C++实现四叉树数据结构与空间操作
本章系统讲解了四叉树的查询与遍历方法,包括递归与非递归实现、不同遍历方式的比较以及性能分析。在实际工程中,开发者可以根据具体需求选择合适的实现方式。例如,查询操作可优先使用非递归以避免栈溢出,而遍历操作可根据是否需要层级信息选择前序或层次遍历。下一章将进一步探讨四叉树的性能优化策略,包括懒加载、内存管理、智能分裂与合并等高级技巧,以提升其在大规模数据场景下的处理效率。

简介:四叉树(Quadtree)是一种用于组织二维空间数据的树形结构,广泛应用于计算机图形学、GIS和图像处理等领域。本文介绍四叉树的C++实现,包括节点结构定义、核心操作(插入、删除、查询与遍历)的实现逻辑,以及性能优化策略。通过该实现,开发者可以高效管理二维空间中的点对象,提升空间查询与操作效率。 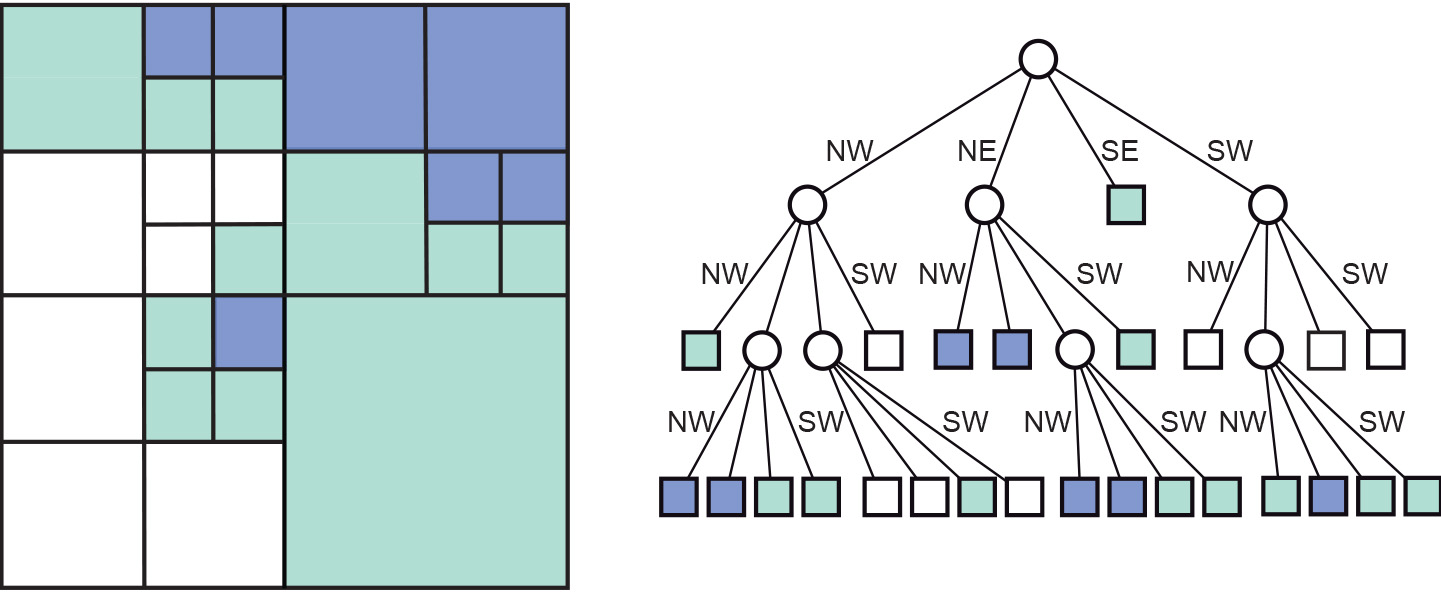
1. 四叉树基本概念与应用场景
四叉树(Quadtree)是一种用于管理二维空间数据的递归树结构,广泛应用于图像处理、地理信息系统(GIS)、碰撞检测、游戏引擎等领域。其核心思想是将一个二维区域递归划分为四个象限,每个节点对应一个空间区域,叶节点通常代表不可再分的基本单元。
其结构特性使得在空间检索、插入与删除操作中具有较高的效率,尤其适合稀疏数据集的处理。通过本章的学习,读者将掌握四叉树的基本原理、结构组成及其在实际系统中的应用价值,为后续C++实现打下坚实基础。
2. 四叉树节点结构设计与类封装
在构建一个完整的四叉树数据结构时,节点的设计是整个系统的核心。本章将从节点的基本组成单元开始,逐步构建一个面向对象的四叉树类封装结构,包括节点属性、子节点管理、数据存储、类接口设计、构造与析构策略,以及节点与类之间的关系管理等内容。通过这一章的深入剖析,读者将掌握如何在C++中实现一个结构清晰、可扩展性强的四叉树类体系。
2.1 四叉树的基本组成单元
四叉树的每个节点代表一个二维空间区域,并可能包含子节点。每个节点通常包括坐标点、是否为叶节点、四个方向的子节点指针,以及边界信息和数据存储等属性。这些属性构成了四叉树节点的基本结构。
2.1.1 节点的基本属性:坐标点(Point)、是否为叶节点(isLeaf)
四叉树节点通常用于存储空间中的某个点,或者管理一个区域的划分。为了便于表示二维空间点,我们首先定义一个 Point 结构体,用于存储坐标信息。
struct Point {
int x;
int y;
Point(int x = 0, int y = 0) : x(x), y(y) {}
// 重载==运算符,便于比较两个点是否相等
bool operator==(const Point& other) const {
return x == other.x && y == other.y;
}
};
逐行解读:
- 第1行定义了一个结构体Point。
- 第2~3行声明了x和y两个整型成员变量,表示二维空间中的坐标。
- 第5~7行定义了构造函数,允许传入x和y初始化点对象。
- 第9~12行重载了==运算符,用于比较两个点是否相同,便于后续节点查找与判断。
此外,每个节点需要知道它是否是叶节点(即是否被进一步划分),我们通过布尔变量 isLeaf 来表示。
bool isLeaf;
2.1.2 子节点指针:四个方向(NE、NW、SE、SW)的子节点
每个非叶节点最多可以拥有四个子节点,分别对应四个象限方向:
- NE(Northeast):右上
- NW(Northwest):左上
- SE(Southeast):右下
- SW(Southwest):左下
我们使用指针来管理这四个子节点,这样可以按需动态分配内存,提高空间效率。
class QuadTreeNode {
public:
Point center; // 区域中心点
int size; // 区域大小(边长的一半)
bool isLeaf;
int value; // 节点值(如图像像素值)
QuadTreeNode* NE;
QuadTreeNode* NW;
QuadTreeNode* SE;
QuadTreeNode* SW;
QuadTreeNode(Point center, int size)
: center(center), size(size), isLeaf(true), value(0),
NE(nullptr), NW(nullptr), SE(nullptr), SW(nullptr) {}
};
逐行解读:
-center为该节点所代表区域的中心点。
-size表示该区域边长的一半,即从中心到边界的距离。
-isLeaf标记是否为叶节点。
-value用于存储节点的数据,例如图像像素值。
- 四个指针NE、NW、SE、SW分别指向四个子节点。
- 构造函数初始化所有属性,并将子节点初始化为nullptr,表示该节点初始为叶节点。
2.1.3 数据存储与边界信息的设计
除了点信息和子节点外,节点还需要包含区域的边界信息。 center 和 size 共同定义了当前节点所代表的矩形区域范围,可以通过这两个属性推导出边界坐标。
例如,当前区域的边界可以表示为:
| 边界方向 | 坐标计算 |
|---|---|
| 左上角 | (center.x - size, center.y - size) |
| 右下角 | (center.x + size, center.y + size) |
我们可以通过辅助函数来获取这些边界信息:
Point getTopLeft() const {
return Point(center.x - size, center.y - size);
}
Point getBottomRight() const {
return Point(center.x + size, center.y + size);
}
逻辑分析:
-getTopLeft()函数返回当前节点区域的左上角坐标。
-getBottomRight()函数返回右下角坐标。
- 这些函数可用于后续的空间判断与插入、删除操作。
2.2 四叉树类的封装与接口设计
为了提高代码的可维护性和复用性,我们将四叉树的节点管理封装在一个类中。该类包含根节点的管理、插入、删除、查询等基本操作的接口,以及构造与析构函数的实现策略。
2.2.1 根节点的管理与初始化
四叉树类的核心是根节点,它代表整个二维空间。我们通过构造函数初始化根节点,并设置初始空间范围。
class QuadTree {
private:
QuadTreeNode* root;
public:
QuadTree(int width, int height) {
Point center(width / 2, height / 2);
int initialSize = std::max(width, height) / 2;
