从机器翻译开始了解Transformer架构
笛卡尔曾经说过:“语言的分歧是人生最大的不幸之一”。地理分隔导致人类之间存在巴别塔,现在机器翻译和大模型的出现让这座塔变得越来越低~虽然世界上有大约 7000 个在使用中的语言,大约200种语言的用户超过10万,但大多数在线的内容都是以少数的流行语言来提供的,比如英语,这让许多不懂这些语言的人处于不利的地位。虽然现存的许多翻译工具,但语法错误会让错误变得难以阅读和理解。另外,如果你想把内容翻译为一
笛卡尔曾经说过:“语言的分歧是人生最大的不幸之一”。
地理分隔导致人类之间存在巴别塔,现在机器翻译和大模型的出现让这座塔变得越来越低~
虽然世界上有大约 7000 个在使用中的语言,大约200种语言的用户超过10万,但大多数在线的内容都是以少数的流行语言来提供的,比如英语,这让许多不懂这些语言的人处于不利的地位。
虽然现存的许多翻译工具,但语法错误会让错误变得难以阅读和理解。另外,如果你想把内容翻译为一个不流行的语言(特别是非洲和亚洲的一些语言),翻译体验不会很好。
1、翻译产品
1.1文字翻译
1)谷歌翻译
谷歌翻译(Google Translate,简称 GT)自2006 年上线以来,一直是最广为人知、用户量最高的在线翻译服务之一,支持多达 133 种语言之间的即时翻译。此外,谷歌翻译使用统计机器翻译(SMT),会在翻译的过程中在经过人工翻译的文档中进行大量检索与推测,并以此得出最适合的翻译结果。
有本书叫《大数据时代》,讲的是谷歌翻译团队,最早是由语言学家和工程师组成。但翻译效果一直上不去,后来开掉一个语言学家,翻译效果就好一点,再开掉一个语言学家,翻译效果又好一点。后来,语言学家全开掉,只剩下工程师们,谷歌翻译终于好用了。就算工程师都不认识阿拉伯文,但翻译效果一样好。
2)DeepL
2017年由德国公司DeepL GmbH推出,以高精度著称,支持31种语言(含中文、日文)。凭借在多语言并行语料学习上的优势获得了业界较高评价。擅长欧系语言,翻译结果相对自然通顺,适用于较高质量要求的商务或学术场景。
1.2 语音翻译
在大模型出现在之前,跟文字翻译的做法类似,这里不在对历史的产品赘述,列举两个当前里程碑的专业级产品,供大家了解。
23年8月,Meta官宣AI大模型SeamlessM4T,能实现近百种语言的自动语音识别、语音到文本翻译,以及近百种输入语言和35种输出语言的语音翻译、文本转语音翻译。同时,Meta还发布了SeamlessAlign的数据集,其博客提到这也是迄今为止最大的开放多模态翻译数据集,覆盖挖掘的语音和文本对齐总计达270000小时。
