pytorch yolo训练后的结果图含义
曲线可帮助根据业务需求选择合适的阈值 —— 例如,在 “不允许误报” 的场景(如危险品检测),可选择曲线中精确率接近 1 的高阈值;简单来说,普通混淆矩阵看 “具体错了多少个”,归一化混淆矩阵看 “错了多大比例”,两者结合能全面评估模型的类别预测能力(如 YOLO 检测时 “把汽车错判为卡车” 的数量和比例)。图中通常以矩阵或热力图形式呈现,横轴和纵轴均为数据集中的类别(如 “猫”“狗”“汽车”
- 在 YOLO(You Only Look Once)目标检测模型的训练过程中,通常会生成多种统计图,这些图表用于分析训练数据的分布特征,帮助理解数据特点并指导模型优化。
标签统计图(labels.jpg)
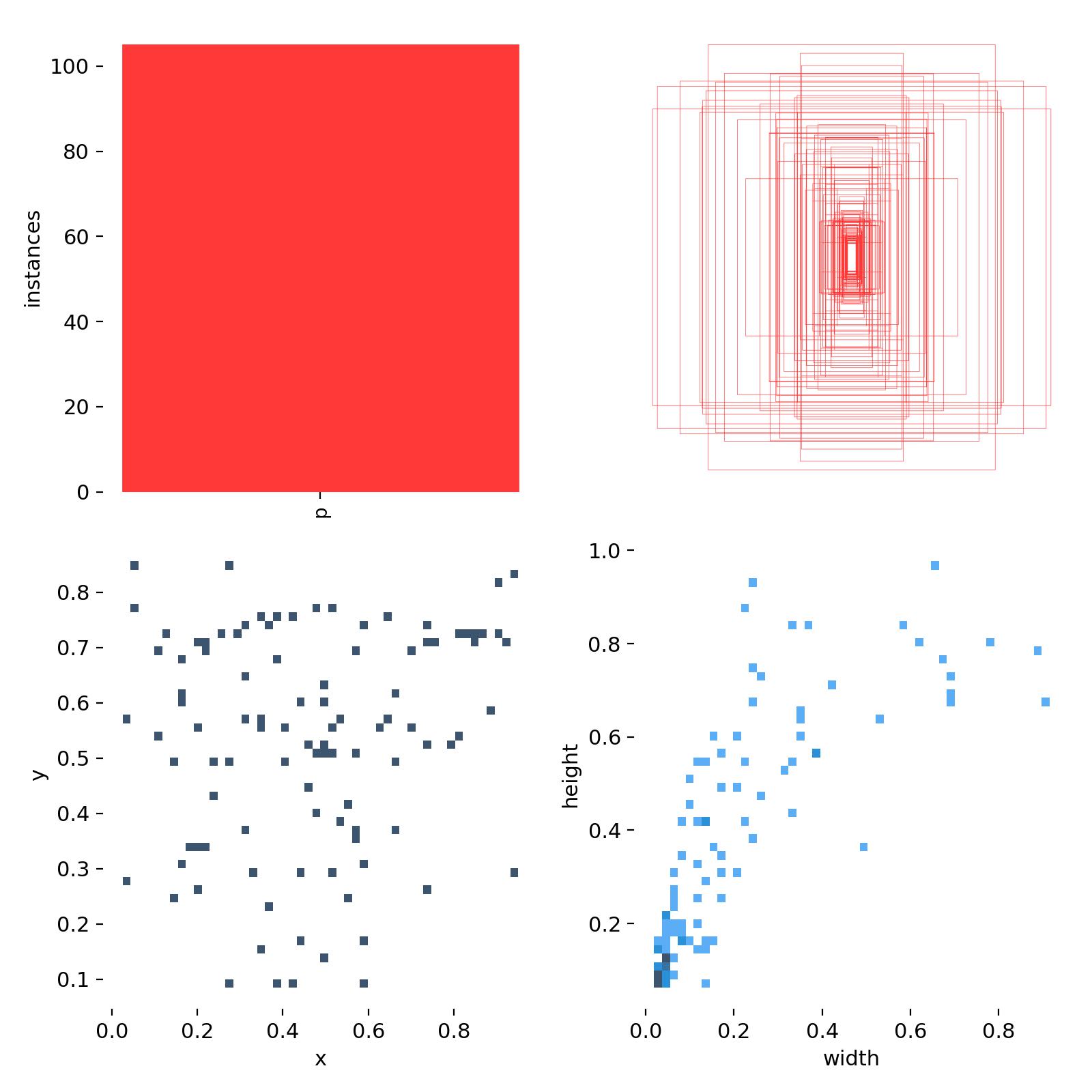
1.类别分布直方图(左上)
- 含义:统计数据集中每个类别的样本数量(或占比)。
- 作用:
直观展示数据集中是否存在类别不平衡问题(某些类别样本过多 / 过少)。
若存在严重不平衡,可能导致模型对少数类识别效果差,需要进行数据增强或重采样
2.标注框叠加图(Bounding Box Overlay Visualization) 或标注框聚合图(右上)
- 含义:将数据集中所有图像的标注框(不考虑原始图像内容)按比例缩放后叠加绘制在同一坐标系中,通常以归一化坐标(将图像宽高映射到 0-1 范围)展示(就是将所有的框全部都叠在了一起,不同的颜色代表着不同类别的框)
- 作用:1.直观呈现所有目标的位置分布趋势(是否集中在特定区域);2.展示目标的尺寸和形状的整体特征(通过密集叠加的框线密度判断);3.辅助发现数据中可能存在的标注偏见(如目标总是偏向图像某一区域)。
3.目标中心坐标分布(Object Center Distribution)(左下)
- 含义:将图像归一化到 [0,1] 坐标后,统计所有目标框中心点(x_center, y_center)的分布,通常用热力图展示。
- 作用:
- 检查目标是否集中在图像的特定区域(如偏左、偏下等),反映数据采集的偏向性。
