YOLOv1、YOLOv2、YOLOv3目标检测算法原理与实战第十一天|YOLOv2
YOLOv2(YOLO9000),预测更准确,速度更快,识别物体更多优点:1.缓解YOLOv1中定位不准确和检测召回率较低的问题缺点:1.小目标检测效果较差2.整体检测效果有待提高。
1.学习哔哩哔哩《YOLOv1、YOLOv2、YOLOv3目标检测算法原理与实战》
炮哥带你学视频链接
第3章 YOLOv2目标检测算法原理
3.1 YOLOv2算法原理先导
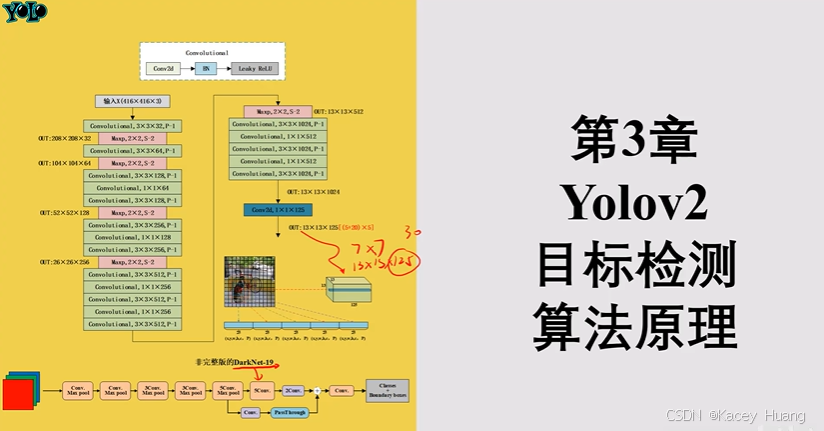
3.2 YOLOv2算法背景介绍
YOLOv2(YOLO9000),预测更准确,速度更快,识别物体更多

3.3 YOLOv2模型改进点
1.加入BN层
2.在分类训练的时候用更高分辨率的图片(448x448),原来用224x224的训练
3.去除全连接层,用卷积层进行输出,用预选框(锚框)进行预测
