基于网络摄像头的 CNN 模型进行实时注视估计进行人机交互Python实现
·
摘要
眼动跟踪和估计对于理解人类行为和增强人机交互至关重要。本研究介绍了一种使用标准网络摄像头进行实时注视跟踪的创新、经济高效的解决方案,为依赖昂贵的红外 (IR) 相机的传统方法提供了一种实用的替代方案。传统方法,如瞳孔中心角膜反射 (PCCR),需要红外相机来捕捉角膜反射和虹膜闪光,需要高分辨率图像和受控环境。相比之下,所提出的方法利用在网络摄像头捕获的图像上训练的卷积神经网络 (CNN) 来实现精确的注视估计。开发的深度学习模型通过一种新的基于轨迹的精度评估系统,实现了 0.0112 的均方误差 (MSE) 和 90.98% 的精度。该系统涉及球在屏幕上移动的动画,用户的视线跟随球的运动。准确性是通过根据球的半径计算落在预定义阈值内的注视点的比例来确定的,从而确保全面评估系统在所有屏幕区域的性能。数据收集既简单又有效,当用户专注于屏幕时捕获右眼的图像。此外,该系统还包括高级凝视分析工具,例如热图、凝视注视跟踪和眨眼速率监控,这些工具都集成到一个直观的用户界面中。通过整合 Google 的 Mediapipe 模型进行面部特征点检测,进一步增强了这种方法的稳健性,从而提高了准确性和可靠性。评估结果表明,所提出的方法无需昂贵的设备即可提供高精度的注视预测,使其成为人机交互和行为研究中各种应用的实用且易于使用的解决方案。
关键词:
眼动追踪;美国有线电视新闻网(CNN);凝视估计
1. 引言
在计算机视觉和人机交互领域,注视估计旨在根据面部或眼睛图像确定一个人的视线位置。这项技术有多种应用,包括虚拟现实 [1]、市场研究 [2] 和残障人士辅助技术 [3]。传统上,眼动估计依赖于专用硬件,例如红外相机,这些硬件既昂贵又笨重,使其只能在受控的实验室环境中使用。这项研究通过开发由卷积神经网络 (CNN) 提供支持的基于网络摄像头的凝视跟踪系统来解决这些挑战。动机在于创建一种经济实惠、可访问且用户友好的传统系统替代方案。通过利用 CNN,这种方法使用标准网络摄像头有效地提取凝视信息,从而显著降低成本和设置复杂性。这种创新方法还强调包容性、实时处理和适应性,使其适用于从辅助技术到人机交互的各种应用,同时优先考虑道德和实际考虑。
1.1. 问题域的一般概述
近年来,眼动追踪技术已成为增强可访问性、改善用户交互和深入了解人类行为的强大工具。虽然传统的眼动追踪系统具有高精度,但它们通常存在一些重大缺点,例如成本高和可访问性有限。因此,这些系统仍然未得到充分利用,尤其是在经济性和易用性至关重要的面向消费者的应用中。
深度学习的出现,尤其是卷积神经网络 (CNN),改变了计算机视觉,能够更快、更准确地处理视觉数据。通过利用 CNN,现在可以使用标准网络摄像头创建凝视跟踪模型。眼动追踪的普及在各个领域开启了许多新的应用和机会。
尽管基于网络摄像头的凝视跟踪前景广阔,但要成功集成到更广泛的应用程序中,必须解决一些挑战。关键问题包括以下小节中列出的问题。
1.1.1. 法律和道德问题
隐私问题:眼动追踪涉及捕获敏感数据,包括用户的注意力、兴趣和认知模式。收集和使用此类数据会引发严重的隐私问题,尤其是在面向消费者的应用程序中,用户可能无法完全了解所记录数据的范围。
数据安全:确保凝视数据的安全性对于防止滥用或未经授权的访问至关重要。强大的数据保护措施和遵守隐私法规(例如《通用数据保护条例》(GDPR))对于解决这些问题至关重要。
1.1.2. 社会和道德问题
偏差和包容性:基于 CNN 的模型可以继承其训练数据集中存在的偏差,从而导致不同种族、眼型或有视力障碍的用户的眼动估计不准确。解决这些偏见对于确保该技术对所有用户公平和包容至关重要。
对用户行为的影响:消费者应用程序(如广告或社交媒体)中使用的眼动追踪技术可以创建微妙影响用户行为的纵策略。这引发了对在商业环境中滥用眼动数据的道德担忧,这可能导致剥削行为。
1.1.3. 经济影响
基于网络摄像头的眼动追踪的采用解决了眼动估计中与成本相关的挑战,使该技术更容易用于研究和商业应用。通过减少对专用硬件的依赖,这种方法提高了可负担性,使其能够在医疗保健、营销和游戏等领域得到更广泛的采用。这种转变促进了创新,并支持经济高效的实时凝视跟踪解决方案。
1.1.4. 商业风险和风险管理
技术限制:基于网络摄像头的系统可能面临挑战,例如在弱光环境下或跟踪快速眼球运动时精度降低。这些限制可能会阻碍它在需要高精度的领域的采用。
市场接受度: 对基于网络摄像头的眼动追踪的准确性、可靠性和隐私性的担忧可能会导致用户和行业犹豫不决。为了降低这些风险,必须进行全面测试和透明地传达该技术的优势。
通过应对这些挑战,基于 CNN 的网络摄像头凝视跟踪的开发有可能彻底改变该领域,使其更易于访问、更实惠并适用于广泛的领域。
为了解决人体实验和数据收集的道德和法律问题,所提出的方法结合了注重隐私的设计原则。通过利用基于网络摄像头的凝视跟踪,避免了侵入性的硬件设置,这种方法最大限度地减少了用户的不适并促进了透明度。参与者充分了解数据收集过程,并在遵守道德准则的情况下获得明确同意。此外,所有数据都是匿名和安全存储的,确保遵守 GDPR 等隐私法规。该方法还通过解决 CNN 模型中的潜在偏见来关注包容性,确保公平对待不同的用户人口统计数据,包括有视觉障碍的用户。
1.2. 眼动估计的应用重要性
