深度学习05——图像分类
本文介绍了分类任务与卷积神经网络的基本原理。分类任务需使用独热编码表示类别,通过交叉熵损失计算输出与实际值的差异。卷积神经网络通过卷积核提取特征图,配合池化操作降低维度,解决图像分类问题。文章详细解释了卷积运算、padding、步长等概念,并介绍了经典模型AlexNet(采用ReLU、Dropout等技术)和ResNet(引入1×1卷积和残差连接解决梯度消失问题)。最后指出全连接层与卷积层的关系,
一、分类任务
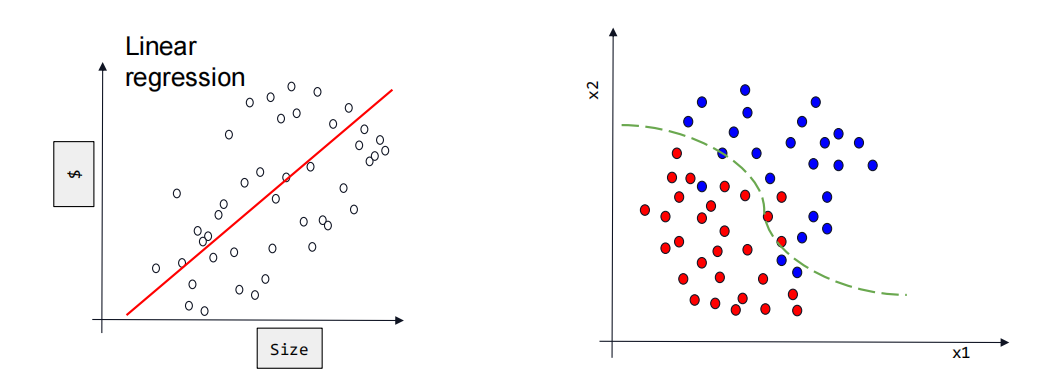
回归与分类
现实中有很多问题并不是预测问题。比如:判断一个图片里的动物是鸟还是人,还是猫。
那么如何实现分类。以右侧图片为例,首先需要考虑如何做分类的输入和输出。
分类的输出。以某一个数字作为输出(比如2.4),并将判断对象划为2这一类别,这显然是不合适的。因为这表示判断对象除了是在2这一类别,还和3这一类别很像,同时和1这一类别很不像,因为2.4距离3更近,距离1更远。这显然违背了分类选项的本意,每一个选项都是等价的,是2就不可能是1和3。所以单一数字输出不适用与分类任务。因此选用独热编码,用1的位置表示判断对象的类别,比如类别1应该是【1 0 0】;类别2应该是【0 1 0】。在使用nn.linear做模型输出时,模型输出也常为3,即Linear(x,3)。
得到输出后,最大值的下标即为判断对象的类别(【0.1 0.7 0.2】时判断对象为类别2)。这进一步引申出来一个新的问题,模型的输出如何与实际值计算loss?(输出值【0.1 0.7 0.2】与实际值【0 1 0】)可以将模型输出和实际值看作是两个概率分布,输出值认为判断对象是类别2的概率为0.7,而实际值认为判断对象的概率为1。因此利用交叉熵损失计算两个概率之间的loss。
