多头注意力(MultiHeadAttention)python实现
·
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
""" Multi-Head Attention """
def __init__(self, n_head, d_k_, d_v_, d_k, d_v, d_o):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.fc_q = nn.Linear(d_k_, n_head * d_k)
self.fc_k = nn.Linear(d_k_, n_head * d_k)
self.fc_v = nn.Linear(d_v_, n_head * d_v)
self.attention = ScaledDotProductAttention(scale=np.power(d_k, 0.5))
self.fc_o = nn.Linear(n_head * d_v, d_o)
def forward(self, q, k, v, mask=None):
n_head, d_q, d_k, d_v = self.n_head, self.d_k, self.d_k, self.d_v
batch, n_q, d_q_ = q.size()
batch, n_k, d_k_ = k.size()
batch, n_v, d_v_ = v.size()
q = self.fc_q(q) # 1.单头变多头
k = self.fc_k(k)
v = self.fc_v(v)
q = q.view(batch, n_q, n_head, d_q).permute(2, 0, 1, 3).contiguous().view(-1, n_q, d_q)
k = k.view(batch, n_k, n_head, d_k).permute(2, 0, 1, 3).contiguous().view(-1, n_k, d_k)
v = v.view(batch, n_v, n_head, d_v).permute(2, 0, 1, 3).contiguous().view(-1, n_v, d_v)
if mask is not None:
mask = mask.repeat(n_head, 1, 1)
attn, output = self.attention(q, k, v, mask=mask) # 2.当成单头注意力求输出
output = output.view(n_head, batch, n_q, d_v).permute(1, 2, 0, 3).contiguous().view(batch, n_q, -1) # 3.Concat
output = self.fc_o(output) # 4.仿射变换得到最终输出
return attn, output
if __name__ == "__main__":
n_q, n_k, n_v = 2, 4, 4
d_q_, d_k_, d_v_ = 128, 128, 64
batch = 2
q = torch.randn(batch, n_q, d_q_)
k = torch.randn(batch, n_k, d_k_)
v = torch.randn(batch, n_v, d_v_)
mask = torch.zeros(batch, n_q, n_k).bool()
mha = MultiHeadAttention(n_head=8, d_k_=128, d_v_=64, d_k=256, d_v=128, d_o=128)
attn, output = mha(q, k, v, mask=mask)
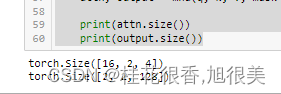
print(attn.size())
print(output.size())

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)