4.采用新的网络架构Darknet-19
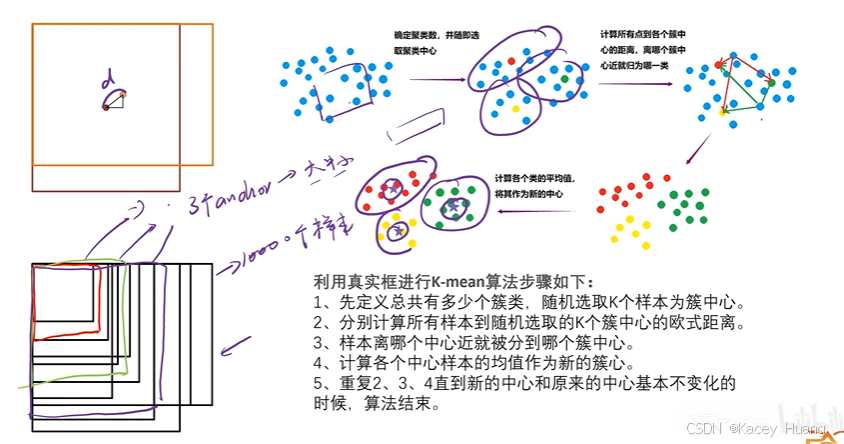
5.用K-means聚类算法找合理的一组anchor
6.用sigmoid进行位置预测
7.passthrough网络模型的连接方式(类似ResNet)
8.多尺度的输入数据训练模型
9.采用更高分辨率的网络进行检测主干网络的训练

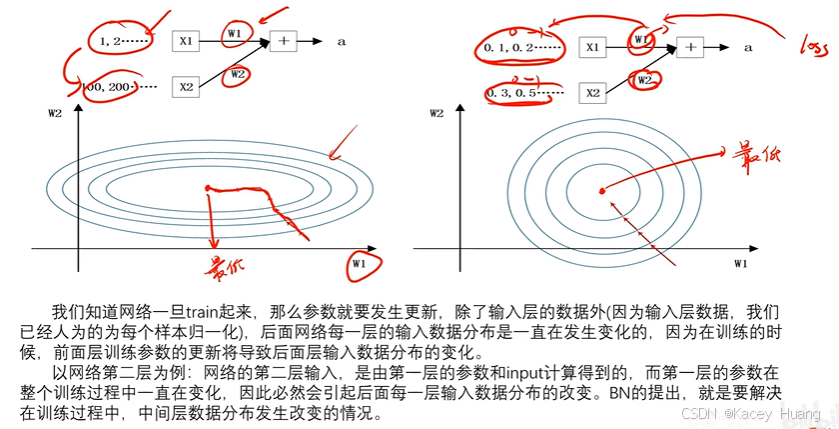
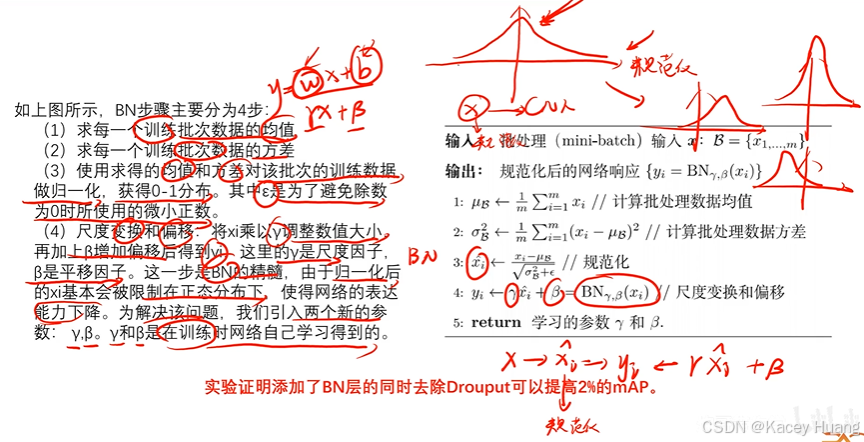
3.4 添加BN层
不加BN层的时候,可能小数值的x1更重要,那么更新的时候w1要变大,更新的比较慢,不容易找到最低点。加入BN层之后,更容易找到最低点
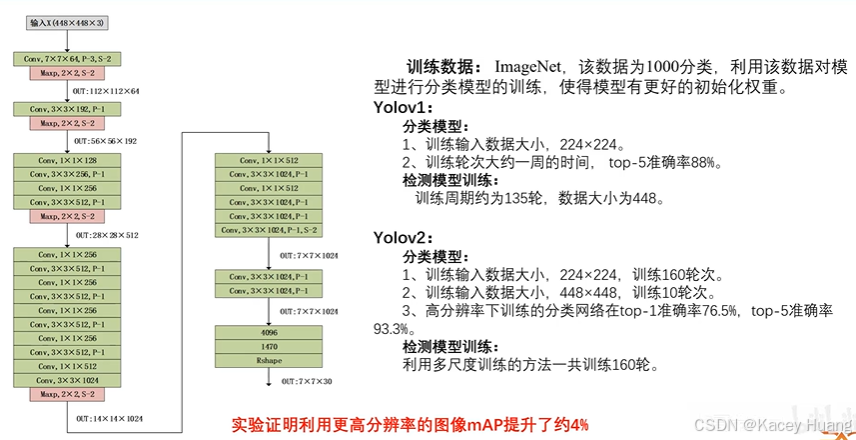
3.5 更高分辨的检测模型
