基于像素与特征的域自适应目标检测
基于像素和特征级别的域自适应在自动驾驶目标检测中的应用
摘要
为许多实际任务标注大规模数据集以训练现代卷积神经网络是极其昂贵且耗时的。一种替代方法是在带标签的合成数据集上训练模型,并将其应用于真实场景中。然而,由于合成数据集与真实数据集之间的域偏差,这种直接的方法通常难以很好地泛化。尽管已提出多种无监督域自适应(UDA)方法来解决这一问题,但大多数方法仅关注简单的分类任务。本文提出了一种新颖的UDA模型,该模型结合了基于图像和特征级别的迁移适应,以解决跨域目标检测问题。我们采用生成对抗网络的目标函数和循环一致性损失进行图像转换。此外,提出了基于区域提议的特征对抗训练和分类,以进一步最小化域间差异并保持目标对象的语义。在多个不同的适应场景下进行了大量实验,结果验证了所提出的方法的鲁棒性和优越性。
1. 引言
目标检测旨在为图像中的每个物体分配一个边界框及其类别标签,例如“行人”、“自行车”、“摩托车”或“汽车”。它在现代自动驾驶系统中起着重要作用,因为检测其他交通参与者至关重要,如图1所示。

尽管自2012年AlexNet [1]引入以来,目标检测算法的性能已大幅提升,但在实际应用中仍远未达到令人满意的程度,主要原因在于数据有限且标注成本高昂。基于深度神经网络的监督学习算法需要大量精细标注的图像,而在实际情况中极难获取。例如,仅对Cityscapes数据集[2]中的一张图像进行标注以用于驾驶场景理解,几乎需要花费九十分钟。即使该数据集已经是最大的驾驶场景数据集之一,也仅有2975张带有精细标注的训练图像。解决此问题的一个有前景的方法是在合成数据集上训练模型。幸运的是,随着图形学和仿真基础设施的显著进展,许多具有高质量标注的大规模数据集被生成,用以模拟不同的真实场景。然而,仅在渲染图像上训练的模型无法被广义地到真实情况,由于存在域偏差或域偏移[3,4]问题。
在过去的几年中,许多研究人员提出了各种无监督域自适应(UDA)方法[5]来解决这一问题。然而,其中大多数方法仅关注简单的分类任务,不适合更复杂的视觉任务,如目标检测或语义分割。本文提出了一种新的UDA模型,该模型在像素和特征空间中均进行迁移适应,以应对自动驾驶中的复杂目标检测问题。在UDA的设定下,我们将基于带有真实标签的源数据集训练的模型推广至没有任何标注的目标数据集。
与本文最相近的研究工作是[6,7]。在[6]中,其图像生成模型基于生成对抗网络(GAN)进行训练,并同时与用于目标分类和姿态估计的任务模型结合。在[7]中,作者尝试基于CycleGAN[8]和传统分割网络来解决跨域语义分割问题。然而,该方法需要额外训练一个分割网络以保持翻译后图像的语义,从而减慢了整个训练过程。实际上,对于目标检测等特定任务而言,并不需要对所有图像像素给予同等关注。目标对象(如“汽车”或“行人”)比其他对象或背景(如“建筑物”或“天空”)更为重要。因此,本文提出了基于区域提议的特征对抗训练和分类方法,以进一步最小化域偏移并保持目标对象的语义。所开发的基于像素级和特征级的域自适应模块可以集成在一起,并以端到端的方式进行训练,以追求更好的检测性能。在多个数据集上进行的定性和定量结果表明了提出的方法的鲁棒性。
2. 相关工作
2.1. 目标检测
目标检测作为计算机视觉中的一个基本问题,自2012年以来随着深度神经网络的发展取得了巨大进展。基于AlexNet,许多不同的卷积神经网络(CNN),如VGG网络[11]、GoogleNet [12]、ResNet [13]、密集连接网络 [14]等,被提出以从数据中学习更强大的深度特征。目标检测算法也受益于这些网络架构,因为更好的特征对其他视觉任务同样有帮助。除了不同的网络架构外,近年来的基于CNN的目标检测器主要可分为两类:单阶段检测器(YOLO [15,16]和SSD [17,18])和两阶段检测器(Faster R-CNN [19]和R-FCN [20]等)。单阶段检测器基于默认锚框直接在一个图像内预测目标标签和边界框坐标,检测速度快但精度不够高。相比之下,两阶段检测器首先基于CNN特征生成大量区域提议,然后使用复杂头部网络对这些提议进行识别,因此性能优于单阶段检测器,但检测速度较慢。
2.2. 无监督域适应
无监督域适应旨在利用具有真实标签的不同但相关源域中的训练数据,来解决目标域中无标签的学习问题。尽管该问题在计算机视觉领域已被研究多年,但如何有效进行无监督域适应仍是一个开放的研究课题。
