python八股【语言基础篇】(会写 python 但不知道原理的看过来)
多个任务在同一时间段内交替执行。
1. 解释性语言和编译型语言
编译型语言:将代码一次性翻译成机器码,然后执行——是再执行前先行编译(C、C++、Go、Rust)
解释型语言:将源代码一句一句解释成机器码并执行,开发效率比较高–python、javascript——是在执行期动态解释
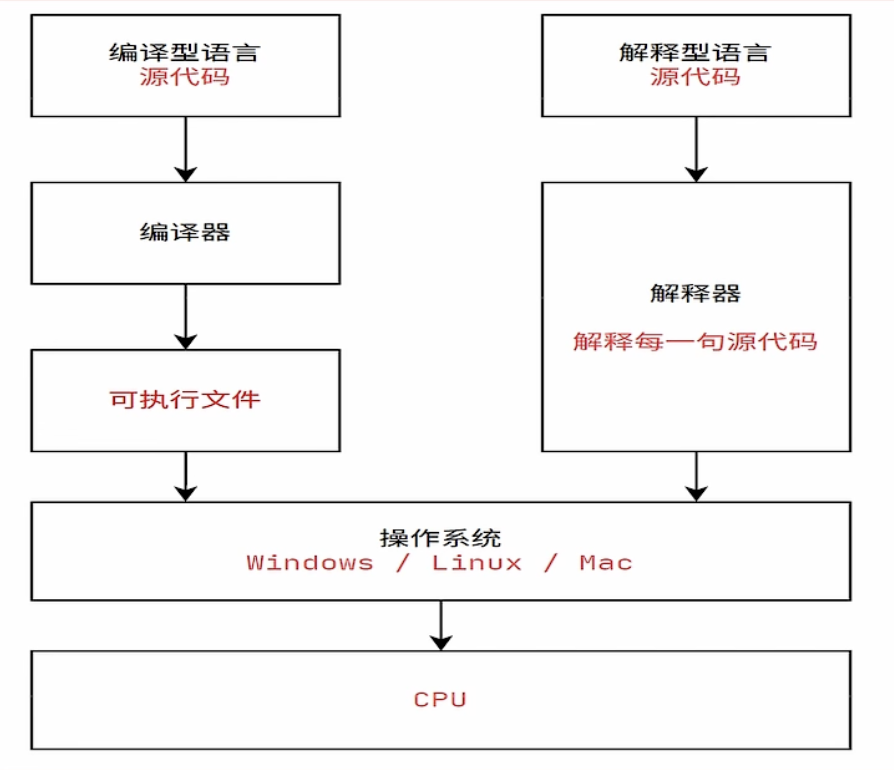
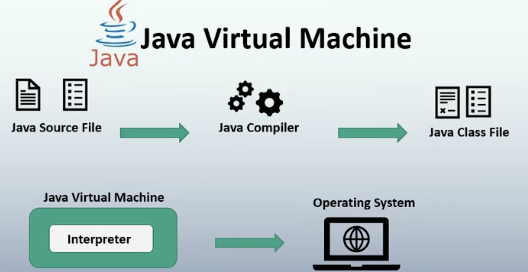
即时编译:让编译与解释并存,先把源代码编译成字节码,到执行期间将字节码直译然后执行
为什么要翻译成机器码才能执行?
计算机智能直接识别和执行特定的指令集,源代码本质上只是文本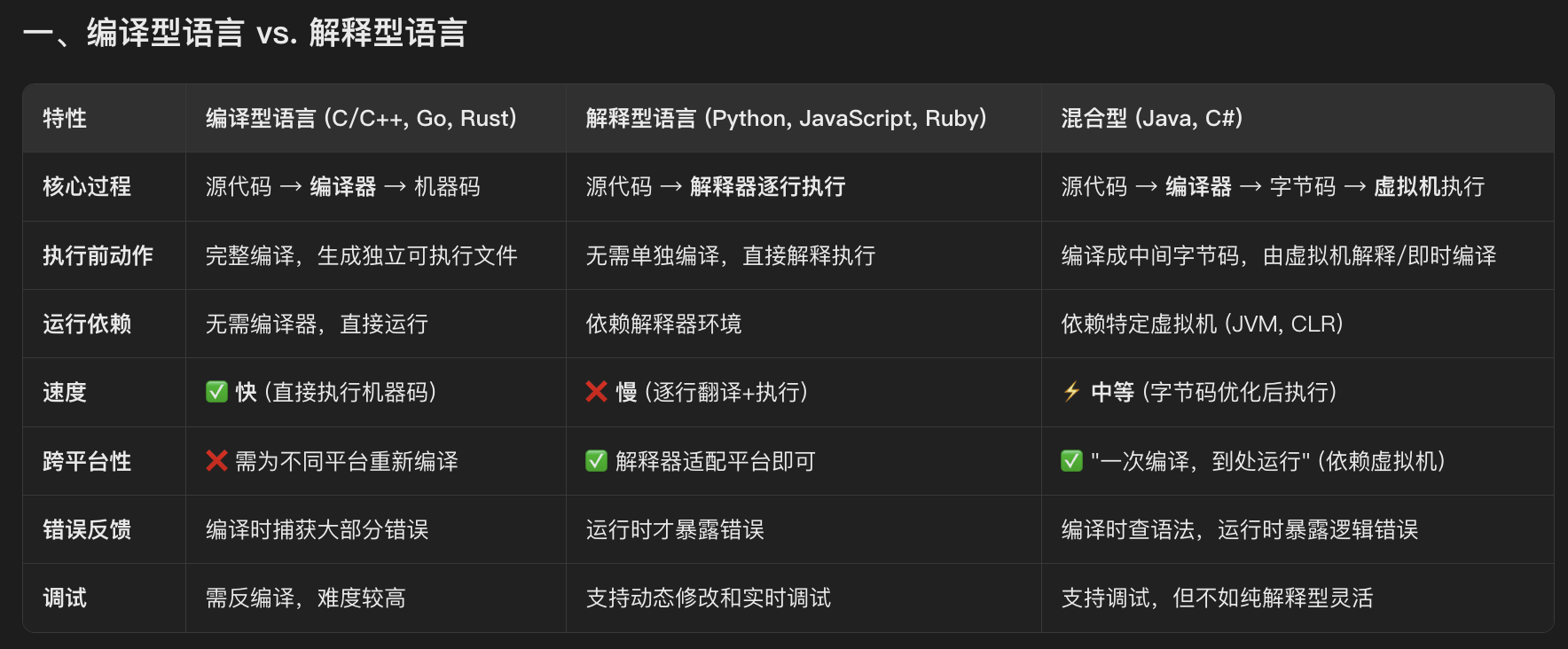
python 的解释性

无独立的编译环节,比如用户运行 python test.py 的时候,源码动态翻译为字节码(.pyc),由 python 虚拟机(PVM)执行,没有独立编译步骤
与GIL锁的关系
全局解释器锁(Global Interpreter Lock),是CPython(标准Python实现)中的一个互斥锁,同一时刻仅允许一个线程执行Python字节码。
- GIL 锁存在的原因
- python 的解释型设计
- 管理内存的方式: 这种解释执行,配合它简单高效的引用计数内存管理机制(但计数操作是频繁且需要绝对同步的)。
- GIL 诞生: 为了保证在解释执行这个动态环境下,对引用计数的修改绝对安全(避免多线程同时修改导致数据竞争崩溃),需要一把全局大锁(GIL) 来强制同一时刻只能有一个线程在执行 Python 字节码(操作引用计数)。为保证引用计数安全,CPython用全局解释器锁(GIL)强制同一时刻只有一个线程能执行字节码,避免竞争。
- 代价出现: 这把锁(GIL)也就成了 Python 实现真正 CPU 并行多线程编程(充分利用多核)的最大阻碍。
- python 的解释型设计
- 引用计数管理内存
a = [1, 2, 3] # 列表的引用计数 = 1(变量a指向它)
b = a # 引用计数 +1 → 变为2(b也指向同一列表)
del a # 引用计数 -1 → 回到1(只剩b指向它)
b = None # 引用计数 -1 → 变为0 → 列表被销毁
2. python的内存管理和垃圾回收机制
Python 的内存管理和垃圾回收机制是为了确保程序能够高效地使用内存并防止内存泄漏。它通过几个关键机制来自动管理内存:内存分配、引用计数、垃圾回收(GC)、以及内存池。下面是对这些机制的详细讲解:
(1)内存分配
Python 的内存分配主要由 CPython(Python 的标准实现)进行管理,使用了 堆内存 和 栈内存。
- 堆内存:用于动态分配内存空间。所有对象(如列表、字典、类实例等)都会在堆上分配内存。
- 栈内存:用于存储局部变量和函数调用的信息,栈内存管理简单而高效,但栈的空间是有限的。
(2)引用计数(Reference Counting)
Python 使用 引用计数 来管理内存,这意味着每个对象都有一个引用计数器,表示当前有多少个引用指向该对象。
import sys
# 创建对象
a = [1, 2, 3] # 引用计数 = 1
print(sys.getrefcount(a)) # 输出:2(函数调用时增加临时引用)
# 增加引用
b = a # 引用计数 = 3
c = b # 引用计数 = 4
# 减少引用
del b # 引用计数 = 3
c = None # 引用计数 = 2
del a # 引用计数 = 1 → 0 时回收
- 每当创建一个新的引用指向对象时,引用计数增加。
- 每当引用超出作用域或被删除时,引用计数减少。
- 当引用计数为 0 时,表示对象不再被任何地方引用,Python 会自动回收该对象的内存。
优点:
- 通过引用计数可以实时管理内存,几乎是即时的,不需要等待。
缺点:
- 循环引用:如果两个或多个对象相互引用(形成循环),即使它们不再使用,引用计数也不会归零,导致内存泄漏。
(3)垃圾回收(Garbage Collection, GC)
- 引用计数
- 引用计数为 0 被清除
- 标记清除机制
- 标记清除算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。
- 它分为两个阶段:第一阶段是标记阶段,GC 会把所有的 活动对象 打上标记,第二阶段是把那些没有标记的对象 非活动对象 进行回收。那么 GC 又是如何判断哪些是活动对象哪些是非活动对象的呢?
