使用Ray RLlib构建自定义强化学习环境
参考文章:使用Ray RLlib构建自定义强化学习环境
原文的代码API以及一些函数因为Ray库更新版本的变动无法使用。我在实操中重新参考了库的官方文档后对一些代码接口进行了修改,最终能运行起来得到结果。
当前版本
Name: ray
Version: 2.51.1
Summary: Ray provides a simple, universal API for building distributed applications.
Home-page: https://github.com/ray-project/ray
Author: Ray Team
Author-email: ray-dev@googlegroups.com
License: Apache 2.0
在现代强化学习研究和应用中,构建自定义环境和模型是实现特定任务目标的关键步骤。Ray RLlib作为一个可扩展的强化学习库,提供了丰富的API和工具来帮助开发者快速搭建和训练强化学习系统。本文将基于实际代码示例,详细介绍如何使用Ray RLlib构建自定义强化学习环境和模型。
环境构建与注册
构建强化学习系统的第一步是定义环境。在Ray RLlib中,环境需要继承自Gymnasium的Env类,并实现必要的接口方法。以下是一个自定义环境的示例:
import gymnasium as gym
from gymnasium import spaces
import numpy as np
class MyCustomEnv(gym.Env):
def __init__(self, config=None):
super(MyCustomEnv, self).__init__()
self.config = config or {}
# 定义观测空间和动作空间
self.observation_space = spaces.Box(low=-1.0, high=1.0, shape=(4,), dtype=np.float32)
self.action_space = spaces.Discrete(2)
self.state = None
def reset(self, *, seed=None, options=None):
# 重置环境状态并返回初始观测
self.state = np.zeros(4, dtype=np.float32)
return self.state, {}
def step(self, action):
# 执行动作并返回结果
reward = 1.0 if action == 1 else 0.0
self.state = self.state + np.random.randn(4) * 0.01
# 让episode在小概率下结束
done = np.random.rand() < 0.05
truncated = False
info = {}
return self.state, reward, done, truncated, info
