Python 训练营打卡 Day 44-预训练模型
模型年份提出团队关键创新点层数参数量LeNet-51998Yann LeCun 等首个 CNN 架构,卷积层 + 池化层 + 全连接层设计,采用 Sigmoid 激活函数,奠定深度学习视觉基础。7 层~60KAlexNet2012Alex Krizhevsky 等首次引入 ReLU 激活函数提升训练效率,使用 Dropout 抑制过拟合,结合数据增强与 GPU 并行计算。8 层60MVGGNet2
一.预训练的概念
我们之前在训练中发现,准确率最开始随着epoch的增加而增加。随着循环的更新,参数在不断发生更新,所以参数的初始值对训练结果有很大的影响:
1. 如果最开始的初始值比较好,后续训练轮数就会少很多
2. 很有可能陷入局部最优值,不同的初始值可能导致陷入不同的局部最优值
所以很自然的想到,如果最开始能有比较好的参数,即可能导致未来训练次数少,也可能导致未来训练避免陷入局部最优解的问题。这就引入了一个概念,即预训练模型
二.经典的预训练模型
2.1 CNN架构预训练模型
| 模型 | 预训练数据集 | 核心特点 | 在 CIFAR10 上的适配要点 |
|---|---|---|---|
| AlexNet | ImageNet | 首次引入 ReLU 激活函数和局部响应归一化(LRN),参数量超 6000 万,开创深度学习视觉模型先河。 | 需将首层卷积核大小从 11×11 修改为适配 32×32 输入的尺寸(如 7×7 或 3×3)。 |
| VGG16 | ImageNet | 采用纯卷积层堆叠的统一结构,通过小卷积核(3×3)重复堆叠构建深度网络,参数量达 1.38 亿。 | 冻结前 10 层卷积层以保留预训练特征,仅对全连接层进行微调以适应 CIFAR10 分类任务。 |
| ResNet18 | ImageNet | 引入残差连接(Residual Connection)解决深度网络梯度消失问题,参数量约 1100 万,兼顾深度与性能。 | 可直接接受 32×32 输入,但需调整池化层步长以匹配输入尺寸,避免特征图尺寸过度缩小。 |
| MobileNetV2 | ImageNet | 采用深度可分离卷积(Depthwise Separable Convolution),大幅减少参数量至 350 万 +,主打轻量级设计,适合移动端和计算资源受限场景。 | 无需大幅修改结构,利用其轻量级特性可直接适配 CIFAR10,适合对模型大小和推理速度有要求的场景。 |
2.2 Transformer类预训练模型
适用于较大尺图像(如224x224),在CIFAR10上需采样图像尺寸或调整Patch大小
| 模型 | 预训练数据集 | 核心特点 | 在 CIFAR10 上的适配要点 |
|---|---|---|---|
| ViT-Base | ImageNet-21K | 纯 Transformer 架构,首次将图像分割为 Patch 序列处理,参数量 8600 万,打破 CNN 在视觉领域的主导地位。 | 将图像 Resize 至 224×224 以匹配预训练输入尺寸,同时将 Patch 大小设为 4×4(原 16×16),确保小图像特征提取粒度更细。 |
| Swin Transformer | ImageNet-22K | 采用分层窗口注意力机制,通过移动窗口实现跨窗口交互,参数量 8000 万 +,兼顾局部与全局特征建模。 | 需根据 CIFAR10 的 32×32 输入调整窗口大小(原 7×7),例如设为 4×4 或 5×5,避免窗口尺寸超过图像本身导致计算失效。 |
| DeiT | ImageNet | 结合 CNN 归纳偏置(如位置编码优化),通过教师 - 学生网络训练提升性能,参数量 2200 万,轻量化设计。 | 直接适配中小尺寸图像,无需大幅调整结构,可利用其轻量级特性在 CIFAR10 上实现高效推理,同时保留 Transformer 的全局建模能力。 |
2.3 自监督预训练模型
无需人工标注,通过 pretext task(如掩码图像重建)学习特征,适合数据稀缺场景
| 模型 | 预训练方式 | 典型数据集 | 在 CIFAR10 上的优势 |
|---|---|---|---|
| MoCo v3 | 对比学习 | ImageNet | 基于无监督对比学习框架,无需标注数据即可学习通用视觉特征,迁移至 CIFAR10 时可大幅降低标注成本,尤其适合无标签场景下的特征提取与迁移学习。 |
| BEiT | 掩码图像建模 | ImageNet-22K | 通过掩码图像重构任务学习语义级特征表示,预训练特征包含更丰富的上下文信息,微调至 CIFAR10 时收敛速度更快,且分类精度提升显著,对小样本场景适应性更强。 |
三.常见的分类预训练模型介绍
| 模型 | 年份 | 提出团队 | 关键创新点 | 层数 | 参数量 |
|---|---|---|---|---|---|
| LeNet-5 | 1998 | Yann LeCun 等 | 首个 CNN 架构,卷积层 + 池化层 + 全连接层设计,采用 Sigmoid 激活函数,奠定深度学习视觉基础。 | 7 层 | ~60K |
| AlexNet | 2012 | Alex Krizhevsky 等 | 首次引入 ReLU 激活函数提升训练效率,使用 Dropout 抑制过拟合,结合数据增强与 GPU 并行计算。 | 8 层 | 60M |
| VGGNet | 2014 | Oxford VGG 团队 | 统一采用 3×3 小卷积核堆叠构建深度网络,通过多尺度特征提取增强表达能力,结构简洁规范。 | 16 层 / 19 层 | 138M/144M |
| GoogLeNet | 2014 | 创新 Inception 模块实现多分支并行卷积,利用 1×1 卷积降维减少计算量,引入全局平均池化。 | 22 层 | 5M | |
| ResNet | 2015 | 何恺明等 | 提出残差连接解决深度网络梯度消失问题,结合 Batch Normalization 加速训练收敛。 | 18/50/152 层 | 11M/25M/60M |
| 模型 | ImageNet Top-5 错误率 | 典型应用场景 | 预训练权重可用性 |
|---|---|---|---|
| LeNet-5 | N/A | 手写数字识别(MNIST) | 无(历史模型) |
| AlexNet | 15.3% | 大规模图像分类 | PyTorch/TensorFlow 官方支持 |
| VGGNet | 7.3%/7.0% | 图像分类、目标检测骨干网络 | PyTorch/TensorFlow 官方支持 |