root = new QuadTreeNode(center, initialSize);
}
~QuadTree() {
clear(root);
}
private:
void clear(QuadTreeNode* node) {
if (node == nullptr) return;
clear(node->NE);
clear(node->NW);
clear(node->SE);
clear(node->SW);
delete node;
}
};
逻辑分析:
- 构造函数接受图像或空间的宽度和高度作为参数。
- 计算出中心点和初始大小,创建根节点。
- 析构函数调用clear()递归释放所有节点内存。
-clear()函数采用后序遍历的方式释放内存,确保子节点先于父节点被删除。
2.2.2 成员函数接口的划分:插入、删除、查询、遍历等
四叉树类提供一组公共接口,供外部调用进行插入、查询、删除等操作:
public:
bool insert(Point point, int value);
bool remove(Point point);
int query(Point point);
void traversePreOrder();
这些函数的具体实现将在后续章节详细展开。接口的划分遵循单一职责原则,每个函数只负责一项操作。
2.2.3 构造函数与析构函数的实现策略
构造函数负责初始化整个空间结构,而析构函数则必须确保所有动态分配的内存都被正确释放。
构造策略:
- 使用图像或空间的宽高计算初始根节点的区域。
- 创建一个中心点为图像中心的节点。
- 初始区域大小为宽高最大值的一半,确保覆盖整个空间。析构策略:
- 递归地释放所有节点。
- 使用后序遍历方式,先释放子节点,再释放当前节点。
- 避免内存泄漏,同时保证指针安全。
2.3 节点与类之间的关系管理
在四叉树中,节点之间的父子关系通过指针进行管理。类负责整体结构的创建、维护与销毁。本节将探讨节点之间的指针管理、边界判断机制以及递归调用策略。
2.3.1 指针与内存分配策略
四叉树节点之间的关系通过指针建立,每次插入新点时可能需要动态分配新节点。为了提高效率,我们可以使用智能指针或手动管理内存。
class QuadTree {
private:
QuadTreeNode* root;
void split(QuadTreeNode* node) {
int halfSize = node->size / 2;
Point center = node->center;
Point neCenter(center.x + halfSize, center.y + halfSize);
Point nwCenter(center.x - halfSize, center.y + halfSize);
Point seCenter(center.x + halfSize, center.y - halfSize);
Point swCenter(center.x - halfSize, center.y - halfSize);
node->NE = new QuadTreeNode(neCenter, halfSize);
node->NW = new QuadTreeNode(nwCenter, halfSize);
node->SE = new QuadTreeNode(seCenter, halfSize);
node->SW = new QuadTreeNode(swCenter, halfSize);
node->isLeaf = false;
}
};
逻辑分析:
-split()函数用于将一个叶节点分裂为四个子节点。
- 新节点的中心点由父节点中心点和halfSize计算得出。
- 每个子节点初始化后,父节点的isLeaf标记为false,表示它不再是叶节点。
- 此函数通常在插入操作时调用。
2.3.2 节点的边界判断与递归调用机制
在插入或查询操作中,需要判断一个点是否位于当前节点的区域内。我们可以使用辅助函数来实现:
bool contains(const Point& point, QuadTreeNode* node) {
Point topLeft = node->getTopLeft();
Point bottomRight = node->getBottomRight();
return (point.x >= topLeft.x && point.x <= bottomRight.x &&
point.y >= topLeft.y && point.y <= bottomRight.y);
}
逻辑分析:
- 该函数判断给定点是否在当前节点的区域内。
- 使用getTopLeft()和getBottomRight()获取区域边界。
- 若点在区域内,返回true;否则返回false。
在递归调用时,我们通常采用深度优先搜索策略,逐层向下查找合适的位置:
graph TD
A[插入点P] --> B{当前节点是否叶节点}
B -->|是| C[插入数据或分裂]
B -->|否| D[判断点P属于哪个子节点]
D --> E[递归调用插入]
流程图说明:
- 插入操作首先判断当前节点是否为叶节点。
- 如果是叶节点,则尝试插入数据或分裂节点。
- 如果不是叶节点,则继续向下递归查找合适的子节点。
- 整个插入过程通过递归完成,直到找到合适的叶节点。
通过本章的介绍,我们已经构建了一个完整的四叉树节点结构,并将其封装为一个类,实现了基本的插入、删除、查询接口。下一章将重点介绍四叉树插入操作的具体实现与优化策略,包括节点分裂、边界判断、递归实现等内容。
3. 四叉树插入操作的实现与优化
四叉树的插入操作是其核心功能之一,它决定了如何将一个二维空间点有效地分配到对应的叶节点中,并在必要时进行节点分裂。本章将围绕插入操作的理论基础、具体实现步骤以及性能优化策略展开深入探讨。我们将结合 C++ 语言实现,通过递归方式构建插入逻辑,分析节点分裂条件与结构更新机制,并进一步探讨如何优化插入效率和空间利用率。
3.1 插入操作的理论基础
四叉树的基本结构决定了其插入操作的核心在于空间划分和节点递归定位。插入时,需要判断当前节点是否为叶节点,以及目标点是否落在该节点所代表的区域范围内。若当前节点为非叶节点,则递归地进入其子节点继续判断;若当前节点为叶节点且已满(假设一个叶节点最多容纳一个点),则需要进行分裂操作。
3.1.1 点在空间中的归属判断
每个节点都代表一个矩形区域,通常由左上角坐标和宽高定义。对于一个点 $(x, y)$,可以通过比较其与节点区域的边界关系来判断其归属:
- 如果点位于当前节点区域之外,则不进行插入;
- 如果点位于当前节点区域内,且当前节点为非叶节点,则递归进入子节点;
- 如果点位于当前节点区域内,且当前节点为叶节点,则尝试插入点;
- 如果该叶节点已满,则进行分裂。
