SCI一区,即插即用!SCSA协同注意力机制:小目标检测与低光照增强的通用涨点方案
现有研究虽已证明通道与空间注意力的结合能提升视觉任务性能,但两者间的,特别是在空间信息如何指导通道特征学习以及如何缓解多语义信息带来的差异方面,仍缺乏深入探讨。现有即插即用注意力机制普遍存在两大局限:一是对固有的多语义空间信息利用不足,无法有效引导关键特征提取;二是对多语义融合带来的处理不当。为应对这些挑战,本文提出了一种新颖的)模块。该方法旨在探索空间与通道注意力在多语义层面的协同关系。SCSA
现有研究虽已证明通道与空间注意力的结合能提升视觉任务性能,但两者间的协同效应,特别是在空间信息如何指导通道特征学习以及如何缓解多语义信息带来的差异方面,仍缺乏深入探讨。
现有即插即用注意力机制普遍存在两大局限:
一是对固有的多语义空间信息利用不足,无法有效引导关键特征提取;
二是对多语义融合带来的语义差异处理不当。
为应对这些挑战,本文提出了一种新颖的空间与通道协同注意力(SCSA)模块。该方法旨在探索空间与通道注意力在多语义层面的协同关系。SCSA由一个可共享多语义空间注意力(SMSA)模块和一个渐进式通道自注意力(PCSA)模块串联而成。
SMSA通过轻量化的多尺度卷积捕获多语义空间先验,以指导PCSA的通道特征重校准;PCSA则利用通道级单头自注意力机制促进特征交互,有效缓解了SMSA中不同子特征间的语义差异,从而增强了模型的特征提取与泛化能力。
01 论文基本信息

- 标题: SCSA: Exploring the Synergistic Effects Between Spatial and Channel Attention
- 核心模块:
- 可共享多语义空间注意力 (Shareable Multi-Semantic Spatial Attention, SMSA)
- 渐进式通道自注意力 (Progressive Channel-wise Self-Attention, PCSA)
02 算法框架与核心模块
2.1 算法框架
本文提出的SCSA模块整体架构如论文图2所示。算法首先通过SMSA模块处理输入特征图:将特征沿通道维度分解为多个独立的子特征,使用多尺度共享的一维卷积提取不同语义层级的空间信息,生成空间注意力图。随后,将经过SMSA调制的特征图送入PCSA模块,该模块通过渐进式压缩保留空间先验,再利用通道级单头自注意力机制计算通道间的相似性,最终生成经过通道重校准的输出特征图。
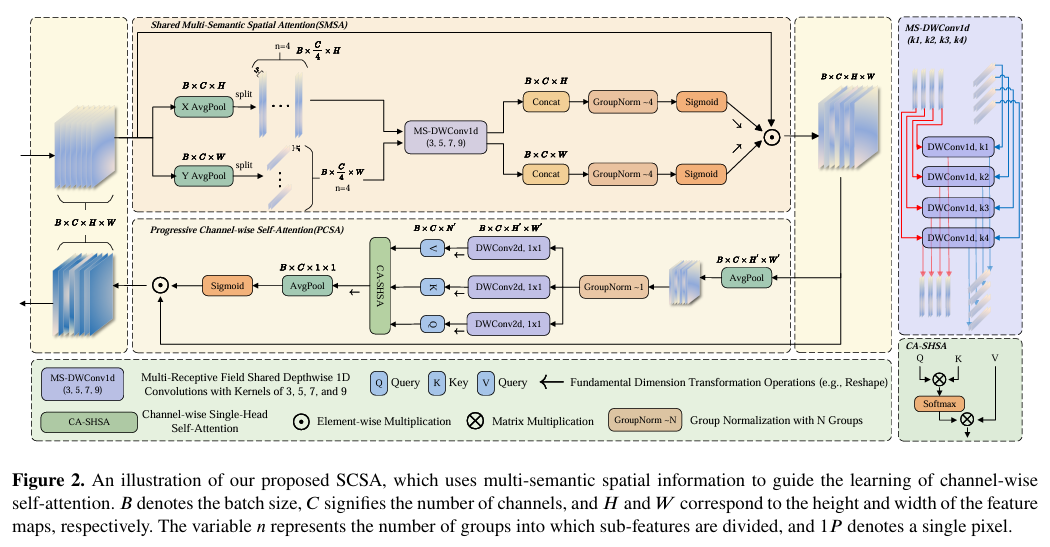
2.2 核心模块
模块一:可共享多语义空间注意力 (SMSA)
-
核心功能: 该模块旨在从不同子特征中高效捕获多层次、多语义的空间结构信息,并为后续的通道注意力模块提供具有判别性的空间先验。
-
实现逻辑:
- 时空分解: 将输入特征图
X分别沿高(H)和宽(W)维度进行全局平均池化,形成两个一维序列。再将通道维度均分为K组独立的子特征。 - 多语义提取: 对每组子特征,分别沿H和W维度使用不同核尺寸(如3, 5, 7, 9)的深度共享一维卷积(MS-DWConv1d)来学习不同感受野的语义信息。
- 注意力生成: 将处理后的多语义子特征拼接(Concat)起来,通过组归一化(Group Normalization, GN)和Sigmoid函数生成H和W维度的空间注意力图
Attn_H和Attn_W。最后将它们与原始输入X相乘,得到经过空间增强的特征X_s。其核心公式如下:
A t t n H = σ ( G N K H ( C o n c a t ( X ~ 1 H , X ~ 2 H , . . . , X ~ K H ) ) ) Attn_H = \sigma(GN_{K_H}(Concat(\tilde{X}_1^H, \tilde{X}_2^H, ..., \tilde{X}_K^H))) AttnH=σ(GNKH(Concat(X~1H,X~2H,...,X~KH)))
