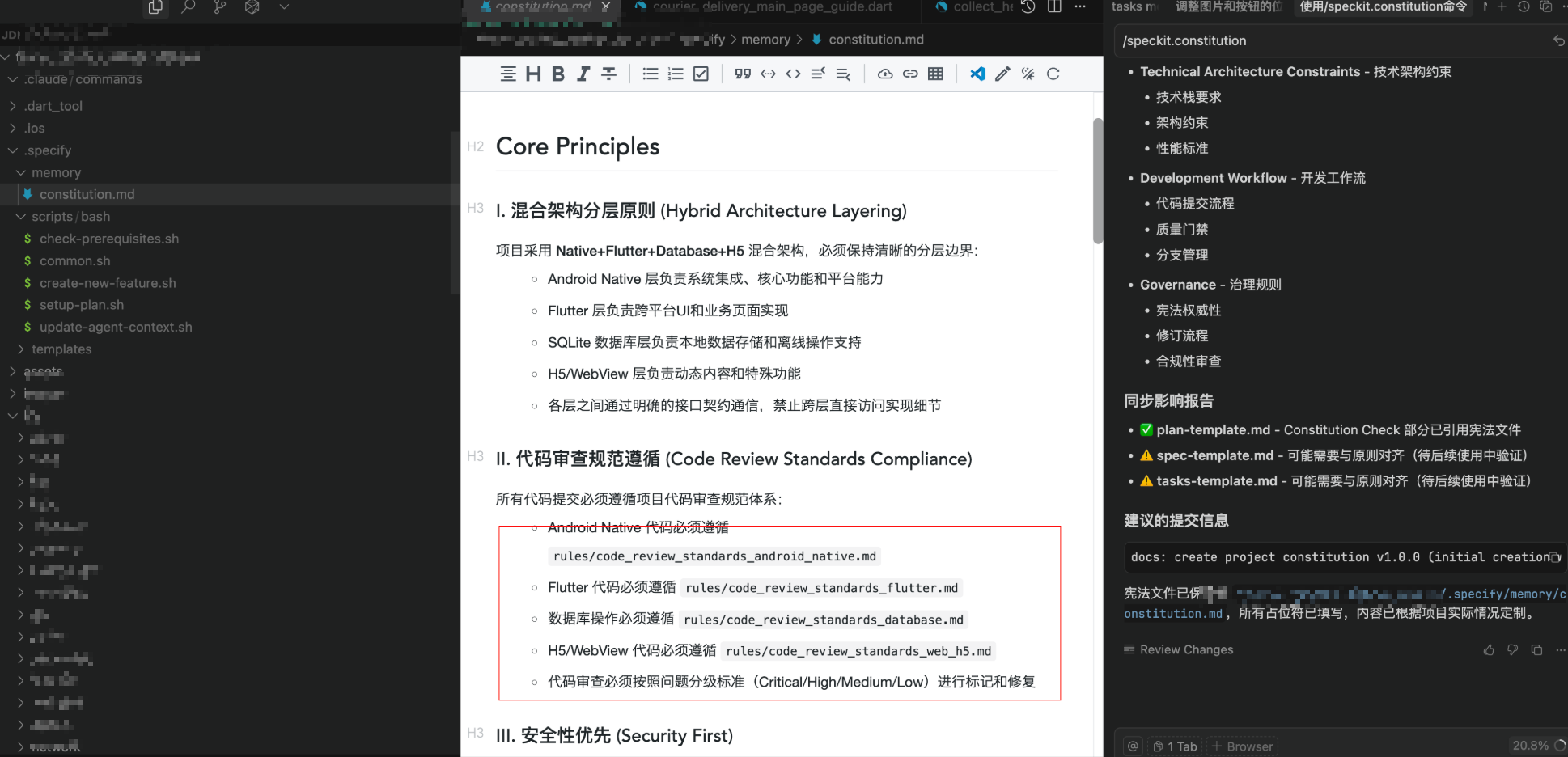
第二步、/speckit.specify 定义功能
接下来是 /specify 命令,用来描述你要构建什么以及为什么要构建。重点关注用户体验需求,即“做什么”和“为什么”,不涉及具体技术栈。
这个命令背后的工作机制是:
1 运行分支创建脚本:执行 .specify/scripts/bash/create-new-feature.sh --json "$ARGUMENTS",创建新的 feature 分支并返回 JSON 格式的分支名和规范文件路径;
2 加载规范模板:读取 .specify/templates/spec-template.md 了解必需的章节结构;
3 智能内容生成:将你的自然语言描述转换为结构化规范,替换模板中的占位符但保持顺序和标题;
4 规范文件写入:在新分支的指定路径创建完整的 spec.md 文件。
关键设计:整个过程只需要运行一次创建脚本。脚本会自动处理 Git 分支切换和文件初始化,然后 AI 在此基础上填充具体内容。
第三步、/speckit.plan 创建代码实现计划
这个命令背后会:
1 环境准备:运行 .specify/scripts/bash/setup-plan.sh --json 获取必要的文件路径;
2 前置验证:检查 feature 规范文件中是否存在 ## Clarifications 章节,如果缺失且存在明显模糊区域,会暂停并要求先运行 /clarify;
3 需求约束分析:解析 feature 规范中的需求、用户故事、验收标准,读取 constitution 了解原则约束,再分析技术约束和依赖关系;
4 模板执行:加载 .specify/templates/plan-template.md 并执行其中定义的流程;
5 分阶段产出:在指定目录生成多个设计文档:
•Phase 0: research.md(技术调研);•
Phase 1: data-model.md、contracts/ 目录、quickstart.md;
•Phase 2: tasks.md(任务分解)。
6 进度跟踪:实时更新 Progress Tracking 确保所有阶段完成。
关键设计:通过可执行的设计模板,规定 AI 严格按照模板中的步骤执行,确保输出的计划具有一致的质量和结构。如果你让 AI 访问其他内部文档,它也可以直接将你的架构模式和标准整合到计划中。
运行命令后、生成的产物大致如下
第四步、/speckit.clarify 反复澄清需求(可选)
在 plan 阶段之前,还有一个重要的可选步骤是 /clarify 命令,用于澄清规范中不够明确的地方。这是在创建技术计划之前的结构化澄清工作流,避免或减少下游的返工,但若定义需求时,没有遗漏或缺失可不使用。