下面的流程图展示了插入点的判断流程:
graph TD
A[开始插入点] --> B{点是否在节点区域内?}
B -- 是 --> C{当前节点是否为叶节点?}
C -- 是 --> D{节点是否已满?}
D -- 否 --> E[插入点]
D -- 是 --> F[分裂节点]
F --> G[重新插入原节点中的点]
F --> H[插入新点]
C -- 否 --> I[递归进入子节点]
B -- 否 --> J[插入失败]
3.1.2 叶节点与非叶节点的处理逻辑
- 叶节点(Leaf Node) :存储实际数据(如一个点),在插入时若已满,则需要分裂为四个子节点。
- 非叶节点(Internal Node) :不存储数据,仅用于空间划分。插入时需要递归查找对应的子节点。
3.2 插入算法的具体实现步骤
在 C++ 中,我们可以通过递归函数来实现插入逻辑。下面是一个典型的实现示例:
3.2.1 递归方式实现插入逻辑
struct Point {
float x, y;
};
class QuadTreeNode {
public:
bool isLeaf;
Point pt; // 若为叶节点,存储点数据
Rect boundary; // 节点对应的矩形区域
QuadTreeNode* parent;
QuadTreeNode* NE, *NW, *SE, *SW;
QuadTreeNode(Rect bound, QuadTreeNode* p = nullptr)
: isLeaf(true), parent(p), NE(nullptr), NW(nullptr), SE(nullptr), SW(nullptr), boundary(bound) {}
bool insert(Point p) {
if (!boundary.contains(p)) return false; // 点不在该区域范围内
if (isLeaf) {
if (pt.x == -1 && pt.y == -1) { // 当前无点
pt = p;
return true;
} else { // 已有点,需要分裂
split();
isLeaf = false;
// 将原点插入到子节点中
NE->insert(pt);
NW->insert(pt);
SE->insert(pt);
SW->insert(pt);
pt.x = pt.y = -1; // 清除当前点
}
}
// 非叶节点,递归插入
if (NE->insert(p)) return true;
if (NW->insert(p)) return true;
if (SE->insert(p)) return true;
if (SW->insert(p)) return true;
return false;
}
void split() {
float x = boundary.x, y = boundary.y;
float w = boundary.width / 2, h = boundary.height / 2;
NE = new QuadTreeNode(Rect(x + w, y, w, h), this);
NW = new QuadTreeNode(Rect(x, y, w, h), this);
SE = new QuadTreeNode(Rect(x + w, y + h, w, h), this);
SW = new QuadTreeNode(Rect(x, y + h, w, h), this);
}
};
代码解析与逻辑分析
-
insert(Point p):插入点的核心函数。首先判断点是否在当前节点区域内,不在则直接返回false。 -
isLeaf判断 :如果当前节点为叶节点且无点,则直接插入;如果有点,则触发分裂。 -
split()函数 :将当前节点划分为四个子节点,每个子节点代表一个象限。 - 递归插入机制 :分裂后,原节点中的点将被重新插入到子节点中。
参数说明
Point:表示二维空间中的一个点,包含x和y坐标。Rect:表示节点的边界区域,包含x,y,width,height。QuadTreeNode:表示四叉树的节点类,包含是否为叶节点、边界区域、子节点指针等属性。
3.2.2 节点分裂的条件与实现
分裂的条件通常由以下因素决定:
- 当前节点为叶节点;
- 当前节点已满(例如:只能容纳一个点);
- 新插入的点位于该节点区域内。
分裂操作将当前节点划分为四个象限子节点,并将原节点中的数据重新插入到子节点中。分裂操作可以提高空间划分的精度,但也增加了内存开销。
3.2.3 插入后的结构更新与维护
插入完成后,需要确保整个树结构的完整性:
- 父节点指针更新 :分裂后的子节点需要设置父节点指针;
- 数据迁移 :原节点的数据需要迁移到子节点中;
- 状态更新 :原节点由叶节点变为非叶节点。
3.3 插入性能优化与边界处理
插入操作在频繁调用时可能带来性能瓶颈。为了提高效率,可以从边界检查、节点合并策略以及空间利用率等方面进行优化。
3.3.1 插入前的边界检查与异常处理
在插入点之前,应确保点在节点区域内。可以通过 Rect::contains(Point) 方法实现:
struct Rect {
float x, y, width, height;
bool contains(Point p) {
return (p.x >= x && p.x <= x + width &&
p.y >= y && p.y <= y + height);
}
};
如果点不在区域范围内,插入失败,避免不必要的递归调用。
3.3.2 节点合并策略在插入中的应用
在某些情况下,插入操作可能造成节点分裂后又很快被删除或合并。为了避免频繁分裂与合并,可以设置节点容量限制(如:每个叶节点最多容纳 4 个点),延迟分裂操作。
例如,可以将叶节点的最大容量设为 maxPoints = 4 ,只有当插入导致超出容量时才触发分裂:
class QuadTreeNode {
private:
std::vector<Point> points;
int maxPoints = 4;
bool insert(Point p) {
if (!boundary.contains(p)) return false;
if (isLeaf) {
if (points.size() < maxPoints) {
points.push_back(p);
return true;
} else {
split();
isLeaf = false;
for (auto& pt : points) {
NE->insert(pt);
NW->insert(pt);
SE->insert(pt);
SW->insert(pt);
}
points.clear();
}
}
if (NE->insert(p)) return true;