| GoogLeNet | 6.7% | 大规模图像分类 | PyTorch/TensorFlow 官方支持 |
| ResNet | 3.57%/3.63%/3.58% | 图像 / 视频分类、检测、分割 | PyTorch/TensorFlow 官方支持 |
| DenseNet | 2.80% | 小数据集、医学图像处理 | PyTorch/TensorFlow 官方支持 |
| MobileNet | 7.4% | 移动端图像分类 / 检测 | PyTorch/TensorFlow 官方支持 |
| EfficientNet | 2.6%(B7 版本) | 高精度图像分类(资源受限场景) | PyTorch/TensorFlow 官方支持 |
上图的层数,代表该模型不同的版本resnet有resnet18、resnet50、resnet152;efficientnet有efficientnet-b0、efficientnet-b1、efficientnet-b2、efficientnet-b3、efficientnet-b4等
其中ImageNet Top - 5 准确率是图像分类任务里的一种评估指标 ,用于衡量模型在 ImageNet 数据集上的分类性能,模型对图像进行分类预测,输出所有类别(共 1000 类 )的概率,取概率排名前五的类别,只要这五个类别里包含人工标注的正确类别,就算预测正确
模型架构演进关键点总结
1. 深度突破:从LeNet的7层到ResNet152的152层,残差连接解决了深度网络的训练难题
2. 计算效率:GoogLeNet(Inception)和MobileNet通过结构优化,在保持精度的同时大幅降低参数量
3. 特征复用:DenseNet的密集连接设计使模型能更好地利用浅层特征,适合小数据集
4. 自动化设计:EfficientNet使用神经架构搜索(NAS)自动寻找最优网络配置,开创了AutoML在CNN中的应用
预训练模型使用建议
| 任务需求 | 推荐模型 | 理由 |
|---|---|---|
| 快速原型开发 | ResNet50/18 | 结构设计平衡,预训练权重稳定性高,且拥有完善的社区支持与丰富的实践案例,便于快速搭建与调试模型。 |
| 移动端部署 | MobileNetV3 | 采用轻量级架构设计,参数量极少且计算效率卓越,针对移动设备的硬件特性进行深度优化,适合在资源受限的终端设备上运行。 |
| 高精度分类(资源充足) | EfficientNet-B7 | 在 ImageNet 等大规模数据集上保持着领先的准确率,通过复合缩放策略实现深度、宽度与分辨率的最优匹配,适合配备 GPU/TPU 等强大算力资源的环境。 |
| 小数据集或特征复用需求 | DenseNet | 凭借密集连接机制最大化特征复用效率,有效减少过拟合问题,在小数据集场景下能充分利用有限数据学习到更丰富的特征表示。 |
| 多尺度特征提取 | Inception-ResNet | 巧妙结合 Inception 模块的多分支并行卷积特性与 ResNet 的残差连接优势,可同时捕捉不同尺度的视觉特征,非常适合复杂场景下的特征提取任务。 |
这些模型的预训练权重均可通过主流框架(如PyTorch的`torchvision.models`、Keras的`applications`模块)直接加载,便于快速迁移到新任务
3.1预训练模型的训练策略
调用预训练模型做微调,本质就是 用这些固定的结构+之前训练好的参数 接着训练
所以需要找到预训练的模型结构并且加载模型参数,相较于之前用自己定义的模型有以下几个注意点:
- 需要调用预训练模型和加载权重
- 需要resize 图片让其可以适配模型
- 需要修改最后的全连接层以适应数据集
其中,训练过程中,为了不破坏最开始的特征提取器的参数,最开始往往先冻结住特征提取器的参数,然后训练全连接层,大约在5-10个epoch后解冻训练
首先复用前几日的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 数据预处理(训练集增强,测试集标准化)
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=train_transform
)
test_dataset = datasets.CIFAR10(
root='./data',
train=False,
transform=test_transform
)
# 3. 创建数据加载器(可调整batch_size)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4. 训练函数(支持学习率调度器)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):
model.train() # 设置为训练模式
train_loss_history = []
test_loss_history = []
train_acc_history = []
test_acc_history = []
all_iter_losses = []
iter_indices = []
for epoch in range(epochs):
running_loss = 0.0
correct_train = 0
total_train = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 记录Iteration损失
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append(epoch * len(train_loader) + batch_idx + 1)
# 统计训练指标
running_loss += iter_loss
_, predicted = output.max(1)
total_train += target.size(0)
correct_train += predicted.eq(target).sum().item()
# 每100批次打印进度
if (batch_idx + 1) % 100 == 0:
print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "
f"| 单Batch损失: {iter_loss:.4f}")
# 计算 epoch 级指标
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct_train / total_train
# 测试阶段
model.eval()