A t t n W = σ ( G N K W ( C o n c a t ( X ~ 1 W , X ~ 2 W , . . . , X ~ K W ) ) ) Attn_W = \sigma(GN_{K_W}(Concat(\tilde{X}_1^W, \tilde{X}_2^W, ..., \tilde{X}_K^W))) AttnW=σ(GNKW(Concat(X~1W,X~2W,...,X~KW)))
S M S A ( X ) = X s = A t t n H × A t t n W × X SMSA(X) = X_s = Attn_H \times Attn_W \times X SMSA(X)=Xs=AttnH×AttnW×X
- 时空分解: 将输入特征图
-
优势:
- 轻量高效: 采用深度共享1D卷积,相比2D卷积大幅减少了参数量和计算开销。
- 语义丰富: 多尺度卷积分支能够同时捕获局部细节和全局轮廓等丰富的空间语义。
- 避免干扰: 使用组归一化(GN)代替批量归一化(BN),能够独立处理各子特征,有效避免了不同语义信息间的干扰和批次噪声。
模块二:渐进式通道自注意力 (PCSA)
-
核心功能: 该模块被设计用于有效利用SMSA提供的空间先验信息,计算通道间的相似度,并缓解因多尺度卷积引入的语义差异,促进多语义信息的融合。
-
实现逻辑:
- 渐进式压缩: 对SMSA输出的特征图
X_s进行渐进式压缩,即使用一个固定核大小(如7x7)的平均池化将其分辨率从(H, W)降至(H', W'),以保留多语义空间先验并降低计算成本。 - 通道自注意力: 将压缩后的特征图
X_p线性投影生成查询(Q)、键(K)和值(V),并应用通道级单头自注意力(CA-SHSA)机制。注意,这里的自注意力是在通道维度C上计算的,而非空间维度。 - 通道重校准: 将自注意力计算结果
X_attn再次通过全局平均池化和Sigmoid激活,生成最终的通道注意力权重,并将其与X_s相乘,得到最终输出X_c。其核心公式为:
X p = P o o l ( H , W ) → ( H ′ , W ′ ) ( 7 , 7 ) ( X s ) X_p = Pool_{(H,W)\rightarrow(H',W')}^{(7,7)}(X_s) Xp=Pool(H,W)→(H′,W′)(7,7)(Xs)
X a t t n = A t t n ( Q , K , V ) = S o f t m a x ( Q K T C ) V X_{attn} = Attn(Q, K, V) = Softmax(\frac{QK^T}{\sqrt{C}})V Xattn=Attn(Q,K,V)=Softmax(CQKT)V
P C S A ( X s ) = X c = X s × σ ( P o o l ( H ′ , W ′ ) → ( 1 , 1 ) ( H ′ , W ′ ) ( X a t t n ) ) PCSA(X_s) = X_c = X_s \times \sigma(Pool_{(H',W')\rightarrow(1,1)}^{(H',W')}(X_{attn})) PCSA(Xs)=Xc=Xs×σ(Pool(H′,W′)→(1,1)(H′,W′)(Xattn))
- 渐进式压缩: 对SMSA输出的特征图
-
优势:
- 保留空间先验: 渐进式压缩策略相比直接全局池化,能更好地保留SMSA提取的多语义空间信息。
- 增强输入感知: 采用自注意力机制比传统卷积更能直观且有效地度量不同通道间的相似性,具有更强的输入感知能力。
- 语义差异缓解: 单头自注意力在所有通道间进行充分交互,有效促进了不同子特征的语义融合,缓解了语义差异。
03 模块适用任务
-
核心应用场景:
本文方法主要针对需要精细化特征表达的各类计算机视觉任务,包括图像分类(ImageNet-1K)、目标检测(MSCOCO、VisDrone等,尤其在密集、小目标、低光照等复杂场景下)、语义分割(ADE20K)和实例分割(MSCOCO)。 -
方法论核心:
