目标检测模型学习(1)
·
两阶段目标检测方法
Two Stage:第一阶段为区域建议(Region Proposal, RP),即图像中可能包含目标的预选框,通常由一组边界框坐标和置信度分数组成。第二阶段是分类和回归,即对第一阶段生成的可能的区域进行分类(目标或背景),以及对边框进行回归,得到更准确的边框。
- 获得RP的方法
(1)传统方法:
- 选择性搜索(SS)(类似层次化聚类):基于图像特征的层次化区域合并,生成多尺度候选框。先将图像分割为较小的区域(可小到单像素),然后计算区域的相似度(有不同维度评价相似度的指标),迭代合并相似度最高的区域对,直到覆盖整个图像。
- EdgeBoxes:基于图像边缘信息预测物体可能位置
- Randomized Prim、CPMC等
(2)深度学习方法:(Region Proposal Network,RPN)参考论文:Faster R-CNN
RPN搭建的网络结构如下:
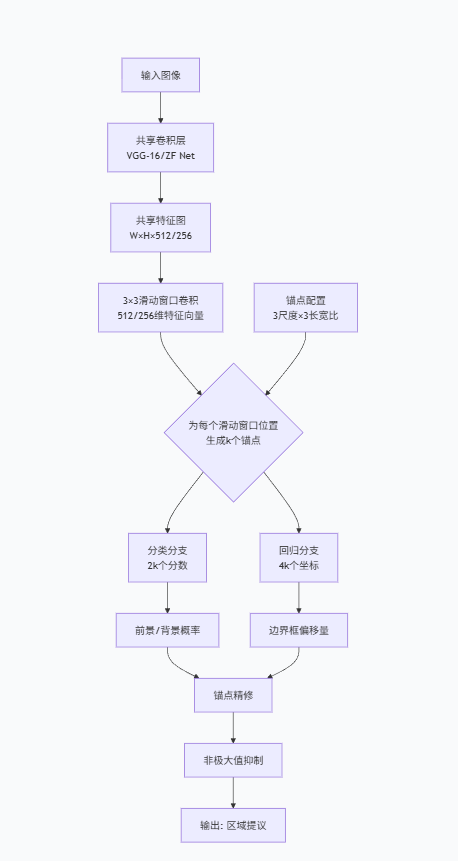
- 3*3滑动窗口卷积的作用是模拟将图像用于分类的特征转化为用于目标检测的特征,因为所用的VGG-16提取的特征是用于分类任务的
- 有关锚点配置:锚点指的是预先定义大小和长宽比的参考边框。Faster R-CNN中用的3个尺度为128², 256², 512²,所用的3个长宽比是1:1,1:2,2:1,所以在每个像素作为中心点处共有9类锚点。锚点的尺寸与长宽比针对的是原图像而非特征图。
- 计算分类分支和回归分支时使用的都是1*1卷积层,通道数分别为2k和4k。对于分类分支,每个通道的输出代表第k种锚点对应于目标或背景的概率,相当于2k个线性分类器,每个线性分类器将学习独属于自己的锚点的相应权重。对于回归分支,每个通道的输出代表第k种锚点对应的相对于锚点中心的偏移量t_x(边界框相对于中心的x方向的偏移量), t_y(边界框相对于中心的y方向的偏移量), t_w(宽度比的对数), t_h(高度比的对数),除以锚点的宽度和长度以归一化,取对数可以使得数据较为对称;
- 锚点精修:计算公式为t_x = (G_x-C_x)/C_w, t_y = (G_y - C_y)/C_h, t_w = log(G_w / C_w), t_h = log(G_h / C_h), 更新边界框的公式为 G_x = C_x+C_w*t_x , G_y = C_y+C_h*t_y , G_w = C_w * e^t_w, G_h = C_h * e^t_h .
- 关于样本分配问题:由于在图像中目标的面积一般较小,大部分都为背景,则会导致生成的所有锚点中负样本占了绝大多数,因此需要对样本做一些处理。本文中选择的方式是选择与某个真实框IoU(交并比) > 0.7的锚点和与真实框有最大IoU的锚点(即使IoU < 0.7)作为正样本,选择与所有真实框IoU < 0.3的锚点作为负样本,对于IoU在[0.3, 0.7]之间的锚点选择忽略。
- 损失函数的选择:本文中选择的损失函数为一个多任务组合函数,将分类任务与回归任务组合起来。
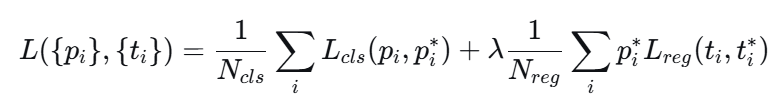
其中前一项为分类任务的损失,其中Ncls为归一化参数,为类别的总数,Lcls为二分类交叉熵损失函数。![]()
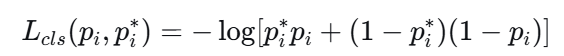
第二项为回归任务的损失,𝑝𝑖∗保证了只对正样本计算回归损失,其中Nreg为归一化参数,为锚点的数量,Lreg为smooth L1函数,λ为平衡权重,可以使得模型对于两种任务的注意力大致平衡,常设为10,因为回归任务的损失通常比分类任务小一个数量级。
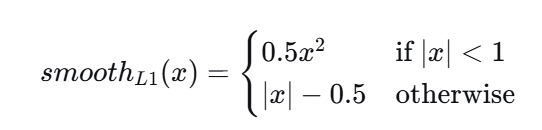
- 非极大值抑制(Non-Maximum Suppression,NMS):将精修后的锚点按对应于目标的概率降序排列,然后依次对每个精修锚点计算与最高分锚点的IoU,若IoU > 0.7,表示这两个锚点很可能对应的是同一个目标,则对其抑制,否则保留。经过NMS后可以输出高质量的候选区域建议。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)