图像分类篇学习笔记
SE 模块首先通过全局自适应平均池化将每个通道的特征进行全局压缩,这一步骤提取了全局的空间信息,并将其缩放至 1×1 的特征图(即每个通道的全局平均值)。最终,这些权重被用于调整输入特征图的每个通道,放大重要特征,抑制不重要特征。该卷积层用于对输入图像进行初步的特征提取,通过较大的卷积核和步长,能够快速降低特征图的尺寸,同时增加通道数,为后续的网络层提供更多的特征信息。,将特征图的空间维度压缩为
MobileNetV3
亮点:轻量化网络结构
硬激活函数h-swish和h-sigmoid
加入SE注意力机制:
SE 模块首先通过全局自适应平均池化将每个通道的特征进行全局压缩,这一步骤提取了全局的空间信息,并将其缩放至 1×1 的特征图(即每个通道的全局平均值)。随后,使用 1×1 卷积层对通道进行压缩(减少特征维度),再通过激活函数(ReLU)增加非线性表达能力。接着,通过另一层 1×1 卷积还原通道维度,并使用 Hardsigmoid 激活函数生成每个通道的加权系数。最终,这些权重被用于调整输入特征图的每个通道,放大重要特征,抑制不重要特征。
深度可分离卷积和线性瓶颈结构,减少计算量和参数量
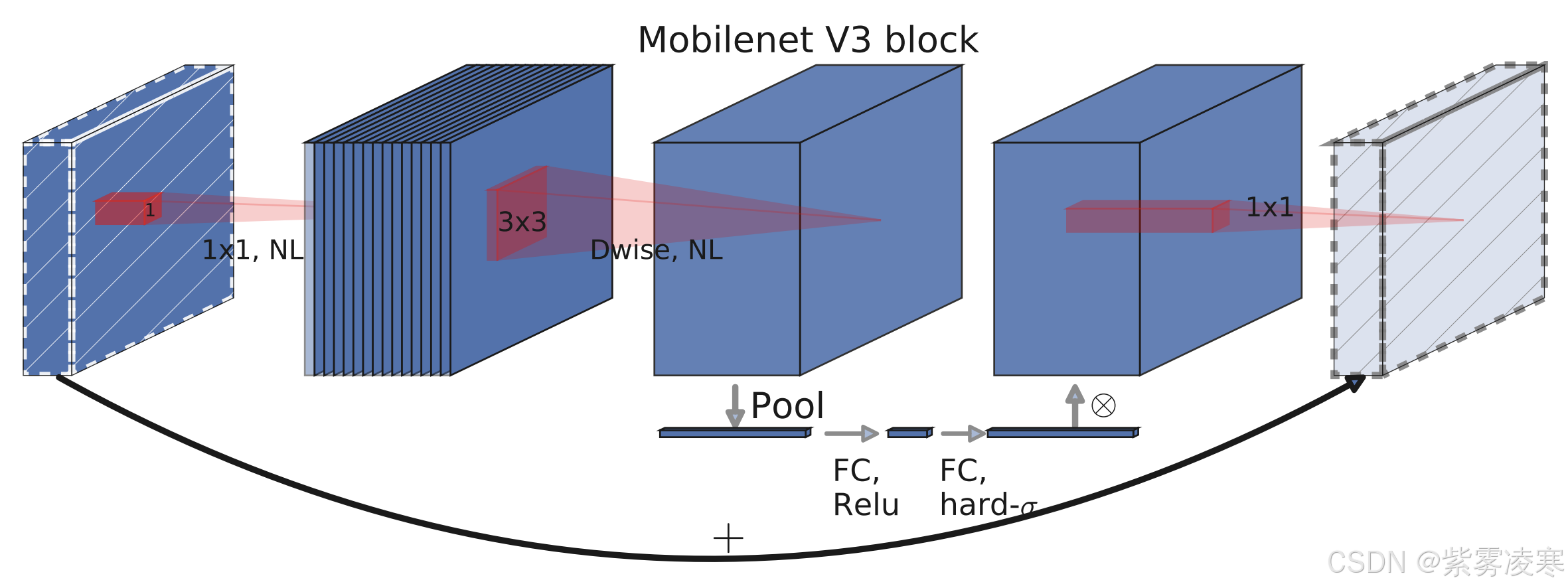
