详解深度学习中的Normalization,BN/LN/WN
其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。独立同分布并非所有机器学习模型的必然要求(比如 Naive Bayes 模型就建立在特征彼此独立的基础之上,而Logistic Regression 和 神经网络 则在非独立的特征数据上依然可以训练出很好
深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Batch Norm 大法自 2015 年由Google 提出之后,就成为深度学习必备之神器。自 BN 之后, Layer Norm / Weight Norm / Cosine Norm 等也横空出世。本文从 Normalization 的背景讲起,用一个公式概括 Normalization 的基本思想与通用框架,将各大主流方法一一对号入座进行深入的对比分析,并从参数和数据的伸缩不变性的角度探讨 Normalization 有效的深层原因。
1. 为什么需要 Normalization
1.1 独立同分布与白化
机器学习界的炼丹师们最喜欢的数据有什么特点?窃以为,莫过于“独立同分布”了,即independent and identically distributed,简称为 i.i.d. 独立同分布并非所有机器学习模型的必然要求(比如 Naive Bayes 模型就建立在特征彼此独立的基础之上,而Logistic Regression 和 神经网络 则在非独立的特征数据上依然可以训练出很好的模型),但独立同分布的数据可以简化常规机器学习模型的训练、提升机器学习模型的预测能力,已经是一个共识。
因此,在把数据喂给机器学习模型之前,“白化(whitening)”是一个重要的数据预处理步骤。白化一般包含两个目的:
(1)去除特征之间的相关性 —> 独立;
(2)使得所有特征具有相同的均值和方差 —> 同分布。
白化最典型的方法就是PCA,可以参考阅读 PCAWhitening。
1.2 深度学习中的 Internal Covariate Shift
深度神经网络模型的训练为什么会很困难?其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
Google 将这一现象总结为 Internal Covariate Shift,简称 ICS. 什么是 ICS 呢?
在一个回答中做出了一个很好的解释:

1.3 ICS 会导致什么问题?
简而言之,每个神经元的输入数据不再是“独立同分布”。
其一,上层参数需要不断适应新的输入数据分布,降低学习速度。
其二,下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止。
其三,每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。
2. Normalization 的通用框架与基本思想
我们以神经网络中的一个普通神经元为例。神经元接收一组输入向量

由于 ICS 问题的存在, x 的分布可能相差很大。要解决独立同分布的问题,“理论正确”的方法就是对每一层的数据都进行白化操作。然而标准的白化操作代价高昂,特别是我们还希望白化操作是可微的,保证白化操作可以通过反向传播来更新梯度。
因此,以 BN 为代表的 Normalization 方法退而求其次,进行了简化的白化操作。基本思想是:在将 x 送给神经元之前,先对其做平移和伸缩变换, 将 x 的分布规范化成在固定区间范围的标准分布。
通用变换框架就如下所示:
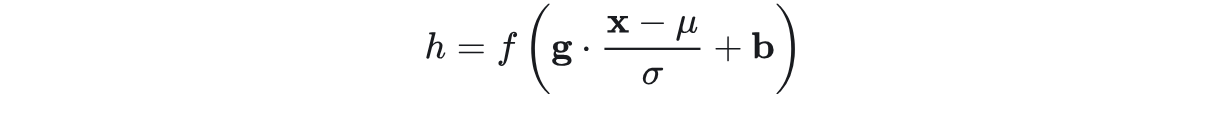
我们来看看这个公式中的各个参数。




除了充分利用底层学习的能力,另一方面的重要意义在于保证获得非线性的表达能力。Sigmoid 等激活函数在神经网络中有着重要作用,通过区分饱和区和非饱和区,使得神经网络的数据变换具有了非线性计算能力。而第一步的规范化会将几乎所有数据映射到激活函数的非饱和区(线性区),仅利用到了线性变化能力,从而降低了神经网络的表达能力。而进行再变换,则可以将数据从线性区变换到非线性区,恢复模型的表达能力。





其中 M 是 mini-batch 的大小。
按上图所示,相对于一层神经元的水平排列,BN 可以看做一种纵向的规范化。由于 BN 是针对单个维度定义的,因此标准公式中的计算均为 element-wise 的。