YOLOv1在训练的时候分为两个阶段,第一阶段分类训练用的是224x224的数据,第二阶段检测的时候再用448x448
YOLOv2在第一阶段的时候先用224x224训练160轮,再用448x448训练10轮,第二阶段多尺度训练160轮
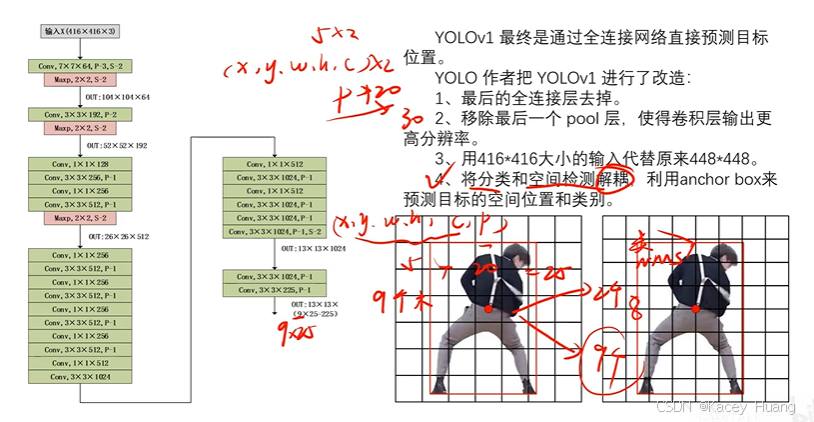
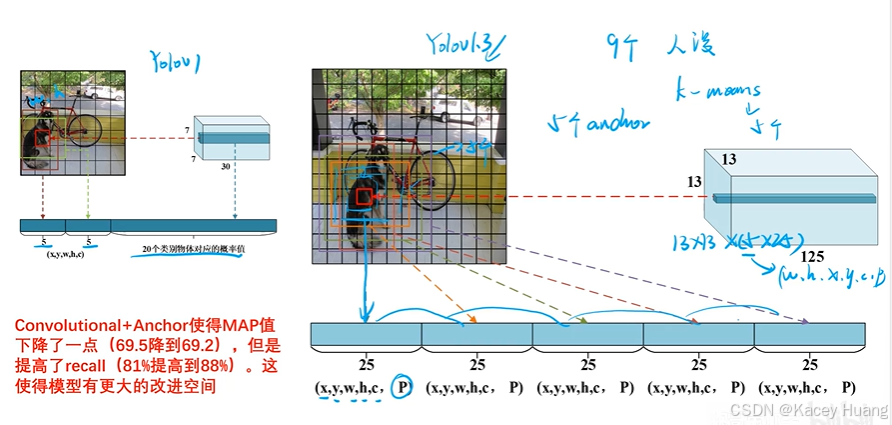
3.6 全卷积和anchor框的添加
全卷积和anchor框对mAP值有所下降,但是对Recall召回率(目标有没有找全)有所上升
全卷积改造:
1.全连接层参数太多,直接去掉全连接
2.去掉最后一个最大池化层,让卷积层输出更高分辨率
3.用416x416代替448x448,使最后的输出变成13x13,而不是14x14是因为训练集的目标物体通常在中心,为了减少检测框的中心落在小方格四个角的中心的概率