分类的输入。一张图片由三通道RGB(红黄蓝)和像素大小(长宽)构成,因此数据量是3*224*224(长宽采用标准大小)。但是为了满足Linear(x,3)的x,需要将数据改造成一个向量。如图所示,方法是将照片的RGB排列并拉长,组成一个向量。
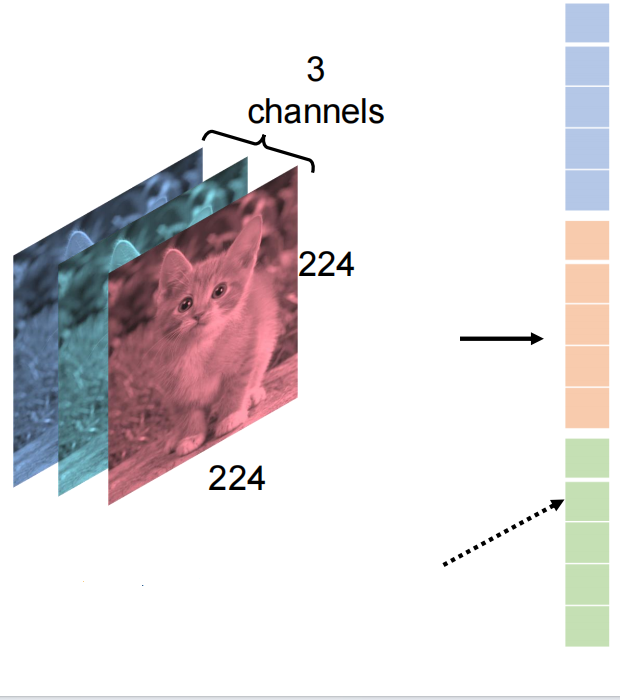
二、卷积神经网络
上文将照片拉长并排列进行输入的方法存在一个问题,即数据量过大,容易过拟合。因此可以使用卷积方法。
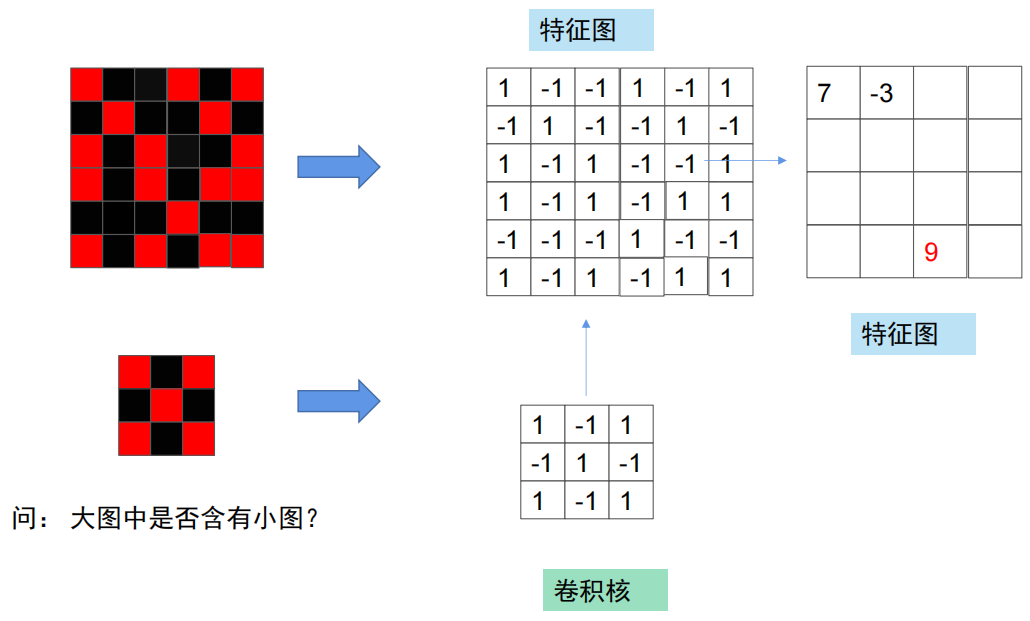
如何判断大图中是否含有小图,将小图放入大图中从左到右从上到下一一对比,这个过程叫做“卷”。再将红色块看作1,黑色块看作-1,此时小图与大图的对比不再使用颜色比对,而是每一部分相乘,最后再将所有结果相加,这一过程叫做“积”。如图,如果完全相等,将会得到9;而数值越大,说明越像。
在图像分类中,也是利用相同的思想。在判断目标图片内容是否是一只鸟时,将鸟喙的图片放入目标图片中卷积,看目标图片是否有鸟喙,由此来对图片分类。
我们将鸟喙这类对比的小图称作卷积核;将初始图片和对比的结果图成为特征图。可以不断将卷积核与特征图进行卷积得到新的特征图从而进行一连串的卷积,但每次卷积都会减小特征图的尺寸,为了维持特征图的大小,可以进行补零操作(zero padding),即在原特征图外增加一圈0.
