低光图像增强-MSRCP
在前文我们已经详细说明了SSR单尺度低光图像增强算法了,作为一种传统的低光图像增强算法,SSR只能作为理论学习的算法,帮助我们了解视网膜算法,学习颜色恒常性理论知识,SSR是不足以算真正的图像增强算法的,MSR和MSRCP才是实际应用中真正使用到的低光图像增强算法,也就是我们常说的Retinex算法,但其实只要前面学习过SSR的,这一块就比较简单了,MSR多尺度低光图像增强算法,顾名思义就是多个
一、概述
在前文我们已经详细说明了SSR单尺度低光图像增强算法了,作为一种传统的低光图像增强算法,SSR只能作为理论学习的算法,帮助我们了解视网膜算法,学习颜色恒常性理论知识,SSR是不足以算真正的图像增强算法的,MSR和MSRCP才是实际应用中真正使用到的低光图像增强算法,也就是我们常说的Retinex算法,但其实只要前面学习过SSR的,这一块就比较简单了,MSR多尺度低光图像增强算法,顾名思义就是多个 SSR 的加权和,SSR只有一个,如果
选的比较大,虽然能够增强局部对比度,但也会导致噪声增大,边缘锐化。如果选的
比较小,全局亮度比较好,但局部细节会有所缺失,MSR正是通过使用多个
进行加权求和,MSR 是多尺度光照补偿的稳健融合。那MSRCP是什么呢?其实他和MSR差不多,但MSRCP 在 Retinex 增强亮度和对比度的同时,有效保持颜色比例,避免颜色失真,具有良好的稳定性和视觉一致性。下面我将具体说明三种算法。
二、单尺度SSR低光图像增强算法
前文已经写过了,这里不多说了,SSR其实就是通过高斯模糊来估计光照分量,然后通过减去光照分量得到反射分量,而反射分量正是模拟我们人眼视网膜所看到的图像,具有颜色恒常性,不会随光照的变换而改变它的颜色。具体代码如下:
#include <opencv2/opencv.hpp>
#include <iostream>
// SSR 单尺度 Retinex
cv::Mat SSR(const cv::Mat& srcGray, double sigma)
{
CV_Assert(srcGray.channels() == 1);
// 1. 转 double
cv::Mat img;
srcGray.convertTo(img, CV_64F);
// 2. 高斯模糊(估计光照)
cv::Mat blur;
int ksize = int(6 * sigma + 1) | 1; // 保证为奇数
cv::GaussianBlur(img, blur, cv::Size(ksize, ksize), sigma);
// 3. Retinex 核心公式
cv::Mat retinex;
cv::log(img + 1.0, img);
cv::log(blur + 1.0, blur);
retinex = img - blur;