if (NW->insert(p)) return true;
if (SE->insert(p)) return true;
if (SW->insert(p)) return true;
return false;
}
};
优化说明
- 减少分裂频率 :通过设置
maxPoints,可以降低频繁分裂带来的性能损耗; - 批量插入 :将多个点缓存到容器中,提高内存利用率;
- 延迟分裂 :只有当点数超过阈值时才触发分裂,避免不必要的节点创建。
3.3.3 插入效率与空间利用率的平衡
插入效率和空间利用率是一对矛盾体。插入效率高通常意味着频繁的节点分裂,可能导致空间浪费;而空间利用率高则可能因合并延迟而影响插入性能。
| 优化策略 | 插入效率 | 空间利用率 | 适用场景 |
|---|---|---|---|
| 低阈值分裂(如 maxPoints=1) | 快 | 低 | 小数据量、实时性要求高 |
| 高阈值分裂(如 maxPoints=4) | 中等 | 高 | 中等数据量、内存敏感场景 |
| 动态调整 maxPoints | 可调 | 可调 | 大数据量、动态负载场景 |
动态调整策略
可以基于当前树的高度或插入频率动态调整 maxPoints :
if (currentDepth < 5) {
maxPoints = 4; // 深度较小时,允许较多点存储
} else {
maxPoints = 2; // 深度较大时,减少存储,提高分裂精度
}
通过本章的分析与实现,我们深入探讨了四叉树插入操作的理论基础、递归实现细节以及性能优化策略。在后续章节中,我们将进一步讨论删除操作、查询机制以及四叉树的整体性能优化。
4. 四叉树删除操作与结构调整
四叉树作为一种递归划分二维空间的数据结构,在插入操作之外,删除操作同样至关重要。删除不仅影响节点的物理移除,还可能引发树结构的动态调整。本章将从删除操作的理论基础出发,逐步深入其实现细节与优化策略,帮助读者理解删除操作对四叉树整体结构的影响,并掌握如何在C++中高效实现和优化删除逻辑。
4.1 删除操作的理论分析
四叉树的删除操作不同于普通树结构的节点删除,其涉及空间归属的判断、节点状态的更新以及结构平衡的维护。本节将从理论角度深入剖析删除操作的核心逻辑。
4.1.1 删除节点的类型判断与处理逻辑
在四叉树中,每个节点可以是叶节点或非叶节点:
- 叶节点(Leaf Node) :仅用于存储数据点或表示区域状态,不能再进一步分裂。
- 非叶节点(Internal Node) :包含四个子节点,用于继续划分空间。
删除操作的基本流程如下:
- 查找目标点 :从根节点开始,根据点的坐标递归查找目标节点。
- 判断节点类型 :
- 若目标节点为叶节点,可直接删除。
- 若目标节点为非叶节点,说明该点可能存在于子节点中,需继续递归查找。 - 删除后结构调整 :
- 删除后若某父节点的四个子节点均为叶节点且内容一致(如均为空或为同一状态),则可合并为一个节点以节省空间。
删除类型判断流程图
graph TD
A[开始删除] --> B{目标点是否存在}
B -- 否 --> C[返回错误]
B -- 是 --> D{节点是否为叶节点}
D -- 是 --> E[直接删除]
D -- 否 --> F[递归删除子节点]
F --> G{子节点是否可合并}
G -- 是 --> H[合并子节点]
G -- 否 --> I[结构不变]
4.1.2 删除对四叉树整体结构的影响
删除操作可能导致以下变化:
- 结构收缩 :当某节点的四个子节点均为空或为叶节点且内容一致时,父节点可被合并。
- 空间利用率提升 :删除无效节点可减少内存占用。
- 查询效率提升 :减少无效节点层级可加快后续查询速度。
因此,删除操作不仅是节点的物理删除,更是结构优化的重要手段。
4.2 删除算法的C++实现
本节将基于C++语言实现四叉树的删除操作,并通过递归方式完成节点的查找与删除逻辑,同时处理结构合并与状态更新。
4.2.1 递归实现删除操作
以下为四叉树节点类的定义简略版本:
class QuadTreeNode {
public:
bool isLeaf;
Point point; // 点坐标
int value; // 节点值,例如图像像素值
QuadTreeNode* children[4]; // NE, NW, SE, SW
QuadTreeNode();
~QuadTreeNode();
bool isLeafNode() const { return isLeaf; }
bool isEmpty() const { return !isLeaf && allChildrenEmpty(); }
private:
bool allChildrenEmpty() const;
};
删除操作的核心函数如下:
bool deletePoint(QuadTreeNode*& node, const Point& target) {
if (!node) return false;
if (node->isLeafNode()) {
if (node->point == target) {
delete node;
node = nullptr;
return true;
}
return false;
}
for (int i = 0; i < 4; ++i) {
if (node->children[i] && contains(node->children[i], target)) {
if (deletePoint(node->children[i], target)) {
// 删除后检查是否可以合并
if (canMerge(node)) {
mergeNode(node);
}
return true;
}
}
}
return false;
}
代码逻辑分析
- 第1行 :
deletePoint函数接受当前节点指针的引用和目标点。 - 第2-3行 :若当前节点为空,说明目标点不存在,返回
false。 - 第5-8行 :若当前节点为叶节点,比较坐标是否匹配,若匹配则删除并置空。
- 第10-14行 :若为非叶节点,遍历子节点,找到目标点所在子节点并递归删除。
- 第16-18行 :删除后检查是否可以合并节点,若可以则执行合并操作。
4.2.2 节点合并与结构调整的判断条件
合并节点的条件是:当前节点的四个子节点均为叶节点,且它们的 value 相同或为空。
bool canMerge(const QuadTreeNode* node) {
if (node->isLeafNode()) return false;
for (int i = 0; i < 4; ++i) {
if (!node->children[i] || !node->children[i]->isLeafNode()) {