- 对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。
- 分代技术
- 垃圾回收是基于 分代收集(Generational Garbage Collection) 算法实现的。
- 分代收集:Python 的垃圾回收器将对象分为三代:年轻代(Generation 0)、中年代(Generation 1)和老年代(Generation 2)。新创建的对象先进入年轻代,经过一定次数的垃圾回收后,如果对象仍然存在,会被提升到更高的代。
- 年轻代:主要用于存储短生命周期的对象,回收频繁。
- 中年代:存储生命周期较长的对象。
- 老年代:存储生命周期最长的对象,回收较少。
- 垃圾回收流程:
- 在每一代的垃圾回收过程中,Python 会扫描所有对象,检查它们是否被引用。
- 在年轻代中,Python 会频繁进行垃圾回收,因为大多数对象生命周期很短。
- 如果年轻代的对象经过多次垃圾回收仍然存活,它们会被提升到中年代,接着再到老年代。
- 垃圾回收触发机制:
- Python 的垃圾回收器是周期性的,会在满足一定条件时自动运行。例如,当内存分配超过一定阈值时,垃圾回收器会被触发。
- 对象的引用计数为零时,它会立即被销毁,但如果发生循环引用,GC 才会被启动进行清理。
(4)内存池机制(Object Pooling)
为了提高性能,Python 使用 内存池 来管理小对象的内存(如整数、字符串)。这些对象被存储在一个内存池中,而不是每次都重新分配内存。
- 小对象:例如小整数和小字符串(在 CPython 中,小于 256 的整数和短小的字符串是常驻内存的)。
- 内存池:通过内存池机制,Python 减少了内存的频繁分配和回收,提高了性能。
- 小对象分配(<512字节):
使用PyMalloc分配器
基于预先分配的内存池(arenas)
提高小对象分配效率,减少系统调用
- 大对象分配(≥512字节):
直接调用操作系统的malloc()/free()
使用系统级内存管理器
(5)如何查看和手动控制内存管理
虽然 Python 会自动管理内存,但开发者仍然可以使用一些工具来帮助管理内存。
gc模块:提供了一些接口来手动控制垃圾回收,查看当前垃圾回收器的状态,或者强制进行垃圾回收。例如:
import gc
gc.collect() # 强制进行垃圾回收
sys模块:可以查看对象的引用计数:
import sys
sys.getrefcount(obj) # 查看对象 obj 的引用计数
3. 静态类型和动态类型
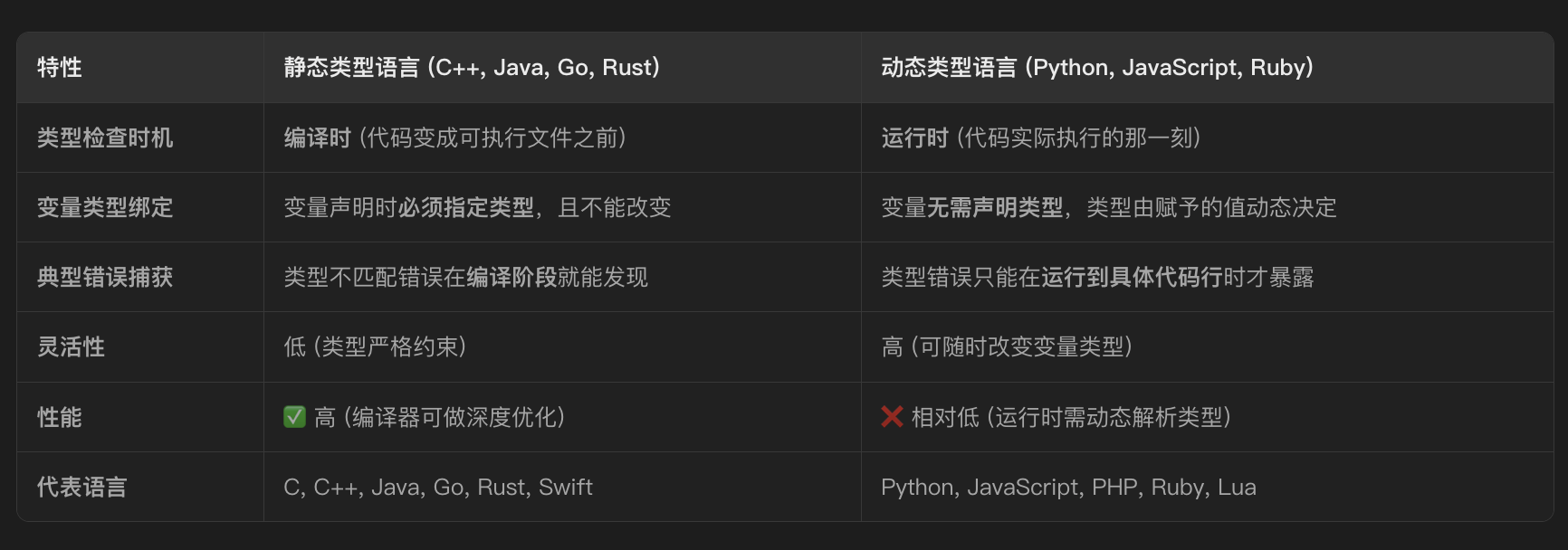
- 静态类型原理
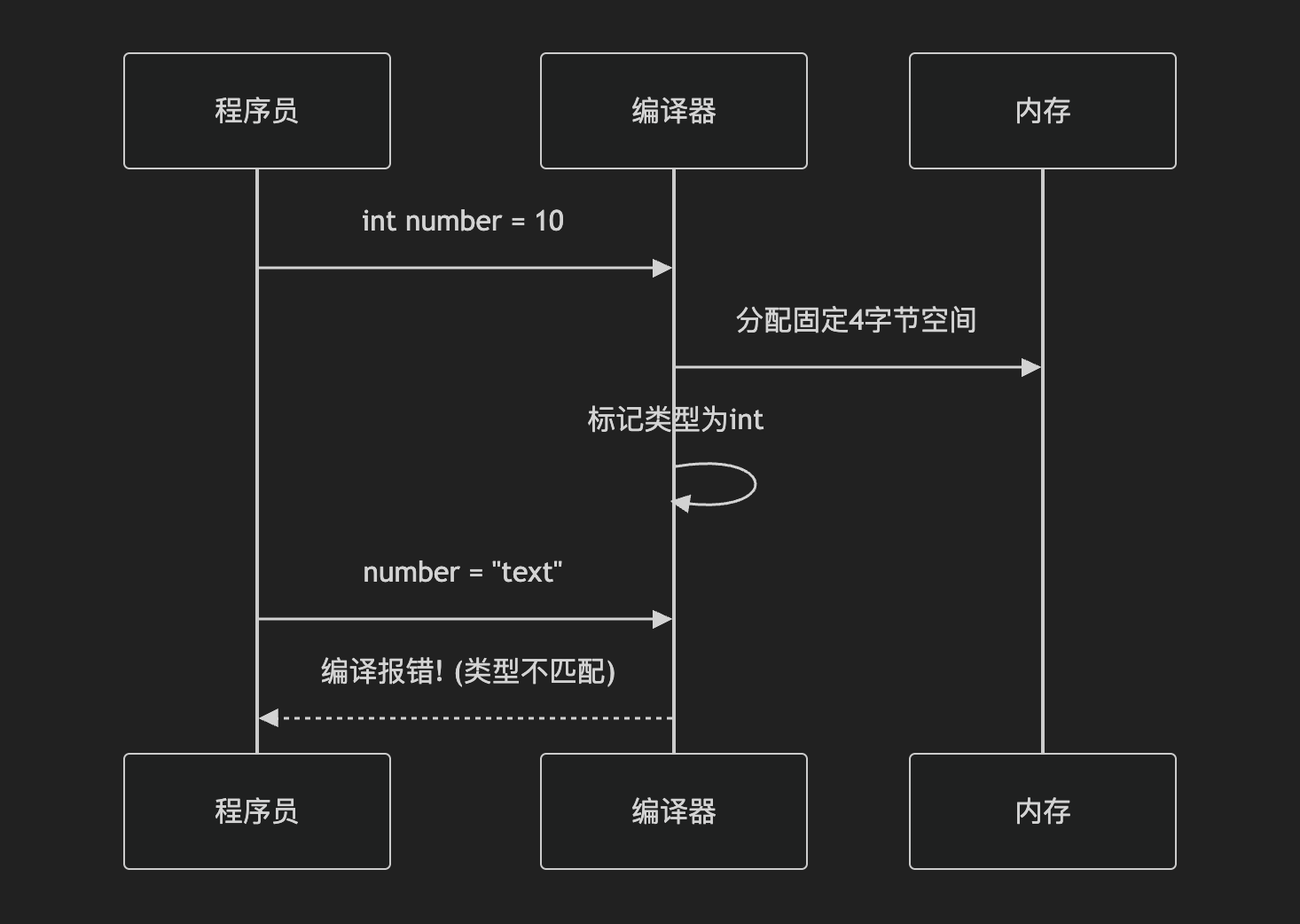
- 编译器创建符号表记录每个变量类型
- 生成的汇编执行包含类型信息
- 类型检查会再编译器完成
- 动态类型原理
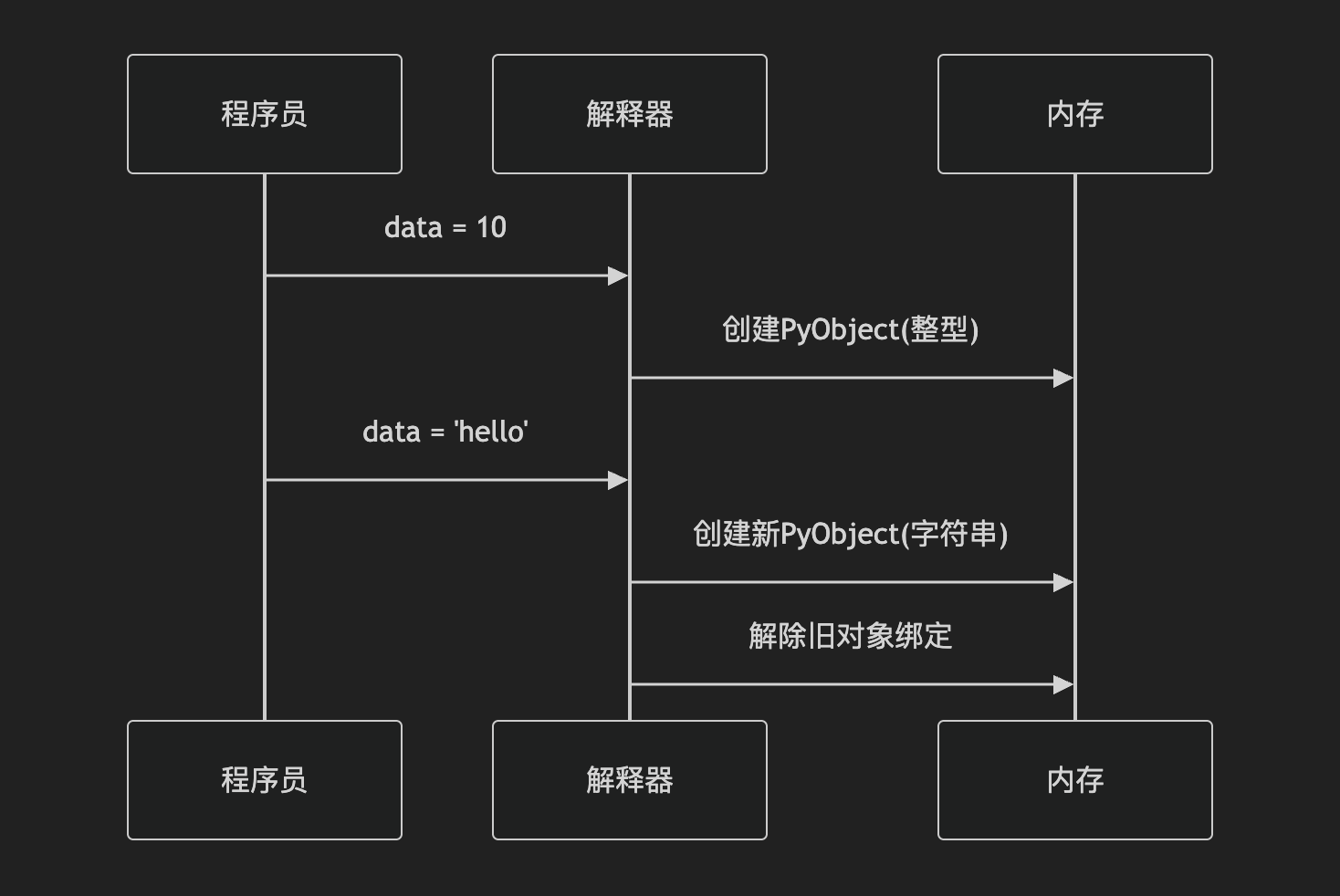
- 运行时动态判断
- 有统一的对象结构(PyObject)
- 动态按需分配 + 统一对象容器
- 为什么动态类型需要解释器?