24年5月,来自中国电信人工智能研究院,AI领域Fellow大满贯科学家李学龙带队,发布首个可同时识别理解粤语、上海话、四川话、温州话等30多种方言。在国际语音顶会INTERSPEECH2024离散语音单元建模挑战赛上,星辰语音识别大模型斩获了语音识别赛道冠军。联合建模使得模型学习到了各个方言之间的共性,显著降低了对新方言标注数据的需求。
2、算法发展阶段
机器翻译(Machine Translation, MT)自上世纪中期萌芽以来,历经规则化、统计化、神经化三大阶段,下面按时间脉络做简要梳理。
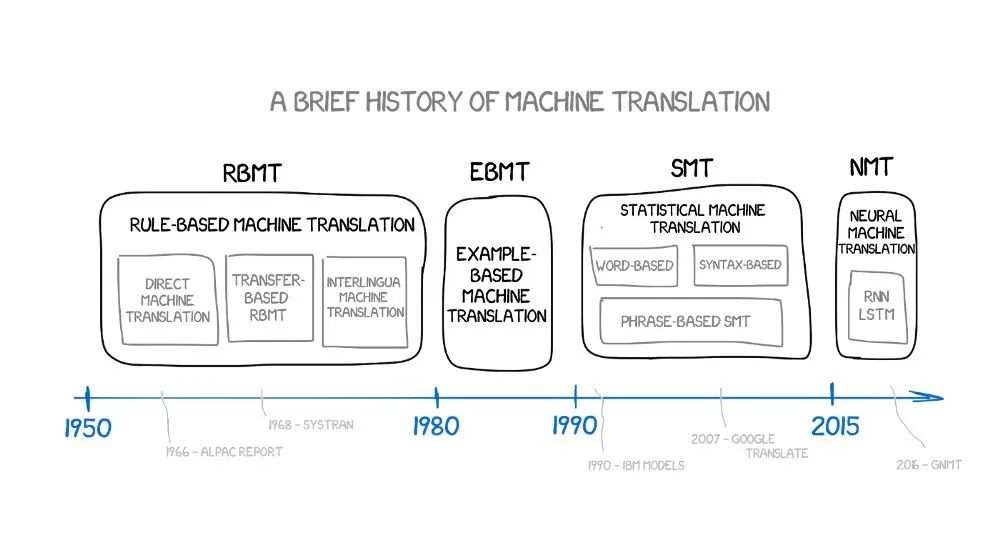
2.1 第一阶段:早期探索与规则驱动
(~1940s - ~1980s)
二战后,受密码破译工作的启发,科学家开始思考用计算机处理语言的可能性。1949年,沃伦·韦弗(Warren Weaver)的备忘录《翻译》(Translation)被认为是机器翻译领域的开创性文献,提出了利用计算机进行语言翻译的初步想法,并类比为“密码破译”。

乔治城-IBM实验 (1954): 首次公开演示了简单的俄语-英语翻译系统,极大提升了公众和政府对MT的期望和投入。主要依赖语言学家编写大量的双语词典和语法规则。
优点: 依赖明确的语言学知识,可解释性强,对于特定领域和语言对,如果规则完备,效果尚可。
缺点: 规则编写成本极高、耗时耗力;难以覆盖语言的复杂性和歧义性;系统非常“脆弱”,遇到规则未覆盖的现象就失败;生成的译文往往生硬、不自然。
如下图,规则翻译逼死语言学家~
美国政府资助的自动语言处理咨询委员会(ALPAC)发布报告,严厉批评了当时机器翻译的研究进展缓慢、成本高昂且质量低下,远未达到预期。导致美国政府大幅削减对MT研究的资助,使该领域进入了一段相对沉寂的时期,被称为机器翻译领域的“寒冬”。研究重点转向更基础的计算语言学问题。
2.2 第二阶段:数据驱动的复兴 - 统计机器翻译
(~1980s末 - ~2010s中期)
随着计算能力的提升和大规模双语平行语料库(Parallel Corpus)的出现,研究思路发生根本转变。不再依赖人工编写规则,而是让计算机自动从大量平行文本中学习翻译模式。翻译被视为一个概率问题:给定源语言句子 S,寻找最可能的目标语言句子 T,即最大化 P(T|S)。根据贝叶斯定理,这通常分解为翻译模型 P(S|T) 和语言模型 P(T) 的乘积。

早期模型: IBM提出的词对齐模型(IBM Models 1-5)。
基于短语的SMT (Phrase-Based SMT, PBSMT): 成为SMT的主流。它不再是词对词翻译,而是学习短语(连续的词序列)之间的对应关系,能更好地处理局部词序和搭配。
代表系统如 Moses。