 3.2 Layer Normalization —— 横向规范化
3.2 Layer Normalization —— 横向规范化
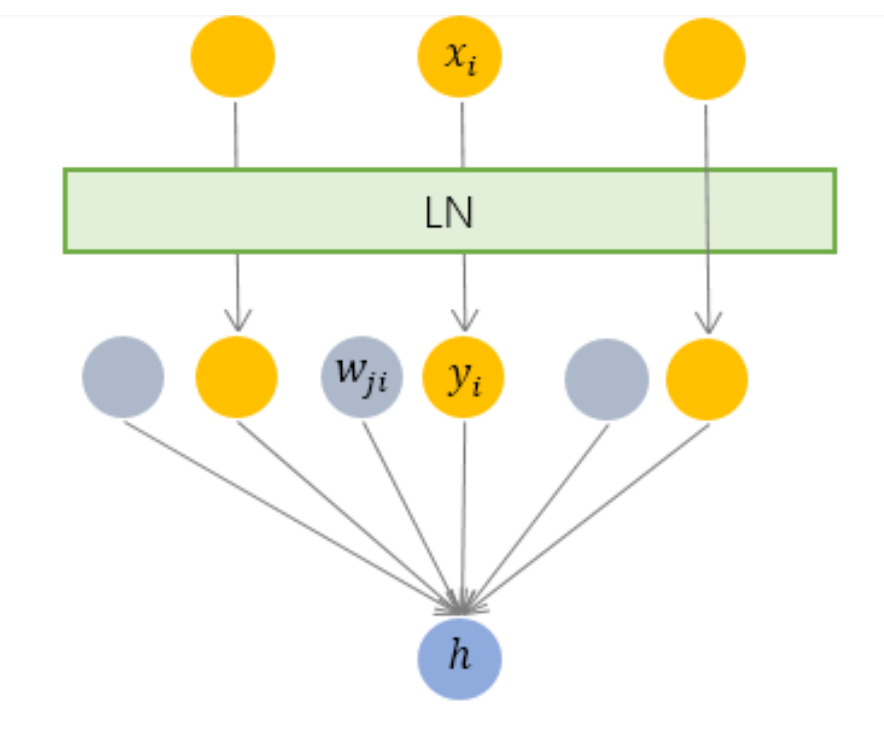
3.2 Layer Normalization —— 横向规范化
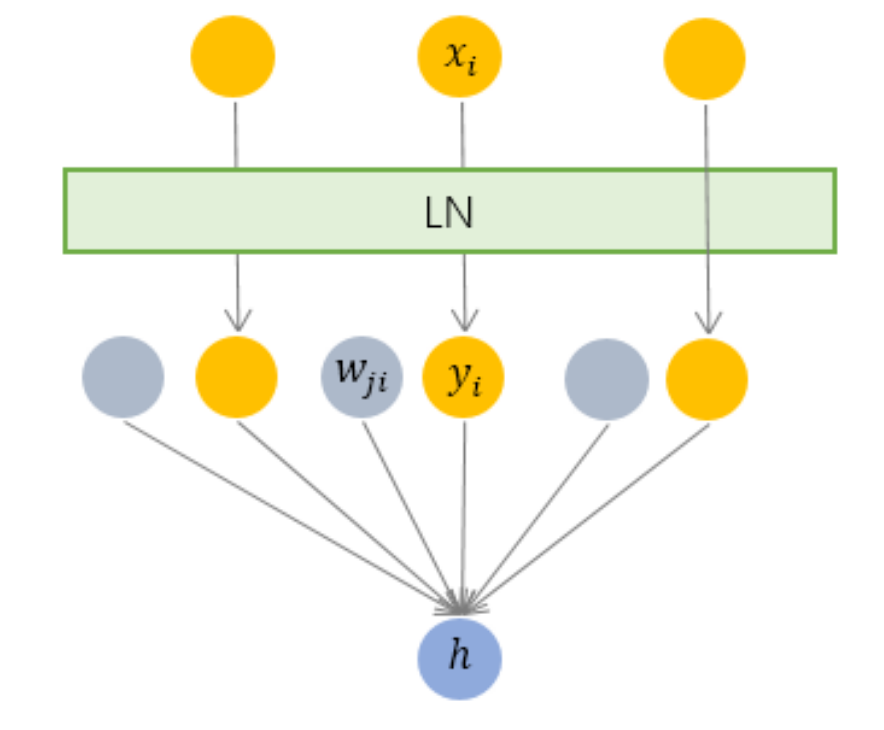
层规范化就是针对 BN 的上述不足而提出的。与 BN 不同,LN 是一种横向的规范化,如图所示。它综合考虑一层所有维度的输入,计算该层的平均输入值和输入方差,然后用同一个规范化操作来转换各个维度的输入。
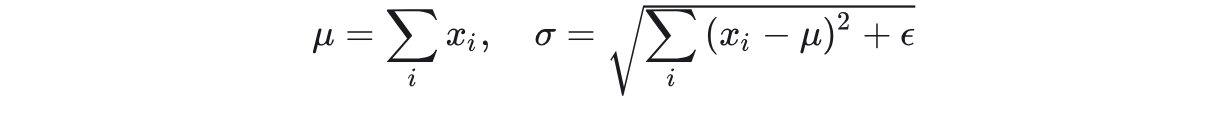