视线估计是一项变革性技术,其应用涵盖辅助工具、数字交互和消费者行为分析。对于残障人士,它实现了对设备和软件的免提控制,从而提高了可访问性和独立性 [3,4]。在游戏和虚拟现实中,凝视跟踪通过促进用户焦点驱动的自然交互来增强沉浸感 [5]。
在这些领域之外,眼动估计通过提供对消费者注意力的可行洞察,正在彻底改变营销、销售和广告。实时眼动数据允许广告商创建个性化、自适应的广告内容,优化其投放和设计,以实现最大的相关性和参与度 [6]。在销售中,视线跟踪通过根据视觉焦点提供上下文相关的产品信息或优惠来改变购物体验,从而提高转化率。此外,它还提供无与伦比的消费者行为分析,识别哪些广告元素吸引了注意力并将参与度与购买决策联系起来。
将多功能、经济高效的眼动估计系统集成到数字营销策略中,使企业能够增强消费者参与度、提高广告效果并推动销售增长。从辅助技术到商业应用,眼动估计继续为各行各业带来创新机会,在可访问性、交互性和消费者洞察之间架起桥梁。
2. 相关工作
眼动追踪在推进人机交互 (HCI) 和行为研究方面发挥着至关重要的作用。传统方法,如瞳孔中心角膜反射 (PCCR),依赖于昂贵的红外 (IR) 摄像头和受控环境。这些系统虽然精确,但成本高昂且不适合广泛使用。
2.1. 凝视跟踪方法
Zhu 和 Ji [7] 开发了一种能够自然头部运动的注视追踪系统。这项创新标志着朝着更灵活和用户友好的解决方案迈出了重要一步,表明无需用户保持静止即可进行准确的眼动估计。这一进步为凝视跟踪的动态应用铺平了道路。
同样,Macinnes 等人 [8] 探索了可穿戴眼动追踪设备,比较了它们的精度和准确性。他们的研究结果强调了设备移动性和跟踪性能之间的权衡,强调了在不依赖专用硬件的情况下保持高精度的技术的必要性。这项研究强调了对能够在不同条件下有效运行的可访问眼动追踪解决方案的需求。为了应对这些挑战,所提出的方法与传统的基于 IR 的技术不同,提供了一种采用标准网络摄像头和 CNN 的经济实惠且用途广泛的替代方案。
Wood 等人 [9] 通过他们基于外观的眼动估计器为这一领域做出了贡献,该估计器利用了 100 万张合成图像的数据集。他们的工作强调了数据多样性在训练 CNN 进行凝视估计方面的重要性。然而,他们对合成数据集的使用对在实际场景中实现高精度构成了挑战。他们的研究侧重于受控环境,限制了其在包含自然头部运动的动态环境中的适用性。尽管该数据集在解决训练数据的稀缺性方面具有开创性,但它并没有完全解决与不同条件下的泛化相关的问题。
在这些进步的基础上,Krafka 等人 [10] 推出了一种专为移动设备设计的注视跟踪系统,利用众包数据来捕获更广泛的真实场景。这种方法通过结合不同的环境条件,显著提高了凝视跟踪模型的泛化性。然而,该系统受到对特定头部位置的依赖的限制,并且难以处理自然环境中常见的头部自由运动。虽然包含更大、更多样化的数据集增强了模型的稳健性,但移动设备之间相机质量的差异导致了眼动估计的不一致。
邓和朱[11]通过引入单目3D凝视跟踪系统来应对自由头部运动的挑战。他们的深度学习模型结合了几何约束,以提高自然头部运动条件下的凝视估计准确性,代表了凝视跟踪在现实和实际应用中的重大进步。但是,该系统需要大量的计算资源,因此在标准消费类设备上实时使用的可能性较小。虽然几何约束的引入具有创新性,但它增加了模型的复杂性,从而限制了其在资源受限环境中的适用性。
基于这些发展,Liu等[12]提出了一种基于外观的眼动估计方法,该方法针对头部自由运动和移动设备进行了优化。他们的方法通过根据移动硬件的计算限制定制模型来改进邓和朱[11]的工作。尽管如此,模型复杂性和效率之间的权衡导致准确性略有下降。该研究将视线追踪扩展到更实际的应用,但仍然面临挑战,例如在不同的照明条件和设备类型下保持高精度。
Chen等[13]探讨了不同的深度网络架构对基于CNN的眼动跟踪的影响,对它们的准确性和计算效率进行了比较分析。这项研究为为特定的注视跟踪需求选择合适的架构提供了指南。然而,Chen et al. [13] 并没有提出一种新的注视跟踪系统,而是专注于优化现有模型。他们的发现强调了平衡准确性和实时性能的重要性,尤其是在资源有限的环境中。
Kanade等[14]提出了一种基于CNN的眼睛凝视跟踪系统,旨在提高驾驶员的安全性。他们的系统利用机器学习算法在具有挑战性的条件下准确预测眼睛凝视,在这种特定应用中展示了高精度和高效性。然而,它对其他人机交互 (HCI) 上下文的普遍适用性是有限的。该模型对基于 Web 的应用程序进行了优化,在应对更广泛的挑战方面留下了差距,例如照明和摄像机角度等环境条件的变化。
Ansari等[15]介绍了一种凝视跟踪系统,该系统利用未经修改的网络摄像头和CNN,旨在通过消除对专用硬件的需求,使凝视跟踪更容易获得。这种方法标志着凝视跟踪技术民主化的重要一步,但由于标准网络摄像头的限制,它在实现高精度方面面临限制。这些设备提供的较低图像质量影响了系统的精度,使其不太适合要求苛刻的应用。尽管如此,这项研究代表了在可访问性和性能之间取得平衡的值得称道的努力,强调了进一步创新以提高准确性和实用性的必要性。
Singh 和 Modi [16] 通过创建一个由深度学习提供支持的强大的基于实时摄像头的系统,提高了凝视跟踪的可访问性。他们的系统旨在高精度地分析用户的视觉注意力,展示了其适用于各种应用的适用性。通过增强不同环境条件下的稳健性,该研究解决了早期方法中的局限性。所使用的 CNN 架构展示了性能的显著改进。然而,对相对高质量摄像头的依赖阻碍了更广泛的采用,尤其是在只有标准网络摄像头可用的情况下。