1、其网络结构的起始层为一个普通的卷积层,使用 3x3 大小的卷积核,该卷积层用于对输入图像进行初步的特征提取,通过较大的卷积核和步长,能够快速降低特征图的尺寸,同时增加通道数,为后续的网络层提供更多的特征信息。激活函数采用 h - swish,h - swish 激活函数
接下来是一系列的 bneck 结构(bottleneck 结构),
首先,是 1x1 的逐点卷积,用于升维操作,增加通道数,扩大特征的表达空间。
然后,是 3x3 的深度可分离卷积,它将传统卷积分解为深度卷积和逐点卷积,大大减少了计算量和参数量。
最后,再通过 1x1 的逐点卷积进行降维操作,恢复到合适的通道数。
3、网络的最后部分:
- 首先是一个 1x1 的卷积层,用于调整通道数。
- 接着是全局平均池化层,将特征图的空间维度压缩为 1x1,只保留通道维度的信息,从而将特征图转换为一个固定长度的特征向量。
- 然后通过一个 1x1 的卷积层进行分类预测,得到最终的分类结果 。
机器学习
线性回归
线性回归是一个回归问题,即用一条线去拟合训练数据
通过训练数据学习一个特征的线性组合,以此作为预测函数。
![]()
梯度下降:W的每一次更新,使用所有的样本。计算得到的是一个标准梯度。更新一次的幅度较大,样本不大的情况,收敛速度可以接受;但是若样本太大,收敛会很慢。
逻辑回归
逻辑回归是一个二分类问题
将线性回归的输出作为sigmoid函数的输入,最终的输出便是分类的结果。
