将MobileNet深度学习模型移植至Android平台
MobileNet是一系列高效的卷积神经网络,专为移动和边缘设备设计。它的核心是深度可分离卷积(Depthwise Separable Convolution),显著降低了模型的参数量和计算复杂性,但保持了较高的准确性。MobileNet广泛应用于图像识别、物体检测等领域,其轻量级的特性使得它非常适合于资源受限的环境中。本章节将带您深入了解MobileNet的架构,并探索其在不同场景下的应用潜力。

简介:MobileNet是一种专为移动和嵌入式设备设计的轻量级深度学习模型,利用深度可分离卷积技术大幅降低了模型的计算复杂度。本移植指南详细阐述了如何将MobileNet模型训练、优化、转换,并集成到Android应用中,同时包括了图像预处理、预测执行、后处理和性能优化等关键步骤。 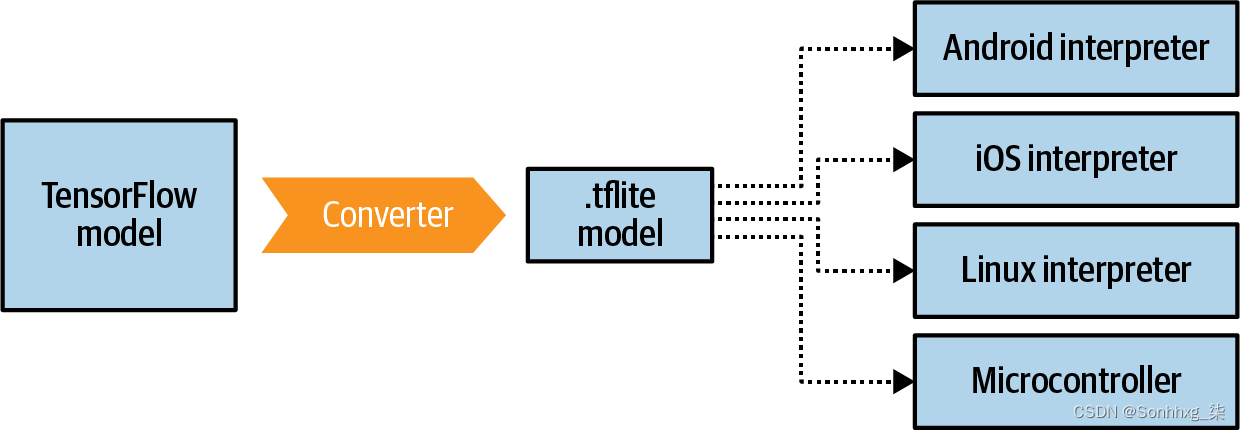
1. MobileNet模型简介
MobileNet是一系列高效的卷积神经网络,专为移动和边缘设备设计。它的核心是深度可分离卷积(Depthwise Separable Convolution),显著降低了模型的参数量和计算复杂性,但保持了较高的准确性。MobileNet广泛应用于图像识别、物体检测等领域,其轻量级的特性使得它非常适合于资源受限的环境中。本章节将带您深入了解MobileNet的架构,并探索其在不同场景下的应用潜力。
2. 模型训练与优化流程
2.1 MobileNet模型训练基础
在构建和部署轻量级深度学习模型时,MobileNet是一个非常流行的选择,因其高效的计算能力而被广泛应用于移动和嵌入式设备。本小节将深入探讨MobileNet模型训练的基础知识,这将为进一步的模型优化打下坚实的基础。
2.1.1 理解深度可分离卷积
深度可分离卷积是MobileNet的核心组件,它将传统的卷积运算拆分成两个部分:深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。深度卷积对每个输入通道分别进行滤波操作,而逐点卷积则对深度卷积的结果进行通道间的组合。这种结构显著减少了模型参数和计算量。
flowchart TD
A[输入特征图] -->|深度卷积| B[深度卷积结果]
B -->|逐点卷积| C[输出特征图]
深度可分离卷积不仅提高了运算效率,还通过限制模型复杂度来减轻过拟合的风险。为了深入理解这一概念,我们可以通过实际的代码例子进行说明。
import tensorflow as tf
def depthwise_conv2d(input_layer, kernel_size, strides=(1, 1, 1, 1), padding='SAME'):
return tf.nn.depthwise_conv2d(input_layer,
kernel=[1, kernel_size, kernel_size, 1],
strides=strides,
padding=padding)
# 示例:使用3x3的深度卷积核对28x28x1的输入图像进行深度卷积操作
input_layer = tf.random.normal([1, 28, 28, 1])
depthwise_conv = depthwise_conv2d(input_layer, 3)
在本例中,我们定义了一个函数 depthwise_conv2d 来模拟深度卷积的过程,并给出了如何应用到一个输入层上。这段代码演示了深度卷积的核心概念,并且可以通过调整 kernel_size 和 strides 参数来观察不同配置对模型性能的影响。
2.1.2 训练数据和标签的准备
数据是模型训练的基础。对于图像识别任务,训练数据通常需要进行预处理,包括图像的裁剪、缩放、归一化等步骤,以确保输入图像满足模型的输入尺寸和数值范围要求。标签是模型学习的目标,需要以one-hot编码或类别索引的形式提供给模型。
def prepare_dataset(images, labels, img_size=(224, 224)):
# 图像预处理函数
def preprocess(image, label):
image = tf.image.resize(image, img_size) / 255.0 # 归一化
return image, tf.one_hot(label, depth=100) # 假设有100个类别
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
dataset = dataset.map(preprocess) # 应用预处理函数
dataset = dataset.batch(32) # 批量处理以提高效率
return dataset
此代码段展示了如何将训练数据和标签进行预处理,并将其构建成可被模型训练所使用的数据集。 prepare_dataset 函数将输入的图像数组和标签数组转换为批处理、标准化并且格式化为模型所需格式的数据集。
2.2 模型优化技术
在训练MobileNet模型时,为了适应有限的计算资源,通常需要应用一些优化技术来进一步提升模型性能。
2.2.1 权重剪枝与量化