在上述代码中,我们定义了一个简单的离散动作环境,其观测空间是一个4维向量,动作空间包含两个离散动作。环境的[reset](file:///D:/PycharmProjects/RayRLEnvLab/RLEnvBuilderRay.py#L32-L35)方法用于初始化环境状态,[step](file:///D:/PycharmProjects/RayRLEnvLab/RLEnvBuilderRay.py#L37-L48)方法用于执行动作并返回新的状态、奖励、终止标志等信息。
定义好环境后,需要将其注册到Ray RLlib中,以便算法可以正确识别和使用:
from ray.tune.registry import register_env
def my_env_creator(env_config):
return MyCustomEnv(env_config)
register_env("MyEnv-v0", my_env_creator)
通过注册环境,我们可以使用字符串标识符"MyEnv-v0"来引用自定义环境,这使得配置和管理变得更加灵活。
自定义模型实现
在强化学习中,策略网络是决定智能体行为的核心组件。Ray RLlib允许开发者实现自定义模型来满足特定需求:
import torch
import torch.nn as nn
import torch.nn.functional as F
from ray.rllib.models.torch.torch_modelv2 import TorchModelV2
from ray.rllib.models.modelv2 import ModelV2
from ray.rllib.utils.annotations import override
class MyCustomDNNModel(TorchModelV2, nn.Module):
def __init__(self, obs_space, action_space, num_outputs, model_config, name):
TorchModelV2.__init__(self, obs_space, action_space, num_outputs, model_config, name)
nn.Module.__init__(self)
# 构建神经网络
input_size = obs_space.shape[0]
hidden_size = 64
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, hidden_size)
# 策略输出层和价值函数输出层
self.policy_layer = nn.Linear(hidden_size, num_outputs)
self.value_layer = nn.Linear(hidden_size, 1)
self._value_out = None
@override(ModelV2)
def forward(self, input_dict, state, seq_lens):