- 动态类型要求 每次操作都检查类型,最适合解释器逐条执行的模式:
- 解释器可动态查询对象头部的类型指针
- 即时生成对应的机器指令
- 出现错误时能定位到具体行号
- 这种灵活性以 20-100倍的速度损失 为代价(需不断查类型指针+动态分派),但也成就了 Python 的简洁高效开发体验。两者取舍正是编程语言设计的永恒课题。
- 动态类型要求 每次操作都检查类型,最适合解释器逐条执行的模式:
- python 动态类型的原理
- - python变量执行的是内存地址
- python变量执行的是内存地址
内存如何变化(详细步骤)
步骤1:data = 42时
内存地址: 0x1000
+-----------------------+
| 引用计数 (refcount=1) |
+-----------------------+
| 类型指针 → int型 | # 指向int类型的描述符
+-----------------------+
| 值: 42 |
+-----------------------+
变量data → 地址0x1000
步骤2:data = "我是文字"时
# 新建字符串对象
内存地址: 0x2000
+-----------------------+
| 引用计数 (refcount=1) |
+-----------------------+
| 类型指针 → str型 | # 指向str类型的描述符
+-----------------------+
| 长度: 4 (中文字符) |
| 编码: UTF-8 |
| 内容: '我是文字' |
+-----------------------+
变量data → 新地址0x2000
# 原整数对象
地址0x1000:
+-----------------------+
| 引用计数 (refcount=0) | # 无变量引用它了!
+-----------------------+
| ... (即将被内存回收) |
+-----------------------+
步骤3:垃圾回收启动
垃圾收集器巡查发现:
0x1000: refcount=0 → 立即回收内存空间
// CPython实现 (简化版)
typedef struct {
Py_ssize_t ob_refcnt; // 引用计数(4-8字节)
PyTypeObject *ob_type; // 类型指针(8字节)
// 以下为具体数据...
} PyObject;
// 例如整数对象:
typedef struct {
PyObject_HEAD // 上面两个字段
long ob_ival; // 整数值(8字节)
} PyIntObject;
// 字符串对象:
typedef struct {
PyObject_HEAD
Py_ssize_t length; // 字符长度
char *utf8; // UTF-8编码数据
// ...其他优化字段
} PyStringObject;
列表的内存
data = [42, '文本', 3.14]
变量区 (栈内存)
+-----------+---------+
| 变量名 | 地址 |
+-----------+---------+
| data | 0x3000 |
+-----------+---------+
堆内存对象 (地址0x3000: 列表对象)
+-------------------------+
| refcount=1 |
| type=PyList_Type |
| 分配空间=4 |
| 已用空间=3 |
| 元素指针[0] → 0x1000 | → 整数42
| 元素指针[1] → 0x2000 | → 字符串'文本'
| 元素指针[2] → 0x4000 | → 浮点数3.14
+-------------------------+
- 动态类型的问题和解决方案
- 动态类型存在的问题
- 可维护性劣化:
- 代码像天书: 别人写的函数,你不清楚参数该传字符串还是数字,返回的是字典还是对象,得多看代码或文档才能搞明白。
- 报错太‘惊喜’: 类型不对这种低级错误(比如用字符串去加数字),要到运行程序时才爆出来,调试起来麻烦,还影响系统稳定。
- 改代码怕‘地震’: 想改一个函数的参数类型,不敢改,怕其他地方没跟着改出问题,测试压力大。
- 脏数据‘埋雷’: API传进来的JSON、用户输入的数据,格式对不对、类型好不好,都得手动写代码去检查判断,又累又容易漏。
- 可维护性劣化:
- 解决方案
- Python 加入 typing 和 pydantic 是为了用静态类型检查和运行时数据验证,解决大型项目中动态类型带来的代码难读、易出错、难维护的问题,同时保持 Python 的灵活性。
-
typing: 给代码加“说明书”(类型提示),让 IDE 和工具帮你提前发现错误,代码更好读。
- typing解决前三个点:给代码加‘说明’,写上参数、变量该是什么类型(比如 name: str),让代码更好懂;用工具(如mypy)能在运行前就检查出类型错误(比如把数字塞给了要字符串的函数);改代码时工具能自动指出哪些地方需要跟着改。
-
pydantic: 主要管“数据进出”(API 请求、配置文件等),自动验证数据格式对不对、确保数据干净再给你用。
- 专门定义数据模型(比如API接口、配置文件长啥样);自动把原始数据(JSON、请求参数)转成Python对象,同时严格验证数据类型、格式对不对;碰到脏数据自动报错拦住,避免处理‘垃圾’进去导致程序崩溃。
-
- Python 加入 typing 和 pydantic 是为了用静态类型检查和运行时数据验证,解决大型项目中动态类型带来的代码难读、易出错、难维护的问题,同时保持 Python 的灵活性。
- 动态类型存在的问题
4. 强类型与弱类型
- 强类型和弱类型
- 强类型:更看重类型的“严格性”和“不容忍”。 它会严格控制不同类型之间如何交互,尤其是不允许(或不鼓励)进行未显式说明的类型转换。
- 弱类型:更看重类型的“灵活性”和“宽容度”。 它允许不同类型之间进行自动、隐式的转换(有时甚至是开发者未曾预料到的),以达到操作能够执行的目的。
- 强/弱类型 vs 静态/动态类型: 这是两个不同的、正交的概念。
- 静态/动态类型 关注的是类型检查发生的时机(编译时 vs 运行时)。
- 强/弱类型 关注的是类型规则执行的严格程度和隐式转换的宽容度。
- 因此,有 静态强类型 (Java, C#, Go), 动态强类型 (Python, Ruby), 静态弱类型 (C, C++ 通常认为是), 动态弱类型 (JavaScript, PHP)。
- TypeScript 是静态类型添加到动态弱类型语言 JavaScript 上的典范,但 TypeScript 自身(在严格模式下)更像静态强类型语言。
5. python 的数据结构类型(可变&不可变;有序&无序)
Python3 中有六个标准的数据类型:
- Number(数字)(包括整型、浮点型、复数、布尔型等)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
5.1 数据类型的可变与不可变
Python3 的六个标准数据类型中:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。

可变与不可变对象的原理
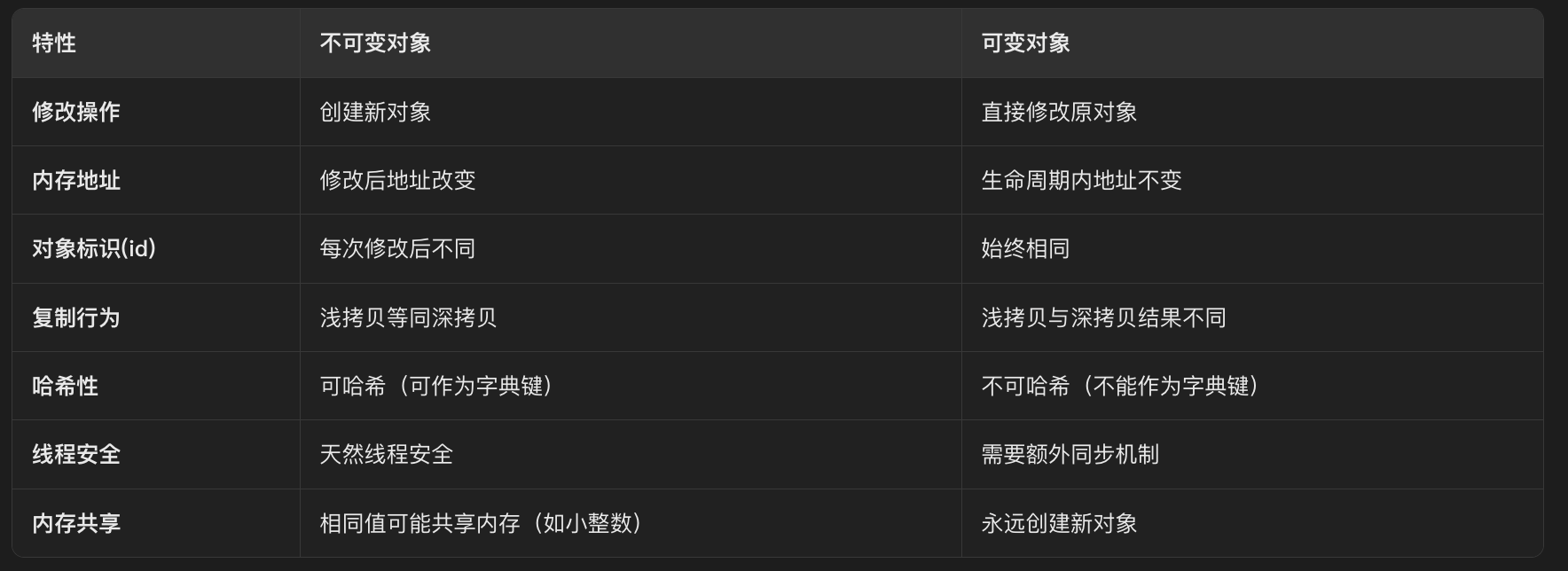
- 不可变对象:不可变类型的数据一旦被创建,其内容就不能改变。当你对一个不可变对象进行修改操作(比如字符串拼接),实际上是创建了一个新的对象,并将变量名绑定到新的对象上。
整数和字符串为例:
整数(int):在Python中,小整数(通常是-5到256)会被缓存,但大整数则不会。整数对象一旦创建,其值就不能改变。
字符串(str):字符串对象也是不可变的。当我们尝试修改字符串(如连接、替换等操作)时,实际上都是创建了一个新的字符串对象。
内存结构示例:
a = 10 # 创建一个整数对象10,变量a引用它
b = a # b也引用同一个整数对象10
a = 20 # 重新绑定a到新的整数对象20
# 字符串的例子
s = "hello"
t = s # s和t指向同一个字符串对象
s = s + " world" # 创建了一个新的字符串对象,s指向新的对象,而t仍然指向原来的"hello"
内部结构(以字符串为例)
Python中的字符串对象(CPython实现)内部结构:
struct PyStringObject {
PyObject_HEAD
Py_ssize_t length; // 字符串长度
char *value; // 指向实际字符数组的指针
// ... 其他字段(例如缓存哈希值)
};
当我们修改字符串时,实际上是创建了一个新的PyStringObject结构,并拷贝修改后的内容。
- 整形示例:
内存地址 0x1000:
+-------------------+
| 引用计数 (refcount) |
+-------------------+
| 类型指针 → int |
+-------------------+
| 值: 100 | # 整数值直接存储在对象内
+-------------------+
变量a → 0x1000
创建后内容不可更改
任何修改操作都创建新对象
节省内存(相同值可共享)
线程安全
- 字符串示例:
内存地址 0x2000:
+-------------------+
| 引用计数 (refcount) |
+-------------------+
| 类型指针 → str |
+-------------------+
| 长度: 4 |
| 哈希值: 12345678 | # 缓存哈希值提高效率
| 编码: LATIN1 |
| 实际字符数据 |
+-------------------+
s = "hello"
s += " world" # 看似修改,实则创建新对象
1. 创建新字符串对象 "hello world" 在地址 0x3000
2. 将变量 s 重定向到 0x3000
3. 原 "hello" 对象引用计数减1
- 可变对象:可变对象在创建后,其内容可以改变。当我们对可变对象进行修改操作时(如向列表添加元素),操作是在原对象上进行的,其内存地址不会改变。
- 列表对象内部维护了一个指向动态数组的指针。当我们添加或删除元素时,这个动态数组可能会重新分配(realloc)以调整大小,但列表对象本身的地址不变
Python中的列表对象(CPython实现)内部结构:
typedef struct {
PyObject_HEAD
Py_ssize_t allocated; // 已分配的内存空间(能够存储的元素个数)
PyObject **items; // 指向实际存储元素指针数组的指针
Py_ssize_t size; // 当前存储的元素个数(列表长度)
} PyListObject;
items指向一个指针数组,数组中的每个元素指向一个具体的Python对象(这些对象可以是任意类型,并且每个对象都是独立的,可以是可变或不可变)。
当列表需要扩展时,会重新分配一个更大的数组(比如加倍),然后将原数组的内容拷贝到新数组,并更新items指针(但列表对象本身的地址不变)。
- 列表对象示例
内存地址 0x4000: (列表对象头)
+-------------------+
| 引用计数 (refcount) |
+-------------------+
| 类型指针 → list |
+-------------------+
| 分配空间: 8 | # 预分配空间 (比实际元素多)
| 元素数量: 3 |
| 元素指针数组地址 → 0x5000
+-------------------+
内存地址 0x5000: (元素指针数组)
+-----------+-----------+
| 地址0x6000 → 整数1 |
+-----------------------+
| 地址0x6100 → 整数2 |
+-----------------------+
| 地址0x6200 → 整数3 |
+-----------------------+
| 空位 (预分配空间) |
+-----------------------+
- 字典对象示例
内存地址 0x7000: (字典对象头)
+-------------------+
| 引用计数 (refcount) |
+-------------------+
| 类型指针 → dict |
+-------------------+
| 哈希表大小: 8 | # 最小为8
| 已用桶数: 1 |
| 桶数组地址 → 0x8000
+-------------------+
内存地址 0x8000: (桶数组)
+---------+------------------+------------------+
| 索引 | 哈希值 | 键指针 | 值指针 | 状态 |
+------+--------+----------+----------+---------+
| 0 | ... | (空) | (空) | EMPTY |
| 1 | 1234 | 0x9000 → 'a' | 0xA000 → 1 | ACTIVE |
| 2 | ... | (空) | (空) | EMPTY |
| ...| ... | ... | ... | ... |
| 7 | ... | (空) | (空) | EMPTY |
+---+--------+-----------+-----------+----------+
- 修改可变对象发生什么
lst = [1, 2, 3]
lst.append(4) # 直接修改原对象
1. 检查列表是否还有空位(本例中:分配空间8 > 元素数量3)
2. 在元素指针数组第4个位置存储新整数4的地址
3. 更新列表头中的元素数量为4
4. 列表对象地址不变 (0x4000)
扩容过程:
1. 分配新数组空间(通常翻倍,新分配16位置)