Narayana Darapaneni等[17]探讨了CNN在眼动追踪分析中的应用,重点关注教育和培训环境。他们的系统优先考虑准确性和效率,使其非常适合实时使用。尽管有这些优势,但该研究主要在受控环境中进行,这限制了其在更动态的真实环境中的适用性。这项工作强调了进一步创新的必要性,以提高凝视跟踪系统的适应性和泛化性。
Donuk et al. [18] 开发了一种专为网络挖掘应用量身定制的实时眼动追踪系统,利用 CNN 实现高精度。他们的研究强调了将凝视跟踪用于专业应用的潜力,尤其是在 Web 挖掘中。但是,与许多系统一样,它受到对高质量输入数据和受控测试环境的要求的限制。虽然该研究为利基用途提供了有价值的见解,但它并没有解决将凝视跟踪技术扩展到多样化且控制较少的领域的更广泛挑战。
2.2. Gaze Tracking 的应用
Zhang et al. [19] 率先使用眼动追踪来分析观众对视频广告的参与度。通过检查注视时间和焦点,他们的系统提供了对消费者注意力和偏好的更深入理解。这项基础研究帮助广告主确定了其广告中最吸引人的元素。然而,对基于硬件的眼动追踪设备的依赖限制了可访问性和可扩展性,使该系统的广泛使用不太实用。
在此基础上,Lee et al. [20] 引入了一种凝视数据可视化系统,通过将凝视模式映射到特定的广告元素上,可以对用户参与度进行更精细的分析。尽管采用了创新的方法,但该研究也存在类似的局限性,因为它需要专门的设备和受控环境。此外,它主要关注静态内容,而视频广告的动态性质在很大程度上没有得到解决。
Okano 和 Asakawa [21] 通过分析消费者对网络广告和电视广告中产品信息的关注度,弥合了这一差距。他们的研究表明,不同的媒体形式会显著影响消费者的看法和产品信息的保留率,这强调了情境在广告中的重要性。然而,缺乏机器学习技术限制了他们从眼动数据中提取更深入见解的能力。
Zhang和Yuan [22]扩展了这些发现,对视频广告进行了全面分析,将特定的广告元素与其效果相关联。这项研究为优化内容提供了可作的见解,但仍然依赖于传统硬件,使其成本高昂。此外,他们的工作侧重于描述性分析,而没有探索预测建模。
Muñoz-Leiva等[23]对眼动追踪在营销中的应用进行了主题分析,确定了新出现的趋势和研究差距。他们强调,缺乏利用深度学习来提高眼动追踪的准确性和效率的研究,尤其是在动态广告环境中。他们的工作强调了将眼动追踪与机器学习相结合用于实时应用的潜力。
Modi 和 Singh [24] 通过使用标准网络摄像头开发基于 CNN 的实时凝视跟踪系统来应对其中一些挑战。这项创新消除了对专用硬件的需求,使该技术更易于访问和扩展。虽然他们的研究侧重于社交媒体应用,但它为在更广泛的营销和广告环境中应用 CNN 奠定了基础。
Onwuegbusi等[25]探讨了暴露于赌博和非赌博广告的年轻观众的注视行为。他们的研究强调了了解各种广告类型如何吸引注意力的重要性,从而为监管政策提供了宝贵的见解。使用深度学习技术可以提高他们分析的粒度和准确性。
Xie等[26]通过将机器学习整合到移动广告的眼动跟踪中,推动了该领域的发展。他们的动态眼动追踪研究提高了消费者注意力分析的精度,强调了机器学习在动态和现实世界环境中的相关性。
最后,Tsubouchi等[27]介绍了一种在智能手机上进行个性化网络广告的创新方法,使实时广告与用户的目光保持一致。这个新颖的应用程序展示了凝视跟踪改变定向广告的潜力。然而,该研究仅限于智能手机,并没有充分利用 CNN 来提高跟踪准确性或探索它们在其他广告媒体中的应用。
2.3. 超越技术水平
拟议的研究旨在通过使用标准网络摄像头和 CNN 开发一种经济实惠的实时注视跟踪系统来解决传统眼动追踪方法的局限性。传统的眼动追踪系统通常依赖于专门的硬件和受控环境,这限制了它们的可访问性和可扩展性。此外,基于 CNN 的眼动跟踪在营销和广告中的应用仍未得到充分探索。拟议的系统通过整合凝视热图、注视分析和眨眼率检测等功能来增强实时凝视分析,从而更深入地了解消费者行为。通过将这些高级功能与 CNN 的实时处理功能集成,该系统为营销人员和广告商提供了一个强大的工具,以评估活动效果并根据消费者参与度优化内容。这种方法不仅克服了传统方法的挑战,而且通过充分探索 CNN 在营销和广告中的潜力,填补了当前研究中的关键空白。最终,这项研究有可能提供更准确、更可行的洞察,显著增强广告策略,并为不断增长的眼动追踪技术知识体系做出贡献。
3. 材料和方法
在本节中,我们提出了一种基于 CNN 的浅层眼动跟踪方法,优先考虑计算效率和降低复杂性,而不是 VGG16 或 DenseNet 等更深的架构。虽然更深的 CNN 在特征提取方面表现出色,但它们增加的参数可能会导致有限数据的过度拟合。我们的浅层架构有效地从眼睛区域捕获基本特征,使其非常适合以最少的计算资源进行实时注视跟踪。为了更清楚地了解整个过程,图 1 说明了所提出的方法的流程,概述了数据收集、数据预处理和数据分析所涉及的步骤。
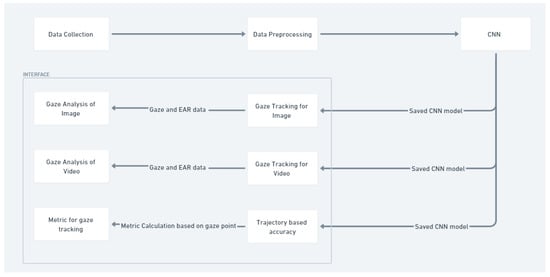
图 1.所提方法的流程图。
3.1. 数据收集