- 若分布不均,可能需要补充多样化数据,避免模型学习到位置偏见。
4.目标框尺寸分布(Bounding Box Size Distribution)
- 含义:将图像归一化到 [0,1] 坐标后,统计所有目标框中心点(x_center, y_center)的分布,通常用热力图展示。
- 作用:
- 检查目标是否集中在图像的特定区域(如偏左、偏下等),反映数据采集的偏向性。
- 若分布不均,可能需要补充多样化数据,避免模型学习到位置偏见。
混淆矩阵图
这两张图都是用来评估分类模型(包括 YOLO 的类别预测任务)性能的核心可视化工具,核心区别在于是否对数值进行 “归一化处理”,以适配不同分析需求。
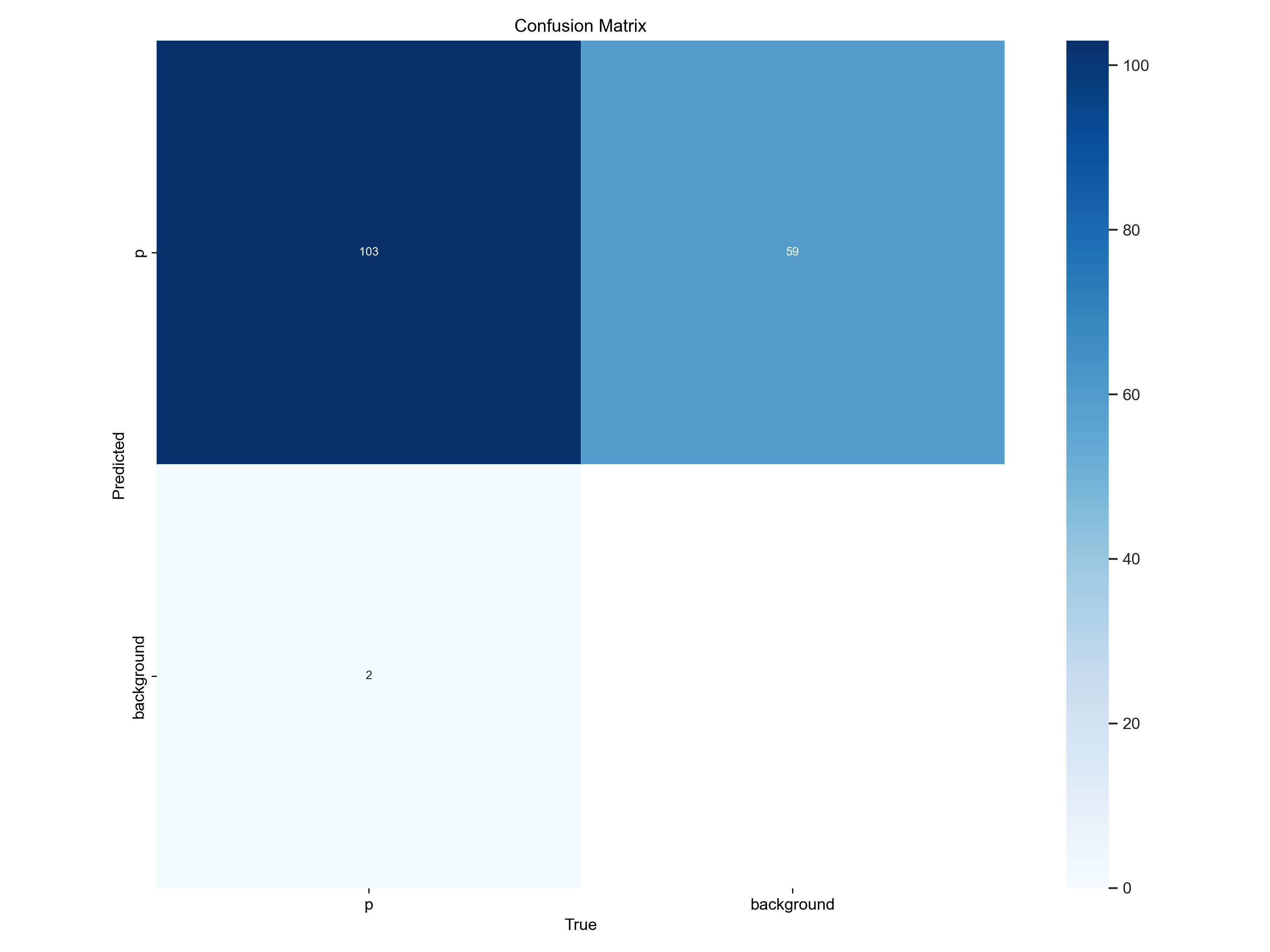
1. confusion_matrix.png(混淆矩阵图)
- 核心定义:以矩阵形式展示模型 “实际类别” 与 “预测类别” 的数量对应关系,每个单元格数值代表 “属于 A 类却被预测为 B 类” 的样本绝对数量。
- 关键解读逻辑:
- 矩阵的行代表 “样本实际类别”(如行 1 对应 “猫” 类)。
- 矩阵的列代表 “模型预测类别”(如列 2 对应 “狗” 类)。
- 对角线单元格(如行 1 列 1):代表 “实际类别与预测类别一致” 的样本数,数值越大说明该类预测越准确,是模型性能的核心指标。
- 非对角线单元格(如行 1 列 2):代表 “实际为 A 类却被误判为 B 类” 的样本数,数值越大说明该类与 B 类的混淆越严重(如猫被错认为狗)。
- 适用场景:需要明确知道 “某类样本具体有多少个被错判” 时使用,比如分析 “100 个猫样本中,有 15 个被错判为狗” 这类具体数量问题。
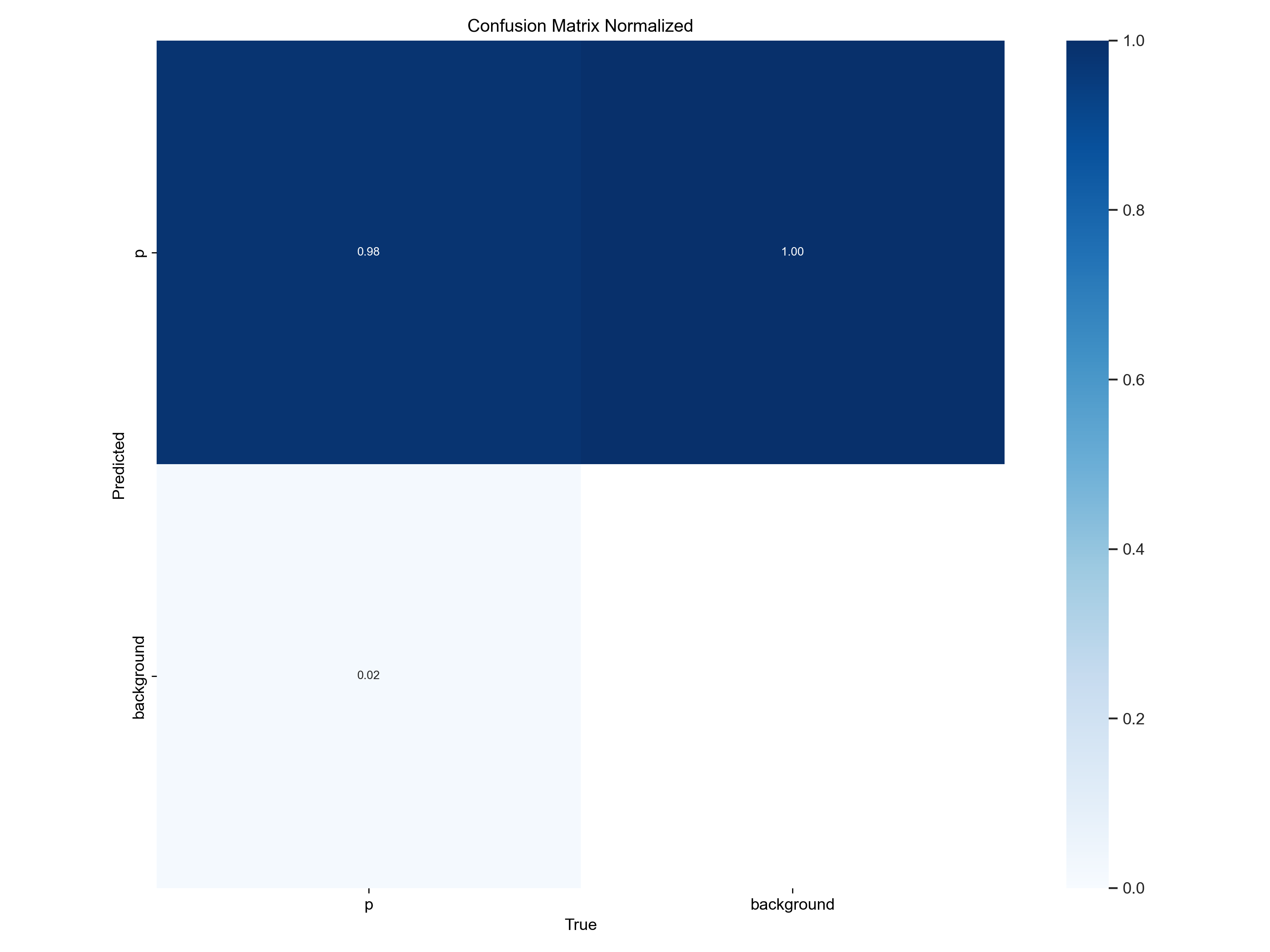
2. confusion_matrix_normalized.png(归一化混淆矩阵图)
- 核心定义:在普通混淆矩阵基础上,对每一行的数值进行归一化处理(通常是除以该行的总样本数),使每行数值之和为 1(或百分比形式,如 85%),单元格数值代表 “属于 A 类却被预测为 B 类” 的样本相对比例。