其最本质的思想是利用空间注意力的多语义先验来引导通道注意力的学习。通过显式地从空间维度提取和分发多层次语义信息,再由通道注意力机制对这些信息进行融合与重校准,实现空间与通道维度的协同增效。 -
启发性拓展:
- 轻量化部署: SCSA的瓶颈在于多分支结构带来的内存访问开销。未来的工作可以探索如何使用结构重参数化等技术,在推理阶段将多分支结构融合成单分支,以在不损失精度的前提下提升实际推理速度。
- 跨维度协同探索: 本文验证了“空间指导通道”的有效性。未来可以进一步探索更多跨维度的协同模式,例如将时间维度(对于视频任务)纳入协同框架,设计时空通三维协同的注意力机制。
04 实验结果与可视化分析
核心实验与结论
(仅选取目标检测相关实验)
- 实验目的:
该实验旨在验证SCSA模块在目标检测这一密集型预测任务上的有效性和泛化能力。通过将SCSA与其他SOTA注意力模块(如SE, CBAM, CA等)在多个检测器(Faster R-CNN, Cascade R-CNN等)和多个数据集(如MSCOCO, VisDrone)上进行对比,检验其在复杂场景下的性能提升。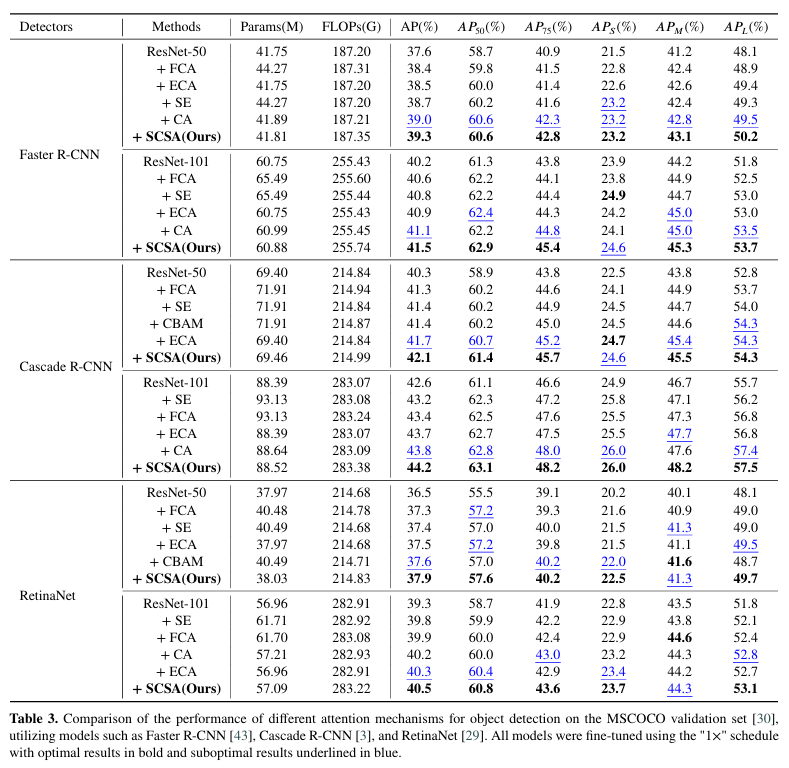
- 关键结果:
如论文中的表3所示,在MSCOCO数据集上,无论基线模型是ResNet-50还是ResNet-101,也无论检测器是Faster R-CNN还是Cascade R-CNN,集成SCSA的模型在各项AP指标(尤其是AP, AP75, APL)上均一致且显著地优于基线和其他注意力方法。例如,在Faster R-CNN (ResNet-50)上,SCSA相比基线提升了1.7%的AP,并且优于CA等先进方法。此外,在论文的图6中,可视化结果显示SCSA在遮挡、密集、小目标等挑战性场景下,相比基线模型能实现更准确的检测。

- 作者结论:
作者基于实验结果得出结论:SCSA模块能有效提升模型在目标检测任务中的性能,尤其是在处理多尺度目标和复杂场景时表现出强大的适应性。这得益于SCSA的多语义空间信息捕获能力和对语义差异的有效缓解,使得模型能够学习到更鲁棒和精细化的特征表示,从而在像素级和实例级的识别任务中取得优势。
05 即插即用模块
可共享多语义空间注意力(SMSA)
-
核心功能:从通道分组的子特征中以多尺度方式提取横纵两维的空间先验,并生成可共享的空间注意力以增强原特征。
-
核心优势:以深度可分离的一维卷积和组归一化高效捕获多语义空间信息,参数开销低且对批次统计不敏感。
-
核心代码(片段):
import torch
import torch.nn as nn
from einops import rearrange
from mmengine.model import BaseModule
class SCSA(BaseModule):
def __init__(self, dim, head_num, window_size=7,
group_kernel_sizes=[3, 5, 7, 9],
qkv_bias=False, attn_drop_ratio=0., gate_layer='sigmoid'):
super().__init__()
self.dim = dim
self.head_num = head_num
self.head_dim = dim // head_num
self.scaler = self.head_dim ** -0.5
self.group_kernel_sizes = group_kernel_sizes
self.window_size = window_size
self.qkv_bias = qkv_bias
self.group_chans = self.dim // 4
self.local_dwc = nn.Conv1d(self.group_chans, self.group_chans,
kernel_size=group_kernel_sizes[0],
padding=group_kernel_sizes[0] // 2,