4.14x14x30改成13x13x225,225=九个检测框x(x,y,w,h,c,20p)
anchor框改造:在预选框的基础上去预测真实检测框,收敛会更快
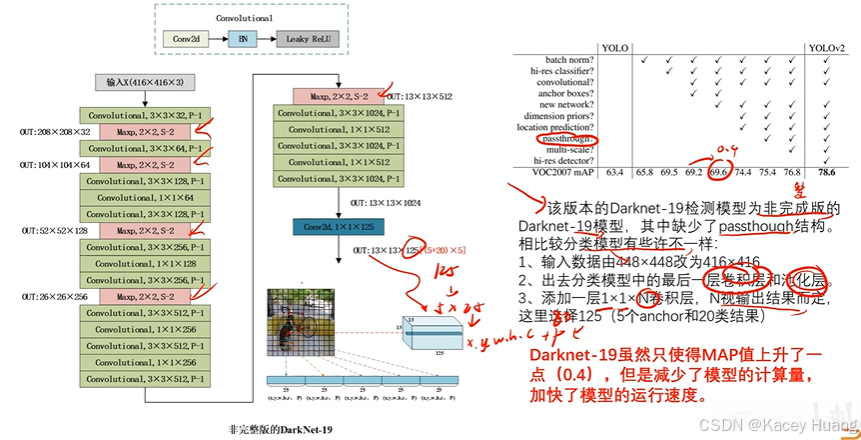
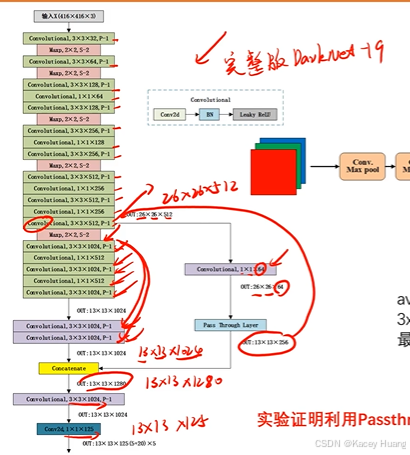
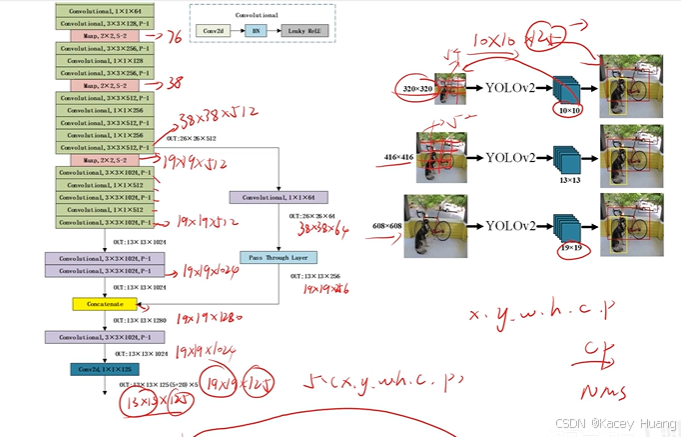
3.7 DarkNet19网络
分类模型:
1.精度和速度都有所提升
2.由于没有全连接层,所以对输入特征图的大小没有特殊规定(如果是全连接层,图片大会导致参数急剧增加,而1x1的卷积核做的只是通道之间的信息融合,宽和高不影响它)
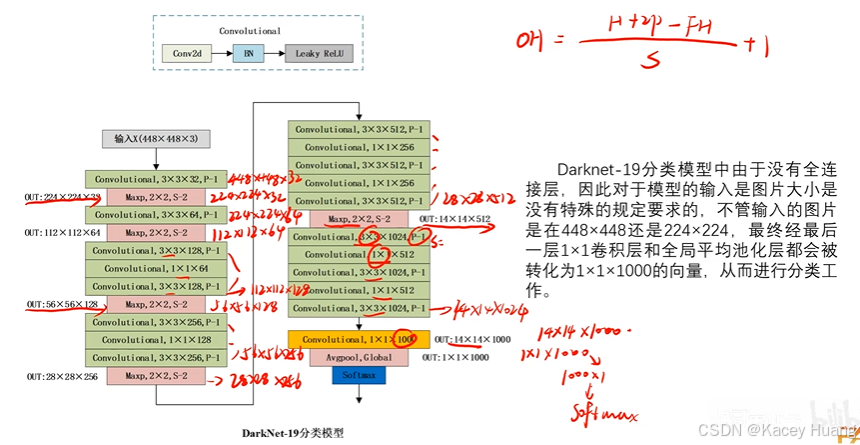
检测模型:去掉分类模型中的最后一层卷积层和池化层,加一层1x1xn的卷积层,n主要取决于想要输出多少类结果