2. 复制所有旧元素到新数组
3. 更新列表头中的分配空间=16
4. 释放旧数组内存
- 元组中的可变对象陷阱
t = (1, [2, 3]) # 元组包含不可变整数和可变列表
# 尝试修改元组会失败
t[0] = 10 # ❌ TypeError: 'tuple' object does not support item assignment
# 但修改元组中的列表是允许的!
t[1].append(4) # ✅ 成功修改
print(t) # (1, [2, 3, 4])
元组对象 @0x5000:
+---------------+-----------------+
| 引用计数 | 类型指针 → tuple |
+---------------+-----------------+
| 元素数量: 2 | |
+-----------------------------+
| 元素0: 地址0x6000 → 整数1 |
| 元素1: 地址0x7000 → 列表对象 | →
↓
列表对象 @0x7000:
+---------------+-----------------+
| 引用计数 | 类型指针 → list |
+---------------+-----------------+
| 分配空间: 4 | 元素数量: 2 |
| 元素指针数组 → [2, 3] |
修改的是列表对象本身,而元组内存储的只是列表对象的地址(该地址未变)!
5.2 可变对象和不可变对象的其他说明
(1)对象标识陷阱
a = [1, 2]
b = [1, 2]
c = a
print(a == b) # True(值相等)
print(a is b) # False(不同对象)
print(a is c) # True(相同对象)
# 字典键中使用可变对象导致错误
invalid_dict = {[1,2]: "value"} # TypeError: unhashable type: 'list'
- 使用is检查对象身份(内存地址)
- 使用==检查值相等
- 绝对不要用可变对象作为字典键
(2)对象的深浅拷贝
- 浅拷贝
original = [1, [2, 3]]
shallow_copy = original.copy() # 或 list(original) 或 original[:]
shallow_copy[0] = 10 # 不影响原对象
print(original) # [1, [2, 3]]
shallow_copy[1][0] = 20 # 修改嵌套对象!
print(original) # [1, [20, 3]] 💥 原对象被修改
- 深拷贝
original = [1, [2, 3]]
deep_copy = copy.deepcopy(original)
deep_copy[1][0] = 20
print(original) # [1, [2, 3]] ✅ 原对象不受影响
- 嵌套结构的可变对象:必须使用copy.deepcopy()
- 简单结构或不可变对象:使用浅拷贝足够
(3)函数参数传递机制
所有参数的传递本质上都是 “按对象引用传递”(Pass by Object Reference)。理解这一机制的关键在于明确 **变量是对象的引用(标签)**这一核心概念。
def modify(num, lst):
num += 10 # 创建新整数对象
lst.append(4) # 修改原始列表对象
x = 5
my_list = [1, 2, 3]
modify(x, my_list)
print(x) # 5 (未改变)
print(my_list) # [1, 2, 3, 4] (已修改)
- 传入不可变对象时如同值传递(函数内创建副本)
- 传入可变对象时直接操作原始对象
- 重新赋值参数不影响原始变量;
(4)线程安全与可变状态
import threading
counter = 0 # 整数不可变看似安全,但...
def increment():
global counter
# 这个操作实际是: counter = counter + 1
for _ in range(100000):
counter += 1
# 创建线程
t1 = threading.Thread(target=increment)
t2 = threading.Thread(target=increment)
t1.start(); t2.start()
t1.join(); t2.join()
print(counter) # ❌ 通常 < 200000 (因为非原子操作)
- 原因
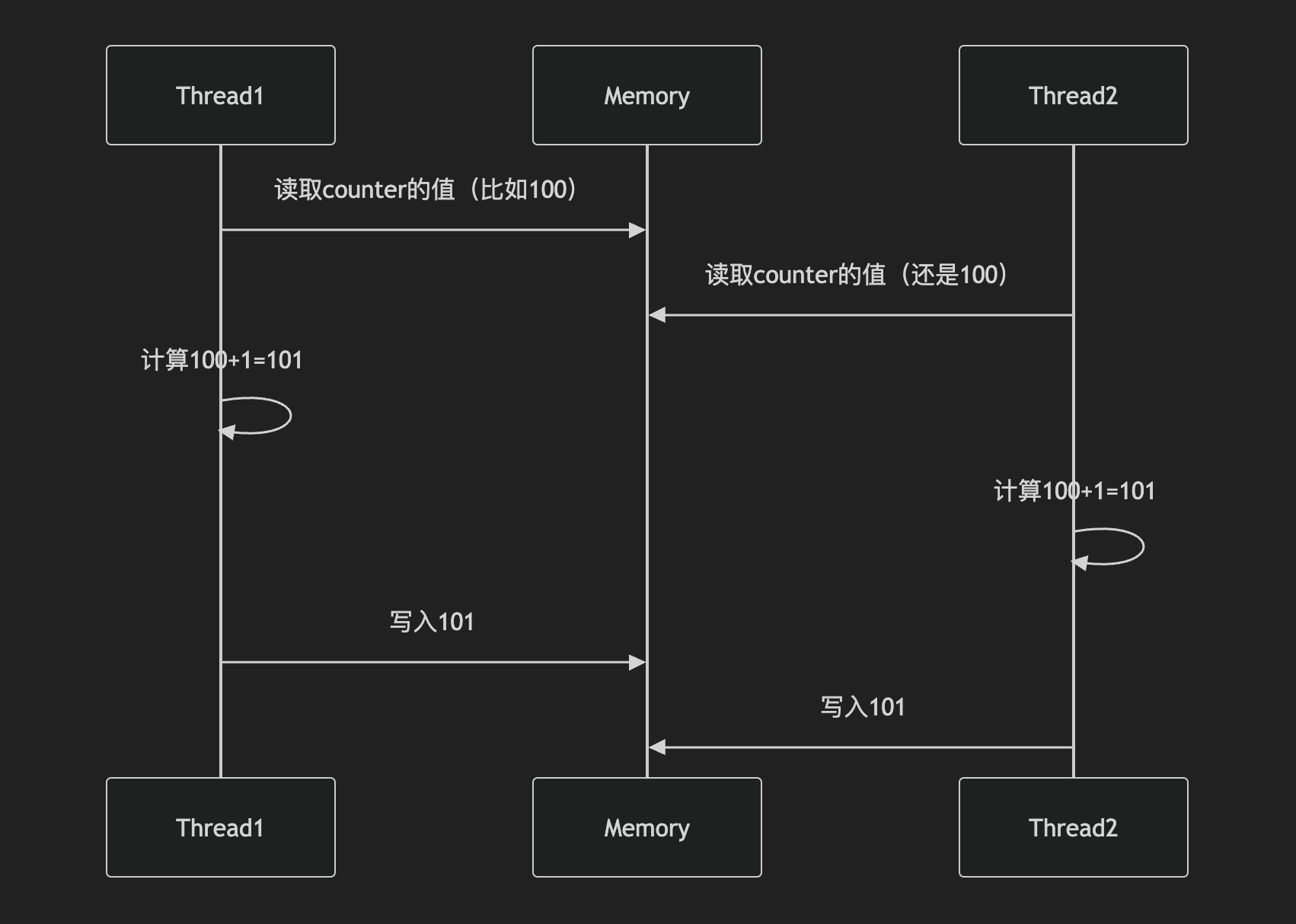
| 时间点 | 线程1操作 | 线程2操作 | counter值 |
|---|---|---|---|
| t1 | 读取counter=0 | 0 | |
| t2 | 读取counter=0 | 0 | |
| t3 | 计算0+1=1 | 0 | |
| t4 | 写回1 | 1 | |
| t5 | 计算0+1=1(基于旧值0) | 1 | |
| t6 | 写回1 | 1 |
- 解决方案
import threading
# 共享资源
counter = 0
# 创建锁对象
lock = threading.Lock()
def safe_increment():
global counter
for _ in range(100000):
# 获取锁
lock.acquire()
try:
# 临界区开始
counter += 1
# 临界区结束
finally:
# 确保锁被释放
lock.release()
# 创建线程
t1 = threading.Thread(target=safe_increment)
t2 = threading.Thread(target=safe_increment)
# 启动线程
t1.start()
t2.start()
# 等待线程完成
t1.join()
t2.join()
print(f"锁方案结果: {counter}")
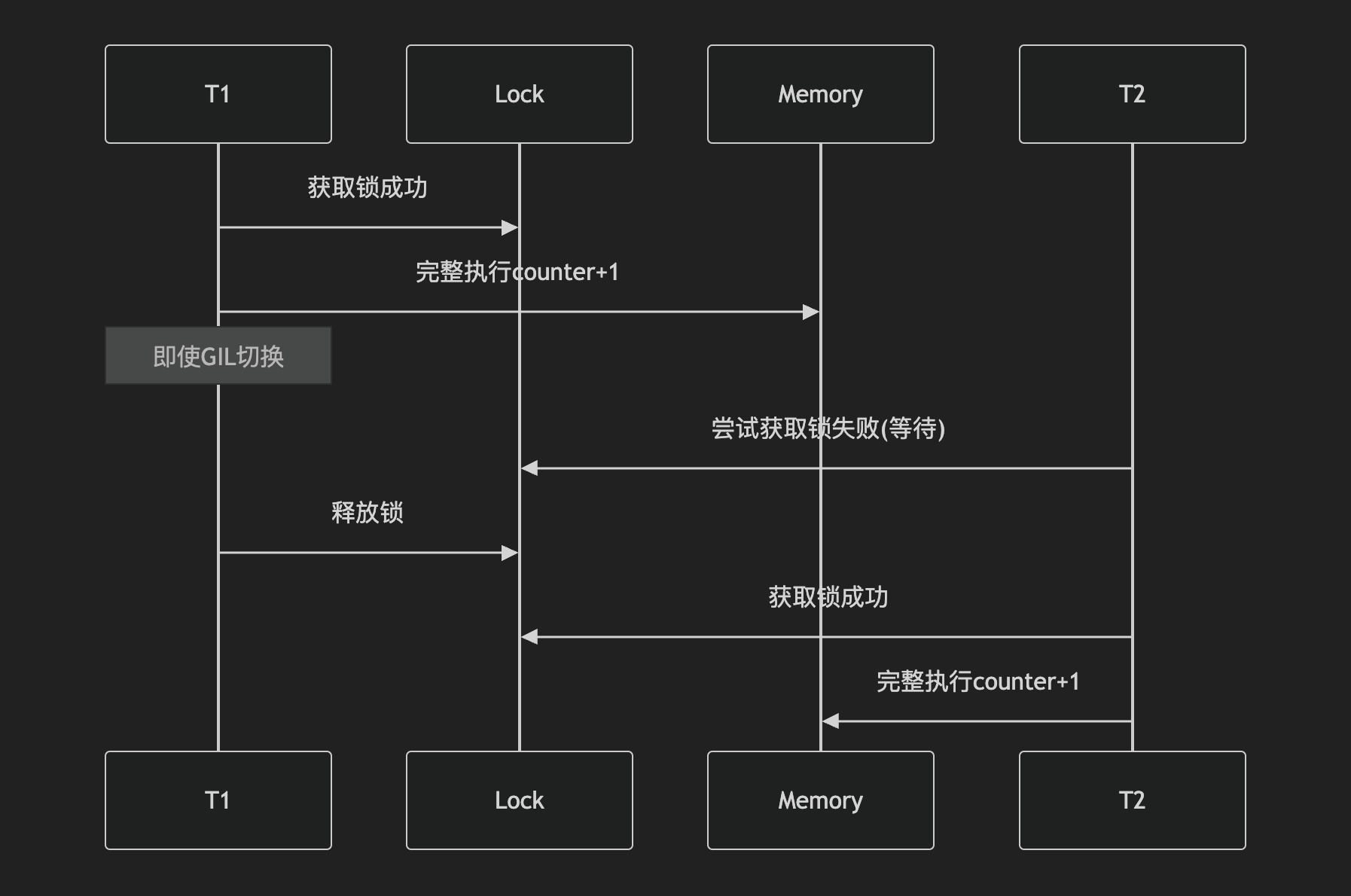
- GIL 与线程安全的关系
- GIL确保:任何时刻只有一个线程在执行Python字节码
- GIL 不保证操作原子性:虽然GIL确保了字节码级别的执行独占,但单个Python操作可能对应多条字节码
- 即使有GIL,线程切换可能发生在这些字节码之间:
counter += 1 在字节码层面的分解:
LOAD_GLOBAL 0 (counter) # 加载counter值到栈
LOAD_CONST 1 (1) # 加载常量1
INPLACE_ADD # 执行加法运算
STORE_GLOBAL 0 (counter) # 存回counter
- 互斥锁可以把整个操作打包成一个原子单元