感知机
感知机是一个二分类问题
SVM支持向量机
1、特点:
是一个二分类线性分类器
学习策略:
在分类超平面的正负两边各找到一个离分类超平面最近的点(也就是支持向量),使得这两个点距离分类超平面的距离和最大
决策树
是一种基于if-then-else规则的有监督学习算法
一般是自上而下生成的。每个决策或事件(即自然状态)都可能引出两个或多个事件,导致不同的结果,把这种决策分枝画成图形很像一棵树的枝干
随机森林
是一种由决策树构成的集成算法, 是由很多决策树构成的,不同决策树之间没有关联。
CNN(卷积神经网络)
CNN变形 具体模型
有LeNet-5、AlexNet、NIN、VGG、GoogLeNet、ResNet、DenseNet、MobileNets等。
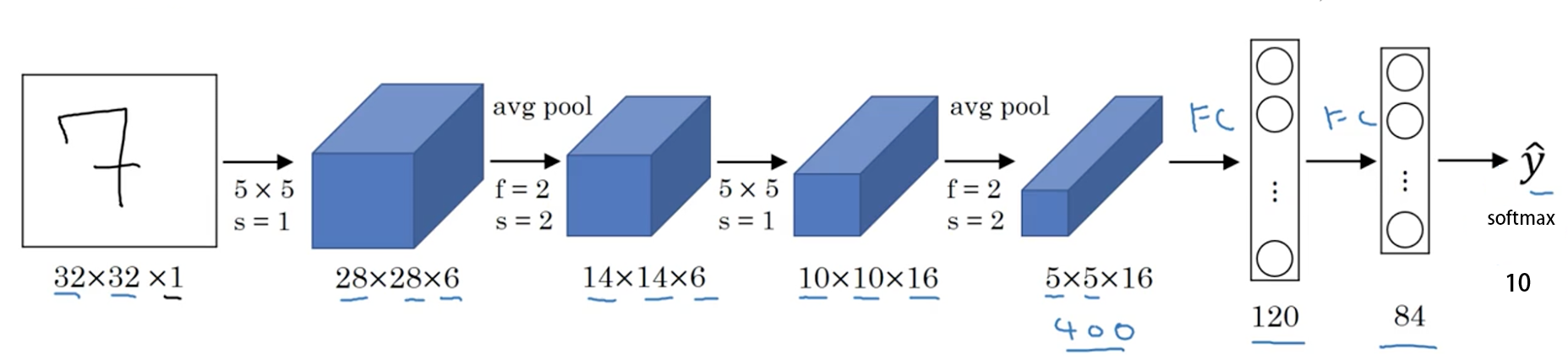
LeNet:它是早期经典的卷积神经网络模型,其网络结构包含两个由卷积层(conv)和池化层(pool)组成的模块,之后连接两层全连接层(FC,Fully Connected Layer) 。这种设计使得 LeNet 能够有效提取图像特征并进行分类
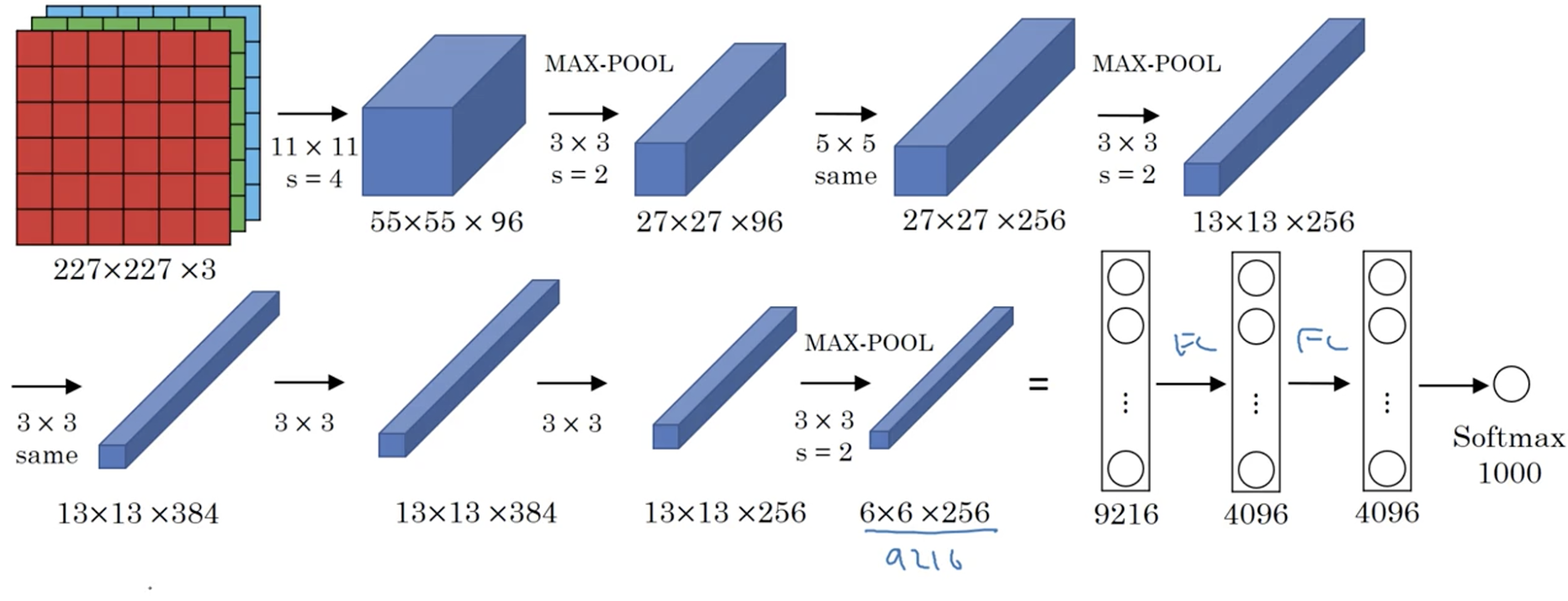