权重剪枝和量化是两种常用的模型压缩技术,它们都可以有效降低模型的存储大小和计算需求,同时尽可能保持模型的预测性能。
-
权重剪枝 :通过移除模型中那些对输出影响较小的权重,从而减少模型的参数数量。这通常涉及到识别出权重矩阵中不重要的元素,并将它们设置为零。
-
量化 :将模型中的浮点权重和激活转换为低精度的整数表示。这不仅减少了模型的大小,而且使得模型可以利用整数运算加速,提高执行效率。
import tensorflow_model_optimization as tfmot
# 使用TensorFlow Model Optimization Toolkit进行权重剪枝
prune_low_magnitude = tfmot.sparsity.keras.prune_low_magnitude
model = prune_low_magnitude(mobilenet_model)
# 对模型进行量化
quantize_model = tfmot.quantization.keras.quantize_model
model_quantized = quantize_model(model)
# 示例:保存量化后的模型
model_quantized.save("quantized_model.h5")
在这段代码中,我们使用了TensorFlow Model Optimization Toolkit来演示如何对MobileNet模型应用权重剪枝和量化。请注意,进行优化时应保持模型的预测精度,并在训练完成后进行模型效果评估。
2.2.2 知识蒸馏
知识蒸馏是一种模型压缩技术,它允许我们将一个大型复杂模型(教师模型)的知识转移到一个更小的模型(学生模型)中。在蒸馏过程中,学生模型不仅尝试最小化与真实标签之间的损失,同时也尝试复现教师模型的输出,这通常称为软标签。
from keras import backend as K
def distillation(y_true, y_pred, teacher_pred, alpha=0.4, temperature=3):
# 损失函数定义
loss = alpha * K.categorical_crossentropy(y_true, y_pred) \
+ (1 - alpha) * K.categorical_crossentropy(teacher_pred, y_pred)
return loss / temperature
在知识蒸馏的实现中,我们定义了一个损失函数 distillation ,该函数结合了标准的交叉熵损失和软标签损失。这个损失函数在训练学生模型时,会同时考虑真实标签和教师模型的输出。
2.3 优化效果评估
模型优化完成之后,需要评估优化的效果,以确保优化不仅提高了效率,而且没有显著影响模型性能。
2.3.1 准确率与速度的权衡
在优化移动和边缘设备上的模型时,需要在模型准确率和运行速度之间找到一个平衡点。这通常涉及调整模型的大小、深度和宽度,以适应特定的性能要求。
- 模型大小 :减小模型的尺寸,通常会牺牲一定的准确率来获得更快的推理速度。
- 模型速度 :优化模型的计算效率,使得模型在保持较高准确率的同时,可以在目标设备上以较高的帧率运行。
评估时,可以使用基准测试来测量模型在特定硬件上运行的速度,同时记录不同优化级别的准确率,以便找到最佳平衡点。
graph LR
A[模型优化] -->|减少参数| B[较小的模型]
A -->|加速计算| C[更快的推理]
B -->|准确率测试| D[准确率评估]
C -->|速度测试| E[速度评估]
D --> F[寻找平衡点]
E --> F
2.3.2 模型压缩率分析
评估模型压缩效果的一个重要方面是压缩率,它表示优化前后模型大小的变化。压缩率越高,表示模型优化的效果越好。分析压缩率通常需要比较模型在优化前后的文件大小、参数数量和计算量。
# 压缩率计算示例
original_size = 14693744 # 原始模型大小
compressed_size = 4767920 # 压缩后模型大小
compression_rate = original_size / compressed_size
print(f"压缩率: {compression_rate:.2f}")
在这个例子中,我们简单地通过比较原始模型和压缩模型的大小来计算压缩率。一个较高的压缩率表明模型被有效地减小了大小,这对于移动设备尤其重要。
通过上述的章节内容,我们已经系统地了解了MobileNet模型训练和优化的基础知识,并在实践中详细探讨了深度可分离卷积、数据准备、模型优化技术及其效果评估方法。这些信息为构建和优化高效、轻量级的模型提供了坚实的基础,并为下一章的模型转换提供了准备。
3. 模型转换成TensorFlow Mobile或Lite格式
3.1 模型转换前的准备
3.1.1 环境搭建和依赖安装
将MobileNet模型转换为TensorFlow Mobile或Lite格式之前,需要在你的开发环境中安装必要的依赖包。主要的依赖是TensorFlow的Python库。以下是一个典型的安装环境搭建和依赖安装的流程。
首先,确保Python环境已经配置好,并安装了pip包管理器。然后,在终端或命令提示符中运行以下命令来安装TensorFlow。