- 关键解读逻辑:
- 行、列的含义与普通混淆矩阵完全一致,仅数值单位从 “绝对数量” 变为 “比例 / 百分比”。
- 对角线单元格(如行 1 列 1 为 85%):代表 “实际为 A 类的样本中,被正确预测为 A 类的比例”,即该类的 “精确率(Precision)”,更直观反映 “每类预测的准确率高低”。
- 非对角线单元格(如行 1 列 2 为 15%):代表 “实际为 A 类的样本中,被误判为 B 类的比例”,便于快速对比 “不同类别间的误判率差异”(如猫错判为狗的比例是 15%,狗错判为猫的比例是 5%)。
- 适用场景:当数据集中存在 “类别不平衡” 时(如 A 类有 1000 个样本,B 类仅 100 个样本),普通混淆矩阵的 “绝对数量” 会掩盖真实误判率(如 A 类错判 50 个 vs B 类错判 20 个,看似 A 类错的多,但 B 类误判率 20% 远高于 A 类的 5%),此时归一化矩阵能更公平地对比各类别预测性能。
两者核心区别对比
| 对比维度 | confusion_matrix.png(普通版) | confusion_matrix_normalized.png(归一化版) |
|---|---|---|
| 数值单位 | 样本绝对数量(如 50、120) | 样本相对比例(如 0.85、15%) |
| 核心优势 | 反映 “误判样本的具体个数”,直观且量化 | 消除类别数量差异影响,公平对比各类别准确率 |
| 适用场景 | 分析具体误判数量、数据集规模相关问题 | 类别不平衡场景、对比不同类别预测精度 |
简单来说,普通混淆矩阵看 “具体错了多少个”,归一化混淆矩阵看 “错了多大比例”,两者结合能全面评估模型的类别预测能力(如 YOLO 检测时 “把汽车错判为卡车” 的数量和比例)。
如上图:横坐标中p标签被预测为p的0.98,被预测为背景的概率为0.02
标签相关性图(labels_correlogram.jpg)
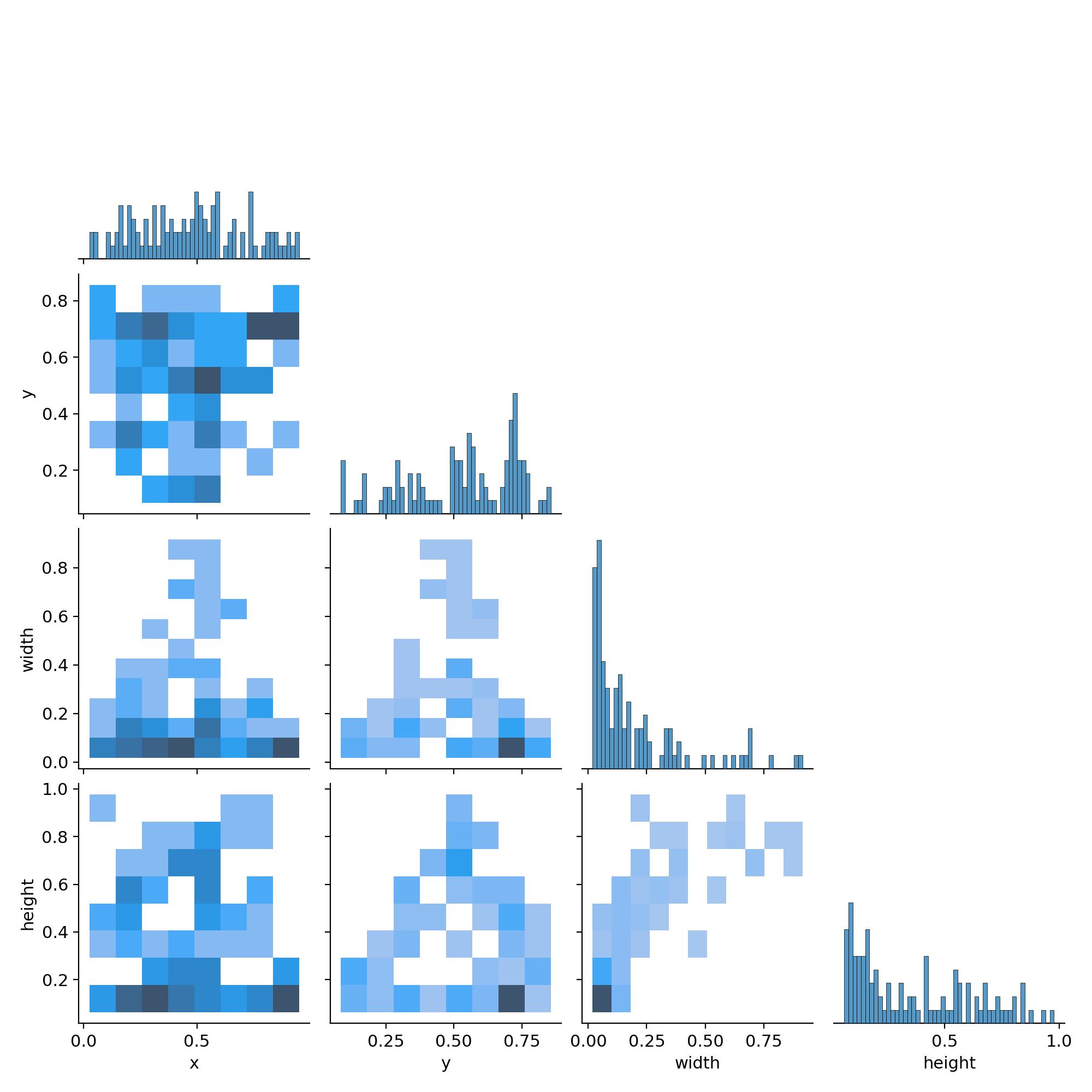