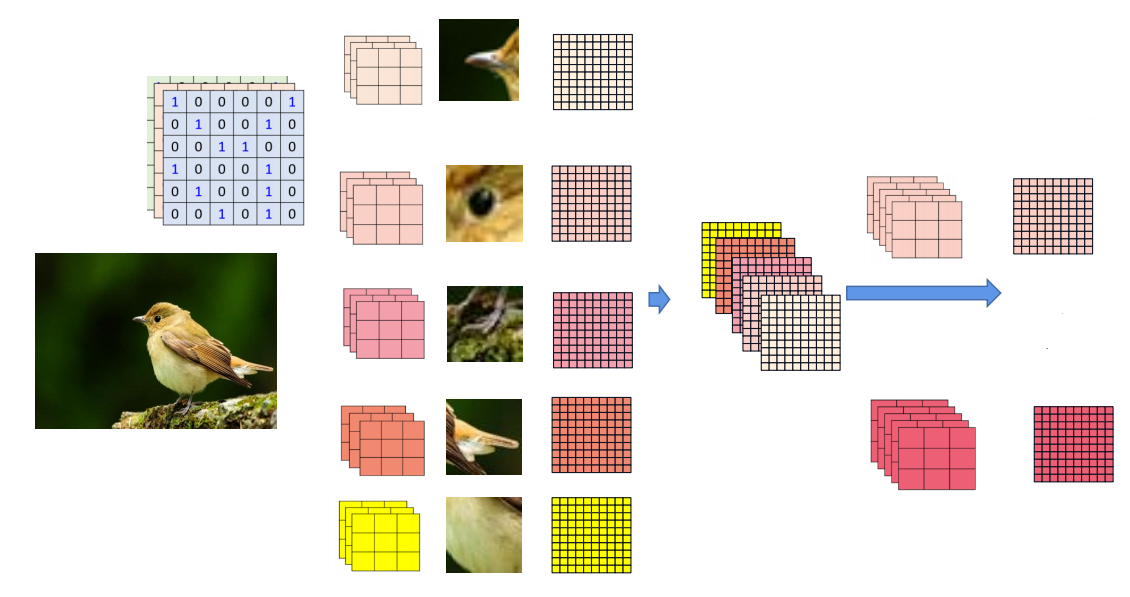
实际的卷积过程。当判断一张鸟的图片时,初始特征图(即初始图片)的大小为3*224*224,同时选取了5个卷积核(鸟喙、翅膀等),它们每个的大小为3*3*3(当然可以选择更大的卷积核)。在对初始特征图进行一层卷积后,等到了5张224*224的特征图。再将这五张特征图合并为一张5*224*224的特征图,并对5个卷积核加厚,变为5*3*3,并进行下一轮卷积。将卷积核的大小称为卷积核的参数量,即参数量由27变为45。
卷积尺寸计算公式 O=(I-K+2P)/S+1 ;其中 I是原特征图大小,K是卷积核大小,P是padding大小,S是步长stride,O是输出特征图大小。
可以预见,经过多次卷积后,无论是特征图的大小还是卷积核的参数量都会越来越大,造成计算困难。如何减小特征图的大小,仅依靠卷积这一过程太慢,因此选择降低采样率(如图像照片一样降低采样率)。
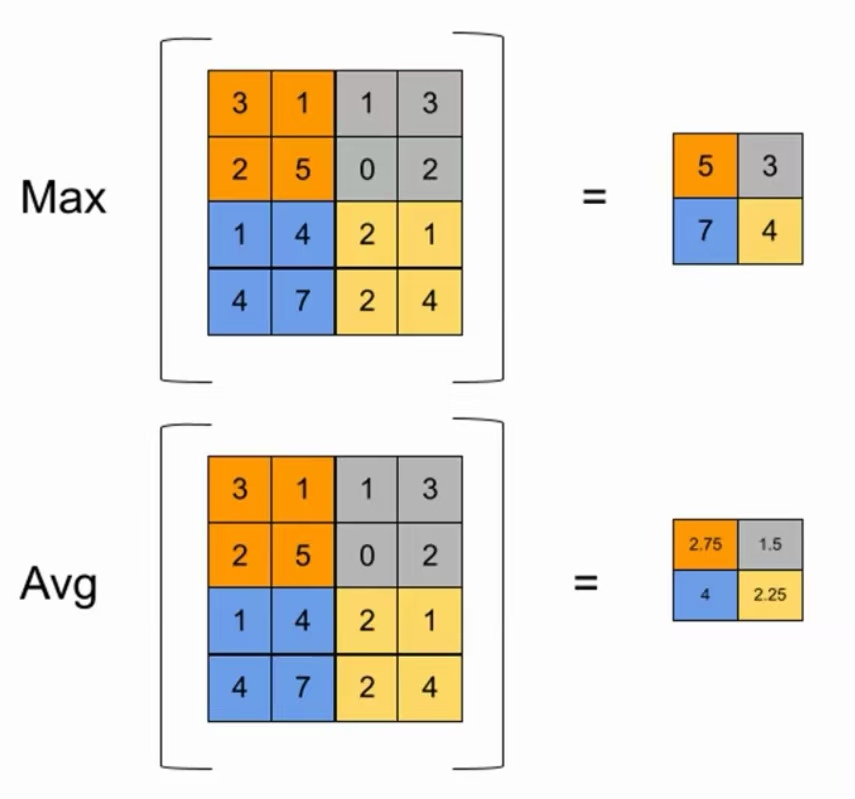
有两种方法降低采样率。方法一:改变卷积步长。卷积过程中,改变一个格子一个格子扫掠的方式,而是跳着格子进行卷积。缺陷是容易丢失信息,引入新的计算。方法二:池化pooling。即在特征图中用一个数代替多个数,从而直接减小特征图的大小。用两种池化方法:最大池化和平均池化。最大池化就是用区域内最大的数来代替所有的数;平均池化就是用区域内所有数的平均数来代替所有的数。在实际运用中,最大池化被使用的最多。
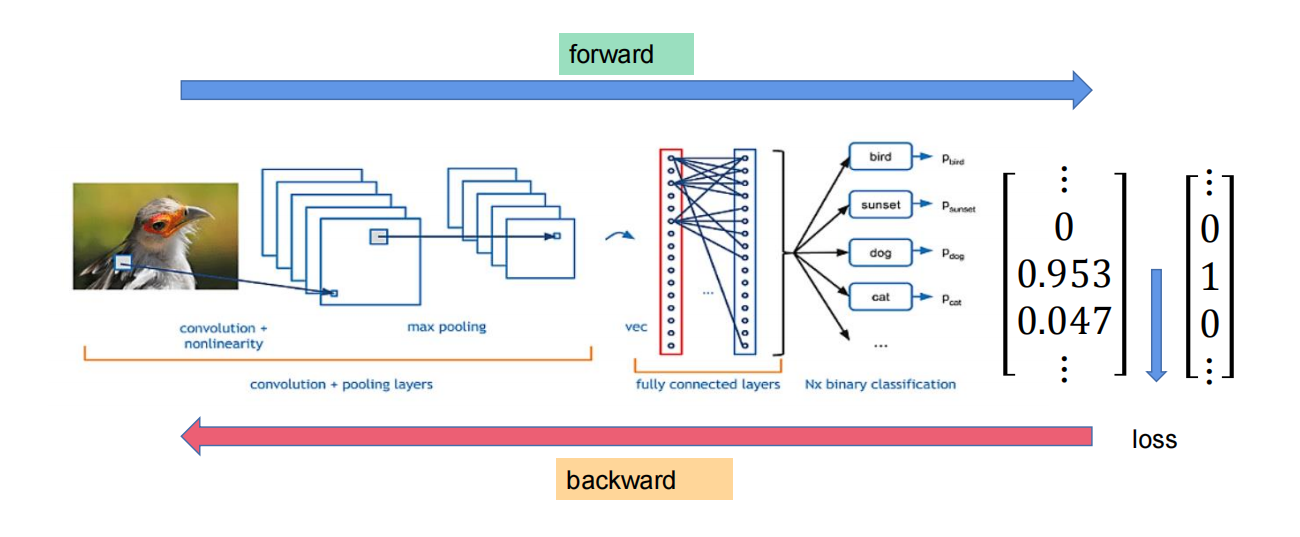
当对特征图进行卷积和池化的交替使用后,已经得到了合适的特征图大小,这时再将特征图拉直为向量进行深度学习。
三、LOSS
