深入大模型架构学习
ROPE是旋转位置编码
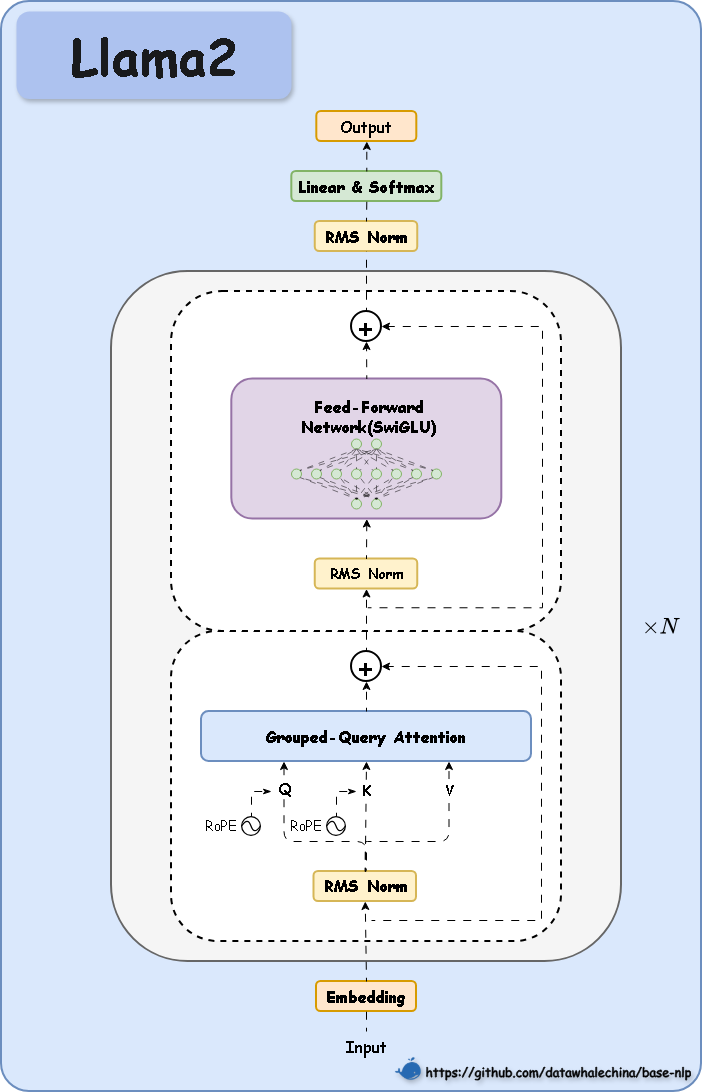
这里的Q和K都是添加了对应的旋转位置编码ROPE
均方根进行缩放,简化了计算过程:

这次task学了区别于前面PEFT的更高级微调方法RLHF,使得参数更少的模型有更强的表现能力。通过奖励模型RM来对模型的回答质量进行评估,PPO、DPO 和 GRPO 几个策略优化算法有各自更加匹配的场景。然后学习了LLaMA-Factory,感受到了通过修改相关参数对于模型回答的帮助。
在这个task中学到了量化的概念,即各个量化的方法都是为了将占用空间更大的浮点数转为占用空间更小的整型或者更小的浮点数。在这个量化的过程中,需要尽可能的保证模型的输出质量不下降太多,因此需要注意相关关键参数,学了GPTQ、AWQ 以及 bitsandbytes三种量化方式的思想和公式。然后对于DeepSpeed有了一定的了解,学习到了这个热门的推理框架库的基础知识,之后再对其进行更加深入的学习。
一、环境准备
依赖:peft, transformers, datasets, accelerate, bitsandbytes。 提示:CUDA 与 bitsandbytes 需版本匹配。
%pip install -q -U peft transformers datasets accelerate bitsandbytes hf_xet ipywidgets
二、加载基础模型和分词器
要点:
- 使用
BitsAndBytesConfig+quantization_config进行 8-bit 量化 - 设置
device_map="auto"由accelerate自动分配设备 - tokenizer 无
pad_token时对齐到eos_token
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# 定义模型 ID
pythia_model_id = "EleutherAI/pythia-2.8b-deduped"
# --- 使用 BitsAndBytesConfig 定义 8-bit 量化配置 ---
bnb_config = BitsAndBytesConfig(
load_in_8bit=True,
)
# 加载模型
# 将量化配置传给 `quantization_config` 参数
pythia_model = AutoModelForCausalLM.from_pretrained(
pythia_model_id,
quantization_config=bnb_config,
dtype=torch.float16,
device_map="auto",
)
pythia_model
# 加载分词器 pythia_tokenizer = AutoTokenizer.from_pretrained(pythia_model_id) # Pythia 模型的 tokenizer 默认没有 pad_token,我们将其设置为 eos_token pythia_tokenizer.pad_token = pythia_tokenizer.eos_token
三、模型预处理
使用 prepare_model_for_kbit_training 让 4/8-bit 量化模型进入可训练状态,并启用梯度检查点等节省显存的优化。
from peft import prepare_model_for_kbit_training # 对量化后的模型进行预处理 pythia_model = prepare_model_for_kbit_training(pythia_model)
四、定义 LoRA 配置并创建 PeftModel
要点:
- Pythia 常用
target_modules:["query_key_value", "dense"] - 仅训练 LoRA 相关参数,显著降低显存与计算
from peft import LoraConfig, get_peft_model
# 定义 LoRA 配置
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["query_key_value", "dense"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
# 应用配置,获得 PEFT 模型
peft_model = get_peft_model(pythia_model, lora_config)
peft_model.print_trainable_parameters()
五、数据处理
数据集:Abirate/english_quotes 流程:加载 -> 仅对 quote 列分词 -> 使用 .map() 批处理
from datasets import load_dataset
# 加载数据集
quotes_dataset = load_dataset("Abirate/english_quotes")
