深度学习中的温度参数(temperature parameter)--疑问待解决
读论文的过程中,看到这个概念:temperature parameter。Ln=−logexp(sim(Zni,Znj)/τ)∑n′=1,n′≠nM(exp(sim(Zni,Zn′j)/τ))τ为温度参数\mathcal{L}_n=-log\frac{exp(sim(Z_{ni},Z_{nj})/\tau)}{\sum^M_{n'=1,n'\ne{n}}(exp(sim(Z_{ni},Z_{n'j
读论文的过程中,看到这个概念:temperature parameter。
L n = − l o g e x p ( s i m ( Z n i , Z n j ) / τ ) ∑ n ′ = 1 , n ′ ≠ n M ( e x p ( s i m ( Z n i , Z n ′ j ) / τ ) ) τ 为 温 度 参 数 \mathcal{L}_n=-log\frac{exp(sim(Z_{ni},Z_{nj})/\tau)}{\sum^M_{n'=1,n'\ne{n}}(exp(sim(Z_{ni},Z_{n'j})/\tau))} \quad \tau为温度参数 Ln=−log∑n′=1,n′=nM(exp(sim(Zni,Zn′j)/τ))exp(sim(Zni,Znj)/τ)τ为温度参数
以softmax函数为例,增加温度系数后的效果如下:可以看温度系数越大,曲线越平滑;反之,曲线越尖锐。
import numpy as np
import matplotlib.pyplot as plt
def softmax(x, t=1):
x = [i/t for i in x] # temperature parameter
return np.exp(x) / sum(np.exp(x))
x = np.arange(10)
[y1,y2,y3]=[softmax(x, i) for i in [2,1,0.2]]
plt.plot(x, y1, label="t=2")
plt.plot(x, y2, label="t=1")
plt.plot(x, y3, label="t=0.2")
plt.legend()
plt.show()
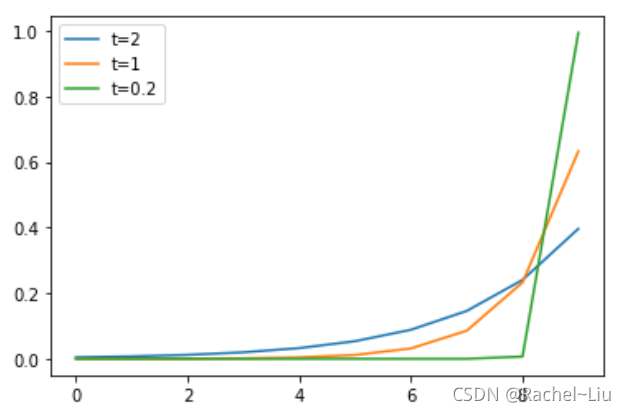
如果在训练的过程中将温度参数设置比较大,那么预测的概率分布会比较平滑,会导致损失变大,从而梯度也越大,参数更新步长就会较大,避免陷入局部最优解。(为什么会陷入局部最优,对于非凸问题而言,在局部最优点处梯度变化非常小,算法会认为已经收敛)
一般在计算概率时使用温度参数,初始会将温度参数设置较大,随着训练的进行,会将温度参数变小,也叫做“降温”的过程,才更有利于模型收敛。
问题:概率分布的平滑程度,如何影响模型收敛?

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)