本研究使用标准网络摄像头和 OpenCV 库来捕获右眼区域的图像。数据是在光线充足的环境中收集的,来自 9 名参与者:4 名男性、4 名女性(均超过 28 岁)和 1 名 8 岁儿童。根据伦理准则,所有参与者都被告知研究的目的,并在实验前签署了一份同意书。所提出的方法采用 Mediapipe,这是 Google 开发的预训练模型,用于提取面部特征点。具体来说,识别出与右眼区域相对应的地标,并将其传递给 OpenCV 进行图像捕获。来自所有参与者的数据将用于验证系统在现实条件下的准确性,例如不同的用户动作和视线转移。测试阶段在评估模型的泛化性、基于轨迹的准确性以及持续捕捉和解释注视模式的能力方面起着至关重要的作用,从而使评估全面而稳健。
为了便于数据收集,屏幕被划分为一个由 16 个单元格组成的网格,每个单元格的中心包含一个脉动的红点,以吸引用户的注意力(见图 2)。该点在每个网格单元格中按顺序显示,并保持可见 5 秒钟,以确保准确捕获用户的凝视图像。所有参与者都舒适地坐在屏幕前,距离网络摄像头约 40 厘米,专注于在屏幕上移动的红点。在此期间,右眼区域的图像以灰度记录并调整为票价:256×256 元256×256像素。
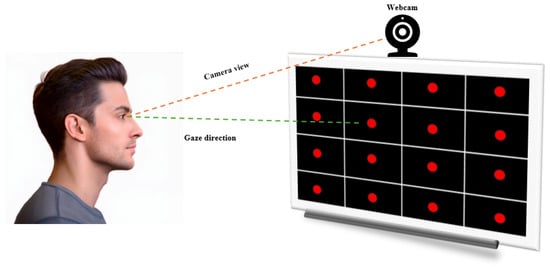
图 2.用于收集注视跟踪数据的实验设置。红点表示网格中每个单元格的中心点。网格由 16 个预定义区域组成,系统地划分屏幕以进行空间参考和分析。
在数据收集过程中,注意到个体层面的差异。成年人表现出稳定的凝视模式,头部运动最少,从而产生高质量的图像。相比之下,儿童参与者表现出快速的视线移动和偶尔的头部运动,导致变异性和噪音。其他预处理(包括过滤模糊帧和使用 Mediapipe 的强大检测)解决了这些问题。眼睛形状、大小和照明的变化也会影响图像质量。戴眼镜的参与者偶尔会出现眩光,通过事先调整屏幕亮度和测试角度可以减轻。
数据收集过程持续了大约 80 秒,在此期间,系统地捕获并保存了所需的图像。这些图像被组织到一个主目录中,每个子文件夹都根据其相应的网格编号进行标记。总共收集了 3387 张图像,平均每个网格单元约 211 张图像。
本研究中提出的方法强调了使用 Mediapipe 和 OpenCV 捕获和处理眼动追踪数据的有效性。Mediapipe 提供用于精确眼睛检测和跟踪的预构建模型,而 OpenCV 管理图像处理任务,从而提高眼动跟踪过程的准确性和效率。
3.2. 数据预处理
数据预处理是此方法中至关重要的步骤,包括数据清理、图像大小调整、归一化和增强,以增强模型的泛化能力。有效的预处理可确保神经网络能够准确学习和预测注视方向,这对于模型的整体成功至关重要。
如图 3 所示的预处理管道首先使用 Mediapipe 结合 OpenCV 检测到的面部特征点捕获眼睛区域图像。首先,初始化 Mediapipe 以识别 468 个面部特征点,重点是右眼区域。右眼周围的标志被隔离,以精确捕获感兴趣区域。提取后,使用 OpenCV 将图像转换为灰度并调整为票价:256×256 元256×256像素。这种标准化的图像大小对于训练卷积神经网络 (CNN) 至关重要,可确保支持准确预测的一致输入数据。第二步是数据清理,确保创建用于模型训练的高质量数据集。此过程是手动执行的,每个图像都要逐个网格仔细检查。目标是删除任何包含可能导致预测不准确的闪烁或失真的图像。当红点在网格中按顺序移动时,一些早期图像可能无法与预期的注视方向正确对齐。
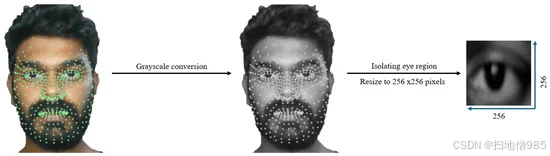
图 3.图像预处理:特征点检测和眼区分割。
这些未对齐的图像(如图 4 所示)被排除在外,以防止它们对神经网络的训练产生负面影响。未来的工作旨在自动化此检测和纠正过程以提高效率。

图 4.眼睛凝视序列的示例,其中眨眼和未对齐的凝视方向(即在红色框内)被删除。
预处理的最后一步涉及将图像转换为灰度,以确保图像格式一致。然后,所有图像的大小都会调整为标准票价:256×256 元256×256像素尺寸和像素归一化以增强模型稳定性。灰度图像的像素值范围为 0 到 255,其中 0 表示黑色,255 表示白色。为了进行标准化,每个像素值除以 255.0,将值缩放到 0 到 1 的范围。此归一化步骤对输入数据进行了标准化,从而提高了模型的稳定性并增强了其在训练期间的泛化能力。
3.3. 模型开发和训练
预处理后,数据已准备好用于卷积神经网络 (CNN) 模型。其架构如图 5 所示,包括卷积层、池化层、全连接层和输出层。卷积层使用图像卷积机制提取分层特征,识别边缘和纹理等模式。池化层减少了特征图维度,最大限度地减少了计算复杂性和过度拟合。全连接层集成了提取的特征,从而实现了复杂的模式识别。输出层预测回归任务的凝视坐标。模型训练涉及通过反向传播优化权重,由损失函数(例如均方误差 (MSE))指导,以有效地最大限度地减少预测误差。
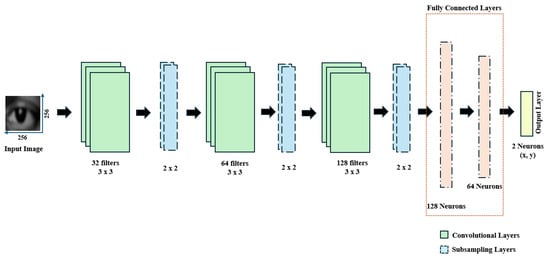
图 5.所提出的方法的 CNN 架构。
使用 CNN 进行实时凝视估计的算法如算法 1 所示。下面我们介绍使用的 CNN 层和参数。


-
Convolutional Layers
CNN 从卷积层开始,这对于从输入图像中提取分层特征至关重要。第一个卷积层使用 32 个过滤器,每个过滤器3×33×3的大小,并应用 Rectified Linear Unit (ReLU) 激活函数。此层负责检测基本特征,例如边缘和纹理。然后,该层的输出通过子采样层,从而减少特征图的空间维度。第二个卷积层具有 64 个相同大小的滤波器,通过分析第一层中检测到的滤波器的组合来捕获更复杂的特征。此输出将再次进行子采样,以仅保留最重要的信息。第三个卷积层使用 128 个滤波器,进一步抽象特征表示,检测数据中的更高级别模式。滤波器数量的逐渐增加使模型能够捕获越来越复杂的结构,从而使特征提取过程更加复杂。在第 3 层之后,输出将进行另一次 subsampling作。