潘等人[21]提出了迁移成分分析(TCA),这是一种基于最大均值差异(MMD)[22]的核方法,用于跨域学习更优的特征表示。在TCA的基础上,[23]提出了一种新的联合分布自适应方法,同时对边缘分布和条件分布进行自适应,从而对显著的分布差异具有鲁棒性。近年来,随着深度学习的发展,许多研究致力于在神经网络中学习深度域不变特征。
例如,龙等人[24,25]提出将隐藏层网络特征嵌入再生核希尔伯特空间,并使用MMD及其变体显式度量两个域之间的差异。孙等人[26]试图通过匹配源域与目标域特征分布的二阶统计量来最小化域偏移。然而与显式建模术语以衡量域差异不同,另一类工作利用对抗训练来隐式地寻找域不变特征表示。加宁等人[27,28]在深度神经网络模型中增加了一个域分类器,用于对输入的域进行分类。通过反转来自域分类损失的梯度来进行对抗训练。与使用共享特征层不同,曾兹等人[29]提出通过训练一个具有类似于传统GAN模型[30]目标的独立网络,来学习目标域数据的不可区分特征。然后将其与在源域上训练的分类器结合用于识别任务。在[31]中,作者认为每个域应具有其自身的特定特征,只有部分特征在不同域之间共享。因此,他们显式地建模了私有和共享域表示,并仅对这些共享部分进行对抗训练。
尽管已提出许多方法来解决无监督域适应问题,但大多数方法仅关注简单的分类任务。针对更复杂的任务(如目标检测或语义分割)的研究工作非常有限。据我们所知,[32]是首个处理目标检测领域迁移适应问题的工作。他们在卷积层和全连接层的特征上进行对抗训练,同时结合检测任务的常规训练。该方法使用域标签一致性检查作为正则化项,以帮助网络学习更具域不变性的特征。尽管在[32]中取得了良好的检测结果,但我们认为,在特征空间和图像像素空间同时进行迁移适应将是最好的选择,因为仅适应高层特征可能无法充分建模低层图像细节。因此,本提出的方法也与图像转换密切相关。
2.3. 图像到图像转换
目前,许多研究工作致力于将图像转换为另一种风格。斯里瓦斯塔瓦等人[33–37]基于存在配对训练图像的假设进行图像转换,但该方法不适用于无监督域适应问题。其他一些近期工作尝试利用非配对图像来解决这一问题。刘等人[38,39]通过共享部分网络权重来学习多模态图像的联合分布。PixelDA[6]提出了一种新颖的基于生成对抗网络的架构,用于跨域图像转换。然而,该方法需要事先了解图像中哪些部分对内容相似性损失有贡献。神经风格迁移[40–42]是另一种将一幅图像转换为另一种风格的方法,通过在反向传播过程中优化像素值来保持其自身内容。风格迁移的一个缺点是,它仅针对两幅特定图像之间的转换,而无法扩展到数据集层面。最近提出的CycleGAN模型[8]是一种用于非配对图像转换的有前景方法。作者利用循环一致性损失对生成模型进行正则化,从而保留转换后图像的结构信息。然而,该方法只能保证:如果某一区域在转换前被某个物体占据,则在生成后该区域仍会被某个物体占据。仅依靠循环一致性损失无法保证像素语义的一致性。
3. 方法
我们研究无监督跨域目标检测问题,假设有带真实标签Y_s的源域图像X_s和不带任何标签的目标域图像X_t。我们的目标是利用源数据集训练检测网络,使其在目标数据集上也能表现良好。整个框架如图2所示。

该模型包含两个模块:(1)基于CycleGAN的像素级域适应(PDA)和基于Faster R-CNN的特征级域适应(FDA)。这两个模块可以集成在一起,并以端到端的方式进行训练,以追求更好的性能。源域图像首先被转换为目标图像风格,然后将转换后的图像与来自目标数据集的采样图像一起用于训练目标检测器和域分类器。
3.1. 基于像素级的域适应
我们首先介绍基于像素级别的域自适应模块。如图2所示,采用两个对称的生成网络G_s−t和G_t−s,分别在两个域中生成图像fake−t和fake−s。另外两个判别器D_s和D_t被训练以区分真实采样和伪造生成的图像。
整个训练过程以极小-极大方式进行,其中生成器始终尝试生成无法与真实图像区分的图像,而判别器则同时被训练以更好地区分真实和伪造图像。生成器G_s−t和判别器D_t的总体目标可表示为公式(1)。
$$
L_{GAN}(D_t, G_{s-t}) = E_{t \sim X(t)}[\log D_t(x)] + E_{s \sim X(s)}[\log(1 - D_t(G_{s-t}(s)))].