-
展示类别共现频率图中通常以矩阵或热力图形式呈现,横轴和纵轴均为数据集中的类别(如 “猫”“狗”“汽车” 等),每个单元格的颜色深浅(或数值)表示 “两个类别同时出现在同一张图像中的频率”。
- 颜色越深(或数值越高):表示这两个类别在同一幅图像中共同出现的次数越多(如 “马路” 和 “汽车” 通常高度共现)。
- 颜色越浅(或数值越低):表示这两个类别很少同时出现(如 “鱼” 和 “飞机” 几乎不会共现)。
-
反映类别关联性帮助分析类别之间的内在关联,例如:
- 哪些类别具有强关联性(如 “行人” 和 “自行车”),哪些是互斥的(如 “晴天” 和 “雨天”)。
- 若某些类别总是同时出现,模型可能会学习到这种关联性,甚至在预测时产生 “连带偏见”(如看到 “马路” 就倾向于预测 “汽车”,即使实际没有)。
-
指导数据与模型优化
- 若发现某些类别共现频率异常(如 “猫” 和 “狗” 本应常共现但数据中很少同时出现),可能提示数据集存在采集偏差,需要补充相应样本。
- 对于强共现的类别,可在训练中适当调整策略(如增强这类样本的多样性),避免模型过度依赖关联性而非目标本身特征进行预测。
这个图主要就是看类别分布不均衡或者我们图是不是存在一些异常分布
结果图
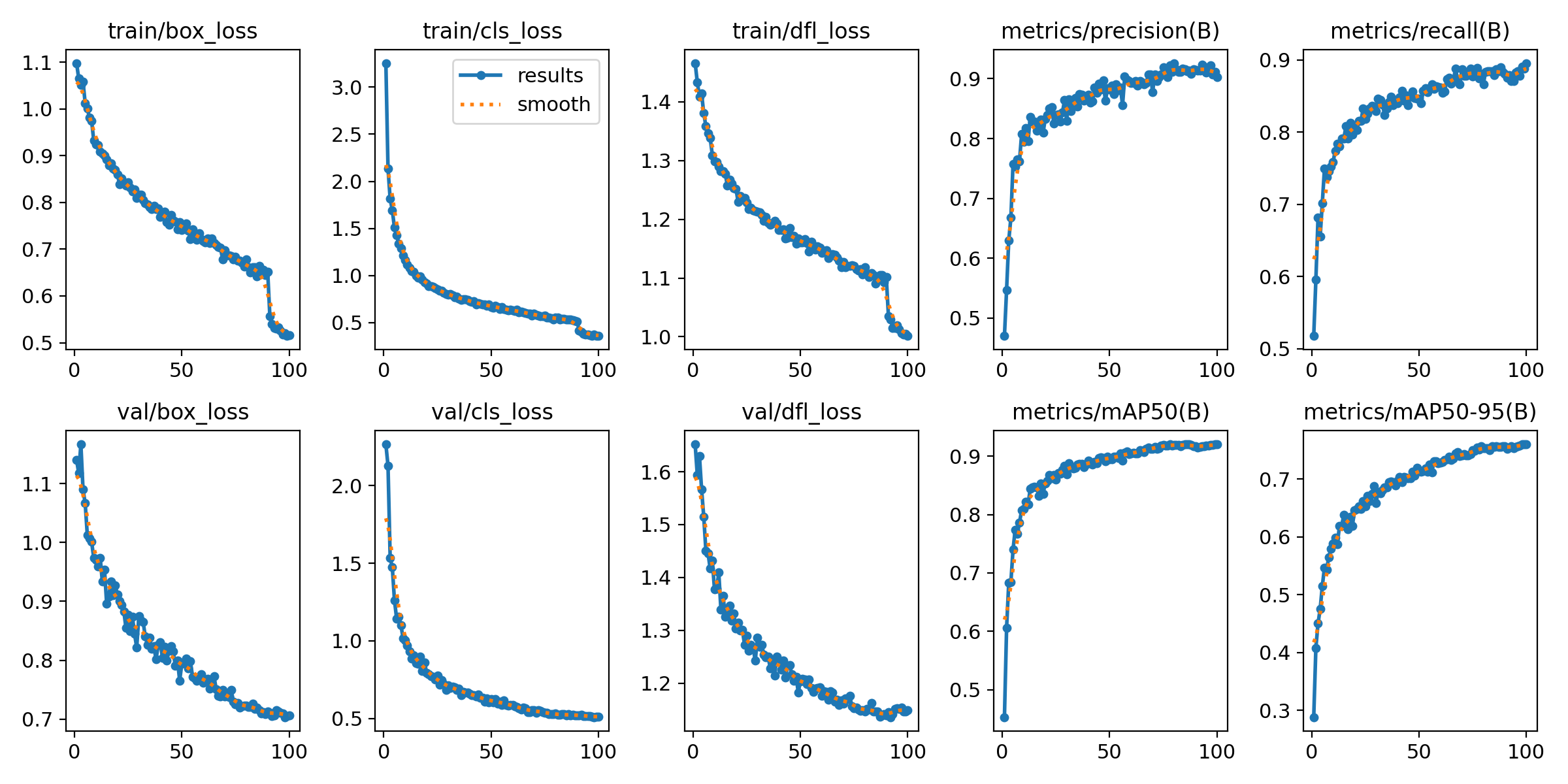
训练(train)/验证(valid)
- 定位损失(box_loss):边界框的预测和标准之间的损失
- 分类损失(cls_loss):预测类别和真实类别之间的损失
- 分布式焦点损失(dfl_loss ):边界框位置概率分布优化的损失
- 精度(Precision):P(精度)=TP(正检)/ TP(正检)+FP(误检)
- 召回率( Recall):R(召回)=P(正检)/ TP(正检)+FN(漏检)
- 平均精度(mAP):MAP50 阈值设为 0.5 时的平均精度;MAP50-95 IoU=0.5 到 0.95的多个阈值的平均精度
训练过程中关键指标的变化趋势,用于直观评估模型的训练效果、收敛状态和潜在问题。