// 4. 动态范围压缩(归一化)
double minVal, maxVal;
cv::minMaxLoc(retinex, &minVal, &maxVal);
retinex = (retinex - minVal) * 255.0 / (maxVal - minVal + 1e-6);
// 5. 转回 8-bit
cv::Mat dst;
retinex.convertTo(dst, CV_8UC1);
return dst;
}
三、MSRCP彩色图像增强恢复算法
MSR其实就是在SSR的基础上进行多个进行加权求和,而MSRCP其实就是做了一个图像恢复,这里我们提供一个代码,代码如下:
cv::Mat MSRCP(const cv::Mat& image, std::vector<double>& sigmas, std::vector<double>& weights, int kSize)
{
CV_Assert(sigmas.size() == weights.size());
if (image.channels() == 1)
{
cv::Mat msr = cv::Mat::zeros(image.size(), CV_64F);
for (size_t i = 0; i < sigmas.size(); ++i)
msr += weights[i] * SSR(image, sigmas[i], kSize);
return postProcess(msr, 0.01);
}
// 彩色图
std::vector<cv::Mat> channels;
cv::split(image, channels);
cv::Mat avg = (channels[0] + channels[1] + channels[2]) / 3.0;
avg.convertTo(avg, CV_64F);
cv::Mat Lmsr = cv::Mat::zeros(avg.size(), CV_64F);
for (size_t i = 0; i < sigmas.size(); ++i)
Lmsr += weights[i] * SSR(avg, sigmas[i], kSize);
Lmsr = postProcess(Lmsr, 0.01);
Lmsr.convertTo(Lmsr, CV_64F);
std::vector<cv::Mat> out(3);
for (int c = 0; c < 3; ++c)
{
cv::Mat ch;
channels[c].convertTo(ch, CV_64F);
out[c] = ch.mul(Lmsr) / (avg + 1e-6);
out[c].setTo(0, out[c] < 0);