$$
类似的方程也可以为G_t−s 和D_s建立,即L_GAN(D_s, G_t−s),此处予以忽略。这类GAN目标函数理论上可以学习映射函数G_s−t和G_t−s,以生成从X_t和X_s数据分布中采样的相同图像。然而,它也面临模式崩溃[30]以及丢失源域图像结构信息的问题。为解决这些问题,本文采用循环一致性损失,迫使由G_s−t生成的假图像fake−t在送入生成器G_t−s后得到的结果与真实图像real−s一致,反之亦然。整个循环一致性损失在公式(2)中给出。
$$
L_{cyc}(G_{t-s}, G_{s-t}) = E_{t \sim X(t)}[|G_{s-t}(G_{t-s}(x_t)) - x_t| 1] + E {s \sim X(s)}[|G_{t-s}(G_{s-t}(x_s)) - x_s|_1].
$$
因此,CycleGAN训练的完整目标是
$$
L_{cyc-gan}(G_{t-s}, G_{s-t}, D_t, D_s) = L_{GAN}(D_t, G_{s-t}) + L_{GAN}(D_s, G_{t-s}) + \lambda_{cyc} L_{cyc}(G_{t-s}, G_{s-t}),
$$
以解决目标为
$$
G^ _{s-t}, G^ {t-s} = \arg\min {G_{s-t}, G_{t-s}} \max_{D_s, D_t} L_{cyc-gan}(G_{t-s}, G_{s-t}, D_t, D_s).
$$
3.2. 基于特征层的域自适应
我们的检测网络基于著名的Faster R-CNN框架。具体而言,区域提议网络(RPN)被训练用于生成区域提议,而快速R-CNN [10] 被用于边界框分类与回归。在该框架中新增了一个小型全卷积网络,以进一步实现域对抗训练。具体来说,输入是由相应区域提议从最终卷积特征中提取的特征。由检测损失和反向域分类损失产生的梯度将流入共享卷积层,以学习用于目标检测的域不变特征。
Faster R-CNN的损失函数。假设检测任务中有m个类别,区域分类层将为每个区域提议输出一个m维的概率分布,即p_obj = (p_obj^0, p_obj^1, …, p_obj^m),其中多出的一个类别用于表示背景。p∗_obj用于表示该区域提议的真实标签。边界框回归层会为每个可能的类别预测四个实数值t_obj,以逼近真实回归目标t∗_obj。此处t_obj和t∗_obj被归一化为[19],以便更好地训练网络。类似地,我们使用p_rp和p∗_rp进行RPN的训练。由于RPN仅被训练用于区分物体/非物体,因此标签p∗_rp只能是1或0。Faster R-CNN训练的完整目标可表示为公式(5)。
$$
L_{det}(p, p^ , t, t^ ) = L_{cls-det}(p_{obj}, p^ _{obj}) + [p^ {obj} \geq 1] L {loc-det}(t_{obj}, t^ _{obj}) + [p^ {rp} \geq 1] L {loc-rpn}(t_{rp}, t^*_{rp}),
$$
其中,L_cls−det和L_cls−rpn表示分类的交叉熵损失。L_loc−det和L_loc−rpn表示用于边界框回归的平滑L1损失[10]。艾弗森括号指示函数[p∗ ≥1]在真实目标类别为p时取值为1,否则为0。
FDA训练的损失。如图2所示,域分类器学习将虚假的−t分类为标签d = 0,将真实的−t分类为标签d= 1。然后在梯度流入共享卷积层之前进行梯度反转。域对抗训练的损失如公式(6)所示。
$$
L_{domain} = -\sum_{i,j}[d \log p_{i,j} + (1 - d) \log(1 - p_{i,j})],
$$
其中p_i,j表示第j张图像中第i个区域建议的分类输出。基于上述公式,我们可以将完整训练目标表示为公式(7),其中λ1、λ2是用于平衡不同损失的权重。
$$
L_{full} = L_{det} + \lambda_1 L_{domain} + \lambda_2 L_{cyc-gan}.