groups=self.group_chans)
self.global_dwc_s = nn.Conv1d(self.group_chans, self.group_chans,
kernel_size=group_kernel_sizes[1],
padding=group_kernel_sizes[1] // 2,
groups=self.group_chans)
self.global_dwc_m = nn.Conv1d(self.group_chans, self.group_chans,
kernel_size=group_kernel_sizes[2],
padding=group_kernel_sizes[2] // 2,
groups=self.group_chans)
self.global_dwc_l = nn.Conv1d(self.group_chans, self.group_chans,
kernel_size=group_kernel_sizes[3],
padding=group_kernel_sizes[3] // 2,
groups=self.group_chans)
self.sa_gate = nn.Softmax(dim=2) if gate_layer == 'softmax' else nn.Sigmoid()
self.norm_h = nn.GroupNorm(4, dim)
self.norm_w = nn.GroupNorm(4, dim)
def smsa(self, x: torch.Tensor) -> torch.Tensor:
b, c, h_, w_ = x.size()
x_h = x.mean(dim=3)
l_x_h, g_x_h_s, g_x_h_m, g_x_h_l = torch.split(x_h, self.group_chans, dim=1)
x_w = x.mean(dim=2)
l_x_w, g_x_w_s, g_x_w_m, g_x_w_l = torch.split(x_w, self.group_chans, dim=1)
x_h_attn = self.sa_gate(self.norm_h(torch.cat((
self.local_dwc(l_x_h),
self.global_dwc_s(g_x_h_s),
self.global_dwc_m(g_x_h_m),
self.global_dwc_l(g_x_h_l),
), dim=1)))
x_h_attn = x_h_attn.view(b, c, h_, 1)
x_w_attn = self.sa_gate(self.norm_w(torch.cat((
self.local_dwc(l_x_w),
self.global_dwc_s(g_x_w_s),
self.global_dwc_m(g_x_w_m),
self.global_dwc_l(g_x_w_l)
), dim=1)))
x_w_attn = x_w_attn.view(b, c, 1, w_)
return x * x_h_attn * x_w_attn
- 对应实现参考:
mmpretrain/models/attentions/SCSA.py:76-101
渐进式通道自注意力(PCSA)
-
核心功能:在保留空间先验的前提下,通过通道维度的单/多头自注意力度量通道间相似性并重校准通道响应。
-
核心优势:通道级自注意力比卷积更强的输入感知与交互能力,配合渐进式压缩有效缓解多语义融合的语义差异。
-
核心代码(片段):
import torch
import torch.nn as nn
from einops import rearrange
from mmengine.model import BaseModule
class SCSA(BaseModule):
def __init__(self, dim, head_num, window_size=7,
