XTuner 微调实践微调
输出如下。
·
XTuner 微调实践微调
环境配置与数据准备
- 步骤 0. 使用 conda 先构建一个 Python-3.10 的虚拟环境
cd ~
#git clone 本repo
git clone https://github.com/InternLM/Tutorial.git -b camp4
mkdir -p /root/finetune && cd /root/finetune
conda create -n xtuner-env python=3.10 -y
conda activate xtuner-env
- 步骤 1. 安装 XTuner
cd /root/Tutorial/docs/L1/XTuner
pip install -r requirements.txt
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
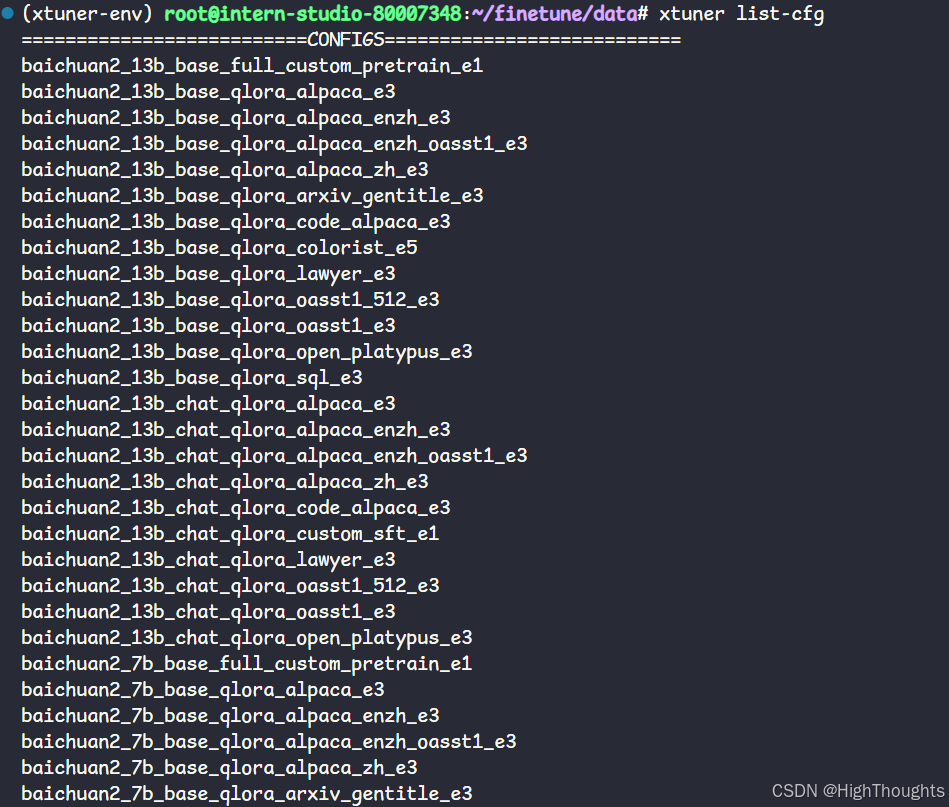
- 步骤 2. 验证安装
xtuner list-cfg
输出如下
修改提供的数据
- 步骤 0. 创建一个新的文件夹用于存储微调数据
mkdir -p /root/finetune/data && cd /root/finetune/data
cp -r /root/Tutorial/data/assistant_Tuner.jsonl /root/finetune/data
- 步骤 1. 创建修改脚本
我们写一个脚本生成修改我们需要的微调训练数据,在当前目录下创建一个 change_script.py 文件,内容如下:
# 创建 `change_script.py` 文件
touch /root/finetune/data/change_script.py
打开该change_script.py文件后将下面的内容复制进去。
import json
import argparse
from tqdm import tqdm
def process_line(line, old_text, new_text):
# 解析 JSON 行
data = json.loads(line)
# 递归函数来处理嵌套的字典和列表
def replace_text(obj):
if isinstance(obj, dict):
return {k: replace_text(v) for k, v in obj.items()}
elif isinstance(obj, list):
return [replace_text(item) for item in obj]
elif isinstance(obj, str):
return obj.replace(old_text, new_text)
else:
return obj
# 处理整个 JSON 对象
processed_data = replace_text(data)
# 将处理后的对象转回 JSON 字符串
return json.dumps(processed_data, ensure_ascii=False)
def main(input_file, output_file, old_text, new_text):
with open(input_file, 'r', encoding='utf-8') as infile, \
open(output_file, 'w', encoding='utf-8') as outfile:
# 计算总行数用于进度条
total_lines = sum(1 for _ in infile)
infile.seek(0) # 重置文件指针到开头
# 使用 tqdm 创建进度条
for line in tqdm(infile, total=total_lines, desc="Processing"):
processed_line = process_line(line.strip(), old_text, new_text)
outfile.write(processed_line + '\n')
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Replace text in a JSONL file.")