# 前向传播
obs = input_dict["obs"].float()
x = F.relu(self.fc1(obs))
x = F.relu(self.fc2(x))
logits = self.policy_layer(x)
self._value_out = self.value_layer(x).squeeze(1)
return logits, state
@override(ModelV2)
def value_function(self):
# 返回价值函数输出
return self._value_out
自定义模型需要继承TorchModelV2和nn.Module,并实现forward和value_function方法。forward方法处理观测并输出策略logits,value_function方法返回状态价值估计。定义好模型后同样需要注册:
from ray.rllib.models import ModelCatalog
ModelCatalog.register_custom_model("my_dnn_model", MyCustomDNNModel)
算法配置与训练
Ray RLlib的新版本采用了链式配置方式来构建算法实例。对于PPO算法,配置过程如下:
from ray.rllib.algorithms.ppo import PPOConfig
config = (
PPOConfig()
.environment(env="MyEnv-v0")
.env_runners(num_env_runners=2)
.framework("torch")
.training(
model={
"custom_model": "my_dnn_model",
},
train_batch_size=4000,
lr=1e-3,
)
)
# 设置SGD参数
config.sgd_minibatch_size = 128
# 禁用新API栈以兼容自定义ModelV2
config.api_stack(
enable_rl_module_and_learner=False,
enable_env_runner_and_connector_v2=False
)
# 构建算法实例
trainer = config.build_algo()
在配置过程中,我们指定了环境名称、并行环境运行器数量、使用PyTorch框架、自定义模型以及其他训练参数。需要注意的是,如果使用自定义ModelV2,必须禁用新API栈以确保兼容性。
训练过程通过循环调用train方法实现:
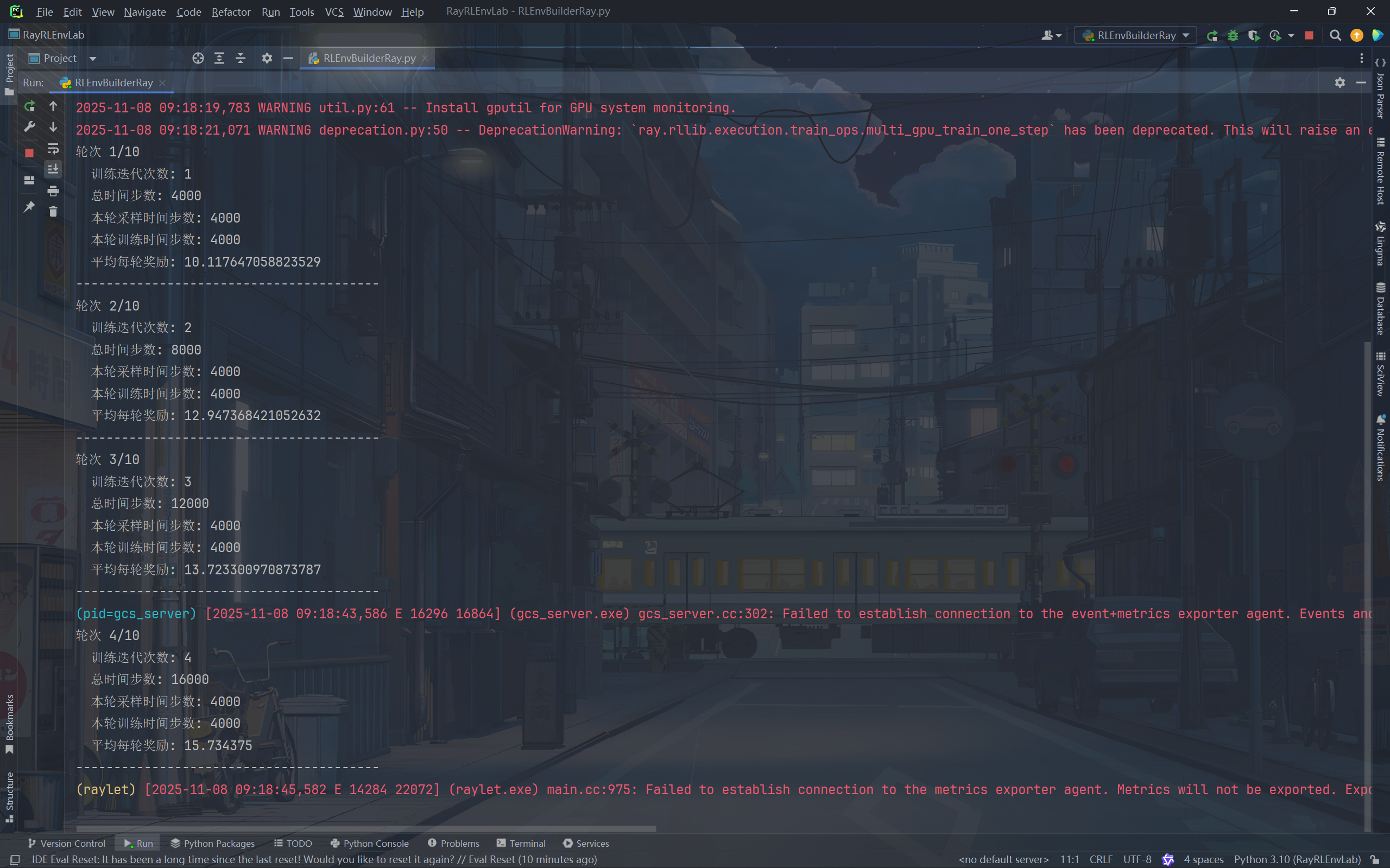
for i in range(10):
result = trainer.train()
print(f"轮次 {i+1}/10")
print(f" 训练迭代次数: {result['training_iteration']}")
print(f" 总时间步数: {result['timesteps_total']}")