$$
4. 实现
4.1. 数据集
为了测试所提出方法的有效性,并与当前最先进的(SOTA)工作[32]进行比较,我们选择了Cityscapes、KITTI[43]、Foggy-Cityscapes[44]、VKITTI-雨天[45]和Sim10k[46]数据集进行实验。Cityscapes数据集包含2975张训练图像和500张验证图像。八类常见交通参与者被标注了实例标签。KITTI是另一个用于自动驾驶中不同视觉任务基准测试的著名数据集,包含7481张带边界框标注的训练图像,类别包括“汽车”、“行人”和“骑车人”。
Foggy-Cityscapes、VKITTI-雨天和Sim10k是模拟不同驾驶场景的合成数据集。特别是,Foggy-Cityscapes和VKITTI-雨天基于真实的Cityscapes和KITTI数据集渲染而成,以模拟雾天和雨天天气。Sim10k包含10,000张训练图像,这些图像采集自电脑游戏GTA5,并通过访问原始游戏引擎自动标注。在Sim10k数据集中,仅对检测任务中的“汽车”对象标注了边界框。因此,本文中基于Sim10k的实验仅计算和比较“汽车”的检测结果。 
4.2. 实现细节
我们在像素适应模块的两个生成器中使用带有层间跳跃连接的U-Net结构[47],并在另外两个判别器上使用PatchGAN[36]。采用实例归一化,因为如原始CycleGAN论文所述,其效果更佳。对于检测网络,我们使用VGG16[11]作为骨干网络,并采用一个小型全卷积网络进行域对抗训练。基于特征级的对抗训练的输入是根据RPN模块生成的64个区域建议裁剪后的VGG16的Conv5特征。在实际的训练过程中,我们选择首先分别预训练检测网络和图像转换网络,然后基于这两个预训练模型进行端到端训练。这主要考虑到大多数生成图像的实际情况。
在像素级自适应模块的初始训练阶段,噪声相当大。我们使用Adam优化器和初始学习率0.0002来训练PDA模块。经过30轮次后,在接下来的30轮次训练过程中,学习率线性衰减至零。FDA模块与目标检测网络一起基于标准SGD算法进行训练,初始学习率为0.001。经过6轮次后,我们将学习率降低至0.0001,并再训练网络3轮次。在反向传播过程中,来自域分类器的梯度在流入共享CNN层之前会被反转。对于端到端训练,上述所有初始学习率均缩小十倍。然后我们对整个网络再进行10轮次的微调,其中λ1和λ2设置为0.5。
5. 结果与讨论
我们在三种适应场景下展示了实验结果:“从合成到真实”、“跨不同天气”和“跨不同摄像头”。具体来说,“Sim10k → Cityscapes”和“Sim10k → KITTI”用于“从合成到真实”场景的实验;“Cityscapes → Foggy-Cityscapes”和“KITTI → VKITTI-Rainy”用于“跨不同天气”场景;“Cityscapes → KITTI”和“KITTI → Cityscapes”用于“跨不同摄像头”场景。对于每一对数据集,我们进行了三次实验,分别考虑PDA模块、FDA模块以及最终的端到端训练。为了测试PDA模块的有效性,我们仅对图像转换部分进行网络训练,并使用翻译后的图像来训练一个纯检测网络。在FDA训练中,我们直接将源域图像作为检测训练的输入,同时将目标域中随机采样的图像与源域图像结合,用于基于特征级的对抗训练。最后,我们将两个模块集成在一起,对整个网络进行端到端训练。所有结果均采用常用的平均精度(AP)和平平均精度(mAP)指标进行评估,IoU阈值设为0.5。