基于句法的SMT (Syntax-Based SMT): 尝试融入句法结构信息,如层次短语模型(Hierarchical Phrase-Based MT)或基于树结构的转换模型,试图解决长距离依赖和结构转换问题,但实现复杂,效果提升有限。
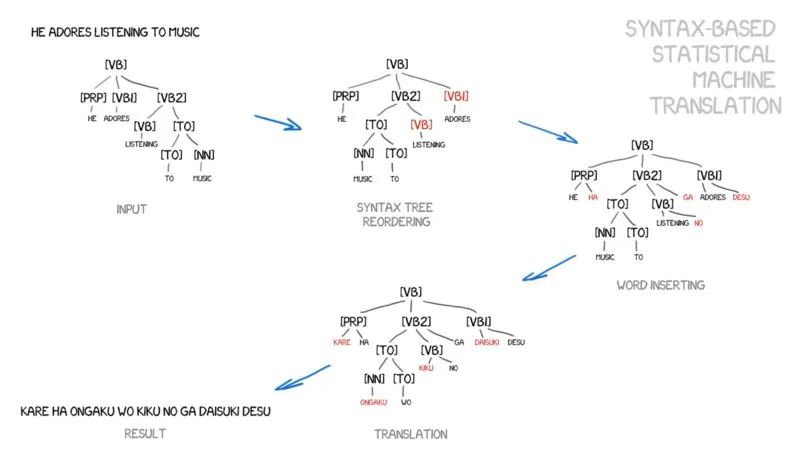
优点: 自动化程度高,无需手动编写规则;能从数据中学习到更自然的表达;对数据规模敏感,数据越多效果越好;相对RBMT,生成的译文更流畅。
缺点: 严重依赖平行语料的规模和质量;对语序差异大的语言对处理不佳;缺乏深层语义理解,常出现“貌合神离”的错误;模型复杂,包含多个独立训练和调优的组件(对齐、短语提取、排序、语言模型等)。
2.3 第三阶段:深度学习革命 - 神经机器翻译
(~2014年至今)
深度学习,特别是循环神经网络(RNN)和后来的Transformer架构,彻底改变了机器翻译领域。核心思想: 使用一个端到端(End-to-End)的神经网络模型直接将源语言序列映射到目标语言序列。
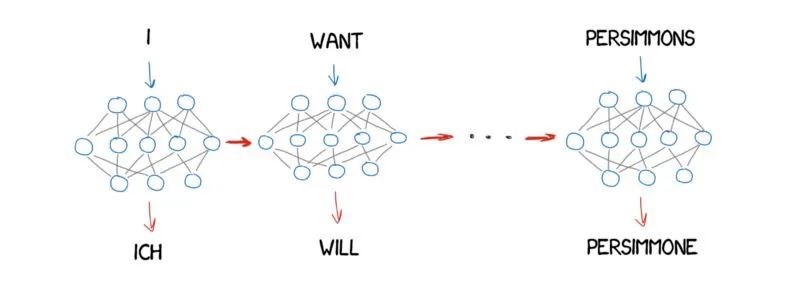
早期NMT (基于RNN): 通常采用编码器-解码器(Encoder-Decoder)架构,使用RNN(如LSTM或GRU)来处理序列信息。编码器将源句子压缩成一个固定大小的向量(上下文向量),解码器再基于这个向量生成目标句子。
注意力机制 (Attention Mechanism): 解决了早期NMT难以处理长句和信息丢失的问题。允许解码器在生成每个目标词时,“关注”源句子中与之相关的不同部分,极大提升了NMT性能。
Transformer模型 (2017): 完全抛弃RNN,仅依赖自注意力(Self-Attention)机制来捕捉词与词之间的依赖关系。可以并行计算,训练效率更高,并且在长距离依赖捕捉上表现出色,迅速成为NMT乃至整个自然语言处理领域的主流架构(如BERT, GPT等的基础)。
3、Transformer架构
3.1 Tranformer基础架构
Transformer是由Vaswani等人在2017年提出的一种基于自注意力(Self-Attention)机制的深度学习模型架构,广泛应用于自然语言处理(NLP)、计算机视觉等领域。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)结构,依靠并行化计算和高效的信息建模方式,极大推动了AI的发展。
1)基础架构
Transformer主要由两大部分组成:编码器(Encoder)和解码器(Decoder)。每个部分都包含多个相同的层堆叠而成。对于标准的Transformer模型来说,编码器和解码器各包含6层,但这个数字可以根据实际应用的需求进行调整。