3.3.1. 所提方法的算法
子采样层
子采样(也称为最大池化)在每个卷积层之后应用,以减少特征图的空间维度。一个2×22×2窗口在特征图上滑动,选择每个窗口中的 Maximum (最大值)。此作有效地保留了最重要的特征,同时丢弃了不太相关的信息。通过降低维度,最大池化不仅可以降低模型的计算复杂度,还有助于防止过度拟合。此外,它还有助于对输入图像进行更抽象和更广义的表示,专注于每个区域中的突出特征,并帮助模型学习更广义的模式。
全连接层
在通过卷积层和池化层进行特征提取和降维之后,模型过渡到全连接层。Flatten 层将 2D 特征图转换为 1D 向量,然后将其传递到密集层中。第一个密集层包含 128 个具有 ReLU 激活的神经元,允许模型学习从前几层中提取的特征的非线性组合。随后的密集层有 64 个神经元,也使用 ReLU 激活,进一步细化了这些特征表示。这些层使模型能够学习特征之间的复杂关系,为准确预测做好准备。
输出层
模型的最后一层是输出层,它由两个神经元组成,分别代表预测注视方向的 x 和 y 坐标。由于此模型是为回归任务设计的,因此没有对输出层应用激活函数,而输出层则适用于预测连续值,例如凝视坐标。在模型编译过程中,均方误差 (MSE) 损失函数用于测量预测的凝视坐标与实际值之间的差异。优化过程旨在最大限度地减少此错误,引导模型进行更准确的注视位置预测。
该模型使用 Adam Optimizer 进行编译,Adam Optimizer 是一种备受推崇的优化方法,以其在训练深度神经网络方面的效率而闻名。学习率设置为 0.001,以确保训练过程中稳定可靠的收敛。对数据集进行划分以进行综合评估和调优:80% 的数据用于训练,而剩余的 20% 保留用于验证。训练过程涉及多个 epoch,在此期间,根据损失函数迭代调整模型权重,以最大限度地减少预测误差并提高模型估计用户注视方向的准确性。
3.4. 数据分析
训练 CNN 模型后,它用于跟踪用户对显示内容(如营销视觉对象、图像和视频)的注视。此过程包括识别内容中吸引用户注意力的区域,并测量他们凝视特定区域的持续时间,从而为视觉元素吸引注意力的有效性提供有价值的见解。
内容显示在一个划分为 16 个网格的屏幕上,每个网格代表视觉对象的不同部分。CNN 模型预测用户在屏幕上的视线坐标,实时跟踪他们的注意力。这些注视数据,包括注视的坐标和持续时间,都记录在 Excel 文件中,从而创建用户看向何处和持续时间的详细日志。这些数据对于营销人员确定内容的哪些部分最有效地吸引受众并确定可能需要改进的领域至关重要。
除了视线跟踪之外,还计算了眼睛纵横比 (EAR) 以在整个观看过程中监控用户的眨眼率。EAR 是眼图张开度的量度,使用以下公式计算:
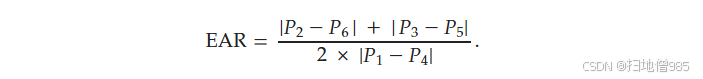
(1)
在方程 (1) 中,|𝑃2−𝑃6||P2−P6|和|𝑃3−𝑃5||P3−P5|表示特定 Eye 特征点之间的垂直距离,而|𝑃1−𝑃4||P1−P4|表示水平距离(参见图 6)。如果眼睛纵横比 (EAR) 在指定数量的连续帧中低于 0.2 的阈值,则会检测到闪烁 [28]。这些闪烁数据以及时间戳也记录在单独的 Excel 文件中,从而深入了解用户参与度和图像查看过程中的潜在疲劳。监控眨眼率可以帮助营销人员了解用户何时可能会失去注意力或变得疲劳,从而为调整内容长度或速度提供信息。
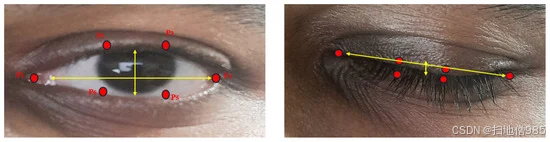
图 6. |𝑃2−𝑃6||P2−P6|和|𝑃3−𝑃5||P3−P5|表示特定眼界标(红点)之间的垂直距离,并且|𝑃1−𝑃4||P1−P4|表示水平距离。
已经开发了一种方法来模拟凝视跟踪,方法是在屏幕上指定网格单元内随机生成的位置绘制一个圆圈。该方法首先根据用户的凝视坐标确定网格单元的中心。然后,它会计算围绕此中心周围 200 像素半径内的随机角度和距离。这种随机化为预测的注视点引入了可变性,使模拟更加动态和真实。计算出这个随机位置后,在计算的位置画一个圆,并存储坐标以供后续分析。这种生成随机坐标的方法模拟了人类凝视行为中的自然可变性。实际上,人眼并不关注单个点,而是关注目标周围的一小块区域,称为“视觉轴”。这与“光轴”不同,“光轴”是穿过眼睛光学中心的直线。如图 7 所示,点。这两个轴之间的偏差通常约为 5 度 [29],这是注视的自然色散的原因
因此,在定义的半径内使用随机坐标可以有效地模拟这种散射,从而准确反映人类注视行为的固有可变性和不精确性。
为了生成图像和视频的热图,该算法首先加载凝视坐标并初始化与图像或视频帧的尺寸相对应的热图矩阵。这些坐标用于向热度地图矩阵添加值,突出显示凝视集中度较高的区域。对于图像,使用高斯模糊对热图进行平滑处理,然后进行归一化和对比度增强,然后应用颜色图。然后,将热图叠加在原始图像上,并绘制一个网格以将图像分割成多个区域,以便于视觉参考。对于视频处理,该算法逐帧作。随着视频的播放,凝视坐标会在热图中不断更新。每个帧都经过平滑和对比度增强,热图实时叠加,在每帧上绘制网格以突出显示感兴趣的区域。这使得注视模式的动态可视化和对整个视频中的用户注意力(例如,注视点)的实时分析成为可能。
热图也可以解释为注视的概率表示,计算如下:

(2)