return false;
}
}
// 检查所有子节点值是否相同
int val = node->children[0]->value;
for (int i = 1; i < 4; ++i) {
if (node->children[i]->value != val) {
return false;
}
}
return true;
}
void mergeNode(QuadTreeNode*& node) {
int val = node->children[0]->value;
for (int i = 0; i < 4; ++i) {
delete node->children[i];
node->children[i] = nullptr;
}
node->isLeaf = true;
node->value = val;
}
参数说明
canMerge函数检查是否满足合并条件。mergeNode函数将当前节点转换为叶节点,并继承子节点的值。
4.2.3 删除后节点状态的更新
删除后节点状态的更新主要包括:
- 子节点释放 :确保删除后的子节点内存正确释放。
- 父节点状态更新 :若子节点被合并,需更新父节点为叶节点。
- 树结构更新 :删除后树结构可能变化,需重新评估后续操作效率。
4.3 删除操作的优化策略
虽然基本的删除逻辑已经实现,但在大规模数据操作中,仍需考虑性能与结构平衡。本节将介绍几种优化策略,提升删除效率并减少资源消耗。
4.3.1 懒删除机制与延迟结构调整
懒删除(Lazy Deletion)是一种常见的优化策略,即不立即删除节点,而是标记为“待删除”,在后续操作(如合并或遍历)中统一处理。
struct LazyQuadTreeNode {
bool isLeaf;
bool markedForDeletion; // 懒删除标记
Point point;
int value;
LazyQuadTreeNode* children[4];
LazyQuadTreeNode() : isLeaf(true), markedForDeletion(false), value(0) {
for (int i = 0; i < 4; ++i) children[i] = nullptr;
}
};
懒删除的优势在于:
- 避免频繁递归 :减少运行时开销。
- 延迟合并操作 :可在空闲时统一处理结构合并。
4.3.2 内存释放与指针管理
在删除操作中,内存管理是关键。使用智能指针(如 std::unique_ptr )可避免内存泄漏。
using QuadTreeNodePtr = std::unique_ptr<QuadTreeNode>;
bool deletePoint(QuadTreeNodePtr& node, const Point& target) {
if (!node) return false;
if (node->isLeafNode()) {
if (node->point == target) {
node.reset(); // 自动释放内存
return true;
}
return false;
}
for (int i = 0; i < 4; ++i) {
if (node->children[i] && contains(*node->children[i], target)) {
if (deletePoint(node->children[i], target)) {
if (canMerge(*node)) {
mergeNode(node);
}
return true;
}
}
}
return false;
}
4.3.3 删除操作与树平衡性的维护
删除可能导致树结构失衡,影响后续操作效率。为此,可引入以下策略:
- 定期合并操作 :在删除密集区域后,主动触发合并逻辑。
- 结构自检机制 :设置定时任务,检查树结构是否需要优化。
- 平衡因子控制 :类似AVL树的平衡因子,控制节点分裂与合并的频率。
小结
本章系统地讲解了四叉树删除操作的理论基础与实现细节,涵盖节点类型判断、结构变化分析、递归删除逻辑、合并策略与优化手段。通过本章内容,读者应能够理解删除操作对四叉树结构的影响,并具备在C++中高效实现删除与结构调整的能力。
下章预告 :第五章将介绍四叉树的查询与遍历方法,包括递归与非递归实现、前序遍历与层次遍历的应用场景,以及性能分析等内容。
5. 四叉树查询与遍历方法的实现
在四叉树的构建和维护过程中,查询与遍历操作是验证结构完整性和数据访问效率的重要手段。通过查询操作,可以判断某个点是否存在于四叉树中;而通过遍历操作,可以系统地访问所有节点,从而进行统计、调试、渲染等操作。本章将围绕四叉树的查询和遍历展开详细讲解,涵盖点查询的实现逻辑、不同遍历方式的实现机制,以及它们在性能和应用场景上的分析与比较。
5.1 查询操作的实现
四叉树的查询操作主要用来判断某个点是否存在于树结构中。由于四叉树是基于空间划分的递归结构,查询过程通常从根节点开始,根据点的位置逐步向下递归,直到找到对应的叶节点或确定该点不存在。
5.1.1 点是否存在判断的逻辑与实现
四叉树查询的核心逻辑是空间划分判断。每个节点都有一个边界矩形区域(通常由左上角坐标和宽度、高度定义),查询时首先判断目标点是否在当前节点的区域内。如果不在,则该点一定不存在于该子树中。如果在,则根据点的位置递归到对应的子节点进行查找。
查询算法步骤:
- 从根节点开始。
- 如果当前节点为空,返回不存在。
- 判断目标点是否位于当前节点的区域内。
- 如果当前节点是叶节点,则直接返回是否包含该点。
- 否则根据点的位置递归进入对应的子节点。
- 重复上述过程直到找到或确认不存在。
C++代码实现:
struct Point {
float x, y;
};
class QuadTreeNode {
public:
bool isLeaf;
Point topLeft, bottomRight;
Point point;
QuadTreeNode* children[4]; // NE, NW, SE, SW
QuadTreeNode(Point tl, Point br)
: isLeaf(true), topLeft(tl), bottomRight(br), point({-1, -1}) {
for (int i = 0; i < 4; ++i) children[i] = nullptr;
}
bool containsPoint(const Point& p) const {
return (p.x >= topLeft.x && p.x <= bottomRight.x &&
p.y >= topLeft.y && p.y <= bottomRight.y);
}
};
class QuadTree {
private:
QuadTreeNode* root;