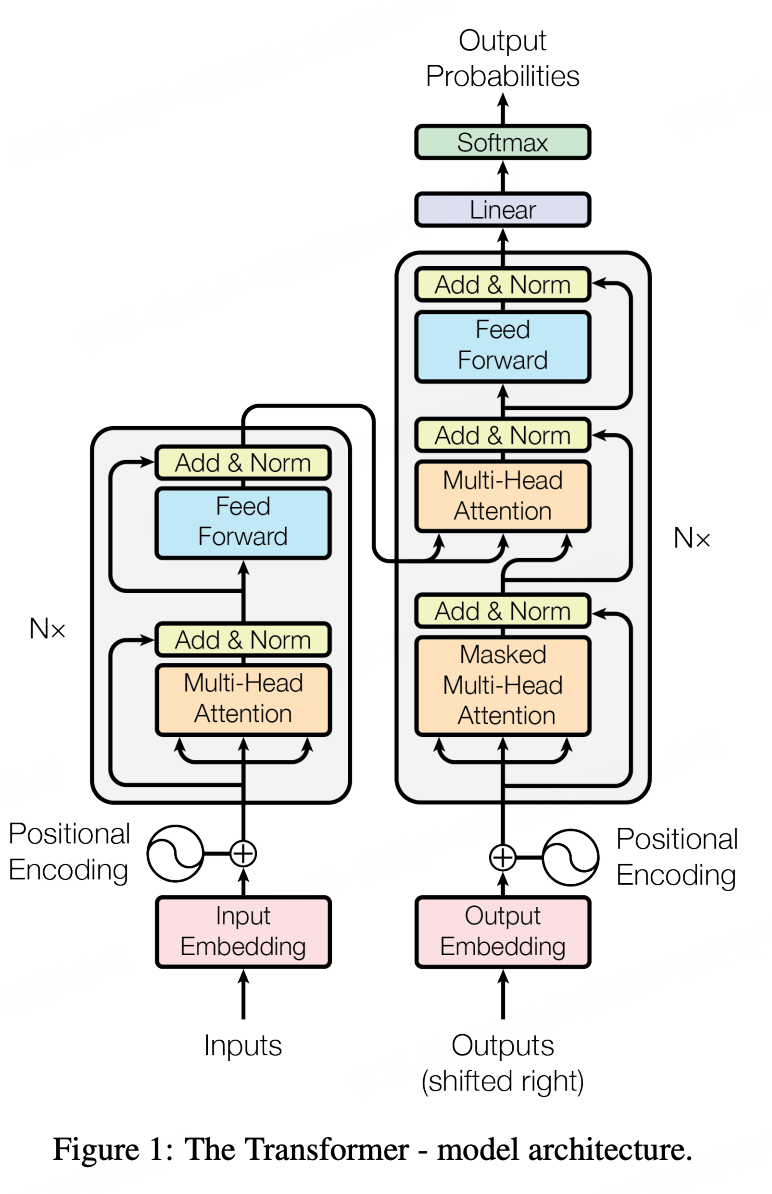
2)编码器
输入嵌入:首先将输入序列中的每个词转换为固定维度的向量表示。
位置编码:由于Transformer没有使用任何递归或卷积结构来捕捉序列信息,因此需要一种方式来让模型了解到每个词的位置信息。通过添加位置编码到输入嵌入上,可以实现这一点。
多头自注意力机制:这是Transformer的核心组件之一。它允许模型同时关注序列中的不同位置,而不仅仅依赖于当前词及其前后的局部上下文。多头机制则是指对同一组数据执行多次不同的线性变换,然后分别计算注意力权重,最后将结果合并起来,以捕捉不同方面的相关信息。
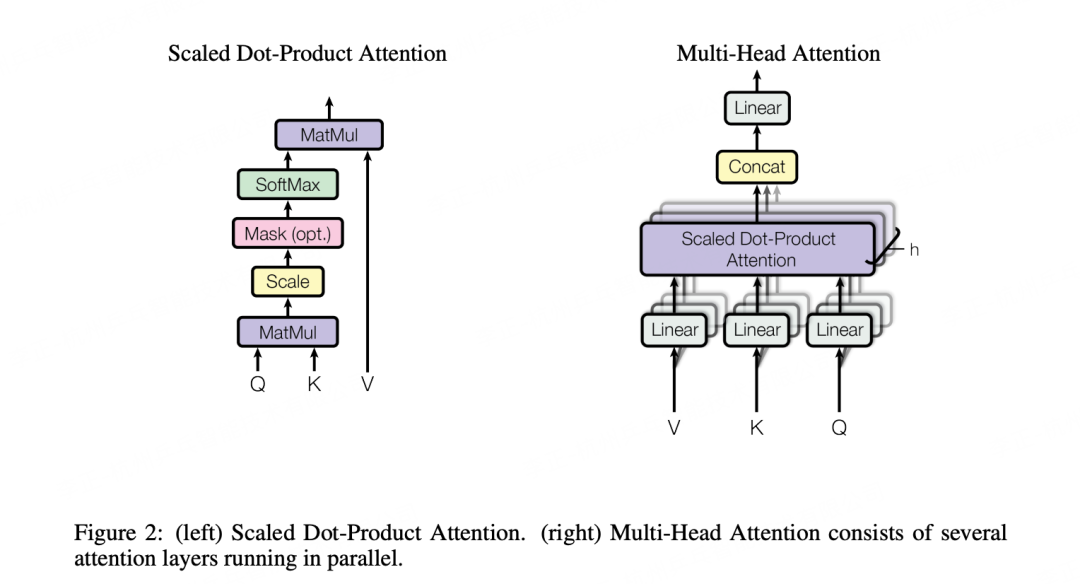
前馈神经网络:每个多头自注意力层之后都会跟随一个简单的全连接前馈网络,该网络对每个位置上的向量独立地应用相同的线性变换。
残差连接与层归一化:为了促进深层网络的训练,在每个子层(即多头自注意力层和前馈网络层)周围都添加了残差连接,并在其后应用层归一化技术。
3)解码器
解码器的结构与编码器相似,但也有一些关键差异:
在解码器中也采用了多头自注意力机制,但是这里使用的是一种特殊的掩码版本,确保预测下一个词时不会看到未来的信息;
除了自注意力层之外,解码器还包含了一个编码器-解码器注意力层,这使得解码器能够在生成输出时参考整个输入序列的信息;
解码器同样具有自己的位置编码、前馈神经网络以及相应的残差连接和层归一化步骤。
3.2 最小规格的模型参数量计算
超参数设置:
D_MODEL = 32
NHEAD = 2
NUM_ENCODER_LAYERS = 1
NUM_DECODER_LAYERS = 1
DIM_FEEDFORWARD = 64
vocab_size = 10
1)词嵌入层 (Embeddings)
假设源端、目标端各一套不共享的词嵌入,Embedding 大小均为
vocab_size × D_MODEL:
• 源端嵌入:10 × 32 = 320
• 目标端嵌入:10 × 32 = 320
合计:320 + 320 = 640
注:位置编码通常使用固定的函数(如sin/cos)生成,不计入可训练参数。
2)单个 EncoderLayer 的参数
一个典型的 EncoderLayer 通常包含以下子模块:
Multi-Head Self-Attention
前向全连接 (Feed Forward, FFN)
两个 LayerNorm(各自子层的残差连接后都会跟一个 LayerNorm)
(1) Multi-Head Self-Attention
对于 PyTorch 的 nn.MultiheadAttention 而言,参数主要分为四部分:
• in_proj_weight: 形状为 (3×d_model, d_model),即 3×32×32 = 3072
• in_proj_bias: 形状为 (3×d_model),即 3×32 = 96
• out_proj.weight: 形状为 (d_model, d_model),即 32×32 = 1024
• out_proj.bias: 形状为 (d_model),即 32
因此,单个多头注意力的参数量 = 3072 + 96 + 1024 + 32 = 4224
(2) Feed Forward 子层
包含两层线性变换,激活函数一般不带额外参数,故只算线性层:
• Linear1:
(DIM_FEEDFORWARD × D_MODEL) + DIM_FEEDFORWARD
= (64×32) + 64 = 2048 + 64 = 2112
• Linear2: (D_MODEL × DIM_FEEDFORWARD) + D_MODEL
= (32×64) + 32 = 2048 + 32 = 2080
Feed Forward 合计 = 2112 + 2080 = 4192
(3) LayerNorm
每个 LayerNorm 对象有 2×d_model 个参数(γ 和 β),d_model = 32 ⇒ 每个 LN = 64。
EncoderLayer 有两个子层(自注意力、FFN),各带一个 LN ⇒ 2×64 = 128
(4) 小结:
单个 EncoderLayer 的参数
= 多头自注意力 4224 + 前向全连接 4192 + LayerNorm 128
= 4224 + 4192 + 128
= 8544
因为NUM_ENCODER_LAYERS = 1,所以整个 Encoder 部分的可训练参数就是 8544。
3)单个 DecoderLayer 的参数
一个典型的 TransformerDecoderLayer(以 PyTorch 为例)通常包含以下子模块:
Masked Multi-Head Self-Attention (针对目标端的序列本身)
Cross-Attention (与编码器输出做注意力)
前向全连接 (Feed Forward, FFN)
三个 LayerNorm(每个子层对应一个 LN)
自注意力(MHA)
与 Encoder 相同,参数量 = 4224
交叉注意力(MHA)
与自注意力同样的结构(维度相同),参数量也 = 4224
前馈网络(FFN)
与 Encoder 的 FFN 参数量相同 = 4192
LayerNorm
在 DecoderLayer 中往往有 3 个 LayerNorm,每个同理都是 2×d_model=64 个参数。