* 
5.3 有序和无序
数据类型的 有序(Ordered) 和 无序(Unordered) 指的是元素是否按照固定的插入顺序存储和访问
- 有序类型
- 特点:元素有明确的固定顺序(插入顺序),可以通过索引(下标)精确访问。
- 基于动态数组,元素连续存储,通过内存偏移直接索引。插入顺序天然保留,但增删元素需移动数据。
- 包含类型:
- 字符串(String):字符序列(如 “hello” 的 ‘h’ 是第0位)
- 列表(List):元素按插入顺序排列(如 [1, 2, 3] 中 1 始终在第一位)
- 元组(Tuple):类似列表,但不可变(如 (4, 5, 6) 中 4 位置固定)
- 无序类型
- 特点:元素无固定顺序(不记录插入顺序),不支持索引访问,主要用于去重和快速查找。
- 基于哈希表,元素存储位置由哈希函数和冲突解决算法决定,迭代顺序与插入无关。Python 3.6+ 的字典通过额外维护顺序数组(indices)实现了按插入序迭代,但查找仍依赖哈希表。
- 包含类型:
- 集合(Set):元素唯一且无序(如 {3, 1, 2} 可能显示为 {1, 2, 3})
- 字典(Dictionary):键值对中 “键”唯一且无序(如 {“b”:2, “a”:1} 可能显示为 {“a”:1, “b”:2})
- 为什么无序类型查询效率更高
- 列表(有序):像把1000把钥匙挂满整面墙(连续挂),你必须从头到尾挨个检查每把钥匙(顺序查找 → O(n))。
- 集合/字典(无序):给钥匙贴上编号,用数学公式算出位置(位置 = hash(钥匙名) % 房间大小),直接冲到这个位置拿钥匙(直接定位 → O(1))。
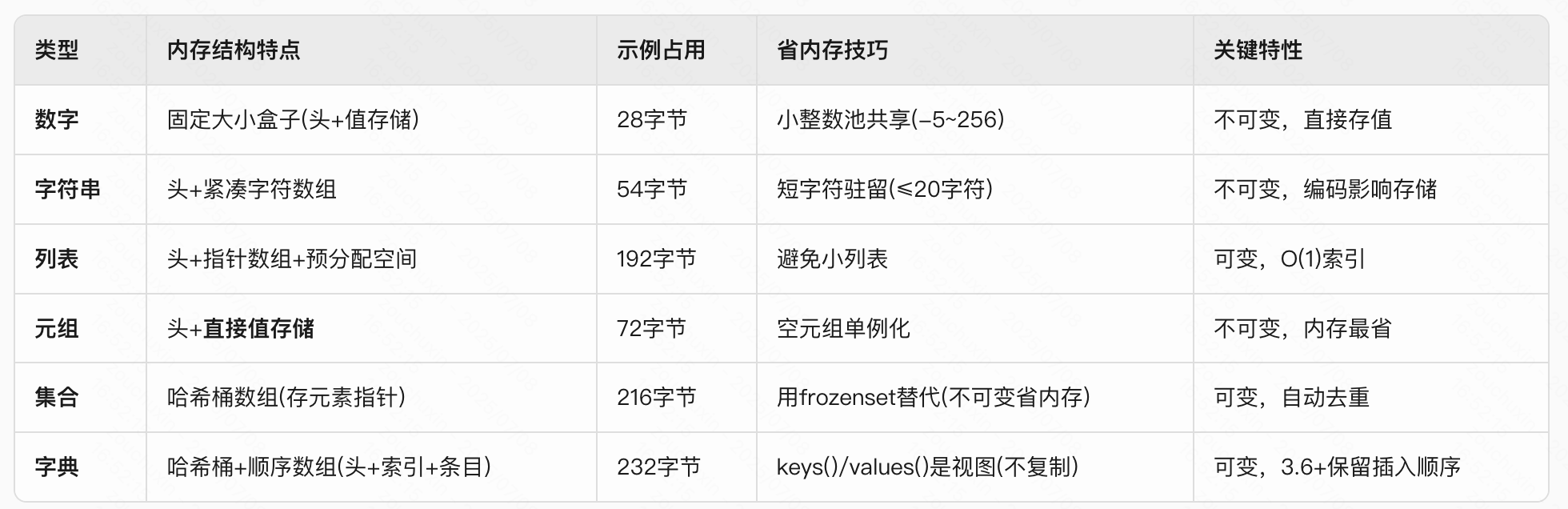
5.4 几种数据类型的内存结构
- 列表
内存地址 0x1000: 列表头信息
+-----------------------+---------------------------+
| 类型: List | 描述:这是一个列表 |
| 元素数量: 3 | 当前有3个元素 |
| 总容量: 4 | 预分配了4个位置(比实际多1)|
| 元素存储位置 → 0x2000 | 指向真正存数据的地方 |
+-----------------------+---------------------------+
内存地址 0x2000: 元素存储区(像一排连续的储物柜)
+----------+-------------------------+
| 储物柜0 | → 存储了数字10的内存地址 |
+----------+-------------------------+
| 储物柜1 | → 存储了数字20的内存地址 |
+----------+-------------------------+
| 储物柜2 | → 存储了数字30的内存地址 |
+----------+-------------------------+
| 储物柜3 | (空位,预留给新元素) |
+----------+-------------------------+
- 集合
内存地址 0x3000: 集合头信息
+----------------------+--------------------------------+
| 类型: Set | 描述:这是一个集合 |
| 元素数量: 3 | 当前有3个元素 |
| 存储桶数量: 8 | 有8个存储位置(比实际多) |
| 桶数组地址 → 0x4000 | 指向存储桶的地方 |
+----------------------+--------------------------------+
内存地址 0x4000: 存储桶区域(像超市货架,不按顺序放)
+----------+------------------------+-----------------+
| 桶位置0 | 空 | |
| 桶位置1 | → "banana"的内存地址 | (不是第1个放的) |
| 桶位置2 | 空 | |
| 桶位置3 | → "apple"的内存地址 | (实际第1个放的) |
| 桶位置4 | 空 | |
| 桶位置5 | → "cherry"的内存地址 | (实际第3个放的) |
| 桶位置6 | 空 | |
| 桶位置7 | 空 | |
+----------+------------------------+-----------------+
- 字典
内存地址 0x5000: 字典头信息
+----------------------+---------------------------------+
| 类型: Dict | 描述:这是一个字典 |
| 键值对数量: 3 | 当前有3个键值对 |
| 存储桶地址 → 0x6000 | 指向快速查找的桶(无序) |
| 顺序数组地址 → 0x7000| 指向记录顺序的地方(有序) |
+----------------------+---------------------------------+
内存地址 0x6000: 查找桶区域(无序)
+----------+-----------------+
| 桶位置0 | 空 |
| 桶位置1 | → b的位置 |
| 桶位置2 | → c的位置 |
| 桶位置3 | 空 |
| 桶位置4 | → a的位置 |
+----------+-----------------+
内存地址 0x7000: 顺序记录区(记住放入顺序)
+----------+------------------------+--------------+
| 位置0 | → 第一个键值对"a":1 | (第1个放的) |
| 位置1 | → 第二个键值对"b":2 | (第2个放的) |
| 位置2 | → 第三个键值对"c":3 | (第3个放的) |
+----------+------------------------+--------------+
- 元组
内存地址 0x8000: 元组头信息 (固定大小)
+-----------------------+---------------------------+
| 类型: Tuple | 描述:这是不可变的元组 |
| 元素数量: 3 | 长度固定 |
| 元素存储区 → 紧挨头部 | 不需要单独指针!(关键优化) |
+-----------------------+---------------------------+
内存地址 0x8000+头信息区: 直接存储元素(连续无空位)
+----------+------------------+--------------+
| 元素0 | 直接存整数10的值 | (不是指针!) |
+----------+------------------+--------------+