if 'env_runners' in result and 'episode_reward_mean' in result['env_runners']:
print(f" 平均每轮奖励: {result['env_runners']['episode_reward_mean']}")
每次训练迭代中,算法会收集指定数量的经验数据并进行策略更新。通过监控训练结果中的指标,可以了解智能体的学习进度。
模型保存与加载
训练完成后,需要将模型保存以便后续使用:
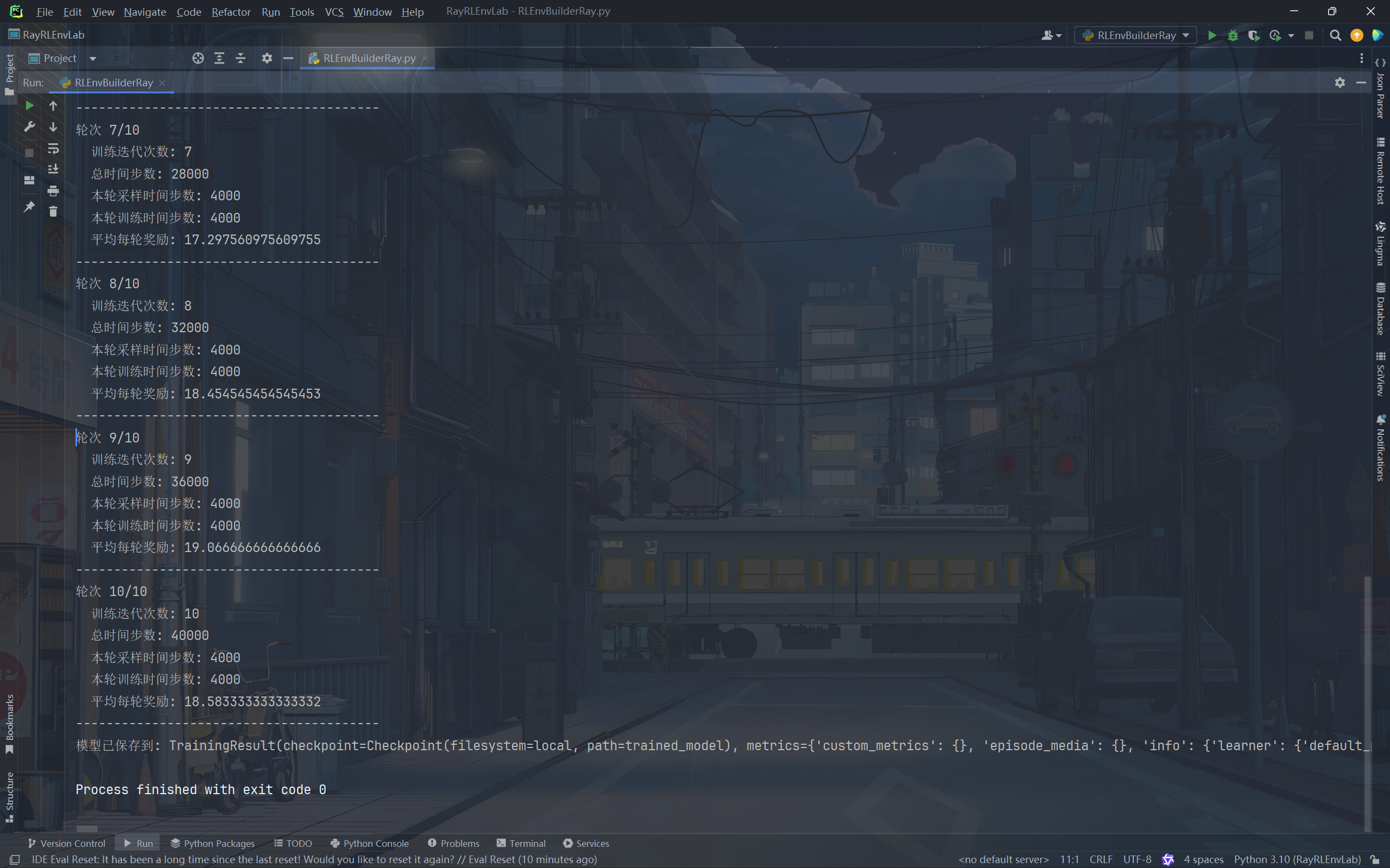
checkpoint_path = trainer.save("trained_model")
print(f"模型已保存到: {checkpoint_path}")
保存的模型包含策略网络权重、算法配置和元数据等信息,组织结构如下:
trained_model/
├── algorithm_state.pkl
├── rllib_checkpoint.json
└── policies/
└── default_policy/
├── policy_state.pkl
└── rllib_checkpoint.json
在其他项目中可以加载保存的模型进行推理:
from ray.rllib.algorithms.ppo import PPO
# 加载保存的模型
algo = PPO.from_checkpoint("trained_model")
# 使用模型进行推理
action = algo.compute_single_action(observation)
运行结果
关键技术要点
在使用Ray RLlib构建强化学习系统时,有几个关键技术要点需要注意:
首先,API版本兼容性是常见问题。随着Ray RLlib的不断更新,许多API发生了变化。例如,rollouts方法已被env_runners替代,build方法已被build_algo替代。此外,新API栈与自定义ModelV2不兼容,需要显式禁用。
其次,环境接口需要符合Gymnasium标准。与旧版Gym不同,Gymnasium的reset方法需要接受seed和options参数,并返回(obs, info)元组;step方法需要返回(obs, reward, terminated, truncated, info)五个值。
最后,训练结果的指标获取需要注意键名变化。新版RLlib的训练结果可能不包含episode_reward_mean等常用键,需要先检查result.keys()确认实际存在的指标键名。
通过以上步骤,我们可以成功构建一个完整的强化学习系统,包括自定义环境、自定义模型、算法配置、训练过程和模型保存加载。这种方法为解决各种复杂的强化学习问题提供了灵活且可扩展的解决方案。
源码:https://github.com/Accelemate/RayRLEnvLab

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)