如何用AI自动爬取和清洗数据集?5个高效工具推荐
经过一番摸索,我发现结合AI技术可以大幅提升数据集处理的效率。下面分享我的实践经验,以及5个实用的工具推荐。,它集成了代码编辑、AI辅助和部署功能,让我可以快速实现从数据爬取到清洗的完整流程。最方便的是无需配置复杂环境,一键就能把数据处理服务部署上线,大大节省了搭建基础设施的时间。通过合理利用这些工具和技术,我的数据准备工作时间从原来的几天缩短到几小时,而且数据质量明显提升。传统爬虫需要手动分析网
快速体验
- 打开 InsCode(快马)平台 https://www.inscode.net
- 输入框内输入如下内容:
开发一个基于AI的数据集爬取和清洗工具,要求:1.支持输入目标网站URL自动识别并爬取结构化数据;2.内置智能去重和异常值检测功能;3.提供数据格式转换选项(CSV/JSON/SQL);4.包含可视化数据质量报告功能;5.支持定时自动更新数据集。使用Python实现,优先考虑Scrapy框架和Pandas库,界面简洁易用。
- 点击'项目生成'按钮,等待项目生成完整后预览效果

如何用AI自动爬取和清洗数据集?5个高效工具推荐
最近在做一个数据分析项目时,遇到了数据收集和清洗的难题。手动从各种网站抓取数据不仅耗时耗力,还要面对格式混乱、重复数据等问题。经过一番摸索,我发现结合AI技术可以大幅提升数据集处理的效率。下面分享我的实践经验,以及5个实用的工具推荐。
1. 自动爬取结构化数据
传统爬虫需要手动分析网页结构,而AI辅助的爬取工具可以自动识别页面中的结构化数据。我测试了几种方法:
- 基于视觉识别的AI爬虫:通过分析网页布局,自动识别表格、列表等数据区域
- 语义分析爬虫:理解网页内容语义,智能提取关键字段
- 自适应爬取:自动适应不同网站结构变化,减少维护成本
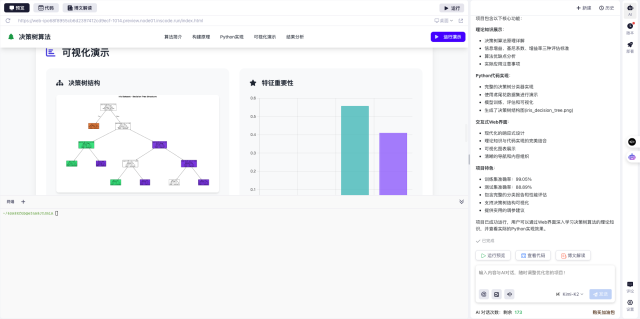
2. 智能数据清洗功能
获取原始数据后,清洗环节同样重要。AI在这方面的表现令人惊喜:
- 自动去重:基于语义相似度分析,识别并合并重复条目
- 异常值检测:利用统计模型识别异常数据点
- 缺失值处理:智能填充或标记缺失数据
- 格式标准化:自动统一日期、货币等不同格式
3. 数据转换与导出
清洗后的数据需要转换为可用格式。我常用的转换方式包括:
- CSV:适合大多数数据分析工具
- JSON:便于Web应用使用
- SQL:直接导入数据库
- Excel:方便非技术人员查看
4. 可视化质量报告
数据质量直接影响分析结果,可视化报告能直观展示:
- 数据完整性统计
- 异常值分布
- 字段间相关性
- 清洗前后对比
5. 定时自动更新
对于需要持续更新的数据集,我设置了:
- 定时爬取任务
- 增量更新机制
- 变更检测通知
- 版本控制管理
5款高效工具推荐
经过实际使用体验,以下工具特别值得推荐:
- Scrapy + Scrapy-Splash:强大的Python爬虫框架,结合渲染引擎
- Pandas:数据清洗和分析的瑞士军刀
- BeautifulSoup:轻量级HTML解析库
- DataCleaner:专业的数据清洗工具
- InsCode(快马)平台:一站式AI开发环境

特别推荐InsCode(快马)平台,它集成了代码编辑、AI辅助和部署功能,让我可以快速实现从数据爬取到清洗的完整流程。最方便的是无需配置复杂环境,一键就能把数据处理服务部署上线,大大节省了搭建基础设施的时间。对于需要持续运行的数据采集服务,这种云端解决方案特别实用。
通过合理利用这些工具和技术,我的数据准备工作时间从原来的几天缩短到几小时,而且数据质量明显提升。希望这些经验对正在处理数据集的朋友有所帮助!
快速体验
- 打开 InsCode(快马)平台 https://www.inscode.net
- 输入框内输入如下内容:
开发一个基于AI的数据集爬取和清洗工具,要求:1.支持输入目标网站URL自动识别并爬取结构化数据;2.内置智能去重和异常值检测功能;3.提供数据格式转换选项(CSV/JSON/SQL);4.包含可视化数据质量报告功能;5.支持定时自动更新数据集。使用Python实现,优先考虑Scrapy框架和Pandas库,界面简洁易用。
- 点击'项目生成'按钮,等待项目生成完整后预览效果

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 13
13 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)