| 元素1 | 直接存整数20的值 | |
+----------+------------------+--------------+
| 元素2 | 直接存整数30的值 | |
+----------+------------------+--------------+
无需预分配空间(长度固定)
- 数字
内存地址 0x9000: 整数对象
+-----------------------+---------------------------+
| 类型: Int | 描述:这是一个整数 |
| 引用计数: 1 | 当前被引用1次 |
| 实际值: 42 | 直接存储数字 |
+-----------------------+---------------------------+
小整数池: -5到256的整数会预创建,重复使用时直接指向同个内存地址
a = 100; b = 100 → a和b指向内存中的同一个100
- 字符串
内存地址 0xA000: 字符串头信息
+-----------------------+---------------------------+
| 类型: String | 描述:这是字符串 |
| 字符长度: 5 | 字节长度: 5 (ASCII) |
| 哈希值缓存: 0xF1A3B | (避免重复计算) |
| 实际字符存储 → 紧挨头部| 不需要单独指针! |
+-----------------------+---------------------------+
内存地址 0xA000+头信息区: 字符连续存储
+---+---+---+---+---+---+
| h | e | l | l | o | \0| # \0是C语言结束符(实际可能不存)
+---+---+---+---+---+---+
不可变: 任何修改都会创建新字符串
内存优化:
短字符串驻留:s1="py"; s2="py" 指向同一个"py"
6. 并发和并行、进程、协程、线程
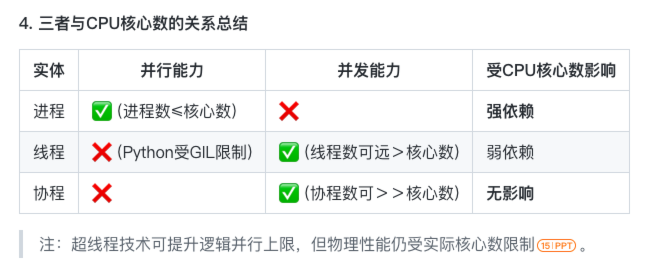
(1)进程、协程、线程
- 进程:
- 你同时打开了 浏览器(Chrome) 、 音乐播放器(Spotify) 和 文档编辑器(Word)。
- 对应概念:进程 (Process): 每个独立的应用程序就是一个进程
- 进程拥有自己独立的内存空间,操作系统为每个程序分配独立的资源,他们相互隔离
- 进程:操作系统资源分配的最小单位,拥有独立的内存空间(堆和栈),数据不共享。进程切换开销大(需切换内存空间、寄存器等),但稳定性高(一个进程崩溃不影响其他进程)
- 线程
- 浏览器进程内部,通常每个标签页或主要功能模块由一个或多个线程来负责执行
- 为什么是线程?这些线程共享Chrome进程的内存空间(比如都能访问你的书签、历史记录、登录状态)。它们由操作系统调度,可以在CPU上轮流执行(并发)或者在多核CPU上同时执行(并行)。这些线程需要协同工作(比如点击新闻链接需要通知渲染线程),但也可能竞争资源(比如同时读写历史记录)
- CPU调度的最小单位,属于同一进程的线程共享进程的内存资源(堆),但拥有独立的栈。线程切换开销小于进程,但需处理共享数据的竞争问题
- 协程
- 视频播放涉及多个步骤:从网络接收数据包 -> 将数据包组装成视频帧 -> 解码视频帧 -> 将解码后的画面显示在屏幕上。网络接收数据可能会很慢(I/O等待)
- 为什么是协程?所有这些协程都在同一个线程内运行!它们共享该线程的所有资源。当一个协程遇到I/O等待(如网络接收)时,它不会傻等阻塞整个线程,而是主动让出控制权给事件循环,事件循环立即去运行其他就绪的协程(如组装、解码或渲染)。这大大提高了单线程的效率和响应速度,能处理非常高的并发连接(想象一个服务器用单线程处理成千上万个这样的视频请求)
- 用户级轻量级线程(微线程),由程序自身控制切换(非操作系统调度)。协程共享线程的资源,切换时仅需保存寄存器上下文和栈,开销极小,适合高并发场景
(2)GIL 锁的影响
GIL(全局解释器锁)是CPython解释器的互斥锁,保证同一时刻仅有一个线程执行Python字节码,防止多线程竞争导致数据错误
- 对线程的影响
- 限制多核并行:多线程无法利用多核CPU,即使多线程也仅在单核上交替运行。
- I/O操作优化:线程进行I/O阻塞(如网络请求)时会主动释放GIL,允许其他线程执行,因此多线程在I/O密集型任务中仍有性能提升。
:::danger
- Python受GIL限制:单进程内线程仅能并发(非并行),无法跨核
:::
- 对进程和协程的影响
- 进程:不受GIL影响。每个进程有独立解释器和GIL,可并行运行在多核CPU上。
- 协程:不受GIL影响。协程在单线程内由用户调度,不涉及线程切换,GIL对其无限制
- 何时关注 GIL 限制
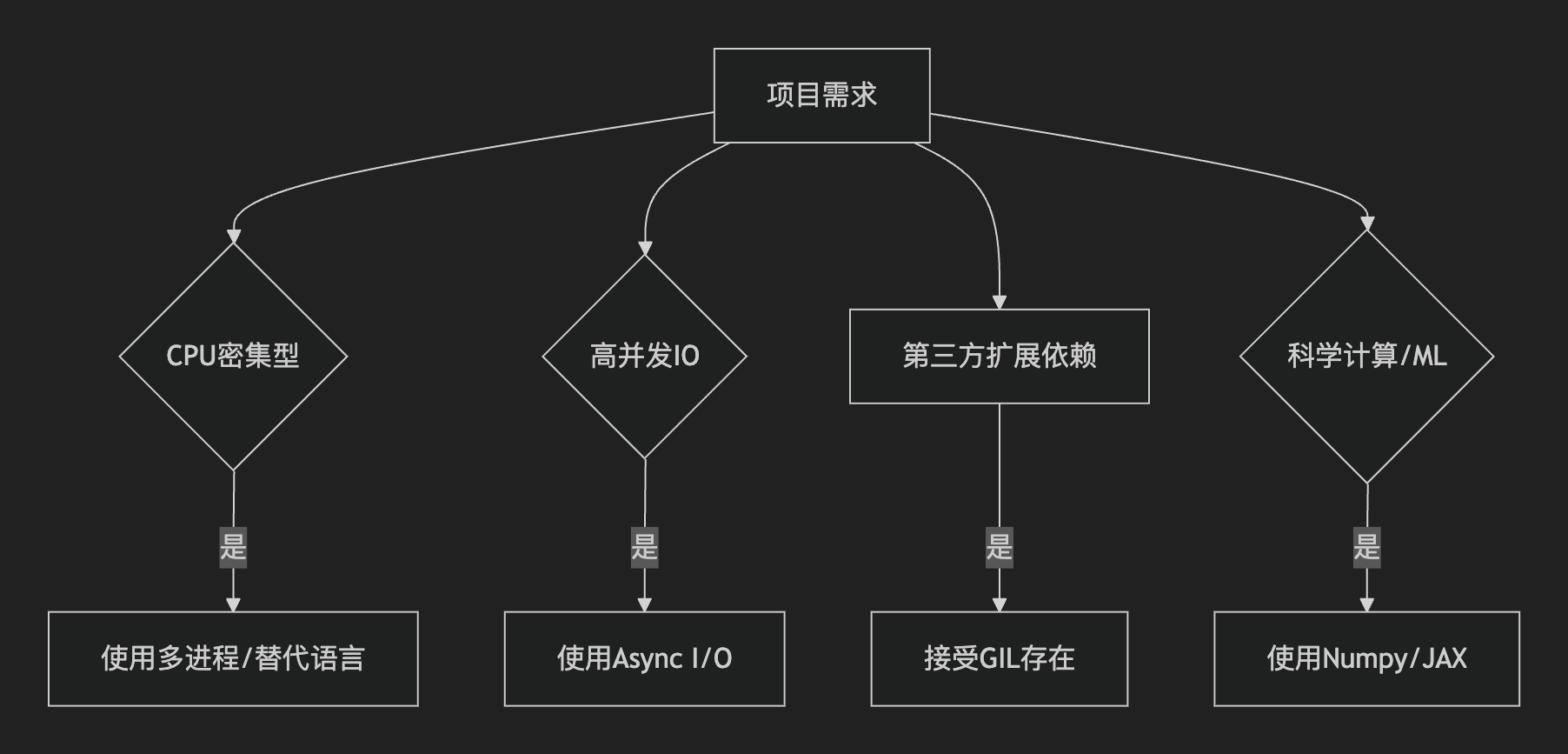
(3)Flask 和 FastAPI
- Flask(同步框架)
- 默认模式:使用多线程/多进程处理请求。
- 通过WSGI服务器(如Gunicorn)启动多进程(Worker),每个进程内用多线程处理请求。
- 受GIL影响,多线程模式适合I/O密集型API,但无法并行执行计算任务。
- 协程支持:可通过
<font style="color:rgb(36, 41, 47);background-color:rgba(175, 184, 193, 0.2);">gevent</font>等库实现协程,但需手动配置。
- 默认模式:使用多线程/多进程处理请求。
gunicorn app:app -w 4 -k gevent # 4进程 + 协程
- FastAPI(异步框架)
- 核心机制:基于ASGI协议,原生支持协程(Async/Await)。
- 单线程内通过事件循环调度协程,高并发时资源占用远低于多线程。
- 协程不受GIL限制,I/O操作自动挂起切换,适合高并发API(如实时推送)。
- 多进程扩展:可搭配Uvicorn等服务器启动多进程,结合协程充分利用多核。
- 核心机制:基于ASGI协议,原生支持协程(Async/Await)。
(4)并发和并行
- 并发(Concurrent)
- 定义:多个任务在同一时间段内交替执行
- 特点:任务间快速切换,看起来像同时进行
- 适用场景:I/O密集型任务(网络请求、文件操作、数据库查询)
- Python实现:threading、asyncio
- 并行(Parallel)
- 定义:多个任务真正同时执行,每个任务占用独立CPU核心
- 特点:需要多核CPU,真正的同时执行
- 适用场景:CPU密集型任务(数学计算、图像处理、机器学习)
- Python实现:multiprocessing、concurrent.futures.ProcessPoolExecutor

如果只有一核 CPU 但是开了多个进程算并行吗?