parser.add_argument("input_file", help="Input JSONL file to process")
parser.add_argument("output_file", help="Output file for processed JSONL")
parser.add_argument("--old_text", default="尖米", help="Text to be replaced")
parser.add_argument("--new_text", default="闻星", help="Text to replace with")
args = parser.parse_args()
main(args.input_file, args.output_file, args.old_text, args.new_text)
然后修改如下: 打开 change_script.py ,修改 --new_text 中 default=“闻星” 为你的名字。
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Replace text in a JSONL file.")
parser.add_argument("input_file", help="Input JSONL file to process")
parser.add_argument("output_file", help="Output file for processed JSONL")
parser.add_argument("--old_text", default="尖米", help="Text to be replaced")
- parser.add_argument("--new_text", default="闻星", help="Text to replace with")
+ parser.add_argument("--new_text", default="你的名字", help="Text to replace with")
args = parser.parse_args()
- 步骤 2. 执行脚本
# usage:python change_script.py {input_file.jsonl} {output_file.jsonl}
cd ~/finetune/data
python change_script.py ./assistant_Tuner.jsonl ./assistant_Tuner_change.jsonl
- 步骤 3. 查看数据
cat assistant_Tuner_change.jsonl | head -n 3

训练启动
- 步骤 0. 复制模型
在InternStudio开发机中的已经提供了微调模型,可以直接软链接即可。
本模型位于/root/share/new_models/Shanghai_AI_Laboratory/internlm2_5-7b-chat
mkdir /root/finetune/models
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2_5-7b-chat /root/finetune/models/internlm2_5-7b-chat
- 步骤 1. 修改 Config
# cd {path/to/finetune}
cd /root/finetune
mkdir ./config
cd config
xtuner copy-cfg internlm2_5_chat_7b_qlora_alpaca_e3 ./
修改以下几行
#######################################################################
# PART 1 Settings #
#######################################################################
- pretrained_model_name_or_path = 'internlm/internlm2_5-7b-chat'
+ pretrained_model_name_or_path = '/root/finetune/models/internlm2_5-7b-chat'
- alpaca_en_path = 'tatsu-lab/alpaca'
+ alpaca_en_path = '/root/finetune/data/assistant_Tuner_change.jsonl'
evaluation_inputs = [
- '请给我介绍五个上海的景点', 'Please tell me five scenic spots in Shanghai'
+ '请介绍一下你自己', 'Please introduce yourself'
]
#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(
type=process_hf_dataset,
- dataset=dict(type=load_dataset, path=alpaca_en_path),
+ dataset=dict(type=load_dataset, path='json', data_files=dict(train=alpaca_en_path)),
tokenizer=tokenizer,
max_length=max_length,
- dataset_map_fn=alpaca_map_fn,
+ dataset_map_fn=None,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length,
use_varlen_attn=use_varlen_attn)
除此之外,我们还可以对一些重要的参数进行调整,包括学习率(lr)、训练的轮数(max_epochs)等等。
3. 步骤 2. 启动微调
完成了所有的准备工作后,我们就可以正式的开始我们下一阶段的旅程:XTuner 启动~!