pip install tensorflow
在某些情况下,你可能需要安装特定版本的TensorFlow以匹配你的项目要求,例如:
pip install tensorflow==2.4.0
另外,为了将模型转换为 .tflite 格式,你还需要安装 tensorflow-lite 转换工具:
pip install tensorflow-lite
确保你的环境中安装了以下依赖,例如Python版本、操作系统兼容性等。你可以通过运行 python --version 和 pip --version 来检查这些依赖是否满足要求。
3.1.2 图的冻结与保存
在转换模型之前,需要将模型中的所有变量转换为常数,并保存这个新的“冻结”图。这样做的原因是TensorFlow Lite仅支持常数图,而不支持训练中使用的变量。
在Python中,你可以使用TensorFlow的 tf.compat.v1 模块来冻结图:
import tensorflow as tf
def freeze_graph(model_dir, output_node_names):
# 加载未冻结的图
with tf.compat.v1.gfile.GFile(os.path.join(model_dir, "saved_model.pb"), "rb") as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read())
# 从GraphDef中移除未使用的节点
from tensorflow.python.framework.graph_util import convert_variables_to_constants
input_graph_def = graph_def
output_graph_def = convert_variables_to_constants(
tf.compat.v1.Session(graph=tf.Graph()),
input_graph_def,
output_node_names.split(","))
# 保存冻结图
with tf.io.gfile.GFile(os.path.join(model_dir, "frozen_model.pb"), "wb") as f:
f.write(output_graph_def.SerializeToString())
freeze_graph(model_dir="/path/to/your/model", output_node_names="output-layer-node-name")
这段代码将加载你的MobileNet模型,移除不必要的节点,并输出一个冻结的图定义文件。记得将 model_dir 和 output-layer-node-name 替换为你的模型实际路径和输出节点名称。
3.2 模型转换工具介绍
3.2.1 TensorFlow Lite Converter的使用
TensorFlow Lite Converter是一个命令行工具,可以将冻结的TensorFlow图模型转换成 .tflite 格式,适用于移动和嵌入式设备。
以下是如何使用命令行工具进行转换的示例:
tflite_convert \
--graph_def_file=/path/to/your/frozen_model.pb \
--output_file=/path/to/your/output.tflite \
--input_arrays=input-layer-name \
--output_arrays=output-layer-name
请确保将 --graph_def_file , --output_file , --input_arrays 和 --output_arrays 的值替换为你的实际文件路径和图中的节点名。
此外,你还可以通过编写Python脚本来使用TensorFlow Lite Converter的API:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_frozen_graph(
graph_def_file="/path/to/your/frozen_model.pb",
input_arrays=["input-layer-name"],
output_arrays=["output-layer-name"])
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16] # 可以选择float16进行优化
tflite_model = converter.convert()
with open("/path/to/your/output.tflite", "wb") as f:
f.write(tflite_model)
此脚本会优化模型,并将优化后的模型以 .tflite 格式保存到指定路径。
3.2.2 转换过程中的常见问题及解决策略
在模型转换过程中,可能会遇到各种问题。以下是一些常见问题和相应的解决策略。
问题1:模型转换后的大小远大于预期
解决策略:
- 使用量化(Quantization)减少模型大小。
