AI入门那么简单|3-非监督学习:探索未标记数据之美
什么是非监督学习???
非监督学习是一种从未标记的数据集中发现启示因素来分类和模式提取的机器学习方法。其要点在于算法没有指定预测变量或结果,而是试图发现数据自身的结构和有趣的特征。
通俗点说,非监督学习就像是探险家拓荒者探索尚未被开发的新大陆一样,寻找未知的、隐藏在数据里的信息。
一个示例是,假设我们有一个没有进行标签分类的音乐库,我们可以使用非监督学习来查找音频质量、相关性等相似性模式。然后,利用这些模式对音乐库中的歌曲进行分类和聚类,得到具有意义的组合。
非监督学习的算法
在非监督学习的发展历程中,有很多经典的算法被提出来,例如:
- K-means聚类算法(Khachiyan, 1991),这是最常用的聚类算法之一,它将数据聚成相互独立的群体,每个群体内的数据点具有相似的特征。
- 主成分分析算法(PCA) (Pearson, 1901),该算法可以将高维数据转换为低维空间,并且确保保留数据的主要内容,而丢弃那些不重要的信息。
- Apriori算法 (Agrawal & Srikant, 1994),该算法可以帮助我们探索两个或多个事物之间的商业关系,比如我们如果知道哪些商品经常被一起购买,就可以进行精准的推荐。
下面,我们就每个算法详细的给各位讲解下。
1、K-means聚类算法
K-means聚类算法是一种基于距离测量的聚类算法。它将数据集分成k个簇,其中每个簇包含最接近质心的数据点。为了更直观地了解这个过程,我们可以看一个简单的示例:
我们有一个二维图像,其中包括所有人的年龄和收入信息。我们可以使用K-means来根据这些信息聚类人群
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 生成标记数据
X = np.array([[10,20],[15,35],[25,60],[30,80],[45,75]])
# 模型训练,k设定为2
kmeans = KMeans(n_clusters=2)
kmeans.fit(X)
# 中心点
centroids = kmeans.cluster_centers_
# 分类
labels = kmeans.labels_
# 可视化
colors = ["g.","r."]
for i in range(len(X)):
print("coordinate:",X[i], "label:", labels[i])
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 10)
plt.scatter(centroids[:, 0], centroids[:, 1], marker = "x", s=150, linewidths = 5, zorder =10)
plt.show()运行结果如下:
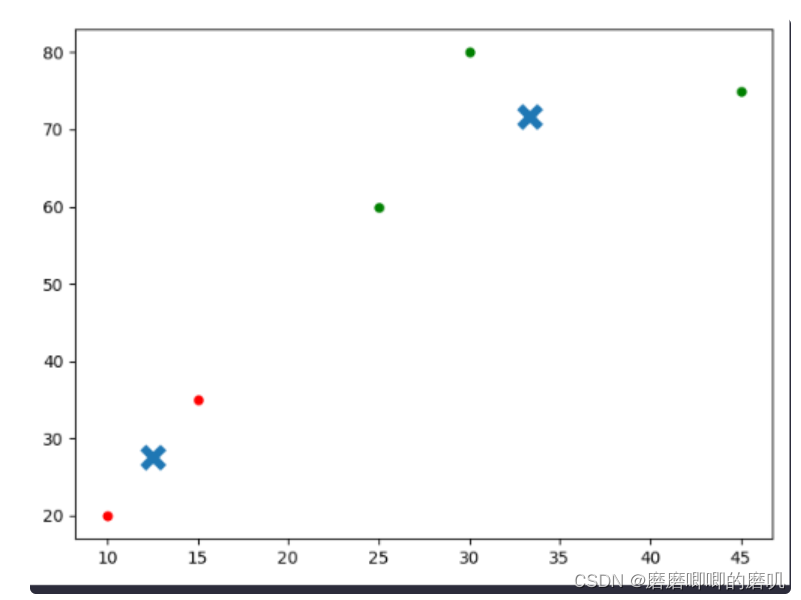
K-means聚类算法
- 主成分分析算法(PCA)
主成分分析算法(PCA)可以帮助我们从高维数据中找出主要信息。
假设我们有一个图片像素为256×256256×256,那么就是一个高维数据。使用PCA算法,我们能够将其转化为一组低维数据点以达到降维的效果。
import numpy as np
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 生成随机数据
rng = np.random.RandomState(1)
X = np.dot(rng.rand(2, 2), rng.randn(2, 200)).T
# 模型训练
pca = PCA(n_components=2)
pca.fit(X)
# 投影数据
X_pca = pca.transform(X)