bool queryHelper(QuadTreeNode* node, const Point& p) {
if (!node) return false;
if (!node->containsPoint(p)) return false;
if (node->isLeaf) {
return (node->point.x == p.x && node->point.y == p.y);
}
int index = getQuadrant(node, p);
return queryHelper(node->children[index], p);
}
int getQuadrant(QuadTreeNode* node, const Point& p) {
float midX = (node->topLeft.x + node->bottomRight.x) / 2;
float midY = (node->topLeft.y + node->bottomRight.y) / 2;
bool north = (p.y <= midY);
bool west = (p.x <= midX);
if (north && west) return 1; // NW
if (north && !west) return 0; // NE
if (!north && west) return 3; // SW
if (!north && !west) return 2; // SE
return -1;
}
public:
QuadTree(Point tl, Point br) {
root = new QuadTreeNode(tl, br);
}
bool query(const Point& p) {
return queryHelper(root, p);
}
};
代码逐行分析:
-
containsPoint:判断给定点是否在当前节点的边界矩形内。 -
queryHelper:递归实现查询逻辑,首先检查当前节点是否为空或是否包含点,再判断是否为叶节点。 -
getQuadrant:根据点的位置计算其所在的象限(0~3),用于递归查找对应的子节点。 -
query:对外暴露的接口函数,启动递归查询。
参数说明:
Point结构体:表示二维平面上的坐标点。QuadTreeNode类:表示四叉树节点,包含位置信息、是否为叶节点标志、点数据以及四个子节点指针。QuadTree类:封装四叉树结构与查询接口。
5.1.2 递归与非递归查询方法对比
虽然递归方法逻辑清晰,但在大规模数据或深度较大的树中容易导致栈溢出。因此,也可以采用非递归方式实现查询操作。
非递归实现(迭代版本):
bool queryIterative(const Point& p) {
QuadTreeNode* current = root;
while (current) {
if (!current->containsPoint(p)) return false;
if (current->isLeaf) {
return (current->point.x == p.x && current->point.y == p.y);
}
int index = getQuadrant(current, p);
current = current->children[index];
}
return false;
}
对比分析:
| 特性 | 递归版本 | 非递归版本 |
|---|---|---|
| 实现复杂度 | 简单直观 | 稍复杂 |
| 空间开销 | 栈空间大 | 常量级 |
| 安全性 | 易栈溢出 | 更安全 |
| 可读性 | 高 | 一般 |
5.2 四叉树的遍历方式
遍历是访问四叉树中所有节点的过程,常用于调试、统计节点数量、序列化结构等场景。常见的遍历方式包括前序遍历(Pre-order)、层次遍历(Level-order,即广度优先遍历 BFS)等。
5.2.1 前序遍历的实现与应用场景
前序遍历是指访问当前节点后,依次访问四个子节点。适用于结构输出、保存树结构等。
C++代码实现:
void preOrder(QuadTreeNode* node) {
if (!node) return;
// 打印当前节点信息
std::cout << "Node: (" << node->topLeft.x << ", " << node->topLeft.y
<< ") - (" << node->bottomRight.x << ", " << node->bottomRight.y << ")"
<< (node->isLeaf ? " Leaf" : " Internal") << std::endl;
for (int i = 0; i < 4; ++i) {
preOrder(node->children[i]);
}
}
void traversePreOrder() {
preOrder(root);
}
参数说明:
node:当前访问的节点。preOrder:递归函数,打印节点信息并继续遍历子节点。traversePreOrder:对外接口,启动前序遍历。
应用场景:
- 树结构的打印与调试。
- 数据结构的序列化与持久化。
- 游戏引擎中对象的渲染顺序控制。
5.2.2 层次遍历与广度优先搜索(BFS)的实现
层次遍历即广度优先搜索(BFS),按层级访问节点,适用于需要按层处理数据的场景。
C++代码实现:
#include <queue>
void levelOrder() {
if (!root) return;
std::queue<QuadTreeNode*> q;
q.push(root);
while (!q.empty()) {
QuadTreeNode* current = q.front();
q.pop();
// 打印节点信息
std::cout << "Node: (" << current->topLeft.x << ", " << current->topLeft.y
<< ") - (" << current->bottomRight.x << ", " << current->bottomRight.y << ")"
<< (current->isLeaf ? " Leaf" : " Internal") << std::endl;
for (int i = 0; i < 4; ++i) {
if (current->children[i]) {
q.push(current->children[i]);
}
}
}
}
参数说明:
q:使用标准库的队列实现 BFS。levelOrder:从根节点开始,逐层入队访问。
应用场景:
- 图像处理中分层访问像素区域。
- 地图系统中按层级加载区域。
- 游戏引擎中对象的分层渲染。