qkv_bias=False, attn_drop_ratio=0., gate_layer='sigmoid',
down_sample_mode='avg_pool'):
super().__init__()
self.dim = dim
self.head_num = head_num
self.head_dim = dim // head_num
self.scaler = self.head_dim ** -0.5
self.conv_d = nn.Identity()
self.norm = nn.GroupNorm(1, dim)
self.q = nn.Conv2d(dim, dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.k = nn.Conv2d(dim, dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.v = nn.Conv2d(dim, dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.ca_gate = nn.Softmax(dim=1) if gate_layer == 'softmax' else nn.Sigmoid()
if window_size == -1:
self.down_func = nn.AdaptiveAvgPool2d((1, 1))
else:
if down_sample_mode == 'avg_pool':
self.down_func = nn.AvgPool2d(kernel_size=(window_size, window_size), stride=window_size)
elif down_sample_mode == 'max_pool':
self.down_func = nn.MaxPool2d(kernel_size=(window_size, window_size), stride=window_size)
def pcsa(self, x: torch.Tensor) -> torch.Tensor:
y = self.down_func(x)
y = self.conv_d(y)
_, _, h_, w_ = y.size()
y = self.norm(y)
q = self.q(y); k = self.k(y); v = self.v(y)
q = rearrange(q, 'b (hn hd) h w -> b hn hd (h w)', hn=int(self.head_num), hd=int(self.head_dim))
k = rearrange(k, 'b (hn hd) h w -> b hn hd (h w)', hn=int(self.head_num), hd=int(self.head_dim))
v = rearrange(v, 'b (hn hd) h w -> b hn hd (h w)', hn=int(self.head_num), hd=int(self.head_dim))
attn = q @ k.transpose(-2, -1) * self.scaler
attn = self.attn_drop(attn.softmax(dim=-1))
attn = attn @ v
attn = rearrange(attn, 'b hn hd (h w) -> b (hn hd) h w', h=int(h_), w=int(w_))
attn = attn.mean((2, 3), keepdim=True)
attn = self.ca_gate(attn)
return attn * x
- 对应实现参考:
mmpretrain/models/attentions/SCSA.py:105-132

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)