答案:无法物理并行:
- 单核 CPU 在任何时刻只能执行一个进程的指令。虽然创建了 4 个进程,但操作系统会通过 时间片轮转 调度它们轮流执行,本质是并发而非并行。
- 额外开销:进程切换成本:操作系统在切换进程时需保存/恢复上下文(寄存器、内存映射等),频繁切换可能消耗 5%~20% 的 CPU 时间。资源开销:每个进程独立占用内存(复制代码、数据),可能导致内存不足或频繁换页(Swap),进一步拖慢性能。

:::
(5)Python中的实现方式
- threading 模块-并发
import threading
def worker():
print("工作线程执行")
thread = threading.Thread(target=worker)
thread.start()
thread.join()
优点:
- 简单易用
- 适合I/O密集型任务
- 线程间共享内存
缺点:
- 受GIL限制,CPU密集型任务无法真正并行
- 线程切换开销
- 需要手动管理锁
- asyncio 模块-并发
import asyncio
async def worker():
await asyncio.sleep(1)
print("异步任务完成")
async def main():
tasks = [worker() for _ in range(3)]
await asyncio.gather(*tasks)
asyncio.run(main())
优点:
- 单线程异步执行,无锁开销
- 性能优于threading
- 适合大量I/O操作
- 内置超时和取消机制
缺点:
- 学习曲线较陡
- 需要异步库支持
- multiprocessing 模块-并行
import multiprocessing
def worker():
print("进程执行")
if __name__ == "__main__":
processes = []
for _ in range(4):
p = multiprocessing.Process(target=worker)
p.start()
processes.append(p)
for p in processes:
p.join()
优点:
- **绕过GIL限制**
- **真正并行执行**
- **适合CPU密集型任务**
缺点:
- **进程间内存隔离**
- **通信成本高**
- **资源消耗大**
- concurrent.futures 模块-并行
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
# 线程池(并发)
with ThreadPoolExecutor(max_workers=4) as executor:
futures = [executor.submit(worker) for _ in range(4)]
results = [future.result() for future in futures]
# 进程池(并行)
with ProcessPoolExecutor(max_workers=4) as executor:
futures = [executor.submit(worker) for _ in range(4)]
results = [future.result() for future in futures]
优点:
- **统一的接口**
- **自动管理线程/进程池**
- **支持超时和取消**
总结
- 进程:独立资源,可并行,适合CPU密集型任务。
- 线程:共享资源,受GIL限制,适合I/O密集型任务。
- 协程:用户级调度,高效并发,适合高I/O并发场景。
- GIL:仅限制多线程并行,多进程和协程可规避。
- 框架选择:
- Flask:多线程/多进程,适合传统同步逻辑。
- FastAPI:异步协程,适合高性能、高并发API。

7. python 的自省
自省就是让程序在运行的时候,能查看一个对象是啥类型、有哪些属性、有哪些方法,甚至能动态获取或修改它的内部结构
- 常用方法
- type(): 直接告诉你一个对象是什么类型。
print(type(123)) # <class 'int'>
print(type("hello")) # <class 'str'>
- isinstance(obj, Class): 检查对象是否是某个类型(或该类型的子类)的实例。
class Animal: pass
class Dog(Animal): pass
d = Dog()
print(isinstance(d, Dog)) # True
print(isinstance(d, Animal)) # True (Dog是Animal的子类)
print(isinstance(d, str)) # False
- dir(): 列出对象可访问的属性和方法名(字符串列表)。非常常用!
print(dir([])) # 会列出列表对象的所有方法和属性名,如 'append', 'pop', 'sort', '__add__', ...
- hasattr(obj, 'name'): 检查对象是否有某个属性或方法(名为 'name')。
- getattr(obj, 'name'[, default]): 动态获取对象的属性或方法(如果存在)。可以用 default 参数避免 AttributeError。
- setattr(obj, 'name', value): 动态设置对象的属性或方法(名为 'name')。
- callable(obj): 检查对象是否可调用(比如一个函数、一个类、或定义了 __call__ 方法的对象)。
- id(obj): 获取对象在内存中的唯一标识(常用来比较对象是否是同一个实例)。
- __dict__ 属性: 大多数对象都有一个 __dict__ 属性,它是一个字典,存储着对象自身的属性和值。类是对象,类也有 __dict__(包含类属性和方法)。
- inspect 模块: Python 标准库中专门为自省设计的强大模块,提供更高级的功能,比如获取函数参数信息、源代码、继承关系、堆栈信息等(非常适合框架和工具开发者)。
- 自省的应用场景
- 调试和探索: 在解释器里(如IPython)用 dir() 和 type() 快速查看陌生对象的结构和能力。
- 动态访问与操作: 比如根据用户输入或配置文件的字符串值 attr_name,通过 getattr(my_obj, attr_name) 来动态调用对应的方法或获取属性。
- 元编程: 编写创建类、修改类行为的代码(如装饰器、元类)。框架(如 Django ORM, Flask)大量使用自省来实现声明式语法和动态绑定。
- 序列化与反序列化: 对象需要被转成 JSON 或保存时,自省可以遍历对象的 dict 或属性。
- 文档生成: 工具可以通过自省获取函数、类的参数签名、注释等信息自动生成文档。
- 类型检查(运行时): 结合 type(), isinstance(), hasattr() 可以在运行时做更复杂的类型或接口检查(尽管静态类型检查 mypy 更高效)。
8. Python中的 *args 和 **kwargs
*args: 收集所有没名字的位置参数,塞进一个叫 args 的元组(tuple) 里。
**kwargs: 收集所有带名字的关键字参数,塞进一个叫 kwargs 的字典(dict) 里。
名字不重要! args 和 kwargs 是约定俗成的名,你可以叫 *things, **options 都行,但 * 和 ** 这两个符号才是关键魔法!
- *args: 处理任意数量的位置参数
def calculate_sum(*args): # *args 收集所有位置参数
total = 0
for number in args: # args 是一个元组 (tuple)
total += number
return total
# 调用:参数个数随意!
print(calculate_sum(1, 2)) # 输出:3 (args = (1, 2))
print(calculate_sum(1, 2, 3, 4)) # 输出:10 (args = (1, 2, 3, 4))
print(calculate_sum()) # 输出:0 (args = ())
- **kwargs: 处理任意数量的关键字参数
def setup_user(**kwargs): # **kwargs 收集所有关键字参数
print("Creating user with:")
for key, value in kwargs.items(): # kwargs 是一个字典 (dict)
print(f" - {key}: {value}")
# 调用:传入任意名字-值对!
setup_user(name='Alice', age=30, role='admin')
# 输出:
# Creating user with:
# - name: Alice
# - age: 30
# - role: admin
setup_user(username='Bob', email='bob@example.com')
# 输出:
# Creating user with:
# - username: Bob
# - email: bob@example.com
- 结合使用
def example_function(req_param, *args, default_param='hello', **kwargs):
"""
req_param: 必须的位置参数
*args: 额外的位置参数(元组)
default_param: 带默认值的关键字参数
**kwargs: 额外的关键字参数(字典)
"""
print("Req Param:", req_param)
print("Args:", args)
print("Default Param:", default_param)
print("KWargs:", kwargs)
# 调用示例 1:
example_function(10, 20, 30, option1='a', option2='b')
# 输出:
# Req Param: 10
# Args: (20, 30) # 第一个位置参数10后面的位置参数
# Default Param: hello # 默认值没覆盖就用默认
# KWargs: {'option1': 'a', 'option2': 'b'} # 所有没定义的关键字参数
# 调用示例 2:
example_function('value', 40, 50, default_param='world', color='red', size=5)
# 输出:
# Req Param: value
# Args: (40, 50)
# Default Param: world # 覆盖了默认值
# KWargs: {'color': 'red', 'size': 5}
- 在定义函数时,这些部分必须严格按 顺序 出现:
- 普通位置参数 (必传)
- *args (收集剩下的位置参数)
- 普通关键字参数 (带默认值的)
- **kwargs (收集剩下的关键字参数)
❗ 模板: def func(req1, req2, *args, kw1=val1, kw2=val2, **kwargs)
9. 生成器和迭代器
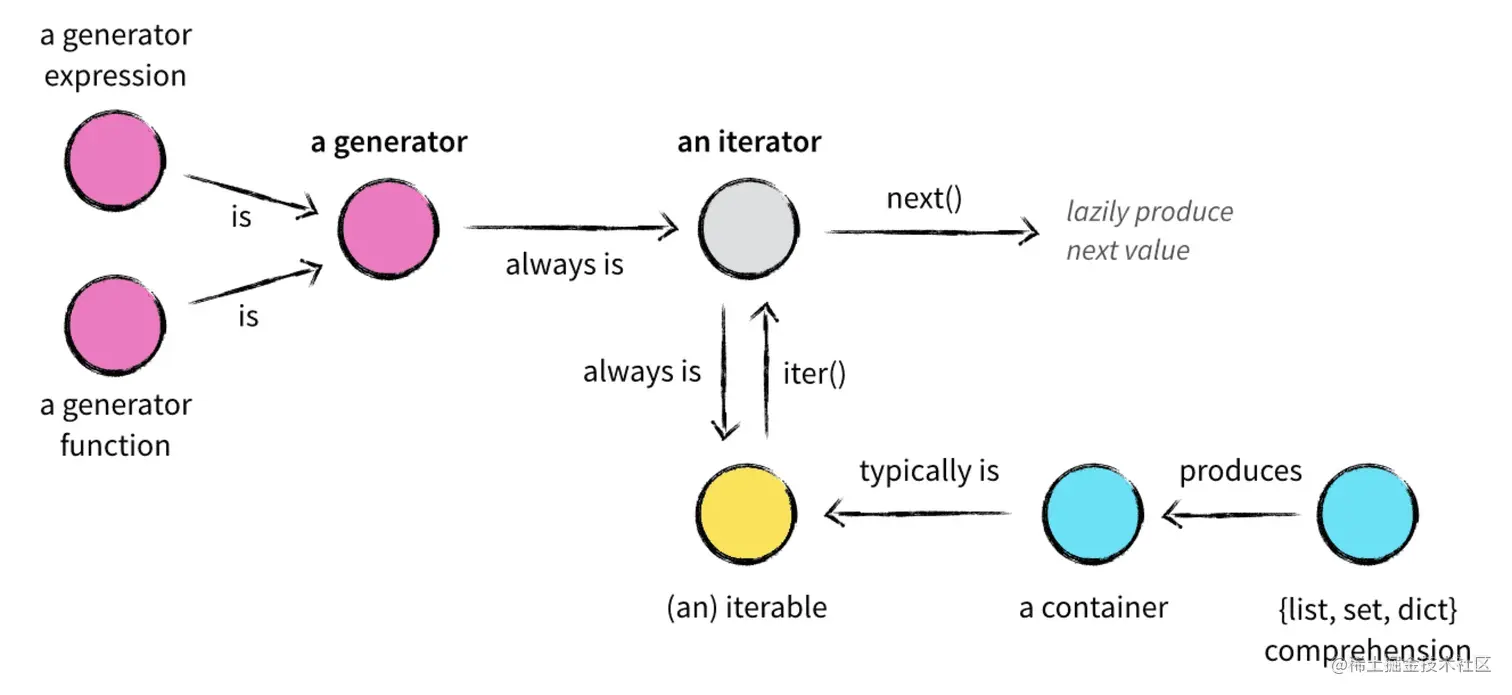
(1)容器
定义:存储多个元素的对象
- 特点:
- 支持len()获取大小
- 支持in成员检测
- 可以遍历内部元素
- 常见容器:
# 标准容器
[1, 2, 3] # 列表
(1, 2, 3) # 元组
{"a":1, "b":2} # 字典
{1, 2, 3} # 集合
"abc" # 字符串(字符容器)
# 特殊容器
range(5) # 范围对象
open("file.txt") # 文件对象
- 核心原理:容器是数据存储的物理结构,不直接参与迭代过程
(2)可迭代对象 (Iterable)
定义:一个可迭代对象是任何能够一次返回一个元素的对象。简单来说,就是可以用for循环遍历的对象。如果一个对象实现了__iter__方法,并且该方法返回一个迭代器,那么它就是可迭代的。
- 特点:
- 可通过for循环遍历
- 可用iter()函数获取迭代器
- 自身不是迭代器(没有__next__()方法)
- 验证方法:
from collections.abc import Iterable
print(isinstance([1,2], Iterable)) # True
print(isinstance(123, Iterable)) # False
- 所有容器都是可迭代对象:
for item in [1, 2, 3]: # 列表迭代
print(item)
for char in "hello": # 字符串迭代
print(char)
v = range(10)
dir(v) # 也是可迭代对象
(3)迭代器
定义:用于逐个访问可迭代对象的元素的对象。迭代器是一个带有状态的对象,它能在你调用next()方法的时候返回容器中的下一个值。任何实现了__iter__和__next__方法的对象都是迭代器。
- 特点:
- 记住遍历位置(状态)
- 元素只能向前访问,不能后退
- 内容被"消耗"后无法重置
- 核心方法:
__iter__() # 返回迭代器自身
__next__() # 返回下一个元素或抛出StopIteration
- 手动使用示例:
nums = [1, 2, 3]
it = iter(nums) # 获取迭代器
print(next(it)) # 1
print(next(it)) # 2
print(next(it)) # 3
print(next(it)) # ❌ 抛出StopIteration
- 创建自定义迭代器:
# 下面是迭代器类
class CountDown:
def __init__(self, start):
self.current = start
def __iter__(self):
return self
def __next__(self):
if self.current <= 0:
raise StopIteration
self.current -= 1
return self.current + 1
for i in CountDown(3): ## 首先会执行__iter__方法,然后一次执行__next__
print(i) # 输出 3, 2, 1
for循环依赖于迭代器
- 迭代器+可迭代对象
class IT(object): # 是一个迭代器
def __init__(self):
self.counter = 0
def __iter__(self):
print("IT__iter__")
return self
def __next__(self):
print("IT__next__")
if self.counter >= 5:
raise StopIteration
self.counter += 1
return self.counter
class Foo(object):
def __iter__(self):
print("Foo__iter__")
return IT()
for i in Foo():##Foo()是一个可迭代对象
print(i)
-------
Foo__iter__
IT__next__
1