1. 损失函数(Loss)相关曲线
- Train Loss(训练损失):模型在训练集上的损失值,反映模型对训练数据的拟合程度。
- 正常趋势:随着训练进行逐渐下降,最终趋于稳定(若持续震荡或上升,可能是过拟合、学习率过高或数据问题)。
- Val Loss(验证损失):模型在验证集上的损失值,反映模型的泛化能力。
- 正常趋势:先下降后稳定,且与训练损失差距较小(若显著高于训练损失,可能是过拟合)。
2. 精度相关指标(针对分类任务)
- Train Accuracy(训练准确率):训练集上预测正确的样本占比。
- Val Accuracy(验证准确率):验证集上预测正确的样本占比。
- 正常趋势:逐渐上升并趋于稳定,验证准确率应接近训练准确率。
3. 目标检测特有的指标(针对 YOLO 等检测模型)
- Precision(精确率):模型预测为 “正样本” 的结果中,实际确实是正样本的比例(少误报)。
- Recall(召回率):所有实际正样本中,被模型成功预测出来的比例(少漏检)。
- mAP(mean Average Precision,平均精度均值):多类别检测中,各分类 AP(平均精度)的平均值,是检测模型性能的核心指标。
- 正常趋势:随训练进行逐渐上升,最终趋于稳定(mAP 越高,模型检测性能越好)。
4. 学习率(Learning Rate)曲线
部分 results.png 会包含学习率随迭代次数的变化,用于验证学习率调度策略是否生效(如余弦退火、阶梯式下降等)。
核心作用
- 判断模型是否收敛:损失曲线是否趋于稳定,精度指标是否不再明显提升。
- 诊断训练问题:
- 若训练损失下降但验证损失上升:可能过拟合(需增加数据增强、减小模型复杂度)。
- 若损失曲线震荡剧烈:可能学习率过高(需调小学习率)。
- 若指标长期无提升:可能陷入局部最优(需调整优化器或初始化策略)。
- 对比不同训练版本:通过不同实验的
results.png对比,判断参数调整(如学习率、锚框)是否有效。
F1曲线
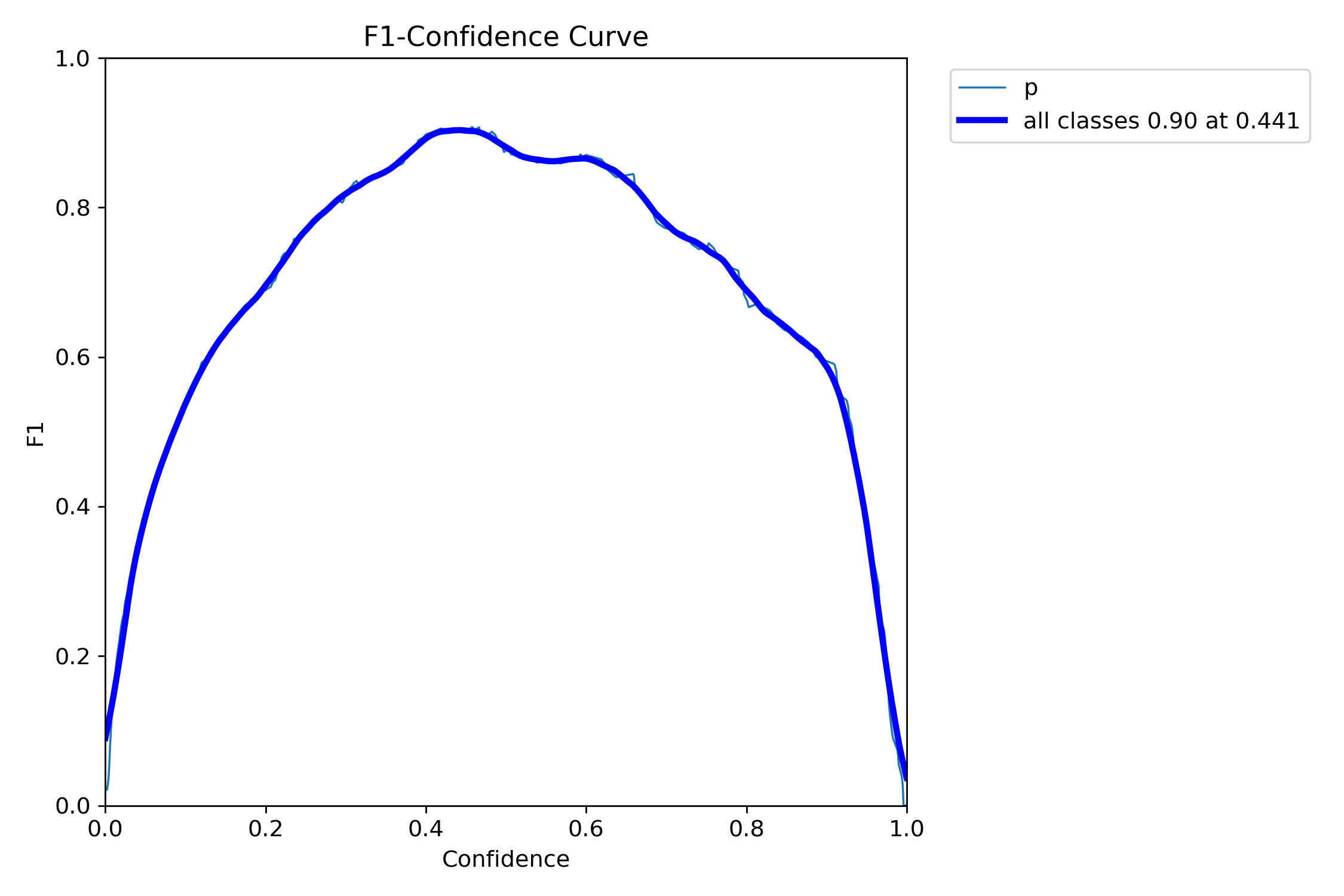