5.1. 合成到真实
在此场景中,检测器在合成数据集上进行训练,并在真实数据集上进行评估。
Sim10k → Cityscapes 。为了研究所提出方法的有效性,我们首先考虑消除计算机合成数据集Sim10k与真实数据集Cityscapes之间的域偏差。表1展示了使用不同适应模块的结果。我们的基线结果基于Faster R-CNN,在源Sim10k上进行训练,并直接在Cityscapes上进行评估。使用VGG16骨干网络时,计算得到的mAP为30.1%。与基线结果和当前最先进的技术相比,所提出的方法分别获得了9.5%和0.6%的性能提升。具体而言,所提出的基于特征级的对抗训练可将基线性能提升至33.8%。PDA模块可带来7.78%的增益。当进行端到端训练时,我们可以获得优于当前最先进的技术的结果。
| Table 1 检测结果(“汽车”的平均精度 (%))在Cityscapes验证集和KITTI训练数据集上进行评估,源数据集为Sim10k。 | ||
|---|---|---|
| Sim10k → Cityscapes | Sim10k → KITTI | |
| Faster R-CNN | 30.1 | 52.7 |
| 最先进的技术 [32] | 39.0 | – |
| 带PDA的Faster R-CNN | 37.8 | 58.4 |
| 带FDA的Faster R-CNN | 33.8 | 55.3 |
| Faster R-CNN w/ (PDA+ FDA) | 39.6 | 59.3 |
Sim10k → KITTI 。为进一步验证所提出方法在“从合成到真实”场景下的鲁棒性,实验采用KITTI数据集作为目标数据集。由于目前没有其他工作在此特定设置下报告检测结果,因此我们仅将我们的结果与基线结果进行比较。所有结果均在KITTI训练分割集上进行评估,如同[32]一样。如表1所示,基线Faster R-CNN网络的AP为52.7%。通过分别使用所提出的FDA和PDA模块,可将其提升至55.3%和58.4%。通过进行端到端训练,我们可以获得最高的结果59.3%。
5.2. 跨不同天气
除了“合成到真实”场景外,实验中还考虑了不同天气引起的域偏移问题。具体而言,所提出的方法被验证可用于处理驾驶场景中的雾天和雨天天气情况。
Cityscapes → Foggy-Cityscapes 。本实验中,Cityscapes及其雾天版本被用作源数据集和目标数据集。所有训练设置均与第5.1节相同。此处的主要目标是利用晴天采集的标注图像,使检测器适应雾天天气。实验结果如表2所示。与基线结果和当前最先进的技术相比,我们最终分别实现了10.1%和1.8%的性能提升。两个模块均能显著提高雾天环境下的检测性能。具体而言,Faster R-CNN的基线结果在使用FDA时可从18.8%提升至23.6%,在使用PDA时可提升至27.1%。
| Table 2 检测结果针对Cityscapes → Foggy-Cityscapes和KITTI → VKITTTI-雨天的迁移适应进行评估。 | ||
