Springboot 整合 Java DL4J 实现文本分类系统
确保开发环境中已安装 JDK 8 或更高版本,Maven 或 Gradle 构建工具。通过调整超参数(如学习率、网络层数)或使用预训练词向量(如 GloVe)进一步提升性能。创建 REST 接口接收文本输入并返回分类结果。文本分类需要将文本转换为数值向量。加载预处理后的数据集(如。
·
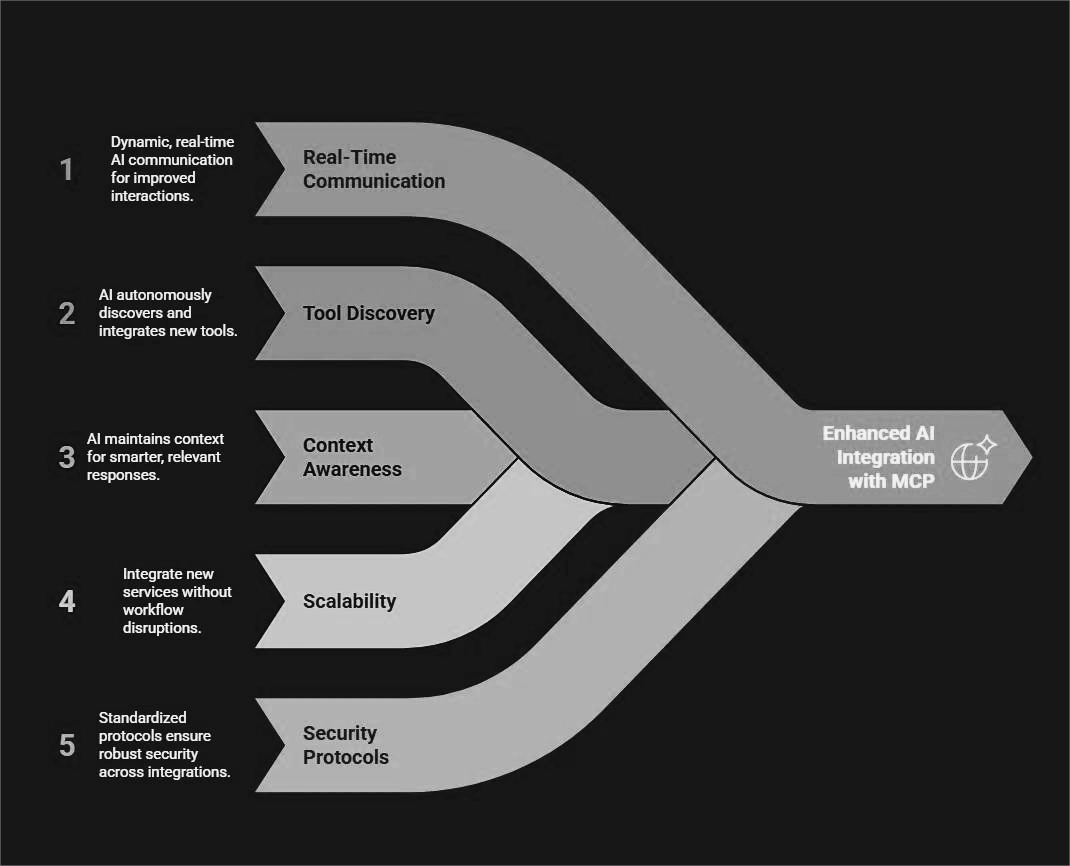
环境准备
确保开发环境中已安装 JDK 8 或更高版本,Maven 或 Gradle 构建工具。在 pom.xml 中添加以下依赖:
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>1.0.0-beta7</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native-platform</artifactId>
<version>1.0.0-beta7</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
数据预处理
文本分类需要将文本转换为数值向量。使用 TokenizerFactory 和 Word2Vec 处理文本数据:
TokenizerFactory tokenizerFactory = new DefaultTokenizerFactory();
Word2Vec vec = new Word2Vec.Builder()
.minWordFrequency(1)
.iterations(1)
.layerSize(100)
.seed(42)
.windowSize(5)
.iterate(iterator)
.tokenizerFactory(tokenizerFactory)
.build();
vec.fit();
构建神经网络模型
通过 MultiLayerConfiguration 定义神经网络结构。以下是一个包含嵌入层、LSTM 层和输出层的示例:
MultiLayerConfiguration config = new NeuralNetConfiguration.Builder()
.updater(new Adam(0.01))
.list()
.layer(new EmbeddingLayer.Builder()
.nIn(vocabSize)
.nOut(embeddingSize)
.build())
.layer(new LSTM.Builder()
.nIn(embeddingSize)
.nOut(lstmSize)
.activation(Activation.TANH)
.build())
.layer(new RnnOutputLayer.Builder()
.nIn(lstmSize)
.nOut(numClasses)