- 移除未使用的模型部分。
- 重新设计或剪枝模型结构。
问题2:模型在转换过程中无法识别某些操作
解决策略:
- 确保转换器支持你的模型中使用的所有操作。
- 如果遇到不支持的操作,考虑使用等效的操作或升级TensorFlow版本。
问题3:转换后的模型在移动设备上运行缓慢
解决策略:
- 对模型进行轻量化优化。
- 使用TensorFlow Lite的神经网络API进行加速。
- 利用GPU或NPU加速器(如果设备支持)。
3.3 转换后的模型验证
3.3.1 模型大小与兼容性检查
转换后的 .tflite 模型需要检查其大小和兼容性,确保它适合部署到移动设备。
以下是使用Python检查模型大小的示例代码:
import os
def check_model_size(tflite_path):
tflite_path = os.path.abspath(tflite_path)
tflite_size = os.path.getsize(tflite_path)
print(f"Model file size: {tflite_size / 1024} KB")
return tflite_size
model_size = check_model_size("/path/to/your/output.tflite")
同时,你可以使用Android Studio的Profile工具来检查模型的兼容性,并验证在不同的Android设备上运行时是否会出现任何问题。
3.3.2 准确性验证
在转换模型后,重要的是验证新模型在特定任务上的准确性是否满足要求。
以下是一个简单的脚本,用于在一组测试数据上进行准确性验证:
import tensorflow as tf
def evaluate_model(tflite_model_path, test_data, test_labels):
# 加载tflite模型
interpreter = tf.lite.Interpreter(model_path=tflite_model_path)
interpreter.allocate_tensors()
# 获取输入和输出张量
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# 在测试数据上运行模型并收集结果
interpreter.set_tensor(input_details[0]['index'], test_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
# 基于输出数据和实际标签评估准确性
accuracy = evaluate_accuracy(output_data, test_labels)
return accuracy
def evaluate_accuracy(output_data, test_labels):
predictions = np.argmax(output_data, axis=1)
return np.mean(predictions == test_labels)
accuracy = evaluate_model("/path/to/your/output.tflite", test_data, test_labels)
print(f"Model accuracy after conversion: {accuracy}")
这段代码将加载 .tflite 模型,运行预测,并与实际标签进行比较以计算准确性。请确保 test_data 和 test_labels 数组正确设置为你的测试数据集。
通过检查模型的大小和准确性,你可以确定模型转换是否成功,并且是否可以继续进行集成到Android应用的步骤。
4. 在Android中集成TensorFlow Mobile或Lite库
随着深度学习在移动设备上的应用越来越广泛,如何在Android平台上集成轻量级的TensorFlow Mobile或Lite库成为了开发者的必修课。本章节将深入探讨如何将TensorFlow Mobile或Lite库集成到Android应用中,提供实际操作步骤,并对关键实现环节进行详细解析。
4.1 Android项目设置
在开始集成TensorFlow Mobile或Lite库之前,我们需要对Android项目进行一些必要的设置。这包括项目的创建、配置以及库的引入。
4.1.1 Android Studio项目创建与配置
在Android Studio中创建一个新的项目通常是一个简单直观的过程。首先打开Android Studio,选择”Start a new Android Studio project”。接下来,我们需要选择一个适合的模板。对于集成TensorFlow Mobile或Lite库,通常选择一个”Empty Activity”模板就可以了。
项目创建完成后,需要进行一些基本的配置,如命名应用、设置最低支持的Android版本、选择项目的保存位置等。建议将最低支持的Android版本设置为API 21或更高,以确保能够利用到Android系统提供的更多功能。
4.1.2 TensorFlow Lite库的引入