→ 3 个共 192
因此,单个 DecoderLayer 参数量 = (自注意力) + (交叉注意力) + (前馈网络) + (3×LayerNorm)
= 4224 + 4224 + 4192 + 192 = 12832
4)输出层 (线性投影到 vocab)
将解码器的输出投影到词表大小 (vocab_size=10)。这是一个 Linear 层:
• weight: (vocab_size × d_model) = 10×32 = 320
• bias: (vocab_size) = 10
合计:320 + 10 = 330
5)合计参数量
源、目标嵌入:640
编码器(1 层):8544
解码器(1 层):12832
输出层:330
总参数量
= 词嵌入 + 编码器层 + 解码器层 + 最终线性层 总参数量
= 640 + 8544 + 12832 + 330
= 22346
6)与实际代码的差异
nn.TransformerEncoder 模块在其所有层执行完毕 之后,还会应用一个最终的层归一化 self.norm。因此在编码和解码层会分别多出encoder.norm (LN): 32 + 32 = 64个参数。因此代码执行后的参数量是22474;
代码参考:
https://github.com/jacksonjack001/deepnoting_lessons/blob/main/3-transformer_train_demo.py
7)结语
通过这次的参数量结算对比,小编确信了gemini2.5pro已经遥遥领先openAI系列的所有模型了,当然也包括sonnet3.7thinking系列;首先是生成代码的长度和可执行性,gemini基本上长度可以多一倍,且基本都可以直接运行;
其次是参数量分析逻辑,运行几次,gemini都是稳定输出一样的结果,然后o3-mini/o1基本每次结果不一样;
最后是对比分析,o1直接输出可能得点了,而gemini会完整的执行分析链路理论逻辑和代码逻辑,然后找出差异;
附注提示词:
1)理论分析
假设超参数设置如下
D_MODEL = 32
NHEAD = 2
NUM_ENCODER_LAYERS = 1
NUM_DECODER_LAYERS = 1
DIM_FEEDFORWARD = 64
MAX_LEN = 10
vocab_size = 10(即数字0-9)
计算下Transformer参数量
2)对比
假设超参数设置如下
D_MODEL = 32
NHEAD = 2
NUM_ENCODER_LAYERS = 1
NUM_DECODER_LAYERS = 1
DIM_FEEDFORWARD = 64
MAX_LEN = 10