这个命令实现了一个 结构化澄清系统:
1 前置检查:运行 .specify/scripts/bash/check-prerequisites.sh --json --paths-only 获取 feature 目录和规范文件路径;
2 多维度覆盖扫描:对规范进行系统性的模糊性和覆盖度扫描,涵盖功能范围、数据模型、交互、质量、集成依赖等共计 10 个分类。
3 智能问题生成:生成最多 5 个高优先级澄清问题,每个问题都满足下面的条件:
•可以通过多选题(2-5 个选项)或短答案(≤5 词)回答;
•对架构、数据建模、任务分解等有实质影响;
•能显著降低下游返工风险。
4 交互式问答循环:一次只问一个问题,获得答案后立即更新规范文件;
5 增量规范更新:每个答案都会实时写入规范的相应章节,并在 ## Clarifications 部分记录。
关键设计:最多问 5 个问题,确保澄清过程高效且聚焦。如果你想跳过澄清步骤,需要明确说明,否则后续 plan 命令会检查并要求先运行 clarify。
第五步、/speckit.tasks 开发任务拆解
用 /tasks 命令让 AI 将规范和计划分解为实际的工作任务:
这个命令实现了 智能任务分解系统:
1 文档分析:读取所有可用的设计文档:
•plan.md(技术栈和库选择)•data-model.md(数据实体,如果存在)•contracts/(API 端点,如果存在)•research.md(技术决策,如果存在)•quickstart.md(测试场景,如果存在)
2 任务生成规则:
•Setup 任务:项目初始化、依赖管理、代码规范配置;
•Test 任务 [P]:每个 contract 一个测试,每个集成场景一个测试(可并行);
•Core 任务:每个实体、服务、CLI 命令、端点一个任务;•
Integration 任务:数据库连接、中间件、日志记录;
•Polish 任务 [P]:单元测试、性能优化、文档(可并行)。
生成的内容如下:
(可选)/speckit.analyze 一致性检查
在 tasks 生成之后、implement 之前,还可以使用 /analyze 命令进行跨文档的一致性和覆盖度分析。
使用示例:
/analyze
这是一个 非破坏性的质量保证系统:
1 文档解析:分析 spec.md、plan.md、tasks.md,构建语义模型;
2 多维度检测:
•重复检测:识别近似重复的需求,标记低质量表述;•模糊性检测:标记含糊形容词(“快速”、“可扩展”、“安全”)缺乏量化标准;•规格不足:需求缺失可测量结果、任务引用未定义组件;•Constitution 对齐:检查任何与 MUST 原则冲突的需求或计划;•覆盖度差距:零任务覆盖的需求、无需求映射的任务;•不一致性:术语漂移、数据实体引用冲突、任务顺序矛盾。