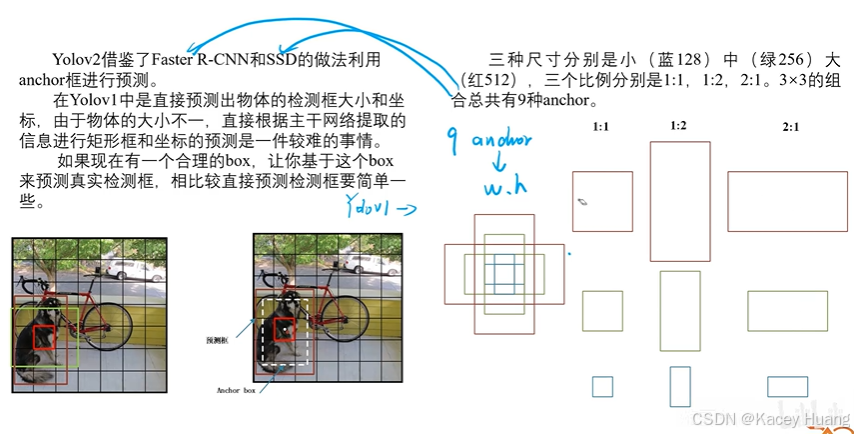
3.8 聚类寻找anchor框

3.9 改进聚类寻找anchor框
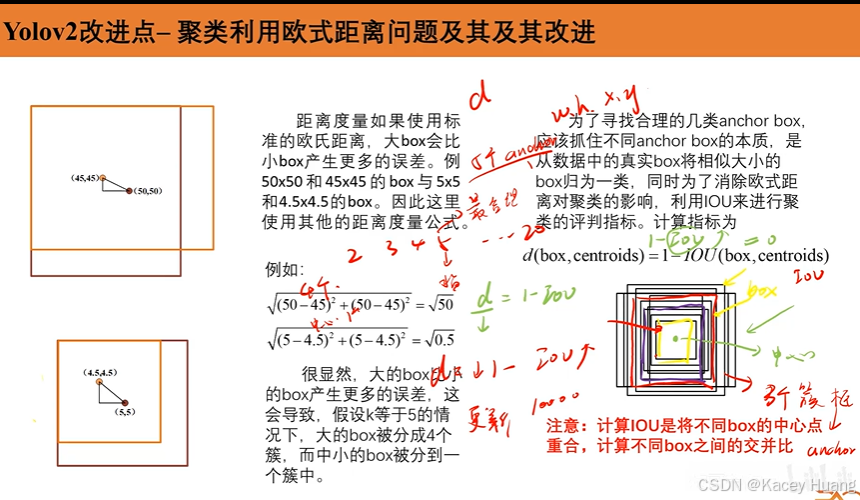
虽然k值越大分得越细,差距也越小,但是不能设置太多的anchor boxes

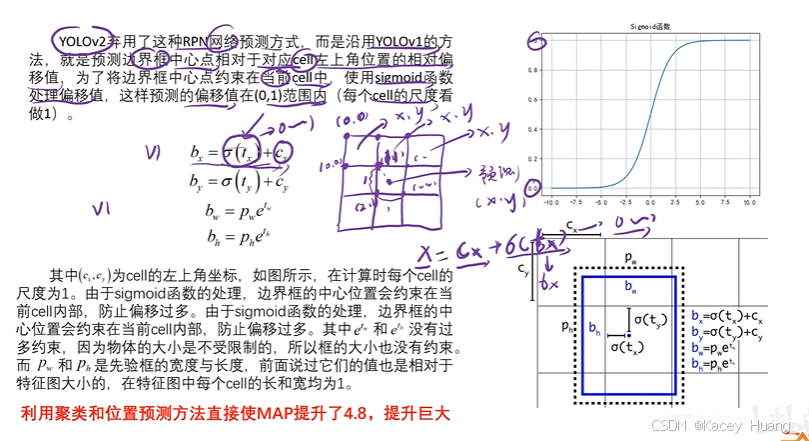
3.10 直接位置预测
anchor框,也称预选框、锚框、先验框
这种确定预测边界框的方式,由于d值大小不稳定,有可能使边界框跟先验框相比,偏离较大尺寸
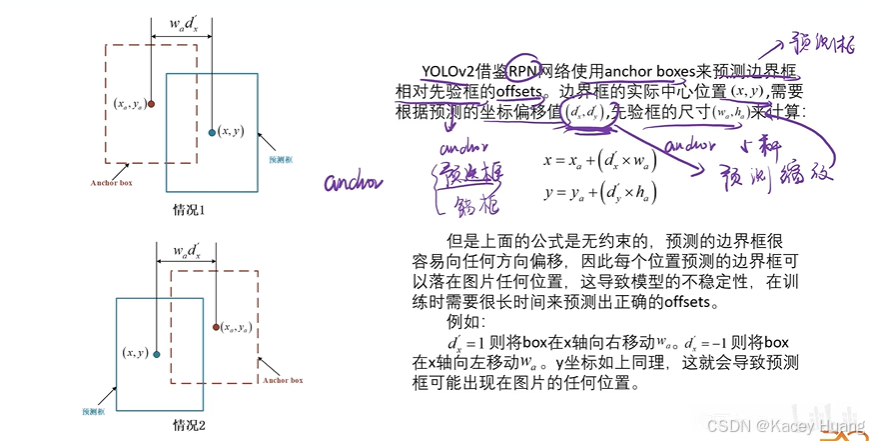
x,y坐标沿用YOLOv1,w,h用缩放的方式
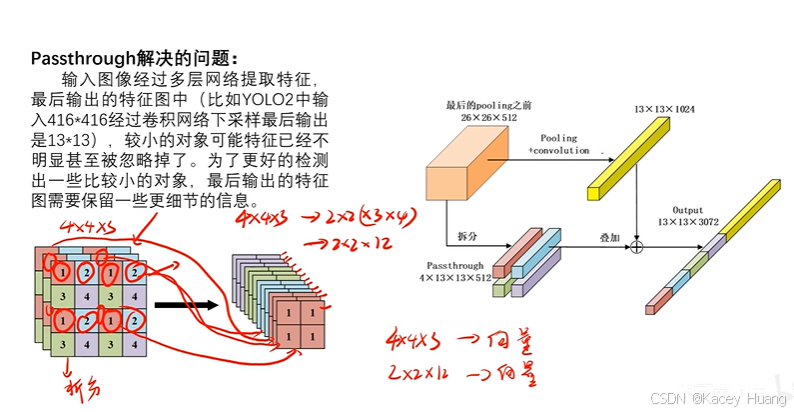
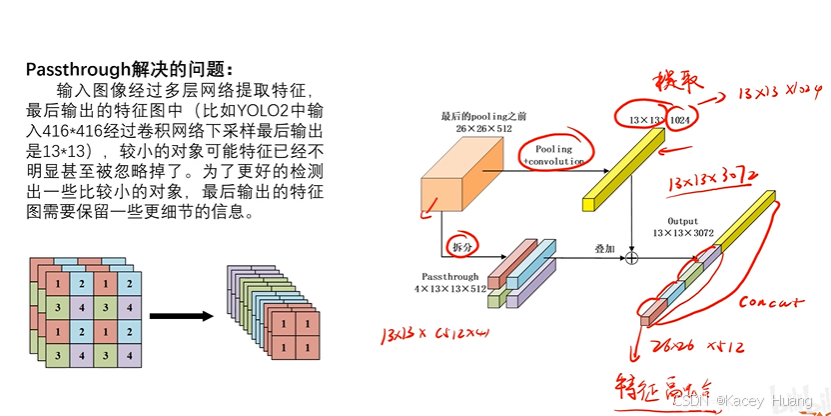