通过将原始凝视计数数据转换为概率分布,我们生成了一个热图,该热图表示在视觉内容的不同区域发生注视的可能性。此转换使用公式 (2) 执行,其中首先对整个图像或视频帧的注视总数求和。然后通过将该特定区域的固定计数除以固定总数来确定每个区域的固定概率。热图不仅突出显示了感兴趣的区域,还显示了每个区域吸引注意力的可能性。这一额外的分析层提供了对视线模式的更细致的理解,从而更深入地了解视觉焦点如何在内容中分布。通过量化固定的可能性,这种方法增强了我们解释和优化视觉材料以实现最大参与度的能力。
3.5. 基于轨迹的精度
基于轨迹的准确性为评估凝视跟踪系统的性能提供了一种新颖而有洞察力的方法。传统的准确率指标通常侧重于基于点的比较,评估预测的注视点与参考点的对齐程度。虽然这些方法提供了有价值的信息,但它们无法捕捉到凝视跟踪的动态性质,尤其是在凝视行为连续且流畅的真实场景中。基于轨迹的准确性通过将随时间推移的预测注视路径与参考轨迹进行比较来解决这一限制,从而提供更全面的系统性能测量。
在这种方法中,当用户在屏幕上的网格中跟随移动的物体(通常由球表示)时,该算法会跟踪卷积神经网络 (CNN) 模型预测的注视点。用户遵循预定义的参考轨迹,例如锯齿形或圆形图案,该轨迹可能会覆盖屏幕的所有边缘,如图 8 所示。预测的注视点和参考轨迹都会随时间记录,从而产生两组轨迹:一组来自模型的预测,另一组来自预定义的路径。然后将这些轨迹转换为数组以计算各种性能指标。
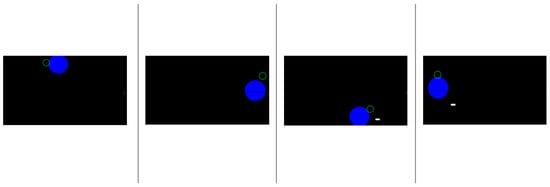
图 8.基于轨迹的精度方法。这个想法是让用户注视给定蓝球的新轨迹。
采用几个关键指标来量化预测的凝视轨迹与参考轨迹的匹配程度。
平均绝对偏差 (MAD):此指标计算预测的凝视点与参考轨迹之间的平均绝对差。MAD 的公式如下:
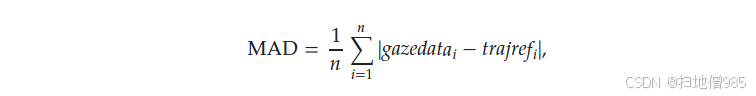

(3)

4. 结果
本节介绍了拟议的基于 CNN 的凝视跟踪模型的结果,该模型使用从不同位置和环境中的参与者收集的数据进行训练。评估涵盖各种性能指标,包括模型损失、凝视点绘制、热图可视化、基于轨迹的分析以及与其他凝视跟踪模型的准确性比较。
4.1. 模型评估和案例分析
我们基于 CNN 的眼动跟踪模型经过了 50 多个时期的训练,持续监控其验证损失,以评估其在看不见的数据上的性能。到最后一个 epoch 时,验证损失为 0.0112,表明模型能够有效地泛化到新数据。如图 9 所示,训练过程显示损失稳步下降,表明模型学习效率很高。
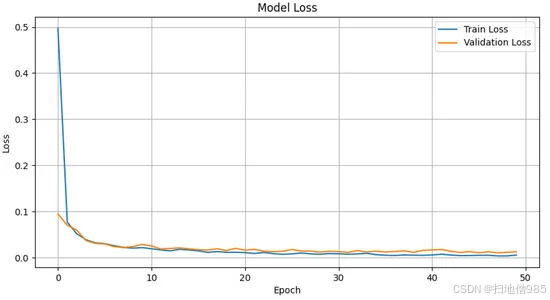
图 9.模型损失超过 50 个 epoch,验证损失为 0.0112。
最初,损失急剧下降,这意味着该模型很快就学会了对注视预测至关重要的基本特征。大约在第 20 个 epoch 中,损失开始趋于稳定,标志着模型向最佳性能收敛。这一趋势凸显了所提出的 CNN 架构在从训练数据中学习底层模式方面的有效性,这对于精确的凝视跟踪至关重要。
为了全面评估模型的性能,分析了三个主要指标(图 10)。
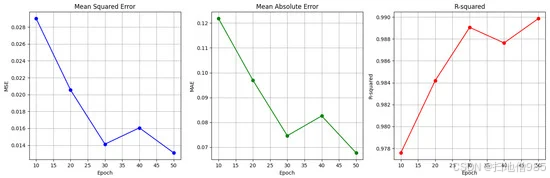
图 10.MSE ( left), MAE ( middle), and R-squared ( right) values across epochs.
均方误差 (MSE):该模型实现了 0.0112 的低 MSE,表明预测的注视点与实际值非常一致。
平均绝对误差 (MAE):MAE 为 0.0531,表明预测和实际注视点之间的平均偏差最小,肯定了模型的精确性。
R 平方值:记录了 0.9953 的高 R 平方值,这意味着 99.53% 的凝视位置方差是由模型解释的。这凸显了其强大的预测能力和能力,可以在输入图像和凝视坐标之间建立准确的关系。
4.1.1. 实时准确率评估
该模型的实时预测准确性使用4×44×4grid 显示在空白屏幕上。用户按顺序关注网格的每个方块,同时实时绘制模型的预测。预测始终落在与用户关注点相对应的网格方块内,证明了该模型在实时应用中的可靠性。图 11 突出显示了实际注视点和预测坐标之间的强烈对齐,整个网格的偏差最小,展示了模型在动态场景中精度的有效性。
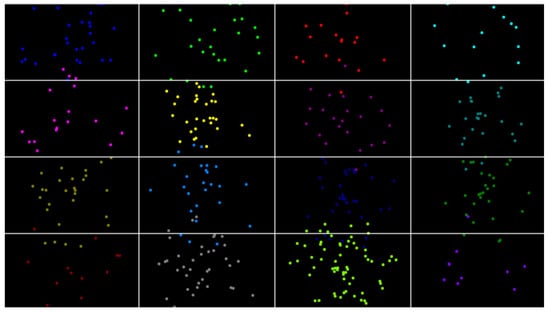
图 11.屏幕不同区域中的凝视跟踪。
4.1.2. 热图分析
使用静态图像和视频内容的热图可视化进一步分析了模型的注视跟踪性能。4×44×4网格,如图 12 和图 13 所示,它们展示了来自一个个体的数据。热图表示受到最多视觉关注的区域,而强烈的区域表示长时间的注视。
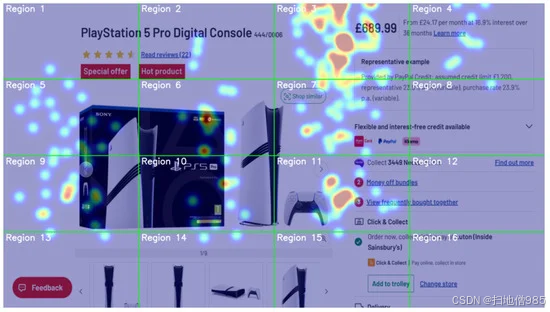
图 12.为静态图像计算的热图可视化。预定义的网格(绿线)将图像分割成不同的区域,而热图则说明了屏幕上注视点的概率分布,突出显示了视觉注意的区域。

图 13.Heatmap interface:给定视频帧计算的热图序列。
静态图像热图:在图 12 中,使用 Argos 官网上的图像,热图显示用户的视线主要集中在特定的网格区域,证实了该模型准确识别感兴趣区域的能力。
视频热图:图 13 显示了对来自 Pexels 官方网站的视频内容进行的动态视线跟踪。热图展示了一致的跟踪,视线在视频帧中准确跟踪目标区域。演示热图分析的链接可在 https://drive.google.com/file/d/1pRTvb9lbpqt_sMOL0DxjfE0QlCOWaSvH/view?usp=sharing 上找到(于 2025 年 2 月 1 日访问)。