|---|---|---|
| Cityscapes → 雾天Cityscapes | KITTI → VKITTI-雨天 | |
| Faster R-CNN | 18.8 | 40.0 |
| 最先进的技术 [32] | 27.6 | – |
| 带PDA的Faster R-CNN | 27.1 | 51.3 |
| 带FDA的Faster R-CNN | 23.6 | 44.5 |
| Faster R-CNN w/ (PDA+ FDA) | 28.9 | 52.2 |
KITTI → VKITT-雨天 。为了验证该方法对雨天天气的鲁棒性,使用VKITTI-雨天作为目标数据集,KITTI作为源数据集。由于先前的最先进方法未在此情况下报告其结果,实验结果仅与基线Faster R-CNN进行比较。在雨天条件下实现了持续的性能提升。检测结果可以从40.0%提升到52.2%,通过端到端训练实现。还可以看到,在此情况下,PDA模块的表现优于FDA模块。
5.3. 跨不同摄像头
为了与当前最先进的技术工作进行全面比较,进一步开展了实验以应对因使用不同摄像头而引起的域偏差。两个真实数据集KITTI和Cityscapes被交替选为源数据集和目标数据集。结果如表3所示。以Cityscapes作为源数据集时,Faster R-CNN的基线结果可从53.5%提升至64.4%(使用PDA)和58.6%(使用FDA)。当使用KITTI作为源数据集时,检测结果可从30.2%提升至41.1%(使用PDA)和34.5%(使用FDA)。在两种适应设置下,提出的方法均优于当前最先进的技术,分别提升了1.5%和2.3%。
| Table 3 检测结果(汽车的平均精度 (%))针对Cityscapes→ KITTI和KITTI→ Cityscapes的迁移适应进行评估。 | ||
|---|---|---|
| Cityscapes → KITTI | KITTI → Cityscapes | |
| Faster R-CNN | 53.5 | 30.2 |
| 最先进的技术 [32] | 64.1 | 38.5 |
| 带PDA的Faster R-CNN | 64.4 | 41.1 |
| 带FDA的Faster R-CNN | 58.6 | 34.5 |
| Faster R-CNN w/ (PDA+ FDA) | 65.6 | 41.8 |
5.4. 分析与讨论
PDA与FDA。提出了两个模块(PDA和FDA)以减少源数据集与目标数据集之间的域偏差。还对整个网络进行了最终的端到端训练,以追求更优的跨域目标检测性能。定量消融结果进一步汇总于表4,以比较不同模块的有效性。
从表4可以看出,这两个模块在不同域偏差下均能有效提升检测器性能。图像像素级变换相比基于特征级的对抗训练效果要好得多,平均提升了两倍。由于PDA模块基于CycleGAN,图像像素在翻译过程后的语义一致性无法得到保证。然而,实验结果表明,图像转换仍然能有效提升检测器在目标数据集上的性能。这一现象可归结为两个原因。第一个原因是尽管翻译后的图像并非完美,但它们可以帮助检测器学习通用的面向目标的CNN特征。第二个原因是交通参与者是目标检测任务的主要关注点。由于不同驾驶场景中沿“道路”的结构布局相似,如图4所示,这些物体的语义在PDA下大多可以得到保留。尽管图像上部(即紫色、蓝色和绿色区域)在不同场景间有所变化,但下部(即红色和黄色区域)非常相似。在这些相似区域中,基于CycleGAN的PDA将主要关注颜色和纹理的转换。