TensorFlow Lite库可以通过Gradle依赖的方式轻松地集成到Android项目中。在项目的 build.gradle (Module:app)文件中的 dependencies 部分,添加以下依赖项:
dependencies {
// ... 其他依赖项 ...
implementation 'org.tensorflow:tensorflow-lite:0.0.0-nightly' // 使用最新的TensorFlow Lite版本
}
添加依赖后,点击Android Studio工具栏上的”Sync Project with Gradle Files”按钮,以确保下载并集成TensorFlow Lite库。
完成这些步骤后,Android项目已经准备好了集成TensorFlow Lite库,接下来我们可以进行模型的加载和初始化操作。
4.2 模型的加载与初始化
在Android应用中使用TensorFlow Lite模型,首先需要加载模型文件,并进行必要的初始化操作。
4.2.1 从文件加载模型
TensorFlow Lite模型以 .tflite 文件格式存在,通常存储在项目的 assets 文件夹中。我们可以使用 Interpreter 类来加载和执行 .tflite 模型。
try {
// 创建一个Interpreter对象,加载.tflite文件
Interpreter tflite = new Interpreter(loadModelFile(activity));
} catch (Exception e) {
// 处理异常,如模型文件加载失败
e.printStackTrace();
}
// ...
// 加载.tflite文件的方法
private MappedByteBuffer loadModelFile(Activity activity) throws IOException {
AssetFileDescriptor fileDescriptor = activity.getAssets().openFd("model.tflite");
FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor());
FileChannel fileChannel = inputStream.getChannel();
long startOffset = fileDescriptor.getStartOffset();
long declaredLength = fileDescriptor.getDeclaredLength();
return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength);
}
上述代码中, loadModelFile 方法将 .tflite 模型文件映射为 MappedByteBuffer ,这是TensorFlow Lite进行模型执行时需要的内存映射。
4.2.2 模型的初始化与运行时设置
在成功加载模型之后,通常需要对模型进行一些初始化操作,设置运行时参数。例如,如果我们使用的是量化模型,可能需要配置量化参数以确保模型的正确执行。
// 设置量化参数,如果模型是量化模型的话
Interpreter.Options options = new Interpreter.Options();
options.setNumThreads(4); // 设置线程数以优化性能
options.setUseNNAPI(true); // 如果设备支持NNAPI,可以提升模型推理性能
// 使用配置的选项创建新的Interpreter
Interpreter tflite = new Interpreter(loadModelFile(activity), options);
以上代码展示了如何设置线程数以及启用Android的神经网络API(NNAPI),以优化模型推理的性能。
完成模型加载和初始化之后,就需要进行接口封装,将模型集成到Android应用中。
4.3 接口封装与应用集成
为了简化模型调用过程,并且提高代码的可读性和可维护性,我们需要对模型预测功能进行接口封装,并集成到Android应用的用户界面中。
4.3.1 API接口的设计与封装
API接口的设计需要考虑如何接收输入数据、如何传递数据给模型、如何处理模型的输出结果,并且提供简洁的接口供其他应用逻辑调用。
// 定义模型预测的API接口
public class TensorFlowLiteModelAPI {
private Interpreter tflite;
public TensorFlowLiteModelAPI(Context context) throws IOException {
// 在构造函数中加载模型
this.tflite = new Interpreter(loadModelFile(context));
}
// 接口方法,接收输入数据,返回模型预测结果
public List<Object> predict(List<float[]> inputData) {
// 这里需要根据实际的输入输出格式设计数据处理逻辑
// ...