图 14 演示了个体的注视注视图,以展示模型准确记录注视点最集中的网格区域的能力——静态图像的区域 3 和视频的区域 5。这种注视分析强调了该模型在跟踪静态和动态内容的视觉焦点方面的一致性能。
图 14.注视界面:注视在屏幕上不同区域的注视分布。
此外,图 15 也基于一个单独的示例,演示了眼睛纵横比 (EAR) 图在分析凝视跟踪期间的眨眼行为方面的效用。该图表有效地捕捉了用户的眨眼,证实了模型对眼睛状态变化的敏感性,同时保持了精确的凝视预测。图 16 和表 1 中描述的注视注视的概率分布同样使用单个示例来提供注视模式的详细视图,从而更深入地了解视觉焦点和注意力。这些结果证明了该模型的有效性并突出了其强大的功能。
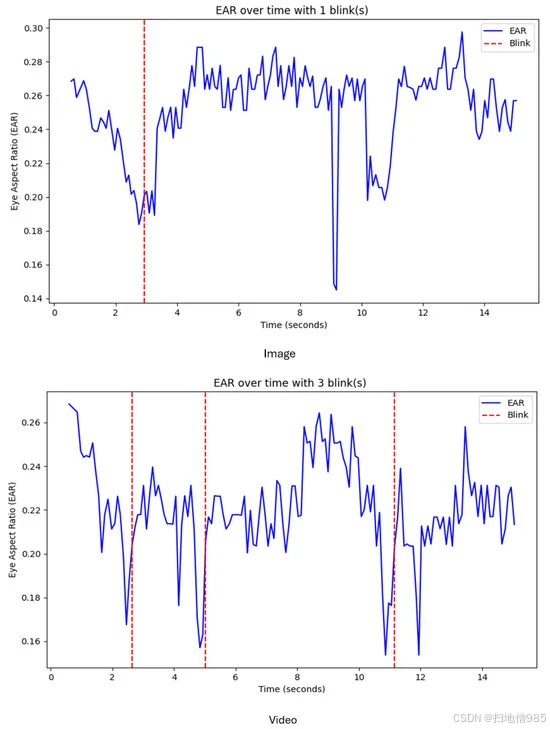
图 15.显示闪烁次数的 EAR 图。
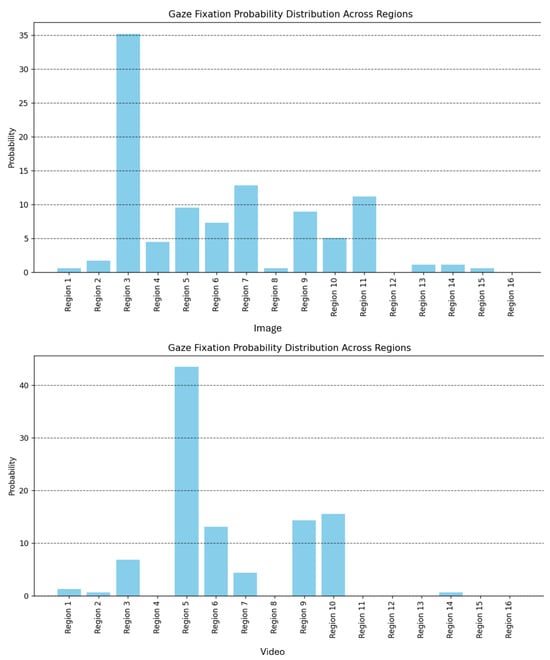
图 16.Gaze fixation interface:注视的概率分布。
表 1.图像和视频在不同区域的注视注视百分比。
Table 1. Percentage of gaze fixation in different regions for image and video.
| Image Region | % | Video Region | % |
|---|---|---|---|
| Region 1 | 0.558659 | Region 1 | 1.24224 |
| Region 2 | 1.67598 | Region 2 | 0.621118 |
| Region 3 | 35.1955 | Region 3 | 6.8323 |
| Region 4 | 4.46927 | Region 4 | 0 |
| Region 5 | 9.49721 | Region 5 | 43.4783 |
| Region 6 | 7.26257 | Region 6 | 13.0435 |
| Region 7 | 12.8492 | Region 7 | 4.34783 |
| Region 8 | 0.558659 | Region 8 | 0 |
| Region 9 | 8.93855 | Region 9 | 14.2857 |
| Region 10 | 5.02793 | Region 10 | 15.528 |
| Region 11 | 11.1732 | Region 11 | 0 |
| Region 12 | 0 | Region 12 | 0 |
| Region 13 | 1.11732 | Region 13 | 0 |
| Region 14 | 1.11732 | Region 14 | 0.621118 |
| Region 15 | 0.558659 | Region 15 | 0 |
| Region 16 | 0 | Region 16 | 0 |
图 17 显示了轨迹准确率为 94.65% 的样本参与者的结果,其中橙色线代表眼动数据,蓝线代表球的轨迹,绿色圆圈代表用于计算准确率的阈值限制。该测试涉及 9 名参与者,通过对所有参与者的准确率求平均值计算得出 90.98% 的轨迹准确性。这种高准确度反映了模型在遵循预定义路径方面的精度。虽然准确性会受到实时数据处理、系统要求和环境条件等因素的影响,但该模型始终以最小的偏差跟踪注视轨迹。这种强大的性能对于需要准确实时视线跟踪的应用程序至关重要,包括交互式系统、营销分析和行为研究,在这些应用中,精确性和可靠性至关重要。
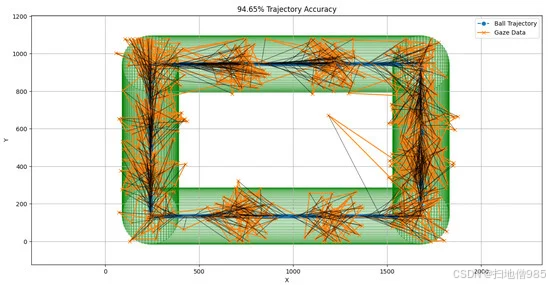
图 17.使用基于轨迹的方法的样本参与者的准确性。
平均绝对偏差 (MAD):MAD 为 156,表示预测的凝视点与参考路径的平均偏差。
均方根误差 (RMSE):RMSE 为 208,表示预测误差的标准差。
动态时间变形 (DTW) 距离:DTW 距离为 172,100.09,这是衡量预测轨迹和参考轨迹之间相似性的指标,同时考虑了注视路径中可能的时间偏移。
这些指标提供了模型轨迹跟踪性能的全面视图,MAD 和 RMSE 表示单个预测的精度,而 DTW 距离评估凝视轨迹与预定义路径的整体对齐。
4.2. 消融研究和性能分析
进行了一项消融研究以评估所提出的 CNN 模型的不同组成部分的贡献。结果表明,卷积层在从输入图像中提取有意义的空间特征方面发挥着重要作用,对模型的成功贡献最大。跟票价:256×256 元256×256来自 9 名参与者的右眼像素灰度图像,该模型利用其预处理步骤和特征提取功能,在光线充足的条件下表现出强大的性能。但是,由于图像质量降低,它在弱光环境中的性能下降。这些发现强调了照明和特征提取在注视跟踪准确性中的重要性。
4.3. 模型比较
为了评估所提出的基于 CNN 的凝视跟踪模型的性能,将其准确性与现有凝视跟踪模型的准确性进行了比较。表 2 提供了详细的比较,展示了每个模型的准确性指标。
表 2.建议的模型与现有凝视跟踪模型的比较。
Table 2. Comparison of the proposed model with existing gaze-tracking models.