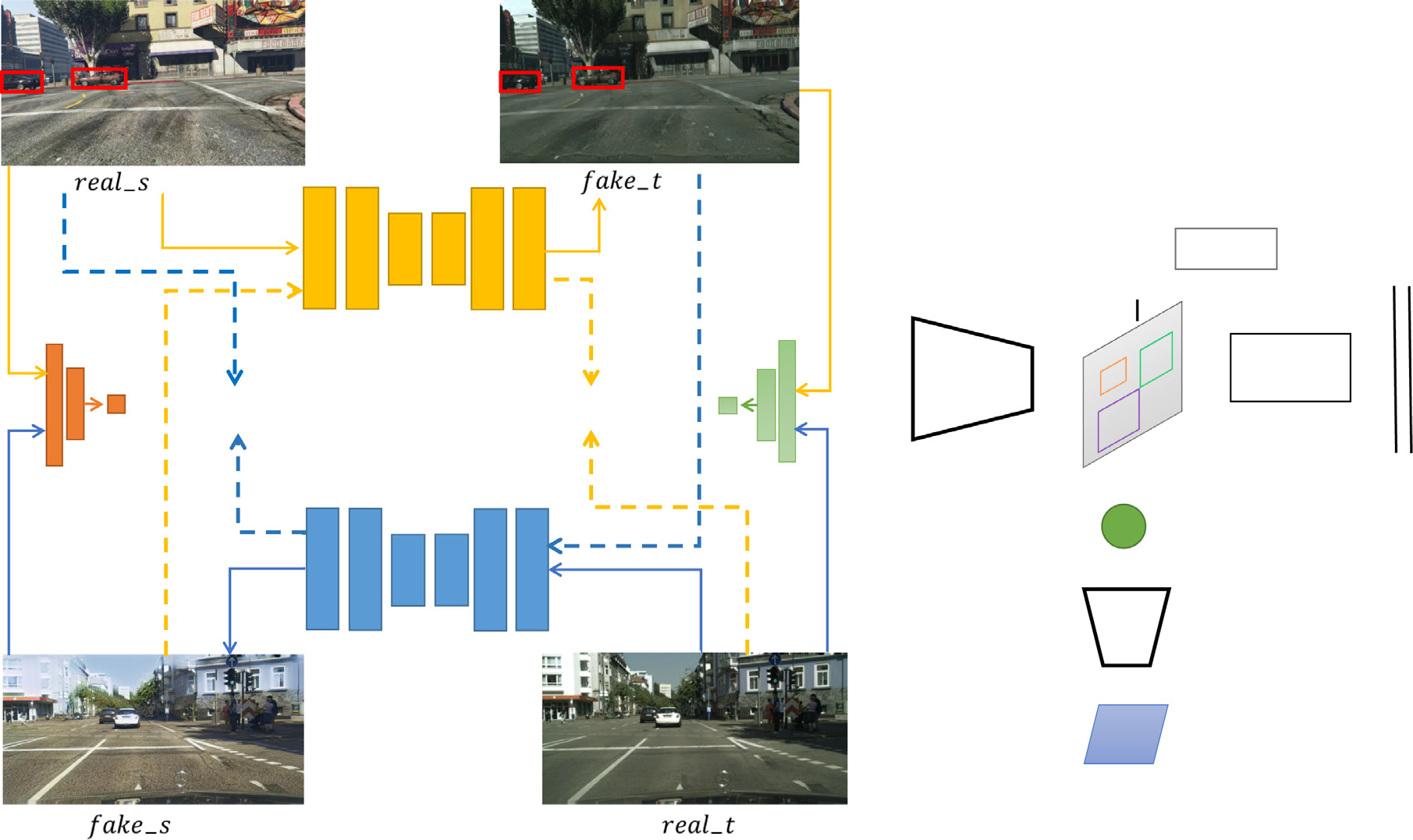
图5展示了Sim10k与Cityscapes之间更多的图像转换结果,以说明这一现象。通常情况下,合成数据集Sim10k与真实Cityscapes数据集在结构布局上有很大差异。Sim10k中的大多数图像拍摄于高速公路场景,而Cityscapes主要拍摄于城市环境。因此,从图5可以看出,Sim10k的许多图像像素被映射为“树”或“建筑物”,以适应Cityscapes的结构布局。类似地,在从Cityscapes到Sim10k的转换中,“树”和“建筑物”的像素大多被映射为“天空”。然而,沿“道路”的物体仍然得以保留,因为这两个数据集共享相似的布局。如图5所示,转换主要集中在颜色和纹理上。

进行/不进行端到端训练。在实验过程中,对整个网络进一步进行了额外10轮次的端到端训练。在此训练阶段,更加关注目标对象。PDA模块也会尝试生成更具真实感的对象,以减少FDA的对抗训练损失。定量上,通过进行端到端训练,在检测任务上可以进一步获得约1% ∼ 2%的提升。定性结果也在图6中展示,以便更好地比较翻译后的图像。仅使用PDA的结果显示在黄色矩形框中,端到端训练的结果显示在红色矩形框中。可以看出,结果更优。

分析的定性结果。图7展示了在不同场景下的定性图像转换结果。第1行和2显示了Sim10k合成图像与Cityscapes和KITTI真实感图像之间的转换。在此“从合成到真实”场景中,图像的结构差异较大。然而,沿“道路”的图像内容语义仍得以保持。第3行和第4行展示了Cityscapes到KITTI以及反向的转换结果。由于这两个数据集均采集自德国的城市,大多数图像具有相似的结构布局,因此在这两个实验设置中可以生成良好的结果。第5行和第6行展示了Cityscapes转换为其雾天版本以及KITTI转换为VKITTI-雨天的结果。在这些实验中,验证了提出的方法在应对此类城市不同天气(例如雾天或雨天)时的鲁棒性。由于城市的结构几乎保持不变,不同天气带来的域偏差主要来源于颜色和纹理。在此情况下,图像转换模块可以生成非常好的结果。

推理性能分析。提出的方法旨在将源域图像适配为目标域的风格,然后利用翻译后的图像作为增强数据来训练检测器。在推理过程中,可以简单地移除图像转换模块。因此,该方法将保持与Faster R-CNN相同的推理时间。类似于[32],输入图像的短边被缩放至500像素。使用NVIDIA Tesla M40 GPU时,基于VGG16的相应推理时间为165毫秒。
6. 结论与未来工作
本文提出了一种新的无监督域自适应方法,以解决自动驾驶领域中的目标检测问题。通过在图像像素和特征空间中进行迁移适应,我们能够取得优于当前最先进的方法的性能。大量实验被实施以验证所提出方法的有效性。未来,我们将尝试基于该提出的方法解决更复杂的跨域视觉任务,如实例分割或深度估计。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)