}
}
在上述示例代码中,我们定义了一个 TensorFlowLiteModelAPI 类,用于封装模型加载和预测的相关逻辑。在实际应用中,可以根据具体需求扩展或修改这个API接口。
4.3.2 应用界面与用户体验优化
在设计应用界面时,要考虑到用户体验(UX)。一个直观且响应迅速的用户界面将极大地提升用户的满意度。在集成TensorFlow Lite模型时,要确保用户在使用模型时不会感到延迟,并且结果的展示要清晰直观。
<!-- 在activity_main.xml中设计一个简单界面 -->
<LinearLayout
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical"
android:padding="16dp">
<Button
android:id="@+id/button_predict"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="Predict"
android:onClick="onPredictClick"/>
<!-- 结果展示区域 -->
<TextView
android:id="@+id/textView_result"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="Result will be shown here"/>
</LinearLayout>
以上界面布局包含了启动模型预测的按钮和显示结果的文本视图。在用户点击按钮时,通过调用 onPredictClick 方法触发模型预测,并将结果显示在 TextView 中。
至此,我们已经完成了在Android应用中集成TensorFlow Lite库的基本步骤。在下一章节中,我们将进一步介绍如何对MobileNet模型进行性能优化,从而提升应用的整体性能和用户体验。
5. MobileNet在Android上的性能优化
5.1 图像预处理方法
在Android设备上运行MobileNet模型时,对输入图像进行适当的预处理是至关重要的,以确保模型可以高效且准确地处理数据。图像预处理通常包括以下几个步骤:图像缩放、归一化处理、裁剪和填充。
5.1.1 图像缩放与归一化处理
为了适应MobileNet模型的输入需求,原始图像首先需要被缩放到模型期望的尺寸,例如224x224像素。接着,将缩放后的图像像素值归一化到[0,1]区间内,以匹配模型训练时使用的归一化方案。
fun preprocessImage(image: Bitmap, targetSize: Int): FloatArray {
// 图像缩放
val resizedBitmap = Bitmap.createScaledBitmap(image, targetSize, targetSize, true)
// 图像归一化处理
val floatValues = FloatArray(targetSize * targetSize * 3)
var counter = 0
for (i in 0 until resizedBitmap.height) {
for (j in 0 until resizedBitmap.width) {
val pixelValue = resizedBitmap.getPixel(j, i)
floatValues[counter++] = ((Color.red(pixelValue).toFloat() - IMAGE_MEAN) / IMAGE_STD)
floatValues[counter++] = ((Color.green(pixelValue).toFloat() - IMAGE_MEAN) / IMAGE_STD)
floatValues[counter++] = ((Color.blue(pixelValue).toFloat() - IMAGE_MEAN) / IMAGE_STD)
}
}
return floatValues
}
5.1.2 图像裁剪与填充
MobileNet模型在训练时,通常会采用固定尺寸的输入。然而,在实际应用中,为了适应不同尺寸的图像,我们可以采用图像裁剪或者填充的方法。裁剪是随机选取图像的一个区域以适配模型输入,而填充则是将图像四周填充特定颜色,达到固定尺寸。
5.2 执行模型预测
在完成图像预处理后,接下来是执行模型预测。为了提高用户体验,预测应尽可能快地完成。这通常涉及到对预测函数的优化,包括实现高效的执行代码以及采用并发预测和异步处理。
5.2.1 预测函数的实现
在Android上,预测函数的实现要保证既高效又不会阻塞UI线程。这通常涉及到在后台线程上运行推理过程,然后在UI线程上更新结果。
fun predictWithMobileNet(bitmap: Bitmap, interpreter: Interpreter) {