# 可视化
plt.scatter(X[:, 0], X[:, 1], alpha=0.8)
plt.scatter(X_pca[:, 0], X_pca[:, 1], alpha=0.8)
plt.axis('equal')
plt.show()运行结果如下:
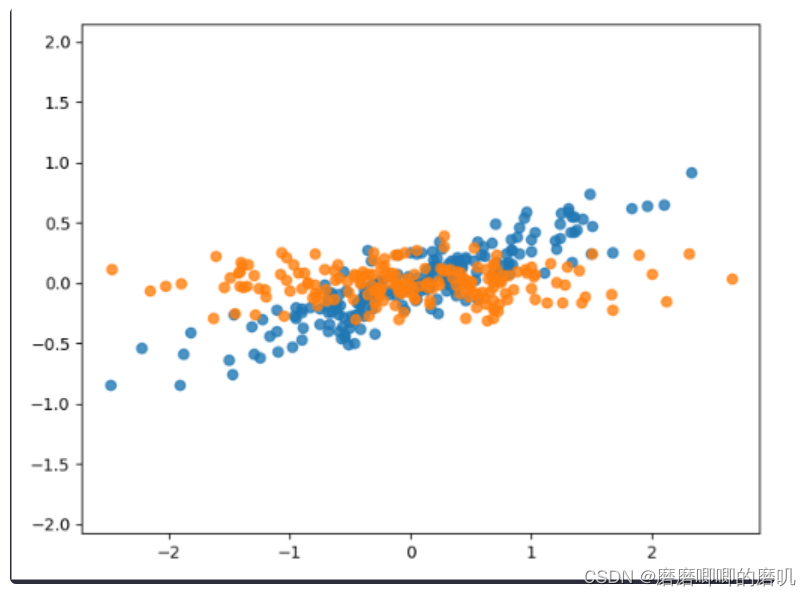
主成分分析算法(PCA)
Apriori算法
Apriori算法是一种用于数据挖掘和机器学习的算法,专门用于发现大规模数据集中的所有频繁项集(itemset)。这种算法基于对多个交易或记录之间关联性的分析,可以帮助我们发现事物之间的联系,进而提高商业效益。比如,我们能够找到哪些商品经常被同时购买等。
该算法最初由Agrawal和Srikant在1994年的“Fast Algorithms for Mining Association Rules in Large Databases”中提出。
现在来让我们通过一个例子来理解这个算法:假设有一个超市销售记录表,信息如下:
|
交易ID |
备选商品 |
|
T100 |
鸡蛋, 牛奶, 豆腐, 苹果 |
|
T200 |
鸡蛋, 牛奶, 苹果 |
|
T300 |
牛奶, 苹果, 葡萄 |
先构造基础数据
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
# 构造示例数据
assist = {'Eggs': [1,1,0], 'Milk': [1,1,1], 'Tofu':[1,0,0], 'Apple':[1,1,1], 'Grape':[0,0,1]}
data= pd.DataFrame(data=assist, columns=['Eggs', 'Milk', 'Tofu', 'Apple', 'Grape'], index=['T100', 'T200', 'T300'])
print(data)
输出结果:
Eggs Milk Tofu Apple Grape
T100 1 1 1 1 0
T200 1 1 0 1 0
T300 0 1 0 1 1
接着使用Apriori算法发现频繁项集,并展示结果:
python复制代码freqItemsets = apriori(data, min_support=0.3, use_colnames=True)
print(freqItemsets)
其中,min_support代表最小支持,即出现次数的占比。这里设定为0.3,即出现在至少30%的记录中。
输出结果:
support itemsets
0 0.666667 (Eggs)
1 1.000000 (Milk)
2 0.333333 (Tofu)
3 1.000000 (Apple)
4 0.333333 (Grape)
5 0.666667 (Eggs, Milk)
6 0.333333 (Eggs, Tofu)
7 0.666667 (Eggs, Apple)
8 0.333333 (Tofu, Milk)
9 1.000000 (Apple, Milk)
10 0.333333 (Grape, Milk)
11 0.333333 (Apple, Tofu)
12 0.333333 (Apple, Grape)
13 0.333333 (Eggs, Tofu, Milk)
14 0.666667 (Eggs, Apple, Milk)
15 0.333333 (Eggs, Apple, Tofu)
16 0.333333 (Apple, Tofu, Milk)
17 0.333333 (Apple, Grape, Milk)
18 0.333333 (Eggs, Apple, Tofu, Milk)
接下来,我们可以使用找到的频繁项集生成关联规则并展示结果:
association_rules(freqItemsets, metric="confidence", min_threshold=0.6)
其中metric代表度量指标,这里使用置信度(confidence);min_threshold代表规则的最小置信度。
输出结果:
antecedents consequents ... conviction zhangs_metric
0 (Eggs) (Milk) ... inf 0.0
1 (Milk) (Eggs) ... 1.0 0.0
2 (Tofu) (Eggs) ... inf 0.5
3 (Eggs) (Apple) ... inf 0.0
4 (Apple) (Eggs) ... 1.0 0.0
5 (Tofu) (Milk) ... inf 0.0
6 (Apple) (Milk) ... inf 0.0
7 (Milk) (Apple) ... inf 0.0
8 (Grape) (Milk) ... inf 0.0
9 (Tofu) (Apple) ... inf 0.0
10 (Grape) (Apple) ... inf 0.0
11 (Eggs, Tofu) (Milk) ... inf 0.0
12 (Tofu, Milk) (Eggs) ... inf 0.5
13 (Tofu) (Eggs, Milk) ... inf 0.5
14 (Eggs, Apple) (Milk) ... inf 0.0
15 (Eggs, Milk) (Apple) ... inf 0.0
16 (Apple, Milk) (Eggs) ... 1.0 0.0
17 (Eggs) (Apple, Milk) ... inf 0.0
18 (Apple) (Eggs, Milk) ... 1.0 0.0
19 (Milk) (Eggs, Apple) ... 1.0 0.0
20 (Eggs, Tofu) (Apple) ... inf 0.0
21 (Tofu, Apple) (Eggs) ... inf 0.5
22 (Tofu) (Eggs, Apple) ... inf 0.5
23 (Tofu, Apple) (Milk) ... inf 0.0
24 (Tofu, Milk) (Apple) ... inf 0.0
25 (Tofu) (Apple, Milk) ... inf 0.0
26 (Apple, Grape) (Milk) ... inf 0.0
27 (Grape, Milk) (Apple) ... inf 0.0
28 (Grape) (Apple, Milk) ... inf 0.0
29 (Eggs, Apple, Tofu) (Milk) ... inf 0.0
30 (Eggs, Tofu, Milk) (Apple) ... inf 0.0
31 (Tofu, Apple, Milk) (Eggs) ... inf 0.5
32 (Eggs, Tofu) (Apple, Milk) ... inf 0.0
33 (Tofu, Apple) (Eggs, Milk) ... inf 0.5
34 (Tofu, Milk) (Eggs, Apple) ... inf 0.5
35 (Tofu) (Eggs, Apple, Milk) ... inf 0.5
[36 rows x 10 columns]四、总结
非监督学习是一项非常重要而且实用的技巧,它可以让我们发现数据中的隐藏信息,抽取最有价值的特征或者模式。常用的算法包括K-means聚类、PCA降维和Apriori算法等;还有很多其他非监督学习算法,在后续的博客文章中我们将会逐一介绍。
各位还想看人工智能的哪些内容,可以关注作者并留言!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)