IT__next__
2
IT__next__
3
IT__next__
v1 = range(10)
dir(v) # 也是可迭代对象
v2 = v1.__iter__()
print(dir(v2)) ## 这是迭代器对象
# 在 for in range执行过程中就是先通过__iter__获取迭代器对象,再用__next__进行迭代
## 基于可迭代对象&迭代器实现自定义 range
class IterRange(object):
def __init__(self,num):
self.num = num
self.counter = -1
def __iter__(self):
print("IterRange__iter__")
return self
def __next__(self):
print("IterRange__next__")
if self.counter >= self.num:
raise StopIteration
self.counter += 1
return self.counter
class Xrange(object):
def __init__(self,max_num):
self.max_num = max_num
def __iter__(self):
print("Xrange__iter__")
return IterRange(self.max_num)
for i in Xrange(10):
print(i)
(4)生成器
定义:一种特殊的迭代器,用函数语法创建(通过yield关键字)。
- 特点:
- 自动实现迭代器协议
- 延迟计算(需要时才生成值)
- 内存高效(不预先生成所有元素)
- 可暂停和恢复执行状态
- yield 的作用
- 核心作用是暂停函数执行并返回中间结果,而不是一次性返回所有结果。
- Python 中的 yield 用于创建生成器函数。生成器函数的行为类似于迭代器,可以在循环中使用,一次检索一个元素。调用生成器函数时,它会返回一个生成器对象,而不会立即执行该函数。在生成器对象上调用 next() 时,函数会一直执行,直到遇到 yield 语句。该语句返回 yield 的值并暂停函数的执行,同时保持其状态。再次调用 next() 时,函数会在 yield 语句之后立即恢复执行,直到遇到另一个 yield 或返回。
- 两类创建方式:
- 生成器函数
# 定义生成器函数
def fibonacci(n):
a, b = 0, 1
for _ in range(n):
yield a # 暂停并返回值
a, b = b, a + b
fib = fibonacci(5) # 返回生成器对象,内部是根据生成器 generator 创建的对象,生成器内部也声明了__iter__和__next__
print(list(fib)) # [0, 1, 1, 2, 3]
# 生成器保持状态
fib = fibonacci(10)
print(next(fib)) # 0
print(next(fib)) # 1
print(next(fib)) # 1
- 生成器表达式
# 类似列表推导,使用圆括号
squares = (x**2 for x in range(5))
print(next(squares)) # 0
print(next(squares)) # 1
print(next(squares)) # 4
# 大文件处理示例
big_file = (line.strip() for line in open('huge.log') if 'ERROR' in line)
for error_line in big_file:
process(error_line) # 每次只处理一行,内存友好
- 基于可迭代对象&生成器实现 range
class Xrange(object):
def __init__(self,max_num):
self.max_num = max_num
def __iter__(self):
counter = 0
while counter < self.max_num:
yield counter
counter += 1
for i in Xrange(10):
print(i)
10. 闭包
在函数内部再定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的一些变量称之为闭包。
- 闭包三要素
- 嵌套函数:内部函数定义在外部函数的内部
- 变量捕获:内部函数引用了外部函数的局部变量
- 外部返回:外部函数返回内部函数(或其引用)
def f():
a = 1
def visit():
print(a)
def add():
nonlocal a
a += 1
return add,visit
add_fuc,v = f()
add_fuc()
v()
add_fuc()
v()
add_fun2,v2 = f()
add_fun2()
v2()
add_fun2()
v2()
def outer_function(x):
# 这是外部函数的变量
def inner_function(y):
# 内部函数可以访问外部函数的变量 x
return x + y
return inner_function
# 使用闭包
my_closure = outer_function(10)
result = my_closure(5) # 结果是 15
- 关键点
- 外部函数执行完毕之后,内部函数依然可以访问外部函数的变量
- 每次调用外部函数,都会创建一个新的闭包环境
- 闭包保存的是变量的引用,不是值的拷贝
- 可以把闭包想象成一个带有记忆的函数,它记住了创建时的环境
- 什么场景使用闭包
- 创建功能相似但是参数不同的函数
def create_validator(min_length):
def validate(text):
if len(text) < min_length:
return f"文本长度必须至少 {min_length} 个字符"
return "验证通过"
return validate
# 创建不同规则的验证器
username_validator = create_validator(6)
password_validator = create_validator(8)
print(username_validator("abc")) # 文本长度必须至少 6 个字符
print(password_validator("12345678")) # 验证通过
- 装饰器(装饰器本质上就是闭包)
def timing_decorator(func):
import time
def wrapper(*args, **kwargs):
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print(f"{func.__name__} 执行时间: {end - start:.4f}秒")
return result
return wrapper
@timing_decorator
def slow_function():
import time
time.sleep(1)
return "完成"
slow_function() # slow_function 执行时间: 1.0001秒
- 状态保持
def create_accumulator():
total = 0
def add(value):
nonlocal total
total += value
return total
return add
acc = create_accumulator()
print(acc(10)) # 10
print(acc(20)) # 30
print(acc(5)) # 35
- 闭包的底层实现原理
- 当Python解释器遇到闭包时,它会执行以下步骤:
- 编译阶段:
- 检测到内部函数引用了外部变量
- 将这些变量标记为"自由变量"(free variables)
- 执行阶段:
- 创建闭包单元(closure cell)来存储捕获的变量
- 在函数对象中添加__closure__属性
- 每个闭包单元存储一个外部变量的引用
- 编译阶段:
- 当Python解释器遇到闭包时,它会执行以下步骤:
11. 装饰器
装饰器本质上就是一个闭包函数,它可以在不修改原函数代码的情况下,给函数添加新的功能。
在了解装饰器之前我们应该先知道
- 在Python中,函数是一等对象,可以作为参数传递:
def say_hello():
return "Hello!"
def call_function(func):
return func()
result = call_function(say_hello)
print(result) # Hello!
- 函数可以返回函数(上面闭包也提到了)
def outer_function():
def inner_function():
return "来自内部函数"
return inner_function
my_func = outer_function()
print(my_func()) # 来自内部函数
装饰器是什么?
- 装饰器的基本结构
# 基础装饰器结构
def decorator(original_func): # 1. 接收函数对象
def wrapper(): # 2. 创建新功能函数
# 增强功能代码...
result = original_func() # 3. 调用原函数
return result
return wrapper # 4. 返回增强后的函数
- 它的闭包特性
- 嵌套函数:装饰器内部有wrapper函数
- 访问外部变量:wrapper访问原函数对象
- 返回内部函数:装饰器返回wrapper函数
- 执行流程
def my_decorator(func):
print(f"正在装饰函数: {func.__name__}")
def wrapper():
print("包装函数执行前")
result = func()
print("包装函数执行后")
return result
print(f"返回包装函数: {wrapper.__name__}")
return wrapper
def original_function():
print("原始函数执行")
return "原始结果"
print("=== 手动装饰过程 ===")
print(f"装饰前: {original_function.__name__}")
# 这就是装饰器做的事情
decorated_function = my_decorator(original_function)
print(f"装饰后: {decorated_function.__name__}")
print(f"原函数还在: {original_function.__name__}")
print("\n=== 执行对比 ===")
print("原函数:")
original_function()
print("\n装饰后函数:")
decorated_function()
=== 手动装饰过程 ===
装饰前: original_function
正在装饰函数: original_function
返回包装函数: wrapper
装饰后: wrapper
原函数还在: original_function
=== 执行对比 ===
原函数:
原始函数执行
装饰后函数:
包装函数执行前
原始函数执行
包装函数执行后
'原始结果'
- 装饰器只执行一次:当@my_decorator时执行
- 函数被替换:original_function实际上指向wrapper函数
- 原函数被闭包捕获:func保存了原始original_function
- 语法糖
# 这两种写法是完全等价的:
# 方法1:使用@语法糖
@my_decorator
def function_a():
return "A"
# 方法2:手动装饰
def function_b():
return "B"
function_b = my_decorator(function_b)
print(f"function_a的类型: {type(function_a)}")
print(f"function_b的类型: {type(function_b)}")
- 更深入的理解
def show_function_info(func):
print(f"函数名: {func.__name__}")
print(f"函数ID: {id(func)}")
print(f"函数类型: {type(func)}")
print(f"函数模块: {func.__module__}")
print("---")
def original():
return "original"
def simple_decorator(func):
def wrapper():
return func()
return wrapper
print("装饰前:")
show_function_info(original)
decorated = simple_decorator(original)
print("装饰后:")
show_function_info(decorated)
show_function_info(original) # 原函数还在
装饰器创建了一个全新的函数对象(wrapper),而不是修改原函数
原函数的ID、类型、模块信息都保持不变
装饰后的函数有自己独立的ID和元信息
- 参数化装饰器的多层闭包
def create_multiplier_decorator(factor):
print(f"创建装饰器,倍数: {factor}")
def decorator(func):
print(f"装饰函数: {func.__name__}")
def wrapper(*args, **kwargs):
print(f"执行时使用倍数: {factor}") # 这里使用了外部变量
result = func(*args, **kwargs)
return result * factor
return wrapper
return decorator
# 创建装饰器
double_decorator = create_multiplier_decorator(2)
triple_decorator = create_multiplier_decorator(3)
@double_decorator
def get_number():
return 10
@triple_decorator
def get_another_number():
return 10
print(get_number()) # 20
print(get_another_number()) # 30
factor 变量在 create_multiplier_decorator 执行完毕后,理论上应该被回收
但由于闭包机制,wrapper 函数保持了对 factor 的引用
每个装饰器实例都有自己独立的 factor 值:double_decorator 的 factor = 2;triple_decorator 的 factor = 3

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 40
40 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)