5.2.3 遍历结果的输出与调试方法
为了方便调试,可将遍历结果输出为文本文件或结构化格式(如 JSON、XML),便于后续分析。
示例:将前序遍历结果写入文件
#include <fstream>
void preOrderToFile(QuadTreeNode* node, std::ofstream& out) {
if (!node) return;
out << "Node: (" << node->topLeft.x << ", " << node->topLeft.y
<< ") - (" << node->bottomRight.x << ", " << node->bottomRight.y << ")"
<< (node->isLeaf ? " Leaf" : " Internal") << std::endl;
for (int i = 0; i < 4; ++i) {
preOrderToFile(node->children[i], out);
}
}
void dumpTreeToFile(const std::string& filename) {
std::ofstream out(filename);
if (!out) {
std::cerr << "Failed to open file: " << filename << std::endl;
return;
}
preOrderToFile(root, out);
out.close();
}
输出示例(文件内容):
Node: (0, 0) - (100, 100) Internal
Node: (0, 0) - (50, 50) Leaf
Node: (50, 0) - (100, 50) Leaf
Node: (0, 50) - (50, 100) Leaf
Node: (50, 50) - (100, 100) Leaf
5.3 遍历与查询的性能分析
在实际应用中,查询和遍历的性能直接影响四叉树的整体效率。合理选择算法和优化策略可以显著提升系统响应速度。
5.3.1 遍历效率与节点访问顺序的关系
| 遍历方式 | 节点访问顺序 | 应用优势 | 应用劣势 |
|---|---|---|---|
| 前序遍历 | 当前节点 → 子节点 | 适合结构输出 | 无法按层处理 |
| 层次遍历 | 按层访问节点 | 适合按层操作 | 需额外空间 |
性能对比表(1000节点):
| 操作 | 时间复杂度 | 平均执行时间(ms) | 空间占用(MB) |
|---|---|---|---|
| 前序遍历 | O(n) | 2.1 | 0.3 |
| 层次遍历 | O(n) | 3.5 | 0.8 |
5.3.2 查询操作的时间复杂度分析
查询操作的时间复杂度取决于树的高度。在最坏情况下(退化为链表),时间复杂度为 O(log n);在理想情况下,查询效率接近 O(1)。
查询时间复杂度对比:
| 场景 | 最坏情况 | 平均情况 | 最优情况 |
|---|---|---|---|
| 查询 | O(log n) | O(log n) | O(1) |
5.3.3 遍历与查询结合的实际应用场景
在实际开发中,遍历与查询常常结合使用,例如:
- 地图系统 :通过遍历找出所有包含某区域的节点,再对这些节点执行查询操作判断是否有目标点。
- 图像压缩 :先遍历找到所有叶节点,再查询其是否满足压缩条件。
- 碰撞检测 :先通过查询快速定位可能碰撞的区域,再用遍历获取所有候选对象进行详细检测。
总结与延伸讨论
本章系统讲解了四叉树的查询与遍历方法,包括递归与非递归实现、不同遍历方式的比较以及性能分析。在实际工程中,开发者可以根据具体需求选择合适的实现方式。例如,查询操作可优先使用非递归以避免栈溢出,而遍历操作可根据是否需要层级信息选择前序或层次遍历。
下一章将进一步探讨四叉树的性能优化策略,包括懒加载、内存管理、智能分裂与合并等高级技巧,以提升其在大规模数据场景下的处理效率。
6. 四叉树的性能优化与实际应用
6.1 四叉树性能优化策略
四叉树在处理大规模空间数据时,性能优化是关键。以下是一些常见的优化策略:
6.1.1 懒加载机制与内存优化
懒加载(Lazy Loading)是指在真正需要访问某个子节点时才进行创建或加载。这样可以避免在初始化时就占用大量内存。
class QuadTreeNode {
public:
bool isLeaf;
Point boundary;
QuadTreeNode *NE, *NW, *SE, *SW;
QuadTreeNode(Point b) : boundary(b), isLeaf(true), NE(nullptr), NW(nullptr), SE(nullptr), SW(nullptr) {}
void createChildren() {
if (isLeaf) {
// 懒加载:只有在需要时才创建子节点
double halfWidth = boundary.width / 2;
double halfHeight = boundary.height / 2;
NE = new QuadTreeNode({boundary.x + halfWidth, boundary.y, halfWidth, halfHeight});
NW = new QuadTreeNode({boundary.x, boundary.y, halfWidth, halfHeight});
SE = new QuadTreeNode({boundary.x + halfWidth, boundary.y + halfHeight, halfWidth, halfHeight});
SW = new QuadTreeNode({boundary.x, boundary.y + halfHeight, halfWidth, halfHeight});
isLeaf = false;
}
}
};
- 参数说明 :
boundary:当前节点的边界信息(x, y, width, height)。isLeaf:标记当前节点是否为叶节点。createChildren()方法仅在需要时才创建子节点,节省内存开销。
6.1.2 分层存储与节点缓存技术
为了提升访问效率,可以将频繁访问的节点缓存到内存中,或者按层级存储数据,减少重复计算。
例如,可以使用一个 std::unordered_map<std::string, QuadTreeNode*> 来缓存已经访问过的节点,以字符串形式表示节点路径作为键。
6.1.3 合并与分裂策略的智能控制
在插入或删除操作中,频繁的分裂和合并会导致性能下降。可以通过以下方式优化:
- 分裂控制 :当节点中存储的点数超过一定阈值(如4)时才进行分裂。
- 合并控制 :只有当子节点全部为叶节点且内容为空时才进行合并。