out[c].setTo(255, out[c] > 255);
out[c].convertTo(out[c], CV_8UC1);
}
cv::Mat dst;
cv::merge(out, dst);
return dst;
}五、后处理
这里我们不采用和SSR算法一样,直接使用normalize归一化到[0,255]之间,而是采用过程化的后处理方式,因为Retinex算法得到的是对数域下的反射分量,数值分布通常长尾、非对称、含强噪声和极端亮暗点。如果直接用 cv::normalize(min-max),最大值和最小值往往由极少数噪声像素或高光点决定,导致大部分像素被压缩到很窄的灰度范围里,画面发灰、对比度不足。我们采用先按百分位裁掉两端的异常值(cut),再在“可信区间”内做线性拉伸,相当于一种鲁棒的动态范围压缩,这是 Retinex 系列论文和工程实现中最常见、最稳定的做法,比直接 normalize 更符合人眼感知。代码如下:
// 后处理
cv::Mat postProcess(const cv::Mat& channel, double cut)
{
cv::Mat result = channel.clone();
cv::Mat flat = result.reshape(1, 1).clone();
cv::sort(flat, flat, cv::SORT_ASCENDING);
int total = flat.cols;
int low_idx = std::min(std::max(0, int(total * cut)), total - 1);
int high_idx = std::min(std::max(0, int(total * (1 - cut))), total - 1);
double lowVal = flat.at<double>(0, low_idx);
double highVal = flat.at<double>(0, high_idx);
double scale = 255.0 / (highVal - lowVal + 1e-6); // 归一化到255上
result = (result - lowVal) * scale;
result.setTo(0, result < 0);
result.setTo(255, result > 255);
result.convertTo(result, CV_8UC1);
return result;
}
六、测试
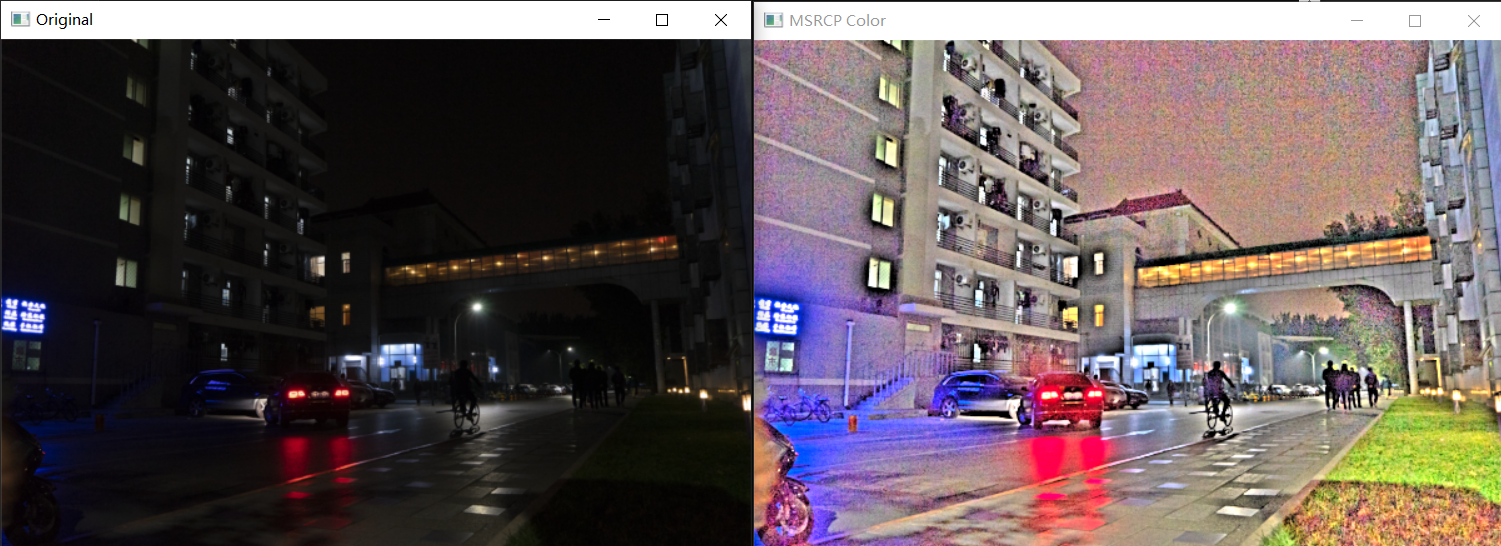
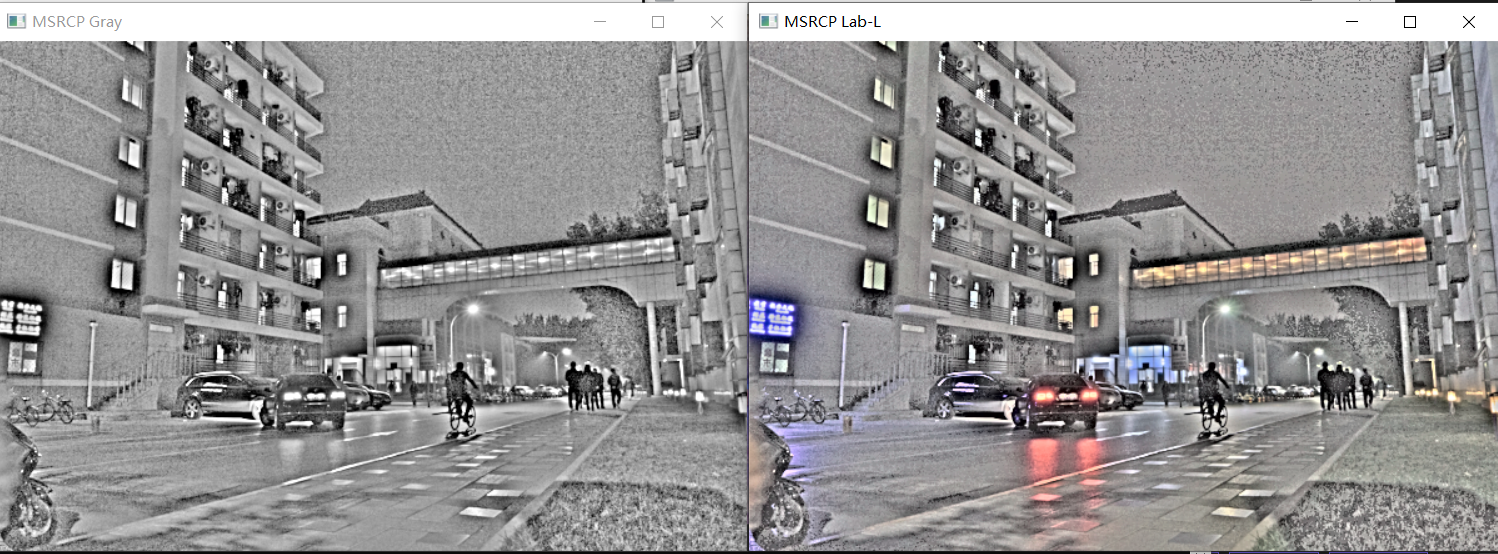

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)