vocab_size = 10(即数字0-9)
上述配置Transformer理论参数量22346,但是实际代码中的参数量22474,分析下为什么参数量会有差异?
代码如下:{code}
3.3 面向机器翻译的开源模型
MarianNMT
Marian NMT(机器翻译深度学习框架)没用使用 TensorFlow 或 PyTorch 之类的通用机器学习框架来实现翻译模型。取而代之的是使用 Marian NMT,这是一个基于 C++的机器学习框架,专门为机器翻译而设计,主要由 Microsoft Translator 团队开发,它已经内置了多个神经翻译模型架构。
OpenNMT
OpenNMT 是一个由 Harvard NLP (哈佛大学自然语言处理研究组) 开源的 Torch 神经网络机器翻译系统。简单的通用接口,只需要源/目标文件。快速高性能GPU训练和内存优化。提高翻译性能的最新的研究成果。
Marian NTM 和 OpenNTM 的一个大的区别是: OpenNTM使用了 SGD , 而 Marian NTM 没有使用。
开源翻译语言模型fairseq
Meta AI在发布开源大型预训练模型OPT之后,再次发布最新成果NLLB。NLLB的全称为No Language Left Behind,如果套用某著名电影,可以翻译成“一个语言都不能少”。这其中,中文分为简体繁体和粤语三种,而除了中英法日语等常用语种外,还包括了许多小众语言。
3.3 大模型的机器翻译适配
大模型能够主动进行语义理解与内容重构,而不是简单的文字转换,从而避免了各种哭笑不得的歧义。AI翻译中融入了情境化翻译能力,这就使它能够依据特定的环境及目标受众进行智能调整。
4、商业化场景
随着LLM的多语言能力越来越强,也让此前鲜有进展的AI翻译赛道,突然卷了起来。早已布局的科技大厂,以及刚刚下场的各路LLM初创,纷纷推出了自家的AI翻译产品。
4.1 阿里的电商翻译
阿里国际站翻译神器推出Marco,产品名AIdge,电商场景效果超google。Marco翻译大模型可支持三种方式的翻译:基于语境的产品翻译、图像翻译、实时聊天翻译。在处理电商专有词、流行词和口语词等翻译任务时,这个模型不仅能更好地保留原意,还能立马输出简洁、准确的表达,而且非常符合「歪果仁」的语言习惯。
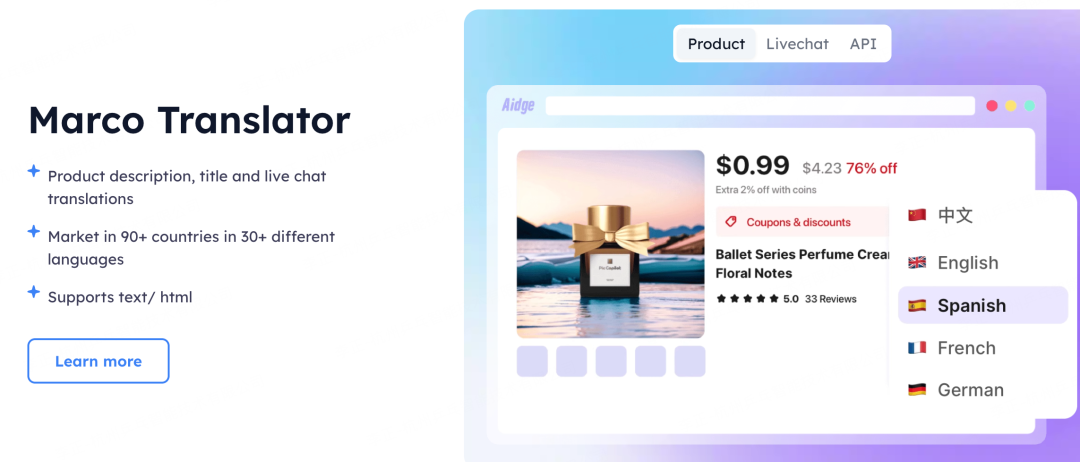
比如「光腿神器」的翻译,以往的两个翻译产品分别是「A magical tool for bare legs」(一个神奇的光腿工具)和「Bare legs god」(光腿神)。而用了Marco翻译大模型,「The bare leg artifact」的译法简洁精妙,老外看了都说好!
4.2 腾讯的翻译Agent