| Study | System Setup | Accuracy | Method Used |
|---|---|---|---|
| Wu et al. (2012) [31] | Webcam | 88% | Support vector machine |
| Meng and Zhao (2017) [32] | Two cameras | 88% | CNN |
| Sattar et al. (2020) [33] | Tobii eye tracker | 80% | CNN |
| Ou et al. (2021) [34] | Wearable eye tracker | 80% | CNN |
| Singh and Modi (2022) [16] | Webcam | 84% | CNN |
| The proposed method | Webcam | 90.98% | CNN |
结果表明,所提出的方法具有卓越的有效性,在精度和可靠性方面都有了显著的提高。这种比较分析突出了该模型准确预测凝视点的高级能力,使其成为凝视跟踪应用的强大解决方案。
Singh 和 Modi [16] 进行了全面的文献综述,分析了各种眼动估计模型,并根据准确性、系统设置和使用的数据集等参数对其进行了评估。基于他们的发现,本研究引入了一种新颖的注视跟踪方法,该方法的准确率达到了 90.98%,优于大多数现有模型,尤其是那些仅依赖标准网络摄像头设置的模型。此最终准确性代表参与测试阶段的 9 名参与者的平均表现。所提出的模型展示了精确的凝视跟踪能力,使其成为通常涉及红外光源或多个摄像头的复杂系统的成本效益和高效的替代方案。
与通常需要昂贵设备和频繁重新校准的早期型号不同,这种方法将稳健性与简单性相结合,无需不断调整。它的实用性使其特别适用于成本效益和可靠性性能都至关重要的场景。通过在不依赖先进或昂贵的硬件的情况下提供高精度,所提出的方法解决了可访问性和可负担性的挑战。这使它成为实际应用的有力候选者,尤其是在部署更复杂和昂贵的设置不切实际的环境中。它的多功能性使其适用于广泛的用例,从营销和用户行为分析到交互式系统设计。
4.4. 凝视跟踪界面
图 18a 展示了一个使用 Python 的 Tkinter 库开发的用户友好型图形界面,旨在简化眼动跟踪和分析的过程。这个界面是一个干净、视觉上吸引人的平台,有助于运行与眼动追踪研究和分析任务相关的各种脚本。

图 18.主凝视跟踪界面 (a) 和所有可用选项(跟踪、校准、测试和分析)。图 (b) 显示了精度测试的初始化。
4.4.1. 算法和功能
该界面由五个主要按钮组成,每个按钮都链接到在凝视跟踪和分析中执行关键功能的特定脚本。
凝视跟踪按钮:激活图像凝视跟踪脚本,该脚本记录和存储图像中特定感兴趣区域的用户的凝视数据。它还跟踪眨眼数据,这对市场研究很有价值。
视频凝视跟踪按钮:运行视频凝视跟踪脚本,将模型的凝视跟踪功能扩展到视频内容。此功能收集凝视和眼睛纵横比 (EAR) 数据,从而实现更动态的分析。
分析按钮:执行图像的热图脚本,提供对凝视注视区域和眨眼计数的更多见解。此脚本处理来自图像跟踪的存储的凝视数据,从而直观地表示用户在屏幕上最关注的位置。
视频凝视分析按钮:运行脚本以为视频内容生成热图,根据收集的凝视和 EAR 数据创建逐帧热图和指标。
Accuracy Test Button:在运行基于轨迹的精度脚本之前,此按钮会提示用户跟随屏幕上的蓝球,确保他们理解任务,如图 18b 所示。确认后,脚本会计算凝视跟踪的准确性。
4.4.2. 视觉效果和可用性
该界面采用时尚的黑色背景,有助于其现代和专业的外观。纽扣采用柔和的绿色和浅胡桃木色调,提供易于阅读的对比。每个按钮在其描述性文本上方都包含一个图标,增添了现代感并增强了整体外观和感觉。这些按钮具有 3D 效果,悬停状态提供即时视觉反馈,增强了其交互性。
布局组织成 2 × 3 网格,确保按钮间距均匀且易于点击,并提高整体可用性。这种设计不仅使界面美观,而且确保它直观且易于导航。其现代设计和功能元素的结合使用户能够毫不费力地管理和执行复杂的注视跟踪任务。
总体而言,此界面为研究人员和专业人员提供了一个强大的工具,简化了进行眼动跟踪和分析的过程,同时在风格和实用性之间保持了平衡。
5. 结论和未来工作
这项研究利用卷积神经网络 (CNN) 和标准相机成功开发了一种经济高效且准确的注视跟踪系统。我们的方法为传统的凝视跟踪系统提供了一种实用的替代方案,传统的凝视跟踪系统通常依赖于昂贵的红外 (IR) 相机和受控环境。通过使用传统相机,这种方法显着拓宽了凝视跟踪技术的可访问性,使其适用于更广泛的应用。该项目的主要目标是设计和实施一个基于 CNN 的眼动追踪系统,能够在各种真实场景中提供精确的眼动估计。为了实现这一目标,该项目专注于开发一种强大的校准方法来收集眼睛数据,创建一个专门用于眼动估计的 CNN 模型,并设计一个集成了眼动跟踪、数据存储和分析功能的用户友好界面。本研究的结果强调了所提出的方法的有效性,CNN 模型达到了 90.98% 的准确率。这代表了 9 名参与者在测试阶段的平均表现,使用基于轨迹的评估系统进行评估。该模型的性能超过了许多现有方法,证实了这种基于网络摄像头的方法在不同环境中进行实时凝视跟踪的可行性。关键性能指标,包括低均方误差 (MSE)、高 R 平方值和最小平均绝对误差 (MAE),进一步突出了该模型在预测凝视点方面的精度和稳健性,具有卓越的可靠性。此外,实时验证和基于轨迹的测试表明,该模型在动态视觉交互过程中保持了高精度,这对于人机交互、营销和行为研究等应用至关重要。
热图、注视点图和眨眼率分析等高级功能的集成都位于直观的用户界面中,增强了系统的可用性并拓宽了其潜在应用范围。与其他注视跟踪技术相比,所提出的方法因其高精度和经济性的结合而脱颖而出。这些属性使其在成本效益和最佳性能都至关重要的情况下特别有价值。用于面部特征点检测的 Google Mediapipe 模型进一步增强了系统的可靠性,即使在不同的环境条件下也能确保一致的视线估计。因此,本研究通过引入一种基于 CNN 的方法,成功地解决了传统凝视跟踪系统的局限性,该方法既用户友好又高效。开发的系统不仅提供高精度,而且还提供了适用于广泛应用的多功能工具,从学术研究到营销和用户体验设计等领域的商业用途。全面的评估指标和直观的界面增强了系统的实用价值,使其成为注视跟踪技术的重大进步。未来的工作可能会改进模型和界面,添加更多功能或提高其对不同环境和用例的适应性。
未来的工作
展望未来,还有许多进一步发展的机会。未来的迭代可能涉及设计更高级的 CNN 架构,以提高准确性和稳健性。允许用户选择他们喜欢的眼睛进行跟踪、扩展数据集以及实施新的方法来清理异常值图像,这将减少手动数据排序并进一步提高系统性能。此外,在未来研究中增加参与者的数量和多样性,以包括更广泛的年龄组、性别和种族,将提高模型在不同人群中的普遍性和准确性。此外,确保不同设备之间的模型性能一致也至关重要。由于这项研究是在 15 英寸笔记本电脑上进行的,因此过渡到不同的屏幕尺寸将需要额外的数据收集和模型重新训练。将整合一个涵盖 240p 到 1080p 分辨率的更广泛的数据集,以及一个先进的系统,以准确映射不同屏幕尺寸的注视点。这些进步将建立在本项目中奠定的基础之上,并突破基于网络摄像头的凝视跟踪的界限。
6.交流与联系

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 26
26 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)