3.3 Weight Normalization —— 参数规范化
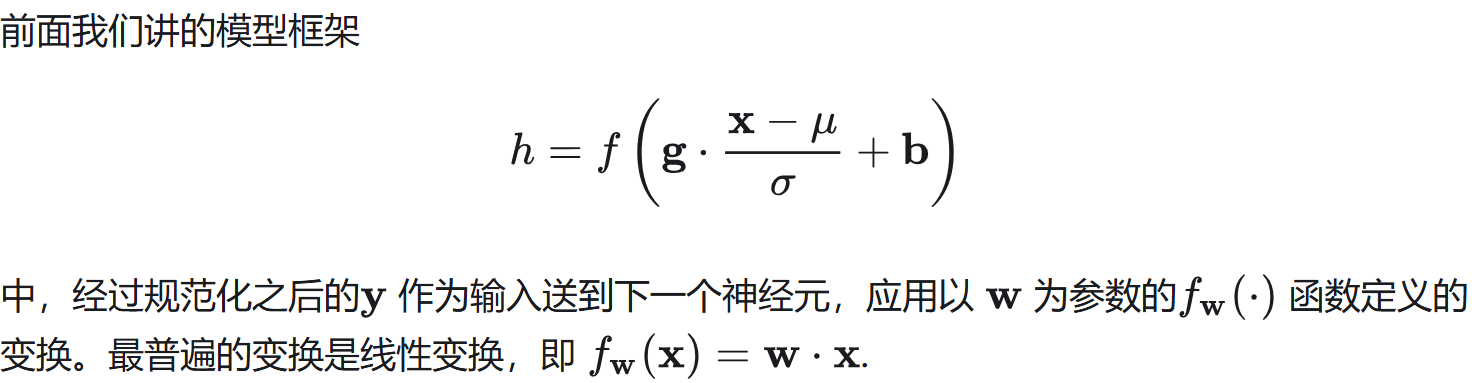



就完美地对号入座了!
回忆一下,BN 和 LN 是用输入的特征数据的方差对输入数据进行 scale,而 WN 则是用 神经元的权重的欧氏范式对输入数据进行 scale。虽然在原始方法中分别进行的是特征数据规范化和参数的规范化,但本质上都实现了对数据的规范化,只是用于 scale 的参数来源不同。


3.4 Cosine Normalization —— 余弦规范化
Normalization 还能怎么做?

然而天才的研究员们盯上了中间的那个点,对,就是

那怎么办呢?我们知道向量点积是衡量两个向量相似度的方法之一。哪还有没有其他的相似度衡量方法呢?有啊,很多啊!夹角余弦就是其中之一啊!而且关键的是,夹角余弦是有确定界的啊,[-1, 1] 的取值范围,多么的美好!仿佛看到了新的世界!



现在,BN, LN, WN 和 CN 之间的来龙去脉是不是清楚多了?
4. Normalization 为什么会有效?
我们以下面这个简化的神经网络为例来分析。
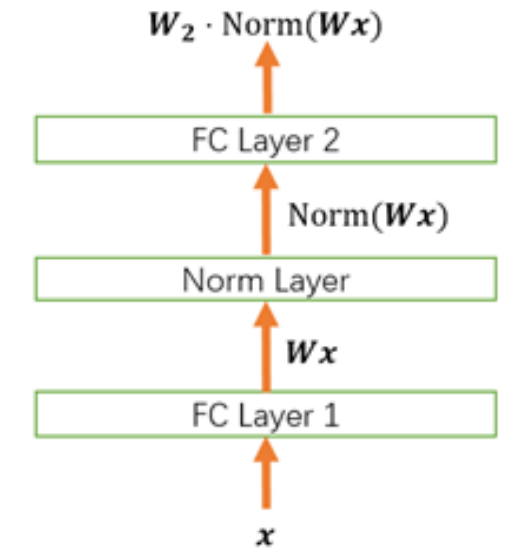


权重伸缩不变性可以有效地提高反向传播的效率。


4.2 Normalization 的数据伸缩不变性

数据伸缩不变性仅对 BN、LN 和 CN 成立。因为这三者对输入数据进行规范化,因此当数据进行常量伸缩时,其均值和方差都会相应变化,分子分母互相抵消。而 WN 不具有这一性质。


为什么用layer norm不用Batch norm
LN的主要作用是使得整个损失函数的曲线更为平滑,从而使得我们可以更平稳地进行训练。使用LN而不用BN处于以下几个角度的原因考虑:


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)