前文提及分类的输出值与实际值应是如下形式:输出值【0.1 0.7 0.2】与实际值【0 1 0】。在计算二者的loss值之前,还需对输出值进行预处理。在实际深度学习中,模型的输出值会得到类似【11.7 23 20】这类大于1且和不1的结果,为了将这个输出值改造为代表概率的值(类似【0.2 0.7 0.3】),会带入公式y=softmax(y):
一般将softmax的输出视作模型预测的概率分布。在对输出值改造后即可利用交叉熵损失进行loss计算,此处不介绍交叉熵损失的具体原理。
四、经典模型SOTA(the state of the art)
经典神经网络 AlexNet。有四大创新点:1.采用relu激活函数;2.drop out,随机禁没神经元,缓解过拟合;3.池化手段;4.对数据归一化处理,即消去量纲的影响
模型结构如下(省略激活函数):
from torchvision import models
import torch
import torch.nn as nn
#model=models.alexnet()
#print(model) #打印库中的Alexnet模型
class MyAlexNet(nn.Module):
def __init__(self,num_cls): #初始化函数,输入需要分辨的类别数
super(MyAlexNet, self).__init__() #继承父类的功能
self.conv1=nn.Conv2d(3,64,11,4,2) #第一层卷积。从左到右数据依次是输入特征图数量、输出特征图数量、卷积核大小、步长、padding
self.pool1=nn.MaxPool2d(3, 2) #第一次最大池化。池化范围3,步长2
self.conv2=nn.Conv2d(64,192,5,1,2) #第二层卷积与池化
self.pool2=nn.MaxPool2d(3,2)