1.核心概念:F1 分数与置信度阈值
-
F1 分数:是精确率(Precision)和召回率(Recall)的调和平均值,计算公式为:
F1 = 2 × (Precision × Recall) / (Precision + Recall)它综合衡量了模型 “少误报”(高精确率)和 “少漏检”(高召回率)的平衡能力,取值范围为 0~1,越接近 1 说明综合性能越好。 -
置信度阈值:模型对预测结果会给出一个 “置信度”(如 0.8 表示模型 80% 确信这是目标),只有置信度高于设定阈值的预测才会被视为有效结果。阈值越高,模型判定越严格(可能漏检多但误报少);阈值越低,判定越宽松(可能误报多但漏检少)。
2.F1_curve.png 的含义与解读
-
横轴:置信度阈值(通常从 0 到 1)。
-
纵轴:对应阈值下的 F1 分数。
-
曲线趋势:展示不同阈值下 F1 分数的变化 —— 通常先上升后下降,形成一个单峰曲线。
- 曲线的峰值点:对应 F1 分数最高的阈值,这个阈值是平衡精确率和召回率的 “最优临界点”,实际应用中常选择此阈值作为默认判定标准。
- 曲线上升段:阈值较低时,随着阈值提高,误报减少的速度超过漏检增加的速度,F1 分数提升。
- 曲线下降段:阈值过高时,漏检增加的速度超过误报减少的速度,F1 分数下降。
P_curve曲线
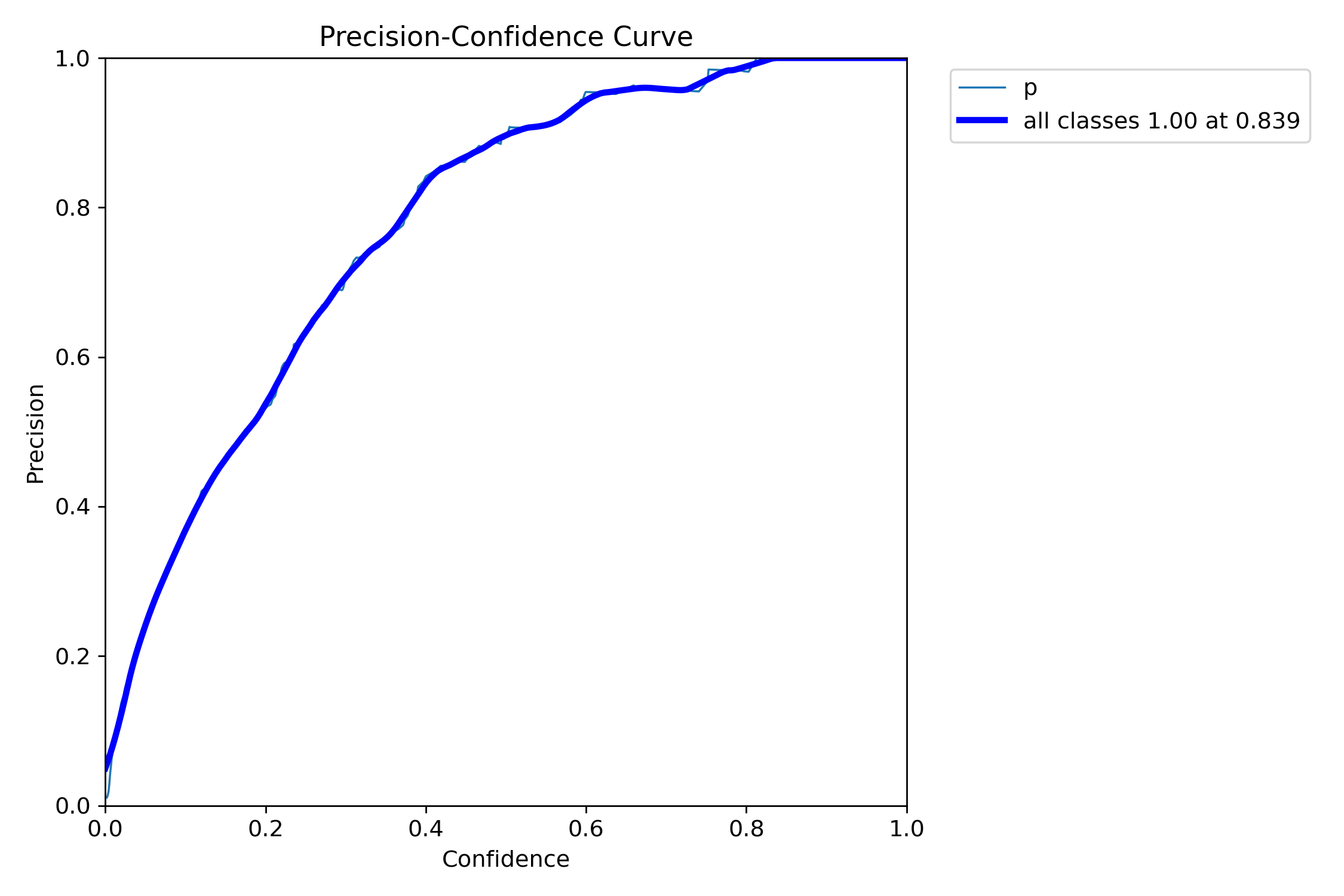
P_curve.png 通常指的是精确率曲线(Precision Curve),用于展示精确率(Precision)随置信度阈值(Confidence Threshold)变化的趋势。
核心含义与图表构成
- 横轴:置信度阈值(通常从 0 到 1),即模型判断 “某区域是否为目标” 的置信度门槛(如 0.3、0.5、0.8 等)。
- 纵轴:对应阈值下的精确率(Precision),即模型预测为 “正样本” 的结果中,实际确实是正样本的比例(计算公式:
Precision = TP / (TP + FP),其中 TP 为真正例,FP 为假正例)。 - 曲线特征:通常呈现单调递增趋势—— 随着置信度阈值提高,模型对 “什么是正样本” 的判定更严格,只有高度确信的预测才会被保留,因此误报(FP)减少,精确率随之上升(或保持稳定)。
曲线可帮助根据业务需求选择合适的阈值 —— 例如,在 “不允许误报” 的场景(如危险品检测),可选择曲线中精确率接近 1 的高阈值;而在 “优先减少漏检” 的场景(如搜救目标检测),可选择中等阈值以平衡精确率和召回率。
PR_curve曲线
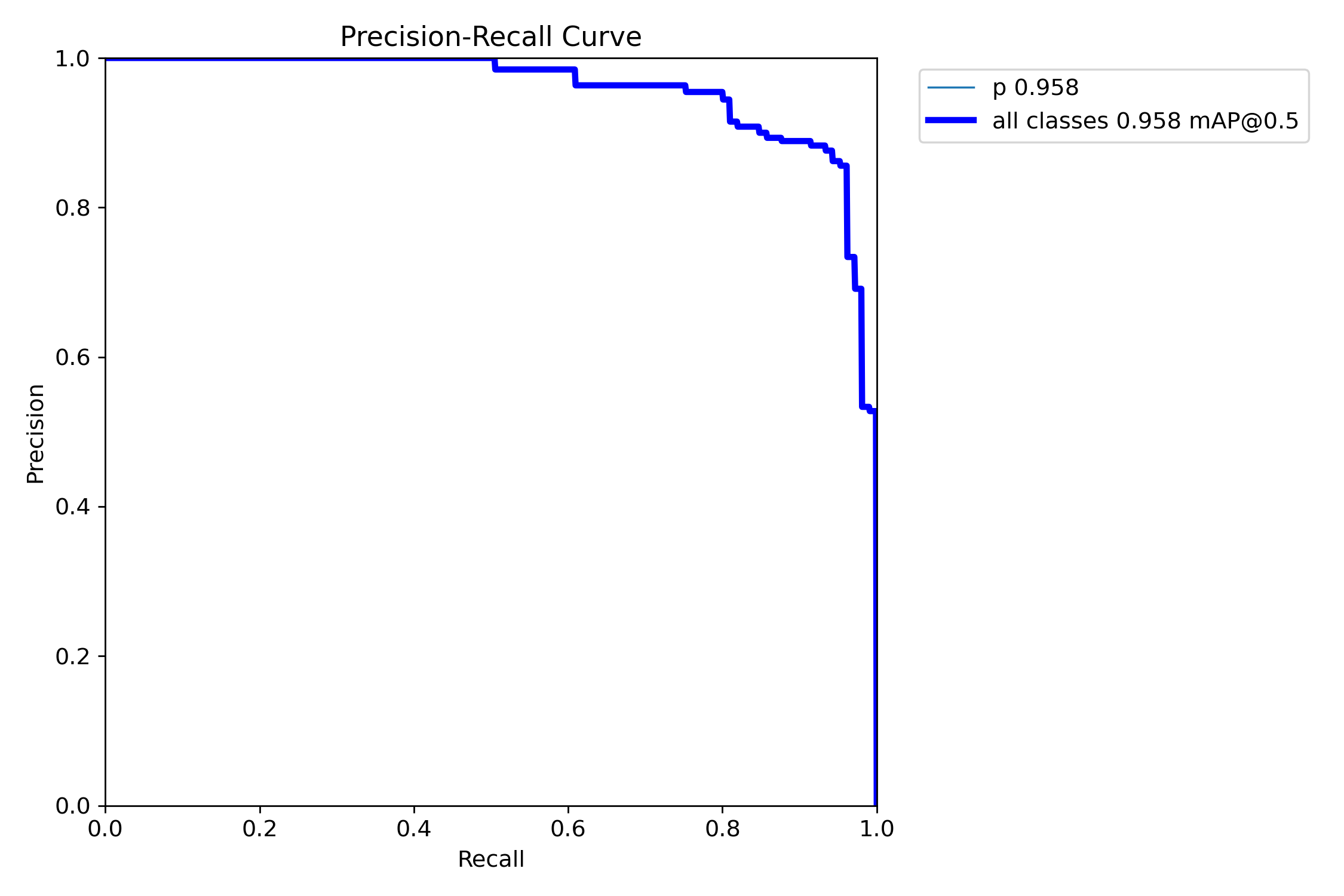
精确率 - 召回率曲线(Precision-Recall Curve),是衡量模型性能的核心可视化工具之一,尤其适用于不平衡数据集的评估。
核心含义与图表构成
- 横轴:召回率(Recall),即所有实际正样本中,被模型成功预测出来的比例(计算公式:
Recall = TP / (TP + FN),其中 TP 为真正例,FN 为假负例 / 漏检)。 - 纵轴:精确率(Precision),即模型预测为正样本的结果中,实际确实是正样本的比例(计算公式:
Precision = TP / (TP + FP),其中 FP 为假正例 / 误报)。 - 曲线特征:通过调整模型的置信度阈值(从 0 到 1),得到不同阈值对应的(Recall, Precision)坐标点,连接这些点形成的曲线即为 PR 曲线。
关键解读
-
曲线趋势与模型性能:
- 理想情况下,曲线应尽可能靠近右上角(高精确率 + 高召回率),表示模型能在少误报的同时,不漏检多数目标。
- 实际中,精确率和召回率通常存在权衡关系:提高召回率(降低阈值,减少漏检)往往会引入更多误报,导致精确率下降;反之,提高精确率(提高阈值,减少误报)可能会漏掉更多真实目标,导致召回率下降。
-
曲线下面积(AP):PR 曲线与横轴之间的面积称为平均精确率(Average Precision, AP),是量化模型性能的重要指标。AP 值越高(越接近 1),说明模型整体性能越好。在多类别检测中,所有类别的 AP 平均值即为 mAP(mean Average Precision),是 YOLO 等模型的核心评价标准。