AlexNet:它由8层网络构成,其中5层为卷积层,后3层为全连接层。AlexNet 首次引入 ReLU 激活函数,有效解决了梯度消失问题,加快了网络的收敛速度。同时, Dropout 和 BN(Batch Normalization,批标准化层)技术。
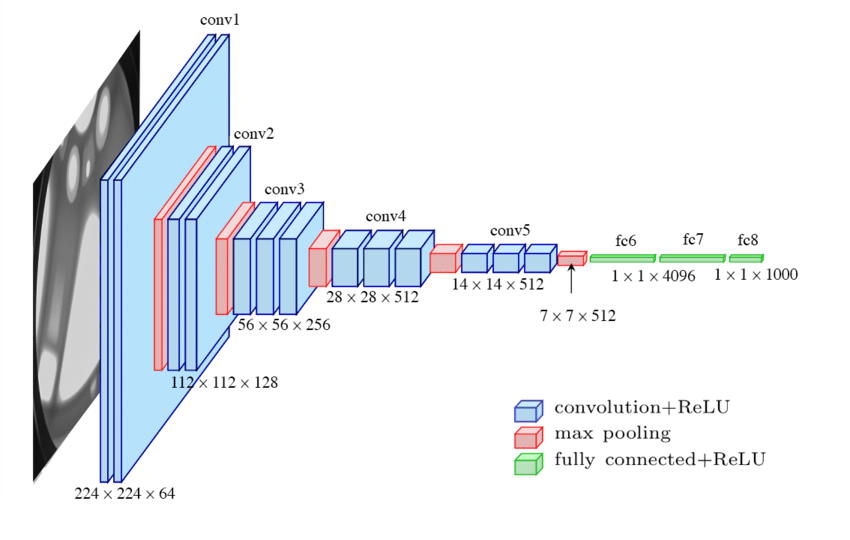
VGG:它是一个参数规模庞大的神经网络模型,16个可训练层,其中13个是卷积层,3个是全连接层
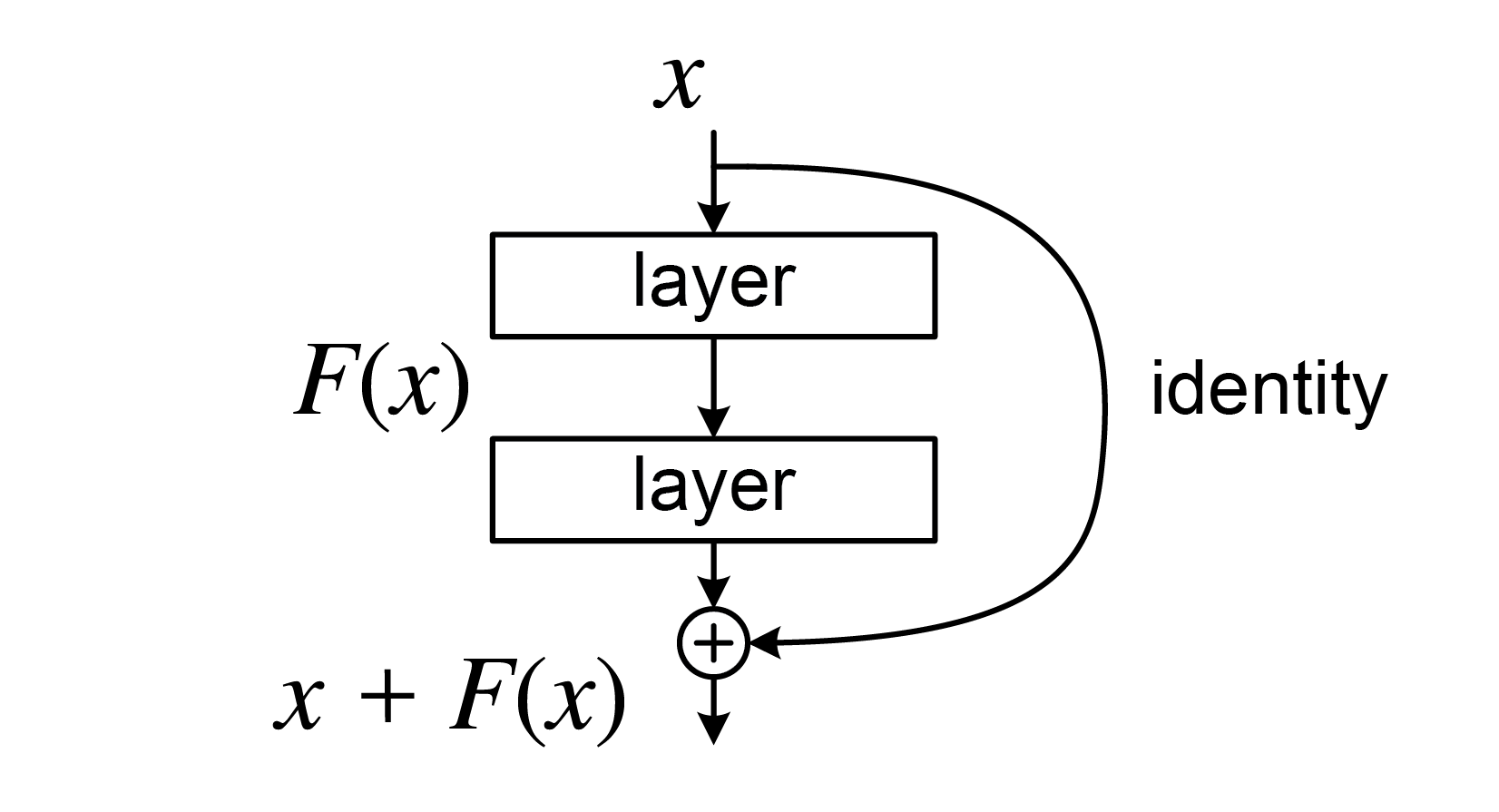
ResNet:残差网络
学习输入和输出之间的残差(即差异),而不是直接映射关系。
由多个残差块组成,每个残差块包含两条路径:一条是卷积层的堆叠,另一条是恒等连接,解决深层网络训练中的梯度消失问题
RNN循环神经网络
处理具有序列特性的数据,如自然语言文本、时间序列数据等
LSTM(长短期记忆神经网络)
Transformer
以自注意力机制(self - attention)为核心构建而成 。自注意力机制赋予模型强大的能力,使其能够在处理序列数据时,同时关注序列中各个位置的信息,而非像传统循环神经网络那样按顺序依次处理。
ViT(Vision Transformer)
将 Transformer 架构引入计算机视觉(CV)任务领域 。将图像巧妙地视作序列数据来处理

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)