correct_test = 0
total_test = 0
test_loss = 0.0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
# 记录历史数据
train_loss_history.append(epoch_train_loss)
test_loss_history.append(epoch_test_loss)
train_acc_history.append(epoch_train_acc)
test_acc_history.append(epoch_test_acc)
# 更新学习率调度器
if scheduler is not None:
scheduler.step(epoch_test_loss)
# 打印 epoch 结果
print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "
f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")
# 绘制损失和准确率曲线
plot_iter_losses(all_iter_losses, iter_indices)
plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)
return epoch_test_acc # 返回最终测试准确率
# 5. 绘制Iteration损失曲线
def plot_iter_losses(losses, indices):
plt.figure(figsize=(10, 4))
plt.plot(indices, losses, 'b-', alpha=0.7)
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('训练过程中的Iteration损失变化')
plt.grid(True)
plt.show()
# 6. 绘制Epoch级指标曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):
epochs = range(1, len(train_acc) + 1)
plt.figure(figsize=(12, 5))
# 准确率曲线
plt.subplot(1, 2, 1)
plt.plot(epochs, train_acc, 'b-', label='训练准确率')
plt.plot(epochs, test_acc, 'r-', label='测试准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率 (%)')
plt.title('准确率随Epoch变化')
plt.legend()
plt.grid(True)
# 损失曲线
plt.subplot(1, 2, 2)
plt.plot(epochs, train_loss, 'b-', label='训练损失')
plt.plot(epochs, test_loss, 'r-', label='测试损失')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.title('损失值随Epoch变化')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()再引入进入的模型
# 导入ResNet模型
from torchvision.models import resnet18
# 定义ResNet18模型(支持预训练权重加载)
def create_resnet18(pretrained=True, num_classes=10):
# 加载预训练模型(ImageNet权重)
model = resnet18(pretrained=pretrained)
# 修改最后一层全连接层,适配CIFAR-10的10分类任务
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, num_classes)
# 将模型转移到指定设备(CPU/GPU)
model = model.to(device)
return model# 创建ResNet18模型(加载ImageNet预训练权重,不进行微调)
model = create_resnet18(pretrained=True, num_classes=10)
model.eval() # 设置为推理模式
# 测试单张图片(示例)
from torchvision import utils
# 从测试数据集中获取一张图片
dataiter = iter(test_loader)
images, labels = dataiter.next()
images = images[:1].to(device) # 取第1张图片
# 前向传播
with torch.no_grad():
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
# 显示图片和预测结果
plt.imshow(utils.make_grid(images.cpu(), normalize=True).permute(1, 2, 0))
plt.title(f"预测类别: {predicted.item()}")
plt.axis('off')
plt.show()
在 CIFAR-10 数据集中,类别标签是固定的 10 个,分别对应:
| 标签(数字) | 类别名称 | 说明 |
|---|---|---|
| 0 | airplane | 飞机 |
| 1 | automobile | 汽车(含轿车、卡车等) |
| 2 | bird | 鸟类 |
| 3 | cat | 猫 |
| 4 | deer | 鹿 |
| 5 | dog | 狗 |
| 6 | frog | 青蛙 |
| 7 | horse | 马 |
| 8 | ship | 船 |
| 9 | truck | 卡车(重型货车等) |
完整代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 数据预处理(训练集增强,测试集标准化)
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=train_transform
)
test_dataset = datasets.CIFAR10(
root='./data',
train=False,