self.conv3 = nn.Conv2d(192,384,3,1,1) #三次卷积
self.conv4 = nn.Conv2d(384,256,3,1,1)
self.conv5 = nn.Conv2d(256,256,3,1,1)
self.pool3 = nn.MaxPool2d(3,2) #池化
self.adapool = nn.AdaptiveAvgPool2d(output_size=6) #自适应平均池化层。将输入的任意尺寸特征图转换为固定尺寸的输出,这里指定的输出尺寸是6×6
self.fc1 = nn.Linear(9216,4096) #三次全连接层
self.fc2 = nn.Linear(4096,4096)
self.fc3 = nn.Linear(4096,1000)
def forward(self,x):
x=self.conv1(x)
x=self.pool1(x)
x=self.conv2(x)
x=self.pool2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.conv5(x)
x=self.pool3(x)
x=self.adapool(x) #此时特征图大小为batch*256*6*6
x = x.view(x.size()[0],-1) #将特征图拉平。x.size()[0]用于获取原张量的第一维大小,即batch大小
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
def get_parameter_number(model): #计算模型参数量
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return {'Total': total_num, 'Trainable': trainable_num}
model=MyAlexNet(1000)
data=torch.ones(4,3,224,224) #创建一个四维张量
pred=model(data)
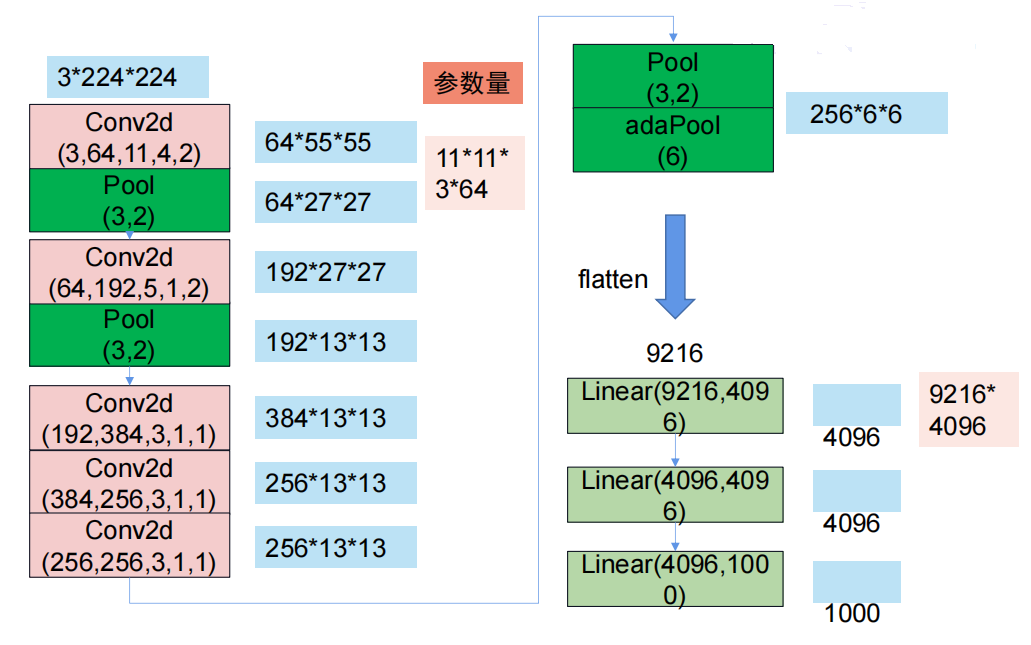
模型结构图
神经网络resNet。它有两大创新点:1*1卷积和残差连接。
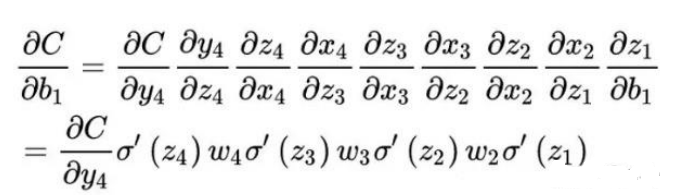
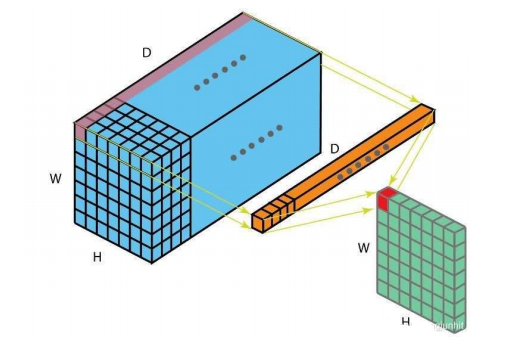
计算参数:1*1卷积。即只使用一个数对原理图进行卷积。作用是减少卷积过程中的参数量,如图,减小原理图的厚度,起到降维的效果。譬如对256*112*112的原理图进行一次Conv2d(256,64,1,1,0)的卷积,原理图变为64*112*112,参数量大大减小。
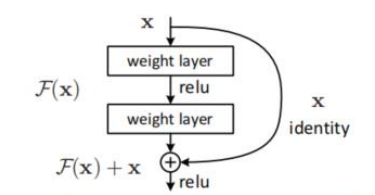
梯度消失和梯度爆炸。当神经网络层数过多时,回传梯度时可能过于接近0或者无穷大,因此层数不是越多越好。resNet提出将每一层的输出变为Out = f(x) + x,即原输出加上输入得到的和作为新输出,可以使得梯度大于1,从而避免梯度消失。这就是残差连接。若输出与输入层大小维度不同,可以对输入进行一次1*1卷积,再加到输出上。
五、全连接与卷积的关系
卷积如何通过梯度更新参数?
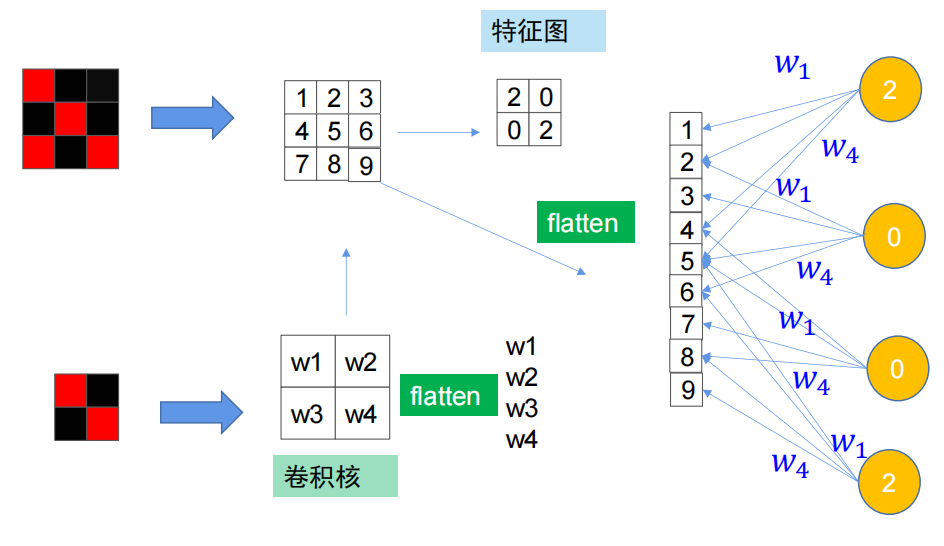
卷积相对于全连接需要的参数更少,同时如图有部分参数是相同的,因此卷积是一种参数共享的“不全连接”。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)