鹅厂搞了个150多人的“翻译公司”,从老板到员工都是AI智能体!主营业务是翻译网络小说,质量极高,参与评价的读者认为比真人翻译得还要好。
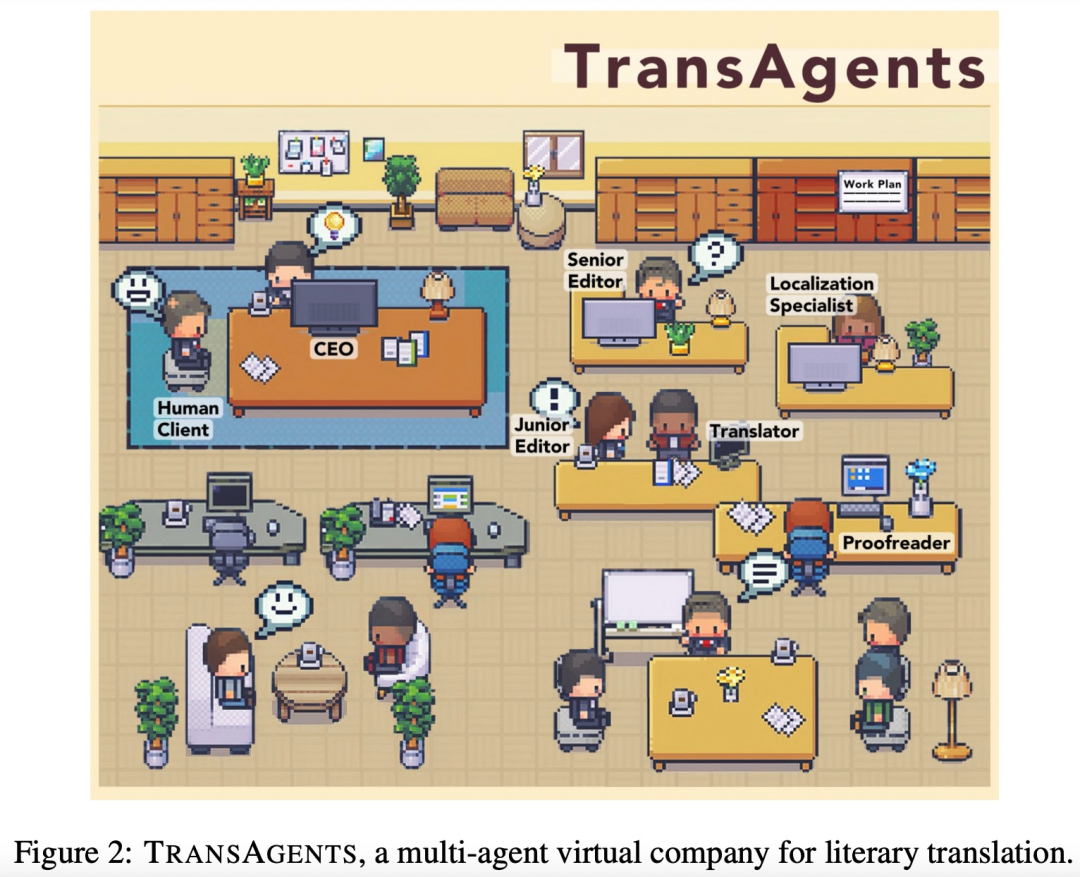
在这个公司当中,不同的智能体分别扮演着CEO、初/高级编辑、真·翻译、本地化专家和校对(Proofreader)这些不同的职位,除CEO外每个职位各有30人,每个人擅长的领域也有所不同,另外还有一个Ghost Agent。
4.3 沉浸式翻译
沉浸式翻译是一款功能强大的双语对照网页翻译插件,旨在帮助用户突破语言障碍,提升信息获取效率。自2023年上线以来,已帮助超过100万用户跨越语言障碍,自由汲取全球智慧。主要指通过插件或应用,将网页、PDF、视频等内容以“原文+译文”双语对照的形式自然地嵌入到原有内容流中,实现无缝、低侵入感的双语阅读体验。
有人对此表示了担忧,认为由AI来主导翻译,会导致语言的同质化,让各种语言中独特的表达消失。
5、大模时代的实际效果对比
1)评估价值
这里引用hacknews上的一句很经典的“评估价值”来对比下大模型的翻译和google翻译的翻译差异:

2)长难句
在举一个例子来说明,最顶尖的直达类模型和推理模型的翻译能力~这个是我让DeepSeekR1想出来的题目。
原文:
While Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo, the chef with a cleaver cleaves cleverly, leaving the leaves quivering, as the bandage wound around the wound wound around the spool, and the farm used to produce produce, now producing tears, where the wind was too strong to wind the sail, but the bass swam past the bass drum, and the Polish window polishers polished windows while pondering the Polish pottery's peculiar polish.

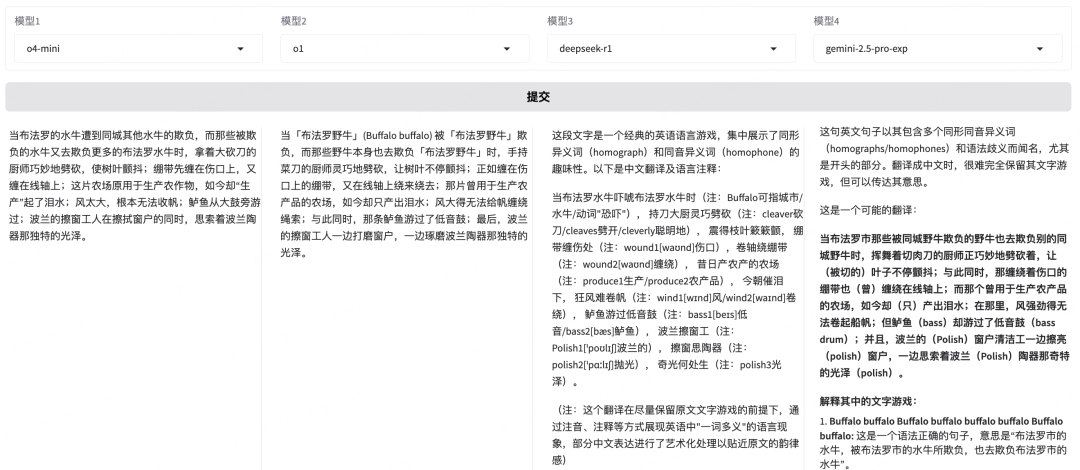
尊敬的读者,请问上面长难句翻译看懂了么,哈哈~

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献184条内容
已为社区贡献184条内容

所有评论(0)