transform=test_transform
)
# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4. 定义ResNet18模型
def create_resnet18(pretrained=True, num_classes=10):
model = models.resnet18(pretrained=pretrained)
# 修改最后一层全连接层
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, num_classes)
return model.to(device)
# 5. 冻结/解冻模型层的函数
def freeze_model(model, freeze=True):
"""冻结或解冻模型的卷积层参数"""
# 冻结/解冻除fc层外的所有参数
for name, param in model.named_parameters():
if 'fc' not in name:
param.requires_grad = not freeze
# 打印冻结状态
frozen_params = sum(p.numel() for p in model.parameters() if not p.requires_grad)
total_params = sum(p.numel() for p in model.parameters())
if freeze:
print(f"已冻结模型卷积层参数 ({frozen_params}/{total_params} 参数)")
else:
print(f"已解冻模型所有参数 ({total_params}/{total_params} 参数可训练)")
return model
# 6. 训练函数(支持阶段式训练)
def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, freeze_epochs=5):
"""
前freeze_epochs轮冻结卷积层,之后解冻所有层进行训练
"""
train_loss_history = []
test_loss_history = []
train_acc_history = []
test_acc_history = []
all_iter_losses = []
iter_indices = []
# 初始冻结卷积层
if freeze_epochs > 0:
model = freeze_model(model, freeze=True)
for epoch in range(epochs):
# 解冻控制:在指定轮次后解冻所有层
if epoch == freeze_epochs:
model = freeze_model(model, freeze=False)
# 解冻后调整优化器(可选)
optimizer.param_groups[0]['lr'] = 1e-4 # 降低学习率防止过拟合
model.train() # 设置为训练模式
running_loss = 0.0
correct_train = 0
total_train = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 记录Iteration损失
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append(epoch * len(train_loader) + batch_idx + 1)
# 统计训练指标
running_loss += iter_loss
_, predicted = output.max(1)
total_train += target.size(0)
correct_train += predicted.eq(target).sum().item()
# 每100批次打印进度
if (batch_idx + 1) % 100 == 0:
print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "
f"| 单Batch损失: {iter_loss:.4f}")
# 计算 epoch 级指标
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct_train / total_train
# 测试阶段
model.eval()
correct_test = 0
total_test = 0
test_loss = 0.0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
# 记录历史数据
train_loss_history.append(epoch_train_loss)
test_loss_history.append(epoch_test_loss)
train_acc_history.append(epoch_train_acc)
test_acc_history.append(epoch_test_acc)
# 更新学习率调度器
if scheduler is not None:
scheduler.step(epoch_test_loss)
# 打印 epoch 结果
print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "
f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")
# 绘制损失和准确率曲线
plot_iter_losses(all_iter_losses, iter_indices)
plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)
return epoch_test_acc # 返回最终测试准确率
# 7. 绘制Iteration损失曲线
def plot_iter_losses(losses, indices):
plt.figure(figsize=(10, 4))
plt.plot(indices, losses, 'b-', alpha=0.7)
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('训练过程中的Iteration损失变化')
plt.grid(True)
plt.show()
# 8. 绘制Epoch级指标曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):
epochs = range(1, len(train_acc) + 1)