quotes_dataset['train'][0]
# 定义分词函数
def tokenize_quotes(batch):
# 我们只对 "quote" 列进行分词
return pythia_tokenizer(batch["quote"], truncation=True)
# 对整个数据集进行分词处理
tokenized_quotes = quotes_dataset.map(tokenize_quotes, batched=True)
tokenized_quotes['train'][0]
六、定义 Trainer 并开始训练
TrainingArguments 关键项:
per_device_train_batch_size与gradient_accumulation_steps决定“有效批量”warmup_steps学习率预热fp16混合精度训练
from transformers import Trainer, TrainingArguments, DataCollatorForLanguageModeling
# 这是推荐操作,可以使训练日志更清晰
peft_model.config.use_cache = False
# 定义训练参数
train_args = TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=100,
max_steps=200,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="outputs",
)
# 数据整理器
quote_collator = DataCollatorForLanguageModeling(pythia_tokenizer, mlm=False)
# 实例化 Trainer
quote_trainer = Trainer(
model=peft_model,
train_dataset=tokenized_quotes["train"],
args=train_args,
data_collator=quote_collator,
)
# 开始训练
quote_trainer.train()
七、模型保存与推理
仅保存 LoRA 适配器(adapter_config.json, adapter_model.safetensors)。
随后做一次推理验证,观察生成效果变化。
# 定义 LoRA 适配器的保存路径 adapter_save_path = "./peft-lora-pythia-2.8b" # 保存 LoRA 适配器 peft_model.save_pretrained(adapter_save_path) adapter_save_path
微调后的推理测试
要点:
- 显式传递
attention_mask - 采样:
do_sample=True配合temperature、top_p、top_k - 正确设置
pad_token_id
# 将模型设置为评估模式
peft_model.eval()
# 设置 pad_token_id 到模型配置中(避免警告)
peft_model.config.pad_token_id = pythia_tokenizer.pad_token_id
prompt = "Be yourself; everyone"
# 对输入进行分词,并获取 attention_mask
after_inputs = pythia_tokenizer(prompt, return_tensors="pt")
after_input_ids = after_inputs["input_ids"].to(peft_model.device)
after_attention_mask = after_inputs["attention_mask"].to(peft_model.device)
# 生成文本
with torch.no_grad():
with torch.amp.autocast('cuda'):
after_output = peft_model.generate(
input_ids=after_input_ids,
attention_mask=after_attention_mask,
max_length=50,
do_sample=True,
temperature=0.7,
top_p=0.9,
top_k=40,
repetition_penalty=1.2,
pad_token_id=pythia_tokenizer.pad_token_id
)
# 解码生成的文本
after_text = pythia_tokenizer.decode(after_output[0], skip_special_tokens=True)
after_text

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)