-
不同模型的对比:若两条 PR 曲线相交,需结合具体场景选择 —— 例如:
- 曲线 A 在高召回率区域优于曲线 B:适合 “优先减少漏检” 的场景(如医疗诊断)。
- 曲线 B 在高精确率区域优于曲线 A:适合 “优先减少误报” 的场景(如安防告警)。若一条曲线完全位于另一条曲线上方,则上方曲线对应的模型性能更优。
R_curve曲线
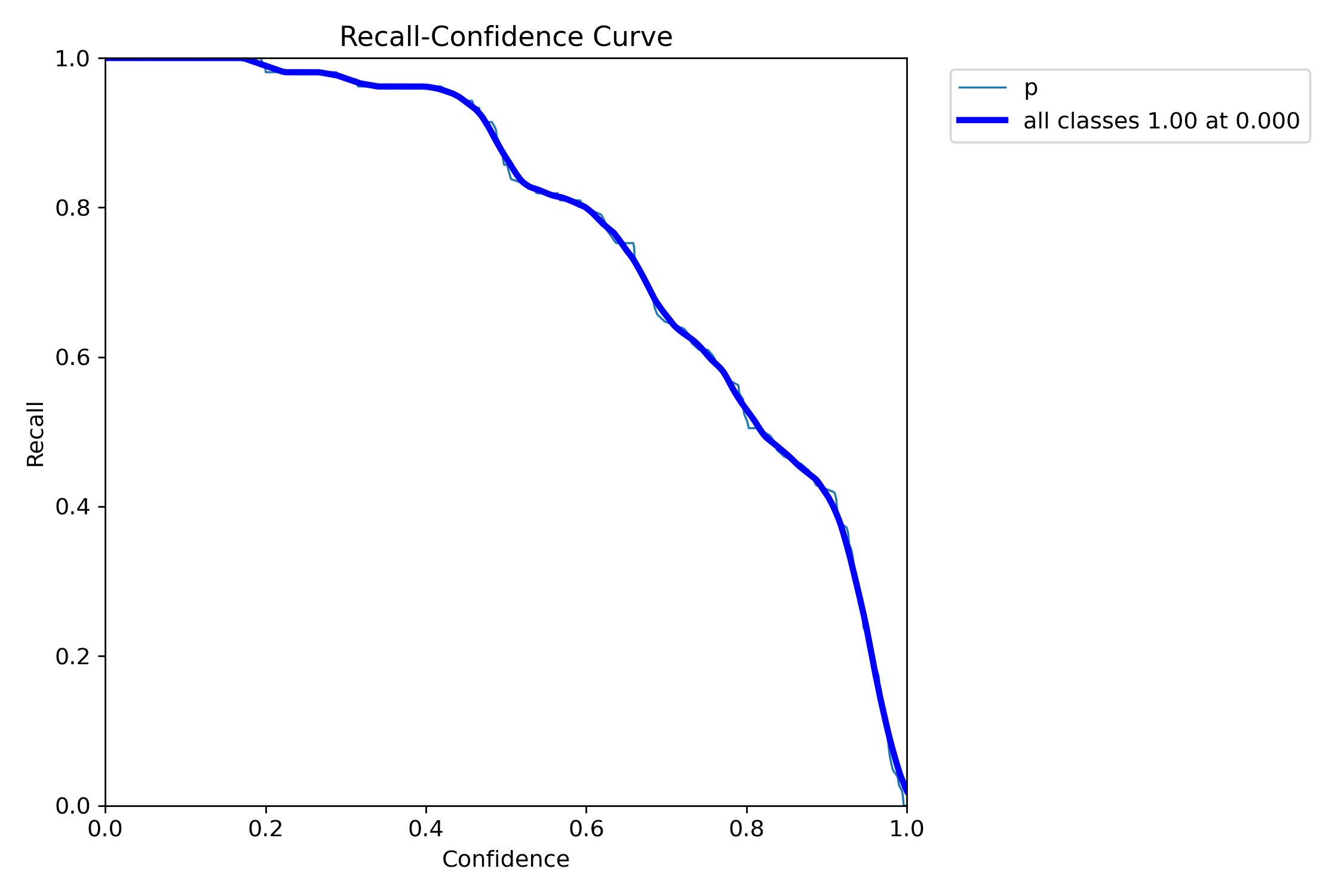
召回率曲线(Recall Curve),核心作用是展示召回率(Recall)随置信度阈值(Confidence Threshold)变化的趋势,帮助理解模型在不同判定宽松程度下 “不漏检目标” 的能力。
- 横轴:置信度阈值(通常从 0 到 1)。这是模型判断 “预测结果是否有效” 的门槛,阈值越低,模型判定越宽松(保留更多预测结果);阈值越高,判定越严格(只保留高置信度结果)。
- 纵轴:对应阈值下的召回率(Recall)。其计算公式为
Recall = 真正例(TP) / (真正例(TP) + 假负例(FN)),其中 TP 是 “预测正确的正样本”,FN 是 “实际为正样本但被模型漏检的数量”。召回率衡量的是模型 “从所有真实目标中,成功找到的比例”,越接近 1 说明漏检越少。 - 曲线特征:通常呈现单调递减趋势。随着置信度阈值升高,模型会过滤掉更多低置信度的预测结果,这可能导致部分真实目标(置信度低于阈值)被误判为无效,从而使漏检增多、召回率下降。
- 阈值与召回率的关系
- 当阈值接近 0 时:模型保留所有预测结果,几乎不会漏检真实目标,召回率接近 1(但会伴随大量误报)。
- 随着阈值升高(如从 0.2 到 0.8):低置信度的预测被逐步过滤,部分真实目标因置信度不足被排除,召回率逐渐下降。
- 当阈值接近 1 时:模型只保留 “极度确信” 的预测结果,此时误报极少,但大量真实目标会被漏检,召回率通常降至较低水平。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)