plt.figure(figsize=(12, 5))
# 准确率曲线
plt.subplot(1, 2, 1)
plt.plot(epochs, train_acc, 'b-', label='训练准确率')
plt.plot(epochs, test_acc, 'r-', label='测试准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率 (%)')
plt.title('准确率随Epoch变化')
plt.legend()
plt.grid(True)
# 损失曲线
plt.subplot(1, 2, 2)
plt.plot(epochs, train_loss, 'b-', label='训练损失')
plt.plot(epochs, test_loss, 'r-', label='测试损失')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.title('损失值随Epoch变化')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 主函数:训练模型
def main():
# 参数设置
epochs = 40 # 总训练轮次
freeze_epochs = 5 # 冻结卷积层的轮次
learning_rate = 1e-3 # 初始学习率
weight_decay = 1e-4 # 权重衰减
# 创建ResNet18模型(加载预训练权重)
model = create_resnet18(pretrained=True, num_classes=10)
# 定义优化器和损失函数
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
criterion = nn.CrossEntropyLoss()
# 定义学习率调度器
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, mode='min', factor=0.5, patience=2, verbose=True
)
# 开始训练(前5轮冻结卷积层,之后解冻)
final_accuracy = train_with_freeze_schedule(
model=model,
train_loader=train_loader,
test_loader=test_loader,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
device=device,
epochs=epochs,
freeze_epochs=freeze_epochs
)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
# # 保存模型
# torch.save(model.state_dict(), 'resnet18_cifar10_finetuned.pth')
# print("模型已保存至: resnet18_cifar10_finetuned.pth")
if __name__ == "__main__":
main()使用设备: cuda
Files already downloaded and verified
c:\Anaconda\envs\DL\lib\site-packages\torch\optim\lr_scheduler.py:60: UserWarning: The verbose parameter is deprecated. Please use get_last_lr() to access the learning rate.
warnings.warn(
已冻结模型卷积层参数 (11176512/11181642 参数)
Epoch 1/40 | Batch 100/782 | 单Batch损失: 2.2301
Epoch 1/40 | Batch 200/782 | 单Batch损失: 1.9047
Epoch 1/40 | Batch 300/782 | 单Batch损失: 2.0831
Epoch 1/40 | Batch 400/782 | 单Batch损失: 2.0294
Epoch 1/40 | Batch 500/782 | 单Batch损失: 1.7660
Epoch 1/40 | Batch 600/782 | 单Batch损失: 1.8659
Epoch 1/40 | Batch 700/782 | 单Batch损失: 1.9069
Epoch 1 完成 | 训练损失: 1.9640 | 训练准确率: 30.09% | 测试准确率: 32.75%
Epoch 2/40 | Batch 100/782 | 单Batch损失: 1.6709
Epoch 2/40 | Batch 200/782 | 单Batch损失: 1.7708
Epoch 2/40 | Batch 300/782 | 单Batch损失: 1.8353
Epoch 2/40 | Batch 400/782 | 单Batch损失: 1.8147
Epoch 2/40 | Batch 500/782 | 单Batch损失: 1.8067
Epoch 2/40 | Batch 600/782 | 单Batch损失: 1.8199
Epoch 2/40 | Batch 700/782 | 单Batch损失: 1.9479
Epoch 2 完成 | 训练损失: 1.8635 | 训练准确率: 33.79% | 测试准确率: 33.98%
Epoch 3/40 | Batch 100/782 | 单Batch损失: 1.8692
Epoch 3/40 | Batch 200/782 | 单Batch损失: 1.7893
Epoch 3/40 | Batch 300/782 | 单Batch损失: 2.1315
Epoch 3/40 | Batch 400/782 | 单Batch损失: 1.9746
Epoch 3/40 | Batch 500/782 | 单Batch损失: 2.0423
Epoch 3/40 | Batch 600/782 | 单Batch损失: 1.9579
Epoch 3/40 | Batch 700/782 | 单Batch损失: 2.0273
Epoch 3 完成 | 训练损失: 1.8528 | 训练准确率: 34.39% | 测试准确率: 34.93%
...