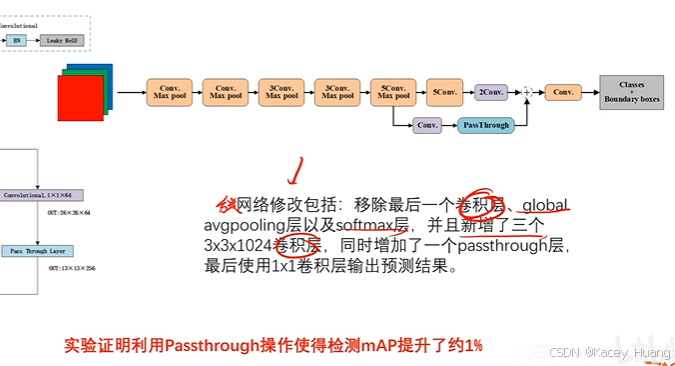
3.11 Passthrough
把特征图拆成小的特征图,然后跟卷积后的特征图通道做一个concat的操作
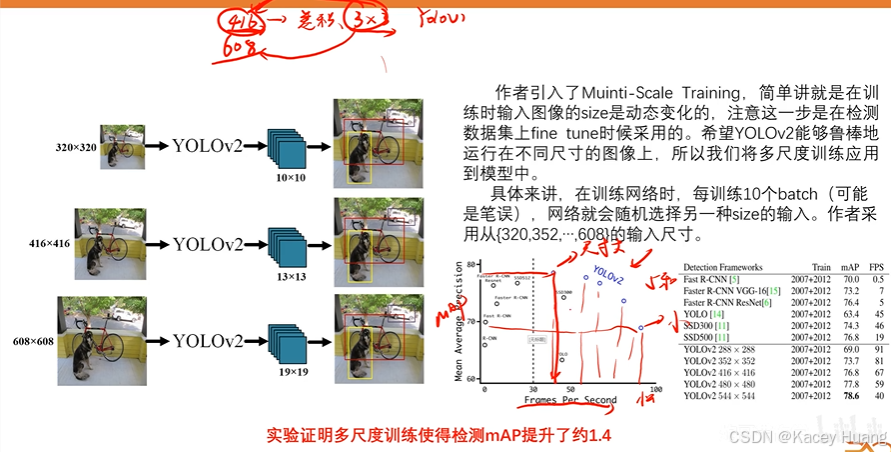
3.12 多尺度训练
利用不同分辨率的图片作为模型输入来训练模型,使模型精度提高,鲁棒性更加强
小尺寸的数据mAP比较小(精度比较差),但是FPS比较大(速度快)
3.13 更高分别率图像的检测输入
第一阶段:分类模式:在ImageNet分类数据集上预训练Darknet-19,输入为224X224
第二阶段:分类模式:在ImageNet数据集上finetune分类模型(微调),输入为448x448
第三阶段:检测模式:在检测数据上finetune网络

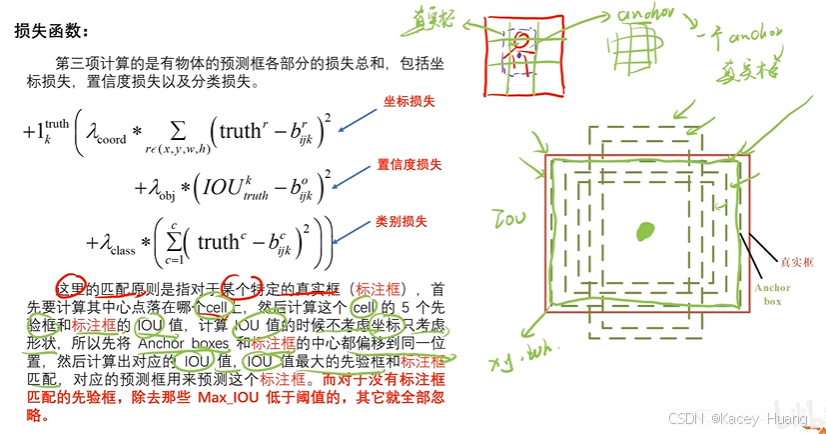
3.14 YOLOv2的损失函数