val input = preprocessImage(bitmap, INPUT_SIZE)
// 在后台线程执行预测
val result = runBlocking {
withContext(Dispatchers.Default) {
val output = Array(1) { FloatArray(OUTPUT_CLASSES) }
interpreter.run(input, output)
output[0]
}
}
// 更新UI(需要在主线程)
updateUIWithPredictionResult(result)
}
5.2.2 并发预测与异步处理
为了使预测过程更加高效,可以采用并发预测和异步处理。可以利用Kotlin的协程来简化异步操作,避免线程的复杂管理。
fun startConcurrentPredictions(bitmapList: List<Bitmap>, interpreter: Interpreter) {
bitmapList.forEach { bitmap ->
GlobalScope.launch(Dispatchers.Default) {
val result = predictWithMobileNet(bitmap, interpreter)
withContext(Dispatchers.Main) {
// 更新UI
updateUIWithPredictionResultForBitmap(result, bitmap)
}
}
}
}
5.3 预测结果的后处理
预测完成后,需要对结果进行后处理,包括结果解析、分类以及在UI上的展示。
5.3.1 结果解析与分类
从MobileNet模型得到的是一个浮点数数组,这个数组代表了每个类别的置信度。后处理的步骤包括找到置信度最高的类别,并将其转换为可读的标签。
fun interpretResults(output: FloatArray): String {
val maxIndex = output.indices.maxByOrNull { output[it] } ?: 0
val labels = arrayOf("cat", "dog", "bird", "other") // 示例标签数组
return labels[maxIndex]
}
5.3.2 用户界面展示与交互
用户界面应该能够清晰地展示预测结果,并提供与用户的交互。这包括显示预测的类别和相应的置信度,以及提供刷新预测或者分享结果的功能。
5.4 性能测试与调优
性能测试是确定模型在实际设备上的运行效率的关键步骤。通过基准测试,我们可以获取模型在不同方面的性能指标,如预测时间、资源消耗等,然后根据测试结果进行调优。
5.4.1 性能基准测试
性能基准测试应该包含多种测试案例,以模拟现实使用场景。例如,可以通过执行一定数量的预测,并记录响应时间来测试模型的性能。
fun benchmarkModelPerformance(interpreter: Interpreter) {
val testBitmapList = loadTestBitmaps() // 加载测试图像
val startTime = System.currentTimeMillis()
testBitmapList.forEach { bitmap ->
predictWithMobileNet(bitmap, interpreter)
}
val endTime = System.currentTimeMillis()
val duration = (endTime - startTime) / testBitmapList.size
Log.d("ModelBenchmark", "Average prediction time: $duration ms")
}
5.4.2 优化建议与实施
根据性能测试的结果,可以提出多种优化建议。优化可以是算法级别的,比如引入更快的模型架构或者算法优化;也可以是硬件级别的,比如使用GPU加速。在实施优化建议后,需要重新进行性能测试来验证优化效果。
在本章节中,我们探讨了在Android平台上如何优化MobileNet模型的性能。从图像预处理,执行模型预测,到预测结果的后处理,以及性能测试与调优,每一个步骤都需要精心设计,以确保最终用户体验的流畅性和模型运行的高效性。
简介:MobileNet是一种专为移动和嵌入式设备设计的轻量级深度学习模型,利用深度可分离卷积技术大幅降低了模型的计算复杂度。本移植指南详细阐述了如何将MobileNet模型训练、优化、转换,并集成到Android应用中,同时包括了图像预处理、预测执行、后处理和性能优化等关键步骤。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 25
25 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)