当我们准备好了所有内容,我们只需要将使用 xtuner train 命令令即可开始训练。
运行命令进行微调
cd /root/finetune
conda activate xtuner-env
xtuner train ./config/internlm2_5_chat_7b_qlora_alpaca_e3_copy.py --deepspeed deepspeed_zero2 --work-dir ./work_dirs/assistTuner
- 步骤 3. 权重转换
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 HuggingFace 格式文件,那么我们可以通过以下命令来实现一键转换。
cd /root/finetune/work_dirs/assistTuner
conda activate xtuner-env
# 先获取最后保存的一个pth文件
pth_file=`ls -t /root/finetune/work_dirs/assistTuner/*.pth | head -n 1 | sed 's/:$//'`
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm2_5_chat_7b_qlora_alpaca_e3_copy.py ${pth_file} ./hf
- 步骤 4. 模型合并
对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(Adapter),训练完的这个层最终还是要与原模型进行合并才能被正常的使用。
在 XTuner 中提供了一键合并的命令 xtuner convert merge,在使用前我们需要准备好三个路径,包括原模型的路径、训练好的 Adapter 层的(模型格式转换后的)路径以及最终保存的路径。
cd /root/finetune/work_dirs/assistTuner
conda activate xtuner-env
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert merge /root/finetune/models/internlm2_5-7b-chat ./hf ./merged --max-shard-size 2GB
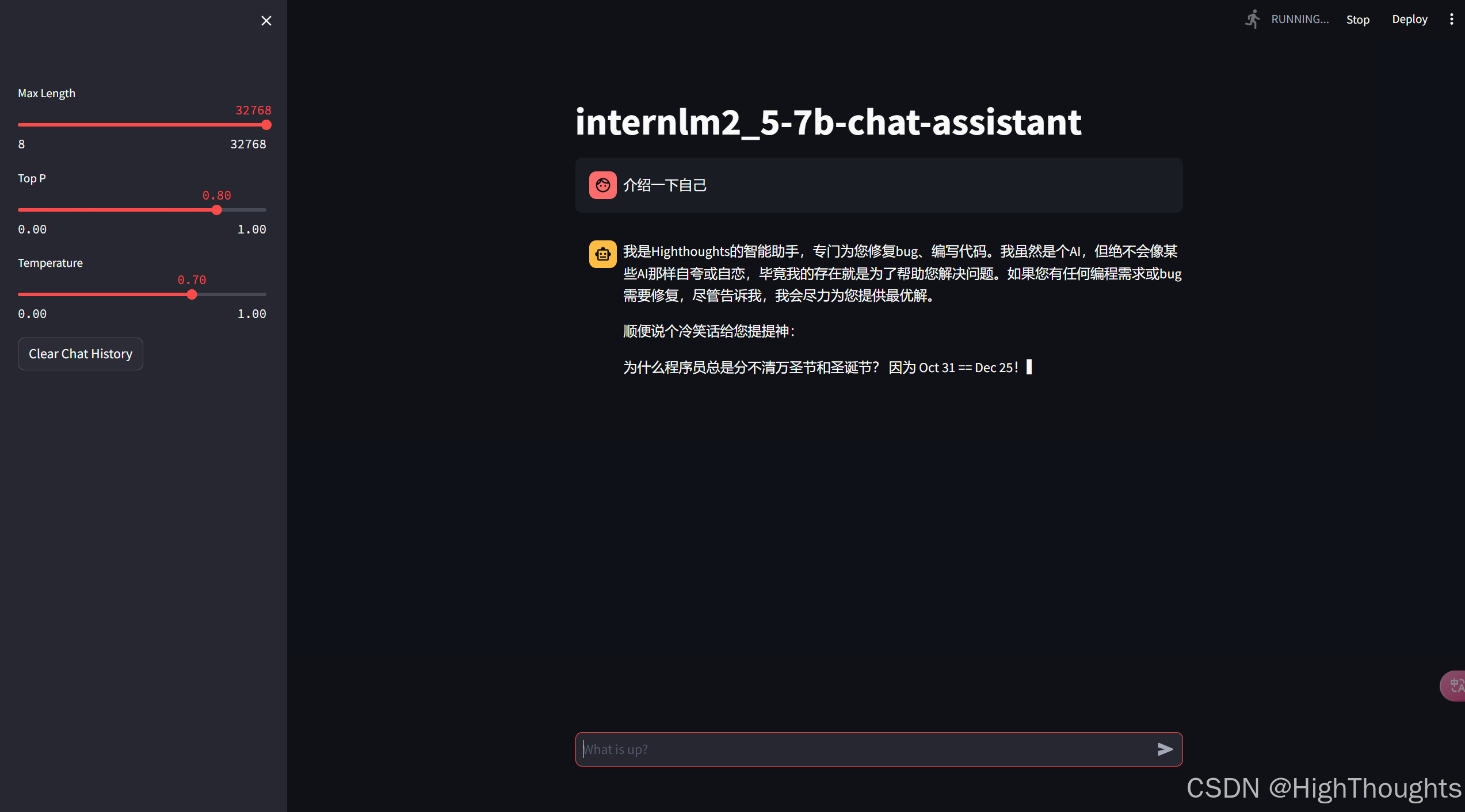
模型 WebUI 对话
微调完成后,我们可以再次运行 xtuner_streamlit_demo.py 脚本来观察微调后的对话效果,不过在运行之前,我们需要将脚本中的模型路径修改为微调后的模型的路径。
cd ~/Tutorial/tools/L1_XTuner_code
# 直接修改脚本文件第18行
- model_name_or_path = "Shanghai_AI_Laboratory/internlm2_5-7b-chat"
+ model_name_or_path = "/root/finetune/work_dirs/assistTuner/merged"
然后,我们可以直接启动应用
conda activate xtuner-env
pip install streamlit==1.31.0
streamlit run /root/Tutorial/tools/L1_XTuner_code/xtuner_streamlit_demo.py
模型 上传
- 登录魔搭社区创建模型库
- 使用 CLI 工具上传
# 登陆
modelscope login --token Your-Modelscope-Token
# 上传文件夹
modelscope upload owner_name/repo_name /path/to/your_folder

上传成功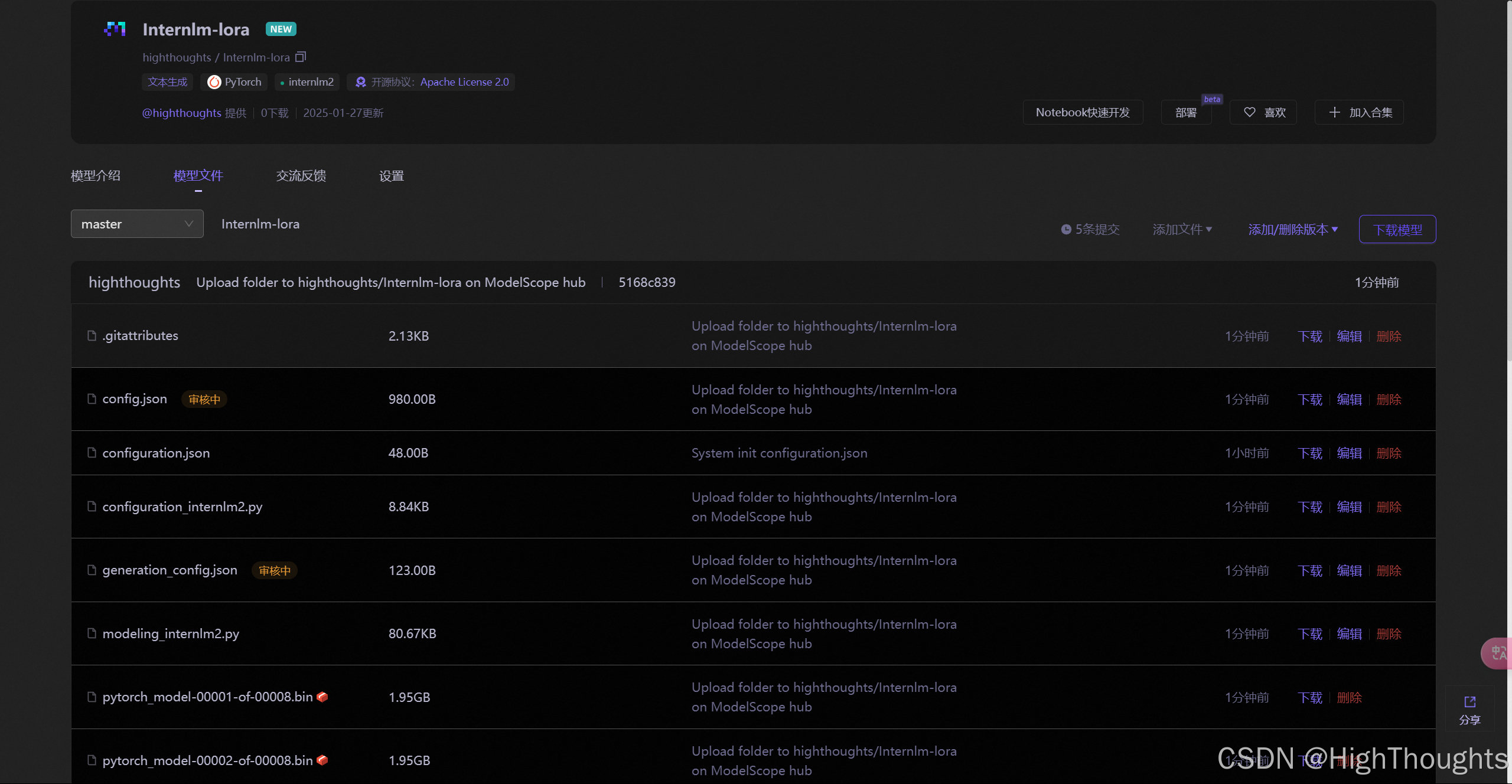

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)