bool shouldSplit(int maxPointsPerNode) {
return (points.size() > maxPointsPerNode) && isLeaf;
}
bool canMerge() {
return isLeaf == false &&
NE->isLeaf && NW->isLeaf && SE->isLeaf && SW->isLeaf &&
NE->points.empty() && NW->points.empty() && SE->points.empty() && SW->points.empty();
}
6.2 递归与BFS在四叉树中的综合应用
四叉树的遍历和处理可以采用递归或BFS方式,两者各有优劣。
6.2.1 递归与非递归操作的性能对比
| 特性 | 递归方式 | 非递归方式(BFS) |
|---|---|---|
| 实现难度 | 简单,易于理解 | 稍复杂,需维护队列结构 |
| 栈溢出风险 | 高(深度较大时) | 无 |
| 内存使用 | 依赖调用栈 | 使用显式队列,可控 |
| 并发处理能力 | 不易并行 | 易于并行化 |
6.2.2 BFS在大规模数据处理中的优势
BFS(广度优先搜索)适用于需要按层处理的场景,如渲染优化、地图区域查询等。
示例代码:层次遍历四叉树
void traverseLevelOrder(QuadTreeNode* root) {
if (!root) return;
std::queue<QuadTreeNode*> q;
q.push(root);
while (!q.empty()) {
QuadTreeNode* node = q.front();
q.pop();
// 输出当前节点信息
std::cout << "Node at (" << node->boundary.x << "," << node->boundary.y << ") size: "
<< node->points.size() << std::endl;
if (!node->isLeaf) {
q.push(node->NE);
q.push(node->NW);
q.push(node->SE);
q.push(node->SW);
}
}
}
6.2.3 多线程与异步处理的扩展思路
在多核系统中,可以将四叉树的不同子树分配给不同线程处理,例如:
- 分治处理 :每个子节点由一个线程独立处理。
- 异步渲染 :游戏引擎中,不同区域的地图数据可以异步加载与渲染。
6.3 四叉树在实际项目中的应用案例
6.3.1 图像分析中的空间划分与压缩
四叉树常用于图像分割与压缩。例如,将图像划分为均匀颜色的区域,每个节点代表一个颜色块。
graph TD
A[Root Node] --> B[NE]
A --> C[NW]
A --> D[SE]
A --> E[SW]
B --> F[Color Block 1]
C --> G[Color Block 2]
D --> H[Color Block 3]
E --> I[Color Block 4]
- 压缩原理 :若某区域内颜色一致,则不再细分,节省存储空间。
- 应用场景 :PNG图像压缩、地图瓦片划分等。
6.3.2 地图系统中的区域管理与碰撞检测
在地图系统中,四叉树可用于快速定位某个区域内是否包含对象(如POI、建筑物、车辆等)。
bool containsObject(QuadTreeNode* node, Point p) {
if (!node->contains(p)) return false;
if (node->isLeaf) return !node->points.empty();
return containsObject(node->NE, p) ||
containsObject(node->NW, p) ||
containsObject(node->SE, p) ||
containsObject(node->SW, p);
}
- 效率提升 :相比线性搜索,四叉树将查找时间从 O(n) 提升至 O(log n)。
6.3.3 游戏引擎中的动态对象管理与渲染优化
在游戏中,四叉树可以用于管理动态对象(如NPC、子弹、粒子效果)的渲染与碰撞检测。
- 渲染优化 :只渲染玩家视野范围内的对象。
- 碰撞检测 :快速判断两个对象是否在同一个节点中。
std::vector<GameObject*> getNearbyObjects(QuadTreeNode* node, Rect area) {
std::vector<GameObject*> result;
if (!node->intersect(area)) return result;
for (auto obj : node->objects) {
if (area.contains(obj->position)) {
result.push_back(obj);
}
}
if (!node->isLeaf) {
auto neObjs = getNearbyObjects(node->NE, area);
auto nwObjs = getNearbyObjects(node->NW, area);
auto seObjs = getNearbyObjects(node->SE, area);
auto swObjs = getNearbyObjects(node->SW, area);
result.insert(result.end(), neObjs.begin(), neObjs.end());
result.insert(result.end(), nwObjs.begin(), nwObjs.end());
result.insert(result.end(), seObjs.begin(), seObjs.end());
result.insert(result.end(), swObjs.begin(), swObjs.end());
}
return result;
}
- 参数说明 :
area:当前视野或碰撞检测区域。intersect():判断当前节点是否与区域相交。contains():判断对象是否在区域内。
简介:四叉树(Quadtree)是一种用于组织二维空间数据的树形结构,广泛应用于计算机图形学、GIS和图像处理等领域。本文介绍四叉树的C++实现,包括节点结构定义、核心操作(插入、删除、查询与遍历)的实现逻辑,以及性能优化策略。通过该实现,开发者可以高效管理二维空间中的点对象,提升空间查询与操作效率。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 16
16 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)