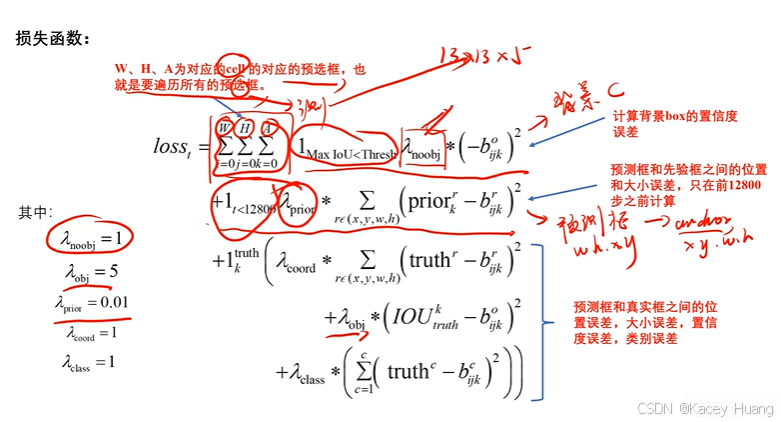
3.15 YOLOv2的背景置信度损失
第一项误差:先判定每一个预测框和所有标注框的IOU,如果小于0.6,就计算无物体的置信度误差

第二项误差:前12800步都要计算,让训练前期的预测框快速学习anchor框的形状

3.16 YOLOv2的有物体的损失值计算
第三项误差:计算有物体的预测框各部分的损失总和,包括坐标损失、置信度损失、类别损失
3.17 YOLOv2算法总结
优点:
1.缓解YOLOv1中定位不准确和检测召回率较低的问题
缺点:
1.小目标检测效果较差
2.整体检测效果有待提高

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 35
35 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)