Epoch 40/40 | Batch 500/782 | 单Batch损失: 0.2173
Epoch 40/40 | Batch 600/782 | 单Batch损失: 0.2623
Epoch 40/40 | Batch 700/782 | 单Batch损失: 0.2519
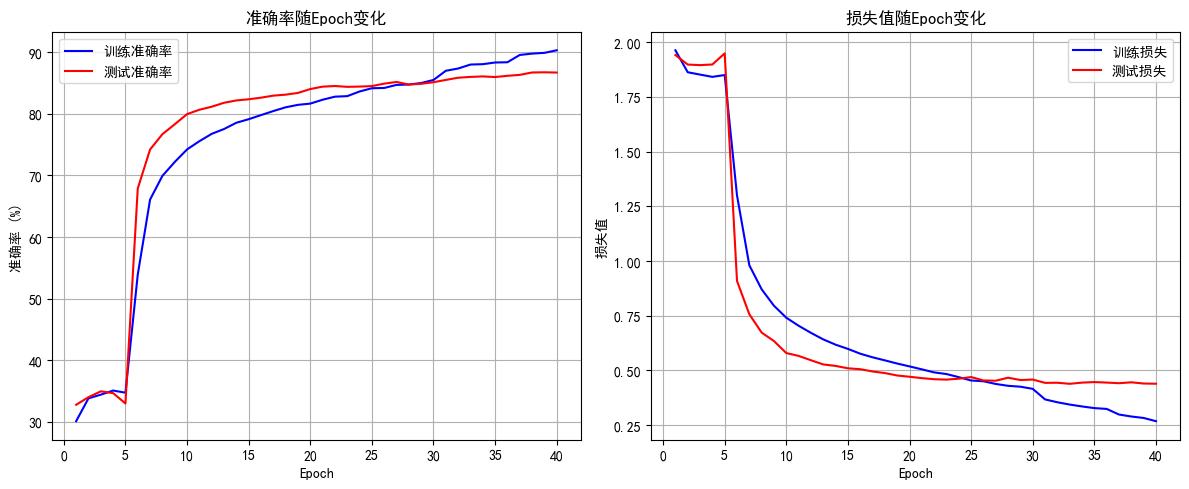
Epoch 40 完成 | 训练损失: 0.2682 | 训练准确率: 90.31% | 测试准确率: 86.69%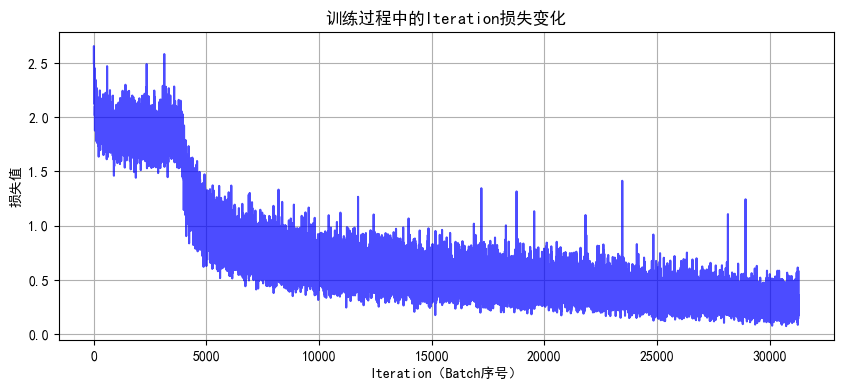


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)