3 严重性分级:CRITICAL/HIGH/MEDIUM/LOW 等;
4 结构化报告:生成包含问题 ID、分类、严重性、位置、建议的 Markdown 表格;
5 行动建议:基于发现的问题提供具体的修复命令建议。
关键设计:严格只读模式,绝不修改文件。如果发现 CRITICAL 问题,建议在 implement 之前解决,从而确保项目质量。
第六步、/speckit.implement 开始编码
有了完整的规范和任务清单,接下来就是用 /implement 命令让 AI 执行实际开发。
这个命令严格按照设计执行所有任务:
1 全面前置检查:运行 .specify/scripts/bash/check-prerequisites.sh --json --require-tasks --include-tasks 确保所有必需文档存在
2 上下文加载:
•必需文档:tasks.md(任务列表)、plan.md(技术架构)
•可选文档:data-model.md、contracts/、research.md、quickstart.md
3 任务编排解析:
•提取任务阶段(Setup、Tests、Core、Integration、Polish)•识别依赖关系(串行 vs 并行 [P] 标记)•理解文件级协调(同文件任务必须串行)
4 分阶段执行:
•严格 TDD:测试任务在对应实现任务之前执行•依赖尊重:串行任务按序执行,并行任务可同时运行•文件级同步:影响同一文件的任务串行化•阶段验证:每个阶段完成前进行检查点验证
5 进度跟踪和错误处理:
•每完成一个任务就在 tasks.md 中标记为 [X]•非并行任务失败时停止执行•并行任务失败时继续其他成功任务,报告失败任务•提供具体错误上下文用于调试
完成验证:
•验证所有必需任务完成•检查实现功能与原始规范匹配•确认测试通过和覆盖率要求•生成最终状态报告
关键设计:严格遵循设计规范和任务清单,确保 AI 按照预定义的约束开发任务。
而后我们看见代码已经生成、接下来人工的根据需求、结合后台提供的接口进行联调验证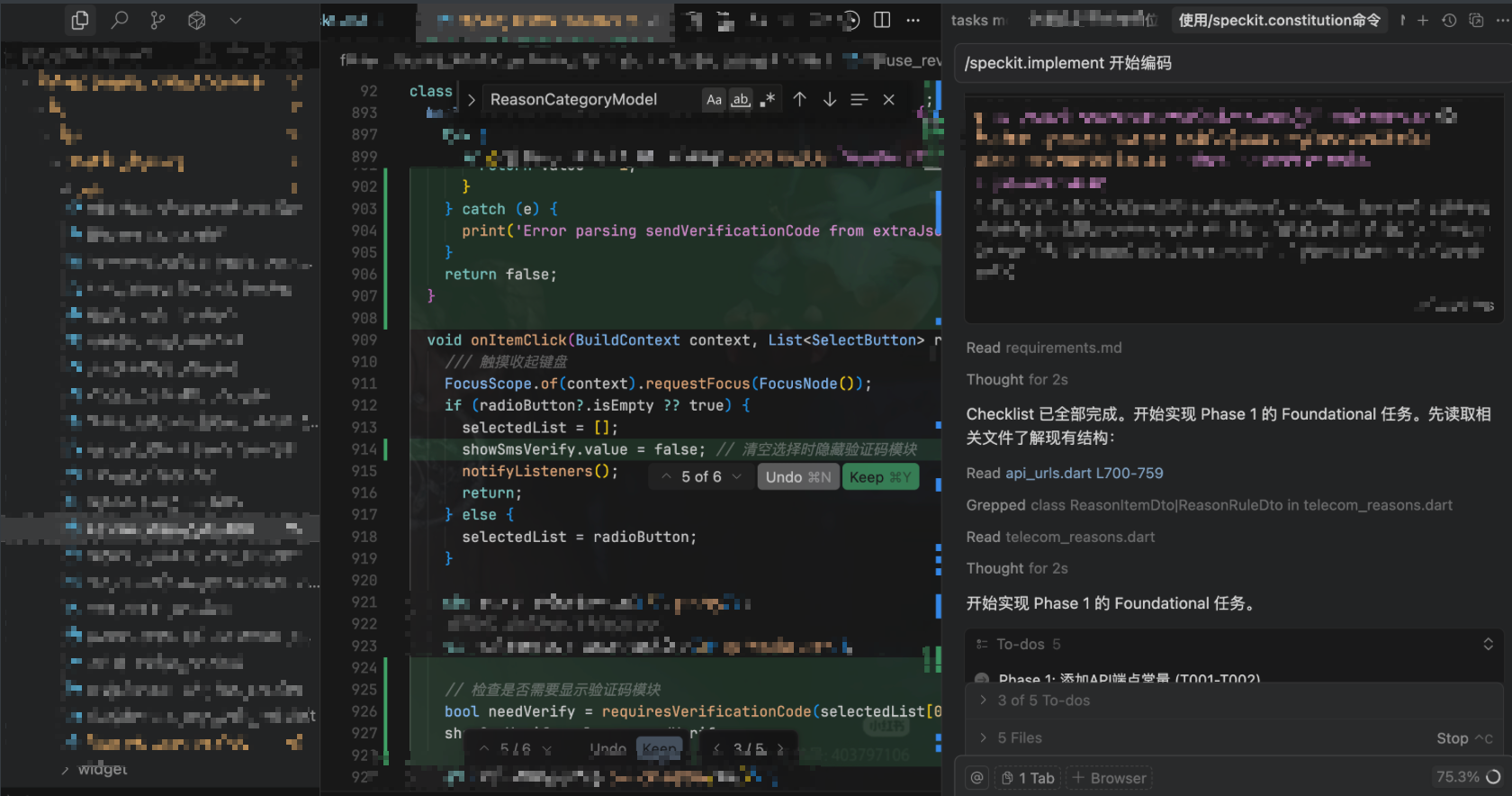
附录:
如果第一次代码生成完,发现缺少逻辑怎么办?重新从头生成才行嘛?
no:只需要从第三步开始继续澄清需求、而后走到编码阶段,会根据task中新增的模块进行编码,而非全部重写
当我选择claude-4.5-sonnet模型时,使用/speckit.clarify 可以直接从澄清需求到代码实现

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)