.activation(Activation.SOFTMAX)
.lossFunction(LossFunctions.LossFunction.MCXENT)
.build())
.build();
MultiLayerNetwork model = new MultiLayerNetwork(config);
model.init();
训练模型
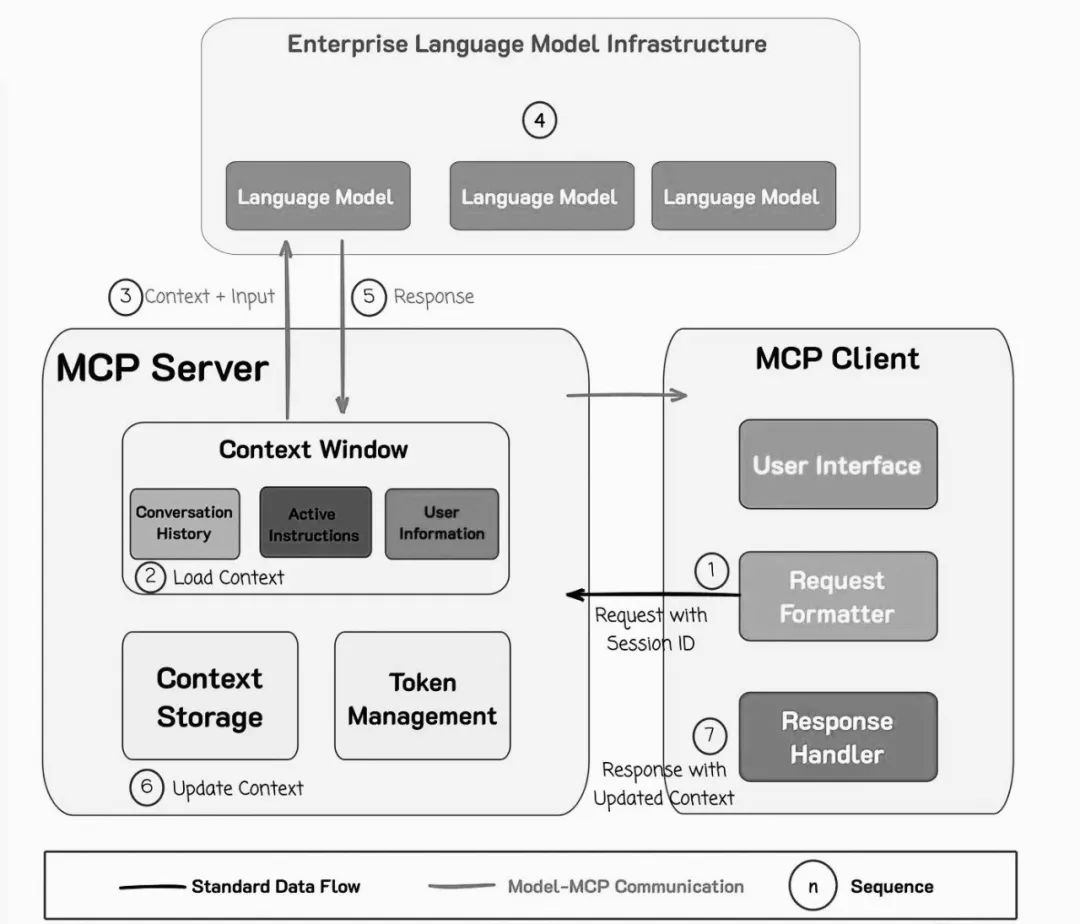
加载预处理后的数据集(如 DataSetIterator),调用 fit 方法进行训练:
DataSetIterator trainData = // 加载训练数据
for (int epoch = 0; epoch < numEpochs; epoch++) {
model.fit(trainData);
trainData.reset();
}
集成 Spring Boot
创建 REST 接口接收文本输入并返回分类结果。示例控制器:
@RestController
@RequestMapping("/api/classify")
public class TextClassificationController {
@Autowired
private MultiLayerNetwork model;
@PostMapping
public String classifyText(@RequestBody String text) {
INDArray features = // 将文本转换为模型输入格式
INDArray output = model.output(features);
return decodePrediction(output);
}
}
模型评估
使用 Evaluation 类计算准确率、精确率等指标:
DataSetIterator testData = // 加载测试数据
Evaluation eval = new Evaluation(numClasses);
while (testData.hasNext()) {
DataSet ds = testData.next();
INDArray output = model.output(ds.getFeatures());
eval.eval(ds.getLabels(), output);
}
System.out.println(eval.stats());
部署与优化
将模型保存为 .zip 文件,便于生产环境加载:
File modelFile = new File("model.zip");
ModelSerializer.writeModel(model, modelFile, true);
通过调整超参数(如学习率、网络层数)或使用预训练词向量(如 GloVe)进一步提升性能。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)